

Cómo generar sentencias SQL de administración para eliminar tablas y vistas
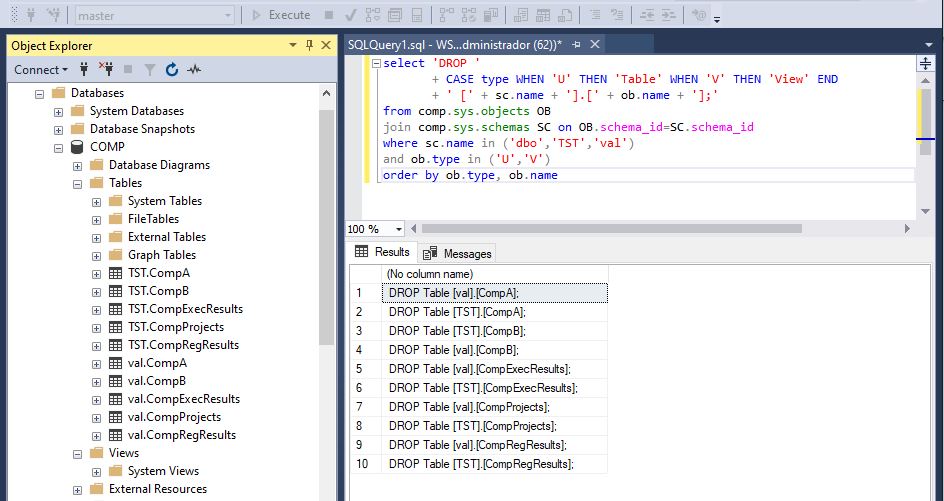
En SQL Server, con las vistas que la base de datos nos da sobre el catálogo podemos consultar, entre otras muchas cosas, los nombres de objetos de las bases de datos como tablas o vistas.
Si lo que queremos hacer es eliminar todas las tablas y vistas de un determinado esquema de una base de datos 'DBName', por ejemplo, conectados a DBName o incluyendo el nombre de la base de datos en la consulta, podemos consultar en las vistas de sistema de SYS.OBJECTS y SYS.SCHEMA de objetos y esquemas, respectivamente, para construir nuestras sentencias de DROP Table en un segundo.
Consultas útiles de SQL Server para administración y desarrollo

Las herramientas como SQL Server Management Studio facilitan mucho la administración y el desarrollo con SQL Server con multitud de funciones, asistentes y exploradores que permiten realizar fácilmente muchas de las tareas del día a día de administradores y desarrolladores de SQLServer..
Estado de los tablespaces en DB2
- Read more about Estado de los tablespaces en DB2
- Log in to post comments
En este artículo podrás consultar los estados más habituales de los tablespaces en DB2.
Estos estados pueden ser consultados de distintas formas, aunque la más habitual desde la linea de comandos en la siguiente.
Cómo conocer el puerto de conexión de DB2
- Read more about Cómo conocer el puerto de conexión de DB2
- Log in to post comments
Aunque seguro que hay otros métodos, en este pequeño artículo, una manera sencilla de conocer el puerto por el que da servicio el servidor DB2.
Obtenemos el nombre del servicio TCP/IP:
> db2 get dbm cfg | grep SVCENAME
Capturamos el resultado:
TCP/IP Service name (SVCENAME) = db2TRP
Lo buscamos en /etc/services:
> cat /etc/services | grep sapdb2QRP db2TRP 5912/tcp # DB2 Communication Port
El puerto de escucha es el 5912.
Un concurso para enviar un DBA al espacio
- Read more about Un concurso para enviar un DBA al espacio
- Log in to post comments
Redgate ha organizado un concurso para DBA's con un premio espectacular: Un viaje al espacio!
El ganador será el primer DBA que vaya al espacio. Una iniciativa de lo más original. Para el que quiera intentarlo, han creado la página www.dbainspace.com
Traducción de terminología Oracle - DB2 LUW
Con la versión 9.7 de DB2 LUW, IBM hace un guiño a todos los DBA's de Oracle, mucho más numerosos en el mercado que los DBA's de DB2.
Para ello, en la versión 9.7 de DB2 LUW ha introducido modos de compatibilidad de Oracle que permiten realizar tareas en DB2 con la facilidad y conocimiento que tienen los DBA de Oracle. Sin embargo, es importante conocer la traslación de terminología entre Oracle y DB2 si tienes la intención de meterte en el mundo IBM DB2.
En este primer artículo sobre equivalencias entre IBM DB2 y Oracle, relaciono una serie de elementos para que esa introducción sea sencilla y se pueda leer la documentación de IBM DB2 fácilmente. Entre ellos, terminología general de estas bases de datos, versiones, utilidades y vistas.
Defragmentar tablas para optimizar MySQL
- Read more about Defragmentar tablas para optimizar MySQL
- Log in to post comments
Con MySQL, cuando se eliminan registros de una tabla, el espacio no se reasigna automáticamente. El problema de esto es que si en una tabla se realizan operaciones de DELETE, el espacio físico de la tabla va quedando cada vez más fragmentado. En MySQL, disponemos del comando OPTIMIZE TABLE para poder realizar sobre cualquier tabla una optimización que, entre otras cosas, realiza una defragmentación automática de la tabla..
Mejora de rendimiento de MySQL ajustando algunos parámetros
 MySQL, al igual que la mayoría de gestores de bases de datos, permite modificar fácilmente sus parámetros que controlan tamaños de memoria dedicados a determinadas tareas, utilización de recursos, límites de concurrencia, etc.
MySQL, al igual que la mayoría de gestores de bases de datos, permite modificar fácilmente sus parámetros que controlan tamaños de memoria dedicados a determinadas tareas, utilización de recursos, límites de concurrencia, etc.
Ajustando adecuadamente estos parámetros se pueden obtener muchas mejoras de rendimiento, sobretodo si el servidor/es de la base de datos no va sobrado de recursos, y si por la parte de optimización SQL no se puede mejorar mucho más.
SQLServer 2008: Actualizar estadísticas de tabla de forma dinámica en toda una base de datos
Al igual que en Oracle existe una tabla donde se listan todas las tablas de la base de datos (dba_tables) y podemos usarla para realizar operaciones de mantenimiento de forma dinámica, en Sql Server podemos hacer lo mismo consultando la tabla [basededatos].dbo.sysobjects.
En el ejemplo inferior (como en otros que he colgado) actualizo las estadísticas de todas las tablas de una base de datos de Sql Server de forma dinámica consultando el diccionario de datos. Este se podría encapsular en un stored procedure o directamente ejecutarlo en un job del Agente de Sql Server para mantener actualizadas las estadísticas de todas las tablas de una base de datos de forma automática...
