5. Administracion de MYSQL
5. Administracion de MYSQL Dataprix 8 Octubre, 2009 - 11:31Las tareas administrativas como la instalación, gestión de usuarios, copias de seguridad, restauraciones, entre otras, son tareas ineludibles en cualquier organización. Las políticas, los recursos y preferencias de los administradores generan una gran variedad de estilos y mecanismos para llevar a cabo estas tareas, por lo que no es posible hablar de métodos completamente estandarizados en estas áreas.
En este apartado se contemplan las opciones de uso común para la administración de un servidor MySQL. Existen tantas alternativas que no es posible incluirlas todas en un curso. Por tal motivo, en este capítulo se tratan algunos temas de importancia para el administrador, desde una perspectiva general, que permiten obtener una visión global de las posibilidades prácticas de las herramientas administrativas.
En este sentido, el manual de MySQL es la referencia principal para encontrar posibilidades y resolver dudas. En especial se recomienda leer los siguientes capítulos:
• Capítulo 2. Instalación de MySQL.
• Capítulo 4. Administración bases de datos.
• Capítulo 5. Optimización.
La información contenida en ellos es muy amplia y clara, y representa una excelente guía para resolver dudas. Asimismo, se deben tener en cuenta las listas de correo incluidas en el sitio oficial www.mysql.com.
Este capítulo se inicia con una breve reseña del proceso de instalación de MySQL. En la actualidad es posible realizar la instalación a partir de binarios empaquetados que facilitan enormemente el proceso. La administración de usuarios se trata con algo más de detalle, incluyendo una breve descripción de las tablas del directorio de datos. Para los temas de copias de seguridad y restauración se muestran los comandos y utilidades de mayor uso en la práctica omitiendo algunos detalles técnicos poco usuales. La optimización se trata de manera muy general, exponiendo los temas básicos que en la práctica son pasados por alto.
Finalmente, se describe brevemente cómo realizar la replicación de datos en un servidor esclavo.
5.1. Instalacion de MYSQL
5.1. Instalacion de MYSQL Dataprix 8 Octubre, 2009 - 11:45La instalación de MySQL no representa mayores problemas, ya que muchas distribuciones incluyen paquetes con los que realizar la instalación y configuración básica. Sin embargo, aquí veremos la instalación de MySQL utilizando el código fuente que se puede obtener en www.mysql.com. Cabe destacar que el uso de una versión de MySQL compilada tiene la ventaja de que, probablemente, se adaptará mucho mejor al entorno del servidor donde se ejecutará, proporcionando así un mejor rendimiento. Por contra, implicará más trabajo en caso de que surjan errores en la versión y tengamos que actualizarla. Las instrucciones que se describen en este apartado se basan en la documentación incluida en la distribución.
En primer lugar, debemos asegurarnos de que contamos con las librerías y utilidades necesarias para compilar los ficheros fuente. Principalmente la lista de verificación debe incluir los ficheros siguientes:
• Compilador gcc
• Librerías libgc
El proceso de instalación incluye los siguientes pasos:
• Descomprimir los archivos fuente
cd /usr/local/src
tar xzvf mysql-VERSION.tar.gz
cd mysql-VERSION• Configurar la versión de MySQL que vamos a obtener. El script 'configure' admite muchos parámetros que deberemos examinar mediante la opción '--help'. Según los esquemas de tabla que necesitemos o extensiones muy concretas que debamos utilizar, deberemos examinar con cuidado sus opciones. En su versión más simple lo ejecutaríamos de la siguiente manera:
./configure -prefix=/usr/local/mysql• Compilar. Procederemos a compilar si no ha habido problemas con la configuración. El parámetro -prefix especifica la ruta del sistema de ficheros donde será instalado.
make
• Instalar el sistema el servidor ya compilado, mediante la siguiente instrucción:
make install• Crear la base de datos inicial del servidor, la que almacenará los usuarios y privilegios. Esta base de datos es imprescindible para que los usuarios se puedan conectar al servidor.
scripts/mysql_istall_db• Crear un nuevo usuario y su grupo, para que el servicio se ejecute en un entorno de privilegios restringido en el sistema operativo. En ningún caso se recomienda que el usuario que ejecute el servicio mysqld sea root.
groupadd mysql
useradd -g mysql mysql• Todos los archivos deben ser propiedad de root (mysql no debe poder modificarse a sí mismo) y del grupo mysql. El directorio de datos será del usuario mysql para que pueda trabajar con las bases de datos, ficheros de registro, etc.
chown -R root /usr/local/mysql
chgrp -R mysql /usr/local/mysql
chown -R mysql /usr/local/mysql/var• Crear el archivo de configuración. La distribución incluye varios archivos de configuración que sirven como plantilla para adaptarlo a nuestras necesidades. En este caso, utilizamos la configuración media como plantilla. Opcionalmente podemos editar el archivo /etc/my.cnf
cp support-files/my-medium.cnf /etc/my.cnf• Lanzar el servidor
/usr/local/mysql/bin/mysql_safe &• En este estado, el servidor no puede servir aún de SGBD. Por defecto, tendremos creado un usuario 'root' sin contraseña que podrá acceder tanto desde el equipo local como remotamente. El siguiente paso será asignar una contraseña a este usuario y repasar los usuarios y privilegios definidos. Para asignar la contraseña, deberemos hacer lo siguiente:
mysqladmin -u root password "nuevapasswd"
mysqladmin -u root -h host_name password "nuevapasswd"Podemos probar el funcionamiento del SGBD conectando con el cliente 'mysql':
mysql -u root -pVeamos ahora algunas características del servidor que acabamos de instalar:
• mysqld. El primer método es lanzarlo directamente, se le pueden especificar las opciones que el administrador desee.
• mysqld_safe. Es un script que ejecuta mysqld garantizando una configuración segura. Es mucho más recomendable que ejecutar mysqld directamente.
• mysql_server. Es un guión que realiza dos tareas: iniciar y detener el servidor mysqld con los parámetros start y stop respectivamente. Utiliza mysqld_safe para lanzar el servidor mysqld. No es común encontrarlo con ese nombre, ya que generalmente se copia como el archivo /etc/init.d/mysql
• mysql_multi. Permite la ejecución de múltiples servidores de forma simultanea.
Para detener el servidor básicamente tenemos dos métodos:
• /etc/init.d/mysql stop. Es el mecanismo estándar en los sistemas tipo UNIX. Aunque los directorios pueden cambiar.
• $ mysqladmin -u root -p shutdown. Es la utilidad para realizar tareas administrativas en un servidor MySQL, en este caso le pasamos el parámetro 'shutdown' para detener el servicio.
Para que los mensajes del servidor aparezcan en español, se debe ejecutar con el parámetro -language:
$ mysqld --language=spanishOtra opción es agregar en el archivo /etc/my.cnf una línea en la sección [mysqld]
[mysqld]
language = /usr/share/mysql/spanish5.2. Usuanos y privilegios
5.2. Usuanos y privilegios Dataprix 8 Octubre, 2009 - 12:13El acceso al servidor MySQL está controlado por usuarios y privilegios. Los usuarios del servidor MySQL no tienen ninguna correspondencia con los usuarios del sistema operativo. Aunque en la práctica es común que algún administrador de MySQL asigne los mismos nombres que los usuarios tienen en el sistema, son mecanismos totalmente independientes y suele ser aconsejable en general.
El usuario administrador del sistema MySQL se llama root. Igual que el superusuario de los sistemas tipo UNIX.
Además del usuario root, las instalaciones nuevas de MySQL incluyen el usuario anónimo, que tiene permisos sobre la base de datos test. Si queremos, también podemos restringirlo asignándole una contraseña. El usuario anónimo de MySQL se representa por una cadena vacía. Vemos otra forma de asignar contraseñas a un usuario, desde el cliente de mysql y como usuario root:
mysql> set password for ''@'localhost' = password('nuevapasswd');La administración de privilegios y usuarios en MySQL se realiza a través de las sentencias:
• GRANT. Otorga privilegios a un usuario, en caso de no existir, se creará el usuario.
• REVOKE. Elimina los privilegios de un usuario existente.
• SET PASSWORD. Asigna una contraseña.
• DROP USER. Elimina un usuario.
5.2.1. La sentencia GRANT
5.2.1. La sentencia GRANT Dataprix 8 Octubre, 2009 - 15:45La sintaxis simplificada de grant consta de tres secciones. No puede omitirse ninguna, y es importante el orden de las mismas:
• grant lista de privilegios
• on base de datos.tabla
• to usuario
Ejemplo
Creación de un nuevo usuario al que se otorga algunos privilegios
mysql> grant update, insert, select
-> on demo.precios
-> to visitante@localhost;En la primera línea se especifican los privilegios que serán otorgados, en este caso se permite actualizar (update), insertar (insert) y consultar (select). La segunda línea especifica que los privilegios se aplican a la tabla precios de la base de datos demo. En la última línea se encuentra el nombre del usuario y el equipo desde el que se va a permitir la conexión.
El comando grant crea la cuenta si no existe y, si existe, agrega los privilegios especificados. Es posible asignar una contraseña a la cuenta al mismo tiempo que se crea y se le otorgan privilegios:
mysql> grant update, insert, select
-> on demo.precios
-> to visitante@localhost identified by ´nuevapasswd´;En la misma sentencia es posible también otorgar permisos a más de un usuario y asignarles, o no, contraseña:
mysql> grant update, insert, select
-> on demo.precios
-> to visitante@localhost,
-> yo@localhost identified by ´nuevapasswd´,
-> tu@equipo.remoto.com;5.2.2. Especificacion de lugares origen de la conexion
5.2.2. Especificacion de lugares origen de la conexion Dataprix 8 Octubre, 2009 - 16:06MySQL proporciona mecanismos para permitir que el usuario realice su conexión desde diferentes equipos dentro de una red específica, sólo desde un equipo, o únicamente desde el propio servidor.
mysql> grant update, insert, select
-> on demo.precios
-> to visitante@´%.empresa.com´;El carácter % se utiliza de la misma forma que en el comando like: sustituye a cualquier cadena de caracteres. En este caso, se permitiría el acceso del usuario 'visitante' (con contraseña, si la tuviese definida) desde cualquier equipo del dominio 'empresa.com'. Obsérvese que es necesario entrecomillar el nombre del equipo origen con el fin de que sea aceptado por MySQL. Al igual que en like, puede utilizarse el carácter ’_’.
Entonces, para permitir la entrada desde cualquier equipo en Internet, escribiríamos:
-> to visitante@´%´Obtendríamos el mismo resultado omitiendo el nombre del equipo origen y escribiendo simplemente el nombre del usuario:
-> to visitanteLos anfitriones válidos también se pueden especificar con sus direcciones IP.
to visitante@192.168.128.10
to visitante@´192.168.128.%´Los caracteres ’ %’ y ’_’ no se permiten en los nombres de los usuarios.
5.2.3. Especificacion de bases de datos y tablas
5.2.3. Especificacion de bases de datos y tablas Dataprix 8 Octubre, 2009 - 16:18Después de analizar las opciones referentes a los lugares de conexión permitidos, veamos ahora cómo podemos limitar los privilegios a bases de datos, tablas y columnas.
En el siguiente ejemplo otorgamos privilegios sobre todas las tablas de la base de datos demo.
mysql> grant all
-> on demo.*
-> to ´visitante´@´localhost´;Podemos obtener el mismo resultado de esta forma:
mysql> use demo;
mysql> grant all
-> on *
-> to ´visitante´@´localhost´;De igual modo, al especificar sólo el nombre de una tabla se interpretará quepertenece a la base de datos en uso:
mysql> use demo;
mysql> grant all
-> on precios
-> to ´visitante´@´localhost´;
| Opción | Significado |
| *.* | Todas las bases de datos y todas las tablas |
| base.* | Todas las tablas de la base de datos especificada |
| tabla | Tabla especificada de la base de datos en uso |
| * | Todas las tablas de la base de datos en uso |
5.2.4. Especificacion de columnas
5.2.4. Especificacion de columnas Dataprix 9 Octubre, 2009 - 12:55A continuación presentamos un ejemplo donde se especifican las columnas sobre las que se otorgan privilegios con el comando grant:
mysql> grant update(precio,empresa)
-> on demo.precios
-> to visitante@localhost;Podemos especificar privilegios diferentes para cada columna o grupos de columnas:
mysql> grant update(precio), select (precio, empresa)
-> on demo.precios
-> to visitante@localhost;5.2.5. Tipos de privilegios
5.2.5. Tipos de privilegios Dataprix 9 Octubre, 2009 - 13:08MySQL proporciona una gran variedad de tipos de privilegios.
• Privilegios relacionados con tablas: alter, create, delete, drop, index, insert, select, update
• Algunos privilegios administrativos: file, proccess, super reload, replication client, grant option, shutdown
• Algunos privilegios para fines diversos: lock tables, show databases, create temporary tables.
El privilegio all otorga todos los privilegios exceptuando el privilegio grant option. Y el privilegio usage no otorga ninguno, lo cual es útil cuando se desea, por ejemplo, simplemente cambiar la contraseña:
grant usage
on *.*
to visitante@localhost identified by ´secreto´;
Tipos de privilegios en MySQL
| Tipo de privilegio | Operación que permite |
| all [privileges] | Otorga todos los privilegios excepto grant option |
| usage | No otorga ningún privilegio |
| alter | Privilegio para alterar la estructura de una tabla |
| create | Permite el uso de create table |
| delete | Permite el uso de delete |
| drop | Permite el uso de drop table |
| index | Permite el uso de index y drop index |
| insert | Permite el uso de insert |
| select | Permite el uso de select |
| update | Permite el uso de update |
| file | Permite le uso de select . . . into outfile y load data infile |
| process | Permite el uso de show full procces list |
| super | Permite la ejecución de comandos de supervisión |
| reload | Permite el uso de flush |
| replication client | Permite preguntar la localización de maestro y esclavo |
| replication slave | Permite leer los binlog del maestro |
| grant option | Permite el uso de grant y revoke |
| shutdown | Permite dar de baja al servidor |
| lock tables | Permite el uso de lock tables |
| show tables | Permite el uso de show tables |
| create temporary tables | Permite el uso de create temporary table |
En entornos grandes, es frecuente encontrarse en la necesidad de delegar el trabajo de administrar un servidor de bases de datos para que otros usuarios, además del administrador, puedan responsabilizarse de otorgar privilegios sobre una base de datos particular. Esto se puede hacer en MySQL con el privilegio grant option:
mysql> grant all, grant option
-> on demo.*
-> to operador@localhost;El mismo resultado se puede obtener con la siguiente sintaxis alternativa:
mysql> grant all
-> on demo.*
-> to operador@localhost
-> with grant option;
De este modo el usuario operador podrá disponer de todos los privilegios sobre la base de datos demo, incluido el de controlar el acceso a otros usuarios.
5.2.6. Opciones de encriptación
5.2.6. Opciones de encriptación Dataprix 9 Octubre, 2009 - 13:36| * Secure Sockets Layer |
MySQL puede establecer conexiones seguras encriptándolas mediante el protocolo SSL*; de esta manera, los datos que se transmiten (tanto la consulta, en un sentido, como el resultado, en el otro) entre el cliente y el servidor estarán protegidos contra intrusos. Para especificar que un usuario debe conectarse obligatoriamente con este protocolo, se utiliza la cláusula require:
mysql> grant all
-> on *.*
-> to visitante@localhost
-> require ssl;Las conexiones encriptadas ofrecen protección contra el robo de información, pero suponen una carga adicional para el servicio, que debe desencriptar la petición del cliente y encriptar la respuesta (además de un proceso más largo de negociación al conectar), por ello, merman el rendimiento del SGBD.
s
5.2.7. Limites de uso
5.2.7. Limites de uso Dataprix 9 Octubre, 2009 - 13:42Los recursos físicos del servidor siempre son limitados: si se conectan muchos usuarios al mismo tiempo al servidor y realizan consultas o manipulaciones de datos complejas, es probable que pueda decaer el rendimiento notablemente. Una posible solución a este problema es limitar a los usuarios el trabajo que pueden pedir al servidor con tres parámetros:
• Máximo número de conexiones por hora.
• Máximo número de consultas por hora.
• Máximo número de actualizaciones por hora.
La sintaxis de estas limitaciones es como se muestra a continuación:
mysql> grant all
-> on *.*
-> to
-> with MAX_CONECTIONS_PER_HOUR 3
-> MAX_QUERIES_PER_HOUR 300
-> MAX_UPDATES_PER_HOUR 30;5.2.8. Eliminar privilegios
5.2.8. Eliminar privilegios Dataprix 9 Octubre, 2009 - 13:45El comando revoke permite eliminar privilegios otorgados con grant a los usuarios. Veamos un ejemplo representativo:
revoke all
on *.*
from visitante@localhost;Al ejecutar este comando se le retiran al usuario visitante todos sus privilegios sobre todas las bases de datos, cuando se conecta desde localhost.
El comando anterior no retira todos los privilegios del usuario visitante, sólo se los retira cuando se conecta desde localhost. Si el usuario se conecta desde otra localidad (y tenía permiso para hacerlo) sus privilegios permanecen intactos.
5.2.9. Eliminar usuarios
5.2.9. Eliminar usuarios Dataprix 9 Octubre, 2009 - 13:47Antes de proceder a la eliminación de un usuario, es necesario asegurarse de que se le han quitado primero todos sus privilegios. Una vez asegurado este detalle, se procede a eliminarlo mediante el comando drop user:
mysql> drop user visitante;5.2.10. La base de datos de privilegios: mysql
5.2.10. La base de datos de privilegios: mysql Dataprix 9 Octubre, 2009 - 13:51MySQL almacena la información sobre los usuarios y sus privilegios en una base de datos como cualquier otra, cuyo nombre es mysql. Si exploramos su estructura, entenderemos la manera como MySQL almacena la información de sus usuarios y privilegios:

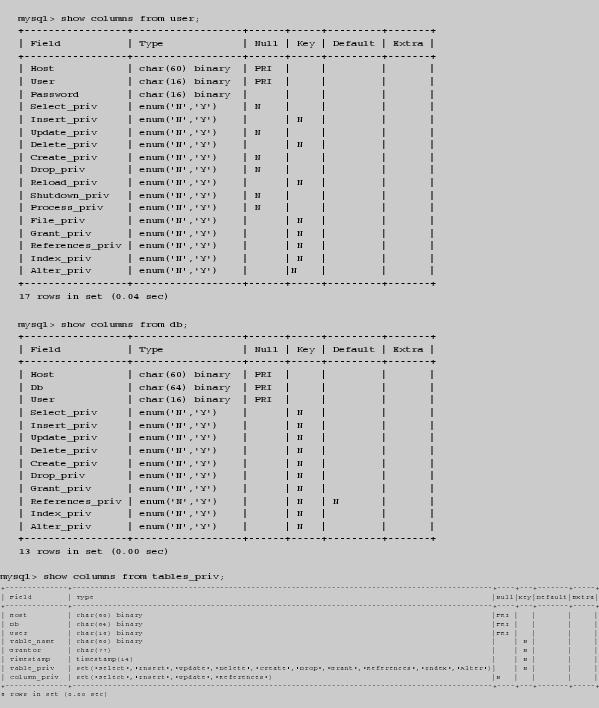
Es posible realizar modificaciones directamente sobre estas tablas y obtener los mismos resultados que si utilizáramos los comandos grant, revoke, set password o drop user:
mysql> update user
-> set Password = password(´nuevapasswd´)
-> where User =´visitante´ and Host = ´localhost´;
mysql> flush privileges;El comando flush privileges solicita a MySQL que vuelva a leer las tablas de privilegios. En el momento de ejecutarse, el servidor lee la información de estas tablas sobre privilegios. Pero si se han alterado las tablas manualmente, no se enterará de los cambios hasta que utilicemos el comando flush privileges.
| Tabla | Contenido |
| user | Cuentas de usuario y sus privilegios globales |
| db | Privilegios sobres bases de datos |
| tables_priv | Privilegios sobre tablas |
| columns_priv | Privilegios sobre columnas |
| host | Privilegios de otros equipos anfitriones sobre bases de datos |
El acceso directo a las tablas de privilegios es útil en varios casos; por ejemplo, para borrar un usuario del sistema en las versiones de MySQL anteriores a la 4.1.1:
mysql> delete from user
-> where User = ´visitante´ and Host = ´localhost´;
mysql> flush privileges;No es posible eliminar mediante un solo comando revoke todos los privilegios de un usuario.
Ejemplo
Se otorgan derechos a un usuario con dos comandos grant.
Observando el contenido de la base de datos de privilegios, podemos entender el comportamiento de los comandos grant y revoke. Primero asignamos privilegios para usar el comando select al usuario visitante con dos comandos grant: el primero de ellos le permite el ingreso desde el servidor nuestra-ong.org y el segundo le otorga el mismo tipo de privilegio, pero desde cualquier equipo en Internet.
mysql> grant select
-> on *.*
-> to visitante@nuestra-ong.org;
Query OK, 0 rows affected (0.01 sec)
mysql> grant select
-> on *.*
-> to visitante@´%´;
Query OK, 0 rows affected (0.00 sec)Consultando la tabla user de la base de datos de privilegios, podemos observar los valores ’Y’ en la columna del privilegio select.
mysql> select user,host,select_priv from user
-> where user = ´visitante´;+-----------+----------------------+----------------+
| user | host | select_priv |
+-----------+----------------------+----------------+
| visitante | nuestra-ong.org | Y |
| visitante | % | Y |
+-----------+----------------------+----------------+
2 rows in set (0.00 sec)Ahora solicitamos eliminar el privilegio select de todas las bases de datos y de todos los equipos en Internet.
mysql> revoke all
-> on *.*
-> from visitante@´%´;
Query OK, 0 rows affected (0.00 sec)
mysql> select user,host,select_priv from user
-> where user = ´visitante´;+-----------+------------------+-------------+
| user | host | select_priv |
+-----------+------------------+-------------+
| visitante | nuestra-ong.org | Y |
| visitante | % | N |
+-----------+------------------+-------------+
2 rows in set (0.01 sec)En la tabla user observamos que, efectivamente, se ha eliminado el privilegio para visitante@’%’ pero no para 'visitante@nuestra-ong.org'. MySQL considera que son direcciones diferentes y respeta los privilegios otorgados a uno cuando se modifica otro.
5.3. Copias de seguridad
5.3. Copias de seguridad Dataprix 13 Octubre, 2009 - 22:40Ningún sistema es perfecto ni está a salvo de errores humanos, cortes en el suministro de la corriente eléctrica, desperfectos en el hardware o errores de software; así que una labor más que recomendable del administrador del servidor de bases de datos es realizar copias de seguridad y diseñar un plan de contingencia. Se deben hacer ensayos del plan para asegurar su buen funcionamiento y, si se descubren anomalías, realizar los ajustes necesarios.
No existe una receta universal que nos indique cómo llevar nuestras copias de seguridad de datos. Cada administrador debe diseñar el de su sistema de acuerdo a sus necesidades, recursos, riesgos y el valor de la información.
MySQL ofrece varias alternativas de copia de seguridad de la información. La primera que podemos mencionar consiste simplemente en copiar los archivos de datos. Efectivamente, es una opción válida y sencilla.
En primera instancia son necesarios dos requisitos para llevarla a cabo:
• Conocer la ubicación y estructura del directorio de datos.
• Parar el servicio MySQL mientras se realiza la copia.
En cuanto a la ubicación y estructura del directorio, recordemos que la distribución de MySQL ubica el directorio de datos en /usr/local/mysql/var, las distribuciones GNU/Linux basadas en paquetes como DEB o RPM ubican, por lo general, los datos en /var/lib/mysql.
Si por algún motivo no encontramos el directorio de datos, podemos consultarlo a MySQL. El comando show variables nos muestra todas las variables disponibles, basta realizar un filtro con la clausula like:
mysql> show variables like ´datadir´;
+---------------+-----------------+
| Variable_name | Value |
+---------------+-----------------+
| datadir | /var/lib/mysql/ |
+---------------+-----------------+
1 row in set (0.00 sec)Una vez ubicados los archivos, detenemos la ejecución del servidor: un modo sencillo de asegurarnos de que la base de datos no será modificada mientras terminamos la copia:
$ mysqladmin -u root -p shutdownFinalmente, copiamos el directorio completo con todas las bases de datos:
$ cp -r /var/lib/mysql/ /algun_dir/Por supuesto podemos elegir otras formas de copiarlo o comprimirlo, de acuerdo a nuestras preferencias y necesidades.
$ tar czf mysql-backup.tar.gz /var/lib/mysqlSi queremos copiar sólo una base de datos, copiamos el directorio con el mismo nombre de la base de datos:
$ cp -r /var/lib/mysql/demo/ /algun_dir/respaldo_demo/También es posible hacer copia de seguridad de una sola tabla.
$ cp -r /var/lib/mysql/demo/productos.* / algun_dir/backup_demo/Como podemos observar, la organización de la base de datos en MySQL es muy simple:
• Todas las bases de datos se almacenan en un directorio, llamado el directorio de datos(datadir).
• Cada base de datos se almacena como un subdirectorio del directorio de datos.
• Cada tabla se almacena en un archivo, acompañada de otros archivos auxiliares con el mismo nombre y diferente extensión.
El problema de este mecanismo es que debemos detener el servicio de bases de datos mientras realizamos el respaldo.
5.3.1. mysqlhotcopy
5.3.1. mysqlhotcopy Dataprix 13 Octubre, 2009 - 22:47Un mecanismo que permite realizar la copia de los archivos del servidor sin necesidad de detener el servicio es el script 'mysqlhotcopy'. El script está escrito en Perl y bloquea las tablas mientras realiza el respaldo para evitar su modificación. Se usa de la siguiente manera:
$ mysqlhotcopy demo /algun_directorioEn este caso, creará un directorio /algun_directorio/demo con todos los archivos de la base de datos.
El comando mysqlhotcopy puede recibir sólo el nombre de una base de datos como parámetro:
$ mysqlhotcopy demoEn este caso, creará un directorio /var/lib/mysql/demo_copy.
Este método no funciona para tablas con el mecanismo de almacenamiento tipo InnoDB.
5.3.2. mysqldump
5.3.2. mysqldump Dataprix 13 Octubre, 2009 - 22:58Las dos opciones anteriores representan copias binarias de la base de datos. El comando mysqldump, en cambio, realiza un volcado de las bases de datos pero traduciéndolas a SQL; es decir, entrega un archivo de texto con todos los comandos necesarios para volver a reconstruir las bases de datos, sus tablas y sus datos. Es el método más útil para copiar o distribuir una base de datos que deberá almacenarse en otros servidores.
$ mysqldump demo > demo.sqlEl comando mysqldump ofrece multitud de parámetros para modificar su comportamiento o el tipo de volcado generado: por defecto, genera sentencias SQL, pero puede generar ficheros de datos tipo CSV u otros formatos. También podemos especificarle que haga el volcado de todas las bases de datos o que sólo vuelque los datos y no la creación de las tablas, etc.
Las primeras líneas del archivo demo.sql según el ejemplo anterior tendrían el siguiente aspecto:
~$ mysqldump demo | head -25
-- MySQL dump 8.21
--
-- Host: localhost Database: demo
---------------------------------------------------------
-- Server version 3.23.49-log
--
-- Table structure for table ´ganancia´
--
DROP TABLE IF EXISTS ganancia;
CREATE TABLE ganancia (
venta enum(´Por mayor´,´Por menor´) default NULL,
factor decimal(4,2) default NULL
) TYPE=MyISAM;
--
Dumping data for table ´ganancia´
--
INSERT INTO ganancia VALUES (´Por mayor´,1.05);
INSERT INTO ganancia VALUES (´Por menor´,1.12);--La ventaja de utilizar mysqldump es que permite que los archivos puedan ser leídos (y modificados) en un simple editor de textos, y pueden ser utilizados para migrar la información a otro SGBD que soporte SQL. Además soporta todos los tipos de tablas. La desventaja es que su procesamiento es lento y los archivos que se obtienen son muy grandes.
5.3.3. Restaurar a partir de respaldos
5.3.3. Restaurar a partir de respaldos Dataprix 13 Octubre, 2009 - 23:06En algún momento, sea por el motivo que sea, necesitaremos realizar la restauración de nuestras bases de datos.
Si tenemos una copia binaria del directorio de datos, bastará con copiarla al directorio original y reiniciar el servidor:
# mysqladmin -u root -p shutdown
# cp /algun_dir/respaldo-mysql/* /var/lib/mysql
# chown -R mysql.mysql /var/lib/mysql
# mysql_safe
Es importante restaurar también el dueño y el grupo de los archivos de datos, para tener los accesos correctamente establecidos. En este ejemplo se adopta el supuesto que el usuario mysql es el que ejecuta el servidor mysqld.
La restauración de un archivo SQL obtenido con mysqldump, se realiza desde el cliente mysql, la base de datos debe existir, ya que el archivo demo.sql no la crea por defecto.
$ mysql demo -u root -p < demo.sql5.4. Reparación de tablas
5.4. Reparación de tablas Dataprix 13 Octubre, 2009 - 23:34En determinadas circunstancias de uso muy frecuente, como la inserción y borrado masivos de datos, coincidiendo con bloqueos del sistema o llenado del espacio en disco u otras circunstancias, es posible que una tabla o algunos de sus índices se corrompan.
Podemos consultar el estado de integridad de una tabla con el comando check table, que realiza algunas verificaciones sobre la tabla en busca de errores y nos entrega un informe con las siguientes columnas de información:
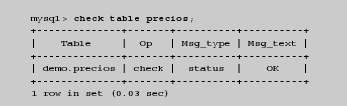
La columna Op describe la operación que se realiza sobre la tabla. Para el comando check table esta columna siempre tiene el valor check porque ésa es la operación que se realiza. La columna Msg_type pude contener uno de los valores status, error, info, o warning. Y la columna Msg_text es el texto que reporta de alguna situación encontrada en la tabla.
Es posible que la información entregada incluya varias filas con diversos mensajes, pero el último mensaje siempre debe ser el mensaje OK de tipo status.
En otras ocasiones check table no realizará la verificación de tabla, en su lugar entregará como resultado el mensaje Table is already up to date, que significa que el gestor de la tabla indica que no hay necesidad de revisarla.
MySQL no permite realizar consultas sobre una tabla dañada y enviará un mensaje de error sin desplegar resultados parciales:
mysql> select * from precios;
ERROR 1016: No puedo abrir archivo: ’precios.MYD’. (Error: 145)Para obtener información del significado del error 145, usaremos la utilidad en línea de comandos perror:
$ perror 145
145 = Table was marked as crashed and should be repaired Después de un mensaje como el anterior, es el momento de realizar una verificación de la integridad de la tabla para obtener el reporte.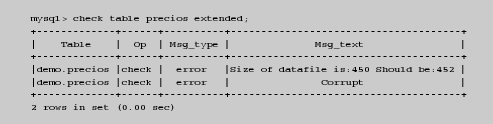
En este caso localizamos dos errores en la tabla. La opción extended es uno de los cinco niveles de comprobación que se pueden solicitar para verificar una tabla.
| Tipo | Significado |
| quick | No revisa las filas en busca de referencias incorrectas. |
| fast | Solamente verifica las tablas que no fueron cerradas adecuadamente. |
| changed | Verifica sólo las tablas modificadas desde la última verificación o que no se han cerrado apropiadamente. |
| medium | Revisa las filas para verificar que los ligados borrados son correctos, verifica las sumas de comprobación de las filas. |
| extended | Realiza una búsqueda completa en todas las claves de cada columna. Garantiza el 100% de la integridad de la tabla. |
La sentencia repair table realiza la reparación de tablas tipo MyISAM corruptas: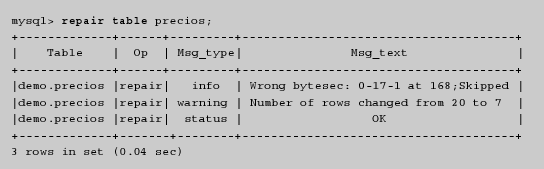
El segundo mensaje informa de la pérdida de 13 filas durante el proceso de reparación. Esto significa, como es natural, que el comando repair table es útil sólo en casos de extrema necesidad, ya que no garantiza la recuperación total de la información. En la práctica, siempre es mejor realizar la restauración de la información utilizando las copias de seguridad. En caso de desastre, se debe conocer el motivo que origina la corrupción de las tablas y tomar las medidas adecuadas para evitarlo. En lo que respecta a la estabilidad de MySQL, se puede confiar en que muy probablemente nunca será necesario utilizar el comando repair table.
El comando optimize table puede también realizar algunas correcciones sobre una tabla.
5.4.1. myisamchk
5.4.1. myisamchk Dataprix 14 Octubre, 2009 - 15:35El programa myisamchk es una utilidad en línea de comandos que se incluye con la distribución de MySQL y sirve para reparar tablas tipo MyISAM. Para utilizarlo con seguridad el servidor no debe estar ejecutándose y se recomienda realizar un respaldo del directorio de datos antes de su utilización.
Recibe como parámetro principal los archivos .MYI correspondientes a las tablas que hay que revisar; es decir, myisamchk no conoce la ubicación del directorio de datos. Por ejemplo, si el directorio de datos está ubicado en /val/ lib/mysql, las siguientes serían dos maneras de realizar una comprobación de los archivos de la base de datos demo:
# myisamchk /var/lib/mysql/demo/*.MYI
# cd /var/lib/lib/mysql/demo
# myisamchk *.MYI Se pueden revisar todas las bases de datos utilizando ’*’ para denominar el directorio de la base de datos:
# myisamchk /var/lib/mysql/*/*.MYI
Para realizar una comprobación rápida, el manual sugiere utilizar el siguiente comando:
# myisamchk --silent --fast *.MYI Y para realizar la corrección de las tablas corruptas, el manual sugiere la sintaxis siguiente:
| Nota |
| En la práctica con estas opciones se logran corregir los errores más comunes. Para conocer otras opciones de recuperación con myisamchk, podéis consultar el manual que acompaña a la distribu- ción de MySQL. |
# myisamchk --silent --force --update-state -O key_buffer=64M \ -O sort_buffer=64M -O read_buffer=1M -O write_buffer=1M *.MYI Las opciones dadas por -O se refieren al uso de memoria, que permiten acelerar de forma notoria el proceso de reparación.
--force reinicia myisamchk con el parámetro --recover cuando encuentra algún error.
--updatestate almacena información sobre el resultado del análisis en la tabla MYI.
5.5. Análisis y optimización
5.5. Análisis y optimización Dataprix 14 Octubre, 2009 - 15:38El diseño de MySQL le permite funcionar con un rendimiento notable, sin embargo, se pueden cometer fácilmente errores que disminuyan la capacidad de respuesta del servidor. También se pueden realizar algunos ajustes a la configuración de MySQL que incrementan su rendimiento.
5.5.1. Indexación
5.5.1. Indexación Dataprix 14 Octubre, 2009 - 15:46La indexación es la principal herramienta para optimizar el rendimiento general de cualquier base de datos. Es también la más conocida por los usuarios de servidores MySQL y, paradójicamente, su no utilización es una de las principales causas de bajo rendimiento en servidores de bases de datos.
Muchos administradores y diseñadores simplemente parecen olvidar usar índices para optimizar los accesos a las bases de datos. Por otro lado, algunas personas tienden a indexar todo, esperando que de esta manera el servidor acelere cualquier tipo de consulta que se le solicite. En realidad, esta práctica puede causar una disminución en el rendimiento, sobre todo en lo que respecta a inserciones y modificaciones.
Para ver las ventajas de utilizar índices, analizaremos en primer término una simple búsqueda en una tabla sin índice alguno:
• El constante acceso de escritura de una tabla la mantiene desordenada.
• La ordenación de una tabla es una operación costosa: el servidor tendría que detenerse un tiempo considerable para ordenar sus tablas.
• Muchas tablas tienen más de un criterio de ordenación: ordenar según una columna implica desordenar otra.
• La inserción y eliminación de datos sin alterar el orden en una tabla es costosa: la inserción de un registro en una tabla grande implicaría una larga espera en la actualización de la misma.
• Si se opta por mantener la tabla desordenada (que es la opción más viable), una búsqueda implicaría forzosamente un recorrido secuencial (también denominado full scan), registro por registro.
El uso de índices en la ordenación de las bases de datos ofrece las ventajas siguientes:
• Permite ordenar las tablas por varios criterios simultáneamente.
• Es menos costoso ordenar un archivo índice, porque incluye sólo referencias a la información y no la información en sí.
• El coste de inserción y eliminación es menor.
• Con los registros siempre ordenados se utilizaran algoritmos mucho más eficientes que el simple recorrido secuencial en las consultas.
El uso de índices también comporta alguna desventaja:
• Los índices ocupan espacio en disco.
• Aún teniendo registros pequeños, el mantener en orden un índice disminuye la velocidad de las operaciones de escritura sobre la tabla.
A pesar de estos inconvenientes, la utilización de índices ofrece mayores ventajas que desventajas, sobre todo en la consulta de múltiples tablas, y el aumento de rendimiento es mayor cuanto mayor es la tabla.
Consideremos por ejemplo una consulta sobre las tablas A, B, y C, independientemente del contenido de la cláusula where, las tres tablas se deben de combinar para hacer posible posteriormente el filtrado según las condiciones dadas:
select *
from A,B,C
where A.a = B.b
and B.b = C.c;Consideremos que no son tablas grandes, que no sobrepasan los 1.000 registros. Si A tiene 500 registros, B tiene 600 y C 700, la tabla resultante de la consulta anterior tendrá 210 millones de registros. MySQL haría el producto cartesiano de las tres tablas y, posteriormente, se recorrería la relación resultante para buscar los registros que satisfacen las condiciones dadas, aunque al final el resultado incluya solamente 1.000 registros.
Si utilizamos índices MySQL los utilizaría de una forma parecida a la siguiente:
• Tomaría cada uno de los registros de A.
• Por cada registro de A, buscaría los registros en B que cumpliesen con la condición A.a = B.b. Como B está indexado por el atributo 'b', no necesitaría hacer el recorrido de todos los registros, simplemente accedería directamente al registro que cumpliese la condición.
• Por cada registro de A y B encontrado en el paso anterior, buscaría los registros de C que cumpliesen la condición B.b = C.c. Es el mismo caso que en el paso anterior.
Comparando las dos alternativas de búsqueda, la segunda ocuparía cerca del 0,000005% del tiempo original. Por supuesto que sólo se trata de una aproximación teórica, pero adecuada para comprender el efecto de los índices en las consultas sobre bases de datos.
5.5.2. Equilibrio
5.5.2. Equilibrio Dataprix 14 Octubre, 2009 - 16:01El índice ideal debería tener las siguientes características:
• Los registros deberían ser lo más pequeños posible.
• Sólo se debe indexar valores únicos.
Analicemos cada recomendación:
• Cuanto más pequeños sean los registros, más rápidamente se podrán cambiar de lugar (al insertar, modificar o borrar filas), además, en un momento dado, el índice puede permanecer en memoria. Consideremos las dos definiciones posibles:
create table Empresa(
nombre char(30),
teléfono char(20),
index (nombre)
);En esta tabla el índice se realiza sobre nombre, que es un campo de 30 caracteres, y se utiliza como clave para hacer los 'joins' con otras tablas.
Ahora considérese la siguiente alternativa:
create table Empresa(
id int ,
nombre char(30),
teléfono char(20),
index (id)
);Se agrega una columna que servirá como identificador de la empresa. Desde el punto de vista de rendimiento implica una mejora, ya que el índice se realiza sobre números enteros, por lo tanto, ocupará menos espacio y funcionará más rápido.
Cuanto más pequeña sea la columna indexada mayor velocidad se tendrá en el acceso a la tabla.• Consideremos el índice siguiente, creado para disminuir la necesidad de efectuar accesos a la tabla:
create table Empresa(
nombre char(30),
crédito enum{´SI´,´NO´},
index(crédito)
);Si consideramos que un índice se crea para evitar la necesidad de recorrer la tabla, veremos que el índice creado es prácticamente inútil, ya que alguno de los valores ocurre el 50% o más de las veces: para encontrar todos los resultados hay que recorrer gran parte de la tabla. MySQL no utiliza los índices que implican un 30% de ocurrencias en una tabla.
Aun así, y exceptuando casos exagerados como este último, puede ser interesante indexar una tabla por algún atributo que no sea único, si ese atributo se utiliza para ordenar los resultados. También puede ser conveniente crear un índice por varios atributos simultáneamente si se usan todos en alguna consulta en la cláusula ORDER BY.
Cuanto menor sea la repetición de valores en una columna indexada, menor será la necesidad de acceder a la tabla y más eficiente será el índice.5.5.3. La cache de consultas de MySQ
5.5.3. La cache de consultas de MySQ Dataprix 16 Octubre, 2009 - 10:31| * Memoria intermedia de acceso rápido. |
El servidor MySQL incluye la posibilidad de utilizar una cache* con los resultados de las últimas consultas para acelerar la velocidad de respuesta. Esta solución es útil cuando las tablas tienen relativamente pocos cambios y se realizan los mismos tipos de consultas. El funcionamiento de la cache se basa en las premisas siguientes:
• La primera vez que se recibe una consulta se almacena en la cache.
• Las siguientes veces la consulta se realiza primero en la cache; si tiene éxito, el resultado se envía inmediatamente.
La cache tiene las siguientes características:
• El servidor compara el texto de la consulta; aunque técnicamente sea igual si difiere en uso de mayúsculas-minúsculas o cualquier otro cambio, no se considera la solicitud idéntica y no será tratada por la cache.
• Si alguna tabla incluida en alguna consulta cambia, el contenido de la consulta es eliminado de la cache.
La configuración de la cache se realiza a través de variables globales:
• query_cache_limit. No almacena resultados que sobrepasen dicho tamaño. Por omisión es de 1M.
• query_cache_size. Tamaño de la memoria cache expresada en bytes. Por omisión es 0; es decir, no hay cache.
• query_cache_type. Puede tener tres valores: ON , OFF o DEMAND
| Valor | Tipo | Significado |
| 0 | OFF | Cache desactivado |
| 1 | ON | Cache activado |
| 2 | DEMAND | Sólo bajo solicitud explicita |
Cuando la cache del servidor esta en modo DEMAND, se debe solicitar explícitamente que la consulta utilice o no la cache:
select sql_cache
select sql_no_cache 5.6. Replicacion
5.6. Replicacion Dataprix 16 Octubre, 2009 - 11:00La replicación es la copia sincronizada entre dos servidores de bases de datos de forma que cualquiera de los dos puede entregar los mismos resultados a sus clientes.
MySQL incluye la posibilidad de replicación con las siguientes características:
• Funciona con el esquema maestro-esclavo: existe un servidor maestro que lleva el control central y uno o varios servidores esclavos que se mantienen sincronizados con el servidor maestro.
• La réplica se realiza mediante un registro de los cambios realizados en la base de datos: no se realizan las copias de las bases de datos para mantenerlas sincronizadas, en su lugar se informa de las operaciones realizadas en el servidor maestro (insert, delete , update ...) para que las realicen a su vez los servidores esclavos.
• No es posible realizar cambios en los servidores esclavos, son exclusivamente para consultas.
Este sencillo esquema permite la creación de replicas sin mayores complicaciones obteniendo los siguientes beneficios:
• Se distribuye la carga de trabajo.
• El sistema es redundante, por lo que en caso de desastre hay menos probabilidades de perder los datos.
• Es posible realizar los respaldos de un esclavo sin interrumpir el trabajo del servidor maestro.
5.6.1. Preparacion previa
5.6.1. Preparacion previa Dataprix 16 Octubre, 2009 - 11:06El equipo maestro debe tener acceso por red. Antes de realizar la configuración de los servidores maestro y esclavo es necesario realizar las siguientes tareas:
• Asegurarse de que en ambos está instalada la misma versión de MySQL.
• Asegurarse de que ninguno de los servidores atenderá peticiones durante el proceso de configuración.
• Asegurarse de que las bases de datos del servidor maestro han sido copiadas manualmente en el servidor esclavo, de manera que en ambos se encuentre exactamente la misma información.
• Asegurarse de que ambos atienden conexiones vía TCP/IP. Por seguridad, esta opción está desactivada por omisión. Para activarla se debe comentar la línea skip_networking en el archivo de configuración /etc/my.cnf
5.6.2. Configuracion del servidor maestro
5.6.2. Configuracion del servidor maestro Dataprix 16 Octubre, 2009 - 11:17En el servidor maestro creamos una cuenta de usuario con permisos de replicación para autorizar, en el servidor maestro, al nuevo usuario para realizar réplicas:
mysql> grant replication slave
-> on *.*
-> to replicador@esclavo.empresa.com identified by ´secreto´;Replicador es el nombre del nuevo usuario.
Esclavo.empresa.com es la dirección del servidor esclavo.
’Secreto’ es la contraseña.
El servidor maestro llevará un archivo de registro 'binlog' donde se registrarán todas las solicitudes de actualización que se realicen en las bases de datos. Para activar la creación de este archivo debemos editar el archivo /etc/my.cnf y agregar las siguientes líneas en la sección [mysqld]:
[mysqld]
log-bin
server-id = 1El servidor maestro debe identificarse con un id, en este caso será el número 1. a continuación, reiniciamos el servidor:
/etc/init.d/mysql restartFinalmente, consultamos el nombre del archivo 'binlog' y la posición de compensación (estos datos son necesarios para configurar el esclavo):
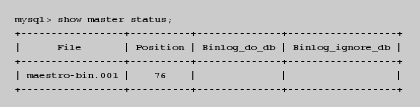
5.6.3. Configuracion del servidor esclavo
5.6.3. Configuracion del servidor esclavo Dataprix 16 Octubre, 2009 - 11:24En el servidor esclavo, editamos el archivo /etc/my.cnf y agregamos, al igual que en el maestro, la activación del archivo 'binlog' y un identificador del servidor (que debe ser distinto del identificador del servidor maestro):
[mysqld]
log-bin
server-id = 2Reiniciamos el servidor esclavo:
# /etc/init.d/mysql restartConfiguramos los datos del maestro en el servidor esclavo:.
mysql> change master to
-> master_host = ´maestro.empresa.com´,
-> master_user = ´replicador´,
-> master_password = ´secreto´,
-> master_log_file = ´maestro-log.001´,
-> master_log_pos = 76;El último paso es iniciar el servidor esclavo:
mysql> start slave;Y ya tendremos el servidor esclavo funcionando.
5.7. Importacion y exportacion de datos
5.7. Importacion y exportacion de datos Dataprix 16 Octubre, 2009 - 11:34En muchas ocasiones es necesario mover datos de una aplicación a otra, para ello son necesarios formatos estándares que puedan ser escritos por la aplicación origen y leídos por la aplicación destino. El más simple de esos formatos es el texto plano, donde cada archivo es una tabla, cada fila es un registro y los valores de los campos se separan por tabuladores.
MySQL puede leer este tipo de archivos, incluyendo valores nulos representados por ’\N’(N mayúscula).s
Utilizando el cliente mysql, podemos introducir los datos del archivo local proveedores.txt en la tabla proveedores:
mysql> load data local infile ´proveedores.txt´
-> into table proveedores;Si se omite la palabra local, MySQL buscará el archivo en el servidor y no en el cliente.
En un archivo se pueden entrecomillar los campos, utilizar comas para separarlos y terminar las líneas con los caracteres ’\r\n’ (como en los archivos Windows). El comando load data tiene dos clausulas opcionales, fields, en el que se especifican estos parámetros.
mysql> load data local infile ´prooveedores.txt´
-> fields terminated by ´,´
-> enclosed by ´"´
-> lines terminated by ´\r\n´;La opción enclosed by puede tener la forma optionaly enclosed by, en caso de que los campos numéricos no sean delimitados.
Además pueden omitirse las primeras lineas del archivo si contienen información de encabezados:
mysql> load data local infile ´proveedores.txt´
-> ignore 1 lines;5.7.1. mysqlimport
5.7.1. mysqlimport Dataprix 16 Octubre, 2009 - 11:41La utilidad mysqlimport que se incluye en la distribución puede realizar el mismo trabajo que load data. Estos son algunos de sus parámetros:
mysqlimport basededatos archivo.txtEstos son algunos de los argumentos de mysqlimport para realizar las tareas equivalentes a la sentencia load data:
--fields-terminated-by=
--fields-enclosed-by=
--fields-optionally-enclosed-by=
--fields-escaped-by=
--lines-terminated-by=La forma más simple para exportar datos es redireccionando la salida del cliente mysql. El parámetro -e permite ejecutar un comando en modo de procesamiento por lotes. MySQL detecta si la salida es en pantalla o está redireccionada a un archivo y elige la presentación adecuada: con encabezados y líneas de separación para la salida en pantalla, y sin encabezados y con tabuladores para un archivo:
$ mysql demo -e "select * from proveedores" > proveedores.txtLa sentencia select también cuenta con una opción para realizar la tarea inversa de la sentencia load data:
mysql> select *
-> into outfile "/tmp/proveedores.txt"
-> fields termitated by ´,´
-> optionaly enclosed by ´"´
-> lines termitates by ´\n´
-> from proveedores;5.7.2. mysqldump
5.7.2. mysqldump Dataprix 16 Octubre, 2009 - 11:46La utilidad mysqldump realiza el volcado de bases de datos y puede utilizarse para transportar datos de una base a otra que también entienda SQL. Sin embargo, el archivo debe ser editado antes de utilizarse, ya que algunas opciones son exclusivas de MySQL. Por lo general, basta con eliminar el tipo de tabla que se especifica al final de un comando create table.
El siguiente comando realiza el vaciado completo de la base de datos demo:
$ mysqldump demo > demo.sqlEn algunos casos, los comandos insert son suficientes y no necesitamos las definiciones de las tablas.
El siguiente comando realiza un vaciado de la tabla proveedores de la base de datos demo filtrando la salida con el comando grep de UNIX que selecciona sólo las líneas que contienen la palabra INSERT. De este modo, el archivo proveedores-insert.txt contiene exclusivamente comandos insert:
$ mysqldump demo proveedores | grep INSERT