7. Administración de PostgreSQL
7. Administración de PostgreSQL Dataprix 27 Octubre, 2009 - 10:33En las tareas administrativas como la instalación, la gestión de usuarios, las copias de seguridad, restauraciones y el uso de prestaciones internas avanzadas, es donde realmente se aprecian las diferencias entre gestores de bases de datos. PostgreSQL tiene fama de ser más complejo de administrar que sus competidores de código abierto, lo que se debe, sobre todo, a que ofrece más prestaciones (o más complejas).
| Bibliografía |
| El manual de PostgreSQL es la referencia principal que se debe tener siempre a mano para encontrar posibilidades y resolver dudas. En especial se recomienda leer los siguientes capítulos: Capítulo III. Server Administration. Capítulo V. Server Programming. Capítulo VII. Internals. De la misma manera, también son muy útiles las listas de correo que se describen en el sitio oficial www.postgresql.org. |
El contenido de los siguientes apartados contempla las opciones de uso común para la administración de un servidor PostgreSQL. Existen tantas alternativas que no es posible incluirlas todas en este módulo, por lo que sólo se presentarán algunos temas de importancia para el administrador, desde una perspectiva general, que permita obtener una visión global de las posibilidades prácticas de las herramientas administrativas.
7.1. Instalacion
7.1. Instalacion Dataprix 27 Octubre, 2009 - 10:51PostgreSQL está disponible para la mayoría de distribuciones de GNU/Linux. Su instalación es tan sencilla como ejecutar el instalador de paquetes correspondiente.
En Debian, el siguiente procedimiento instala el servidor y el cliente respectivamente:
# apt-get install postgresql
# apt-get install postgresql-clientEn distribuciones basadas en RPM, los nombres de los paquetes son un poco diferentes:
# rpm -Uvh postgresql-server
# rpm -Uvh postgresql
| Notación |
|---|
| Además del start también po- dremos utilizar los parámetros restart, stop, reload que permiten reiniciar, detener y recargar el servidor (releyendo su configuración), respectivamente. |
Una vez instalado, se escribirá un script de inicio que permite lanzar y apagar el servicio PostgreSQL; de este modo, para iniciar el servicio, deberemos ejecutar el siguiente comando:
# /etc/init.d/postgresql start
Si se desea realizar una instalación a partir del código fuente, puede obtenerse del sitio oficial www.postgresql.org. A continuación, se describe el proceso de instalación de forma muy simplificada. En la práctica podrán encontrarse algunas diferencias; lo más recomendable es leer cuidadosamente la documentación incluida en los archivos INSTALL y README. Cualquier duda no resuelta por la documentación, puede consultarse en la lista de distribución.
# tar xzvf postgresql-7.4.6.tar.gz
# cd postgresql-7.4.6
# ./configure
# make
# make install
Con este proceso se instala la versión 7.4.6. El archivo se descomprime utilizando tar. Dentro del directorio recién creado se ejecuta configure, que realiza una comprobación de las dependencias de la aplicación. Antes de ejecutar configure, debemos instalar todos los paquetes que vamos a necesitar.
La compilación se realiza con make y, finalmente, los binarios producidos se copian en el sistema en los lugares convenientes con make install.
Después de instalados los binarios, se debe crear el usuario postgres (responsable de ejecutar el proceso postmaster) y el directorio donde se almacenarán los archivos de las bases de datos.
# adduser postgres
# cd /usr/local/pgsql
# mkdir data
# chown postgres data
| initdb |
|---|
| El ejecutable initdb realiza el procedimiento necesario para inicializar la base de datos de postgres, en este caso, en el directorio /usr/local/pgsql/data. |
Una vez creado el usuario postgres, éste debe inicializar la base de datos:
# su - postgres
# /usr/local/pgsql/initbd -D /usr/local/pgsql/data
| Bibliografía |
|---|
| El proceso de compilación tiene múltiples opciones que se explican en la documentación incluida con las fuentes. |
El postmaster ya está listo para ejecutarse manualmente:
# /usr/local/pgsql/postmaster -D /usr/local/pgsql/data
7.1.1. Internacionalizacion
7.1.1. Internacionalizacion Dataprix 27 Octubre, 2009 - 11:06Por omisión, PostgreSQL no está compilado para soportar mensajes en español, por lo que es necesario compilarlo a partir de las fuentes incluyend las siguientes opciones de configuración, para que tanto el servidor como el cliente psql adopten la configuración establecida por el programa setlocales y las variables de entorno respectivas:
# configure --enable-nls -enable-locale
7.2. Arquitectura de PostgreSQL
7.2. Arquitectura de PostgreSQL Dataprix 27 Octubre, 2009 - 11:15El siguiente gráfico muestra de forma esquemática las entidades involucradas en el funcionamiento normal del gestor de bases de datos:
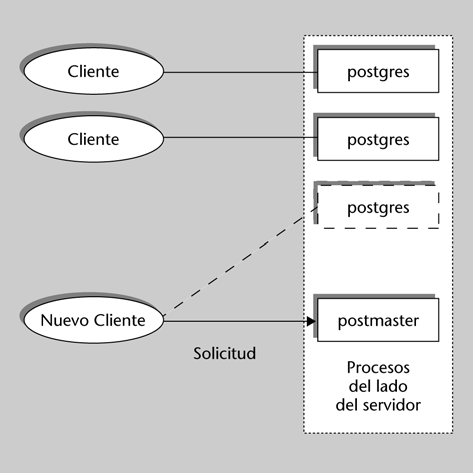
PostgreSQL está basado en una arquitectura cliente-servidor. El programa servidor se llama postgres y entre los muchos programas cliente tenemos, por ejemplo, pgaccess (un cliente gráfico) y psql (un cliente en modo texto).
Un proceso servidor postgres puede atender exclusivamente a un solo cliente; es decir, hacen falta tantos procesos servidor postgres como clientes haya. El proceso postmaster es el encargado de ejecutar un nuevo servidor para cada cliente que solicite una conexión.
Se llama sitio al equipo anfitrión (host) que almacena un conjunto de bases de datos PostgreSQL. En un sitio se ejecuta solamente un proceso postmaster y múltiples procesos postgres. Los clientes pueden ejecutarse en el mismo sitio o en equipos remotos conectados por TCP/IP.
Es posible restringir el acceso a usuarios o a direcciones IP modificando las opciones del archivo pg_hba.conf, que se encuentra en /etc/postgresql/pg_hba.conf.
Este archivo, junto con /etc/postgresql/postgresql.conf son particularmente importantes, porque algunos de sus parámetros de configuración por defecto provocan multitud de problemas al conectar inicialmente y porque en ellos se especifican los mecanismos de autenticación que usará PostgreSQL para verificar las credenciales de los usuarios.
Para habilitar la conexión a PostgreSQL desde clientes remotos, debemos verificar el parámetro tcpip_socket = true en el fichero /etc/postgresql/postgresql.conf.
A continuación, para examinar los métodos de autenticación y las posibilidades de conexión de clientes externos, debemos mirar el fichero /etc/postgresql/ pg_hba.conf, donde se explicita la acción que hay que emprender para cada conexión proveniente de cada host externo, o grupo de hosts.
7.3. El administrador de postgres
7.3. El administrador de postgres Dataprix 27 Octubre, 2009 - 11:26Al terminar la instalación, en el sistema operativo se habrá creado el usuario postgres, y en PostgreSQL se habrá creado un usuario con el mismo nombre.
Él es el único usuario existente en la base de datos y será el único que podrá crear nuevas bases de datos y nuevos usuarios.
Normalmente, al usuario postgres del sistema operativo no se le permitirá el acceso desde un shell ni tendrá contraseña asignada, por lo que deberemos convertirnos en el usuario root, para después convertirnos en el usuario postgres y realizar tareas en su nombre:
yo@localhost:~$ su
Password:
# su - postgres
postgres@localhost:~$El usuario postgres puede crear nuevas bases de datos utilizando el comando createdb. En este caso, le indicamos que el usuario propietario de la misma será el usuario postgres:
postgres@localhost:~$ createdb demo --owner=postgres
create database
| Se ha creado el usuario yo con permisos para crear bases de datos y sin permisos para crear usuarios. |
El usuario postgres puede crear nuevos usuarios utilizando el comando createuser:
postgres@localhost:~$ createuser yo
Shall the new user be allowed to create databases? (y/n) y
Shall the new user be allowed to create more new users? (y/n) n
CREATE USER
Los siguientes comandos eliminan bases de datos y usuarios, respectivamente:
postgres@localhost:~$ dropdb demo
postgres@localhost:~$ dropuser yoEs recomendable que se agreguen los usuarios necesarios para operar la instalación de PostgreSQL, y recurrir, así, lo menos posible al ingreso con postgres.
También disponemos de sentencias SQL para la creación de usuarios, grupos y privilegios:
demo=# create user marc password `marc21´;
CREATE USER
demo=# alter user marc password `marc22´;
ALTER USER
demo=# drop user marc;
DROP USERLos grupos permiten asignar privilegios a varios usuarios y su gestión es sencilla:
create group migrupo;Para añadir o quitar usuarios de un grupo, debemos usar:
alter group migrupo add user marc, ... ;
alter group migrupo drop user marc, ... ;7.3.1. Privilegios
7.3.1. Privilegios Dataprix 27 Octubre, 2009 - 11:35Cuando se crea un objeto en PostgreSQL, se le asigna un dueño. Por defecto, será el mismo usuario que lo ha creado. Para cambiar el dueño de una tabla, índice, secuencia, etc., debemos usar el comando alter table. El dueño del objeto es el único que puede hacer cambios sobre él, si queremos cambiar este comportamiento, deberemos asignar privilegios a otros usuarios.
Los privilegios se asignan y eliminan mediante las sentencias grant y revoke. PostgreSQL define los siguientes tipos de operaciones sobre las que podemos dar privilegios:
select, insert, update, delete, rule, references, trigger, create, temporary, execute, usage, y all privileges.
Presentamos algunas sentencias de trabajo con privilegios, que siguen al pie de la letra el estándar SQL:
grant all privileges on proveedores to marc;
grant select on precios to manuel;
grant update on precios to group migrupo;
revoke all privileges on precios to manuel;
grant select on ganacias from public;
7.4. Creacion de tipos de datos
7.4. Creacion de tipos de datos Dataprix 27 Octubre, 2009 - 11:42Entre las múltiples opciones para extender PostgreSQL, nos queda aún por ver la creación de tipos o dominios (según la nomenclatura del estándar SQL). PostgreSQL prevé dos tipos de datos definidos por el administrador:
• Un tipo de datos compuesto, para utilizar como tipo de retorno en las funciones definidas por el usuario.
• Un tipo de datos simple, para utilizar en las definiciones de columnas de las tablas.
A modo de ejemplo, veamos un tipo compuesto y la función que lo devuelve:
create type comptipo as (f1 int, f2 text);
create function gettipo() returns setof comptipo as
`select id, nombre from clientes´ language sql;Para el tipo de datos simple, la definición es más compleja, pues se debe indicar a PostgreSQL funciones que tratan con este tipo que le permitirán usarlo en operaciones, asignaciones, etc.
| Tratar con el tipo de datos simple |
|---|
| Habitualmente, las funciones que tratarán con este tipo de datos se escribirán en C. |
A modo de ejemplo, vamos a crear el tipo “numero complejo”, tal como lo hace la documentación de PostgreSQL. En primer lugar, debemos definir la estructura donde almacenaremos el tipo:
typedef struct Complex {
double x;
double y;
} Complex;Después, las funciones que lo recibirán o devolverán:
PG_FUNCTION_INFO_V1(complex_in);
Datum
complex_in(PG_FUNCTION_ARGS)
{ char *str = PG_GETARG_CSTRING(0);
double x,
y;
Complex *result; if (sscanf(str, " ( %lf , %lf )", &x, &y) != 2)
ereport(ERROR,
(errcode(ERRCODE_INVALID_TEXT_REPRESENTATION),
errmsg("invalid input syntax for complex: "%s"", str)));
result = (Complex *) palloc(sizeof(Complex));
result->x = x;
result->y = y;
PG_RETURN_POINTER(result);
}PG_FUNCTION_INFO_V1(complex_out
Datum
complex_out(PG_FUNCTION_ARGS)
{
Complex *complex = (Complex *) PG_GETARG_POINTER(0);
char *result; result = (char *) palloc(100);
snprintf(result, 100, "(%g,%g)", complex->x, complex->y);
PG_RETURN_CSTRING(result);
}Ahora estamos en condiciones de definir las funciones, y el tipo:
create function complex_in(cstring)
returns complex
as `filename´
language c immutable strict;create function complex_out(complex)
returns cstring
as `filename´
language c immutable strict;create type complex (
internallength = 16,
input = complex_in,
output = complex_out,
alignment = double
);
El proceso es un poco farragoso, pero compensa por la gran flexibilidad que aporta al SGBD. A continuación, podríamos crear algunos operadores para trabajar con este tipo (suma, resta, etc.), mediante los pasos que ya conocemos.
La creación de un dominio en PostgreSQL consiste en un tipo (definido por el usuario o incluido en el SGBD), más un conjunto de restricciones. La sintaxis es la siguiente:
| Se ha creado un dominio basado en un tipo definido por el sistema donde la única restricción es su longitud. |
create domain country_code char(2) not null;
create domain complejo_positivo complex not null check
(complejo_mayor(value,(0,0)))Evidentemente, deberíamos haber definido el operador complejo_mayor que recibiera dos números complejos e indicara si el primero es mayor que el segundo.
7.5. Plantilla de creacion de bases de datos
7.5. Plantilla de creacion de bases de datos Dataprix 27 Octubre, 2009 - 15:52PostgreSQL tiene definidas dos bases de datos de sistema, template0 y template1(que habremos visto en los ejemplos al listar las bases de datos del gestor), con un conjunto de objetos tales como los tipos de datos que soporta o los lenguajes de procedimiento instalados.
La base de datos template0 se crea al instalar el servidor, con los objetos por defecto del mismo, y la base de datos template1 se crea a continuación de la anterior con algunos objetos más particulares del entorno o sistema operativo donde se ha instalado PostgreSQL. Esto hace que sea muy recomendable heredar siempre de template1 (que es el comportamiento por defecto).
Estas bases de datos se utilizan como “padres” del resto de bases de datos que se crean, de modo que, al crear una nueva base de datos, se copian todos los objetos de template1.
Ventajas de esta situación
Si queremos añadir algún objeto (una tabla, un tipo de datos, etc.) a todas las bases de datos, sólo tenemos que añadirlo a template1, y el resto de bases de datos que se hayan creado a partir de ésta lo tendrán disponible.
Si se instala un lenguaje sobre la base de datos template1, automáticamente todas las bases de datos también usarán el lenguaje. En las distribuciones de Linux es frecuente que se haya realizado de este modo, por lo que no hay necesidad de instalarlo.
Por supuesto, podemos escoger otra plantilla para crear bases de datos, especificándola en la sentencia:
create database nuevbd template plantillabd 7.6. Copias de seguridad
7.6. Copias de seguridad Dataprix 27 Octubre, 2009 - 16:07Hacer periódicamente copias de seguridad de la base de datos es una de las tareas principales del administrador de cualquier base de datos. En PostgreSQL, estas copias de seguridad se pueden hacer de dos maneras distintas:
• Volcando a fichero las sentencias SQL necesarias para recrear las bases de datos.
• Haciendo copia a nivel de fichero de la base de datos.
En el primer caso, disponemos de la utilidad pg_dump, que realiza un volcado de la base de datos solicitada de la siguiente manera:
$ pg_dump demo > fichero_salida.sqlpg_dump es un programa cliente de la base de datos (como psql), lo que significa que podemos utilizarlo para hacer copias de bases de datos remotas, siempre que tengamos privilegios para acceder a todas sus tablas. En la práctica, esto significa que debemos ser el usuario administrador de la base de datos para hacerlo.
Si nuestra base de datos usa los OID para referencias entre tablas, debemos indicárselo a pg_dump para que los vuelque también (pg_dump -o) en lugar de volver a crearlos cuando inserte los datos en el proceso de recuperación. Asimismo, si tenemos BLOB en alguna de nuestras tablas, también debemos indicárselo con el parámetro correspondiente (pg_dump -b) para que los incluya en el volcado.
Para restaurar un volcado realizado con pg_dump, podemos utilizar directamente el cliente psql:
$ psql demo < fichero_salida.sql
| pg_dump |
|---|
| pg_dump realiza la copia a partir de la base de datos de sistema template0, por lo que también se volcarán los tipos definidos, funciones, etc. de la base de datos. Cuando recuperemos esta base de datos, debemos crearla a partir de template0 si hemos perso-nalizado template1 (y no de template1 como lo haría por defecto la sentencia create database) para evitar duplicidades. |
Una vez recuperada una base de datos de este modo, se recomienda ejecutar la sentencia analyze para que el optimizador interno de consultas de PostgreSQL vuelva a calcular los índices, la densidad de las claves, etc.
Las facilidades del sistema operativo Unix, permiten copiar una base de datos a otra en otro servidor de la siguiente manera:
$ pg_dump -h host1 demo | psql -h host2 demoPara hacer la copia de seguridad a nivel de fichero, simplemente copiamos los ficheros binarios donde PostgreSQL almacena la base de datos (especificado en tiempo de compilación, o en paquetes binarios, suele ser /var/lib/postgres/data), o bien hacemos un archivo comprimido con ellos:
$ tar -cvzf copia_bd.tar.gz /var/lib/postgres/dataEl servicio PostgreSQL debe estar parado antes de realizar la copia.
A menudo, en bases de datos grandes, este tipo de volcados origina ficheros que pueden exceder los límites del sistema operativo. En estos casos tendremos que utilizar técnicas de creación de volúmenes de tamaño fijo en los comandos tar u otros con los que estemos familiarizados.
7.7. Mantenimiento rutinario de la base de datos
7.7. Mantenimiento rutinario de la base de datos Dataprix 27 Octubre, 2009 - 16:14Hay una serie de actividades que el administrador de un sistema gestor de bases de datos debe tener presentes constantemente, y que deberá realizar periódicamente. En el caso de PostgreSQL, éstas se limitan a un mantenimiento y limpieza de los identificadores internos y de las estadísticas de planificación de las consultas, a una reindexación periódica de las tablas, y al tratamiento de los ficheros de registro.
7.7.1. vacuum
7.7.1. vacuum Dataprix 27 Octubre, 2009 - 16:49El proceso que realiza la limpieza de la base de datos en PostgreSQL se llama vacuum. La necesidad de llevar a cabo procesos de vacuum periódicamente se justifica por los siguientes motivos:
• Recuperar el espacio de disco perdido en borrados y actualizaciones de datos.
• Actualizar las estadísticas de datos utilizados por el planificador de consultas SQL.
• Protegerse ante la pérdida de datos por reutilización de identificadores de transacción.
Para llevar a cabo un vacuum, deberemos ejecutar periódicamente las sentencias vacuum y analyze. En caso de que haya algún problema o acción adicional a realizar, el sistema nos lo indicará:
demo=# VACUUM;
WARNING: some databases have not been vacuumed in 1613770184 transactions
HINT: Better vacuum them within 533713463 transactions, or you may have a wraparound failure.VACUUM
demo=# VACUUM VERBOSE ANALYZE;
INFO: haciendo vacuum a "public.ganancia"
INFO:"ganancia":seencontraron 0 versiones de filas eliminables y 2 no eliminables en 1 páginas
DETAIL: 0 versiones muertas de filas no pueden ser eliminadas aún.
Hubo 0 punteros de ítem sin uso.
páginas están completamente vacías.
CPU 0.00s/0.00u sec elapsed 0.00 sec.
INFO: analizando "public.ganancia"
INFO: "ganancia": 1 páginas, 2 filas muestreadas, se estiman 2 filas en total
VACUUM7.7.2. Reindexacion
7.7.2. Reindexacion Dataprix 27 Octubre, 2009 - 17:02La reindexación completa de la base de datos no es una tarea muy habitual, pero puede mejorar sustancialmente la velocidad de las consultas complejas en tablas con mucha actividad.
demo=# reindex database demo;
7.7.3. Ficheros de registro
7.7.3. Ficheros de registro Dataprix 27 Octubre, 2009 - 17:05Es una buena práctica mantener archivos de registro de la actividad del servidor. Por lo menos, de los errores que origina. Durante el desarrollo de aplicaciones puede ser muy útil disponer también de un registro de las consultas efectuadas, aunque en bases de datos de mucha actividad, disminuye el rendimiento del gestor y no es de mucha utilidad.
En cualquier caso, es conveniente disponer de mecanismos de rotación de los ficheros de registro; es decir, que cada cierto tiempo (12 horas, un día, una semana...), se haga una copia de estos ficheros y se empiecen unos nuevos, lo que nos permitirá mantener un histórico de éstos (tantos como ficheros podamos almacenar según el tamaño que tengan y nuestras limitaciones de espacio en disco).
PostgreSQL no proporciona directamente utilidades para realizar esta rotación, pero en la mayoría de sistemas Unix vienen incluidas utilidades como logrotate que realizan esta tarea a partir de una planificación temporal.