7.3.4 Generación Modelos
7.3.4 Generación Modelos alfonsocutro 18 Marzo, 2010 - 12:55En este apartado se analizarán los modelos impuestos en el apartado “Definición de los Problemas”.
Describir la composición del empleo en Corrientes.
Como se hacía referencia anteriormente, con el Weka no solamente se podrá aplicar técnicas de minería de datos.
En el transcurso del estudio relacionado con este objetivo se utilizará únicamente análisis de las variables.
A continuación se visualizan distintos análisis de las variables referentes a los estados de actividad de los individuos de la provincia de Corrientes.
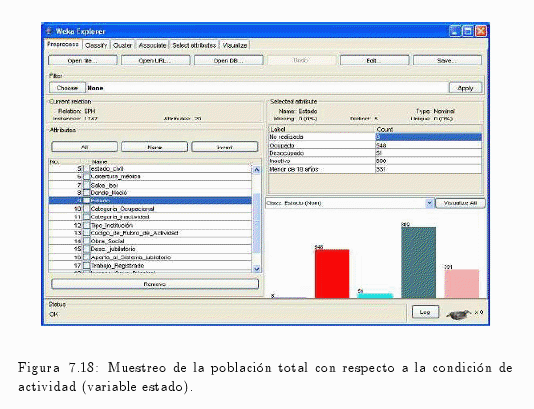
En el gráfico de la fig. 7.18 se puede visualizar la frecuencia absoluta (número de casos) de la variable de estudio que en este caso es estado (condición de actividad).
También se pude visualizar cómo se manifiesta la variable estado (condición de actividad) con las demás variables de la muestra (ver fig. 7.19).
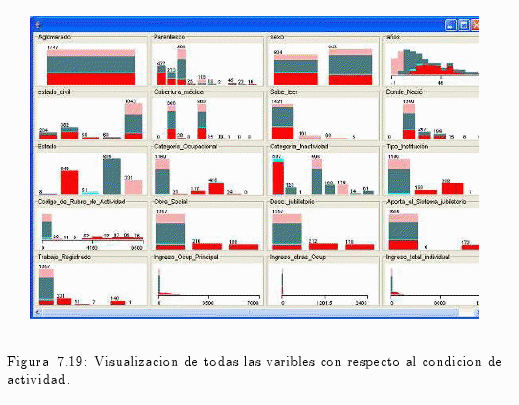
Como resultado de esta clasificación, se visualizó el número de ocupado, desocupados, inactivos, etc.
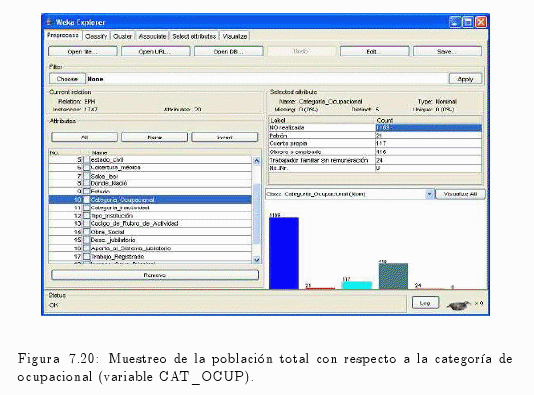
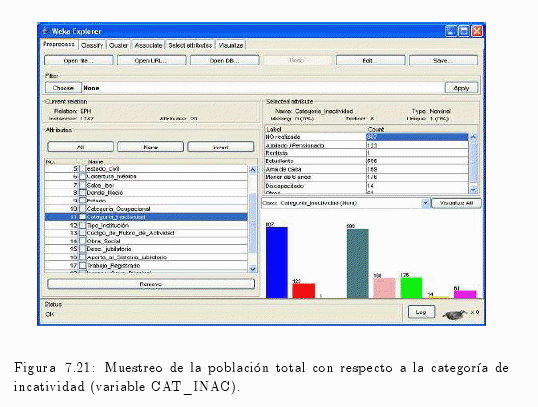
Similar al anterior procedimiento, se puede realizar con las variables cat_ocup (categoría ocupacional) o incluso con cat_inac (categoría de inactividad) (ver fig. 7.20 y fig. 7.21).
Conocer los perfiles socio demográficos de los individuos de la población de Corrientes.
A diferencia del anterior apartado, en este se utilizarán técnicas de Minería de Datos.
Lo que interesa en este caso es descubrir los diferentes perfiles de los individuos que poseen planes asistenciales en la provincia de Corrientes.
Para ello se empleará la técnica de Clustering con un algoritmo SimplekMeans , utilizando el atributo sexo para la distribución de los grupos.
Se obtendrá un modelo de minería de datos donde se dividirán todos los individuos de la población de Corrientes en los grupos correspondientes a la variable sexo.
Una vez culminado el proceso de Clustering la herramienta nos permite observar los resultados de modo textual (ver fig. 7.22) o también de manera grafica (ver fig. 7.24).
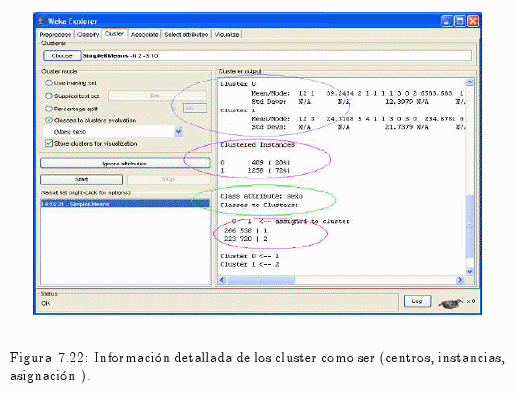
En la fig. 7.22 se puede apreciar la información sobre el número de clusters involucrados, las instancias de estos, como así también las clases y los atributos que participan en este análisis.
También se visualiza a los dos grupos, donde:
Cluster 0 <— 1 (Varón)
Cluster 1 <— 2 (Mujer)
Además se pude apreciar en la 7.22 a cuatro círculos de diferentes colores; cada uno de estos destacan la siguiente información:
- El primero círculo de color violeta destaca la distribución de los atributos en cada cluster.
- El segundo, de color rosado muestra en porcentaje y en frecuencia el número de instancias por cluster.
- El tercer círculo visualiza el atributo en este caso es la variable sexo con el cual se realizó el análisis.
- El último muestra la asignación de cada cluster por cada valor de la variable sexo, con su respectivo número de casos.
Si se presiona con el botón derecho del ratón sobre la lista de resultado (ver fig. 7.23) se puden observar los correspondientes resultados extraídos de la técnica de Clustering en forma gráfica (ver fig. 7.24).
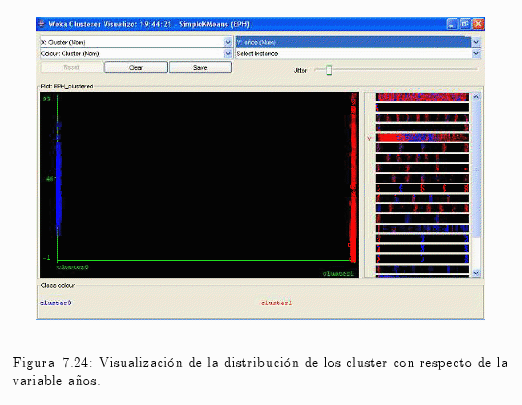
A continuación se visualizarán los resultados resultados extraídos de la técnica de Clustering.
En la fig. 7.24 se muestra la dispersión de la variable años en cada cluster.
Donde:
- Cluster 0 de colo azul.
- Cluster 1 de color rojo.
En la fig. 7.25 se pueden observar los valores que toma cada cluster de la variable que indica el analfabetismo.
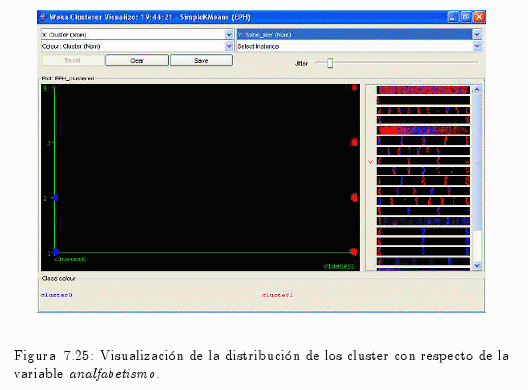
En el gráfico de la fig. 7.25 permite extraer la siguiente infomación:
- El Cluster 0 asume el valor 1 (1= Sí sabe leer y escribir; 2= No sabe leer y escribir).
- El Cluster 1 asume todos los valores restantes.
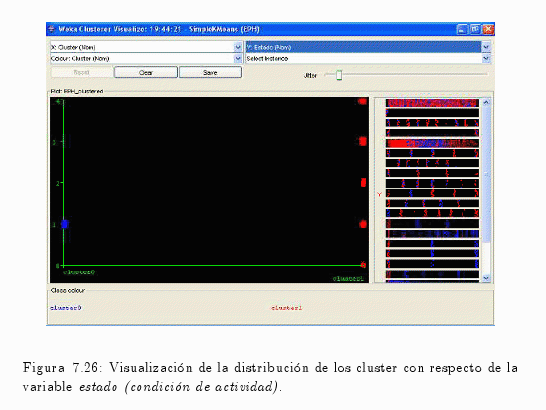
Como se puede comprobar en la fig. 7.26, el Cluster 0 asume únicamente el valor 1 (Ocupado), en cambio el Cluster 1 el resto de los valores.
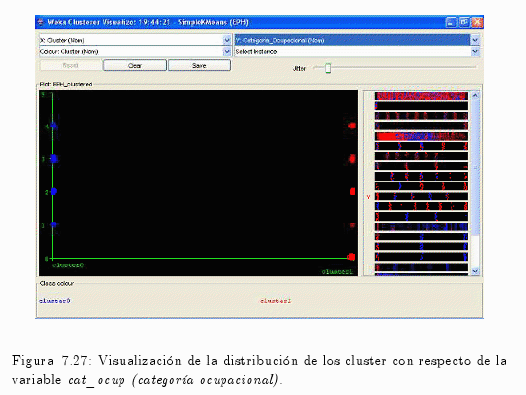
Cuando se contrasta la variable cat_ocup (categoria ocupacional) con respecto a los cluster se puede comprobar lo siguiente:
- Cluster 0 asume todos los valores exepto el 0 (cero), con mayor presencia de instancia en el valor 3 y con un importante número menor en la opción 4.
- Cluster 1 asume todos los valores inclusive el 0 (cero).
Donde:
— 0 = Entrevista individual no realizada.
— 1 = Patrón.
— 2 = Cuenta propia.
— 3 = Obrero o empleado.
— 4 = Trabajador familiar sin remuneración.
— 9 = Ns./Nr.
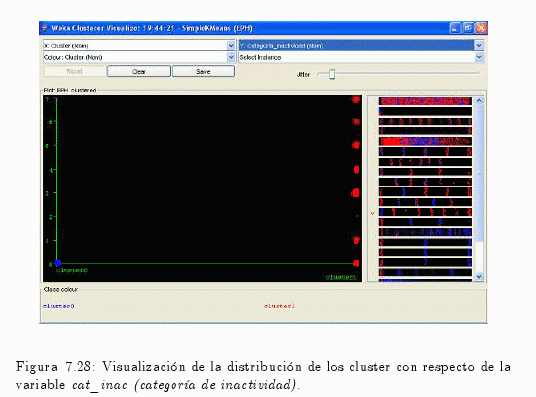
En la fig. 7.28 permite observar los valores que poseen los diferentes cluster.
Como por ejemplo:
- Cluster 0 asume el único valor 0 (cero), 0 = Entrevista individual no realizada.
- Cluster 1 toma todos los valores que asume la variable, es decir:
— 1 = Jubilado / Pensionado.
— 2 = Rentista.
— 3 = Estudiante.
— 4 = Ama de casa.
— 5 = Menor de 6 años.
— 6 = Discapacitado.
— 7 = Otros.
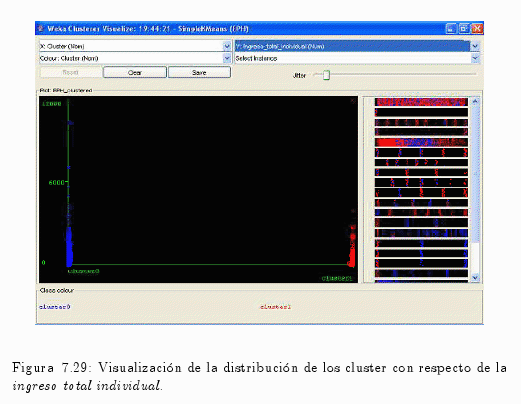
En la fig. 7.29 se puede visualizar que la distribución de los ingresos de los individuos en el Cluster 0 es superior que el Cluster 1.
El gráfico 7.29 permite comprobar que el Cluster 0 supera los 6000 pesos y el Cluster 1 no solamente no supera esta cifra si no que también posee menor número de casos.
Lo que se realizó hasta aquí es una descripción de perfiles de los individuos por la variable sexo.
Si se quisiera conocer la representación de los perfiles pero en este caso utilizando la variable estado, se procederá como se detalla a continuación.
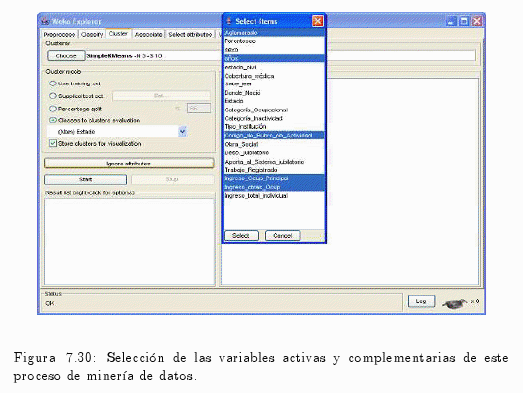
Como se puede visualizar en la fig. 7.30 la variable estado es la variable activa y parentesco, sexo, estado civil, cobertura médica, sabe leer, donde nació, categoría ocupacional, categoría inactividad, tipo de institución, obra social, desc. jubilatorio, aporta al sistema jubilatorio, trabajo registrado y ingreso total individual son las variables complementarias de dicho proceso.
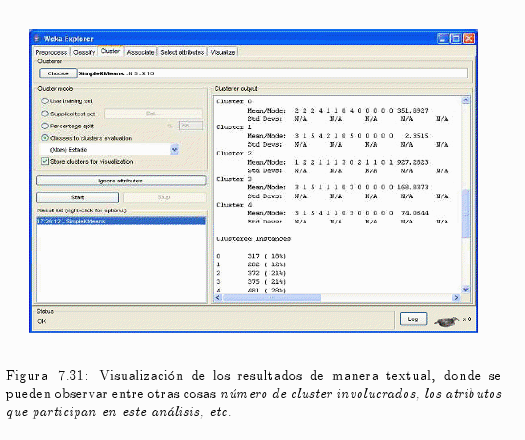
Una vez ejecutado dicho proceso se obtienen los siguientes resultados, ya sea en formato textual como gráfico (ver fig. 7.31 y fig. 7.32).
En la fig. 7.31 se puede observar la siguiente información: el número de cluster involucrados, las instancias de estos, como así también las clases y los atributos que participan en este análisis.
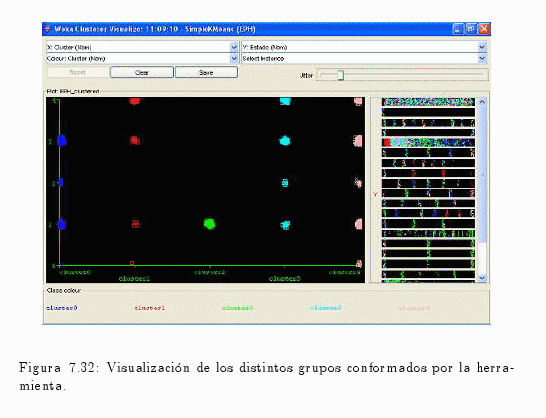
En la fig. 7.32 se puede observar la formación de los diferentes clústers, donde los mismos representan distintos estados.
Por ejemplo:
- El clúster No 0 asume los siguientes valores (ocupado, desocupado e inactivo).
- El clúster No 1 está compuesto por mayor presencia de la población menor de 10 años y con una inferior representación en las poblaciones inactivas y ocupadas.
- El clúster No 2 posee únicamente a los individuos que se encuentren ocupados.
- Los clúster No 3 y 4 poseen casi la misma distribución, con la diferencia que el clúster No 4 asume el valor 0 (cero) que es la no respuesta al cuestionario individual.
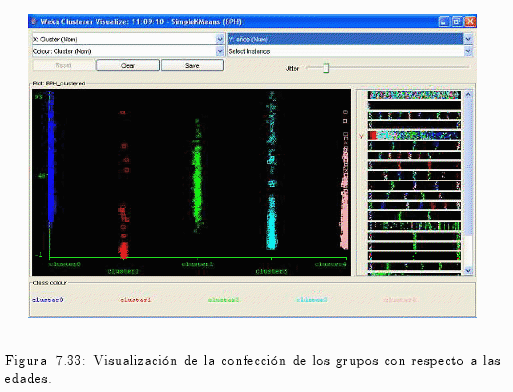
Como se puede visualizar en el gráfico 7.31, las edades están estrechamente relacionadas a los estados (condición de actividad) de los individuos:
- El clúster No 0 corresponde a los individuos que no respondieron al cuestionario individual.
- El clúster No 1 (población menor de 10 años de edad) contiene a los menores de 10 años en el gráfico.
- El clúster No 2 (población ocupada) siendo estas las edades más productivas de la población.
- El clúster No 3 (población inactiva) posee una distribución de edades diferente a la anterior distribución ya que en este grupo se encuentran estudiantes, amas de casa, etc., entre otros.
- El clúster No 4 (población desocupada) corresponde a los desocupados, con su respectiva distribución de edades.