
En el presente post pretendemos mostrar la problemática que con frecuencia encontramos en los procesos de extracción, validación y carga de datos en los entornos Big Data.
Evolución procesos ETL. Problemática en entornos Big Data
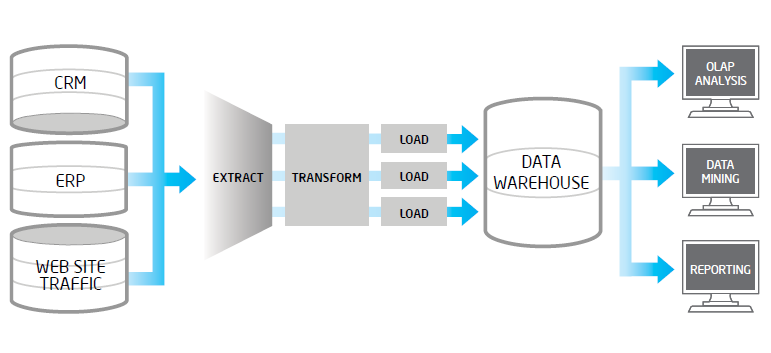
Un proceso ETL tradicional, extrae datos desde múltiples fuentes origen, después los valida, normaliza, realiza determinadas transformaciones y vuelca los mismos en un entorno datawarehouse para su posterior análisis. Cuando en los datos fuentes, tenemos volúmenes altos, una frecuencia de actualización alta en origen o bien son datos no estructurados, estos procesos ETL tradicionales suelen tener problemas en su adaptación, esta suele ser costosa y pueden tener problemas de rendimiento.
El 80% de los esfuerzos de desarrollo en un proyecto Big Data están en los procesos de integración y sólo un 20% en los procesos de análisis de datos propiamente dichos.
De forma muy resumida, los procesos ETL realizan los siguientes pasos:
- Extraer datos de múltiples fuentes como ERP, CRM, sistemas operaciones diversos que proveen ficheros con formatos varios (host, csv, XML), etc…, algunos de ellos serán sistemas legacy que pueden tener formatos de datos antiguos y costosos de tratar.
- Transformar estos datos en la estructura que hayamos definido en nuestro datawarehouse. El paso de transformación, incluye acciones de validación sobre reglas de negocio, validaciones técnicas (duplicados, integridad, nulos..), normalización y homogeneización de códigos, cambios de formato, así como costosos procesos de ordenación, filtrados, cruces y agregados.
- Carga (Load) de datos en las estructuras de almacenamiento datawarehouse. Este paso puede ser realizado en procesos batch y pueden ser de diferente tipos: por lotes, registro a registro, cargas totales, cargas incrementales, etc..
Históricamente estos procesos se han realizado codificando manualmente en lenguajes tipo Cobol, RPG, PL-SQL, SAS/BASE, etc.. , actualmente se estima que todavía el 40% del trabajo sobre procesos ETL (nueva creación, mantenimiento) se realiza con herramientas de este tipo y codificando a mano.
Si bien, las herramientas ETL de generación de código también tienen sus limitaciones, ya que no mapean todo tipo de sistemas fuente o destino y no dan soporte a todo tipo de transformaciones, siendo limitados para procesos con una lógica de transformación compleja. Estas limitaciones se han ido mitigando en las últimas versiones de estas herramientas de ETL, sobre todo en lo relativo a mapeo de fuentes origen y destino. Herramientas tales como Informática Power Center, SAS Data Integration, Capa de integración Oracle B.I, SSIS sobre Microsoft SQL Server, Pentaho Kettle, Business Objetcs Data Integrator, Cognos Decisionstream, etc…
Las arquitecturas ETL tradicionales realizan múltiples iteraciones y se componen de procesos y áreas intermedias, tales como la “staging area”. Adicionalmente, podemos tener procesos ETL posteriores que vayan del datawarehouse a los data marts que realizan análisis temáticos. Lo cual complica la arquitectura, tendiendo a crecer tanto las áreas y procesos intermedios, como nuevas ramas de salida de datos del datawarehouse.
El ETL tradicional se ha visto afectado en las últimas décadas por la mejoría de capacidad de proceso de lo SGDB, que permiten realizar en SQL transformaciones complejas y tratar volúmenes de datos altos. Por otro lado, la incorporación de capacidades de minería de datos in-database, procesos de limpieza y validación de datos in-database, o ejecución de algoritmo complejos in-database han cambiado el concepto de los procesos ETL, apareciendo el llamado ELT que realiza la mayor parte de tratamiento de datos dentro del motor de la base de datos.
El procesado ELT conlleva ventajas, ya que al realizar los procesos de transformación pesados en la propia base de dato destino, nos podemos aprovechar de la escalabilidad de estas bases de datos, son más fácilmente adaptables al crecimiento del volumen de datos y están ya optimizadas par procesos I/O.
El siguiente paso ha sido la aparición de procesos ETLT, en los cuales las herramientas ETL permiten ambas opciones, pudiendo realizar el grueso de la transformación en la propia base de datos o realizarlo con las capacidades de la herramienta (sobre todo para pasos no soportados por la BBDD) y finalmente volcarlos.
No obstante, esta evolución tecnológica da soporte con grandes dificultades y costes a los desafíos ‘Big Data’, relativos a crecimiento de volumen de datos, complejidad de los mismos y diversidad en la naturaleza, estructuración y origen del dato: foro de discusión, sites de noticias, redes sociales, wikis, tweets, blogs, etc…
Encontramos habitualmente problemas en el volumen de datos, su frecuencia de actualización, estructuración de datos y diversidad de sistemas fuente, por mencionar sólo algunos.
Propuesta Apache Hadoop
Bajo las circunstancias expuestas anteriormente, vemos las soluciones que puede darnos una herramienta Big Data como Apache Hadoop:
- Posibilidad de insertar volúmenes altos de datos, sin especificar un esquema predefinido de datos previamente. Esto es válido tanto para datos estructurados como no estructurados. Es una característica de Hadoop llamada “no schema on-write”. En SQL tradicional necesitamos crear las tablas u objetos de BBDD destino de la información, previamente a ser cargados. Esto, no es necesario en Hadoop. La estructura de datos, es en Hadoop necesaria al leer datos (“schema on-read”), no al vocarlo.
- Posibilidad de realizar procesos offload posteriores al volcado. Una vez los datos ya están en la estructura Hadoop, podemos ejecutar (paralelizando tareas), tareas de limpieza, normalización y agregación de datos.
Hadoop te permite evitar problemas de rendimiento en el ETL realizando las tareas de transformación en post-procesos (offload). Por otra parte, proporciona mayores capacidades de mapeo de fuentes, aceptando tipos de datos complejos o información no estructurada. Gracias a su arquitectura escalable, podemos acelerar los procesos ETL de forma sencilla. Y por último, su capacidad de almacenamiento nos permite mantener datos al nivel de granularidad más bajo que necesitemos.
Empleando Hadoop de este modo, podemos almacenar datos que nunca deberían estar en el data warehouse. Por ejemplo datos, que un analista puede necesitar para enriquecer sus modelos analíticos, tales como: datos de redes sociales, blogs, foros, etc…., que pueden ser almacenados en Hadoop sin afectar al data warehouse. Así mismo, con independencia de que empleemos procesos, ETL, ELT o ETLT en la población del data warehouse, podemos reducir costes operacionales de la solución B.I. completa, realizando transformación ETL en modo offload usando el MapReduce en HDFS dentro de nuestra arquitectura Hadoop, pudiendo tratar información heterogénea en un entorno escalable y tolerante al fallo.

Es un tema interesante, sin
Subido por Carmen G. (no verificado) el 9 Abril, 2014 - 12:49
Es un tema interesante, sin embargo, hay conceptos de estas herramientas que a los que venimos de las BBDD relacionales SQL, no acabamos de entender.
¿Qué es "schema on-read"?
Gracias y un saludo,
Las BBDD tradcionales emplean
Subido por Juan_Vidal el 9 Abril, 2014 - 15:10
Las BBDD tradcionales emplean "schema on-write" el cual necesita que la estructura del objeto de base de datos esté definido previo a la carga y los datos son validados contra esta estructura. Por ejemplo, para cargar una tabla, debemos ejecutar previamente el 'create table ...', con las validaciones (constraints) que creamos necesarias. Sin embargo el modelo "schema on-read" que emplean algunas herramientas 'Big Data' no necesita una estructura previa y no realiza validaciones en el tiempo de carga de datos. En este caso, la estructura de los objetos de BBDD se define en tiempo de lectura, no hay una estructura de datos predeterminada, lo cual aporta flexibilidad. Según el tipo de datos que almacenemos puede ser mejor una u otra, si pensamos en ficheros planos estructurados tradicionales, nos iremos a "schema on-write", pero si trabajamos con datos no estructurados deberíamos pensar en "schema on-read". Es un ejemplo, hay muchas consideraciones más a tener en cuenta.
Lógicamente el "schema on-read" mejora el rendimiento del proceso de carga frente al "schema on-write", pero puede penalizar los tiempos del proceso de lectura.
Espero, esto te aclare algo.
Un saludo,
Juan
Muchas gracias, está muy
Subido por Carmen G. (no verificado) el 22 Abril, 2014 - 14:20
Muchas gracias, está muy clara la explicación y el post posterior.
Estimados, si bien el post es
Subido por IgnacioB (no verificado) el 14 Marzo, 2017 - 04:56
Estimados, si bien el post es viejo. Me viene bien para hacerles una pregunta. Que herramienta de BIG DATA puede reemplazar a un proceso de ETL grande hecho en SSIS. O que tecnologia en la nube lo puede reemplazar. Saludos. Ignacio
En mi opinión, siguiendo el
Subido por Carlos el 16 Marzo, 2017 - 00:25
En respuesta a Estimados, si bien el post es por IgnacioB (no verificado)
En mi opinión, siguiendo el planteamiento que se hace en el post, si las necesidades de rendimiento, cargas de datos más frecuentes y/o escalabilidad lo justifican, se podría transformar el proceso ETL en ELT con tecnologia Microsoft para Big Data utilizando el Parallel Data Warehouse de Azure.
Los datos podrían entrar por el Azure Blob Storage, que haría la misma función que podría hacer Hadoop en la entrada de datos, aplicar aquí ya algunas transformaciones, y después completar la carga ejecutando procedimientos almacenados y otros procesos de transformación orquestados por Azure Data Factory.
Lo malo es que el proceso de carga cambiaría tanto que del desarrollo de SSIS no podrías aprovechar casi nada, y otro inconveniente a tener en cuenta es que Azure Data Factory está muy limitado, al menos de momento, nada que ver con una herramienta de ETL tradicional, o con Integration Services.