Manual para la adquisición de un sistema de Data Warehouse
Manual para la adquisición de un sistema de Data WarehouseEl Consejo Superior de informática ha publicado una serie de Guías Técnicas Aplicables a la Contratación de Bienes y Servicios de Tecnologías de la Información y las Comunicaciones. Una de estas guías está dedicada a los Sistemas de Data Warehouse. Publicamos aquí su contenido, dada la claridad con la que se explican los conceptos básicos relativos al Data Warehouse y, en definitiva, la utilidad de la misma.
2.- ANÁLISIS DEL ENTORNO DE DATA WAREHOUSE
2.1.- ¿Qué es un Data Warehouse?
2.2.- Conceptos y funcionalidades básicas
2.3.- Tendencias tecnológicas y de mercado
3.- ASPECTOS TÉCNICOS DEL PROCESO DE ADQUISICIÓN DE SISTEMAS DE DATA WAREHOUSE
3.1.- Análisis de las necesidades del comprador
3.2.- Factores relevantes en el proceso de adquisición
3.3.- Diseño del pliego de prescripciones técnicas particulares
4.- PRUEBAS DE VERIFICACIÓN Y CONTROL
6.- EQUIPO RESPONSABLE DE LA GUIA TÉCNICA
Introducción al Manual de Data Warehouse
Introducción al Manual de Data Warehouse1.- INTRODUCCIÓN
1.1. Justificación histórica
En la actualidad, las tecnologías de la información han automatizado los procesos de carácter típicamente repetitivo o administrativo, haciendo uso de lo que llamaremos sistemas de información operacionales. Entendemos por aplicaciones operacionales, aquellas que resuelven las necesidades de funcionamiento de la empresa. En este tipo de sistemas, los conceptos más importantes son la actualización y el tiempo de respuesta.
Una vez satisfechas las necesidades operacionales más acuciantes, surge un nuevo grupo de necesidades sobre los sistemas de la empresa, a las cuales vamos a calificar como necesidades informacionales. Por necesidades informacionales, entendemos aquellas que tienen por objeto obtener la información necesaria, que sirva de base para la toma de decisiones tanto a escala estratégica como táctica. Estas necesidades informacionales se basan en gran medida en el análisis de un número ingente de datos, en el que es tan importante el obtener un valor muy detallado de negocio como el valor totalizado para el mismo. Es fundamental también la visión histórica de todas las variables analizadas, y el análisis de los datos del entorno. Estos requerimientos no son, a priori, difíciles de resolver dado que la información está efectivamente en los sistemas operacionales. Cualquier actividad que realiza la empresa está reflejada de forma minuciosa en sus bases de datos.
La realidad, sin embargo, es distinta, puesto que al atender las necesidades de tipo informacional, los responsables de sistemas se tropiezan con múltiples problemas. En primer lugar, al realizar consultas masivas de información (con el fin de conseguir el ratio, valor agrupado o grupo de valores solicitados), se puede ver perjudicado el nivel de servicio del resto de sistemas, dado que las consultas de las que estamos hablando, suelen ser bastante costosas en recursos. Además, las necesidades se ven insatisfechas por la limitada flexibilidad a la hora de navegar por la información y a su inconsistencia debido a la falta de una visión global (cada visión particular del dato está almacenada en el sistema operacional que lo gestiona).
En esta situación, el siguiente paso evolutivo ha venido siendo la generación de un entorno gemelo del operativo, que se ha denominado comúnmente Centro de Información, en el cual la información se refresca con menor periodicidad que en los entornos operacionales y los requerimientos en el nivel de servicio al usuario son más flexibles.
Con esta estrategia se resuelve el problema de la planificación de recursos ya que las aplicaciones que precisan un nivel de servicio alto usan el entorno operacional y las que precisan consultas masivas de información trabajan en el Centro de Información. Otro beneficio de este nuevo entorno, es la no inferencia con las aplicaciones operacionales.
Pero no terminan aquí los problemas. La información mantiene la misma estructura que en las aplicaciones operacionales por lo que este tipo de consultas debe acceder a multitud de lugares para obtener el conjunto de datos deseado. El tiempo de respuesta a las solicitudes de información es excesivamente elevado. Adicionalmente, al proceder la información de distintos sistemas, con visiones distintas y distintos objetivos, en muchas ocasiones no es posible obtener la información deseada de una forma fácil y además carece de la necesaria fiabilidad.
De cara al usuario estos problemas se traducen en que no dispone a tiempo de la información solicitada y que debe dedicarse con más intensidad a la obtención de la información que al análisis de la misma, que es donde aporta su mayor valor añadido.
1.2. Sumario
En los capítulos siguientes expondremos, por un lado qué es un Data Warehouse, un Data Mart y el porqué de estos conceptos. Por otro lado, veremos sus componentes de base (hardware y software) y el "estado del arte" de las distintas tecnologías disponibles. Analizaremos las distintas partes de las que se compone un sistema Data Warehouse y presentaremos una metodología de construcción del mismo. Examinaremos el uso que se le puede dar (Explotación del Data Warehouse), con especial hincapié en el Data Mining y las posibilidades de acceso a esta información. También presentaremos cómo algunas áreas se han beneficiado de las tecnologías de Data Warehouse: Marketing, Departamento Financiero, Área de Riesgo de Crédito, etc. Y por último, expondremos algunas recomendaciones generales a considerar para un buen uso de los sistemas de este tipo.

Análisis del entorno Data Warehouse
Análisis del entorno Data Warehouse2.- ANÁLISIS DEL ENTORNO DATA WAREHOUSE
2.1.- ¿Qué es un Data Warehouse?
2.2.- Conceptos y funcionalidades básicas
2.3.- Tendencias tecnológicas y de mercado
|
 |
|
¿Qué es un Data Warehouse?
¿Qué es un Data Warehouse?2.1. - ¿QUÉ ES UN DATA WAREHOUSE?
Tras las dificultades de los sistemas tradicionales en satisfacer las necesidades de información, surge el concepto de Data Warehouse, como solución a las necesidades informacionales globales de la empresa. Este término, acuñado por Bill Inmon, se traduce literalmente como Almacén de Datos. No obstante si el Data Warehouse fuese exclusivamente un almacén de datos, los problemas seguirían siendo los mismos que en los Centros de Información.
Características del Data Warehouse
La ventaja principal de este tipo de sistemas se basa en su concepto fundamental, la estructura de la información. Este concepto significa el almacenamiento de información homogénea y fiable, en una estructura basada en la consulta y el tratamiento jerarquizado de la misma, y en un entorno diferenciado de los sistemas operacionales. Según definió Bill Inmon, el Data Warehouse se caracteriza por ser:
- Integrado: los datos almacenados en el Data Warehouse deben integrarse en una estructura consistente, por lo que las inconsistencias existentes entre los diversos sistemas operacionales deben ser eliminadas. La información suele estructurarse también en distintos niveles de detalle para adecuarse a las distintas necesidades de los usuarios.
- Temático: sólo los datos necesarios para el proceso de generación del conocimiento del negocio se integran desde el entorno operacional. Los datos se organizan por temas para facilitar su acceso y entendimiento por parte de los usuarios finales. Por ejemplo, todos los datos sobre clientes pueden ser consolidados en una única tabla del Data Warehouse. De esta forma, las peticiones de información sobre clientes serán más fáciles de responder dado que toda la información reside en el mismo lugar.
- Histórico: el tiempo es parte implícita de la información contenida en un Data Warehouse. En los sistemas operacionales, los datos siempre reflejan el estado de la actividad del negocio en el momento presente. Por el contrario, la información almacenada en el Datawarehouse sirve, entre otras cosas, para realizar análisis de tendencias. Por lo tanto, el Data Warehouse se carga con los distintos valores que toma una variable en el tiempo para permitir comparaciones.
- No volátil: el almacén de información de un Data Warehouse existe para ser leído, y no modificado. La información es por tanto permanente, significando la actualización del DWH la incorporación de los últimos valores que tomaron las distintas variables contenidas en él sin ningún tipo de acción sobre lo que ya existía.
Las Dimensiones del Data Warehouse
E.F. Codd, considerado como el padre de las bases de datos relacionales, ha venido insistiendo desde principio de los noventa, que disponer de un sistema de bases de datos relacionales, no significa disponer de un soporte directo para la toma de decisiones. Muchas de estas decisiones se basan en un análisis de naturaleza multidimensional, que se intentan resolver con la tecnología no orientada para esta naturaleza. Este análisis multidimensional parte de una visión de la información como dimensiones de negocio.
Dimensiones de negocio vistas como cubos

Estas dimensiones de negocio se comprenden mejor fijando un ejemplo, para lo que vamos a mostrar, para un sistema de gestión de expedientes, las jerarquías que se podrían manejar para el número de los mismo para las dimensiones: zona geográfica, tipo de expediente y tiempo de resolución. La visión general de la información de ventas para estas dimensiones definidas, la representaremos gráficamente como un cubo:

Un gerente de una zona estaría interesado en visualizar la información para su zona en el tiempo para todos los productos que distribuye, lo podría tener una representación gráfica como el cubo de la figura inferior.

Un director de producto, sin embargo, querría examinar la distribución geográfica de sus productos, para toda la información histórica almacenada en el Data Warehouse.
Esto se podría representar como la figura inferior, que refleja la selección de datos por la jerarquía de producto.

O se podría también examinar los datos en un determinado momento o una visión particularizada.
Jerarquías de las dimensiones
A su vez, estas dimensiones tienen una jerarquía, interpretándose en el cubo como que cada cubo elemental es un dato elemental, del que se puede extraer información agregada.
En el ejemplo anterior podría ser:
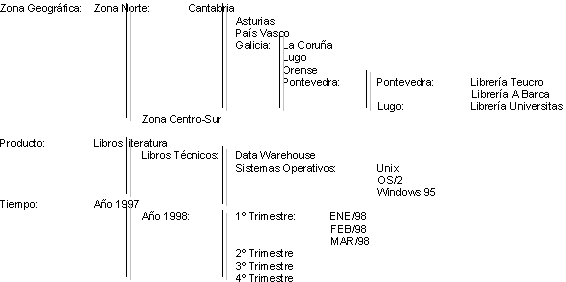
Y así, por ejemplo, se podría querer analizar la evolución de las ventas en Galicia de libros de Física por meses desde Febrero del 1996 hasta Marzo del 1997.
Ello es fácil de obtener (incluso a "golpe de ratón") si la información de ventas se ha almacenado en un Data Warehouse, definiendo estas jerarquías y estas dimensiones de negocio.
En este sentido citamos las palabras de D. Wayne Calloway Director Ejecutivo de Operaciones de Pepsico en una asamblea general de accionistas:
"Hace diez años les pude decir cuántos Doritos vendimos al Oeste del Mississipi. Hoy no sólo les puedo decir eso mismo, sino cuántos vendimos en California, en el Condado de Orange, en la ciudad de Irvine, en el Supermercado local Von’s, en una promoción especial, al final del pasillo 4, los jueves".
La importancia de los metadatos
Otra característica del Data Warehouse es que contiene datos relativos a los datos, concepto que se ha venido asociando al término de metadatos. Los metadatos permiten mantener información de la procedencia de la información, la periodicidad de refresco, su fiabilidad, forma de cálculo, etc., relativa a los datos de nuestro almacén.
Estos metadatos serán los que permitan simplificar y automatizar la obtención de la información desde los sistemas operacionales a los sistemas analíticos.
Los objetivos que deben cumplir los metadatos, según el colectivo al que va dirigido, serían:
- Dar soporte al usuario final, ayudándole a acceder al Datawarehouse con su propio lenguaje de negocio, indicando qué información existe y qué significado tiene. Ayudar a construir consultas, informes y análisis, mediante herramientas de navegación.
- Dar soporte a los responsables técnicos del Data Warehouse en aspectos de auditoría, gestión de la información histórica, administración del Data Warehouse, elaboración de programas de extracción de la información, especificación de las interfaces para la realimentación a los sistemas operacionales de los resultados obtenidos, etc.
Procesos clave en la gestión del Data Warehouse
Para comprender el concepto de Data Warehouse, es importante considerar los procesos que lo conforman. A continuación se describen dichos procesos clave en la gestión de un Data Warehouse:
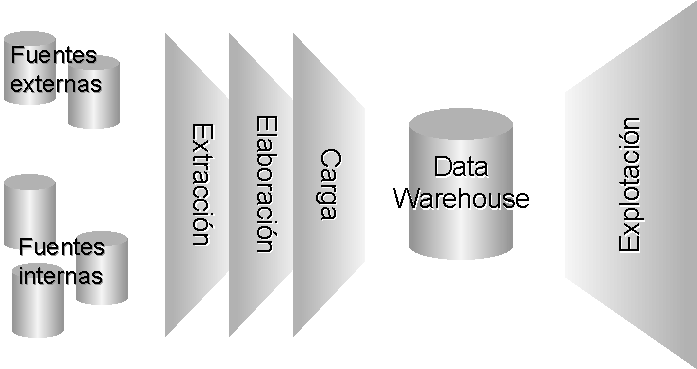
- Extracción: obtención de información de las distintas fuentes tanto internas como externas.
- Elaboración: filtrado, limpieza, depuración, homogeneización y agrupación de la información.
- Carga: organización y actualización de los datos y los metadatos en la base de datos.
- Explotación: extracción y análisis de la información en los distintos niveles de agrupación.
Desde el punto de vista del usuario, el único proceso visible es la explotación del almacén de datos, aunque el éxito del Data Warehouse radica en los tres procesos iniciales que alimentan la información del mismo y suponen el mayor porcentaje de esfuerzo (en torno a un 80%) a la hora de desarrollar el almacén.
Data Warehouse vs. Sistemas de información tradicionales
Las diferencias de un Data Warehouse con un sistema de gestión de la información tradicional, que podríamos llamar operacional, las podríamos resumir en el siguiente esquema:
SISTEMA TRADICIONAL
DATA WAREHOUSE
- Predomina la actualización
- Predomina la consulta
- La actividad más importante es de tipo operativo (día a día)
- La actividad más importante es el análisis y la decisión estratégica
- Predomina el proceso puntual
- Predomina el proceso masivo
- Mayor importancia a la estabilidad
- Mayor importancia al dinamismo
- Datos en general desagregados
- Datos en distintos niveles de detalle y agregación
- Importancia del dato actual
- Importancia del dato histórico
- Importante del tiempo de respuesta de la transacción instantánea
- Importancia de la respuesta masiva
- Estructura relacional
- Visión multidimensional
- Usuarios de perfiles medios o bajos
- Usuarios de perfiles altos
- Explotación de la información relacionada con la operativa de cada aplicación
- Explotación de toda la información interna y externa relacionada con el negocio
Beneficios de la implantación de un Data Warehouse
Una de las claves del éxito en la construcción de un Data Warehouse es el desarrollo de forma gradual, seleccionando a un departamento usuario como piloto y expandiendo progresivamente el almacén de datos a los demás usuarios. Por ello es importante elegir este usuario inicial o piloto, siendo importante que sea un departamento con pocos usuarios, en el que la necesidad de este tipo de sistemas es muy alta y se puedan obtener y medir resultados a corto plazo.
Terminamos este apartado resumiendo los beneficios que un Data Warehouse puede aportar:
- Proporciona una herramienta para la toma de decisiones en cualquier área funcional, basándose en información integrada y global del negocio.
- Facilita la aplicación de técnicas estadísticas de análisis y modelización para encontrar relaciones ocultas entre los datos del almacén; obteniendo un valor añadido para el negocio de dicha información.
- Proporciona la capacidad de aprender de los datos del pasado y de predecir situaciones futuras en diversos escenarios.
- Simplifica dentro de la empresa la implantación de sistemas de gestión integral de la relación con el cliente.
- Supone una optimización tecnológica y económica en entornos de Centro de Información, estadística o de generación de informes con retornos de la inversión espectaculares.
Conceptos y funcionalidades básicas de Data Warehouse
Conceptos y funcionalidades básicas de Data Warehouse2.2.- CONCEPTOS Y FUNCIONALIDADES BÁSICAS
2.2.1.- Data Warehouse vs. Data Mart
2.2.2.- Componentes a tener en cuenta a la hora de construir un Data Warehouse
2.2.3.- Fases de implantación de un Data Warehouse
2.2.4.- Estrategias de implantación
2.2.5.- Técnicas de Explotación de la Información
2.2.6.- Tipos de aplicaciones en las que utilizar las técnicas disponibles sobre DW
2.2.7.- Seguridad de acceso y manipulación de la información en el Data Warehouse
Data Warehouse vs Data Mart
Data Warehouse vs Data Mart2.2.1.- DATA WAREHOUSE VS. DATA MART
La duplicación en otro entorno de datos es un término que suele ser mal interpretado e incomprendido. Así es usado por los fabricantes de SGBD en el sentido de simple réplica de los datos de un sistema operacional centralizado en sistemas distribuidos. En un contexto de Data Warehouse, el término duplicación se refiere a la creación de Data Marts locales o departamentales basados en subconjuntos de la información contenida en el Data Warehouse central o maestro.
[[ad]]Según define Meta Group, "un Data Mart es una aplicación de Data Warehouse, construida rápidamente para soportar una línea de negocio simple". Los Data Marts, tienen las mismas características de integración, no volatilidad, orientación temática y no volatilidad que el Data Warehouse. Representan una estrategia de "divide y vencerás" para ámbitos muy genéricos de un Data Warehouse.
Esta estrategia es particularmente apropiada cuando el Data Warehouse central crece muy rápidamente y los distintos departamentos requieren sólo una pequeña porción de los datos contenidos en él. La creación de estos Data Marts requiere algo más que una simple réplica de los datos: se necesitarán tanto la segmentación como algunos métodos adicionales de consolidación.
La primera aproximación a una arquitectura descentralizada de Data Mart, podría ser venir originada de una situación como la descrita a continuación.
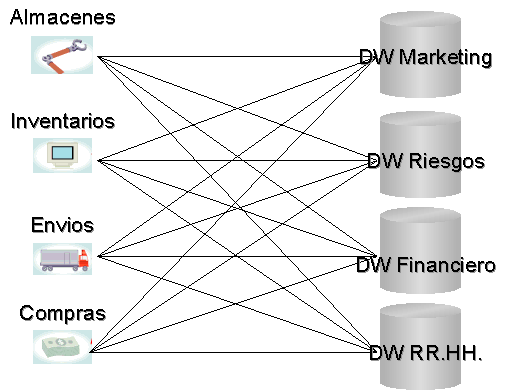
El departamento de Marketing, emprende el primer proyecto de Data Warehouse como una solución departamental, creando el primer Data Mart de la empresa.
[[ad]]Visto el éxito del proyecto, otros departamentos, como el de Riesgos, o el Financiero se lanzan a crear sus Data Marts. Marketing, comienza a usar otros datos que también usan los Data Marts de Riesgos y Financiero, y estos hacen lo propio.
Esto parece ser una decisión normal, puesto que las necesidades de información de todos los Data Marts crecen conforme el tiempo avanza. Cuando esta situación evoluciona, el esquema general de integración entre los Data Marts pasa a ser, la del gráfico de la derecha.
En esta situación, es fácil observar cómo este esquema de integración de información de los Data Marts, pasa a convertirse en un rompecabezas en el que la gestión se ha complicado hasta convertir esta ansia de información en un auténtico quebradero de cabeza. No obstante, lo que ha fallado no es la integración de Data Marts, sino su forma de integración.
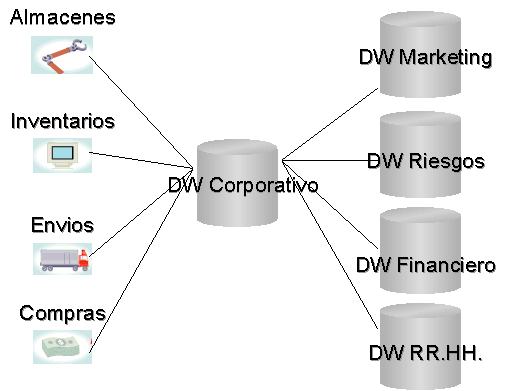
En efecto, un enfoque más adecuado sería la coordinación de la gestión de información de todos los Data Marts en un Data Warehouse centralizado.
En esta situación los Data Marts obtendrían la información necesaria, ya previamente cargada y depurada en el Data Warehouse corporativo, simplificando el crecimiento de una base de conocimientos a nivel de toda la empresa.
Esta simplificación provendría de la centralización de las labores de gestión de los Data Marts, en el Data Warehouse corporativo, generando economías de escala en la gestión de los Data Marts implicados.
Según un estudio de IDC (International Data Corporation) tras analizar 541 empresas, la distribución de las implantaciones de Data Warehouse y Data Marts en la actualidad, y sus opiniones respecto a esta distribución en el futuro, nos muestra los siguientes datos:
En la gráfica, observamos, cómo en la actualidad, de las empresas consultadas, un 80% de ellas cuentan con implantaciones de Data Warehouse o Data Marts.

La proporción actual de implantaciones de Data Warehouse es casi el doble que el de Data Mart.
[[ad]]No obstante, seguramente tras la andadura inicial de alguno de estos proyectos de Data Mart, se ve como más adecuado para el futuro este enfoque "divide y vencerás", previéndose una inversión de estos papeles y duplicando la implantación de Data Marts a los Data Warehouse.
Probablemente, el 5% de usuarios que disponen de tecnología de Data Warehouse y piensan renunciar a ella en el futuro, no han realizado previamente un estudio de factores implicados en un Data Warehouse, o han pasado por la situación inicial de partida, y no se han planteado una reorganización del mismo.
Componentes a tener en cuenta a la hora de construir un Data Warehouse
Componentes a tener en cuenta a la hora de construir un Data Warehouse2.2.2.- COMPONENTES A TENER EN CUENTA A LA HORA DE CONSTRUIR UN DW
2.2.2.2.- Software de almacenamiento (SGBD)
2.2.2.3.- Software de extracción y manipulación de datos
2.2.2.4.- Herramientas Middleware
2.2.2.1.-Hardware
Un componente fundamental a la hora de poder contar con un Data Warehouse que responda a las necesidades analíticas avanzadas de los usuarios, es el poder contar con una infraestructura hardware que la soporte.
En este sentido son críticas, a la hora de evaluar uno u otro hardware, dos características principales:
Por un lado, a este tipo de sistemas suelen acceder pocos usuarios con unas necesidades muy grandes de información, a diferencia de los sistemas operacionales, con muchos usuarios y necesidades puntuales de información. Debido a la flexibilidad requerida a la hora de hacer consultas complejas e imprevistas, y al gran tamaño de información manejada, son necesarias unas altas prestaciones de la máquina.
Por otro lado, debido a que estos sistemas suelen comenzar con una funcionalidad limitada, que se va expandiendo con el tiempo (situación por cierto aconsejada), es necesario que los sistemas sean escalables para dar soporte a las necesidades crecientes de equipamiento. En este sentido, será conveniente el optar por una arquitectura abierta, que nos permita aprovechar lo mejor de cada fabricante.
En el mercado se han desarrollado tecnologías basadas en tecnología de procesamiento paralelo, dan el soporte necesario a las necesidades de altas prestaciones y escalabilidad de los Data Warehouse. Estas tecnologías son de dos tipos:
- SMP (Symmetric multiprocessing, o Multiprocesadores Simétricos): Los sistemas tienen múltiples procesadores que comparten un único bus y una gran memoria, repartiéndose los procesos que genera el sistema, siendo el sistema operativo el que gestiona esta distribución de tareas. Estos sistemas se conocen como arquitecturas de "casi todo compartido". El aspecto más crítico de este tipo de sistemas es el grado de rendimiento relativo respecto al número de procesadores presentes, debido a su creciente no lineal.
- MPP (Massively parallel processing, o Multiprocesadores Masivamente Paralelos): Es una tecnología que compite contra la SMP, en la que los sistemas suelen ser casi independientes comunicados por intercambiadores de alta velocidad que permiten gestionarlos como un único sistema. Se conocen por ello como arquitecturas de "nada compartido". Su escalabilidad es mayor que la de los SMP.
Según Meta Group, las tendencias de mercado indican que las arquitecturas SMP aportan normalmente suficientes características de escalabilidad, con una mayor oferta y un menor riesgo tecnológico. Sin embargo, cuando las condiciones de escalabilidad sean extremas, se puede plantear la opción MPP.
No obstante, se están produciendo avances significativos en arquitecturas SMP, que han logrado máquinas con un crecimiento lineal de rendimiento hasta un número de 64 procesadores.
Recomendamos desde estas páginas, la visita a la dirección Internet:
http://www.tpc.org/bench.results.html
en donde la Transaction Processing Council (de la que son miembros ALR, Amdahl, Bull, Compaq, Data General, Dell, Digital, Fujitsu, HP, IBM, Intergraph, NCR , Siemens-Nixdorf, Sun o Unisys), realiza una comparativa entre las máquinas de sus miembros, proporcionando para diferentes modelos y diferentes configuraciones de Sistemas Operativos y Software de Base de Datos, un análisis de rendimiento (throughput), y un resumen de características (precio, número de procesadores, arquitectura y futuras versiones y fecha de disponibilidad).
2.2.2.2.-Software de almacenamiento (SGBD)
Como hemos comentado, el sistema que gestione el almacenamiento de la información (Sistema de Gestión de Base de Datos o SGBD), es otro elemento clave en un Data Warehouse. Independientemente de que la información almacenada en el Data Warehouse se pueda analizar mediante visualización multidimensional, el SGBD puede estar realizado utilizando tecnología de Bases de Datos Relacionales o Multidimensionales.
Las bases de datos relacionales, se han popularizado en los sistemas operacionales, pero se han visto incapaces de enfrentarse a las necesidades de información de los entornos Data Warehouse. Por ello, y puesto que, como hemos comentado, las necesidades de información suelen atender a consultas multidimensionales, parece que unas Bases de Datos multidimensionales, parten con ventaja. En este sentido son de aplicación los comentarios que realizamos en el apartado de hardware, por requerimientos de prestaciones, escalabilidad y consolidación tecnológica.
Al igual que en el hardware, nuevos diseños de las bases de datos relacionales, las bases de datos post-relacionales, abren un mayor abanico de elección. Estas bases de datos post-relacionales, parten de una tecnología consolidada y dan respuesta al agotamiento de las posibilidades de los sistemas de gestión de bases de datos relacionales, ofreciendo las mismas prestaciones aunque implantadas en una arquitectura diseñada de forma más eficiente.
Esta mayor eficiencia se consigue instaurando relaciones lógicas en vez de físicas, lo que hace que ya no sea necesario destinar más hardware a una solución para conseguir la ejecución de las funciones requeridas. El resultado es que la misma aplicación implantada en una BD post-relacional requiere menos hardware, puede dar servicio a un mayor número de usuarios y utilizar mecanismos intensivos de acceso a los datos más complejos. Asimismo, esta tecnología permite combinar las ventajas de las bases de datos jerárquicas y las relacionales con un coste más reducido. Ambos sistemas aportan como ventaja que no resulta necesario disponer de servidores omnipotentes, sin que puede partirse de un nivel de hardware modesto y ampliarlo a medida que crecen las necesidades de información de la compañía y el uso efectivo del sistema.
Dejamos fuera del ámbito de esta guía el detallar cómo los proveedores de bases de datos han optimizado los accesos a los índices, o las nuevas posibilidades que ofrece la compresión de datos (menos espacio para la misma información lo que implica, entre otras ventajas, que más información se puede tener en caché), para lo que remitimos a la prensa especializada o a las publicaciones de los fabricantes.
2.2.2.3.- Software de extracción y manipulación de datos
En este apartado analizaremos un componente esencial a la hora de implantar un Data Warehouse, la extracción y manipulación. Para esta labor, que entra dentro del ámbito de los profesionales de tecnologías de la información, es crítico el poder contar con herramientas que permitan controlar y automatizar los continuos "mimos" y necesidades de actualización del Data Warehouse.
Estas herramientas deberán proporcionar las siguientes funcionalidades:
- Control de la extracción de los datos y su automatización, disminuyendo el tiempo empleado en el descubrimiento de procesos no documentados, minimizando el margen de error y permitiendo mayor flexibilidad.
- Acceso a diferentes tecnologías, haciendo un uso efectivo del hardware, software, datos y recursos humanos existentes.
- Proporcionar la gestión integrada del Data Warehouse y los Data Marts existentes, integrando la extracción, transformación y carga para la construcción del Data Warehouse corporativo y de los Data Marts.
- Uso de la arquitectura de metadatos, facilitando la definición de los objetos de negocio y las reglas de consolidación.
- Acceso a una gran variedad de fuentes de datos diferentes.
- Manejo de excepciones.
- Planificación, logs, interfaces a schedulers de terceros.
- Interfaz independiente de hardware.
- Soporte en la explotación del Data Warehouse.
A veces, no se suele prestar la suficiente atención a esta fase de la gestión del Data Warehouse, aun cuando supone una gran parte del esfuerzo en la construcción de un Data Warehouse. Existen multitud de herramientas disponibles en el mercado que automatizan parte del trabajo, para lo cual recomendamos la visita a la página Internet:
http://pwp.starnetinc.com/larryg/clean.html
en la que se proporciona una lista de mas de 100 herramientas de extracción y manipulación de datos, con links a sus páginas Internet, y una somera descripción de la funcionalidad cubierta por cada herramienta.
2.2.2.4.- Herramientas Middleware
Como herramientas de soporte a la fase de gestión de un Data Warehouse, analizaremos a continuación dos tipos de herramientas:
- Por un lado herramientas Middleware, que provean conectividad entre entornos diferentes, para ayudar en la gestión del Data Warehouse.
- Por otro, analizadores y aceleradores de consultas, que permitan optimizar tiempos de respuestas en las necesidades analíticas, o de carga de los diferentes datos desde los sistemas operacionales hasta el Data Warehouse.
Las herramientas Middleware deben ser escalables siendo capaces de crecer conforme crece el Data Warehouse, sin problemas de volúmenes. Tambien deben ser flexibles y robustas, sin olvidarse de proporcionar un rendimiento adecuado. Estarán abiertas a todo tipos de entornos de almacenamiento de datos, tanto mediante estándares de facto (OLE, ODBC, etc.), como a los tipos de mercado más populares (DB2, Access, etc.). La conectividad, al menos en estándares de transporte (SNA LU6.2, DECnet, etc.) debe estar tambien asegurada.
Con el uso de estas herramientas de Middleware lograremos:
- Maximizar los recursos ejecutando las aplicaciones en la plataforma más adecuada.
- Integrar los datos y aplicaciones existentes en una plataforma distribuida.
- Automatizar la distribución de datos y aplicaciones desde un sistema centralizado.
- Reducir tráfico en la red, balanceando los niveles de cliente servidor (mas o menos datos en local, mas o menos proceso en local).
- Explotar las capacidades de sistemas remotos sin tener que aprender multiples entornos operativos.
- Asegurar la escalabilidad del sistema.
- Desarrollar aplicaciones en local y explotarlas en el servidor.
Los analizadores y aceleradores de querys trabajan volcando sobre un fichero de log las consultas ejecutadas y datos asociados a las mismas (tiempo de respuesta, tablas accedidas, método de acceso, etc). Este log se analiza, bien automáticamente o mediante la supervisión del administrador de datos, para mejorar los tiempos de accesos.
Estos sistemas de monitorización se pueden implementar en un entorno separado de pruebas, o en el entorno real. Si se ejecutan sobre un entorno de pruebas, el rendimiento del entorno real no se vé afectado. Sin embargo, no es posible optimizar los esfuerzos, puesto que los análisis efectuados pueden realizarse sobre consultas no críticas o no frecuentemente realizadas por los usuarios.
El implantar un sistema analizador de consultas, en el entorno real tiene además una serie de ventajas tales como:
- Se pueden monitorizar los tiempos de respuesta del entorno real.
- Se pueden implantar mecanismos de optimización de las consultas, reduciendo la carga del sistema.
- Se puede imputar costes a los usuarios por el coste del Data Warehouse.
- Se pueden implantar mecanismos de bloqueo para las consultas que vayan a implicar un tiempo de respuesta excesivo.
Fases de implantación de un Data Warehouse
Fases de implantación de un Data Warehouse2.2.3.- FASES DE IMPLANTACIÓN DE UN DATA WAREHOUSE
Tal y como aparecía en un artículo en ComputerWorld: "Un Data Warehouse no se puede comprar, se tiene que construir". Como hemos mencionado con anterioridad, la construcción e implantación de un Data Warehouse es un proceso evolutivo.
Este proceso se tiene que apoyar en una metodología específica para este tipo de procesos, si bien es más importante que la elección de la mejor de las metodologías, el realizar un control para asegurar el seguimiento de la misma.
En las fases que se establezcan en el alcance del proyecto es fundamental el incluir una fase de formación en la herramienta utilizada para un máximo aprovechamiento de la aplicación. El seguir los pasos de la metodología y el comenzar el Data Warehouse por un área específica de la empresa, nos permitirá obtener resultados tangibles en un corto espacio de tiempo.
Planteamos aquí la metodología propuesta por SAS Institute: la "Rapid Warehousing Methodology". Dicha metodología es iterativa, y está basada en el desarrollo incremental del proyecto de Data Warehouse dividido en cinco fases:
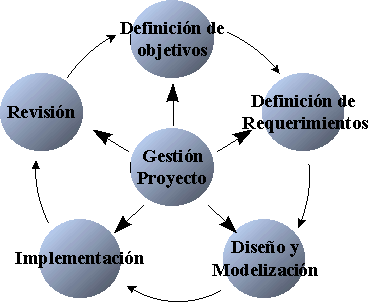
- Definición de los objetivos
- Definición de los requerimientos de información
- Diseño y modelización
- Implementación
- Revisión
2.2.3.1-Definición de los objetivos
2.2.3.2.-Definición de los requerimientos de información
Tal como sucede en todo tipo de proyectos, sobre todo si involucran técnicas novedosas como son las relativas al Data Warehouse, es analizar las necesidades y hacer comprender las ventajas que este sistema puede reportar.
Es por ello por lo que nos remitimos al apartado de esta guía de Análisis de las necesidades del comprador. Será en este punto, en donde detallaremos los pasos a seguir en un proyecto de este tipo, en donde el usuario va a jugar un papel tan destacado.
2.2.3.3.-Diseño y modelización
Los requerimientos de información identificados durante la anterior fase proporcionarán las bases para realizar el diseño y la modelización del Data Warehouse.
En esta fase se identificarán las fuentes de los datos (sistema operacional, fuentes externas,..) y las transformaciones necesarias para, a partir de dichas fuentes, obtener el modelo lógico de datos del Data Warehouse. Este modelo estará formado por entidades y relaciones que permitirán resolver las necesidades de negocio de la organización.
El modelo lógico se traducirá posteriormente en el modelo físico de datos que se almacenará en el Data Warehouse y que definirá la arquitectura de almacenamiento del Data Warehouse adaptándose al tipo de explotación que se realice del mismo.
La mayor parte estas definiciones de los datos del Data Warehouse estarán almacenadas en los metadatos y formarán parte del mismo.
La implantación de un Data Warehouse lleva implícitos los siguientes pasos:
- Extracción de los datos del sistema operacional y transformación de los mismos.
- Carga de los datos validados en el Data Warehouse. Esta carga deberá ser planificada con una periodicidad que se adaptará a las necesidades de refresco detectadas durante las fases de diseño del nuevo sistema.
- Explotación del Data Warehouse mediante diversas técnicas dependiendo del tipo de aplicación que se de a los datos:
Query & Reporting
On-line analytical processing (OLAP)
Executive Information System (EIS) ó Información de gestión
Decision Support Systems (DSS)
Visualización de la información
Data Mining ó Minería de Datos, etc.
La información necesaria para mantener el control sobre los datos se almacena en los metadatos técnicos (cuando describen las características físicas de los datos) y de negocio (cuando describen cómo se usan esos datos). Dichos metadatos deberán ser accesibles por los usuarios finales que permitirán en todo momento tanto al usuario, como al administrador que deberá además tener la facultad de modificarlos según varíen las necesidades de información.
Con la finalización de esta fase se obtendrá un Data Warehouse disponible para su uso por parte de los usuarios finales y el departamento de informática.
La construcción del Data Warehouse no finaliza con la implantación del mismo, sino que es una tarea iterativa en la que se trata de incrementar su alcance aprendiendo de las experiencias anteriores.
Después de implantarse, debería realizarse una revisión del Data Warehouse planteando preguntas que permitan, después de los seis o nueve meses posteriores a su puesta en marcha, definir cuáles serían los aspectos a mejorar o potenciar en función de la utilización que se haga del nuevo sistema.
2.2.3.6.-Diseño de la estructura de cursos de formación
Con la información obtenida de reuniones con los distintos usuarios se diseñarán una serie de cursos a medida, que tendrán como objetivo el proporcionar la formación estadística necesaria para el mejor aprovechamiento de la funcionalidad incluida en la aplicación. Se realizarán prácticas sobre el desarrollo realizado, las cuales permitirán fijar los conceptos adquiridos y servirán como formación a los usuarios.
Estrategias de implantación de un Data Warehouse
Estrategias de implantación de un Data Warehouse2.2.4.- ESTRATEGIAS DE IMPLANTACIÓN
Resaltamos en esta guía algunas consideraciones que recomendamos deben seguirse a la hora de abordar un proyecto de este tipo:
"La Base de Datos de Riesgos debe estar separada de las Bases de Datos Operacionales" con objeto de no interferir en la actividad del día a día, disponiendo de la información necesaria para Riesgos (interna y externa) y en un entorno orientado hacia la consulta y el análisis (Data Warehouse).
"Concepción del sistema como un conjunto de herramientas de análisis", debido a que las actividades de Análisis de Riesgos no se pueden automatizar completamente, puesto que requieren análisis y decisiones del usuario.
"Diseño del sistema no orientado a procesos"; se debe disponer de un conjunto abierto de herramientas que se utilizan con propósitos determinados no relacionados con las necesidades operativas.
"Abordar el sistema con un enfoque de desarrollo gradual", se debe comenzar con un esqueleto básico de funcionalidad y datos que produzcan resultados a corto plazo y permita aprender en la práctica, y a continuación ir configurando progresivamente nuevas funcionalidades conforme la experiencia lo vaya requiriendo.
Son de aplicación en este apartado las consideraciones que realizamos en los apartados Data Warehouse vs. Data Marts y Fases de Implantación de un Data Warehouse.
Técnicas de explotación de la implantación de un Data Warehouse
Técnicas de explotación de la implantación de un Data Warehouse2.2.5.-TÉCNICAS DE EXPLOTACIÓN DE LA IMPLANTACIÓN
2.2.5.- Introducción
2.2.5.3.- Data Mining o Minería de Datos
Introducción
Dentro del esquema de Gestión y Explotación del Data Warehouse que se muestra en el gráfico, pasamos a detallar las posibilidades que nos ofrece esta última fase.
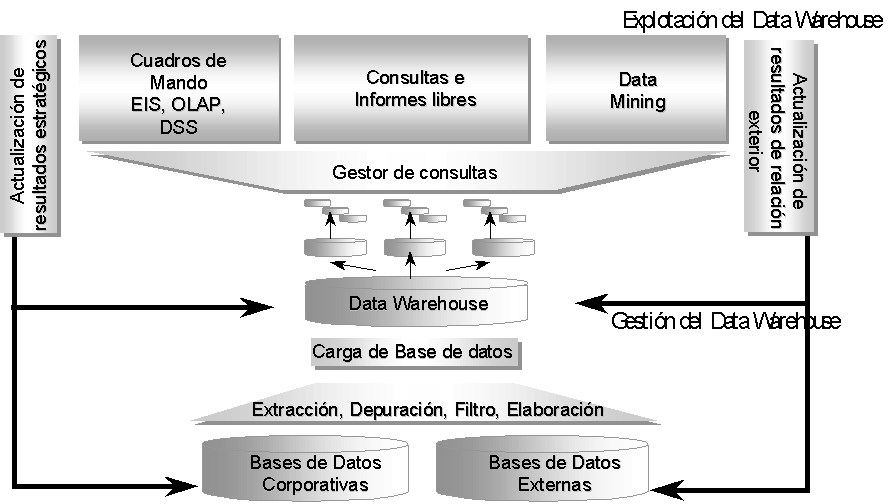
En ella, examinaremos
- el uso que se puede realizar de las utilidades OLAP del Data Warehouse para análisis multidimensionales,
- las facilidades de obtención de información mediante consultas e informes libre, y el uso de técnicas de Data Mining que nos permitan descubrir "información oculta" en los datos mediante el uso de técnicas estadísticas.

OLAP, MOLAP y ROLAP
OLAP, MOLAP y ROLAP2.2.5.1.- OLAP, ROLAP, MOLAP
2.2.5.1.3.- ROLAP vs. MOLAP (Comparativa)
Introducción.-
La explotación del Data Warehouse mediante información de gestión, se fundamenta básicamente en los niveles agrupados o calculados de información.
La información de gestión se compone de conceptos de información y coeficientes de gestión, que los cuadros directivos de la empresa pueden consultar según las dimensiones de negocio que se definan.
Dichas dimensiones de negocio se estructuran a su vez en distintos niveles de detalle (por ejemplo, la dimensión geográfica puede constar de los niveles nacional, provincial, ayuntamientos y sección censal).
Este tipo de sistemas ha existido desde hace tiempo, en el mundo de la informática bajo distintas denominaciones: cuadros de mando, MIS, EIS, etc.
Su realización fuera del entorno del Data Warehouse, puede repercutir sobre estos sistemas en una mayor rigidez, dificultad de actualización y mantenimiento, malos tiempos de respuesta, incoherencias de la información, falta del dato agregado, etc.
Los sistemas de soporte a la decisión usando tecnologías de Data Warehouse, se llaman sistemas OLAP (siglas de On Line Analytical Processing (OLAP). En general, estos sistemas OLAP deben:
- Soportar requerimientos complejos de análisis
- Analizar datos desde diferentes perspectivas
- Soportar análisis complejos contra un volumen ingente de datos
La funcionalidad de los sistemas OLAP se caracteriza por ser un análisis multidimensional de datos corporativos, que soportan los análisis del usuario y unas posibilidades de navegación, seleccionando la información a obtener.
Normalmente este tipo de selecciones se ve reflejada en la visualización de la estructura multidimensional, en unos campos de selección que nos permitan elegir el nivel de agregación (jerarquía) de la dimensión, y/o la elección de un dato en concreto, la visualización de los atributos del sujeto, frente a una(s) dimensiones en modo tabla, pudiendo con ello realizar, entre otras las siguientes acciones:
Rotar (Swap): 		alterar las filas por columnas (permutar dos dimensiones de análisis)
Bajar (Down): 		bajar el nivel de visualización en las filas a una jerarquía inferior
Detallar (Drilldown): 	informar para una fila en concreto, de datos a un nivel inferior
Expandir (Expand): 	id. anterior sin perder la información a nivel superior para éste y el resto de los valores
Colapsar (Collapse): 	operación inversa de la anterior.
Para ampliar el glosario sobre exploraciones en análisis OLAP, recomendamos la visita a la página Internet:
http://www.kenan.com/acumate/olaptrms.htm
en donde se describen en torno a 50 términos relacionados con las posibilidades de navegación que permiten este tipo de análisis.
Existen dos arquitecturas diferentes para los sistemas OLAP: OLAP multidimensional (MOLAP) y OLAP relacionales (ROLAP).
2.2.5.1.1.-Sistemas MOLAP
La arquitectura MOLAP usa unas bases de datos multidimensionales para proporcionar el análisis, su principal premisa es que el OLAP está mejor implantado almacenando los datos multidimensionalmente. Por el contrario, la arquitectura ROLAP cree que las capacidades OLAP están perfectamente implantadas sobre bases de datos relacionales
Un sistema MOLAP usa una base de datos propietaria multidimensional, en la que la información se almacena multidimensionalmente, para ser visualizada multidimensionalmente.
El sistema MOLAP utiliza una arquitectura de dos niveles: La bases de datos multidimensionales y el motor analítico.
- La base de datos multidimensional es la encargada del manejo, acceso y obtención del dato.
- El nivel de aplicación es el responsable de la ejecución de los requerimientos OLAP. El nivel
de presentación se integra con el de aplicación y proporciona un interfaz a través del cual
los usuarios finales visualizan los análisis OLAP. Una arquitectura cliente/servidor permite a varios usuarios
acceder a la misma base de datos multidimensional.
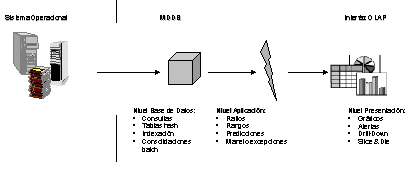
La información procedente de los sistemas operacionales, se carga en el sistema MOLAP, mediante una serie de rutinas batch. Una vez cargado el dato elemental en la Base de Datos multidimensional (MDDB), se realizan una serie de cálculos en batch, para calcular los datos agregados, a través de las dimensiones de negocio, rellenando la estructura MDDB.
Tras rellenar esta estructura, se generan unos índices y algoritmos de tablas hash para mejorar los tiempos de accesos a las consultas.
Una vez que el proceso de compilación se ha acabado, la MDDB está lista para su uso. Los usuarios solicitan informes a través del interface, y la lógica de aplicación de la MDDB obtiene el dato.
La arquitectura MOLAP requiere unos cálculos intensivos de compilación. Lee de datos precompilados, y tiene capacidades limitadas de crear agregaciones dinámicamente o de hallar ratios que no se hayan precalculados y almacenados previamente.
2.2.5.1.2.-Sistemas ROLAP
La arquitectura ROLAP, accede a los datos almacenados en un Data Warehouse para proporcionar los análisis OLAP. La premisa de los sistemas ROLAP es que las capacidades OLAP se soportan mejor contra las bases de datos relacionales.
El sistema ROLAP utiliza una arquitectura de tres niveles. La base de datos relacional maneja los requerimientos de almacenamiento de datos, y el motor ROLAP proporciona la funcionalidad analítica.
- El nivel de base de datos usa bases de datos relacionales para el manejo, acceso y obtención del dato.
- El nivel de aplicación es el motor que ejecuta las consultas multidimensionales de los usuarios.
- El motor ROLAP se integra con niveles de presentación, a través de los cuales los usuarios realizan
los análisis OLAP.
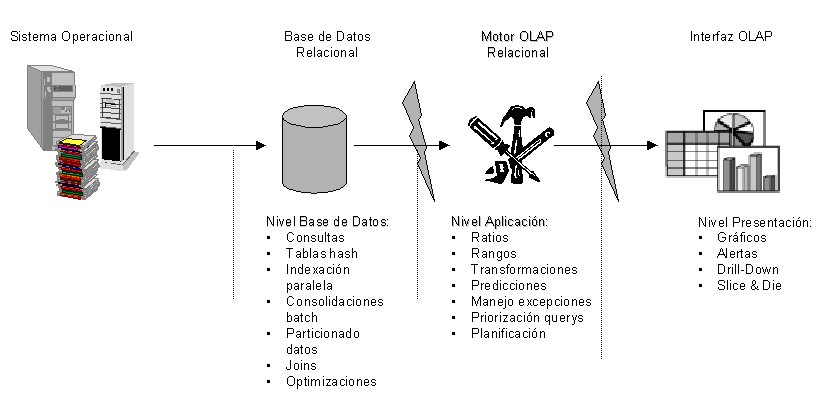
Después de que el modelo de datos para el Data Warehouse se ha definido, los datos se cargan desde el sistema operacional. Se ejecutan rutinas de bases de datos para agregar el dato, si así es requerido por el modelos de datos.
Se crean entonces los índices para optimizar los tiempos de acceso a las consultas.
Los usuarios finales ejecutan sus análisis multidimensionales, a través del motor ROLAP, que transforma dinámicamente sus consultas a consultas SQL. Se ejecutan estas consultas SQL en las bases de datos relacionales, y sus resultados se relacionan mediante tablas cruzadas y conjuntos multidimensionales para devolver los resultados a los usuarios.
La arquitectura ROLAP es capaz de usar datos precalculados si estos están disponibles, o de generar dinámicamente los resultados desde los datos elementales si es preciso. Esta arquitectura accede directamente a los datos del Data Warehouse, y soporta técnicas de optimización de accesos para acelerar las consultas. Estas optimizaciones son, entre otras, particionado de los datos a nivel de aplicación, soporte a la desnormalización y joins múltiples.
2.2.5.1.3.-ROLAP vs. MOLAP (Comparativa)
Cuando se comparan las dos arquitecturas, se pueden realizar las siguientes observaciones:
- El ROLAP delega la negociación entre tiempo de respuesta y el proceso batch al diseño del sistema.
Mientras, el MOLAP, suele requerir que sus bases de datos se precompilen para conseguir un rendimiento aceptable
en las consultas, incrementando, por tanto los requerimientos batch. - Los sistemas con alta volatilidad de los datos (aquellos en los que cambian las reglas de agregación
y consolidación), requieren una arquitectura que pueda realizar esta consolidación ad-hoc. Los sistemas
ROLAP soportan bien esta consolidación dinámica, mientras que los MOLAP están más orientados
hacia consolidaciones batch. - Los ROLAP pueden crecer hasta un gran número de dimensiones, mientras que los MOLAP generalmente son
adecuados para diez o menos dimensiones. - Los ROLAP soportan análisis OLAP contra grandes volúmenes de datos elementales, mientras que
los MOLAP se comportan razonablemente en volúmenes más reducidos (menos de 5 Gb)
Por ello, y resumiendo, el ROLAP es una arquitectura flexible y general, que crece para dar soporte a amplios requerimientos OLAP. El MOLAP es una solución particular, adecuada para soluciones departamentales con unos volúmenes de información y número de dimensiones más modestos.
Query y reporting en un Data Warehouse
Query y reporting en un Data Warehouse2.2.5.2.- QUERY & REPORTING
Las consultas o informes libres trabajan tanto sobre el detalle como sobre las agregaciones de la información.
Realizar este tipo de explotación en un almacén de datos supone una optimización del tradicional entorno de informes (reporting), dado que el Data Warehouse mantiene una estructura y una tecnología mucho más apropiada para este tipo de solicitudes.
Los sistemas de "Query & Reporting", no basados en almacenes de datos se caracterizan por la complejidad de las consultas, los altísimos tiempos de respuesta y la interferencia con otros procesos informáticos que compartan su entorno.
La explotación del Data Warehouse mediante "Query & Reporting" debe permitir una gradación de la flexibilidad de acceso, proporcional a la experiencia y formación del usuario. A este respecto, se recomienda el mantenimiento de al menos tres niveles de dificultad:
- Los usuarios poco expertos podrán solicitar la ejecución de informes o consultas predefinidas según unos parámetros predeterminados.
- Los usuarios con cierta experiencia podrán generar consultas flexibles mediante una aplicación que proporcione una interfaz gráfica de ayuda.
- Los usuarios altamente experimentados podrán escribir, total o parcialmente, la consulta en un lenguaje de interrogación de datos.
Hay una extensa gama de herramientas en el mercado para cumplir esta funcionalidad sobre entornos de tipo Data Warehouse, por lo que se puede elegir el software más adecuado para cada problemática empresarial concreta.
Minería de datos
Minería de datos2.2.5.3.- DATA MINING O MINERÍA DE DATOS
2.2.5.3.2.- Técnicas de Data Mining
2.2.5.3.3.- Metodología de aplicación
2.2.5.3.1.-Introducción
El Data Mining es un proceso que, a través del descubrimiento y cuantificación de relaciones predictivas en los datos, permite transformar la información disponible en conocimiento útil de negocio. Esto es debido a que no es suficiente "navegar" por los datos para resolver los problemas de negocio, sino que se hace necesario seguir una metodología ordenada que permita obtener rendimientos tangibles de este conjunto de herramientas y técnicas de las que dispone el usuario.
Constituye por tanto una de las vías clave de explotación del Data Warehouse, dado que es este su entorno natural de trabajo.
Se trata de un concepto de explotación de naturaleza radicalmente distinta a la de los sistemas de información de gestión, dado que no se basa en coeficientes de gestión o en información altamente agregada, sino en la información de detalle contenida en el almacén. Adicionalmente, el usuario no se conforma con la mera visualización de datos, sino que trata de obtener una relación entre los mismos que tenga repercusiones en su negocio.
2.2.5.3.2.Técnicas de Data Mining
Para soportar el proceso de Data Mining, el usuario dispone de una extensa gama de técnicas que le pueden ayudar en cada una de las fases de dicho proceso, las cuales pasamos a describir:
Análisis estadístico:
Utilizando las siguientes herramientas:
- ANOVA: o Análisis de la Varianza, contrasta si existen diferencias significativas entre las medidas de una o más variables continuas en grupo de población distintos.
- Regresión: define la relación entre una o más variables y un conjunto de variables predictoras de las primeras.
- Ji cuadrado: contrasta la hipótesis de independencia entre variables.
- Componentes principales: permite reducir el número de variables observadas a un menor número de variables artificiales, conservando la mayor parte de la información sobre la varianza de las variables.
- Análisis cluster: permite clasificar una población en un número determinado de grupos, en base a semejanzas y desemejanzas de perfiles existentes entre los diferentes componentes de dicha población.
- Análisis discriminante: método de clasificación de individuos en grupos que previamente se han establecido, y que permite encontrar la regla de clasificación de los elementos de estos grupos, y por tanto identificar cuáles son las variables que mejor definan la pertenencia al grupo.
Métodos basados en árboles de decisión:
El método Chaid (Chi Squared Automatic Interaction Detector) es un análisis que genera un árbol de decisión para predecir el comportamiento de una variable, a partir de una o más variables predictoras, de forma que los conjuntos de una misma rama y un mismo nivel son disjuntos. Es útil en aquellas situaciones en las que el objetivo es dividir una población en distintos segmentos basándose en algún criterio de decisión.
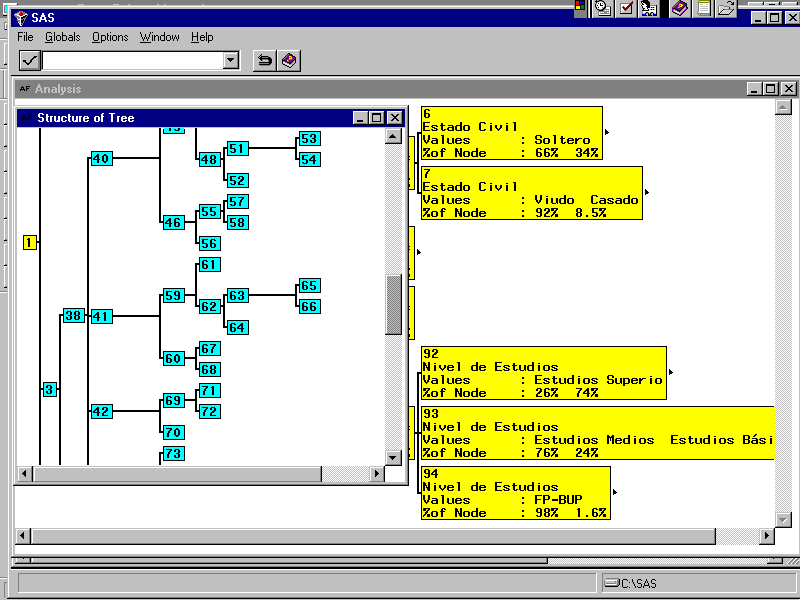
El árbol de decisión se construye partiendo el conjunto de datos en dos o más subconjuntos de observaciones a partir de los valores que toman las variables predictoras. Cada uno de estos subconjuntos vuelve después a ser particionado utilizando el mismo algoritmo. Este proceso continúa hasta que no se encuentran diferencias significativas en la influencia de las variables de predicción de uno de estos grupos hacia el valor de la variable de respuesta.
La raíz del árbol es el conjunto de datos íntegro, los subconjuntos y los subsubconjuntos conforman las ramas del árbol. Un conjunto en el que se hace una partición se llama nodo.
El número de subconjuntos en una partición puede ir de dos hasta el número de valores distintos que puede tomar la variable usada para hacer la separación. La variable de predicción usada para crear una partición es aquella más significativamente relacionada con la variable de respuesta de acuerdo con test de independencia de la Chi cuadrado sobre una tabla de contingencia.
Algoritmos genéticos:
Son métodos numéricos de optimización, en los que aquella variable o variables que se pretenden optimizar junto con las variables de estudio constituyen un segmento de información. Aquellas configuraciones de las variables de análisis que obtengan mejores valores para la variable de respuesta, corresponderán a segmentos con mayor capacidad reproductiva. A través de la reproducción, los mejores segmentos perduran y su proporción crece de generación en generación. Se puede además introducir elementos aleatorios para la modificación de las variables (mutaciones). Al cabo de cierto número de iteraciones, la población estará constituida por buenas soluciones al problema de optimización.
Redes neuronales:
Genéricamente son métodos de proceso numérico en paralelo, en el que las variables interactúan mediante transformaciones lineales o no lineales, hasta obtener unas salidas. Estas salidas se contrastan con los que tenían que haber salido, basándose en unos datos de prueba, dando lugar a un proceso de retroalimentación mediante el cual la red se reconfigura, hasta obtener un modelo adecuado.
Lógica difusa:
Es una generalización del concepto de estadística. La estadística clásica se basa en la teoría de probabilidades, a su vez ésta en la técnica conjuntista, en la que la relación de pertenencia a un conjunto es dicotómica (el 2 es par o no lo es). Si establecemos la noción de conjunto borroso como aquel en el que la pertenencia tiene una cierta graduación (¿un día a 20ºC es caluroso?), dispondremos de una estadística más amplia y con resultados más cercanos al modo de razonamiento humano.
Series temporales:
Es el conocimiento de una variable a través del tiempo para, a partir de ese conocimiento, y bajo el supuesto de que no van a producirse cambios estructurales, poder realizar predicciones. Suelen basarse en un estudio de la serie en ciclos, tendencias y estacionalidades, que se diferencian por el ámbito de tiempo abarcado, para por composición obtener la serie original. Se pueden aplicar enfoques híbridos con los métodos anteriores, en los que la serie se puede explicar no sólo en función del tiempo sino como combinación de otras variables de entorno más estables y, por lo tanto, más fácilmente predecibles.
2.2.5.3.3. Metodología de aplicación:
Para utilizar estas técnicas de forma eficiente y ordenada es preciso aplicar una metodología estructurada, al proceso de Data Mining. A este respecto proponemos la siguiente metodología, siempre adaptable a la situación de negocio particular a la que se aplique:
Muestreo
Extracción de la población muestral sobre la que se va a aplicar el análisis. En ocasiones se trata de una muestra aleatoria, pero puede ser también un subconjunto de datos del Data Warehouse que cumplan unas condiciones determinadas. El objeto de trabajar con una muestra de la población en lugar de toda ella, es la simplificación del estudio y la disminución de la carga de proceso. La muestra más óptima será aquella que teniendo un error asumible contenga el número mínimo de observaciones.
En el caso de que se recurra a un muestreo aleatorio, se debería tener la opción de elegir
- El nivel de confianza de la muestra (usualmente el 95% o el 99%).
- El tamaño máximo de la muestra (número máximo de registros), en cuyo caso el sistema deberá informar del el error cometido y la representatividad de la muestra sobre la población original.
- El error muestral que está dispuesto a cometer, en cuyo caso el sistema informará del número de observaciones que debe contener la muestra y su representatividad sobre la población original.
Para facilitar este paso s debe disponer de herramientas de extracción dinámica de información con o sin muestreo (simple o estratificado). En el caso del muestreo, dichas herramientas deben tener la opción de, dado un nivel de confianza, fijar el tamaño de la muestra y obtener el error o bien fijar el error y obtener el tamaño mínimo de la muestra que nos proporcione este grado de error.
Exploración
Una vez determinada la población que sirve para la obtención del modelo se deberá determinar cuales son las variables explicativas que van a servir como "inputs" al modelo. Para ello es importante hacer una exploración por la información disponible de la población que nos permita eliminar variables que no influyen y agrupar aquellas que repercuten en la misma dirección.
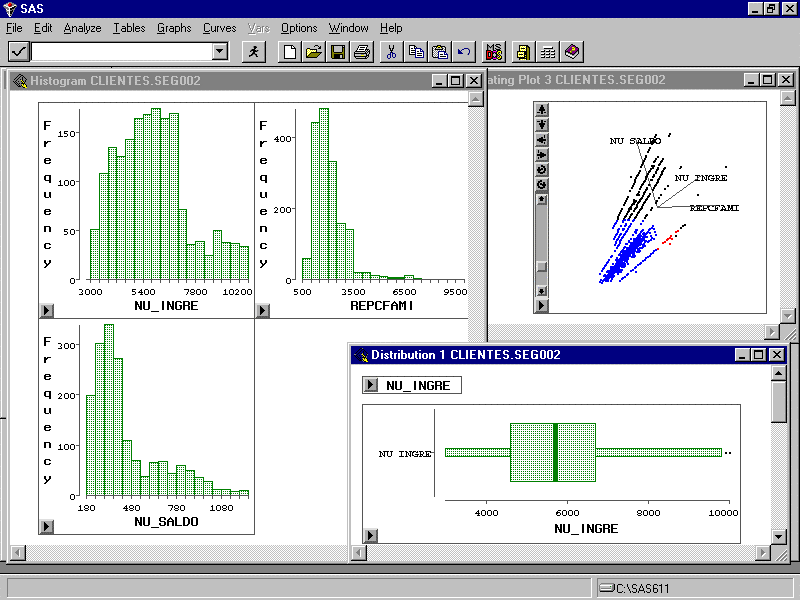
El objetivo es simplificar en lo posible el problema con el fin de optimizar la eficiencia del modelo. En este paso se pueden emplear herramientas que nos permitan visualizar de forma gráfica la información utilizando las variables explicativas como dimensiones.
También se pueden emplear técnicas estadísticas que nos ayuden a poner de manifiesto relaciones entre variables. A este respecto resultará ideal una herramienta que permita la visualización y el análisis estadístico integrados
Manipulación
Tratamiento realizado sobre los datos de forma previa a la modelización, en base a la exploración realizada, de forma que se definan claramente los inputs del modelo a realizar (selección de variables explicativas, agrupación de variables similares, etc.).
Modelización
Permite establecer una relación entre las variables explicativas y las variables objeto del estudio, que posibilitan inferir el valor de las mismas con un nivel de confianza determinado.
Valoración
Análisis de la bondad del modelo contrastando con otros métodos estadísticos o con nuevas poblaciones muestrales.
Webhousing
Webhousing2.2.5.4.- WEBHOUSING
La popularización de Internet y la tecnología Web, ha creado un nuevo esquema de información en el cual los clientes tienen a su disposición unas cantidades ingentes de información. La integración de las tecnologías Internet y Data Warehouse tienen una serie de ventajas como son:
- Consistencia: toda la organización accede al mismo conjunto de datos y ve los informes que reflejan
sus necesidades. Hay una "única versión de la verdad". - Accesibilidad: la empresa acede a la información a través de un camino común (el browser
de Internet), simplificando el proceso de búsqueda de la información. - Disponibilidad: la información es accesible en todo momento, independientemente de los sistemas operacionales.
- Bajos costes de desarrollo y mantenimiento, debidos a la estandarización de las aplicaciones de consultas
basadas en Internet, independientemente del sistema operativo que soporte el browser, y de la reducción
de los costes de distribución de software en los puestos clientes. - Protección de los datos, debido al uso de tecnologías consolidadas de protección en entornos
de red (firewalls). - Bajos costes de formación, debido al uso de interfaces tipo Web.
La interactividad de las aplicaciones en este entorno pueden tener varios niveles:
- Publicación de datos: las páginas distribuyen información obtenida del Data Warehouse,
volcada en las páginas intra/internet. - Distribución de reportes: dando soporte a consultas simples elaboradas por los usuarios.
- Aplicaciones dinámicas: sirviendo de soporte de decisión a servicios solicitados desde el puesto
cliente, ejecutando la petición en el servidor y devolviéndolas al cliente, vía el browser
de Internet o haciendo uso de "applets" de Java.
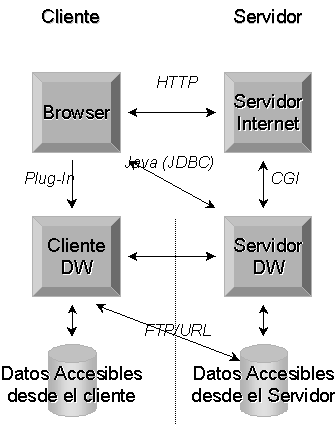
Las arquitecturas base de una implantación de Data Warehouse en Internet, pueden tener las siguientes
alternativas:
- Usar el Servidor Internet como router, y ejecutar la petición desde el cliente al servidor directamente.
- Hacer uso del navegador para visualizar una página Internet residente en el servidor de Internet. Esta
página contendría información que se actualizaría en el servidor Internet, desde el
servidor DW, a petición del usuario haciendo uso de CGI's. - El cliente podría lanzar su consulta directamente al servidor de DW, con "applets" de Java,
haciendo el servidor Internet únicamente de encaminamiento (router). - El cliente podría ejecutar la aplicación DW desde el navegador, pero con un plug-in, que haría
que se tuvieran las mismas opciones que la aplicación DW. - Realizar una descarga masiva de datos con un protocolo de transferencia de ficheros (FTP), para su proceso
en local.
El alcance funcional de la implantación del Data Warehouse, basado en tecnologías Internet, puede ser la misma que la realizada sin su uso. En este sentido las críticas que se le pueden achacar en la actualidad, provienen de la baja velocidad de las líneas actuales, que se solventa parcialmente mediante el uso de aplicaciones Java, en lugar de hacer uso de páginas HTML, o CGI. Solución parcial, mientras la velocidad de transferencia se incrementa día a día mediante nuevos algoritmos de compresión de datos o el uso de líneas de alta capacidad RDSI.
Tipos de aplicaciones donde utilizar técnicas de Data Warehouse
Tipos de aplicaciones donde utilizar técnicas de Data Warehouse2.2.6.- TIPOS DE APLICACIONES EN LAS QUE UTILIZAR LAS TÉCNICAS DISPONIBLES SOBRE EL DW
2.2.6.1.- Data Warehouse y Sistemas de Marketing
2.2.6.2.- Data Warehouse y Análisis de Riesgo Financiero
2.2.6.3.- Data Warehouse y Análisis de Riesgo de Crédito
2.2.6.4.- Data Warehouse: Otras Áreas de Aplicación
2.2.6.1. Data Warehouse y Sistemas de Marketing
La aplicación de tecnologías de Data Warehouse supone un nuevo enfoque de Marketing, haciendo uso del Marketing de Base de Datos. En efecto, un sistema de Marketing Warehouse implica un marketing científico, analítico y experto, basado en el conocimiento exhaustivo de clientes, productos, canales y mercado.
Este conocimiento se deriva de la disposición de toda la información necesaria, tanto interna como externa, en un entorno de Data Warehouse, persiguiendo con toda esta información, la optimización de las variables controladas del Marketing Mix y el soporte a la predicción de las variables no controlables (mediante técnicas de Data Mining). Basándose en el conocimiento exhaustivo de los clientes se consigue un tratamiento personalizado de los mismos tanto en el día a día (atención comercial) como en acciones de promoción específicas.
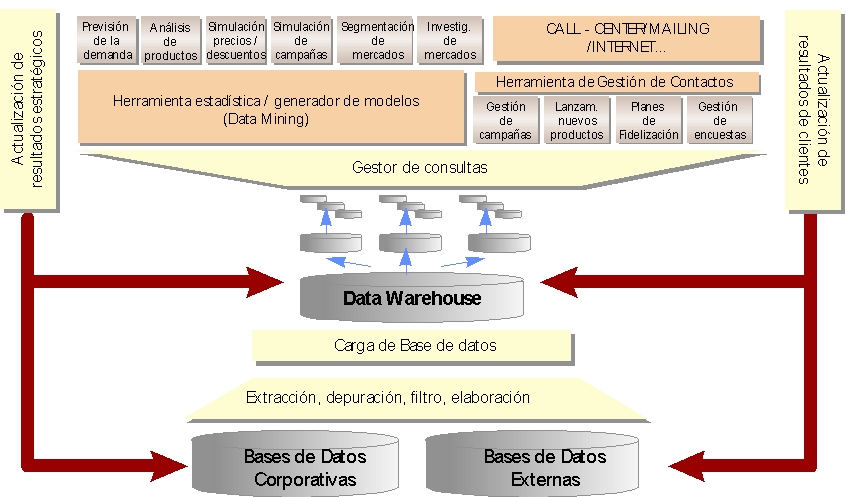
Las áreas en las que se puede aplicar las tecnologías de Data Warehouse a Marketing son, entre otras:
- Investigación Comercial
- Segmentación de mercados
- Identificación de necesidades no cubiertas y generación de nuevos productos, o modificación de productos existentes
- Fijación de precios y descuentos
- Definición de la estrategia de canales de comercialización y distribución
- Definición de la estrategia de promoción y atención al cliente
- Relación con el cliente:
- Programación, realización y seguimiento de acciones comerciales
- Lanzamiento de nuevos productos
- Campañas de venta cruzada, vinculación, fidelización, etc.
- Apoyo al canal de venta con información cualificada
2.2.6.2. Data Warehouse y Análisis de Riesgo Financiero
El Data Warehouse aplicado al análisis de riesgos financieros ofrece capacidades avanzadas de desarrollo de aplicaciones para dar soporte a las diversas actividades de gestión de riesgos. Es posible desarrollar cualquier herramienta utilizando las funciones que incorpora la plataforma, gracias a la potencionalidad estadística aplicada al riesgo de crédito.
Así se puede usar para llevar a cabo las siguientes funcionalidades:
- Para la gestión de la posición:
Determinación de la posición, Cálculo de sensibilidades, Análisis what/if, Simulaciones, Monitorización riesgos contra límites, etc.
- Para la medición del riesgo:
Soporte metodología RiskMetrics (Metodología registrada de J.P. Morgan / Reuters), Simulación de escenarios históricos, Modelos de covarianzas, Simulación de Montecarlo, Modelos de valoración, Calibración modelos valoración, Análisis de rentabilidad, Establecimiento y seguimiento. de límites, Desarrollo/modificación modelos, Stress testing, etc.
El uso del Data Warehouse ofrece una gran flexibilidad para creación o modificación de modelos propios de valoración y medición de riesgos, tanto motivados por cambios en la regulación, como en avances en la modelización de estos instrumentos financieros.
Ello por cuanto se puede almacenar y poner a disposición información histórica de mercado y el uso de técnicas de Data Mining nos simplifica la implantación de cualquier método estadístico. Los métodos de previsión, se pueden realizar usando series históricas, (GARCH, ARIMA, etc.)

Pero la explotación de la información nos permite no solo la exploración de los datos para un conocimiento de la información histórica, sino también para examinar condiciones de normalidad de las que la mayoría de las metodologías de valoración del riesgo parten.
Además de implantar modelos ya existentes, se pueden acometer análisis con vistas a determinar modelos propios, basados en análisis de correlación para el estudio de la valoración del riesgo de carteras o procesos de simulación de Montecarlo.
Todo ello en una plataforma avanzada de gestión de la información basada en la fácil visualización de la misma y de su análisis estadístico como soporte a metodologías estándar de facto, o a las particularidades de cada entorno.
2.2.6.3. Data Warehouse y Análisis de Riesgo de Crédito
La información relativa a clientes y su entorno se ha convertido en fuente de prevención de Riesgos de Crédito. En efecto, existe una tendencia general en todos los sectores a recoger, almacenar y analizar información crediticia como soporte a la toma de decisiones de Análisis de Riesgos de Crédito.
Los avances en la tecnología de Data Warehouse hacen posible la optimización de los sistemas de Análisis de Riesgo de Crédito:
Para la gestión del riesgo de crédito los sistemas operacionales han ofrecido:
- Sistemas de Información para Gerencia (MIS) e informes de Soporte a la Decisión de Problemas (DSS) estáticos y no abiertos a nuevas relaciones y orígenes de datos, situación en la que la incorporación de nuevas fuentes de información ha sido un problema en lugar de una ventaja.
- Exploraciones de datos e informes cerrados y estáticos.
- Análisis sin inclusión de consideraciones temporales lo que imposibilita el análisis del pasado y la previsión del futuro.
- Herramientas de credit-scoring no flexibles, construidas sobre algoritmos difícilmente modificables, no adaptados al entorno de la empresa, o exclusivamente basados en la experiencia personal no contrastada, con lo que los sistemas han ayudado a repetir los errores en vez de a corregirlos.
Pero estos sistemas tradicionales se enfrentan a una problemática difícil de resolver para acomodarse a las necesidades analíticas de los Sistemas de Análisis del Riesgo, necesidades que se pueden cubrir mediante el uso de tecnologías de Data Warehouse
Dentro de la Prevención de Impagados, utilizando sistemas OLAP se puede obtener el grado interno de concentración de riesgos con el cliente, y almacenar la variedad de fuentes internas o externas de información disponibles sobre el mismo. Ello nos permite obtener sin dificultad la posición consolidada respecto al riesgo del cliente. El análisis se puede realizar asimismo por las diferentes características de la operación para la que se realiza el análisis, en cuanto al plazo y la cuantía de la misma, la modalidad de crédito elegida, la finalidad de la operación o las garantías asociadas a la misma. Usando las mismas capacidades es fácil el establecer una segmentación ABC de la cartera de clientes potenciales o reales que nos optimicen el nivel de esfuerzo en el Análisis de Riesgos.
En el soporte al proceso de Anticipación al Riesgo, se puede dar un adecuado soporte a la correcta generación y consideración de señales de alerta, teniendo en cuenta las pautas y condicionantes diferenciados dependiendo del tipo de cliente y producto usando Data Mining
Para el caso del Seguimiento del ciclo de Impagados, de nuevo el uso de sistemas OLAP, simplifican el análisis la diversidad de los diferentes parámetros que intervienen en el mismo, tales como la jerarquía de centros de recobro a contemplar, la diferente consideración dependiendo de la antigüedad del impago, del cliente o del importe impagado. Un sistema de Data Mining puede aconsejar la mejor acción en caso de impagados, litigio, precontencioso, etc. frente a los parámetros de importe, antigüedad, zona geográfica, etc.
Estos sistemas hacen que el analista se dedique con más intensidad al análisis de la información, que es donde aporta su mayor valor añadido, que a la obtención de la misma. No obstante, estos sistemas deben de huir de las automatizaciones completas sin intervención del analista: es él el que mejor sabe lo que quiere descubrir. "La herramienta debe ser un medio y no un fin".
2.2.6.4. Data Warehouse: Otras áreas de aplicación
Otras áreas de la empresa han aplicado las soluciones que proporciona la tecnología Data Warehouse para mejorar gran parte de sus procesos actuales. Entre ellas destacamos:
- Control de Gestión:
Sistemas de Presupuestación, Análisis de Desviaciones, Reporting (EIS, MIS, etc.)
- Logística:
Mejora de la relación con proveedores, Racionalización de los procesos de control de inventarios, Optimización de los niveles de producción, Previsión de la demanda en infraestructura.
- Recursos Humanos
Planificación de incorporaciones, Gestión de carreras profesionales, Asignación de recursos a proyectos alternativos, etc.
Seguridad de acceso y manipulación de la información en el Data Warehouse
Seguridad de acceso y manipulación de la información en el Data Warehouse2.2.7.- SEGURIDAD DE ACCESO Y MANIPULACIÓN DE LA INFORMACIÓN EN EL DW
A continuación trataremos las consideraciones a contemplar en cuanto a seguridad de accesos y seguridad de datos (backup), puesto que si bien la seguridad de accesos (al nivel de datos y de aplicación) debe ser tratada de la misma manera que en los sistemas operacionales, los procedimientos de copias de seguridad merecen un especial tratamiento.
Tal y como ocurre en los sistemas operacionales, un sistema Data Warehouse debe poder realizar procedimientos de recuperación de la información desde cualquier momento en el que los datos estaban validados. Un Data Warehouse, debe poder contar con procedimientos de recuperación, que permitan recuperar los datos ante cualquier situación de catástrofe.
No obstante, es preciso tener en cuenta otras consideraciones, así por ejemplo dependiendo del tamaño de un Data Mart, se puede elegir no realizar un backup, sino realizar un refresco especial desde los datos operacionales, dependiendo de la periodicidad estándar de carga.
En cuanto a la seguridad de acceso, se cumple en los sistemas de Data Warehouse, que es preciso el implantar niveles de acceso a la información, realizando un plan completo de seguridad que contemple:
- Acceso a recursos de la red (local o intranet)
- Asignación de usuarios a grupos con perfiles de seguridad diferenciados
- Asignación de niveles de autorización de aplicación a grupos de usuarios
- Seguridad a nivel de Base de Datos, mediante los procedimientos provistos por las mismas.
- Etc.
Tendencias tecnológicas y de mercado de sistemas de Data Warehouse
Tendencias tecnológicas y de mercado de sistemas de Data Warehouse2.3.- TENDENCIAS TECNOLÓGICAS Y DE MERCADO
Describimos a continuación una recopilación de las principales tendencias observadas en el mercado. Estas tendencias se han comentado con anterioridad en otros apartados de esta Guía y se hace referencia a dichos puntos.
Tendencias hacia herramientas especializados:
El uso de herramientras de propósito general no satisface por completo las necesidades de un proyecto de Data Warehouse. Se ha comentado en esta guía las Herramientas de usuario final y tecnológicas, en el que se muestran para cada paso de la creación de un Data Warehouse, una lista de los principales vendedores y sus direcciones Web.
Webhousing
El uso de Internet como fuente de información hacia el exterior e interior (via intranets), crece constantemente, y la integración de una herramienta de Data Warehouse con Internet, se comenta en el apartado de Webhousing
Uso generalizado de Data Marts
Las peculiaridades de un proyecto Data Warehouse, y el enfoque progresivo de su construcción, hace que cada vez mas organizaciones realicen sus desarrollos mediante el uso de Data Marts integrados, tal y como comentabamos en el apartado Data Warehouse vs. Data Mart
Uso de tecnología OLAP
Este aspecto está comentado con amplitud en el apartado OLAP, ROLAP, MOLAP
Aspectos técnicos en el proceso de creación y explotación de un Data Warehouse
Aspectos técnicos en el proceso de creación y explotación de un Data Warehouse3.- ASPECTOS TÉCNICOS EN EL PROCESO DE CREACIÓN Y EXPLOTACIÓN DEL DW
En este capítulo se pretende dar la orientación suficiente al comprador para la preparación del conjunto de especificaciones que definirán los requisitos que han de cumplir la Creación y Explotación de un Data Warehouse.
Se realiza en primer lugar un análisis de las necesidades del comprador, a continuación se recogen los factores relevantes a tener en cuenta en el proceso de adquisición y, finalmente, se describe cómo deben ser planteadas las especificaciones técnico - funcionales para la elaboración del Pliego de Prescripciones Técnicas, qué normas, estándares y cláusulas tipo pueden ser de aplicación, y cuál es el cuestionario técnico diseñado para normalizar las ofertas y facilitar su evaluación.
3.1.- Análisis de las necesidades del comprador
3.2.- Factores relevantes en el proceso de adquisición
3.3.- Diseño del pliego de prescripciones técnicas particulares
Análisis de las necesidades del comprador de un Data Warehouse
Análisis de las necesidades del comprador de un Data Warehouse3.1.- ANÁLISIS DE LAS NECESIDADES DEL COMPRADOR
Incluimos aquí unos pasos que, tal y como se comentaban en la Fases de implantación de un Data Warehouse , son previos al inicio de un proyecto de este tipo.
En efecto, como punto de arranque de todo, es preciso "vender la idea" a los usuarios finales de un Data Warehouse. Esto es así, por ser una idea bastante novedosa y sobre la que pueden surgir recelos de su efectividad. Estos recelos se pueden eliminar comenzando por un pequeño módulo, del cual se valoren los beneficios posteriores, para iniciar progresivamente el desarrollo de nuevos módulos, cada uno con un coste unitario cada vez más reducido, pero sin embargo con unos beneficios distribuidos cada vez mayores por poder cada vez incluir más información. (Ver Data Warehouse vs. Data Mart) para comprobar un caso de este tipo.
El simple hecho de realizar un informe de necesidades previas en el que se enumeren la situación de los datos entre los diversos sistemas operacionales, puede ser un hecho decisivo para emprender un proyecto de este tipo. Muchas veces la información existente se encuentra tan poco normalizada, existen tantas discrepancias entre estos sistemas, que el abordar un Data Warehouse en el que se limpien estos datos y se normalicen pueden aportar un valor intangible: "la calidad y fiabilidad de la información".
La venta de esta idea no sólo se ha de realizar frente a la Dirección sino que es preciso realizarla a todos los niveles: a la Dirección, Gerencia e incluso al área de Desarrollo.
Tras esta venta de la idea, comienzan dos fases similares al análisis de requisitos del sistema (ARS según abreviaturas de la metodología METRICA): la definición de objetivos y requerimientos de información, en el que se analicen las necesidades del comprador.
Definición de los objetivos
En esta fase se definirá el equipo de proyecto que debe estar compuesto por representantes del departamento informático y de los departamentos usuarios del Data Warehouse además de la figura de jefe de proyecto.
Se definirá el alcance del sistema y cuales son las funciones que el Data Warehouse realizará como suministrador de información de negocio estratégica para la empresa. Se definirán así mismo, los parámetros que permitan evaluar el éxito del proyecto.
Definición de los requerimientos de información
Durante esta fase se mantendrán sucesivas entrevistas con los representantes del departamento usuario final y los representantes del departamento de informática. Se realizará el estudio de los sistemas de información existentes, que ayudaran a comprender las carencias actuales y futuras que deben ser resueltas en el diseño del Data Warehouse
Asimismo, en esta fase el equipo de proyecto debe ser capaz de validar el proceso de entrevistas y reforzar la orientación de negocio del proyecto. Al finalizar esta fase se obtendrá el documento de definición de requerimientos en el que se reflejarán no solo las necesidades de información de los usuarios, sino cual será la estrategia y arquitectura de implantación del Data Warehouse.
Factores relevantes en el proceso de adquisición de un sistema de Data Warehouse
Factores relevantes en el proceso de adquisición de un sistema de Data WarehouseDATA WAREHOUSE
3.2.- FACTORES RELEVANTES EN EL PROCESO DE ADQUISICIÓN
En la definición del objeto del contrato y los requisitos inherentes al mismo, así como en la valoración y comparación de ofertas de los licitadores pueden intervenir muchos factores y de muy diversa índole.
Es de suma importancia que todos los factores relevantes que intervienen en el proceso de contratación queden debidamente recogidos en el pliego de prescripciones técnicas que regule el contrato. Así mismo, es conveniente que las soluciones ofertadas por los licitadores sean recogidas en los cuestionarios disponibles a tal efecto:
- De empresa
- Económicos
- Técnicos particulares
Se van a relacionar a continuación algunos de los factores que suelen tener mayor peso al seleccionar una herramienta de Data Warehouse. Sin embargo, debe tenerse en cuenta que la importancia de cada factor variará en función de cada caso particular, por lo que siempre será necesario identificar la importancia relativa de cada punto. Los puntos a contemplar son bastante similares a los contemplados en el apartado homónimo de los SGBD, que adaptaremos a la casuística particular de un Data Warehouse.
Pruebas en condiciones reales
Tal y como sucedía en los SGBD, el rendimiento real de un Data Warehouse es muy difícil de predecir mediante procedimientos teóricos. Por ello, de igual forma que en el SGBD, si se va a instalar un Data Warehouse que contendrá un gran volumen de datos o, si por cualquier otra razón, existen dudas sobre la capacidad del Data Warehouse de dar unas prestaciones adecuadas en las máquinas disponibles se debe exigir al suministrador una prueba anterior a la adquisición del Data Warehouse. Esta prueba debe realizarse en la propia instalación de destino.
La prueba se debería realizar en las condiciones más parecidas a las reales que se puedan conseguir. Para ello se deberá cargar el Data Warehouse con un volumen de datos adecuado y se deberán crear procesos de prueba similares a los más costosos de los que se vayan a desarrollar.
A diferencia de con los SGBD, no es preciso realizar la prueba en momentos de gran carga, por la diferente filosofía de un almacén de datos orientado al conocimiento, pero sí que será preciso la comprobación de la compatibilidad de la herramienta para los procesos de extracción y carga desde los diferentes sistemas operacionales (sistemas operativos, bases de datos, etc.) implicados .
Volumen y organización de los datos
Debe estar garantizado que el Data Warehouse es capaz de tratar el volumen de datos que se vaya a necesitar en la instalación. Para ello debe verificarse no sólo que el Data Warehouse puede manejar el volumen total de datos, sino que no existe ninguna limitación que impide organizarlo de la forma más conveniente.
No obstante, en este sentido y como factor común de un SGBD con un Data Warehouse, cabe reseñar que muchos problemas de rendimiento se deben más veces a un mal diseño del modelo de datos del Data Warehouse que a un problema de rendimiento de la herramienta en sí.
Dimensionamiento de la plataforma de instalación
De lo comentado en los dos puntos anteriores puede deducirse que existe la posibilidad de que sea necesario redimensionar la máquina en la que se instale el Data Warehouse, o mejor aun, disponer de una dedicada al Data Warehouse.
Es necesario que el suministrador detalle cual de las dos versiones está ofreciendo para cada una de las licencias que se compren y si alguna de ellas fuese una versión limitada, que especifique claramente cuales de las funcionalidades ofertadas no se encuentran presentes en la versión restringida.
Condiciones económicas y del soporte
Existen actualmente varios sistemas de cobro por el uso de Data Warehouse según el fabricante. Los más utilizados son facturar por:
- Cada máquina y/o tipo de máquina en la que se instale.
- Cada usuario que acceda al SGBD.
- Por tiempo de utilización (usualmente renovación anual).
- Por combinación de las anteriores.
Es imprescindible que el suministrador indique con toda claridad el método utilizado.
También debe explicitarse que, salvo indicación en contrario, todas las licencias son de versiones completas sin ninguna restricción respecto a las funcionalidades ofertadas.
También es conveniente pedir los precios de los productos adicionales que no se desee instalar en el momento pero que puedan ser interesantes en el futuro.
Otro factor importante es la duración de la garantía, período de tiempo durante el que el suministrador proporcionará soporte gratuito a sus productos y, también el precio del soporte en años sucesivos. Este último precio debe fijarse sobre variables presentes en el contrato no sobre futuros precios de lista del fabricante.
Otro factor que debe evaluarse es la calidad del soporte ofrecido. Este puede dividirse en un gran número de puntos cuya importancia variará en función de las necesidades del comprador. Entre ellos, se pueden citar:
- La inclusión o no de la instalación en el precio del producto.
- El tiempo máximo de entrega.
- La inclusión o no de prestaciones adicionales gratuitas como puede ser un cierto número de horas de formación.
- Capacitación y experiencia del personal que presta soporte técnico y consultoría.
- Calidad de la documentación, idioma en que está escrita, número de copias suministradas gratuitamente y precio de las copias adicionales.
- Capacidad técnica de la empresa y de la asistencia técnica que presta para lo que es recomendable pedir referencias a otros usuarios de la Administración de este tipo de productos.
Pliego de descripciones técnicas particulares de un Data Warehouse
Pliego de descripciones técnicas particulares de un Data WarehouseDATA WAREHOUSE
3.3.- DISEÑO DEL PLIEGO DE PRESCRIPCIONES TÉCNICAS PARTICULARES
Debido a la no existencia de ninguna norma o estándar aplicable a un Data Warehouse, mas que estándares de facto, describimos a continuación cuestionarios técnicos de normalización y valoración de ofertas de SGBD.
Estos cuestionarios han de partir de unas especificaciones previas de:
Entorno Hardware:
Host: (Tipo Máquina, Sistema Operativo y Base de Datos Operacional)
Servidor de la aplicación de DW (Tipo Máquina, Nº procesadores, Memoria total y por procesador, Sistema Operativo, Capacidad de Disco)
Clientes (Tipo de Máquina, Memoria, Sistema Operativo, Capacidad de Disco)
Red local (Topología, Protocolos, Sofware de Cliente y Número de Usuarios soportados)
Entorno Software:
Gestor de Base de Datos para el Data Warehouse
Volumen estimado de la Base de Datos
A continuación y dependiendo del ámbito de aplicación del Data Warehouse describimos un cuestionario aplicado a la creación del Data Warehouse por un lado, por otro del Análisis de la Calidad del dato y la depuración, y por último de su Explotación.
3.3.1.- Cuestionario para la Extracción, Movimiento y Carga
3.3.2.- Cuestionario de Análisis de Calidad
3.3.3.- Cuestionario de Herramientas de Usuario Final: OLAP, EIS y Reporting.
Cuestionario para la ETL
Cuestionario para la ETL3.3.1.- CUESTIONARIO PARA LA EXTRACCIÓN, MOVIMIENTO Y CARGA
Con carácter general y a fin de utilizar la información recopilada de cara a la contratación, es importante destacar que los datos recogidos en este cuestionario están dirigidos a obtener un resumen estructurado de la oferta y a demostrar la solvencia técnica o profesional de la empresa en aquellos casos en que no sea requerida la clasificación de la misma. Dicha información sólo servirá de base a la valoración cuando esté relacionada con lo expresado en la cláusula "Criterios de adjudicación del contrato", siendo, en el resto de los casos, de carácter meramente informativo.
Nota: (*) significa que hay que indicar "1" en caso afirmativo.
(**) significa que hay que repetir para cada sistema operativo ofertado.
| Cuestión | Respuesta | Referencia a
oferta (Página) |
| ------------------------------------------ | ||
| ENTORNO OPERATIVO | ||
| - REQUERIMIENTOS LÓGICOS | ||
| . Especificar para cada uno de las paquetes software ofertados la o las posibles plataformas (servidor central, servidor intermedio y cliente) donde podrían instalarse, detallando los requerimientos físicos y lógicos asociados a cada alternativa, junto con los procesos que se ejecutarían en cada una de las posibles plataformas |
[ ] | [ ] |
| . Compatibilidad con Sistemas operativos (Enumerar) | [ ] | [ ] |
 |
||
| . Compatibilidad con software de red | [ ] | [ ] |
| . Necesidad de software adicional | [ ] | [ ] |
| - REQUERIMIENTOS FÍSICOS | ||
| . Especificar detalladamente los requerimientos físicos mínimos y recomendados, tales como memoria RAM, espacio libre en disco, procesadores, etc... |
[ ] | [ ] |
| CARACTERÍSTICAS GENERALES | ||
| - FUENTES DE DATOS (ORIGEN) SOPORTADAS | ||
| . Permite extraer datos desde varias plataformas origen simultáneamente | [ ] | [ ] |
| . Indicar las distintas fuentes de datos operacionales a las que es posible acceder, especificando en los casos que sea necesario las últimas versiones certificadas. |
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
| - BASES DE DATOS DESTINO SOPORTADAS | ||
| . Permite cargar datos en varias plataformas destino simultáneamente | [ ] | [ ] |
| .Gestores de bases de datos destino soportados, especificando las
últimas versiones certificadas |
||
|
||
| - FUNCIONALIDADES | ||
|
. Enumerar las funcionalidades de la o las herramientas propuestas:
|
[ ] | [ ] |
|
||
| - TRATAMIENTO INTERMEDIO DE LOS DATOS RECUPERADOS | ||
|
.Realiza un almacenamiento intermedio de los datos recuperados a partir de . Especificar
|
[ ] | [ ] |
|
||
| - BASE DE DATOS COMO FUENTE DE DATOS OPERACIONALES | ||
|
. Conocimiento de la estructura de la base de datos
|
[ ] | [ ] |
|
. Detección a captura de modificaciones en la estructura de las bases
|
[ ] | [ ] |
|
||
|
. Acceso a las bases de datos
|
[ ] | [ ] |
|
||
|
. Detección y captura de las modificaciones en los datos
|
[ ] | [ ] |
|
||
| - RECOMENDACIONES PRÁCTICAS | ||
| . Enumerar las principales recomendaciones prácticas para asegurar una plena explotación de la potencialidad de los paquetes software ofertados . Enumerar y justificar brevemente los puntos fuertes tanto de la arquitectura funcional propuesta como de |
[ ] | [ ] |
|
||
| FUNCIONALIDAD | ||
| - FACILIDAD DE USO | ||
|
. Especificar los idiomas soportados en cada una de las siguientes áreas:
. Soporta alfabetización internacional . Dispone de ayuda on-line . Es posible la presentación preliminar de la documentación . Posee un interfaz gráfico que permita tener una visión global . Especificar detalladamente los diferentes perfiles de usuario contemplados . Posee un Editor de Diagramas que facilite las tareas de diseño de |
[ ] | [ ] |
|
||
| - PROCESOS DE EXTRACCIÓN Y TRANSFORMACIÓN | ||
|
. Indicar el paquete software ofertado que incluye esta funcionalidad . Requiere algún software adicional que complemente esta funcionalidad . Es posible automatizar completamente los procesos de extracción y . Se puede integrar con el planificador externo de tareas . Explicar detalladamente el mecanismo de acceso a las estructuras de . Explicar el mecanismo de extracción de los datos desde los sistemas . Detallar los procedimientos de depuración incorporados . Indicar las funciones de transformación más importantes incluidas
. Es posible definir reglas de transformación generales que se puedan . En caso de exclusión de datos en base a reglas de transformación, . Indicar:
|
[ ] | [ ] |
|
||
| - CARACTERÍSTICAS DE LOS PROGRAMAS GENERADOS | ||
| . Especificar el lenguaje utilizado en la generación de código para las distintas fuentes soportadas . Indicar si genera también los JCL o scripts de compilación y ejecución . Es posible modificar los esqueletos de los programas a generar . Enumerar los tipos de programas generados, con una breve descripción de los mismos, y las plataformas |
[ ] | [ ] |
|
||
| - GENERACIÓN DE DOCUMENTACIÓN | ||
|
. Posee un Generador de Informes que automatice la generación de la . Indicar el paquete software ofertado que incluye esta funcionalidad . Requiere algún software adicional que complemente esta funcionalidad . Describir la información incluida en dicha documentación
. Soporta el versionado de la documentación generada . Se proporciona algún software que facilite el mantenimiento |
[ ] | [ ] |
|
||
| - CARACTERÍSTICAS DEL ENTORNO FUNCIONAL | ||
| . Especificar el software mínimo que es necesario tener instalado en las diferentes plataformas . La transferencia de los programas generados desde el puesto cliente hasta los sistemas operacionales y el Data . Son necesarios otros requisitos software adicionales, como por ejemplo compiladores (Observaciones) |
[ ] | [ ] |
|
||
| - DETECCIÓN Y CAPTURA DE MODIFICACIONES | ||
|
[ ] | [ ] |
|
||
| - DETECCIÓN Y CAPTURA DE MODIFICACIONES EN LA ESTRUCTURA DE LAS BASES DE DATOS DE DATA WAREHOUSE |
||
| . Indicar el paquete software ofertado que incluye esta funcionalidad y la plataforma o plataformas donde ha de instalarse . Requiere algún software adicional que complemente esta funcionalidad . Explicar con detalle los mecanismos utilizados para la detección de modificaciones en los datos de . Es posible automatizar la detección de estas modificaciones . Explicar detalladamente los mecanismos utilizados para la captura de dichas modificaciones . Es posible automatizar la captura de dichas modificaciones . Indicar si la herramienta es capaz de detectar automáticamente las transformaciones a las que afectan . Es necesario parar las bases de datos operacionales para realizar el proceso de captura de las modificaciones |
[ ] | [ ] |
|
||
|
. Detección y captura de modificaciones en los datos de los |
||
|
||
|
||
|
[ ] | [ ] |
|
||
|
||
|
[ ] | [ ] |
|
||
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
- MOVIMIENTO Y CARGA |
||
|
. Indicar el paquete software ofertado que incluye esta funcionalidad |
||
|
||
|
. Requiere algún software adicional que complemente esta funcionalidad |
[ ] | [ ] |
|
. Explicar detalladamente los mecanismos de movimiento y carga de |
||
|
||
|
. Transferencia de datos desde los Sistemas |
[ ] | [ ] |
| . Control de las filas que sean rechazadas en el proceso de carga | [ ] | [ ] |
|
||
|
||
|
. Para el caso de los datos rechazados indicar |
||
|
[ ] | [ ] |
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
||
|
. Indicar las alternativas para realizar la carga final del Data Warehouse |
||
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
. Incorpora la herramienta algún proceso de comunicación automática de la disponibilidad |
[ ] | [ ] |
|
. En caso afirmativo indicar |
||
|
||
|
||
|
[ ] | [ ] |
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
||
|
- CARGA INCREMENTAL |
||
|
. Explicar detalladamente el mecanismo de carga incremental de los |
||
|
||
|
. Enumerar las principales diferencias respecto al proceso de carga |
||
|
||
|
- FUNCIONALIDADES ADICIONALES |
||
|
. Análisis y control de la calidad |
||
|
[ ] | [ ] |
|
||
|
||
|
[ ] | [ ] |
|
. Limpieza |
||
|
[ ] | [ ] |
|
||
|
||
|
[ ] | [ ] |
|
||
|
||
|
- GESTIÓN DEL METADATA |
||
|
. Procedimientos de creación, mantenimiento y consulta |
||
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
[ ] | [ ] |
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
||
|
[ ] | [ ] |
|
||
|
||
|
. Integración de los metadatos |
||
|
[ ] | [ ] |
|
||
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
. Control de versiones y documentación del metadato |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
. Importación y exportación de metadatos |
||
|
[ ] | [ ] |
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
[ ] | [ ] |
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
[ ] | [ ] |
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
ADMINISTRACIÓN |
||
|
- GESTIÓN DE RECURSOS |
||
|
. Administración centralizada |
||
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
. Estadísticas y logs de los procesos de extracción, |
||
|
[ ] | [ ] |
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
||
|
||
|
- SEGURIDAD |
||
|
. Indicar los niveles de seguridad soportados |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
. En qué plataforma se gestiona la seguridad |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
| . Se realiza una identificación del usuario a la hora de acceder al sistema | [ ] | [ ] |
|
. Almacenamiento físico de la password |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
. Localización física de la password |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
. Explicar en detalle los mecanismos de seguridad que incorporan la |
||
|
||
|
- PROCEDIMIENTO DE PLANIFICACIÓN Y MANTENIMIENTO |
||
| . Posible construir procedimientos que automaticen las tareas de planificación y mantenimiento |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
| . En caso afirmativo, indicar las posibles bases de dicha planificación | ||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
| . Indicar el paquete software ofertado que incluye esta funcionalidad y la plataforma o plataformas donde ha de instalarse |
||
|
||
| . Requiere algún software adicional que complemente dicha funcionalidad | [ ] | [ ] |
|
ACLARACIONES GENERALES |
||
|
||
|
REFERENCIAS |
||
|
Cuestionario de análisis de la calidad en un Data Warehouse
Cuestionario de análisis de la calidad en un Data Warehouse3.3.2.- CUESTIONARIO DE ANÁLISIS DE CALIDAD
Con carácter general y a fin de utilizar la información recopilada de cara a la contratación, es importante destacar que los datos recogidos en este cuestionario están dirigidos a obtener un resumen estructurado de la oferta y a demostrar la solvencia técnica o profesional de la empresa en aquellos casos en que no sea requerida la clasificación de la misma. Dicha información sólo servirá de base a la valoración cuando esté relacionada con lo expresado en la cláusula "Criterios de adjudicación del contrato", siendo, en el resto de los casos, de carácter meramente informativo.
Nota: (*) significa que hay que indicar "1" en caso afirmativo.
(**) significa que hay que repetir para cada sistema operativo ofertado.
| Cuestión | Respuesta | Referencia a oferta (Página) |
| ------------------------------------------ | ---------- | ---------- |
|
ENTORNO OPERATIVO |
||
|
- REQUERIMIENTOS LÓGICOS |
||
|
. Especificar para cada uno de las paquetes software ofertados la o las posibles plataformas (servidor central, |
[ ] | [ ] |
|
. Compatibilidad con Sistemas operativos. (Enumerar) |
[ ] | [ ] |
|
|
||
|
. Compatibilidad con software de red |
[ ] | [ ] |
|
. Necesidad de software adicional. (Enumerar) |
[ ] | [ ] |
|
|
||
|
- REQUERIMIENTOS FÍSICOS |
||
|
. Memoria RAM Mínima requerida |
[ ] | [ ] |
|
. Memoria RAM Recomendada |
[ ] | [ ] |
|
. Espacio libre de disco Mínimo requerido |
[ ] | [ ] |
|
. Espacio libre de disco Recomendado |
[ ] | [ ] |
|
. Procesador mínimo requerido |
[ ] | [ ] |
|
. Porcesador recomendado |
[ ] | [ ] |
|
. Observaciones |
||
 |
||
| CARACTERISTICAS GENERALES | [ ] | [ ] |
| - ORIGEN DE LOS DATOS A ANALIZAR | ||
| . Indicar si se analiza el total de los datos o bien sólo una muestra significativa de los mismos |
||
|
[ ] | [ ] |
|
||
|
[ ] | [ ] |
| . Observaciones | ||
|
||
| . Indicar y explicar detalladamente el mecanismo de obtención de los datos a analizar. |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
| . Observaciones | ||
|
||
| . Explicación detallada del mecanismo seguido | ||
|
||
| . En el caso de acceder directamente a las fuentes de datos indicar | ||
|
[ ] | [ ] |
|
||
|
||
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
[ ] | [ ] |
|
||
|
||
|
||
| . En el caso de extraer los datos a analizar desde las fuentes soportadas y almacenarlos para su análisis, indicar |
||
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
||
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
||
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
||
|
||
|
||
|
||
|
||
| . En el caso de analizar los datos que otras herramientas han extraído de las fuentes de datos, especificar de qué herramientas se trata. así como sus requerimientos lógicos y físicos y la plataforma o plataformas donde han de instalarse. |
||
|
||
| - ELECCION Y TRATAMIENTO DE LAS MUESTRAS | ||
| . Describir el mecanismo de elección de la muestra, para asegurar la aleatoriedad de la misma |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
||
|
||
|
||
| . Indicar el almacenamiento físico de la muestra de datos | ||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
||
| . Indicar la localización física de la muestra de datos | ||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
||
| . Porcentaje que supone la muestra sobre el volumen total de datos | ||
|
||
|
||
|
||
| . Técnicas aplicadas sobre la muestra de datos | ||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
||
|
||
| - MECANISMOS DE ANALISIS DE LA CALIDAD Y FUNCIONALIDADES | ||
| . Explicar detalladamente el mecanismo de análisis de calidad utilizado y las funcionalidades disponibles |
||
|
||
| . Indicar los niveles de análisis de calidad disponibles | ||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
||
| . Indicar la plataforma o plataformas donde se ejecutan los procesos de análisis de calidad de los datos |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
||
| . Indicar las métricas que proporciona la herramienta por defecto para cuantificar la calidad de los datos |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
||
| . Posibilidad de utilizar "métricas" definidas por el usuario para cuantificar la calidad de los datos |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
| - LIMITACIONES | ||
| . Existencia de alguna limitación interna de la herramienta en cuanto al volumen máximo de información que se puede analizar |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
||
|
||
| - RECOMENDACIONES PRACTICAS | ||
| . Enumerar las principales recomendaciones prácticas para asegurar una plena explotación de la potencialidad de los paquetes software ofertados. |
||
|
||
| . Enumerar y justificar brevemente los puntos fuertes tanto de la arquitectura funcional propuesta como de las herramientas ofertadas. |
||
|
||
| FUNCIONALIDAD | ||
| - FACILIDAD DE USO | ||
| . Especificar los idiomas soportados en cada una de las siguientes áreas | ||
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
| . Incluye los caracteres exclusivos del español: Ñ, ñ y vocales acentuadas |
[ ] | [ ] |
| . Interfaz gráfico | [ ] | [ ] |
| . Ayuda on-line | [ ] | [ ] |
|
. Presentación preliminar de la documentación antes |
[ ] | [ ] |
|
. Observaciones |
||
|
||
|
. Especificar detalladamente los diferentes perfiles de usuario contemplados |
||
|
||
|
- ACCESO A LAS FUENTES DE DATOS |
||
|
. Conocimiento de la estructura de las bases |
||
|
[ ] | [ ] |
|
||
|
||
|
||
|
||
|
. Detección y captura de modificaciones en la estructura de |
||
|
[ ] | [ ] |
|
||
|
||
|
[ ] | [ ] |
|
||
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
. Acceso a las bases de datos |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
- PROCEDIMIENTOS DE ANALISIS DE CALIDAD |
||
|
. Indicar el paquete software ofertado que incluye esta funcionalidad |
||
|
||
|
. Requiere algún software adicional que complemente esta funcionalidad |
[ ] | [ ] |
|
. Es posible automatizar completamente los procesos de análisis |
[ ] | [ ] |
|
. Es posible mantener un histórico sobre evolución temporal |
[ ] | [ ] |
|
. Formatos soportados para la exportación de los resultados |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
[ ] | [ ] |
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
. Adjuntar como anexo un ejemplo, lo más completo posible, |
||
|
- GENERACION DE DOCUMENTACION |
||
|
. Posee un Generador de Informes que permita la generación |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
. Indicar el paquete software ofertado que incluye esta funcionalidad |
||
|
||
|
. Requiere algún software adicional que complemente esta funcionalidad |
[ ] | [ ] |
|
. Describir la información incluida en dicha documentación |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
. Soporta el versionado de la documentación generada |
[ ] | [ ] |
|
. Se proporciona algún software que facilite el mantenimiento |
[ ] | [ ] |
|
- CARACTERISTICAS DEL ENTORNO FUNCIONAL |
||
|
. Especificar el software mínimo que es necesario tener instalado |
||
|
||
|
. Son necesarios otros requisitos software adicionales |
[ ] | [ ] |
|
- FUNCIONALIDADES ADICIONALES |
||
|
. Limpieza de datos |
||
|
[ ] | [ ] |
|
||
|
||
|
[ ] | [ ] |
|
||
|
||
|
. Otras funcionalidades |
||
|
[ ] | [ ] |
|
||
|
||
|
||
|
[ ] | [ ] |
|
||
|
||
|
- GESTION DE LOS METADATOS DE CALIDAD |
||
|
. Se generan metadatos sobre la calidad de los datos |
[ ] | [ ] |
|
. Procedimientos de creación, mantenimiento y consulta |
||
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
||
|
||
|
[ ] | [ ] |
|
||
|
||
|
. Integración de los metadatos de calidad con otros metadatos |
||
|
[ ] | [ ] |
|
||
|
||
|
||
|
||
|
[ ] | [ ] |
|
. Control de versiones y documentación del metadato de calidad |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
| . Importación y exportación de los metadatos de calidad | ||
|
[ ] | [ ] |
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
[ ] | [ ] |
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
||
|
||
|
[ ] | [ ] |
|
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
| - PLANIFICACION DEL ANALISIS DE CALIDAD | ||
| . Posibilidad de construir procedimientos que automaticen las tareas de análisis de la calidad de los datos |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
| . Indicar las posibles bases de dicha planificación | ||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
| . Indicar el paquete software ofertado que incluye esta funcionalidad y la plataforma o plataformas donde ha de instalarse |
||
|
||
| . Requiere algún software adicional que complemente dicha funcionalidad | [ ] | [ ] |
| ACLARACIONES GENERALES | ||
|
||
| REFERENCIAS | ||
| Resumen de las principales instalaciones donde se encuentran instaladas las herramientas propuestas, con una breve descripción del entorno tecnológico y de los volúmenes de información manejados |
||
|
Cuestionario de Herramientas de usuario final: OLAP, EIS, Reporting (1/3)
Cuestionario de Herramientas de usuario final: OLAP, EIS, Reporting (1/3)3.3.3.- CUESTIONARIO DE HERRAMIENTAS DE USUARIO FINAL: OLAP, EIS, REPORTING
Con carácter general y a fin de utilizar la información recopilada de cara a la contratación, es importante destacar que los datos recogidos en este cuestionario están dirigidos a obtener un resumen estructurado de la oferta y a demostrar la solvencia técnica o profesional de la empresa en aquellos casos en que no sea requerida la clasificación de la misma. Dicha información sólo servirá de base a la valoración cuando esté relacionada con lo expresado en la cláusula "Criterios de adjudicación del contrato", siendo, en el resto de los casos, de carácter meramente informativo.
Nota: (*) significa que hay que indicar "1" en caso afirmativo.
(**) significa que hay que repetir para cada sistema operativo ofertado.
| Cuestión | Respuesta | Referencia a oferta (Página) |
| ------------------------------------------ | ---------- | ---------- |
|
ENTORNO OPERATIVO |
||
|
|
||
|
- REQUERIMIENTOS LÓGICOS |
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
|
||
|
- REQUERIMIENTOS FÍSICOS |
||
|
. Memoria RAM Mínima requerida |
[ ] | [ ] |
|
. Memoria RAM Recomendada |
[ ] | [ ] |
|
. Espacio libre de disco Mínimo requerido |
[ ] | [ ] |
|
. Espacio libre de disco Recomendado |
[ ] | [ ] |
|
. Procesador mínimo requerido |
[ ] | [ ] |
|
. Porcesador recomendado |
[ ] | [ ] |
|
. Observaciones |
||
|
|
||
|
CARACTERÍSTICAS GENERALES |
||
| - INTERFACES DE USUARIO FINAL APORTADAS Y SOPORTADAS | ||
|
. Especificar los diferentes interfaces de usuario final que aportan |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
|
||
|
. Especificar los diferentes interfaces de usuario final que se soportan, |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
|
||
|
- DESCRIPCIÓN DEL ACCESO |
||
|
. Especificar el tipo de acceso efectuado |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
|
||
|
. Indicar las arquitecturas cliente/servidor soportadas |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
|
||
|
. Indicar los gestores de bases de datos que soporta, así como |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
|
||
|
. Almacenamiento físico de los datos recuperados |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
|
||
|
. Dónde se almacena la información recuperada |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
|
||
| . Indicar la visión lógica de los datos recuperados. | ||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
. En caso de almacenar la información recuperada de manera |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
|
||
|
||
|
|
||
|
. En caso de almacenamiento multidimensional explicar qué ocurre |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
|
||
|
||
|
|
||
|
- TÉCNICAS DE EXPLORACIÓN DE DATOS |
||
|
. Técnicas de exploración de datos soportadas |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
|
||
|
. Para las técnicas de navegación soportadas indicar |
||
|
|
||
|
. En el caso de utilizar alguna de las técnicas de exploración |
[ ] | [ ] |
|
||
|
|
||
|
. Es posible navegar por más de una ocurrencia |
[ ] | [ ] |
|
||
|
|
||
|
Observaciones |
||
|
|
||
|
- FUNCIONALIDADES. POTENCIA DE CÁLCULO |
||
|
. Principales funcionalidades proporcionadas |
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
|
||
|
||
|
|
||
|
. Enumerar las funciones estadísticas disponibles |
||
|
|
||
|
. Funcionalidades de cálculo dinámico soportadas |
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
|
||
|
. Posibilidad de utilizar fechas dinámicas, |
[ ] |
[ ] |
|
||
|
|
||
|
. Posible realizar cálculos dinámicos |
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
- VISIÓN DEL MODELO DE NEGOCIO |
||
|
. Posee un interfaz gráfica que muestre el modelo de negocio |
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
. En caso de poder limitar esta expansión especificar los posibles |
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
|
||
|
. Posible en dicho interfaz gráfico visualizar |
[ ] |
[ ] |
|
||
|
|
||
|
- LIMITACIONES |
||
|
. Limitación interna de la herramienta |
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
||
|
|
||
|
. Limitación en cuanto al número |
[ ] |
[ ] |
|
||
|
|
||
|
. Especificar detalladamente las principales limitaciones de los paquetes |
||
|
|
||
|
- RECOMENDACIONES PRÁCTICAS |
||
|
. Indicar el modelo de datos recomendado (en el servidor de datos) |
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
|
||
|
. Especificar detalladamente las principales recomendaciones prácticas |
||
|
|
||
|
. Enumerar y justificar brevemente los puntos fuertes tanto de la |
||
|
|

Cuestionario de herramientas de usuario final: OLAP, EIS, Reporting (2/3)
Cuestionario de herramientas de usuario final: OLAP, EIS, Reporting (2/3)3.3.3.- CUESTIONARIO DE HERRAMIENTAS DE USUARIO FINAL: OLAP, EIS, REPORTING
Con carácter general y a fin de utilizar la información recopilada de cara a la contratación, es importante destacar que los datos recogidos en este cuestionario están dirigidos a obtener un resumen estructurado de la oferta y a demostrar la solvencia técnica o profesional de la empresa en aquellos casos en que no sea requerida la clasificación de la misma. Dicha información sólo servirá de base a la valoración cuando esté relacionada con lo expresado en la cláusula "Criterios de adjudicación del contrato", siendo, en el resto de los casos, de carácter meramente informativo.
Nota: (*) significa que hay que indicar "1" en caso afirmativo.
(**) significa que hay que repetir para cada sistema operativo ofertado.
| Cuestión | Respuesta | Referencia a oferta (Página) |
| ------------------------------------------ | ---------- | ---------- |
|
ENTORNO OPERATIVO |
||
|
|
||
|
- REQUERIMIENTOS LÓGICOS |
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
|
||
|
- REQUERIMIENTOS FÍSICOS |
||
|
. Memoria RAM Mínima requerida |
[ ] | [ ] |
|
. Memoria RAM Recomendada |
[ ] | [ ] |
|
. Espacio libre de disco Mínimo requerido |
[ ] | [ ] |
|
. Espacio libre de disco Recomendado |
[ ] | [ ] |
|
. Procesador mínimo requerido |
[ ] | [ ] |
|
. Porcesador recomendado |
[ ] | [ ] |
|
. Observaciones |
||
|
|
||
|
CARACTERÍSTICAS GENERALES |
||
| - INTERFACES DE USUARIO FINAL APORTADAS Y SOPORTADAS | ||
|
. Especificar los diferentes interfaces de usuario final que aportan |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
|
||
|
. Especificar los diferentes interfaces de usuario final que se soportan, |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
|
||
|
- DESCRIPCIÓN DEL ACCESO |
||
|
. Especificar el tipo de acceso efectuado |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
|
||
|
. Indicar las arquitecturas cliente/servidor soportadas |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
||
|
|
||
|
. Indicar los gestores de bases de datos que soporta, así como |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
|
||
|
. Almacenamiento físico de los datos recuperados |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
|
||
|
. Dónde se almacena la información recuperada |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
|
||
| . Indicar la visión lógica de los datos recuperados. | ||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
. En caso de almacenar la información recuperada de manera |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
|
||
|
||
|
|
||
|
. En caso de almacenamiento multidimensional explicar qué ocurre |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
|
||
|
||
|
|
||
|
- TÉCNICAS DE EXPLORACIÓN DE DATOS |
||
|
. Técnicas de exploración de datos soportadas |
||
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
[ ] | [ ] |
|
|
||
|
. Para las técnicas de navegación soportadas indicar |
||
|
|
||
|
. En el caso de utilizar alguna de las técnicas de exploración |
[ ] | [ ] |
|
||
|
|
||
|
. Es posible navegar por más de una ocurrencia |
[ ] | [ ] |
|
||
|
|
||
|
Observaciones |
||
|
|
||
|
- FUNCIONALIDADES. POTENCIA DE CÁLCULO |
||
|
. Principales funcionalidades proporcionadas |
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
|
||
|
||
|
|
||
|
. Enumerar las funciones estadísticas disponibles |
||
|
|
||
|
. Funcionalidades de cálculo dinámico soportadas |
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
|
||
|
. Posibilidad de utilizar fechas dinámicas, |
[ ] |
[ ] |
|
||
|
|
||
|
. Posible realizar cálculos dinámicos |
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
- VISIÓN DEL MODELO DE NEGOCIO |
||
|
. Posee un interfaz gráfica que muestre el modelo de negocio |
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
. En caso de poder limitar esta expansión especificar los posibles |
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
|
||
|
. Posible en dicho interfaz gráfico visualizar |
[ ] |
[ ] |
|
||
|
|
||
|
- LIMITACIONES |
||
|
. Limitación interna de la herramienta |
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
||
|
|
||
|
. Limitación en cuanto al número |
[ ] |
[ ] |
|
||
|
|
||
|
. Especificar detalladamente las principales limitaciones de los paquetes |
||
|
|
||
|
- RECOMENDACIONES PRÁCTICAS |
||
|
. Indicar el modelo de datos recomendado (en el servidor de datos) |
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
|
||
|
. Especificar detalladamente las principales recomendaciones prácticas |
||
|
|
||
|
. Enumerar y justificar brevemente los puntos fuertes tanto de la |
||
|
|
Cuestionario de herramientas de usuario final: OLAP, EIS, Reporting (3/3)
Cuestionario de herramientas de usuario final: OLAP, EIS, Reporting (3/3)3.3.3.- CUESTIONARIO DE HERRAMIENTAS DE USUARIO FINAL: OLAP, EIS, REPORTING (cont.)
Con carácter general y a fin de utilizar la información recopilada de cara a la contratación, es importante destacar que los datos recogidos en este cuestionario están dirigidos a obtener un resumen estructurado de la oferta y a demostrar la solvencia técnica o profesional de la empresa en aquellos casos en que no sea requerida la clasificación de la misma. Dicha información sólo servirá de base a la valoración cuando esté relacionada con lo expresado en la cláusula "Criterios de adjudicación del contrato", siendo, en el resto de los casos, de carácter meramente informativo.
Nota: (*) significa que hay que indicar "1" en caso afirmativo.
(**) significa que hay que repetir para cada sistema operativo ofertado.
| Cuestión | Respuesta | Referencia a oferta (Página) |
| ------------------------------------------ | ---------- | ---------- |
|
ADMINISTRACIÓN |
||
|
- GESTIÓN DE RECURSOS |
||
|
. Administración centralizada |
||
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
|
||
|
||
|
|
||
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
||
|
|
||
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
||
|
|
||
|
||
|
|
||
|
. Tratamiento de los datos recuperados |
||
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
|
||
|
||
|
|
||
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
|
||
|
[ ] |
[ ] |
|
||
|
|
||
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
||
|
|
||
|
. Estadísticas de ejecución |
||
|
[ ] |
[ ] |
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
|
||
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
|
||
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
||
|
|
||
|
. Simulación, estimaciones de consumo y |
||
|
[ ] |
[ ] |
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
 |
||
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
||
|
|
||
|
||
|
|
||
| . Asignación dinámica de recursos | ||
|
[ ] |
[ ] |
|
||
|
|
||
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
|
||
|
||
|
|
||
|
. Limitación del consumo de recursos en las consultas |
||
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
||
|
|
||
|
- GESTIÓN DE ACCCESO Y EJECUCIÓN |
||
|
. Seguridad de acceso |
||
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
|
||
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
|
||
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
|
||
|
[ ] |
[ ] |
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
|
||
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
|
||
|
||
|
|
||
|
. Limitaciones a nivel de acceso |
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
|
||
|
[ ] |
[ ] |
|
||
|
|
||
|
. Prioridades de ejecución |
||
|
[ ] |
[ ] |
|
||
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
[ ] |
[ ] |
|
|
||
|
||
|
|
||
|
ACLARACIONES GENERALES |
||
|
|
||
|
||
|
|
||
|
REFERENCIAS |
||
| Resumen de las principales instalaciones donde se encuentran instaladas las herramientas propuestas, con una breve descripción del entorno tecnológico y de los volúmenes de información manejados |
||
|
|
||
|
||
|
|
Pruebas de verificación y control de un Data Warehouse
Pruebas de verificación y control de un Data Warehouse4.- PRUEBAS DE VERIFICACIÓN Y CONTROL
Un Data Warehouse precisa de un conjunto de pasos desde su creación hasta su explotación final. En todos estos pasos se precisa de una herramienta que nos permita simplificar su ejecución. Debido a la amplia variedad de herramientas disponibles, y para asegurar la idoneidad de la herramienta, caben varias alternativas:
Evaluación distribuida: En ella se evaluaría cada herramienta en un paso concreto. Se vería cual es la que mejor se adapta a nuestras necesidades, y a continuación, examinaríamos la compatibilidad en cascada de todas ellas.
Evaluación centralizada: En ella se evaluaría el soporte que cada herramienta proporciona a todos los pasos, y a continuación se examina cual es la que globalmente se adecua de forma global a nuestras necesidades.
La elección de una u otra alternativa tiene sus ventajas e inconvenientes: la primera nos permitiría obtener la mejor herramienta (la de mejor relación cumplimiento expectativas/ precio), pero podría comprometer la cadena completa de uso de un Data Warehouse. Lo contrario ocurriría en la segunda alternativa.
Debido a la creciente información disponible de cada fabricante en Internet, y a su frecuente actualización, recomendamos la visita al Data Warehousing Information Center (LGI Systems Incorporated), desde su página principal en http://pwp.starnetinc.com/larryg/index.html en donde, desde donde se encuentran enlaces a:
Vendedores de herramientas de usuario final:
- Herramientas de Query and Reporting
- Bases de Datos OLAP y Multidimensionales
- Sistemas EIS (Executive Information Systems)
- Herramientas de Data Mining
- Recuperación de Documentos
- Sistemas de Información Geográfica (GIS)
- Herramientas de Análisis de Decisiones
- Estadísticas
- Modelado de Procesos
- Filtrado de Información
- Obtención de Informes
- Otras herramientas
Vendedores de Infraestrutura Tecnológica:
- Extracción de Datos, Limpieza y Carga
- Catalogación de la Información
- Bases de Datos para Data Warehousing
- Administración de Consulas y Almacenamiento
- Modelado de Datos para Data Warehouse
- Herramientas iddleware
- Aceleradoras de Query's y Carga
- Otras utilidades de BD
- Hardware
Vendedores por Función e Industria:
- Herramientas de Análisis Financiero
- Herramientas de Marketing y Análisis de Ventas
- Herramientas de Análisis de la cadena de suministro
- Herramientas para la Industria de la Salud
- Herramientas para la Industria Detallista
- Herramientas para el Sector Financiero
- Otras herramientas específicas
Empresas de Servicios:
- Consultoras Especialistas en DW
- NorSistemas
- Consultoras Generales
- Formación
Referencias utilizadas para la confección de la guia
Referencias utilizadas para la confección de la guia5. REFERENCIAS UTILIZADAS
 "Informe Data Mining" Suplemento 709 ComputerWorld España.
"Informe Data Mining" Suplemento 709 ComputerWorld España.
"Data Warehouse" Cuadernos de Cinco Días.
"Rapid Data Warehousing with the SAS System" SAS Institute.
"The SAS System and Web Integration" SAS Institute White Paper.
"Building a Decision Support Architecture for Data Warehousing"	 ATG's Data Warehousing Technology Guide.
"Enterprise Storage for Today's Data Warehousing Environment" 	ATG's Data Warehousing Technology Guide.
"Managing the Warehouse thruits Lifecycle" ATG's Data Warehousing Technology Guide.
"Data Warehousing Information Center" LGI System Incorporated
"What is a Data Warehouse?"W.H. Innmon (Prism Brochure Num. 1)
"The Case For Relational OLAP"MicroStrategy Incorporated White Paper
"Data Mining" Curso Formación Interno NorSistemas
"Nuevas Tecnologías en Análisis de Riesgos" 	Hardvard-Deusto Finanzas y Contabilidad (SEP/OCT 97)
Equipo responsable de la guia técnica
Equipo responsable de la guia técnica6. EQUIPO RESPONSABLE DE LA GUÍA TÉCNICA
Coordinadores de la Guía Técnica
Isabel Criado Gómez
Ministerio de Trabajo y Asuntos Sociales
Paloma Sánchez López
Ministerio de Trabajo y Asuntos Sociales
Empresa Consultora Externa