
Ejemplo 2. Segmentación de clientes (Analisis de cluster).
El analisis de clúster ofrece un método para agrupar valores de datos basado en similitudes dentro de estos. Esta técnica segmenta distintos elementos en grupos según el grado de asociación entre los elementos. El grado de asociación entre dos objetos es máximo si pertenecen al mismo grupo y mínimo si no pertenecen al mismo grupo. Se forma un número determinado o especificado de grupos, o clusteres, lo que permite clasificar matematicamente cada valor de los datos en el grupo adecuado.
El analisis de cluster se considera una técnica de aprendizaje sin guía debido a que no hay variable de destino o dependiente. Generalmente, hay características subyacentes (que habrá que descubrir) que determinan el motivo por el que determinadas cosas aparecen relacionadas y otras no lo estan. El análisis de cluster de elementos relacionados proporciona información significativa sobre cómo se relacionan entre sí los diversos elementos de un conjunto de datos.
Microstrategy emplea el algoritmo de promedio k para determinar los clusteres. Con esta técnica, los clústeres se definen por un centro en un espacio multidimensional. Las dimensiones de este espacio se determinan mediante las variables independientes que caracterizan cada elemento. Las variables continuas se normalizan en el rango de cero a uno (de modo que no haya una variable dominante). Las variables categóricas se reemplazan con una variable de indicador binario para cada categoría ( 1 = un elemento está en la categoria, 0 = un elemento no esta en la categoría). De esta manera, cada variable abarca un rango similar y representa una dimensión en este espacio.
El usuario especifica el número de clústeres, k y el algoritmo determina las coordinadas del centro de cada cluster. En Microstrategy, el usuario o el software de manera automática pueden determinar el número de agrupaciones que se generarán de un conjunto de datos. Si se determina mediante el software, el número de agrupaciones se basa en varias iteraciones para descubrir la agrupación óptima. El usuario establece un valor máximo para limitar el número de agrupaciones determinadas por el software.
La creación de un modelo de clústeres es el primer paso porque, aunque el algoritmo simpre generará los clústeres adecuados, el usuario debe comprender de qué manera difiere cada clúster de los demás. El analisis de cluster no genera ninguna conclusión en si mismo, y habrá que analizar los resultados para buscar esas relaciones ocultas entre los atributos que nos permitan determinan la segmentación, en este caso, de los clientes.
Vamos a ver un ejemplo de segmentación de clientes, en el que intentaremos formar grupos de forma que los miembros de cada uno de ellos se parezcan mas entre si que los miembros de los otros grupos. Vamos a crear cinco segmentos de clientes basandonos en criterios demográficos y psicográficos, que son:
- Rango de edades.
- Formación.
- Sexo.
- Tipo de vivienda.
- Estado civil.
La información reside en los datos de los clientes, y ha sido previamente elaborada para normalizarla según vemos en el informe siguiente (que es el informe de partida para el análisis):
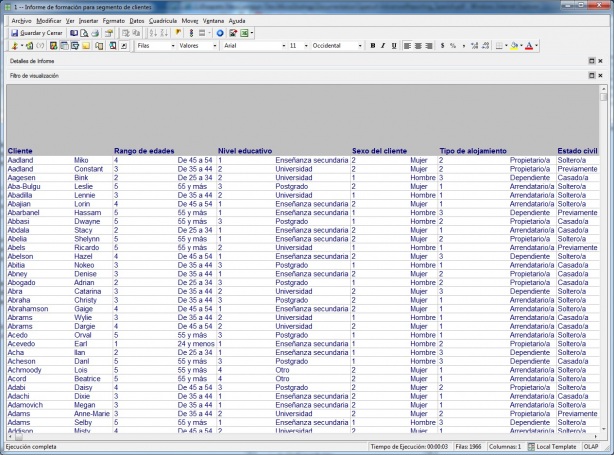
Informe de Datos de clientes
Podemos observar que la información de edades ha sido clasificada en rangos de edad, al igual que la información de Nivel Educativo (formación), Sexo del cliente, Tipo de alojamiento (vivienda) y estado civil. Los valores de estos atributos del cliente ha sido codificados (valor 1, 2, 3, etc). Esta información puede haber sido generado en los procesos de carga del DW o bien definida por indicadores calculados, o por grupos personalizados. Para analizar los clientes, realizaremos un muestro de ellos extrayendo un porcentaje del total de clientes (en nuestro caso, vamos a analizar un 20%).
Para realizar el muestro de datos nos vamos a crear un indicador para luego poder filtrarlo y extraer exactamente el 20% de los clientes. Como vemos en la imagen, con la función Randbetween, que devuelve un numero aleatorio entre dos valores dados, creamos un valor, que luego filtraremos en el informe de creación de los indicadores previsibles a través de un filtro.
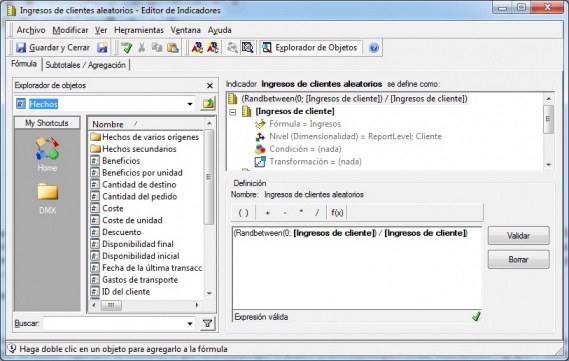
Cluster- Indicar de filtrado para muestreo
A continuación, al igual que en el ejemplo anterior, realizaremos la definición del indicador de formación. En este caso, selecciones el tipo de analisis Agrupación. Podremos realizar dos tipos de análisis. Indicar un número especifico de clusteres, lo que determinara que se analice la información para formar exactamente N grupos o bien la opción segunda, que es especificar un número máximo de clusters y un porcentaje de mejora. En este caso, el algoritmo crea dos clusteres y evaluará la calidad del modelo. A continuación, se crearán 3 clusteres y se comprobara si el modelo ha mejorado. Sino ha mejorado, nos quedamos con el modelo de 2 clusteres. Si mejora, se construira el de 4 clusters y se comparara con el de 3. El proceso continuará hasta que se alcance el número máximo de clusteres especificados o hasta que la mejora no supere el porcentaje indicado.
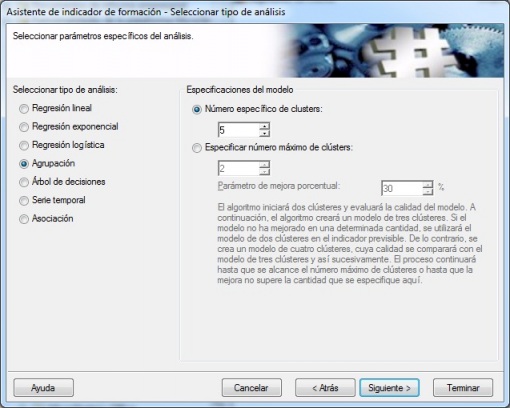
Indicador de formación en Analisis Cluster - Propiedades Análisis
En nuestro ejemplo, indicamos un número especifico de clusteres, en concreto 5.
A continuación, indicaremos los indicadores independientes que van a formar parte del modelo. Como ya indicamos, aunque estamos analizando atributos de los clientes, tendremos que crear indicadores para estos atributos, pues en el indicador de formación somo podemos incluir indicadores. Tendremos un indicador para cada atributo de los que queremos incluir en el análisis.
Finalmente, definiremos los indicadores previsibles que se generaran cuando ejecutemos un informe incluyendo el indicador de formación. Recordemos que en estos indicadores previsibles, cuando sean creados, podremos ver el modelo generado con el visor de Microstrategy. También podremos utilizarlos en informes para analizar los resultados de la segmentación y sacar conclusiones.
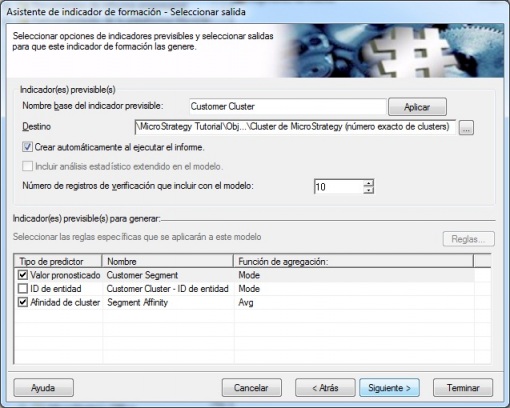
Analisis Cluster - Indicadores previsibles a generar con el modelo
El siguiente paso, una vez creado el indicador de formación, es incluirlo en un informe de Microstrategy junto con todos los atributos necesarios para el análisis. Ejecutaremos el informe, con el muestreo visto anteriormente (a traves de un filtro), y se generaran los indicadores previsibles que podremos analizar. A partir de los indicadores previsibles creados, con el visor de modelos, observamos los resultados del análisis:
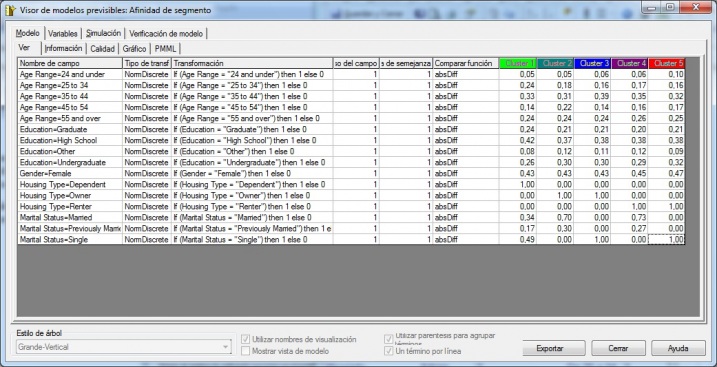
Analisis de Cluster - Visor de Modelo Previsible
Aparece una tabla con los diferentes valores de los atributos de los clientes (edades, nivel educativo, sexo, tipo de vivienda y estado civil) y con los valores de peso de cada valor de cada atributo para pertenecer a cada unos de los clusteres. Vemos que los valores mas determinantes para determinar si un cliente entra en un cluster u en otro es el tipo de vivienda. El factor edad, educación o sexo es menos relevante (tiene menos peso). Por ejemplo, en el cluster 1, el tipo de vivienda “Dependiente” es condición para formar el cluster 1. Igualmente para el cluster 5, es condición el tipo de vivienda “Alquiler” y el estado civil soltero. La tabla nos puede hacer una idea de las relaciones entre los valores de los atributos y la pertenencia a un cluster u a otro.
El modelo previsible tiene en la pestaña Simulación una herramienta para ir jugando con las diferentes variables y ver la relación entre ellas. También nos puede ayudar para el análisis crear un informe que incluya todos los atributos y el indicador previsible creado (que devuelve al ejecutar el informe el cluster al que pertenece un cliente). Con el analisis de los datos, filtrado, conteo, ordenación podremos seguramente también descubrir relaciones entre los datos).
En nuestro ejemplo hemos limitado los atributos de clientes que utilizamos para el analisis, pero en una situación real, podriamos ir cambiando los atributos utilizados en el analisis por otros (o eliminando atributos no relevantes), hasta conseguir un modelo que satisfaga nuestra perspectiva de análisis.
Una funcionalidad interesante de Microstrategy es crear un grupo personalizado utilizando el indicador previsible creado, y utilizar este grupo personalizado dentro de los informes. La creación de los grupos personalizados es tan sencilla como vemos en la imagen:
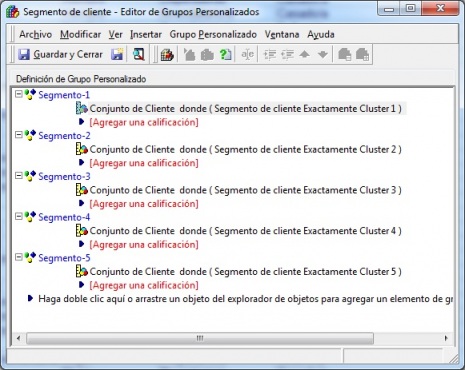
Grupos Personalizado utilizando el indicador previsible Segmento de cliente
Podemos incluir este objeto dentro de un informe para realizar analisis de las características de la segmentación o para analizar información de los clientes incluidos en cada grupo (por ejemplo, ventas, número de clientes, promedio por cliente). Esto nos puede ayudar a conocer mas características del grupo. Igualmente, podriamos realizar detalles y navegacion dentro de cada segmento por zona geográfica, tipo de material u otros aspectos que nos ayudaran a profundizar aun mas en características especificas de cada grupo.
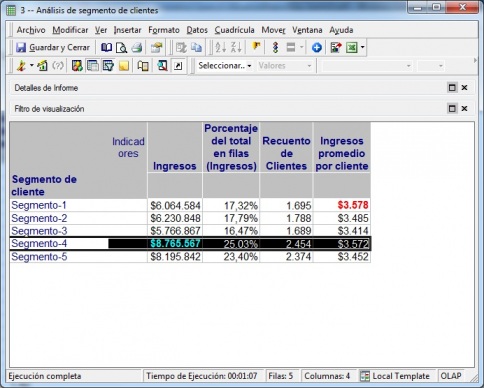
Analisis de Segmento de Clientes usango Grupos Personalizados
El modelo descrito se puede validar en otro conjunto de datos para darle un contenido definitivo y presentar los resultados del análisis de cara a establecer las correspondientes medidas dentro del area de ventas o marketing.
Ejemplo 3. Predicción de ventas en una campaña (Arbol de decisión).
En este analisis utilizaremos un arbol de decisión para determinar la respuesta de un determinado grupo de clientes a rebajas en determinados productos en la epoca de vuelta al colegio. Para ello, utilizaremos arboles de decisión del tipo binario (recordemos que los arboles de decisión se pueden utilizar tanto para clasificación como para analisis de regresión, como en este caso). Intentaremos determinar como influyen factores como la edad, el sexo o el numero de hijos en la probabilidad de realizar compras en esa campaña de rebajas.
Los arboles de decisión son uno de los modelos de mineria de datos mas intuitivos, debido a que muestran una estructura “si-entonces-otro”, facil de comprender. Los arboles de decisión separan un conjunto de datos en distintos subconjuntos de datos. En lugar de utilizar un enfoque de aprendizaje sin guia (como en el análisis cluster), el arbol de decisión utiliza un algoritmo guiado, de forma que los subconjuntos de datos creados comparten una característica de destino determinada, que proporciona una variable dependiente. Las demas características las proporcionan las variables independientes, que se utilizan para dividir los conjuntos de datos originales en subconjuntos de datos. Normalmente, se utiliza la variable independiente con mayor poder previsible y asi sucesivamente. Microstrategy implementa el algoritmo de árbol de clasificación y regresión (CART).
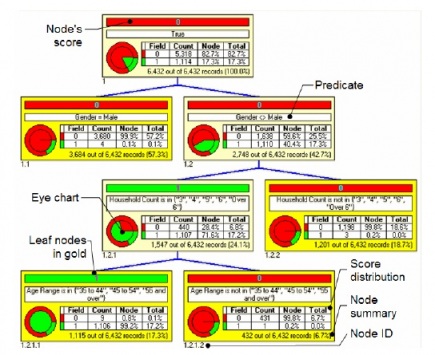
Ejemplo de arbol de decision en Microstrategy
Cada nodo incluye la información siguiente:
- Puntuación (node´s score): el resultado más común (o dominante) de los registros de datos para el nodo.
- Predicado (predicate): una sentencia lógica que se usa para separar registros de datos del origen de un noto. Los registros pertenecen a un nodo si se evalua como verdadero (pueden incluir una o varias sentencias lógicas combinadas con los operadores AND, OR, XOR, etc).
- Gráfico de ojo (eye chart): representación gráfica de la distribución de puntuaciones.
- Distribución de puntuaciones (score distribution): tabla que muestra el desglose de registros de datos de formación asociados con el nodo. Sirve de leyenda para el gráfico de ojo. La distribución de puntuaciones contiene el conteo real de los registros de datos de formacion del nodo que se representa mediante cada clase de destino. La proporción de cada clase de registros de datos se muestra como porcentaje de los conteos totales de este nodo y como porcentaje de la población total.
- Resumen de nodo (node summary): porcentaje de todos los registros de datos de formación asociados con el nodo.
- ID de nodo (node id): identificador unico o referencia para cada nodo. Se usa un formato de profundidad en nivel (el id es una serie de numeros ).
Vamos a realizar un analisis de una campaña utilizando un arbol de decision. Como indicador dependiente utilizaremos el indicador “Respuesta a Rebajas vuelta al cole año X”. Como indicadores independientes, los valores sociodemográficos del cliente como rango de edades, número de mienbros de la familia, sexo o educación. Con estos valores, construiremos, de la forma habitual (e igual que en el resto de ejemplos), el indicador de formación, seleccionando el tipo de análisis Arbol de decisión:
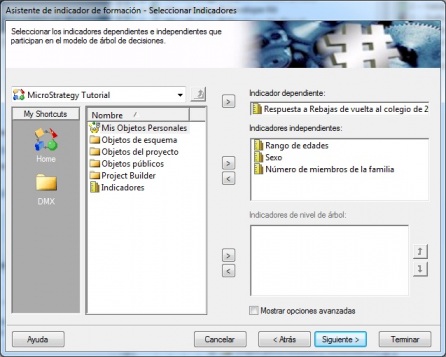
Arbol Decision - Indicador Formacion
El indicador dependiente, cuya definición vemos en la imagen siguiente, es un numero cuyo valor indica un uno si una compra del cliente en el año X fue dentro de la campaña de rebajas y un 0 sino lo fue. Este va a ser el indicador dependiente dentro de nuestro modelo, y el resto los independientes.
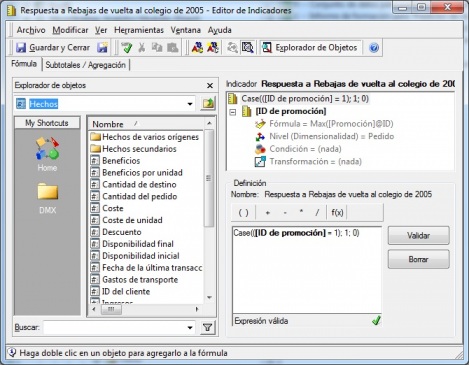
Arbol Decision - Indicador Dependiente
El siguiente paso, como en los ejemplos anteriores, es definir un informe de Microstrategy e incluir el indicador de formación para generar los indicadores previsibles en cuyo contenido podremos analizar los resultados del modelo con el visor de modelos previsibles. En nuestro ejemplo, construimos un informe que lee los datos de pedidos de un periodo de tiempo determinado, incluyendo la información del cliente y el indicador de formación (tal y como vemos en la imagen).
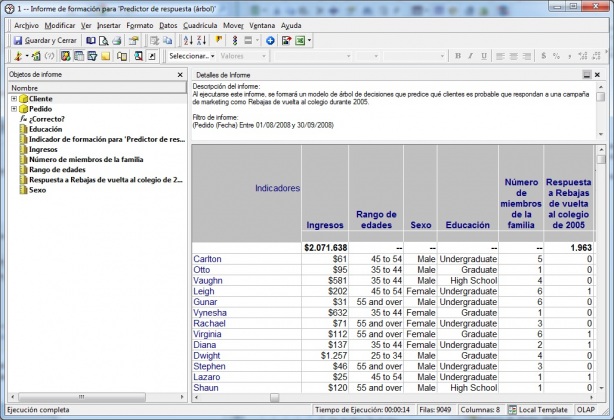
Arbol Decision - Informe creación modelo
Ejecutaremos el informe y se realizará la creación de los indicadores previsibles, donde podremos validar el modelo creado. Podremos ir jugando con las variables dependientes que incluimos en el modelo hasta dar con un arbol de decisión acorde con el objetivo de nuestro análisis. En nuestro caso, hemos obtenido el siguiente árbol de decisión:
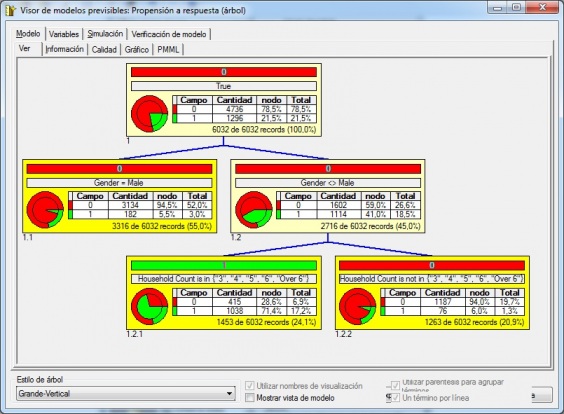
Arbol Decision - Resultados Ejemplo
Podemos observar los resultados del arbol. El sexo es una factor determinante para participar en la campaña (Gender <> Male). Los hombres no han comprado utilizando la rebaja en el 94,5% de los casos. Para las mujeres, si han comprado en el 41% de los casos. Ademas, para mujeres en familias numerosas (3, 4, 5, 6 hijos o mas), se utilizo la promoción en el 71,4% de los casos.
Una vez ajustado el modelo previsible, podremos realizar un analisis de previsión de ingresos de la campaña utilizando en informes (en forma de tabla o gráficos) los indicadores previsibles creados. Podremos de estar manera hacer una predicción de respuesta haciendo simulaciones con los datos de ventas anteriores, con estimaciónes según la predicción de respuesta o ver de forma gráfica el aumento de predictor de respuesta.
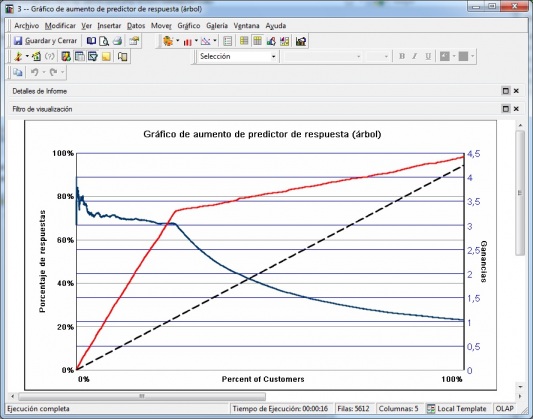
Arbol Decision - Grafico Aumento Respuesta
Los analisis nos permitiran realizar un analisis de los resultados de la campaña en un escenario basado en la respuesta prevista de un cliente a una campaña.
Conclusiones.
He intentado en estos ejemplos entender y transmitiros los conceptos básicos, la metodologia de aplicación y algunas técnicas de las que se utilizan en datamining con ejemplos prácticos que hacen mas fácil su comprensión. Como desconocedor del datamining y sus técnicas, siempre encontraba la carencia de no encontrar ejemplos prácticos que me hiciesen entender un poco mas a fondo y sin un enfoque técnico o estadístico, como es su aplicación, como se desarrollan las técnicas y como se sacan conclusiones de los resultados obtenidos. Espero haber conseguido con esta serie de ejemplos este objetivo.
Por otro lado, a nivel de Microstrategy 9, he constatado algunas ventajas e incovenientes, que os enumero:
Ventajas
- Total integración de los servicios de Data Mining con la plataforma. Se utilizan informes para generar los modelos predictivos a traves de los indicadores de formación. Los resultados obtenidos se analizan y ajustan con el visor de modelos y se pueden validar y explotar las conclusiones utilizando los indicadores previsibles como un elemento mas de los informes (o como parte de otros objetos, como filtros, grupos personalizados, nuevos indicadores, etc). Esto ultimo nos da gran potencia para realizar simulaciones o analisis de posibles resultados siempre trabajando en el entorno de nuestro DW o de los subconjutos de datos extraidos y preparados para el análisis (a través de la creación, por ejemplo, de los Datamarts).
- El uso del estandar XML para exportacion/importación de modelos (PMML), nos permite tanto exportar desde Microstrategy los analisis a otras herramientas de data mining que soporten el estandar para utilizar los modelos en ellas, o bien importar en nuestro sistema modelos desarrollados en otras herramientas (y poder validar los resultados de los análisis, pues al importar los modelos también creamos los indicadores previsibles, que podremos incluir en los informes para verificar resultados o previsiones).
Inconvenientes
- Microstrategy no es una herramienta especifica de Data Mining. Tiene limitaciones respecto al tipo de analisis que se pueden realizar y no es una herramienta diseñada especificamente para dicho proposito, con lo que en muchos aspectos no podrá competir con herramientas especificas.
