
En este post vamos a realizar un ejemplo de segmentación de datos de clientes, empleando un proceso de clusterización, concretamente el procedimiento proc fastclus de SAS.

Este procedimiento realiza agrupamiento de datos basándonse en el algoritmo k-medias. Este algoritmo, es un método de agrupamiento, que tiene como objetivo la partición de un conjunto de n observaciones en k grupos en el que cada observación pertenece al grupo más cercano a la media.
En nuestro caso, tenemos una tabla de clientes con el consumo medio realizado por los clientes en los últimos tres meses. El consumo medio está entre 0 y 50 euros, y vamos a generar 5 grupos de clientes, entorno a 5 valores medios de consumo medio.
El algoritmo k-means es iterativo de forma que tenemos que indicar en el procedimiento el número máximo de iteraciones.
Utilizamos el procedimiento proc fastclus, indicamos el número de grupos a realizar en el parámetro maxc y el número máximo de iteraciones en maxiter. La tabla de entrada es clientes y la tabla de salida cluster_clientes, la variable que contiene el consumo medio en los últimos tres meses es arpu_m.
proc fastclus data=clientes maxc=5 maxiter=100 out=cluster_clientes replace=random;
var arpu_m;
run;
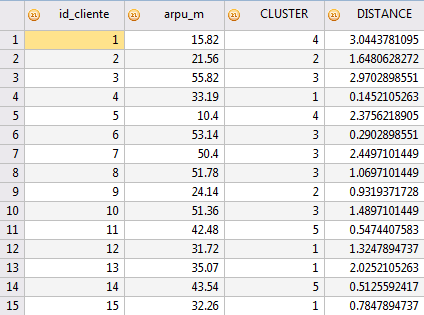
En la tabla de salida se crea un campo adicional (cluster) que indica el grupo en el que queda clasificado el cliente y la distancia al valor medio de ese grupo (distance).
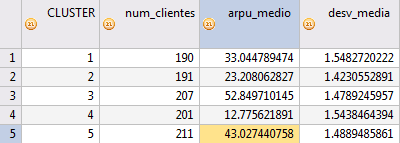
Como validación, hacemos un agregado que nos permite ver el valor medio y la desviación media en ese grupo.
proc sql;
create table res as
(select cluster, count(*) as num_clientes, avg(arpu_m) as arpu_medio, avg(distance) as desv_media
from cluster_clientes
group by cluster);
quit;
Vemos en la tabla resumen, los grupos generados, el número de clientes que cae en cada grupo, el valor medio y la desviación media.
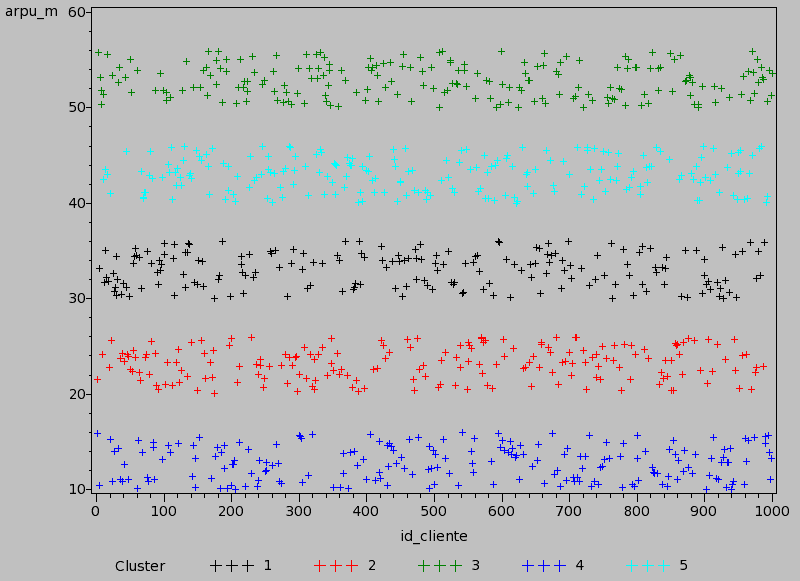
Mostrarmos una gráfica la distribución de los grupos:
proc gplot data=cluster_clientes;
plot arpu_m*id_cliente = cluster;
run;
Hay otros procedimientos de clusterización en SAS también basados en el algoritmo k-medias como: proc cluster.
Lógicamente se trata de un ejemplo sencillo, el proceso de clusterización se puede complicar mucho más, de entrada podemos hacer más grupos modificando el parámetro maxc ,podemos incluir más variables parámetro var en la agrupación y existen muchos otros parámetros (ejemplo inclusión de semillas) para modificar el proceso de clusterización.
