
Hello everyone:
I am preparing the design of a DW for use with Pentaho, and to revise the definition of the time dimension I have some doubts. I explain:
DW is a sales analysis. In the model I have two fact tables, one for sales, whose granularity is at the level of day, customer, product, etc, and a fact table which records the information in the sales forecast (this table has a level of different granularity, where a month and level of client channel (which is one of the attributes of the customer dimension)). The keys to the fact table are not therefore the keys to the dimension table, but a component within a dimension.
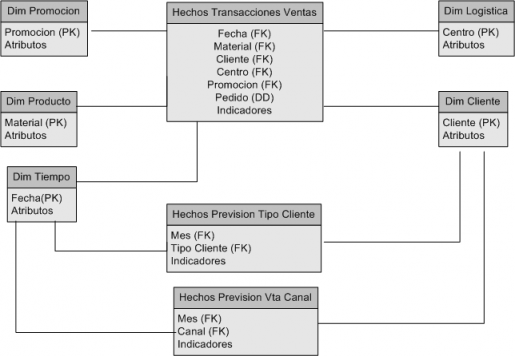
Initial Logical Model
Given this, I rather doubt arise about the best design choice to build the database:
1) Having made tables on a different level of granularity, is it necessary or advisable to spend the dimensions involved in a star schema to work properly after the consultation?.
2) What may be the case that aspects of design such as this are conditioned by the tool we will use later?. For example, if I will use Pentaho, or Microstrategy, etc, can be the case that using a tool or another is determining how to model in certain cases?. I have read in a blog for example, Microstrategy recommends switching to a snowflake schema (including the examples provided with the platform, the Analytic Modules, are built that way).
3) Could we generalize that a simple scheme to use a scheme smoothly total star, but at the time that complicate the model with more fact tables and different granularity is better to spend a snowflake?. "To follow the Kimball methodology in terms of the scale formed is also necessary to do that, and so we can address the complex models with multiple fact tables?.
I hope I throw a cable, especially those who have been visiting the construction of DW. It is an issue for me is a bit confusing (besides the examples provided in star schemas are used to illustrate simple, then do not correspond with reality more complex).
- Log in to post comments
