Muchos operadores de RapidMiner se pueden utilizar para estimar la performance de un aprendiz, un paso de preprocesamiento, o un espacio de características sobre uno o varios conjuntos de datos. El resultado de estos operadores de validación es un vector de performance que recoge los valores de un conjunto de criterios de performance. Para cada criterio se dan el valor medio y la desviación estándar.
La cuestión es ¿cómo se pueden comparar estos vectores de performance? Las pruebas de estadísticas de significancia como ANOVA o pruebas t por pares, se pueden utilizar para calcular la probabilidad de que
los valores medios reales sean diferentes.
Suponemos que se han obtenido varios vectores de performance y se desea compararlos. En este proceso se utiliza el mismo conjunto de datos para las validaciones cruzadas (de ahí el IOMultiplier) y para estimar la performance de un esquema de aprendizaje lineal y una RBF basada en SVM.
1. Agregar el operador Utility → Data Generation → Generate Data a la zona de trabajo. Cambiar el nombre del mismo a “GeneradorConjEjs” y los valores de los parámetros target function a “one variable non linear”, number examples a 80, number of attributes a 1, attributes lower bound a -40.0 y attributes upper bound a 30.0.
2. Agregar el operador Process Control → Multiply. Cambiar el nombre del mismo a “ESMultiplicador_1” y conectar la salida del operador GeneradorConjEjs (Generate Data) a la entrada de este operador.
3. Agregar un operador Evaluation → Validation → X-Validation. Cambiar el nombre del mismo a “XValidación” y el parámetro sampling type a “shuffled sampling”. Conectar la salida out (output 1) del operador ESMultiplicador_1 (Multiply) a la entrada tra de este operador.
4. Agregar otro operador Evaluation → Validation → X-Validation. Cambiar el nombre del mismo a “XValidación (2)” y el parámetro sampling type a “shuffled sampling”. Conectar la salida out (output 2) del operador ESMultiplicador_1 a la entrada tra de este operador.
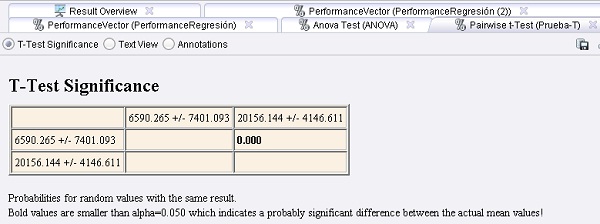
5. Agregar el operador Evaluation → Significance → T-Test. Conectar la salida ave (averagable 1) del operador XValidación (X-Validation) a la entrada per (performance 1) de ![]() este operador y la salida ave (averagable 1) del operador XValidación (2) a la entrada per (performance 2) de este último. También conectar la salida sig (significance) de este operador al conector res del panel.
este operador y la salida ave (averagable 1) del operador XValidación (2) a la entrada per (performance 2) de este último. También conectar la salida sig (significance) de este operador al conector res del panel.
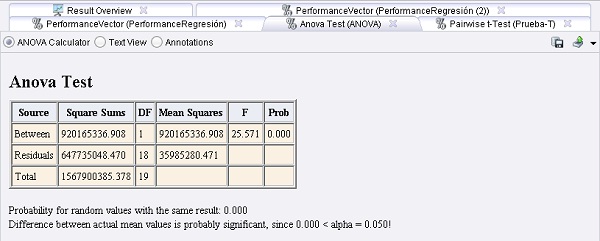
6. Agregar el operador Evaluation → Significance → ANOVA. Cambiar el nombre del mismo a “Prueba- T”. Conectar las salidas per (performance 1) y per (performance 2) del operador T-Test a las entradas per (performance 1) y per (performance 2) de este operador, y las salidas sig (significance), per (performance 1) y per (performance 2) del mismo a conectores res del panel.

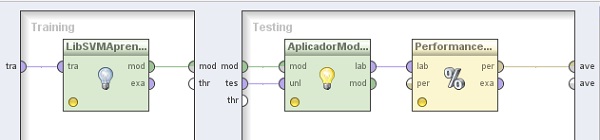
7. Hacer doble clic sobre el operador XValidación. En el panel Training del nivel inferior, agregar el siguiente operador:
7.1 Modeling → Classification and Regression → Support Vector Modeling → Support Vector Machine (LibSVM). Cambiar el nombre del mismo a “LibSVMAprendiz” y los valores de los parámetros svm type a “nu-SVR”, kernel type a “poly” y C a 10000.0. Conectar la entrada tra (training) y salida mod (model) de este operador a los puertos tra y mod del panel, respectivamente
8. En el panel Testing de la derecha, agregar los siguientes operadores:
8.1 Modeling → Model Application → Apply Model. Cambiar el nombre del mismo a “AplicadorModelo” y conectar las entradas mod y tes del panel a las entradas mod y unl de este operador, respectivamente.
8.2 Evaluation → Performance Measurement → Classification and Regression → Performance (Regression). Cambiar el nombre del mismo a “PerformanceRegresión”, quitar la tilde de la opción root mean squared error y tildar la opción absolute error. Conectar la salida lab del operador AplicadorModelo (Apply Model) a la entrada lab de este operador y la salida per (performance) de éste último al conector ave (averagable 1) del panel.
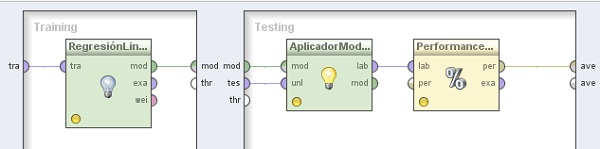
9. Subir un nivel (Proceso Principal) y hacer doble clic sobre el operador XValidación (2). En el panel Training del nivel inferior, agregar el siguiente operador:
9.1 Modeling → Classification and Regression → Function Fitting → Linear Regression. Cambiar el nombre del mismo a “RegresiónLineal” y conectar la entrada tra (training) y salida mod (model) del mismo a los puertos tra y mod del panel, respectivamente.
10. En el panel Testing de la derecha, agregar los siguientes operadores:
10.1 Modeling → Model Application → Apply Model. Cambiar el nombre del mismo a “AplicadorModelo (2)” y conectar las entradas mod y tes del panel a las entradas mod y unl de este operador, respectivamente.
10.2 Evaluation → Performance Measurement → Classification and Regression → Performance (Regression). Cambiar el nombre del mismo a “PerformanceRegresión (2)”, quitar la tilde de la opción root mean squared error y tildar la opción absolute error. Conectar la salida lab del operador AplicadorModelo (2) a la entrada lab de este operador y la salida per (performance) de éste último al conector ave (averagable 1) del panel.
11. Ejecutar el proceso y comparar los resultados: las probabilidades de una diferencia significativa son iguales, porque sólo se crearon 2 vectores de performance. En este caso, la SVM es probablemente más
adecuada para el conjunto de datos en cuestión debido a que los valores medios reales probablemente son diferentes.
12. Observar que los vectores de performance como todos los demás objetos que se pueden pasar entre los operadores de RapidMiner se pueden escribir en y cargar desde un archivo.