Snowflake Data and AI Platform
Snowflake Data and AI PlatformSnowflake se presenta como una plataforma de datos nativa en la nube, diseñada para consolidar funcionalidades de almacenamiento, procesamiento y compartición de datos en un entorno administrado que abstrae en gran medida la infraestructura subyacente. Corre sobre AWS, Azure y Google Cloud, y adopta una arquitectura que separa almacenamiento de cómputo, lo que le permite escalar ambos de forma independiente.
La plataforma concentra datos estructurados y no estructurados en un catálogo accesible por SQL y APIs, proporciona motores de consulta optimizados para analítica y añade capacidades avanzadas de modelado, entrenamiento y serving de modelos mediante componentes nativos y servicios integrados de terceros. La evolución reciente ha introducido funciones multimodales para trabajar con texto, documentos e imágenes sin salir del perímetro de datos, lo que transforma flujos de trabajo tradicionales de ingeniería de datos y ciencia de datos.
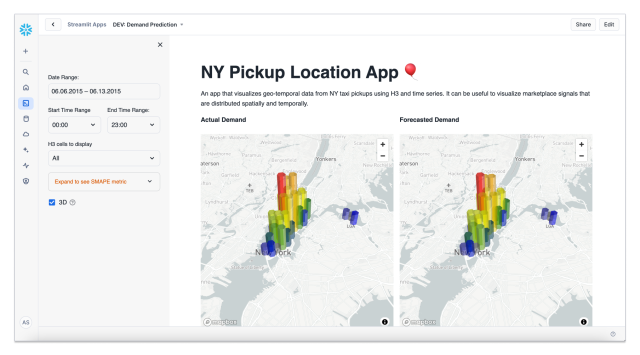
La arquitectura combina un data lakehouse lógico construido sobre formatos abiertos (Iceberg, Parquet), un motor de ejecución columnar y servicios administrados para ingestión, búsqueda semántica, vector stores y agentes de IA. La plataforma ofrece múltiples opciones de cómputo escalable, optimizaciones hardware-software y herramientas para observabilidad de pipelines y modelos.
En su evolución más reciente, Snowflake ha extendido su propósito clásico de data warehouse hacia el terreno de la IA y el aprendizaje automático, integrando capacidades para construir, desplegar y operar modelos directamente sobre su plataforma, sin necesidad de mover datos. Esa capa de extensión incluye componentes como Snowpark, funciones definidas por el usuario (UDF) en Python/Java/Scala, y el reciente módulo Cortex, que incorpora motores generativos, búsqueda vectorial y orquestación de modelos.
Desde la perspectiva de un departamento de TI con responsabilidades en gobernanza y en adopción de IA, la propuesta de Snowflake presenta una apuesta por la democratización del valor de los datos: usuarios de negocio, analistas y científicos de datos acceden a capacidades de IA mediante SQL, notebooks y asistentes conversacionales integrados, con controles de seguridad y trazabilidad alrededor del dato y del modelo. Esa convergencia reduce la fricción entre ingestion, preparación, entrenamiento y despliegue, y facilita que iniciativas de machine learning pasen de prototipo a producción con menos fragmentación tecnológica.
Arquitectura y fundamentos tecnológicos
Separación de almacenamiento y cómputo, y naturaleza “serverless controlado”
Uno de los pilares de Snowflake es su arquitectura que disocia el almacenamiento persistente del cómputo activo. Esta separación permite que múltiples “warehouses” (clusters virtuales) accedan al mismo almacén sin interferencia, y que cada uno escale independientemente. De ese modo se optimiza el uso de recursos y se aísla la carga entre tareas analíticas o de modelado.
Aunque se promociona como en muchos aspectos “serverless”, no es completamente desatendido: los usuarios deben decidir el tamaño, número y configuración de los warehouses, así como cuándo pausar, escalar o ajustar esas instancias. Esa configuración requiere conocimiento técnico de SQL y arquitectura de data warehouse.
Snowflake administra internamente tareas operativas críticas: optimización de almacenamiento, gestión de metadatos, compresión, reordenamiento físico, actualización automática del software y balanceo de carga. Esa gestión oculta complejidad operativa a equipos de datos, pero al mismo tiempo implica que no se tiene control fino de la infraestructura subyacente.
En términos de implantación, la plataforma ofrece un modelo gestionado que reduce la carga operativa del equipo de infra. Las configuraciones multi-región y multicloud existen, con capacidades para compartir datos entre cuentas y organizaciones, lo que facilita patrones de colaboración B2B y neutraliza algunos riesgos de bloqueo aunque exige cuidada planificación de latencias y soberanía.
Capas de extensión para IA / ML: Snowpark, UDFs, funciones nativas, Cortex
Para que el ecosistema de IA y ML prospere dentro de la plataforma, Snowflake ha desarrollado diversas herramientas extensibles:
-
Snowpark proporciona APIs para ejecutar lógica de datos en Python, Java o Scala directamente cerca del almacenamiento, sin necesidad de extraer los datos. Actúa como la plataforma de ejecución de tareas de transformación, preparación de datos o inferencia ligera directamente dentro del entorno Snowflake.
-
Funciones definidas por el usuario (UDF / UDTF / UDAF) permiten extender el motor con código personalizado (por ejemplo, Python) para ejecutar transformaciones complejas o inferencias de modelos. Esto posibilita aplicar modelos ML directamente sobre tablas.
-
Funciones nativas / integradas de IA dentro de Snowflake (por ejemplo, operaciones de vector search, embeddings, LLMs) forman parte de la iniciativa Cortex. Cortex facilita descubrir insights, generar texto, construir agentes de IA o ejecutar búsquedas vectoriales, todo ello desde el ecosistema nativo.
-
Snowflake también permite contenerización de modelos o despliegue en contexto mediante servicios de contenedor, integrando lógica más compleja.
-
Por último, Snowflake impulsa la integración con marcos externos (TensorFlow, PyTorch, scikit-learn, etc.) mediante conectores o exportación de datos, lo que mantiene flexibilidad para pipelines híbridos.
Gestión de datos, formatos y escalabilidad
Snowflake acepta datos estructurados y semi-estructurados (JSON, Avro, Parquet, ORC), con mecanismos incorporados para consultar esos formatos desde SQL sin necesidad de preprocesamiento riguroso (por ejemplo, funciones de transformación automática desde JSON).
El almacenamiento se construye sobre sistemas de objetos en la nube (por ejemplo, S3 en AWS), con versiones de datos históricas (time travel), clonación instantánea (zero-copy cloning) y optimización interna de micro-particionamiento.
En cuanto a escalabilidad, Snowflake permite expandir o reducir la capacidad de cómputo dinámicamente. Su modelo de pago por consumo habilita pagar solo por lo utilizado, aunque ese modelo demanda disciplina para evitar sobrecostes.
Metadatos, catálogos y optimización de consultas están integrados de forma automática, con herramientas de optimización de ejecución (pruning de particiones, estadísticas automáticas) que reducen la carga de ajuste manual.
Gobierno, seguridad y operativa
Snowflake incorpora control de acceso fino (roles, permisos a nivel de objeto, enmascaramiento de datos, seguridad a nivel de fila/columna), auditoría, cifrado en reposo y en tránsito, y compatibilidad con estándares de cumplimiento de industria.
Su paradigma de gobernanza se complementa con funciones de etiquetado de objetos, clasificación de datos, lineage (trazabilidad de flujos) y visibilidad del uso.
Operativamente, la plataforma está diseñada para minimizar la administración: actualizaciones automáticas, mantenimiento interno y optimización de infraestructura recae en el proveedor. Eso reduce la carga operativa del equipo técnico, aunque al precio de menor control sobre ajustes finos de hardware.
Ciclo de vida de modelos de Machine Learning en Snowflake
Para quienes evalúan Snowflake en el contexto de IA/ML, es esencial comprender cómo soporta (o habilita) cada fase del ciclo de vida de un modelo:
Descubrimiento y preparación de datos
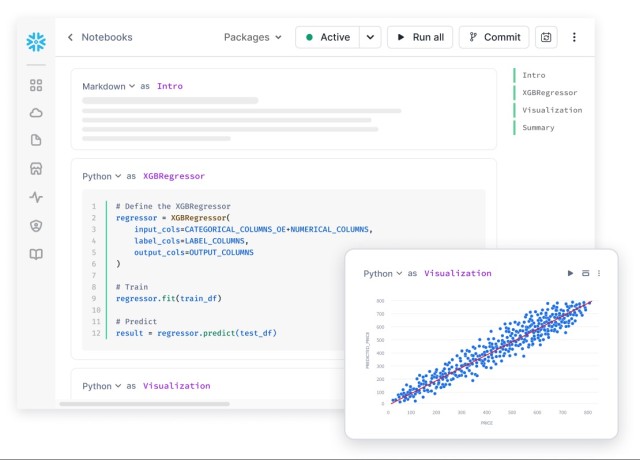
La fase inicial consiste en explorar, limpiar y transformar datos para extraer features. Snowflake ofrece herramientas SQL tradicionales, funciones sobre estructuras semi-estructuradas, y capacidades de feature engineering directamente en el banco de datos mediante SQL o Snowpark. Esa proximidad al dato acelera la fase exploratoria.
Además, el hecho de que los datos no deban moverse fuera de la plataforma reduce la latencia de operaciones y disminuye los riesgos de duplicación o versiones inconsistentes.
Sin embargo, cuando las operaciones de transformación son extremadamente complejas (por ejemplo, pipelines de streaming extensivos), algunos equipos optan por combinar Snowflake con plataformas especializadas (como Databricks) para esa capa ETL pesada. En foros técnicos se debate esa opción híbrida regularmente.
Entrenamiento de modelos
Snowflake proporciona la capacidad de entrenar modelos ligeros o intermedios mediante UDFs o lógica en Snowpark. Para entrenamientos más intensivos, muchos equipos prefieren extraer subconjuntos de datos hacia entornos GPU externos optimizados (clusters de ML dedicados) y luego importar los modelos entrenados al entorno Snowflake para inferencia.
No obstante, con Cortex, Snowflake amplía su alcance al permitir entrenamiento interno de modelos generativos, manejo de embeddings y búsqueda vectorial en contextos más amplios, integrando funcionalidades de IA generativa sin necesidad de infraestructura externa.
Despliegue e inferencia
Uno de los puntos más potentes es que Snowflake permite ejecutar inferencias cerca de los datos mediante UDF o contenedores, eliminando latencias de transmisión. Eso facilita aplicaciones en tiempo casi real dentro de pipelines analíticos.
Cortex también introduce la posibilidad de orquestar agentes de IA o aplicaciones generativas directamente dentro de la plataforma, combinando modelos y lógica de negocio sin necesidad de capas intermedias.
Snowflake ofrece modelos de inferencia escalables, con posibilidad de paralelismo y concurrencia ajustable según la demanda de computación.
Monitorización, gobernanza y reentrenamiento
Para mantener modelos actualizado, es imprescindible monitorizar su rendimiento (drift), rastrear datos de entrada y salida (lineage), y tener procesos de retraining automáticos. Snowflake brinda visibilidad operativa, registros de uso y trazabilidad de datos. Las capacidades de gobernanza y control permiten auditar las predicciones, revisar versiones de modelos y aplicar controles de acceso sobre modelos e inferencias.
Para retraining, es común usar nuevamente las capacidades internas o combinar con pipelines externos que vuelven a entrenar y desplegar versiones nuevas dentro de Snowflake.
Integración con ecosistemas y conectores
Snowflake no busca competir con todos los productos del mercado, sino interoperar con ellos. En ese sentido:
-
Tiene conectores nativos a herramientas de BI como Tableau, Power BI, Looker, Qlik, Sigma, entre otras.
-
Puede integrarse con plataformas de orquestación de datos (Airflow, dbt, etc.).
-
Permite conectividad con herramientas de ML externas (por ejemplo, exportar a formatos compatibles o usar conectores Python/SQL).
-
Su Mercado de Datos (Snowflake Marketplace) facilita compartir datos en vivo entre organizaciones, con acceso directo a datasets listos para consulta.
-
Su ecosistema de partners y redes recientemente ha sido reforzado para atender la demanda creciente en IA.
Esa capa de integración permite a los equipos mixtos (analistas, científicos de datos, ingenieros) trabajar con sus herramientas preferidas sin quedar encerrados en una sola plataforma.
Gobernanza, seguridad y cumplimiento
La plataforma incorpora controles de acceso, encriptación y capacidades de compartición segura que resultan imprescindibles en proyectos empresariales con IA. Los elementos principales de gobernanza incluyen:
-
Control de acceso granular: políticas RBAC, masking dinámico y control a nivel de fila/columna para minimizar exposición de datos sensibles.
-
Cifrado por defecto: datos en reposo y en tránsito cifrados, con gestión de claves (KMS) y opciones para integración con claves propias del cliente.
-
Audit logging y lineage: trazabilidad de consultas, cambios en esquemas y movimientos de datos; útil para auditorías y para demostrar cumplimiento normativo.
-
Perímetro gestionado de modelos: ejecución de modelos y LLMs dentro de la plataforma reduce superficie de riesgo y facilita controles de privacidad y gestión de datos de entrenamiento.
Ventajas para cumplimiento:
-
Soporte para políticas de retención y data residency, con despliegue multirregión y controles de localización.
-
Marketplaces y extensiones que respetan control de datos, permitiendo incorporar datasets externos sin perder gobernanza.
Cuestiones críticas:
-
La gobernanza de prompts y del ciclo de vida de modelos generativos requiere procesos organizativos: definición de responsables, políticas de revisión de outputs y pruebas de equidad y bias.
-
Integraciones con servicios externos (por ejemplo, modelos alojados en terceros) deben evaluarse con matrices de riesgo por la posible transferencia de datos o metadatos sensibles.
Rendimiento, escalabilidad y costes
Snowflake ha desarrollado optimizaciones para mejorar el rendimiento analítico y reducir costes mediante elasticidad. Las prácticas habituales para optimizar adopción incluyen:
-
Dimensionamiento de warehouses acorde a la concurrencia y al tipo de consulta: cargas ad-hoc y dashboards interactivos pueden usar warehouses distintos a los de ETL.
-
Uso de caching y materialized views para reducir consultas repetidas y latencias.
-
Segmentación de datos por particionado lógico y uso de formatos columnar para mejorar IO.
-
Monitorización de consumo y configuración de políticas de auto-suspend/auto-resume para evitar facturación innecesaria.
Trade-offs económicos:
-
El modelo de pago por uso facilita comenzar sin inversión inicial, pero cargas altas de inferencia con LLM o pipelines de streaming intensivos pueden generar factura elevada si no se controlan.
-
Migraciones masivas de datos a la plataforma y retención prolongada de grandes volúmenes requieren planificación FinOps para gestionar coste total de propiedad.
Recomendaciones prácticas:
-
Implementar tagging y showback para imputar costes por equipo o proyecto.
-
Aplicar políticas de retención graduales con tiering para archivar datos fríos.
-
Evaluar modelos de compromiso (reserved capacity) si hay cargas predecibles que justifiquen descuento por consumo.
Comparativa frente a competidores
Para decidir si Snowflake encaja en tu organización, conviene compararlo frente a otras opciones fuertes del mercado, como Databricks, Google BigQuery ML, Azure Synapse + ML, entre otros.
Snowflake vs Databricks
-
Databricks se originó como plataforma unificada basada en Spark, con fuerte énfasis en transformación de datos, notebooks colaborativos y arquitecturas tipo lakehouse. Snowflake empezó como data warehouse puro y ha ido extendiéndose hacia ML.
-
En tareas complejas de streaming o pipelines de transformación masiva, Databricks puede tener ventaja operativa. En cambio, Snowflake gana en simplicidad y aislamiento entre cargas de trabajo analíticas.
-
Snowflake requiere menos configuración para administrar cargas concurrency, y su modelo serverless/cero administración es más pulido típicamente.
-
Algunos usuarios reportan que los costos de computación en Snowflake pueden ser más altos comparados con entornos Spark bien dimensionados, especialmente para tareas reiterativas o uso intensivo. Hay debates en comunidades técnicas al respecto.
-
En cuanto a AI/ML, Databricks ofrece un ecosistema más maduro para notebooks colaborativos, experimentación y pipelines de entrenamiento nativo, aunque la brecha se ha ido cerrando con los esfuerzos de Snowflake.
Snowflake vs BigQuery ML / Azure Synapse
-
BigQuery ofrece la ventaja de ejecutar modelos ML directamente desde SQL mediante BigQuery ML, lo cual es muy atractivo para cargas de trabajo simples basadas en SQL puro. Sin embargo, puede carecer de flexibilidad para modelos más complejos.
-
Azure Synapse ofrece integración nativa con servicios como Azure ML, lo que puede resultar atrayente para entornos Microsoft.
-
Snowflake compite al ofrecer mayor neutralidad de nube (multicloud) y mejor separación entre cómputo y almacenamiento frente a algunos rivales que tienen dependencias más fuertes con un solo proveedor de nube.
Fortalezas competitivas clave
-
Alta facilidad de uso y experiencia relativamente homogénea entre diferentes niveles de usuarios.
-
Escalabilidad automática que tolera picos de demanda.
-
Ecosistema creciente en IA/ML con Cortex.
-
Muy buena gobernanza, seguridad y cumplimiento.
-
Flexibilidad multicloud.
Áreas donde otros pueden ganar
-
Para tareas de entrenamiento intensivo (GPU / deep learning), plataformas especializadas siguen siendo más eficientes.
-
Si un cliente ya está muy invertido en un ecosistema cloud específico (por ejemplo, Azure), podría preferir herramientas nativas que integren ML de forma más estrecha.
-
Costes operativos y económicos pueden dispararse si no se optimiza el uso.
Puntos fuertes y débiles: análisis crítico
Puntos fuertes
-
Abstracción operativa
La mayor parte de la administración de infraestructura queda bajo el paraguas del proveedor, lo que libera a los equipos de datos de tareas tediosas como parches, mantenimiento o ajustes físicos. -
Escalabilidad elástica y separación compute/almacenamiento
Esa separación permite un uso eficiente de recursos y escalabilidad granular de cargas analíticas o de inferencia. -
Ejecución de IA/ML “cerca del dato”
La capacidad de ejecutar inferencias directamente sobre tablas minimiza latencias y reduce la complejidad de arquitecturas distribuidas. -
Governanza, seguridad y cumplimiento integrados
Snowflake entrega controles finos, auditoría y políticas de acceso listas para entornos corporativos con exigencias regulatorias. -
Compatibilidad multicloud y ecosistema abierto
La independencia de proveedor de nube favorece estrategias híbridas/multicloud, y la gran variedad de conectores permite coexistir con otros sistemas. -
Innovación centrada en IA generativa con Cortex
La integración de modelos generativos, vectores y agentes dentro del ecosistema es un diferenciador emergente.
Debilidades o retos
-
Costes y control de uso
Varios usuarios advierten que un uso no optimizado —warehouses sobredimensionados, consultas frecuentes, transformación de grandes volúmenes— puede generar facturas muy elevadas.
La trazabilidad de costes (cost management) exige disciplina y herramientas de monitoreo para evitar sorpresas. -
Curva de aprendizaje y complejidad inicial
Dominar la arquitectura, elegir tamaños adecuados de warehouses y optimizar consultas demanda experiencia. Algunos usuarios nuevos se sienten abrumados. -
Limitaciones en entrenamiento profundo/inferencia pesada
Aunque eficientes para muchos casos de uso, las capacidades nativas pueden no competir con soluciones dedicadas (clusters GPU externos) para entrenamiento de modelos pesados. -
Menor control de infraestructura
Al estar más abstraída la infraestructura, usuarios con necesidades específicas de personalización difícilmente pueden modificar aspectos de hardware o ajuste bajo nivel. -
Funcionalidades IA emergentes aún en evolución
Aunque Cortex y funciones integradas nacen con ambición, su madurez aún no equipara a productos especializados de IA. Algunos casos extremos pueden demandar capacidades aún no cubiertas. -
Dependencia de conectividad y latencia de red
Como plataforma en la nube, el rendimiento depende de la calidad del acceso a red. Para entornos con conectividad limitada puede haber penalizaciones. -
Riesgo de vendor lock-in
A medida que modelos y lógica se integran profundamente en Snowflake, migrar parte del pipeline a otra plataforma puede implicar esfuerzos de reescritura.
Tabla Resumen de Fortalezas y Debilidades de Snowflake
-
Fortalezas principales: arquitectura multicloud, integración nativa de IA/ML, alta seguridad, IA generativa con Cortex, escalabilidad elástica.
-
Debilidades clave: costes variables, falta de control sobre infraestructura, entrenamiento limitado para deep learning, dependencia de red.
| Fortalezas de Snowflake | Debilidades de Snowflake |
|---|---|
| Arquitectura elástica y multicloud: separación total entre almacenamiento y cómputo, con escalado automático e independencia de proveedor (AWS, Azure, GCP). | Costes variables y difíciles de controlar si no se monitoriza el consumo. Requiere buena gestión de warehouses y queries. |
| Integración nativa con IA y Machine Learning mediante Snowpark y Cortex, que permiten crear y ejecutar modelos directamente sobre los datos. | Limitaciones en entrenamiento intensivo de modelos complejos (Deep Learning o GPU-heavy) que exigen plataformas externas. |
| Gobernanza y seguridad avanzadas con cifrado integral, auditoría, mascarado dinámico y cumplimiento de normativas (GDPR, SOC 2, HIPAA). | Menor control de infraestructura: el usuario no puede personalizar hardware o configuración del entorno subyacente. |
| Alta disponibilidad y rendimiento estable incluso con cargas concurrentes elevadas; ideal para entornos empresariales. | Curva de aprendizaje inicial para nuevos equipos que desconocen la arquitectura de warehouses y optimización SQL. |
| IA generativa integrada con funciones de búsqueda vectorial, embeddings y LLMs a través de Cortex. | Funcionalidades de IA aún en evolución; algunas capacidades de Cortex todavía están en fase temprana frente a soluciones especializadas. |
| Modelo de pago por uso flexible, ideal para escalar proyectos de Data Science sin inversión inicial elevada. | Dependencia total de conectividad cloud: el rendimiento puede verse afectado en entornos con redes limitadas o inestables. |
| Interoperabilidad amplia con herramientas de BI (Tableau, Power BI), MLOps y frameworks como TensorFlow o PyTorch. | Posible vendor lock-in al depender de funciones y APIs propietarias para lógica avanzada de IA. |
Casos de uso típicos y escenarios recomendados
Para ilustrar dónde Snowflake ofrece valor claro, y dónde quizás no es ideal, presentamos escenarios representativos:
Casos de uso ideales
-
Análisis y machine learning sobre grandes volúmenes de datos estructurados o semiestructurados
Organizaciones que tienen grandes pipelines de datos — logs, datos transaccionales, eventos — y desean aplicar modelos predictivos sin mover datos fuera de la plataforma. -
Sistemas de recomendación, scoring o predicción en tiempo cercano a real
Al ejecutar inferencias directamente sobre los datos más recientes, plataformas como e-commerce, fintech o análisis en línea pueden acelerar decisiones. -
IA generativa integrada a productos de datos
Aplicaciones que requieren generación de texto, resúmenes, agentes o búsqueda semántica pueden beneficiarse de Cortex y funciones vectoriales en línea. -
Estrategias de gobernanza y compartición segura de datos
Empresas que necesitan compartición de datos entre unidades o incluso con terceros (partners) pueden usar Snowflake Marketplace o capacidades nativas de intercambio seguro. -
Migraciones de data warehouses on-prem hacia la nube
Clientes con grandes sistemas heredados pueden trasladar workloads de BI/analítica hacia Snowflake, beneficiándose de su arquitectura administrada y escalabilidad.
Escenarios menos ideales
-
Entrenamiento extensivo de modelos de deep learning
Un proyecto que exige entrenar redes neuronales complejas con GPU masiva puede requerir plataformas especializadas. -
Operaciones en entornos con conectividad difícil o intermitente
Si la latencia de red hacia la nube es alta o poco fiable, la experiencia global puede degradarse. -
Requisitos de personalización profunda de hardware / optimización al nivel de sistema operativo
Si el cliente necesita ajustar hardware, disco local o funciones de kernel, plataformas autogestionadas seguirán siendo más flexibles. -
Ecosistemas muy atados a nube específica (Azure ML, AWS Sagemaker, Google Vertex AI)
En entornos fuertemente integrados se puede preferir soluciones nativas para minimizar brechas de integración.
Recomendaciones para selección e implementación exitosa
Al evaluar o implementar Snowflake para IA y ML, conviene seguir buenas prácticas y tener ojo en ciertos aspectos críticos:
-
Dimensionamiento y límites de costos desde el inicio
Definir políticas de uso, alertas y presupuestos para evitar sorpresas. Usar warehouses pausables, escalado automático y monitoreo de consumo. -
Empoderar el equipo con capacitación técnica
Invertir tiempo en que los científicos de datos, ingenieros y analistas comprendan la arquitectura y optimización de Snowflake. -
Adoptar un enfoque híbrido si conviene
No es obligatorio que todo el pipeline corra dentro de Snowflake; es válido combinarlo con herramientas especializadas (Databricks, sistemas GPU externos) para partes pesadas. -
Construir modelos ligeros para inferencia dentro de la plataforma
Siempre que sea posible, priorizar modelos eficientes (menos parámetros, cuantización, distillación) para que la inferencia sea operativa con latencia baja dentro de Snowflake. -
Diseñar pipelines modulares con lógica desacoplada
Separar claramente preprocesamiento, inferencia y postprocesamiento para facilitar mantenimiento, pruebas y versiones. -
Versionado, monitoreo y retraining continuos
Integrar métricas de drift, alertas automáticas y pipelines de retraining para mantener modelos actualizados. -
Pruebas de escalabilidad y concurrencia
Simular escenarios de alto tráfico para validar que los warehouses y la infraestructura toleran concurrencia sin degradación excesiva. -
Arquitectura orientada a microservicios cuando convenga
Para aplicaciones más complejas, encapsular la lógica IA en servicios micro que interactúan con Snowflake en lugar de acoplar todo dentro de él. -
Auditoría y gobernanza desde el primer día
Configurar roles, mascarado, políticas de acceso, etiquetado y trazabilidad antes de exponer datos sensibles o modelos al entorno de producción. -
Estrategia de migración paulatina
Iniciar con casos piloto o workloads menos críticos, validar rendimiento e integración, y luego ampliar el uso hacia modelos más complejos.
Licenciamiento e instalación
Snowflake es un software comercial bajo licencia de suscripción, ya que utiliza un modelo SaaS (Software as a Service) con facturación basada en uso y consumo de recursos. Está orientado principalmente a empresas medianas y grandes corporaciones, aunque su modelo escalable permite también su adopción por pymes que requieran analítica avanzada sin grandes inversiones iniciales.
En cuanto al tipo de instalación, Snowflake es una plataforma 100 % en la nube (cloud-native), desplegada en infraestructuras de AWS, Microsoft Azure o Google Cloud, lo que significa que no necesita instalación local y ofrece acceso inmediato desde cualquier entorno conectado, garantizando mantenimiento automático, actualización continua y alta disponibilidad.
Video de demostración de Snowflake
Conclusión ejecutiva y recomendaciones para la selección
Snowflake ha logrado evolucionar más allá de su identidad original como data warehouse en la nube, para transformarse en una plataforma de IA y ML con capacidades nativas. Su arquitectura administrada, su capa de extensibilidad (Snowpark, UDF, Cortex) y sus fuertes garantías de seguridad y gobernanza lo sitúan como una opción sólida para organizaciones que buscan integrar analítica avanzada sin desplegar infraestructura pesada.
No obstante, no es una panacea: los costes pueden elevarse si no se gestionan, el entrenamiento profundo sigue demandando soluciones especializadas y algunos componentes de IA deben madurar aún. En muchos casos, una estrategia mixta —donde Snowflake cubre buena parte del pipeline, y herramientas externas se utilizan para cargas extremas— proporciona un equilibrio pragmático.
La decisión final dependerá del perfil de uso, el tamaño del equipo, el ecosistema tecnológico existente y la estrategia de datos de cada organización. Pero si tu objetivo es disponer de una plataforma unificada, escalable, segura y cercana al dato para desplegar modelos y generar valor con IA, Snowflake merece estar en la terna de soluciones a evaluar seriamente.
❓ Preguntas frecuentes sobre Snowflake, IA, Data Science y Machine Learning
🔹 ¿Qué es Snowflake y para qué se utiliza?
Snowflake es una plataforma de datos en la nube que permite almacenar, procesar y analizar información de forma escalable. Se emplea en analítica avanzada, Data Science y Machine Learning para crear modelos predictivos y sistemas de inteligencia artificial sin necesidad de administrar infraestructura.
🔹 ¿Cómo funciona Snowflake en proyectos de Machine Learning?
Snowflake ejecuta procesos de Machine Learning directamente sobre los datos almacenados gracias a su entorno Snowpark, que permite usar Python, Java o Scala para crear, entrenar e implementar modelos. Además, con Cortex, se pueden realizar inferencias y búsquedas vectoriales dentro de la propia base de datos sin mover los datos a otras plataformas.
🔹 ¿Qué ventajas ofrece Snowflake frente a otros Data Warehouses?
Entre las principales ventajas destacan su arquitectura elástica, la separación entre almacenamiento y cómputo, la alta seguridad, el modelo de pago por uso y su capacidad de ejecutar IA directamente en la nube. También resalta por su interoperabilidad multicloud (AWS, Azure y Google Cloud) y su bajo mantenimiento operativo.
🔹 ¿Snowflake incluye herramientas de inteligencia artificial generativa?
Sí. A través de Snowflake Cortex, la plataforma integra IA generativa, modelos de lenguaje (LLM), búsqueda semántica y embeddings vectoriales. Esto permite crear aplicaciones que generan texto, resúmenes, clasificaciones y recomendaciones directamente sobre los datos corporativos.
🔹 ¿Snowflake puede sustituir a Databricks en proyectos de Data Science?
Depende del tipo de proyecto. Snowflake destaca por su simplicidad, seguridad y escalabilidad, mientras que Databricks ofrece mayor control y flexibilidad para entrenamientos intensivos de modelos o pipelines complejos de datos. En muchos casos, se utilizan de forma complementaria, aprovechando lo mejor de ambos ecosistemas.
🔹 ¿Es Snowflake adecuado para proyectos de IA en tiempo real?
Sí. Gracias a su capacidad para ejecutar inferencias cerca del dato, Snowflake permite procesar flujos en tiempo casi real, ideal para casos de uso como recomendadores, scoring financiero o detección de fraude. Sin embargo, para cargas de baja latencia extrema, puede requerir integración con sistemas de streaming especializados.
🔹 ¿Qué herramientas de IA y ML se integran con Snowflake?
Snowflake se integra con herramientas populares como TensorFlow, PyTorch, scikit-learn, Hugging Face y frameworks de MLOps externos. También se conecta con orquestadores como Airflow, dbt o Prefect, y plataformas BI como Tableau, Power BI o Looker.
🔹 ¿Cómo gestiona Snowflake la seguridad de los datos?
La plataforma incluye cifrado de extremo a extremo, control de acceso por roles, mascarado dinámico de datos, gobernanza centralizada, auditoría de uso y cumplimiento con normativas como GDPR, HIPAA o SOC 2. Todo ello la convierte en una opción confiable para entornos empresariales críticos.
🔹 ¿Snowflake es multicloud? ¿Se puede usar en diferentes proveedores?
Sí. Snowflake opera de forma nativa sobre AWS, Microsoft Azure y Google Cloud Platform, lo que permite mover datos y workloads entre nubes sin rediseñar la arquitectura. Esta neutralidad multicloud es una de sus ventajas competitivas más destacadas.
🔹 ¿Cuáles son los principales puntos débiles de Snowflake?
Aunque Snowflake sobresale en facilidad de uso, algunos retos incluyen:
-
Costes altos si no se optimiza el consumo.
-
Limitaciones en el entrenamiento de modelos muy grandes (GPU intensivo).
-
Menor control de infraestructura subyacente.
-
Curva de aprendizaje inicial para optimizar warehouses y consultas.
🔹 ¿Qué tipos de datos puede manejar Snowflake?
Snowflake gestiona datos estructurados y semiestructurados (JSON, Parquet, Avro, ORC), y permite consultas SQL sobre ellos sin transformaciones previas. Su motor convierte automáticamente estructuras complejas en columnas consultables mediante funciones específicas.
🔹 ¿Cómo ayuda Snowflake a los científicos de datos?
Los científicos de datos utilizan Snowflake para acceder a datasets limpios, crear features, ejecutar modelos directamente sobre las tablas y compartir resultados de forma segura. La integración con lenguajes como Python mediante Snowpark facilita la creación de notebooks y pipelines reproducibles.
🔹 ¿Qué es Snowflake Cortex y por qué es importante?
Cortex es el módulo de IA generativa de Snowflake. Incluye motores para búsqueda vectorial, embeddings y acceso a modelos de lenguaje grandes (LLM) preentrenados. Permite crear aplicaciones inteligentes directamente sobre los datos corporativos, sin salir de la plataforma ni replicar información.
🔹 ¿Cuánto cuesta usar Snowflake para IA o ML?
El coste se basa en el modelo de consumo, pagando solo por el almacenamiento y cómputo usados. Cada warehouse se factura por segundos de uso. Para IA y ML, los costos dependerán del tamaño del modelo, la frecuencia de inferencias y el número de usuarios concurrentes.
🔹 ¿Snowflake sirve para IA generativa empresarial?
Sí. Snowflake está construyendo una plataforma de IA generativa empresarial centrada en la seguridad, el gobierno de datos y la integración de modelos propios. Cortex y las funciones vectoriales permiten a las empresas crear asistentes, chatbots y motores de búsqueda internos basados en sus propios datos.
🔹 ¿Qué diferencia a Snowflake de un Data Lake tradicional?
Mientras que un Data Lake requiere gestión manual de metadatos y estructuras, Snowflake ofrece un modelo unificado, con SQL nativo sobre datos estructurados o semiestructurados, optimización automática y gobernanza integrada. Esto lo convierte en una plataforma más madura para analítica avanzada e IA.
🔹 ¿Snowflake es adecuado para pequeñas y medianas empresas?
Sí, gracias a su modelo de pago por uso, las pymes pueden empezar con costes bajos y escalar conforme crecen sus necesidades. Además, su interfaz simple y su soporte multicloud lo hacen accesible para equipos con recursos limitados.
🔹 ¿Cómo se compara Snowflake con Google BigQuery ML?
BigQuery ML permite crear modelos ML con SQL de forma directa, pero tiene limitaciones para pipelines complejos. Snowflake, en cambio, combina SQL + Snowpark + Cortex, lo que ofrece un entorno más completo y extensible para IA generativa y analítica empresarial multicloud.
🔹 ¿Qué futuro tiene Snowflake en IA y Machine Learning?
El roadmap de Snowflake apunta hacia una plataforma unificada de datos e inteligencia artificial, con más integración de modelos generativos, funciones nativas de inferencia y herramientas para desarrolladores. Su apuesta por Cortex sugiere un enfoque fuerte hacia IA generativa empresarial segura y escalable.
Referencias
Página oficial de Snowflake: https://www.snowflake.com/es/