Técnicas de explotación de la implantación de un Data Warehouse
Técnicas de explotación de la implantación de un Data Warehouse Carlos 8 August, 2007 - 00:162.2.5.-TÉCNICAS DE EXPLOTACIÓN DE LA IMPLANTACIÓN
2.2.5.- Introducción
2.2.5.3.- Data Mining o Minería de Datos
Introducción
Dentro del esquema de Gestión y Explotación del Data Warehouse que se muestra en el gráfico, pasamos a detallar las posibilidades que nos ofrece esta última fase.

En ella, examinaremos
- el uso que se puede realizar de las utilidades OLAP del Data Warehouse para análisis multidimensionales,
- las facilidades de obtención de información mediante consultas e informes libre, y el uso de técnicas de Data Mining que nos permitan descubrir "información oculta" en los datos mediante el uso de técnicas estadísticas.

OLAP, MOLAP y ROLAP
OLAP, MOLAP y ROLAP Carlos 8 August, 2007 - 00:19Aprende Bases de Datos de forma práctica
¿Quieres complementar la teoría con práctica real? Estos cursos de SQL en español te llevan de cero a nivel avanzado con ejercicios en MySQL, Oracle y SQL Server.
Enlaces de afiliado · Dataprix puede recibir una comisión
2.2.5.1.- OLAP, ROLAP, MOLAP
2.2.5.1.3.- ROLAP vs. MOLAP (Comparativa)
Introducción.-
La explotación del Data Warehouse mediante información de gestión, se fundamenta básicamente en los niveles agrupados o calculados de información.
La información de gestión se compone de conceptos de información y coeficientes de gestión, que los cuadros directivos de la empresa pueden consultar según las dimensiones de negocio que se definan.
Dichas dimensiones de negocio se estructuran a su vez en distintos niveles de detalle (por ejemplo, la dimensión geográfica puede constar de los niveles nacional, provincial, ayuntamientos y sección censal).
Este tipo de sistemas ha existido desde hace tiempo, en el mundo de la informática bajo distintas denominaciones: cuadros de mando, MIS, EIS, etc.
Su realización fuera del entorno del Data Warehouse, puede repercutir sobre estos sistemas en una mayor rigidez, dificultad de actualización y mantenimiento, malos tiempos de respuesta, incoherencias de la información, falta del dato agregado, etc.
Los sistemas de soporte a la decisión usando tecnologías de Data Warehouse, se llaman sistemas OLAP (siglas de On Line Analytical Processing (OLAP). En general, estos sistemas OLAP deben:
- Soportar requerimientos complejos de análisis
- Analizar datos desde diferentes perspectivas
- Soportar análisis complejos contra un volumen ingente de datos
La funcionalidad de los sistemas OLAP se caracteriza por ser un análisis multidimensional de datos corporativos, que soportan los análisis del usuario y unas posibilidades de navegación, seleccionando la información a obtener.
Normalmente este tipo de selecciones se ve reflejada en la visualización de la estructura multidimensional, en unos campos de selección que nos permitan elegir el nivel de agregación (jerarquía) de la dimensión, y/o la elección de un dato en concreto, la visualización de los atributos del sujeto, frente a una(s) dimensiones en modo tabla, pudiendo con ello realizar, entre otras las siguientes acciones:
Rotar (Swap): 		alterar las filas por columnas (permutar dos dimensiones de análisis)
Bajar (Down): 		bajar el nivel de visualización en las filas a una jerarquía inferior
Detallar (Drilldown): 	informar para una fila en concreto, de datos a un nivel inferior
Expandir (Expand): 	id. anterior sin perder la información a nivel superior para éste y el resto de los valores
Colapsar (Collapse): 	operación inversa de la anterior.
Existen dos arquitecturas diferentes para los sistemas OLAP: OLAP multidimensional (MOLAP) y OLAP relacionales (ROLAP).
2.2.5.1.1.-Sistemas MOLAP
La arquitectura MOLAP usa unas bases de datos multidimensionales para proporcionar el análisis, su principal premisa es que el OLAP está mejor implantado almacenando los datos multidimensionalmente. Por el contrario, la arquitectura ROLAP cree que las capacidades OLAP están perfectamente implantadas sobre bases de datos relacionales
Un sistema MOLAP usa una base de datos propietaria multidimensional, en la que la información se almacena multidimensionalmente, para ser visualizada multidimensionalmente.
El sistema MOLAP utiliza una arquitectura de dos niveles: La bases de datos multidimensionales y el motor analítico.
- La base de datos multidimensional es la encargada del manejo, acceso y obtención del dato.
- El nivel de aplicación es el responsable de la ejecución de los requerimientos OLAP. El nivel de presentación se integra con el de aplicación y proporciona un interfaz a través del cual los usuarios finales visualizan los análisis OLAP. Una arquitectura cliente/servidor permite a varios usuarios acceder a la misma base de datos multidimensional.
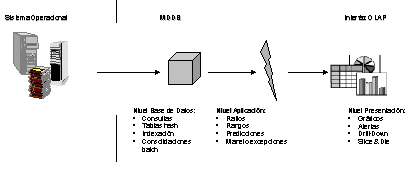
La información procedente de los sistemas operacionales, se carga en el sistema MOLAP, mediante una serie de rutinas batch. Una vez cargado el dato elemental en la Base de Datos multidimensional (MDDB), se realizan una serie de cálculos en batch, para calcular los datos agregados, a través de las dimensiones de negocio, rellenando la estructura MDDB.
Tras rellenar esta estructura, se generan unos índices y algoritmos de tablas hash para mejorar los tiempos de accesos a las consultas.
Una vez que el proceso de compilación se ha acabado, la MDDB está lista para su uso. Los usuarios solicitan informes a través del interface, y la lógica de aplicación de la MDDB obtiene el dato.
La arquitectura MOLAP requiere unos cálculos intensivos de compilación. Lee de datos precompilados, y tiene capacidades limitadas de crear agregaciones dinámicamente o de hallar ratios que no se hayan precalculados y almacenados previamente.
2.2.5.1.2.-Sistemas ROLAP
La arquitectura ROLAP, accede a los datos almacenados en un Data Warehouse para proporcionar los análisis OLAP. La premisa de los sistemas ROLAP es que las capacidades OLAP se soportan mejor contra las bases de datos relacionales.
El sistema ROLAP utiliza una arquitectura de tres niveles. La base de datos relacional maneja los requerimientos de almacenamiento de datos, y el motor ROLAP proporciona la funcionalidad analítica.
- El nivel de base de datos usa bases de datos relacionales para el manejo, acceso y obtención del dato.
- El nivel de aplicación es el motor que ejecuta las consultas multidimensionales de los usuarios.
- El motor ROLAP se integra con niveles de presentación, a través de los cuales los usuarios realizan los análisis OLAP.
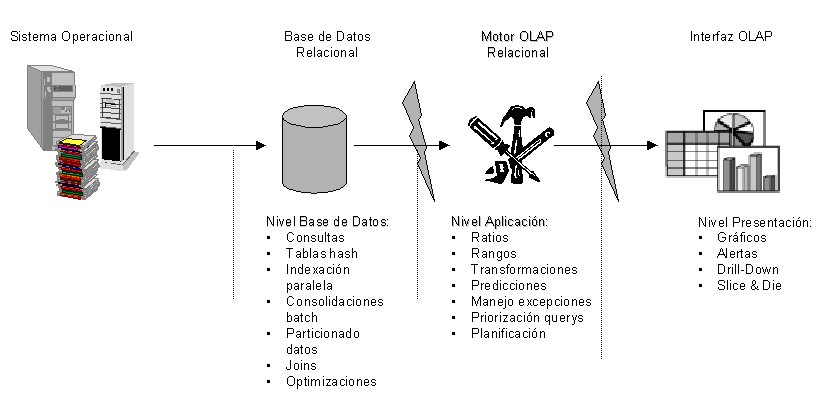
Después de que el modelo de datos para el Data Warehouse se ha definido, los datos se cargan desde el sistema operacional. Se ejecutan rutinas de bases de datos para agregar el dato, si así es requerido por el modelos de datos.
Se crean entonces los índices para optimizar los tiempos de acceso a las consultas.
Los usuarios finales ejecutan sus análisis multidimensionales, a través del motor ROLAP, que transforma dinámicamente sus consultas a consultas SQL. Se ejecutan estas consultas SQL en las bases de datos relacionales, y sus resultados se relacionan mediante tablas cruzadas y conjuntos multidimensionales para devolver los resultados a los usuarios.
La arquitectura ROLAP es capaz de usar datos precalculados si estos están disponibles, o de generar dinámicamente los resultados desde los datos elementales si es preciso. Esta arquitectura accede directamente a los datos del Data Warehouse, y soporta técnicas de optimización de accesos para acelerar las consultas. Estas optimizaciones son, entre otras, particionado de los datos a nivel de aplicación, soporte a la desnormalización y joins múltiples.
2.2.5.1.3.-ROLAP vs. MOLAP (Comparativa)
Cuando se comparan las dos arquitecturas, se pueden realizar las siguientes observaciones:
- El ROLAP delega la negociación entre tiempo de respuesta y el proceso batch al diseño del sistema. Mientras, el MOLAP, suele requerir que sus bases de datos se precompilen para conseguir un rendimiento aceptable en las consultas, incrementando, por tanto los requerimientos batch.
- Los sistemas con alta volatilidad de los datos (aquellos en los que cambian las reglas de agregación y consolidación), requieren una arquitectura que pueda realizar esta consolidación ad-hoc. Los sistemas ROLAP soportan bien esta consolidación dinámica, mientras que los MOLAP están más orientados hacia consolidaciones batch.
- Los ROLAP pueden crecer hasta un gran número de dimensiones, mientras que los MOLAP generalmente son adecuados para diez o menos dimensiones.
- Los ROLAP soportan análisis OLAP contra grandes volúmenes de datos elementales, mientras que los MOLAP se comportan razonablemente en volúmenes más reducidos (menos de 5 Gb)
Por ello, y resumiendo, el ROLAP es una arquitectura flexible y general, que crece para dar soporte a amplios requerimientos OLAP. El MOLAP es una solución particular, adecuada para soluciones departamentales con unos volúmenes de información y número de dimensiones más modestos.
? Aprende Bases de Datos de forma práctica
¿Quieres complementar la teoría con práctica real? Estos cursos de SQL en español te llevan de cero a nivel avanzado con ejercicios en MySQL, Oracle y SQL Server.
Enlaces de afiliado · Dataprix puede recibir una comisión

Query y reporting en un Data Warehouse
Query y reporting en un Data Warehouse Carlos 8 August, 2007 - 00:142.2.5.2.- QUERY & REPORTING
Las consultas o informes libres trabajan tanto sobre el detalle como sobre las agregaciones de la información.
Realizar este tipo de explotación en un almacén de datos supone una optimización del tradicional entorno de informes (reporting), dado que el Data Warehouse mantiene una estructura y una tecnología mucho más apropiada para este tipo de solicitudes.
Los sistemas de "Query & Reporting", no basados en almacenes de datos se caracterizan por la complejidad de las consultas, los altísimos tiempos de respuesta y la interferencia con otros procesos informáticos que compartan su entorno.
La explotación del Data Warehouse mediante "Query & Reporting" debe permitir una gradación de la flexibilidad de acceso, proporcional a la experiencia y formación del usuario. A este respecto, se recomienda el mantenimiento de al menos tres niveles de dificultad:
- Los usuarios poco expertos podrán solicitar la ejecución de informes o consultas predefinidas según unos parámetros predeterminados.
- Los usuarios con cierta experiencia podrán generar consultas flexibles mediante una aplicación que proporcione una interfaz gráfica de ayuda.
- Los usuarios altamente experimentados podrán escribir, total o parcialmente, la consulta en un lenguaje de interrogación de datos.
Hay una extensa gama de herramientas en el mercado para cumplir esta funcionalidad sobre entornos de tipo Data Warehouse, por lo que se puede elegir el software más adecuado para cada problemática empresarial concreta.
Minería de datos
Minería de datos Carlos 8 August, 2007 - 00:232.2.5.3.- DATA MINING O MINERÍA DE DATOS
2.2.5.3.2.- Técnicas de Data Mining
2.2.5.3.3.- Metodología de aplicación
2.2.5.3.1.-Introducción
El Data Mining es un proceso que, a través del descubrimiento y cuantificación de relaciones predictivas en los datos, permite transformar la información disponible en conocimiento útil de negocio. Esto es debido a que no es suficiente "navegar" por los datos para resolver los problemas de negocio, sino que se hace necesario seguir una metodología ordenada que permita obtener rendimientos tangibles de este conjunto de herramientas y técnicas de las que dispone el usuario.
Constituye por tanto una de las vías clave de explotación del Data Warehouse, dado que es este su entorno natural de trabajo.
Se trata de un concepto de explotación de naturaleza radicalmente distinta a la de los sistemas de información de gestión, dado que no se basa en coeficientes de gestión o en información altamente agregada, sino en la información de detalle contenida en el almacén. Adicionalmente, el usuario no se conforma con la mera visualización de datos, sino que trata de obtener una relación entre los mismos que tenga repercusiones en su negocio.
2.2.5.3.2.Técnicas de Data Mining
Para soportar el proceso de Data Mining, el usuario dispone de una extensa gama de técnicas que le pueden ayudar en cada una de las fases de dicho proceso, las cuales pasamos a describir:
Análisis estadístico:
Utilizando las siguientes herramientas:
- ANOVA: o Análisis de la Varianza, contrasta si existen diferencias significativas entre las medidas de una o más variables continuas en grupo de población distintos.
- Regresión: define la relación entre una o más variables y un conjunto de variables predictoras de las primeras.
- Ji cuadrado: contrasta la hipótesis de independencia entre variables.
- Componentes principales: permite reducir el número de variables observadas a un menor número de variables artificiales, conservando la mayor parte de la información sobre la varianza de las variables.
- Análisis cluster: permite clasificar una población en un número determinado de grupos, en base a semejanzas y desemejanzas de perfiles existentes entre los diferentes componentes de dicha población.
- Análisis discriminante: método de clasificación de individuos en grupos que previamente se han establecido, y que permite encontrar la regla de clasificación de los elementos de estos grupos, y por tanto identificar cuáles son las variables que mejor definan la pertenencia al grupo.
Métodos basados en árboles de decisión:
El método Chaid (Chi Squared Automatic Interaction Detector) es un análisis que genera un árbol de decisión para predecir el comportamiento de una variable, a partir de una o más variables predictoras, de forma que los conjuntos de una misma rama y un mismo nivel son disjuntos. Es útil en aquellas situaciones en las que el objetivo es dividir una población en distintos segmentos basándose en algún criterio de decisión.
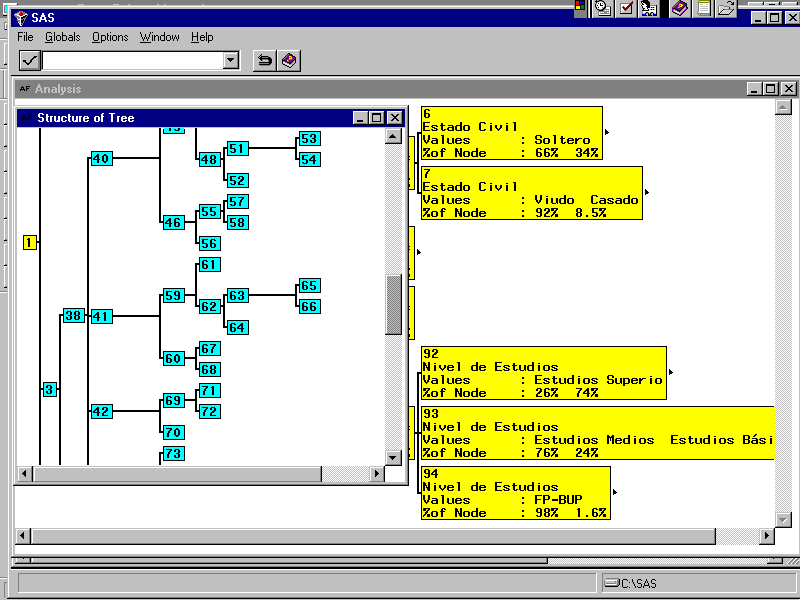
El árbol de decisión se construye partiendo el conjunto de datos en dos o más subconjuntos de observaciones a partir de los valores que toman las variables predictoras. Cada uno de estos subconjuntos vuelve después a ser particionado utilizando el mismo algoritmo. Este proceso continúa hasta que no se encuentran diferencias significativas en la influencia de las variables de predicción de uno de estos grupos hacia el valor de la variable de respuesta.
La raíz del árbol es el conjunto de datos íntegro, los subconjuntos y los subsubconjuntos conforman las ramas del árbol. Un conjunto en el que se hace una partición se llama nodo.
El número de subconjuntos en una partición puede ir de dos hasta el número de valores distintos que puede tomar la variable usada para hacer la separación. La variable de predicción usada para crear una partición es aquella más significativamente relacionada con la variable de respuesta de acuerdo con test de independencia de la Chi cuadrado sobre una tabla de contingencia.
Algoritmos genéticos:
Son métodos numéricos de optimización, en los que aquella variable o variables que se pretenden optimizar junto con las variables de estudio constituyen un segmento de información. Aquellas configuraciones de las variables de análisis que obtengan mejores valores para la variable de respuesta, corresponderán a segmentos con mayor capacidad reproductiva. A través de la reproducción, los mejores segmentos perduran y su proporción crece de generación en generación. Se puede además introducir elementos aleatorios para la modificación de las variables (mutaciones). Al cabo de cierto número de iteraciones, la población estará constituida por buenas soluciones al problema de optimización.
Redes neuronales:
Genéricamente son métodos de proceso numérico en paralelo, en el que las variables interactúan mediante transformaciones lineales o no lineales, hasta obtener unas salidas. Estas salidas se contrastan con los que tenían que haber salido, basándose en unos datos de prueba, dando lugar a un proceso de retroalimentación mediante el cual la red se reconfigura, hasta obtener un modelo adecuado.
Lógica difusa:
Es una generalización del concepto de estadística. La estadística clásica se basa en la teoría de probabilidades, a su vez ésta en la técnica conjuntista, en la que la relación de pertenencia a un conjunto es dicotómica (el 2 es par o no lo es). Si establecemos la noción de conjunto borroso como aquel en el que la pertenencia tiene una cierta graduación (¿un día a 20ºC es caluroso?), dispondremos de una estadística más amplia y con resultados más cercanos al modo de razonamiento humano.
Series temporales:
Es el conocimiento de una variable a través del tiempo para, a partir de ese conocimiento, y bajo el supuesto de que no van a producirse cambios estructurales, poder realizar predicciones. Suelen basarse en un estudio de la serie en ciclos, tendencias y estacionalidades, que se diferencian por el ámbito de tiempo abarcado, para por composición obtener la serie original. Se pueden aplicar enfoques híbridos con los métodos anteriores, en los que la serie se puede explicar no sólo en función del tiempo sino como combinación de otras variables de entorno más estables y, por lo tanto, más fácilmente predecibles.
2.2.5.3.3. Metodología de aplicación:
Para utilizar estas técnicas de forma eficiente y ordenada es preciso aplicar una metodología estructurada, al proceso de Data Mining. A este respecto proponemos la siguiente metodología, siempre adaptable a la situación de negocio particular a la que se aplique:
Muestreo
Extracción de la población muestral sobre la que se va a aplicar el análisis. En ocasiones se trata de una muestra aleatoria, pero puede ser también un subconjunto de datos del Data Warehouse que cumplan unas condiciones determinadas. El objeto de trabajar con una muestra de la población en lugar de toda ella, es la simplificación del estudio y la disminución de la carga de proceso. La muestra más óptima será aquella que teniendo un error asumible contenga el número mínimo de observaciones.
En el caso de que se recurra a un muestreo aleatorio, se debería tener la opción de elegir
- El nivel de confianza de la muestra (usualmente el 95% o el 99%).
- El tamaño máximo de la muestra (número máximo de registros), en cuyo caso el sistema deberá informar del el error cometido y la representatividad de la muestra sobre la población original.
- El error muestral que está dispuesto a cometer, en cuyo caso el sistema informará del número de observaciones que debe contener la muestra y su representatividad sobre la población original.
Para facilitar este paso s debe disponer de herramientas de extracción dinámica de información con o sin muestreo (simple o estratificado). En el caso del muestreo, dichas herramientas deben tener la opción de, dado un nivel de confianza, fijar el tamaño de la muestra y obtener el error o bien fijar el error y obtener el tamaño mínimo de la muestra que nos proporcione este grado de error.
Exploración
Una vez determinada la población que sirve para la obtención del modelo se deberá determinar cuales son las variables explicativas que van a servir como "inputs" al modelo. Para ello es importante hacer una exploración por la información disponible de la población que nos permita eliminar variables que no influyen y agrupar aquellas que repercuten en la misma dirección.
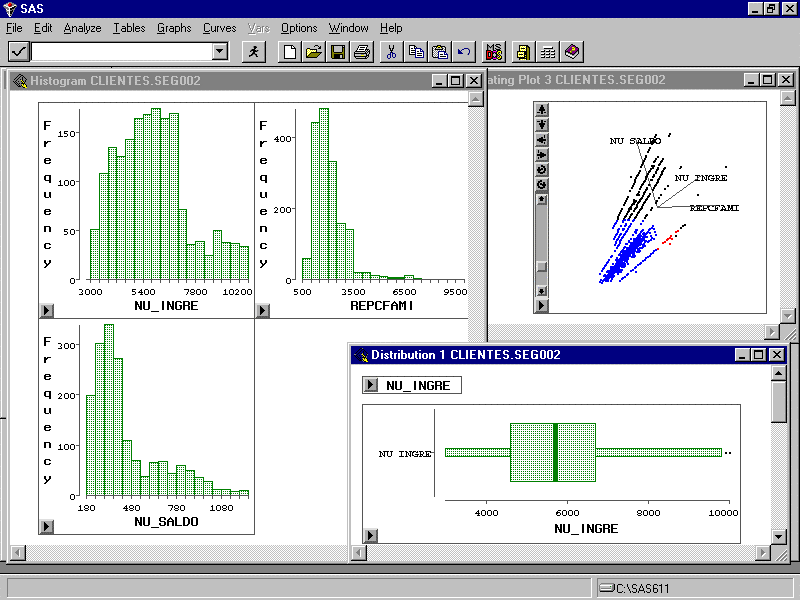
El objetivo es simplificar en lo posible el problema con el fin de optimizar la eficiencia del modelo. En este paso se pueden emplear herramientas que nos permitan visualizar de forma gráfica la información utilizando las variables explicativas como dimensiones.
También se pueden emplear técnicas estadísticas que nos ayuden a poner de manifiesto relaciones entre variables. A este respecto resultará ideal una herramienta que permita la visualización y el análisis estadístico integrados
Manipulación
Tratamiento realizado sobre los datos de forma previa a la modelización, en base a la exploración realizada, de forma que se definan claramente los inputs del modelo a realizar (selección de variables explicativas, agrupación de variables similares, etc.).
Modelización
Permite establecer una relación entre las variables explicativas y las variables objeto del estudio, que posibilitan inferir el valor de las mismas con un nivel de confianza determinado.
Valoración
Análisis de la bondad del modelo contrastando con otros métodos estadísticos o con nuevas poblaciones muestrales.
Webhousing
Webhousing Carlos 8 August, 2007 - 00:102.2.5.4.- WEBHOUSING
La popularización de Internet y la tecnología Web, ha creado un nuevo esquema de información en el cual los clientes tienen a su disposición unas cantidades ingentes de información. La integración de las tecnologías Internet y Data Warehouse tienen una serie de ventajas como son:
- Consistencia: toda la organización accede al mismo conjunto de datos y ve los informes que reflejan
sus necesidades. Hay una "única versión de la verdad". - Accesibilidad: la empresa acede a la información a través de un camino común (el browser
de Internet), simplificando el proceso de búsqueda de la información. - Disponibilidad: la información es accesible en todo momento, independientemente de los sistemas operacionales.
- Bajos costes de desarrollo y mantenimiento, debidos a la estandarización de las aplicaciones de consultas
basadas en Internet, independientemente del sistema operativo que soporte el browser, y de la reducción
de los costes de distribución de software en los puestos clientes. - Protección de los datos, debido al uso de tecnologías consolidadas de protección en entornos
de red (firewalls). - Bajos costes de formación, debido al uso de interfaces tipo Web.
La interactividad de las aplicaciones en este entorno pueden tener varios niveles:
- Publicación de datos: las páginas distribuyen información obtenida del Data Warehouse,
volcada en las páginas intra/internet. - Distribución de reportes: dando soporte a consultas simples elaboradas por los usuarios.
- Aplicaciones dinámicas: sirviendo de soporte de decisión a servicios solicitados desde el puesto
cliente, ejecutando la petición en el servidor y devolviéndolas al cliente, vía el browser
de Internet o haciendo uso de "applets" de Java.
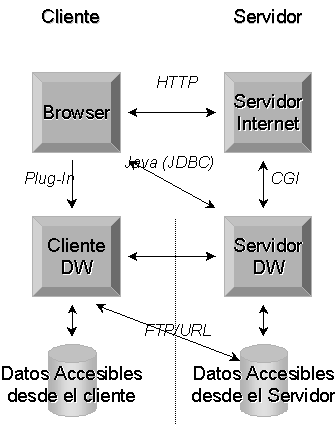
Las arquitecturas base de una implantación de Data Warehouse en Internet, pueden tener las siguientes
alternativas:
- Usar el Servidor Internet como router, y ejecutar la petición desde el cliente al servidor directamente.
- Hacer uso del navegador para visualizar una página Internet residente en el servidor de Internet. Esta
página contendría información que se actualizaría en el servidor Internet, desde el
servidor DW, a petición del usuario haciendo uso de CGI's. - El cliente podría lanzar su consulta directamente al servidor de DW, con "applets" de Java,
haciendo el servidor Internet únicamente de encaminamiento (router). - El cliente podría ejecutar la aplicación DW desde el navegador, pero con un plug-in, que haría
que se tuvieran las mismas opciones que la aplicación DW. - Realizar una descarga masiva de datos con un protocolo de transferencia de ficheros (FTP), para su proceso
en local.
El alcance funcional de la implantación del Data Warehouse, basado en tecnologías Internet, puede ser la misma que la realizada sin su uso. En este sentido las críticas que se le pueden achacar en la actualidad, provienen de la baja velocidad de las líneas actuales, que se solventa parcialmente mediante el uso de aplicaciones Java, en lugar de hacer uso de páginas HTML, o CGI. Solución parcial, mientras la velocidad de transferencia se incrementa día a día mediante nuevos algoritmos de compresión de datos o el uso de líneas de alta capacidad RDSI.