El lenguaje SQL
El lenguaje SQL Carlos 15 Junio, 2009 - 23:17Introducción
El SQL es el lenguaje estándar ANSI/ISO de definición, manipulación y control de bases de datos relacionales. Es un lenguaje declarativo: sólo hay que indicar qué se quiere hacer. En cambio, en los lenguajes procedimentales es necesario especificar cómo hay que hacer cualquier acción sobre la base de datos. El SQL es un lenguaje muy parecido al lenguaje natural; concretamente, se parece al inglés, y es muy expresivo. Por estas razones, y como lenguaje estándar, el SQL es un lenguaje con el que se puede acceder a todos los sistemas relacionales comerciales.
Empezamos con una breve explicación de la forma en que el SQL ha llegado a ser el lenguaje estándar de las bases de datos relacionales:
1) Al principio de los años setenta, los laboratorios de investigación Santa Teresa de IBM empezaron a trabajar en el proyecto System R. El objetivo de este proyecto era implementar un prototipo de SGBD relacional; por lo tanto, también necesitaban investigar en el campo de los lenguajes de bases de datos relacionales. A mediados de los años setenta, el proyecto de IBM dio como resultado un primer lenguaje denominado SEQUEL (Structured English Query Language), que por razones legales se denominó más adelante SQL (Structured Query Language). Al final de la década de los setenta y al principio de la de los ochenta, una vez finalizado el proyecto System R, IBM y otras empresas empezaron a utilizar el SQL en sus SGBD relacionales, con lo que este lenguaje adquirió una gran popularidad.
2) En 1982, ANSI (American National Standards Institute) encargó a uno de sus comités (X3H2) la definición de un lenguaje de bases de datos relacionales. Este comité, después de evaluar diferentes lenguajes, y ante la aceptación comercial del SQL, eligió un lenguaje estándar que estaba basado en éste prácticamente en su totalidad. El SQL se convirtió oficialmente en el lenguaje estándar de ANSI en el año 1986, y de ISO (International Standards Organization) en 1987. También ha sido adoptado como lenguaje estándar por FIPS (Federal Information Processing Standard), Unix X/Open y SAA (Systems Application Architecture) de IBM.
3) En el año 1989, el estándar fue objeto de una revisión y una ampliación que dieron lugar al lenguaje que se conoce con el nombre de SQL1 o SQL89. En el año 1992 el estándar volvió a ser revisado y ampliado considerablemente para cubrir carencias de la versión anterior. Esta nueva versión del SQL, que se conoce con el nombre de SQL2 o SQL92, es la que nosotros presentaremos en esta unidad didáctica.
Como veremos más adelante, aunque aparezca sólo la sigla SQL, siempre nos estaremos refiriendo al SQL92, ya que éste tiene como subconjunto el SQL89; por lo tanto, todo lo que era válido en el caso del SQL89 lo continuará siendo en el SQL92.
De hecho, se pueden distinguir tres niveles dentro del SQL92:
1) El nivel introductorio (entry), que incluye el SQL89 y las definiciones de clave primaria y clave foránea al crear una tabla.
2) El nivel intermedio (intermediate), que, además del SQL89, añade algunas ampliaciones del SQL92.
3) El nivel completo (full), que ya tiene todas las ampliaciones del SQL92.
El modelo relacional tiene como estructura de almacenamiento de los datos las relaciones. La intensión o esquema de una relación consiste en el nombre que hemos dado a la relación y un conjunto de atributos. La extensión de una relación es un conjunto de tuplas. Al trabajar con SQL, esta nomenclatura cambia, como podemos apreciar en la siguiente figura:
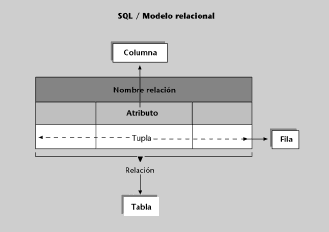
• Hablaremos de tablas en lugar de relaciones.
• Hablaremos de columnas en lugar de atributos.
• Hablaremos de filas en lugar de tuplas.
Sin embargo, a pesar de que la nomenclatura utilizada sea diferente, los conceptos son los mismos.
Con el SQL se puede definir, manipular y controlar una base de datos relacional. A continuación veremos, aunque sólo en un nivel introductorio, cómo se pueden realizar estas acciones:
El concepto de clave primaria y su importancia en una relación o tabla se ha visto en la unidad “El modelo relacional y el álgebra relacional” de este curso.
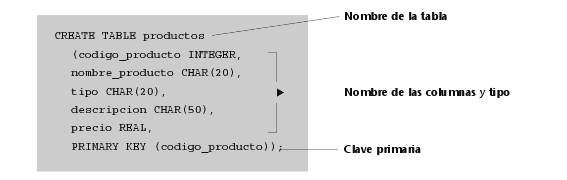
1) Sería necesario crear una tabla que contuviese los datos de los productos de nuestra empresa:
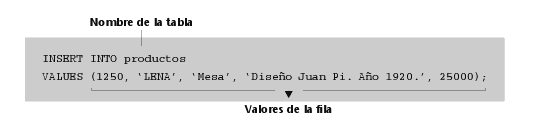
2) Insertar un producto en la tabla creada anteriormente:
3) Consultar qué productos de nuestra empresa son sillas:
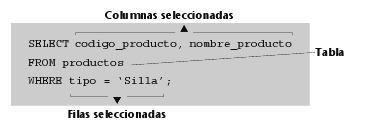
4) Dejar acceder a uno de nuestros vendedores a la información de la tabla productos:
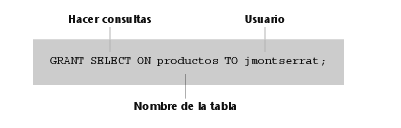
Y muchas más cosas que iremos viendo punto por punto en los siguientes apartados.
Fijémonos en la estructura de todo lo que hemos hecho hasta ahora con SQL. Las operaciones de SQL reciben el nombre de sentencias y están formadas por diferentes partes que denominamos cláusulas, tal y como podemos apreciar en el siguiente ejemplo:

Esta consulta muestra el código, el nombre y el tipo de los productos que cuestan más de 1.000 euros.
Los tres primeros apartados de este módulo tratan sobre un tipo de SQL denominado SQL interactivo, que permite acceder directamente a una base de datos relacional:
a) En el primer apartado definiremos las denominadas sentencias de definición, donde crearemos la base de datos, las tablas que la compondrán y los dominios, las aserciones y las vistas que queramos.
b) En el segundo aprenderemos a manipular la base de datos, ya sea introduciendo, modificando o borrando valores en las filas de las tablas, o bien haciendo consultas.
c) En el tercero veremos las sentencias de control, que aseguran un buen uso de la base de datos.
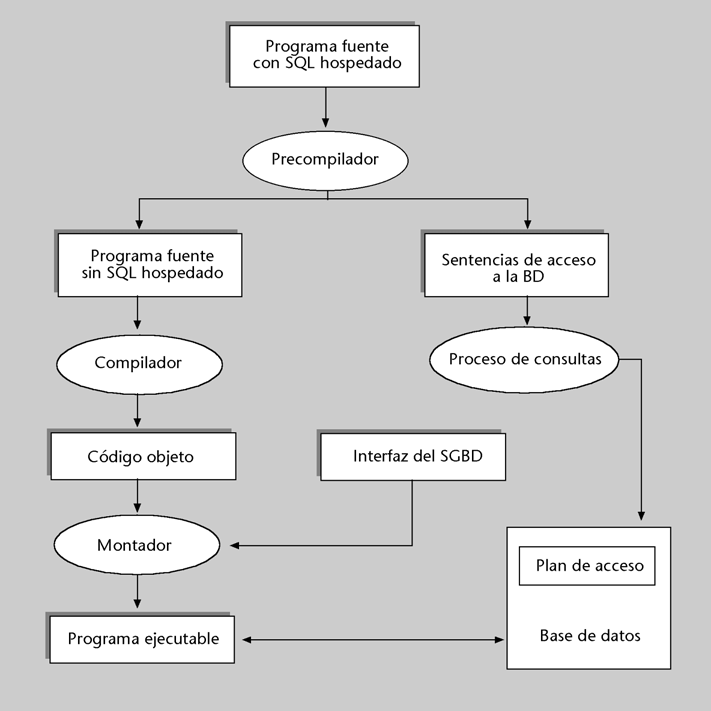
Sin embargo, muchas veces querremos acceder a la base de datos desde una aplicación hecha en un lenguaje de programación cualquiera, que nos ofrece mucha más potencia fuera del entorno de las bases de datos. Para utilizar SQL desde un lenguaje de programación necesitaremos sentencias especiales que nos permitan distinguir entre las instrucciones del lenguaje de programación y las sentencias de SQL. La idea es que trabajando básicamente con un lenguaje de programación anfitrión se puede cobijar SQL como si fuese un huésped. Por este motivo, este tipo de SQL se conoce con el nombre de SQL hospedado. Para trabajar con SQL hospedado necesitamos un precompilador que separe las sentencias del lenguaje de programación de las del lenguaje de bases de datos. Una alternativa a esta forma de trabajar son las rutinas SQL/CLI* (SQL/Call-Level Interface), que resolviendo también el problema de acceder a SQL desde un lenguaje de programación, no necesitan precompilador.
Antes de empezar a conocer el lenguaje, es necesario añadir un último comentario. Aunque SQL es el lenguaje estándar para bases de datos relacionales y ha sido ampliamente aceptado por los sistemas relacionales comerciales, no ha sido capaz de reflejar toda la teoría del modelo relacional establecida por E.F. Codd; esto lo iremos viendo a medida que profundicemos en el lenguaje.
Los sistemas relacionales comerciales y los investigadores de bases de datos son una referencia muy importante para mantener el estándar actualizado. En estos momentos ya se dispone de una nueva versión de SQL92 que se denomina SQL: 1999 o SQL3. SQL: 1999 tiene a SQL92 como subconjunto, e incorpora nuevas prestaciones de gran interés. En informática, en general, y particularmente en bases de datos, es necesario estar siempre al día, y por eso es muy importante tener el hábito de leer publicaciones periódicas que nos informen y nos mantengan al corriente de las novedades.
Objetivos
Una vez finalizado el estudio de los materiales didácticos de esta unidad, dispondréis de las herramientas indispensables para alcanzar los siguientes objetivos:
1. Conocer el lenguaje estándar ANSI/ISO SQL92.
2. Definir una base de datos relacional, incluyendo dominios, aserciones y vistas.
3. Saber introducir, borrar y modificar datos.
4. Ser capaz de plantear cualquier tipo de consulta a la base de datos.
5. Saber utilizar sentencias de control.
6. Conocer los principios básicos de la utilización del SQL desde un lenguaje de programación.
1. Sentencias de definicion
1. Sentencias de definicion Dataprix 22 Septiembre, 2009 - 10:42Para poder trabajar con bases de datos relacionales, lo primero que tenemos que hacer es definirlas. Veremos las órdenes del estándar SQL92 para crear y borrar una base de datos relacional y para insertar, borrar y modificar las diferentes tablas que la componen.
| Vistas |
| Una vista en el modelo relacional no es si no una tabla virtual derivada de las tablas reales de nuestra base de datos, un esquema externo puede ser un conjunto de vistas. |
En este apartado también veremos cómo se definen los dominios, las aserciones (restricciones) y las vistas.
La sencillez y la homogeneidad del SQL92 hacen que:
1) Para crear bases de datos, tablas, dominios, aserciones y vistas se utilice la sentencia CREATE.
2) Para modificar tablas y dominios se utilice la sentencia ALTER.
3) Para borrar bases de datos, tablas, dominios, aserciones y vistas se utilice la sentencia DROP.
La adecuación de estas sentencias a cada caso nos dará diferencias que iremos perfilando al hacer la descripción individual de cada una.
Para ilustrar la aplicación de las sentencias de SQL que veremos, utilizaremos una base de datos de ejemplo muy sencilla de una pequeña empresa con sede en Barcelona, Girona, Lleida y Tarragona, que se encarga de desarrollar proyectos informáticos. La información que nos interesará almacenar de esta empresa, que denominaremos BDUOC, será la siguiente:
1) Sobre los empleados que trabajan en la empresa, querremos saber su código de empleado, el nombre y apellido, el sueldo, el nombre y la ciudad de su departamento y el número de proyecto al que están asignados.
2) Sobre los diferentes departamentos en los que está estructurada la empresa, nos interesa conocer su nombre, la ciudad donde se encuentran y el teléfono. Será necesario tener en cuenta que un departamento con el mismo nombre puede estar en ciudades diferentes, y que en una misma ciudad puede haber departamentos con nombres diferentes.
3) Sobre los proyectos informáticos que se desarrollan, querremos saber su código, el nombre, el precio, la fecha de inicio, la fecha prevista de finalización, la fecha real de finalización y el código de cliente para quien se desarrolla.
4) Sobre los clientes para quien trabaja la empresa, querremos saber el código de cliente, el nombre, el NIF, la dirección, la ciudad y el teléfono.
1.1. Creacion y borrador de una base de datos relacional
1.1. Creacion y borrador de una base de datos relacional Dataprix 22 Septiembre, 2009 - 10:55El estándar SQL92 no dispone de ninguna sentencia de creación de bases de datos. La idea es que una base de datos no es más que un conjunto de tablas y, por lo tanto, las sentencias que nos ofrece el SQL92 se concentran en la creación, la modificación y el borrado de estas tablas.
|
La instrucción |
|
Muchos de los sistemas relacionales comerciales (como ocurre en el caso de informix, DB2, SQL Server y otros) han incorporado sentencias de creación de base de datos con la siguiente sintanxis: |
En cambio, disponemos de una sentencia más potente que la de creación de bases de datos: la sentencia de creación de esquemas denominada CREATE SCHEMA. Con la creación de esquemas podemos agrupar un conjunto de elementos de la base de datos que son propiedad de un usuario. La sintaxis de esta sentencia es la que tenéis a continuación:

La nomenclatura utilizada en la sentencia es la siguiente:
• Las palabras en negrita son palabras reservadas del lenguaje:
• La notación [...] quiere decir que lo que hay entre los corchetes se podría poner o no.
• La notación {A| ... |B} quiere decir que tenemos que elegir entre todas las opciones que hay entre las llaves, pero debemos poner una obligatoriamente.
La sentencia de creación de esquemas hace que varias tablas (lista_de_ele- mentos_del_esquema) se puedan agrupar bajo un mismo nombre (nom- bre_esquema) y que tengan un propietario (usuario). Aunque todos los parámetros de la sentencia CREATE SCHEMA son opcionales, como mínimo se debe dar o bien el nombre del esquema, o bien el nombre del usuario propietario de la base de datos. Si sólo especificamos el usuario, éste será el nombre del esquema.
La creación de esquemas puede hacer mucho más que agrupar tablas, porque lista_de_elementos_del_esquema puede, además de tablas, ser también dominios, vistas, privilegios y restricciones, entre otras cosas.
| La sentencia DROPDATABASE |
| Muchos de los sistemas relacionales comerciales (como ocurre en el caso de informix, DB2, SQL Server y otros) han incorporado sentencias de borrado de base de datos con la siguiente sintanxis: DROPDATABASE |
Para borrar una base de datos encontramos el mismo problema que para crearla. El estándar SQL92 sólo nos ofrece la sentencia de borrado de esquemas DROP SCHEMA, que presenta la siguiente sintaxis:

Donde tenemos lo siguiente:
• La opción de borrado de esquemas RESTRICT hace que el esquema sólo se pueda borrar si no contiene ningún elemento.
• La opción CASCADE borra el esquema aunque no esté completamente vacío.
1.2. Creacion de tablas
1.2. Creacion de tablas Dataprix 22 Septiembre, 2009 - 10:57Como ya hemos visto, la estructura de almacenamiento de los datos del modelo relacional son las tablas. Para crear una tabla, es necesario utilizar la sentencia CREATE TABLE. Veamos su formato:

Donde definición_columna es:

El proceso que hay que seguir para crear una tabla es el siguiente:
1) Lo primero que tenemos que hacer es decidir qué nombre queremos poner a la tabla (nombre_tabla).
2) Después, iremos dando el nombre de cada uno de los atributos que formarán las columnas de la tabla (nombre_columna).
3) A cada una de las columnas le asignaremos un tipo de datos predefinido o bien un dominio definido por el usuario. También podremos dar definiciones por defecto y restricciones de columna.
4) Una vez definidas las columnas, sólo nos quedará dar las restricciones de tabla.
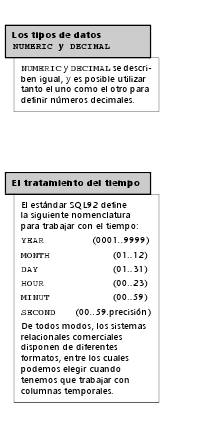
1.2.1. Tipos de datos
1.2.1. Tipos de datos Dataprix 22 Septiembre, 2009 - 11:45Para cada columna tenemos que elegir entre algún dominio definido por el usuario o alguno de los tipos de datos predefinidos que se describen a continuación:

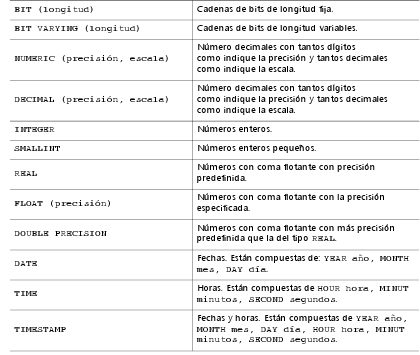
Ejemplos de asignaciones de columnas
Veamos algunos ejemplos de asignaciones de columnas en los tipos de datos predefinidos DATE, TIME y TIMESTAMP:
• La columna fecha_nacimiento podría ser del tipo DATE y podría tener como valor ‘1978-12-25’.
• La columna inicio_partido podría ser del tipo TIME y podría tener como valor ‘17:15:00.000000’.
• La columna entrada_trabajo podría ser de tipo TIMESTAMP y podría tener como valor ‘1998-7-8 9:30:05’.
1.2.2. Creacion, modificacion y borrado de dominios
1.2.2. Creacion, modificacion y borrado de dominios Dataprix 22 Septiembre, 2009 - 12:07| Dominios definidos por el usuario |
| Aunque el SQL92 nos ofrece la sentencia CREATE DOMAIN, hay pocos sistemas relacionales comerciales que nos permitan utilizarla. |
Además de los dominios dados por el tipo de datos predefinidos, el SQL92 nos ofrece la posibilidad de trabajar con dominios definidos por el usuario.
Para crear un dominio es necesario utilizar la sentencia CREATE DOMAIN:
CREATE DOMAIN nombre dominio [AS] tipos_datos
[def_defecto] [restricciones_dominio];
donde restricciones_dominio tiene el siguiente formato:
[CONSTRAINT nombre_restricción] CHECK (condiciones)
Creación de un dominio en BDUOC
Si quisiéramos definir un dominio para las ciudades donde se encuentran los departamentos de la empresa BDUOC, haríamos:
CREATE DOMAIN dom_ciudades AS CHAR (20)
CONSTRAINT ciudades_validas
CHECK (VALUE IN (‘Barcelona’, ‘Tarragona’, ‘Lleida’, ‘Girona’));De este modo, cuando definimos la columna ciudades dentro de la tabla departamentos no se tendrá que decir que es de tipo CHAR (20), sino de tipo dom_ciudades. Esto nos debería asegurar, según el modelo relacional, que sólo haremos operaciones sobre la columna ciudades con otras columnas que tengan este mismo dominio definido por el usuario; sin embargo, el SQL92 no nos ofrece herramientas para asegurar que las comparaciones que hacemos sean entre los mismos dominios definidos por el usuario.
Por ejemplo, si tenemos una columna con los nombres de los empleados definida sobre el tipo de datos CHAR (20), el SQL nos permite compararla con la columna ciudades, aunque semánticamente no tenga sentido. En cambio, según el modelo relacional, esta comparación no se debería haber permitido.
Para borrar un dominio definido por el usuario es preciso utilizar la sentencia DROP DOMAIN, que tiene este formato:
DROP DOMAIN nombre_dominio {RESTRICT|CASCADE};
En este caso, tenemos que:
• La opción de borrado de dominios RESTRICT hace que el dominio sólo se pueda borrar si no se utiliza en ningún sitio.
• La opción CASCADE borra el dominio aunque esté referenciado, y pone el tipo de datos del dominio allí donde se utilizaba.
Borrar un dominio de BDUOC
Si quisiéramos borrar el dominio que hemos creado antes para las ciudades donde se encuentran los departamentos de la empresa BDUOC, haríamos:
DROP DOMAIN dom_ciudades RESTRICT;
En este caso nos deberíamos asegurar de que ninguna columna está definida sobre dom_ciudades antes de borrar el dominio.
Para modificar un dominio semántico es necesario utilizar la sentencia ALTER DOMAIN. Veamos su formato:
ALTER DOMAIN nombre_dominio {acción_modificar_dominio|
acción_modif_restricción_dominio};
Donde tenemos lo siguiente:
• acción_modificar_dominio puede ser:
{SET def_defecto|DROP DEFAULT}
• acción_modif_restricción_dominio puede ser:
{ADD restricciones_dominio|DROP CONSTRAINT nombre_restricción}
Modificar un dominio en BDUOC
Si quisiéramos añadir una nueva ciudad (Mataró) al dominio que hemos creado antes para las ciudades donde se encuentran los departamentos de la empresa BDUOC, haríamos:
ALTER DOMAIN dom_ciudades DROP CONSTRAINT ciudades_validas;
Con esto hemos eliminado la restricción de dominio antigua. Y ahora tenemos que introducir la nueva restricción:
ALTER_DOMAIN dom_ciudades ADD CONSTRAINT ciudades_validas
CHECK (VALUE IN (‘Barcelona’, ‘Tarragona’, ‘Lleida’, ‘Girona’, ‘Mataro’));1.2.3. Definiciones por defecto
1.2.3. Definiciones por defecto Dataprix 22 Septiembre, 2009 - 12:15Ya hemos visto en otros módulos la importancia de los valores nulos y su inevitable aparición como valores de las bases de datos.
La opción def_defecto nos permite especificar qué nomenclatura queremos dar a nuestros valores por omisión.
Por ejemplo, para un empleado que todavía no se ha decidido cuánto ganará, podemos elegir que, de momento, tenga un sueldo de 0 euros (DEFAULT 0.0), o bien que tenga un sueldo con un valor nulo (DEFAULT NULL).
Sin embargo, hay que tener en cuenta que si elegimos la opción DEFAULT NULL, la columna para la que daremos la definición por defecto de valor nulo debería admitir valores nulos.
La opción DEFAULT tiene el siguiente formato:
DEFAULT (literal|función|NULL)
La posibilidad más utilizada y la opción por defecto, si no especificamos nada, es la palabra reservada NULL. Sin embargo, también podemos definir nuestro propio literal, o bien recurrir a una de las funciones que aparecen en la tabla siguiente:
| Finción | Descripción |
| {USER CURRENT_USER} | Identificador del usuario actual |
| SESSION_USER | Identificador del usuario de esta sesión |
| SYSTEM_USER | Identificador del usuario del sistema operativo |
| CURRENT_DATE | Fecha actual |
| CURRENT_TIME | Hora actual |
| CURRENT_TIMESTAMP | Fecha y hora actuales |
1.2.4. Restricciones de columna
1.2.4. Restricciones de columna Dataprix 22 Septiembre, 2009 - 12:16En cada una de las columnas de la tabla, una vez les hemos dado un nombre y hemos definido su dominio, podemos imponer ciertas restricciones que siempre se tendrán que cumplir. Las restricciones que se pueden dar son las que aparecen en la tabla que tenemos a continuación:
| Restricción | Descripción |
| NOT NULL | La columna no puede tener valores nulos. |
| UNIQUE | La columna no puede tener valores repetidos. Es una clave alternativa. |
| PRIMARY KEY | La columna no puede tener valores repetidos ni nulos. Es la clave primaria. |
| REFERENCES tabla [ (columna) ] | La columna es la clave foránea de la columna de la tabla especificada. |
| CHECK (condiciones) | La columna debe cumplir las condiciones especificas. |
1.2.5. Restricciones de tabla
1.2.5. Restricciones de tabla Dataprix 23 Septiembre, 2009 - 11:47Una vez hemos dado un nombre, hemos definido una tabla y hemos impuesto ciertas restricciones para cada una de las columnas, podemos aplicar restricciones sobre toda la tabla, que siempre se deberán cumplir. Las restricciones que
se pueden dar son las siguientes:
| Restricción | Descripción |
| UNIQUE (columna [, columna...]) |
El conjunto de las columnas especificadas no puede tener valores repetidos. Es una clave alternativa |
| PRIMARY KEY (columna [, columna...]) |
El conjunto de las columnas espacificadas no puede tener valores nulos ni repetidos. Es una clave primaria |
| FOREIGN KEY (columna [, columna...]) REFERENCES tabla [(columna2 [, columna2...])] |
El conjunto de las columnas especificadas es una clave foránea que referencia la clave primaria formada por el conjunto de las columnas2 se denominan exactamente igual, entonces no sería necesario poner columnas2. |
| CHECK (condiciones) | La tabla debe cumplir las condiciones especificadas. |
1.2.6. Modificacion y borrado de claves con claves foráneas que hacen referncia a éstas
1.2.6. Modificacion y borrado de claves con claves foráneas que hacen referncia a éstas Dataprix 23 Septiembre, 2009 - 11:50En otra unidad de este curso hemos visto tres políticas aplicables a los casos de borrado y modificación de filas que tienen una clave primaria referenciada por claves foráneas. Estas políticas eran la restricción, la actualización en cascada y la anulación.
El SQL nos ofrece la posibilidad de especificar, al definir una clave foránea, qué política queremos seguir. Veamos su formato:
CREATE TABLE nombre_tabla
( definición_columna
[, definición_columna. . .]
[, restricciones_tabla]
);
Donde una de las restricciones de tabla era la definición de claves foráneas, que tiene el siguiente formato:
FOREIGN KEY clave_secundaria REFERENCES tabla [(clave_primaria)]
[ON DELETE {NO ACTION | CASCADE | SET DEFAULT | SET NULL}]
[ON UPDATE {NO ACTION | CASCADE | SET DEFAULT | SET NULL}]Donde NO ACTION corresponde a la política de restricción; CASCADE, a la actualización en cascada, y SET NULL sería la anulación. SET DEFAULT se podría considerar una variante de SET NULL, donde en lugar de valores nulos se puede poner
el valor especificado por defecto.
1.2.7. Aserciones
1.2.7. Aserciones Dataprix 23 Septiembre, 2009 - 11:52Una aserción es una restricción general que hace referencia a una o más columnas de más de una tabla. Para definir una aserción se utiliza la sentencia CREATE ASSERTION, y tiene el siguiente formato:
CREATE ASSERTION nombre_aserción CHECK (condiciones);
Crear una aserción en BDUOC
Creamos una aserción sobre la base de datos BDUOC que nos asegure que no hay ningún empleado con un sueldo superior a 80.000 asignado al proyecto SALSA:
CREATE ASSERTION restriccion1 CHECK (NOT EXISTS (SELECT *
FROM proyectos p, empleados e
WHERE p.codigo_proyec =
= e.num_proyec and e.sueldo > 8.0E+4
and p.nom_proj = ‘SALSA’) );Para borrar una aserción es necesario utilizar la sentencia DROP ASSERTION, que presenta este formato:
DROP ASSERTION nombre_aserción;
Borrar una aserción en BDUOC
Por ejemplo, para borrar la aserción restriccion1, utilizaríamos la sentencia DROP ASSERTION de la forma siguiente:
DROP ASSERTION restriccion1;1.3. Modificacion y borrado de tablas
1.3. Modificacion y borrado de tablas Dataprix 23 Septiembre, 2009 - 11:53Para modificar una tabla es preciso utilizar la sentencia ALTER TABLE. Veamos su formato:
ALTER TABLE nombre_tabla {acción_modificar_columna|
acción_modif_restricción_tabla};En este caso, tenemos que:
• acción_modificar_columna puede ser:
{ADD [COLUMN] columna def_columna |
ALTER [COLUMN] columna {SET def_defecto|DROP DEFAULT}|
DROP [COLUMN ] columna {RESTRICT|CASCADE}}
• acción_modif_restricción_tabla puede ser:
{ADD restricción|
DROP CONSTRAINT restricción {RESTRICT|CASCADE}}Si queremos modificar una tabla es que queremos realizar una de las siguientes
operaciones:
1) Añadirle una columna (ADD columna).
2) Modificar las definiciones por defecto de la columna (ALTER columna).
3) Borrar la columna (DROP columna).
4) Añadir alguna nueva restricción de tabla (ADD restricción).
5) Borrar alguna restricción de tabla (DROPCONSTRAINT restricción). Para borrar una tabla es preciso utilizar la sentencia DROP TABLE:
DROP TABLE nombre_tabla {RESTRICT|CASCADE};
En este caso tenemos que:
• Si utilizamos la opción RESTRICT, la tabla no se borrará si está referenciada, por ejemplo, por alguna vista.
• Si usamos la opción CASCADE, todo lo que referencie a la tabla se borrará con ésta.
1.4. Creacion y borrado de vistas
1.4. Creacion y borrado de vistas Dataprix 23 Septiembre, 2009 - 13:36Como hemos observado, la arquitectura ANSI/SPARC distingue tres niveles, que se describen en el esquema conceptual, el esquema interno y los esquemas externos. Hasta ahora, mientras creábamos las tablas de la base de datos, íbamos describiendo el esquema conceptual. Para describir los diferentes esquemas externos utilizamos el concepto de vista del SQL.
Para crear una vista es necesario utilizar la sentencia CREATE VIEW. Veamos su formato:
CREATE VIEW nombre_vista [(lista_columnas)] AS (consulta)
[WITH CHECK OPTION];Lo primero que tenemos que hacer para crear una vista es decidir qué nombre le queremos poner (nombre_vista). Si queremos cambiar el nombre de las columnas, o bien poner nombre a alguna que en principio no tenía, lo pode- mos hacer en lista_columnas. Y ya sólo nos quedará definir la consulta que formará nuestra vista.
Las vistas no existen realmente como un conjunto de valores almacenados en la base de datos, sino que son tablas ficticias, denominadas derivadas (no materializadas). Se construyen a partir de tablas reales (materializadas) almacenadas en la base de datos, y conocidas con el nombre de tablas básicas (o tablas de base). La no-existencia real de las vistas hace que puedan ser actualizables o no.
Creación de una vista en BDUOC
Creamos una vista sobre la base de datos BDUOC que nos dé para cada cliente el número de proyectos que tiene encargados el cliente en cuestión.
CREATE VIEW proyectos_por_cliente (codigo_cli, numero_proyectos) AS
(SELECT c.codigo_cli, COUNT(*)
FROM proyectos p, clientes c
WHERE p.codigo_cliente = c.codigo_cli
GROUP BY c.codigo_cli);
Si tuviésemos las siguientes extensiones:
• Tabla clientes:
| codigo_cli | nombre_cli | nif | dirección | ciudad | teléfono |
| 10 | EGICSA | 38.567.893-C | Aragón 11 | Barcelona | NULL |
| 20 | CME | 38.123.898-E | Valencia 22 | Girona | 972.223.57.21 |
| 30 | ACME | 36.432.127-A | Mallorca33 | Leida | 973.23.45.67 |
• Tabla proyectos:
| codigo_proyec | nombre_proyec | precio | fecha_inicio | fecha_prev_fin | fecha_fin | codigo_cliente |
|---|---|---|---|---|---|---|
| 1 | GESCOM | 1.000.000 | 1-1-98 | 1-1-99 | NULL | 10 |
| 2 | PESCI | 2.000.000 | 1-10-96 | 31-3-98 | 1-5-98 | 10 |
| 3 | SALSA | 1.000.000 | 10-2-98 | 1-2-99 | NULL | 20 |
| 4 | TNELL | 4.000.000 | 1-1-97 | 1-12-99 | NULL | 30 |
Y mirásemos la extensión de la vista proyectos_por_clientes, veríamos lo que encontramos en el margen.
En las vistas, además de hacer consultas, podemos insertar, modificar y borrar filas.
| codigo_cli | numero_proyectos |
|---|---|
| 10 | 2 |
| 20 | 1 |
| 30 | 1 |
Actualización de vistas en BDUOC
Si alguien insertase en la vista proyectos_por_cliente, los valores para un nuevo cliente 60 con tres proyectos encargados, encontraríamos que estos tres proyectos tendrían que figurar realmente en la tabla proyectos y, por lo tanto, el SGBD los debería insertar con la información que tenemos, que es prácticamente inexistente. Veamos gráficamente cómo quedarían las tablas después de esta hipotética actualización, que no llegaremos a hacer nunca, ya que iría en contra de la teoría del modelo relacional:
• Tabla clientes:
| codigo_cli | nombre_cli | nif | dirección | ciuda | teléfono |
| 10 | ECIGSA | 38.567.893-C | Aragón 11 | Barcelona | NULL |
| 20 | CME | 38.123.898-E | Valencia 22 | Girona | 972.23.57.21 |
| 30 | ACME | 36.432.127-A | mallorca 33 | Lleida | 973.23.45.67 |
| 60 | NULL | NULL | NULL | NULL | NULL |
• Tabla proyectos:
| codigo_proyec | nombre_proyec | precio | fecho_inicio | fecha_prev_fin | fecha_fin | codigo_cliente |
| 1 | GESCOM | 1.000.000 | 1-1-98 | 1-1-99 | NULL | 10 |
| 2 | PESCI | 2.000.000 | 1-10-96 | 31-3-98 | 1-5-98 | 10 |
| 3 | SALSA | 1.000.000 | 10-2-98 | 1-2-99 | NULL | 20 |
| NULL | NULL | NULL | NULL | NULL | NULL | 60 |
| NULL | NULL | NULL | NULL | NULL | NULL | 60 |
| NULL | NULL | NULL | NULL | NULL | NULL | 60 |
El SGBD no puede actualizar la tabla básica clientes si sólo sabe la clave primaria, y todavía menos la tabla básica proyectos sin la clave primaria; por lo tanto, esta vista no sería actualizable.
En cambio, si definimos una vista para saber los clientes que tenemos en Barcelona o en Girona, haríamos:
CREATE VIEW clientes_Barcelona_Girona AS
(SELECT *
FROM clientes
WHERE ciudad IN (‘Barcelona’, ‘Girona’))
WHITH CHECK OPTION;Si queremos asegurarnos de que se cumpla la condición de la cláusula WHERE, debemos poner la opción WHITH CHECK OPTION. Si no lo hiciésemos, podría ocurrir que alguien incluyese en la vista clientes_Barcelona_Girona a un cliente nuevo con el código 70, de nombre JMB, con el NIF 36.788.224-C, la dirección en NULL, la ciudad Lleida y el teléfono NULL.
Si consultásemos la extensión de la vista clientes_Barcelona_Girona, veríamos:
| codigo_cli | nombre_cli | nif | dirección | ciudad | teléfono |
|---|---|---|---|---|---|
| 10 | ECIGSA | 38.567.893-C | Aragón 11 | Barcelona | NULL |
| 20 | CME | 38.123.898-E | Valencia 22 | Girona | 972.223.57.21 |
Esta vista sí podría ser actualizable. Podríamos insertar un nuevo cliente con código 50, de nombre CEA, con el NIF 38.226.777-D, con la dirección París 44, la ciudad Barcelona y el teléfono 93.422.60.77. Después de esta actualización, en la tabla básica clientes encontraríamos, efectivamente:
| codigo_cli |
nombre_cli |
nif |
dirección |
ciudad |
teléfono |
|---|---|---|---|---|---|
| 10 | ECIGSA | 35.567.893-C | Aragón 11 | Barcelona | NULL |
| 20 | CME | 38.123.898-E | Valencia 22 | Girona | 972.23.57.21 |
| 30 | ACME | 36.432.127-A | Mallorca 33 | Lleida | 973.23.45.67 |
| 50 | CEA | 38.226.777-D | París 44 | Barcelona | 93.442.60.77 |
Para borrar una vista es preciso utilizar la sentencia DROP VIEW, que presenta el formato:
DROP VIEW nombre_vista (RESTRICT|CASCADE);Si utilizamos la opción RESTRICT, la vista no se borrará si está referenciada, por ejemplo, por otra vista. En cambio, si ponemos la opción CASCADE, todo lo que referencie a la vista se borrará con ésta.
Borrar una vista en BDUOC
Para borrar la vista clientes_Barcelona_Girona, haríamos lo siguiente:
DROP VIEW clientes_Barcelona_Girona RESTRICT;1.5. Definicion de la base de datos relacional BDUOC
1.5. Definicion de la base de datos relacional BDUOC Dataprix 24 Septiembre, 2009 - 09:32Veamos cómo se crearía la base de datos BDUOC, utilizando, por ejemplo, un SGBD relacional que disponga de la sentencia CREATE DATABASE:
CREATE DATABASE bduoc;
CREATE TABLE clientes
(codigo_cli INTEGER,
nombre_cli CHAR(30) NOT NULL,
nif CHAR (12),
direccion CHAR (30),
ciudad CHAR (20),
telefono CHAR (12),
PRIMARY KEY (codigo_cli),
UNIQUE(nif)
);CREATE TABLE departamentos
(nombre_dep CHAR(20) PRIMARY KEY,* * Tenemos que
ciudad_dep CHAR(20), elegir restricción
telefono INTEGER DEFAULT NULL, de tabla porque la
PRIMARY KEY (nombre_dep, ciudad_dep) clave primaria
); está compuesta por
más de un atributo. CREATE TABLE proyectos
(codigo_proyec INTEGER,
nombre_proyec CHAR(20),
precio REAL,
fecha_inicio DATE,
fecha_prev_fin DATE,
fecha_fin DATE DEFAULT NULL,
codigo_cliente INTEGER,
PRIMARY KEY (codigo_proyec),
FOREIGN KEY codigo_cliente REFERENCES clientes (codigo_cli),
CHECK (fecha_inicio < fecha_prev_fin),
CHECK (fecha_inicio < fecha_fin)
);CREATE TABLE empleados
(codigo_empl INTEGER,
nombre_empl CHAR (20),
apellido_empl CHAR(20),
sueldo REAL CHECK (sueldo > 7000),
nombre_dep CHAR(20)
ciudad_dep CHAR(20),
num_proyec INTEGER,
PRIMARY KEY (codigo_empl),
FOREIGN KEY (nombre_dep, ciudad_dep) REFERENCES
departamentos (nombre_dep, ciudad_dep),
FOREIGN KEY (num_proyec) REFERENCES proyectos (codigo_proyec)
);COMMIT;Al crear una tabla vemos que muchas restricciones se pueden imponer de dos formas: como restricciones de columna o como restricciones de tabla. Por ejem- plo, cuando queremos decir cuál es la clave primaria de una tabla, tenemos las dos posibilidades. Esto se debe a la flexibilidad del SQL:
• En el caso de que la restricción haga referencia a un solo atributo, podemos elegir la posibilidad que más nos guste.
• En el caso de la tabla departamentos, tenemos que elegir por fuerza la op- ción de restricciones de tabla, porque la clave primaria está compuesta por más de un atributo.
En general, lo pondremos todo como restricciones de tabla, excepto NOT NULL y CHECK cuando haga referencia a una sola columna.
2. Sentencias de manipulacion
2. Sentencias de manipulacion Dataprix 18 Septiembre, 2009 - 09:56Una vez creada la base de datos con sus tablas, debemos poder insertar, modificar y borrar los valores de las filas de las tablas. Para poder hacer esto, el SQL92 nos ofrece las siguientes sentencias: INSERTpara insertar, UPDATE para modificar y DELETE para borrar. Una vez hemos insertado valores en nuestras tablas, tenemos que poder consultarlos. La sentencia para hacer consultas a una base de datos con el SQL92 es SELECT FROM. Veamos a continuación estas sentencias.
2.1. Insercion de las filas en una tabla
2.1. Insercion de las filas en una tabla Dataprix 18 Septiembre, 2009 - 10:00Antes de poder consultar los datos de una base de datos, es preciso introducirlos con la sentencia INSERT INTO VALUES, que tiene el formato:
INSERT INTO nombre_tabla [(columnas)]
{VALUES ({v1|DEFAULT|NULL}, ..., {vn/DEFAULT/NULL})|};| Inserción de múltiples filas |
|
Para insertar más de una fila |
Los valores v1, v2, ..., vn se deben corresponder exactamente con las columnas que hemos dicho que tendríamos con el CREATE TABLE y deben estar en el mismo orden, a menos que las volvamos a poner a continuación del nombre de la tabla. En este último caso, los valores se deben disponer de forma coherente con el nuevo orden que hemos impuesto. Podría darse el caso de que quisiéramos que algunos valores para insertar fuesen valores por omisión, definidos previamente con la opción DEFAULT. Entonces pondríamos la palabra reservada DEFAULT. Si se trata de introducir valores nulos, también podemos utilizar la palabra reservada NULL.
Inserción de una fila en BDUOC
La forma de insertar a un cliente en la tabla clientes de la base de datos de BDUOC es:
INSERT INTO clientes
VALUES (10, ‘ECIGSA’, ‘37.248.573-C’, ‘ARAGON 242’, ‘Barcelona’, DEFAULT);o bien:
INSERT INTO clientes(nif, nombre_cli, codigo_cli, telefono, direccion,
ciudad)
VALUES (‘37.248.573-C’, ‘ECIGSA’, 10, DEFAULT, ‘ARAGON 242’, ‘Barcelona’);2.2. Borrado de las filas de una tabla
2.2. Borrado de las filas de una tabla Dataprix 18 Septiembre, 2009 - 10:01Para borrar valores de algunas filas de una tabla podemos utilizar la sentencia DELETE FROM WHERE. Su formato es el siguiente:
DELETE FROM nombre_tabla
[WHERE condiciones];En cambio, si lo que quisiéramos conseguir es borrar todas las filas de una tabla, entonces sólo tendríamos que poner la sentencia DELETE FROM, sin WHERE.
| Borrado de múltiples filas |
| Notemos que el cliente con el código 2 podría tener más de un proyectyo contratado y, por lo tanto, se borraría más de una fila con una sola sentencia. |
Borrar todas las filas de una tabla en BDUOC
Podemos dejar la tabla proyectos sin ninguna fila:
DELETE FROM proyectos;
En nuestra base de datos, borrar los proyectos del cliente 2 se haría de la forma que mostramos a continuación:
DELETE FROM proyectos
WHERE codigo_cliente = 2;2.3. Modificacion de filas de una tabla
2.3. Modificacion de filas de una tabla Dataprix 18 Septiembre, 2009 - 10:03Si quisiéramos modificar los valores de algunas filas de una tabla, tendríamos que utilizar la sentencia UPDATE SET WHERE. A continuación presentamos su formato:
UPDATE nombre_tabla
SET columna = {expresión|DEFAULT|NULL}
[, columna = {expr|DEFAULT|NULL} ...]
WHERE condiciones;
| Modificación de múltiples filas |
| Notemos que el proyecto número 2 podría tener a más de un empleado asignado y, por lo tanto, se modificaría la columna sueldo, de más de una fila con una sola sentencia |
Modificación de los valores de algunas filas en BDUOC
Supongamos que queremos incrementar el sueldo de todos los empleados del proyecto 2 en 1.000 euros. La modificación a ejecutar sería:
UPDATE empleados
SET sueldo = sueldo + 1000
WHERE num_proyec = 2;2.4. Introduccion de filas en la base de datos relacional BDUOC
2.4. Introduccion de filas en la base de datos relacional BDUOC Dataprix 18 Septiembre, 2009 - 11:20
Antes de empezar a hacer consultas a la base de datos BDUOC, habremos introducido unas cuantas filas en sus tablas con la sentencia INSERT INTO. De esta forma, podremos ver reflejado el resultado de las consultas que iremos haciendo, a partir de este momento, sobre cada extensión; esto lo podemos observar en las tablas correspondientes a cada extensión, que presentamos a continuación:
• Tabla departamentos:
| nombre_dep | ciudad_dep | telefono |
|---|---|---|
| DIR | Barcelona | 93.422.60.70 |
| DIR | Girona | 972.23.89.70 |
| DIS | Lleida | 973.23.50.40 |
| DIS | Barcelona | 93.224.85.23 |
| PROG | Tarragona | 977.33.38.52 |
| PROG | Girona | 972.23.50.91 |
• Tabla clientes:
| codigo_cli | nombre_cli | nif | direccion | ciudad | telefono |
|---|---|---|---|---|---|
| 10 | EGICSA | 38.567.893-C | Aragón 11 | Barcelona | NULL |
| 20 | CME | 38.123.898-E | Valencia 22 | Girona | 972.23.57.67 |
| 30 | ACME | 36.432.127-A | Mallorca 33 | Lleida | 973.23.45.67 |
| 40 | JGM | 38.782.345-B | Rosellon 44 | Tarragona | 977.33.71.43 |
• Tabla empleados:
| codigo_empleado | nombre_empl | apellido_empl | sueldo | nombre_dep | ciudad_dep | num_proyec |
|---|---|---|---|---|---|---|
| 1 |
María |
Puig |
100.000 |
DIR |
Girona |
1 |
| 2 |
Pedro |
Mas |
90.000 |
DIR |
Barcelona |
4 |
| 3 |
Ana |
Ros |
70.000 |
DIS |
Lleida |
3 |
| 4 |
Jorge |
Roca |
70.000 |
DIS |
Barcelona |
4 |
| 5 |
Clara |
Blanc |
40.000 |
PROG |
Tarragona |
1 |
| 6 |
Laura |
Tort |
30.000 |
PROG |
Tarragona |
3 |
| 7 |
Rogelio |
Salt |
40.000 |
NULL |
NULL |
4 |
| 8 |
Sergio |
Grau |
30.000 |
PROG |
Tarragona |
Null |
• Tabla proyectos
| codigo_proyec | nombre_proyec | precio | fecha_inicio | fecha_prev_fin | fecha_fin | codigo_cliente |
|---|---|---|---|---|---|---|
| 1 |
GESCOM |
1.000.000 | 1-1-98 | 1-1-99 | NULL | 10 |
| 2 | PESCI | 2.000.000 | 1-10-96 | 31-3-98 | 1-5-98 | 10 |
| 3 | SALSA | 1.000.000 | 10-2-98 | 1-2-99 | NULL | 20 |
| 4 | TINELL | 4.000.000 | 1-1-97 | 1-12-99 | NULL | 30 |
2.5. Consultas a una base de datos relacional
2.5. Consultas a una base de datos relacional Dataprix 18 Septiembre, 2009 - 11:35Para hacer consultas sobre una tabla con el SQL es preciso utilizar la sentencia SELECT FROM, que tiene el siguiente formato:
SELECT nombre_columna_a_seleccionar [[AS] col_renombrada]
[,nombre_columna_a_seleccionar [[AS] col_renombrada]...]
FROM tabla_a_consultar [[AS] tabla_renombrada];La opción AS nos permite renombrar las columnas que queremos seleccionar o las tablas que queremos consultar que en este caso, es sólo una. Dicho de otro modo, nos permite la definición de alias. Fijémonos en que la palabra clave AS es opcional, y es bastante habitual poner sólo un espacio en blanco en lugar de toda la palabra.
Consultas a BDUOC
A continuación presentamos un ejemplo de consulta a la base de datos BDUOC para conocer todos los datos que aparece en la tabla clientes:
SELECT *
FROM clientes;
El * después de SELECT indicaque queremos ver todos los atributos que aparecen en la tabla.
La respuesta a esta consulta sería:
| codigo_cli | nombre_cli | nif | direccion | ciudad | telefono |
|---|---|---|---|---|---|
| 10 | EGICSA | 38.567.893-C | Aragón 11 | Barcelona | NULL |
| 20 | CME | 38.123.898-E | Valencia 22 | Girona | 972.23.57.67 |
| 30 | ACME | 36.432.127-A | Mallorca 33 | Lleida | 973.23.45.67 |
| 40 | JGM | 38.782.345-B | Rosellon 44 | Tarragona | 977.33.71.43 |
Si hubiésemos querido ver sólo el código, el nombre, la dirección y la ciudad, habríamos hecho:
SELECT codigo_cli, nombre_cli, direccion, ciudad
FROM clientes;Y habríamos obtenido la respuesta siguiente:
| codigo_cli | nombre_cli | direccion | ciudad |
|---|---|---|---|
| 10 | EGICSA | Aragón 11 | Barcelona |
| 20 | CME | Valencia 22 | Girona |
| 30 | ACME | Mallorca 33 | Lleida |
| 40 | JGM | Rosellon 44 | Tarragona |
Con la sentencia SELECT FROM podemos seleccionar columnas de una tabla, pero para seleccionar filas de una tabla es preciso añadirle la cláusula WHERE. El formato es:
SELECT nombre_columnas_a_seleccionar
FROM tabla_a_consultar
WHERE condiciones;La cláusula WHERE nos permite obtener las filas que cumplen la condición especificada en la consulta.
| codigo_emple |
| 2 |
| 4 |
| 7 |
Consultas a BDUOC seleccionando filas
Veamos un ejemplo en el que pedimos “los códigos de los empleados que trabajan en el proyecto número 4”:
SELECT codigo_empl
FROM empleados
WHERE num_proyec = 4;La respuesta a esta consulta sería la que podéis ver en el margen.
Para definir las condiciones en la cláusula WHERE, podemos utilizar alguno de los operadores de los que dispone el SQL, que son los siguientes:
| = | Igual |
| < | Menor |
| > | Mayor |
| <= | Menor o igual |
| >= | Mayor o igual |
| <> | Diferente |
| NOT | Para la negación de condiciones |
| AND | Para la conjunción de conciciones |
| OR | Para la disyunción de condiciones |
Si queremos que en una consulta nos aparezcan las filas resultantes sin repeticiones, es preciso poner la palabra clave DISTINCT inmediatamente después de SELECT. También podríamos explicitar que lo queremos todo, incluso con repeticiones, poniendo ALL (opción por defecto) en lugar de DISTINCT. El formato de DISTINCT es:
SELECT DISTINCT nombre_columnas_a_seleccionar
FROM tabla_a_consultar
[WHERE condiciones];| 30.000 |
| 40.000 |
| 70.000 |
| 90.000 |
| 100.000 |
Consulta a BDUOC seleccionando filas sin repeticiones
Por ejemplo, si quisiéramos ver qué sueldos se están pagando en nuestra empresa, podríamos hacer:
SELECT DISTINCT sueldo
FROM empleados;La respuesta a esta consulta, sin repeticiones, sería la que aparece en el margen.
2.5.1. Funciones de agregacion
2.5.1. Funciones de agregacion Carlos 17 Septiembre, 2009 - 11:52El SQL nos ofrece las siguientes funciones de agregación para efectuar varias operaciones sobre los datos de una base de datos:
| Función | Descripción |
| COUNT | Nos da el número total de filas seleccionadas |
| SUM | Suma los valores de una columna |
| MIN | Nos da el valor mínimo de una columna |
| MAX | Nos da el valor máximo de una columna |
| AVG | Calcula el valor medio de una columna |
En general, las funciones de agregación se aplican a una columna, excepto la función de agregación COUNT, que normalmente se aplica a todas las columnas de la tabla o tablas seleccionadas. Por lo tanto,COUNT (*) contará todas las filas de la tabla o las tablas que cumplan las condiciones. Si se utilizase COUNT(distinct columna), sólo contaría los valores que no fuesen nulos ni repetidos, y si se utilizase COUNT(columna), sólo contaría los valores que no fuesen nulos.
Ejemplo de utilización de la función COUNT (*)
Veamos un ejemplo de uso de la función COUNT, que aparece en la cláusula SELECT, para hacer la consulta “¿Cuántos departamentos están ubicados en la ciudad de Lleida?”:
SELECT COUNT(*) AS numero_dep
FROM departamentos
WHERE ciudad_dep = ‘Lleida’;| numero_dep |
| 1 |
La respuesta a esta consulta sería la que aparece reflejada en la tabla que encontraréis en el margen.
Veremos ejemplos de las demás funciones de agregación en los siguientes apartados.
2.5.2. Subconsultas
2.5.2. Subconsultas Dataprix 18 Septiembre, 2009 - 11:30Una subconsulta es una consulta incluida dentro de una cláusula WHERE o HAVING de otra consulta. En ocasiones, para expresar ciertas condiciones no hay más remedio que obtener el valor que buscamos como resultado de una consulta.
| codigo_proyec | nombre_proyec |
| 4 | TINELL |
Subconsulta en BDUOC
Si quisiéramos saber los códigos y los nombres de los proyectos de precio más elevado, en primer lugar tendríamos que encontrar los proyectos que tienen el precio más elevado. Lo haríamos de la forma siguiente:
| Los proyectos de precio más bajo |
| Si en lugar de los códigos y los nombres de los proyectos de precio más alto hubiésemos querido saber los de precio más bajo, habríamos aplicado la función de agregación MIN. |
SELECT codigo_proyec, nombre_proyec
FROM proyectos
WHERE precio = (SELECT MAX(precio)
FROM proyectos);El resultado de la consulta anterior sería lo que puede verse al margen.
2.5.3. Otros predicados
2.5.3. Otros predicados Dataprix 21 Septiembre, 2009 - 09:571) Predicado BETWEEN
Para expresar una condición que quiere encontrar un valor entre unos límites concretos, podemos utilizar Roman;">BETWEEN</span>:</p>
SELECT nombre_columnas_a_seleccionar
FROM tabla_a_consultar
WHERE columna BETWEEN límite1 AND límite2;
Ejemplo de uso del predicado BETWEEN
Un ejemplo en el que se pide “Los códigos de los empleados que ganan entre 20.000 y 50.000 euros anuales” sería:
| codio_empl |
|---|
| 5 |
| 6 |
| 7 |
| 8 |
La respuesta a esta consulta sería la que se ve en el margen.
2) Predicado IN
Para comprobar si un valor coincide con los elementos de una lista utilizaremos IN, y para ver si no coincide, NOT IN:
Ejemplo de uso del predicado IN
“Queremos saber el nombre de todos los departamentos que se encuentran en las ciudades de Lleida o Tarragona”:
| nombre_dep |
ciudad_dep |
|---|---|
| DIS | Lleida |
| PROG | Tarragona |
La respuesta sería la que aparece en el margen.
3) Predicado LIKE
Para comprobar si una columna de tipo carácter cumple alguna propiedad determinada, podemos usar LIKE:
Los patrones del SQL92 para expresar características son los siguientes:
| Otros patrones |
| Aunque_y % son los caracteres elegidos por el estandar, cada sistema relacional comercial ofrece diversas variantes. |
a) Pondremos un carácter _ para cada carácter individual que queramos considerar.
b) Pondremos un carácter % para expresar una secuencia de caracteres, que puede no estar formada por ninguno.
Ejemplo de uso del predicado LIKE
| Atributos añadidos |
| Aunque la consulta pide sólo los nombres de empleados añadimos los códigos para poder diferenciar dos empleados con el mismo nombre. |
A continuación presentamos un ejemplo en el que buscaremos los nombres de los empleados que empiezan por J, y otro ejemplo en el que obtendremos los proyectos que comienzan por S y tienen cinco letras:
a) Nombres de empleados que empiezan por la letra J:
| codigo_empl |
nombre_empl |
|---|---|
| 4 | Jorge |
La respuesta a esta consulta seria la que se muestra den el margen.
b) Proyectos que empiezan por S y tienen cinco letras:
| codigo_progec |
|---|
| 3 |
Y la respuesta a esta otra consulta sería la que aparece en el margen.
4) Predicado IS NULL
Para comprobar si un valor es nulo utilizaremos IS NULL, y para averiguar si no lo es, IS NOT NULL. El formato es:
Ejemplo de uso del predicado IS NULL
Un ejemplo de uso de este predicado sería “Queremos saber el código y el nombre de todos los empleados que no están asignados a ningún proyecto”:
| codigo_emple |
nombre_emple |
|---|---|
| 8 | Sergio |
Obtendríamos la respuesta que tenemos al margen.
5) Predicados ANY/SOME y ALL
| Los predicados ANY/SOME |
| Podemos elegir cualquiera de los predicados para pedir que alguna fila satisfaga una conducción. |
Para ver si una columna cumple que todas sus filas (ALL) o algunas de sus filas (ANY/SOME) satisfagan una condición, podemos hacer:
Ejemplo de uso de los predicados ALL y ANY/SOME
a) Veamos un ejemplo de aplicación de ALL para encontrar los códigos y los nombres de los proyectos en los que los sueldos de todos los empleados asignados son menores que el precio del proyecto:
| codigo_proyec | nombre_proyec |
|---|---|
| 1 | GESCOM |
| 2 | PESCI |
| 3 | SALSA |
| 4 | TINELL |
Fijémonos en la condición de WHERE de la subconsulta, que nos asegura que los sueldos que observamos son los de los empleados asignados al proyecto de la consulta. La respuesta a esta consulta sería la que aparece en el margen.
b) A continuación, presentamos un ejemplo de ANY/SOME para buscar los códigos y los nombres de los proyectos que tienen algún empleado que gana un sueldo más elevado que el precio del proyecto en el que trabaja.
| codigo_proyec | nombre_proyec |
|---|---|
La respuesta a esta consulta está vacía, como se ve en el margen.
6) Predicado EXISTS
Para comprobar si una subconsulta produce alguna fila de resultados, podemos utilizar la sentencia denominada test de existencia: EXISTS. Para comprobar si una subconsulta no produce ninguna fila de resultados, podemos utilizar NOT EXISTS.
Ejemplo de uso del predicado EXISTS
| codigo_empl | nombre_empl |
|---|---|
| 1 |
María |
| 2 | Pedro |
| 3 | Ana |
| 4 | Jorge |
| 5 | Clara |
| 6 | Laura |
| 7 | Rogelio |
Un ejemplo en el que se buscan los códigos y los nombres de los empleados que están asignados a algún proyecto sería:
La respuesta a esta consulta sería la que se muestra en el margen.