Administración de Microsoft SQL Server 2014
Administración de Microsoft SQL Server 2014 Dataprix 23 May, 2014 - 19:29Automatizando el backup y restore de una base de datos SQL Server 2014 usando PowerShell
Automatizando el backup y restore de una base de datos SQL Server 2014 usando PowerShell il_masacratore 14 November, 2013 - 10:38![]()
Igual que en servidores Linux donde tenemos bases de datos MySql y Oracle automatizamos tareas banales mediante scripts en bash, en los servidores donde tengamos Windows Server podemos apañarnos con Windows Power Shell. Como administradores de las bases de datos Sql server, puede interesar saber algo de scripting en este lenguaje para llegar más lejos que con el Agente de Sql Server y sus trabajos. También es cierto que podemos profundizar todo lo que queramos, empezando con Server Management Objects para interactuar con SQL Server (requiere conocimientos mínimos de .NET y POO) e incluso pudiendo combinarlo con WMI para consultar información relativa al sistema operativo.
En este ejemplo de script Power Shell (extensión .ps1) voy a hacer algo sencillo que será refrescar la base de datos del entorno de desarrollo desde una copia que haremos de la base de datos de producción. En mi caso, esto me tiene que permitir elegir si refrescar el entorno de desarrollo o el entorno de test. Lo bueno de PowerShell es que podemos incluir dentro del mismo script .ps1 comandos de la propia linea de comandos de dos.
Antes de empezar abriremos la consola de power shell. Para probar y poder ejecutar scripts desde la consola scripts seguramente hemos de permitirlo ya que por defecto la directiva deshabilita esta opción. Consultamos y modificamos el la restricción con los comandos Get-ExecutionPolicy y Set-ExecutionPolicy:
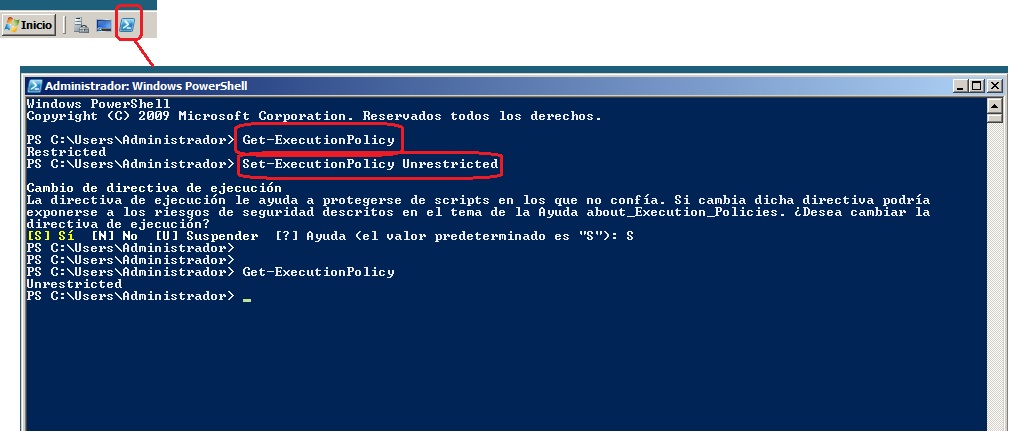
Este script está pensado para ejecutarlo desde el servidor de desarrollo. Para hacerlo más "universal", haré primero una consulta para saber los nombres de la bases de datos accesibles de producción, pidiendo previamente servidor al que conectarse, usuario y clave. Después permito introducir el nombre de la elegida.
*** $SQLServerOrigen = read-host "Nombre del servidor origen" $SQLUserOrigen = read-host "Usuario bbdd origen" $SQLClaveUserOrigen = read-host "Clave" $SqlQuery = "select name from master.dbo.sysdatabases order by 1 asc" $SqlConnection = New-Object System.Data.SqlClient.SqlConnection $SqlConnection.ConnectionString = "Server = $SQLServerOrigen; User id=$SQLUserOrigen; Password=$SQLClaveUserOrigen" $SqlCmd = New-Object System.Data.SqlClient.SqlCommand $SqlCmd.CommandText = $SqlQuery $SqlCmd.Connection = $SqlConnection $SqlAdapter = New-Object System.Data.SqlClient.SqlDataAdapter $SqlAdapter.SelectCommand = $SqlCmd $DataSet = New-Object System.Data.DataSet $SqlAdapter.Fill($DataSet) $SqlConnection.Close() clear $DataSet.Tables[0] echo "" $BBddOrigen = read-host "Base de datos de $SQLServerOrigen a copiar" ***Para hacer la copia, en esta primera versión uso el cliente sql de la linea de comandos (sqlcmd) y un sql a pelo montado de forma dinámica para hacer el backup de solo copia en una ruta fijada. Montaré una unidad de red temporal para hacer la copia, se copia, se desmonta la unidad y se lanza de nuevo desde sqlcmd el restore (mapeando y hardcodeando la nueva ruta por la distinta ubicación de los .mdf y .ldf). Finalmente elimino el fichero.
*** sqlcmd -S $SQLServerOrigen -U $SQLUserOrigen -P $SQLClaveUserOrigen -Q "BACKUP DATABASE [$BBddOrigen] TO DISK = N'F:\Backup\$BBddOrigen\$BBddOrigen.temp.bak' WITH COPY_ONLY" echo "\\$SQLServerOrigen\F$\Backup\$BBddOrigen\" Net Use T: \\$SQLServerOrigen\F$\Backup\$BBddOrigen Copy-Item T:\$BBddOrigen.temp.bak C:\$BBddOrigen.temp.bak Remove-Item T:\$BBddOrigen.temp.bak Net Use T: /delete $BBddDestino = read-host "Base de datos destino" SQLCMD -E -S localhost -Q "RESTORE DATABASE $BBddDestino FROM DISK='C:\$BBddOrigen.temp.bak' WITH FILE=1, MOVE N'$BBddOrigen' TO 'C:\Program Files\Microsoft SQL Server\MSSQL10_50.MSSQLSERVER\MSSQL\DATA\$BBddDestino.mdf', MOVE N'${BBddOrigen}_log' TO 'C:\Program Files\Microsoft SQL Server\MSSQL10_50.MSSQLSERVER\MSSQL\DATA\$BBddDestino.ldf' " #En la cadena de texto anterior, BBDDOrigen va entre {} para poder escapar el '_' acompañado del nombre de la variable y no interprete el _log como parte del nombre de la misma Remove-Item C:\$BBddOrigen.temp.bak ***En el script anterior, en lugar de usar sqlcmd para hacer el backup, podríamos haberlo hecho usando SMO (Server Management Objects). En este caso, el equivalente al sqlcmd sería algo parecido a lo siguiente:
[System.Reflection.Assembly]::LoadWithPartialName("Microsoft.SqlServer.SMO") [System.Reflection.Assembly]::LoadWithPartialName("Microsoft.SqlServer.SmoExtended") [System.Reflection.Assembly]::LoadWithPartialName("Microsoft.SqlServer.ConnectionInfo") [System.Reflection.Assembly]::LoadWithPartialName("Microsoft.SqlServer.SmoEnum") #Preparamos el servidor y cargamos tb el directorio de backup $server = New-Object ("Microsoft.SqlServer.Management.Smo.Server") "($SQLServerOrigen)" $backupDirectory = $server.Settings.BackupDirectory $db = $server.Databases[$dbToBackup] $dbName = $db.Name $timestamp = Get-Date -format yyyyMMddHHmmss $smoBackup = New-Object ("Microsoft.SqlServer.Management.Smo.Backup") $smoBackup.Action = "Database" $smoBackup.BackupSetDescription = "Full Backup of " + $dbName $smoBackup.BackupSetName = $dbName + " Backup" $smoBackup.Database = $dbName $smoBackup.MediaDescription = "Disk" $smoBackup.Devices.AddDevice($backupDirectory + "\" + $dbName + "_" + $timestamp + ".bak", "File") $smoBackup.SqlBackup($server) #Obtenenmos la lista de ficheros en el directorio de backup para luego filtrar y mostrar los .bak $directory = Get-ChildItem $backupDirectory $backupFilesList = $directory | where {$_.extension -eq ".bak"} $backupFilesList | Format-Table Name, LastWriteTimeLa gracia de usar los SMO es la complejidad. Seguramente segun el objeto podremos profundizar algo más y modificar parámetros y obtener información que no conseguiriamos de otra manera. Este trozo de código de arriba, a diferencia del sqlcmd está usando la ruta definida por defecto para los backups del propio sqlserver en lugar de hardcodearla. Ciertamete no es un avance pero ya vemos que la interacción es mejor. Si seguimos con SMO, el equivalente al restore con sqlcmd donde se permite elegir el nombre de la base de datos destino y se renombran los ficheros. Sería algo parecido a lo siguiente:
#Librerias... [System.Reflection.Assembly]::LoadWithPartialName("Microsoft.SqlServer.SMO") | Out-Null [System.Reflection.Assembly]::LoadWithPartialName("Microsoft.SqlServer.SmoExtended") | Out-Null [Reflection.Assembly]::LoadWithPartialName("Microsoft.SqlServer.ConnectionInfo") | Out-Null [Reflection.Assembly]::LoadWithPartialName("Microsoft.SqlServer.SmoEnum") | Out-Null $backupFile = 'C:\Program Files\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\Backup\test.bak' $server = New-Object ("Microsoft.SqlServer.Management.Smo.Server") "(local)" $backupDevice = New-Object("Microsoft.SqlServer.Management.Smo.BackupDeviceItem") ($backupFile, "File") $smoRestore = new-object("Microsoft.SqlServer.Management.Smo.Restore") #Propiedades de la restauracion $smoRestore.NoRecovery = $false; $smoRestore.ReplaceDatabase = $true; $smoRestore.Action = "Database" $smoRestorePercentCompleteNotification = 10; $smoRestore.Devices.Add($backupDevice) #Nombre de la nueva bbdd $BBddDestino = read-host "Base de datos destino" $smoRestore.Database =$BBddDestino #Nuevos ficheros... $smoRestoreFile = New-Object("Microsoft.SqlServer.Management.Smo.RelocateFile") $smoRestoreLog = New-Object("Microsoft.SqlServer.Management.Smo.RelocateFile") $smoRestoreFile.LogicalFileName = $BBddDestino $smoRestoreFile.PhysicalFileName = $server.Information.MasterDBPath + "\" + $BBddDestino + "_Data.mdf" $smoRestoreLog.LogicalFileName = $BBddDestino + "_Log" $smoRestoreLog.PhysicalFileName = $server.Information.MasterDBLogPath + "\" + $BBddDestino + "_Log.ldf" $smoRestore.RelocateFiles.Add($smoRestoreFile) $smoRestore.RelocateFiles.Add($smoRestoreLog) #Restauracion $smoRestore.SqlRestore($server)
En conclusión...
...invirtiendo un poco de tiempo la ganancia futura puede ser mayor. Podemos ahorrar mucho tiempo en tareas repetitivas o hacer verdaderas obras de arte que permitan hacer cosas más viriles. Por ejemplo algo como desactivar el reflejo del mirror en una base de datos reflejada para tenerla preparada en pocos segundos. Recrear el mismo reflejo de forma automática (o a un solo intro). Podemos reinventar la rueda y monitorizar nosotros determinados aspectos de nuestro propio servidor y tener nuestra propia versión de los hechos (sin contar la del departamento de sistemas...).
Como configurar el almacén de administración de datos y su recopilación en SQL Server 2014
Como configurar el almacén de administración de datos y su recopilación en SQL Server 2014 il_masacratore 30 December, 2013 - 10:44El recopilador de datos es una parte de MS Sql Server que permite recopilar diferentes tipos de datos y métricas sobre el rendimiento y desempeño de la base de datos. Se incluye desde la versión 2008 de SqlServer hasta la 2014 y esta formado por un conjunto de trabajos que se ejecutan mediante el agente de Sql Server periódicamente o de forma continua. Su configuración esta formada por dos sencillos pasos mediante asistente. Una vez finalizados ya podemos explotar su información mediante los informes incluidos.
Configurar el almacén de administración de datos
Para configurar el Almacén de Administración de Datos nos conectamos a SQL Server mediante Management Studio con un usuario administrador. En el árbol del Explorador de Objetos, iremos a Administración>Recopilación de datos y seleccionamos Configurar almacén de administración de datos. Esto iniciará un asistente del tipo Siguiente>Siguiente...
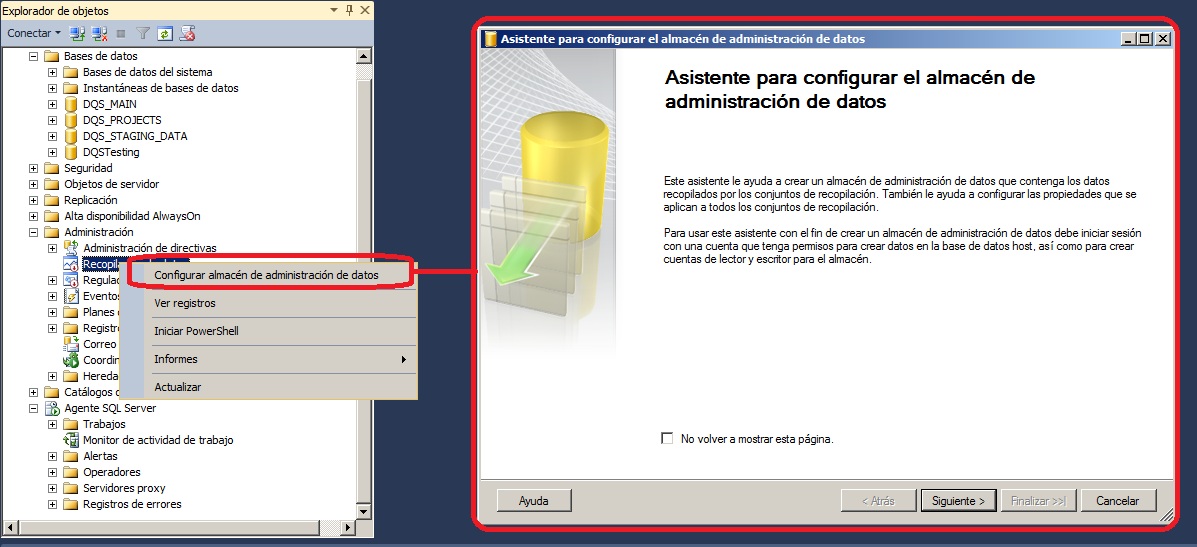
En el primer paso elegiremos la primera opción. Ésta configura la base de datos "almacén" donde se guardan los datos recogidos por los recopiladores (que configuramos en un paso posterior, seleccionando la segunda opción de este mismo punto del asistente).
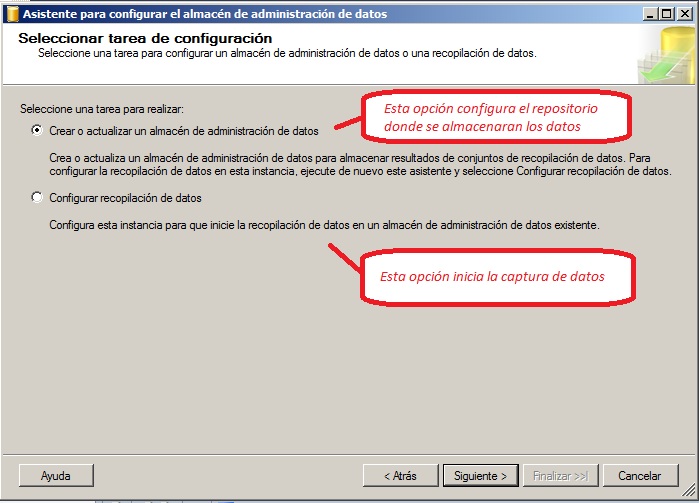
Siguiendo con la primera opción (la de configurar el almacén), nos encontraremos primero con la elección del nombre para la nueva base de datos y el servidor donde estará. El servidor será el mismo servidor y no podemos cambiarlo, pero para la base datos podemos elegir una ya existente o podemos crear una nueva pulsando Nuevo. Elegir una existente podría tener sentido si ya tenemos una ya creada para este propósito o con temas relacionados de administración. Si creamos una nueva base de datos es interesante desactivar de por sí el seguimiento y dejarlo como simple. Hemos de pensar que dependiendo de la cantidad de datos a recopilar o la actividad sobre el servidor puede suponer más una molestia en el consumo de recursos que otra cosa.
El el siguiente paso debemos elegir que inicios de sesión pertenecen a cada rol propio de este compenente. Lo normal puede ser que usemos uno de sistema, el mismo del agente o directamente creemos uno nuevo con los permisos necesarios si nos interesa aislar la carga producida de forma rápida. El nuevo usuario lo creamos desde el botón del panel inferior. A continuación le asignamos los permisos sobre la base de datos.
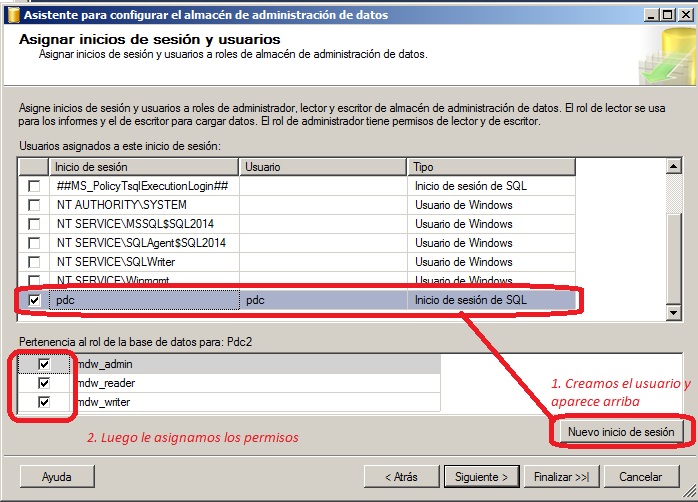
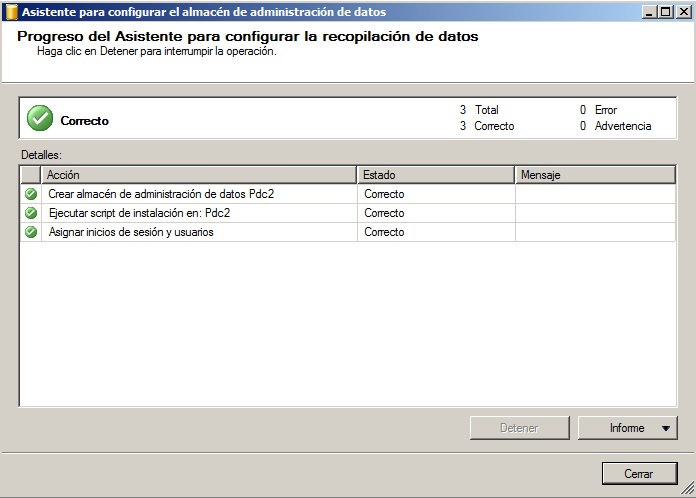
Pulsamos siguiente y entonces nos aparecerá el resumen de la configuración que hemos hecho a modo de confirmación. Pulsamos de nuevo siguiente si estamos conformes y esperamos un resultado como este donde todo es correcto.
Configurar recopilación de datos
Ahora que ya tenemos la base de datos, nos falta configurar los recopiladores. Como he comentado antes, configuramos el recopilador de datos desde el mismo punto del explorador de objetos (Administración>Recopilador de datos> Configurar el almacén de administración de datos) pero esta vez seleccionamos en el segundo paso del asistente la opción inferior: Configurar recopilación de datos.
Una vez empezado el asistente, y ya en el tercer paso elegimos donde está hospedado el almacén de datos (la base de datos que hemos creado antes). Pulsamos de nuevo siguiente y nos aparece de nuevo el resumen de configuración y de los pasos a realizar. Estos incluyen habilitar la recopilación de datos y su inicio. Con todos estos pasos ya tenemos todo configurado y en marcha.
Recopiladores incluidos e informes incluidos
Por defecto, mediante los dos pasos anteriores conseguimos la creación de los tres recopiladores:
- Actividad del servidor: Cpu, memoria, etc...
- Estadísticas de consultas: Consultas, esperas, etc...
- Uso de disco: Evolución del espacio ocupado por cada bases de datos.
La parte más interesante son también los informes que se incluyen. Para poder acceder a ellos podemos hacerlo desde SQL Server Management Studio navegando por el árbol del Explorador de objetos, botón derecho en la base de datos almacén y seleccionamos informes del Almacén de Administración. Se abrirá una nueva pestaña y en el panel principal ya seleccionamos lo que queremos ver y el intervalo de fechas. Podemos consultar:
-
Resumen de uso de disco: Este informe muestra por cada base de datos el espacio que ocupan sus ficheros de datos y registro y la tendencia. Útil para ver comportamientos anómalos o hacer estimaciones sobre la necesidad de espacio en disco.
-
Historial de estadísticas de consultas: Del intervalo seleccionado muestra las consultas ordenadas de mayor a menor impacto por CPU, Duración etc... Lo vemos en un gráfico y en una tabla donde se muestra también el número de ejecuciones, duración, lecturas, escrituras.
-
Historial de actividad del servidor: Vista general del servidor donde podemos ver el uso de cpu, memoria, disco y red en la parte superior. en la parte media podemos ver otro gráfico con los tipos de esperas de SQL Server. En la parte inferior vemos un resumen de actividad con las conexiones, batch request etc. De estos dos últimos podemos ver más detalle haciendo clic sobre ellos.
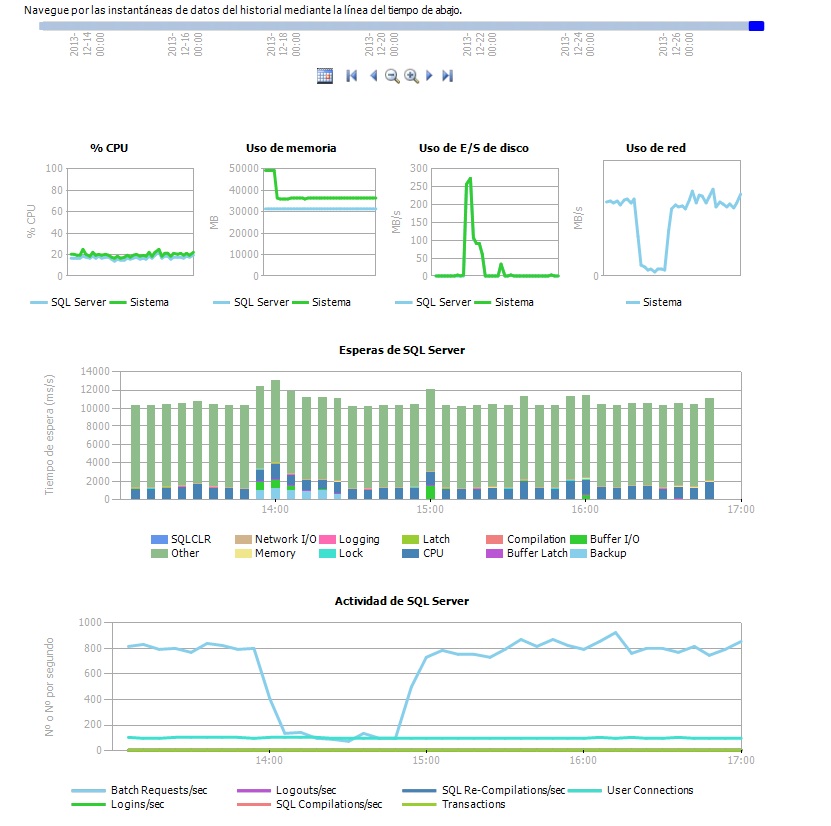
De estos tres informes, del que podemos sacar mas jugo es el tercero porque nos da un estado general de la base de datos en el tiempo y nos permite indagar de manera superficial que se estaba ejecutando y durante cuanto tiempo. Por ejemplo, podemos detectar picos de actividad consultando el tercer gráfico. Observando el segundo podemos ver cual puede ser el origen de la lentitud según el mayor tipo de espera que veamos en el gráfico.
En resumen...
... este componente puede resultar útil por falta de alternativas dentro de la misma instalación de SqlServer y complementa los cuatro informes iniciales que pueden venir por defecto. Además, supone una alternativa auto-configurada para recopilar los mismos contadores que recoge el monitor de rendimiento del sistema. Es muy interesante la posibilidad de tener una foto del estado del servidor en un intervalo de tiempo anterior y verlo de forma gráfica.
Además, si queremos ir más allá podemos crear nuestros propios informes para explotar esta base de datos. Lo podríamos hacer con Report Builder o Business Intelligence Developer Studio y el punto de partida pueden ser las tablas snapshots.performance_counter_instances y snapshots.performance.counter_values. Ahí podemos ver los valores recogidos que podemos ver en cualquier momento consultando el monitor de rendimiento del sistema.
Buena información ya que
Buena información ya que cuando nos falten alternativas auto-configurada para recopilar los mismos contadores que recoge el monitor de rendimiento del sistema.
- Log in to post comments
Como instalar SQL Server 2014
Como instalar SQL Server 2014 il_masacratore 30 October, 2013 - 09:13… para empezar a probar las nuevas características que tenemos desde la versión 2008 de SqlServer.
Desde entonces ha llovido mucho, de hecho, la release date fue el 6 de agosto de 2008, y particularmente me interesa empezar a probar nuevas implementaciones ya sean novedad en la versión SQL Server 2014 o la anterior, la de 2012. Por ahora empiezo con esta serie de post sobre la nueva, primero con lo más básico que es como instalarlo para empezar a probar. Después en otros posts, comentaré seguramente pruebas de rendimiento con la nueva posibilidad de trabajar con tablas en memoria y cosas más bonitas o tangibles como el uso de Power View (ahora también contra ssas).
Este paso a paso resumido está hecho con la segunda versión preliminar de SQL Server 2014. Si queréis algo más completo tenéis algo más completo en la MSDN, pero quizás es más tedioso. Otras cosas podrán cambiar en la versión definitiva, pero el modo de instalación no lo creo. Así que vamos al lío. En mi caso la instalaré en una máquina virtual con Windows Server 2008 Enterprise, y por aquí abajo os comento cuatro sobre la marcha como instalarlo:
- Una vez cargada la ISO/CD lanzamos el instalador. Nosotros queremos una nueva instancia de bbdd. Nos vamos al apartado de Instalación y agregamos una nueva instancia (captura inferior). Pulsamos Siguiente y nos pide la clave, que introducimos si toca y pulsamos siguiente de nuevo.
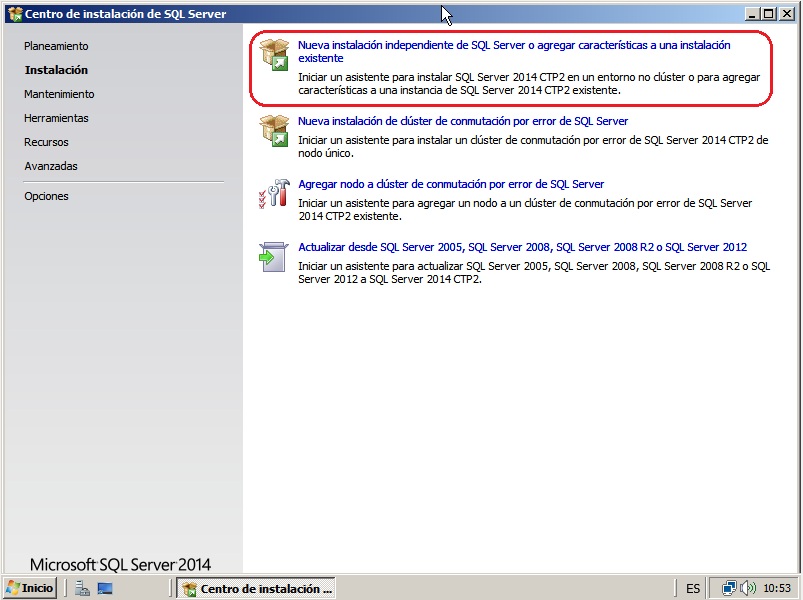
- Seguimos con la licencia (que aceptamos, claro) y después seguimos con los validación de requisitos. Seguramente si probáis sobre una máquina virtual os falle la parte de “Actualización de .NET 2.0 y .NET 3,5 Service Pack 1 para...”. No pasa nada. Miramos el detalle del error y nos bajamos el paquete que nos especifica para nuestro sistema operativo. Más adelante también se comprueba si tentemos habilitado Windows PowerShell 2.0 y el NetFramework 3.5 Sp1. Lo instalamos todo y volvemos a empezar.
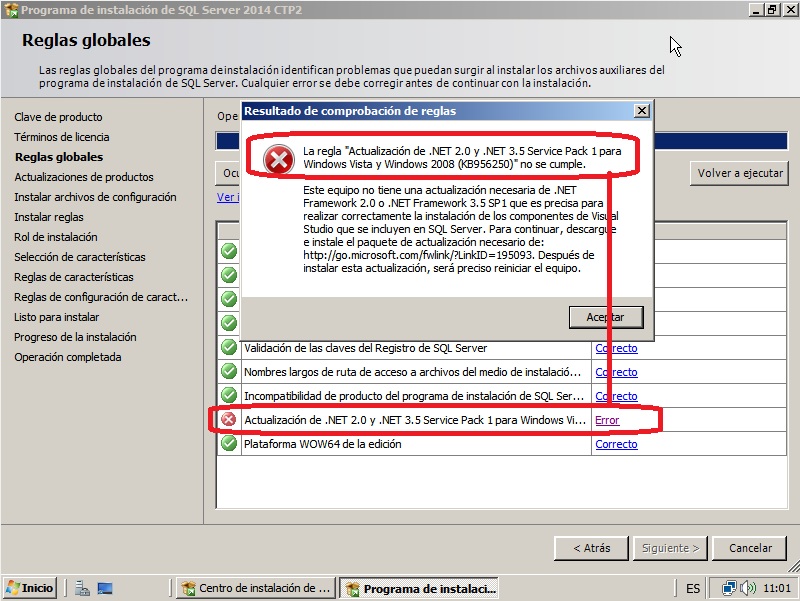
- Cuando lleguemos al mismo punto, se pone a buscar actualizaciones, lo dejamos si hace falta y pasamos al siguiente paso que es otra validación, en este caso de reglas (firewall etc..). Si está habilitado nos advertirá (captura inferior). Posteriormente podemos añadir los puertos de sql o deshabilitarlo si lo creyéramos preciso.
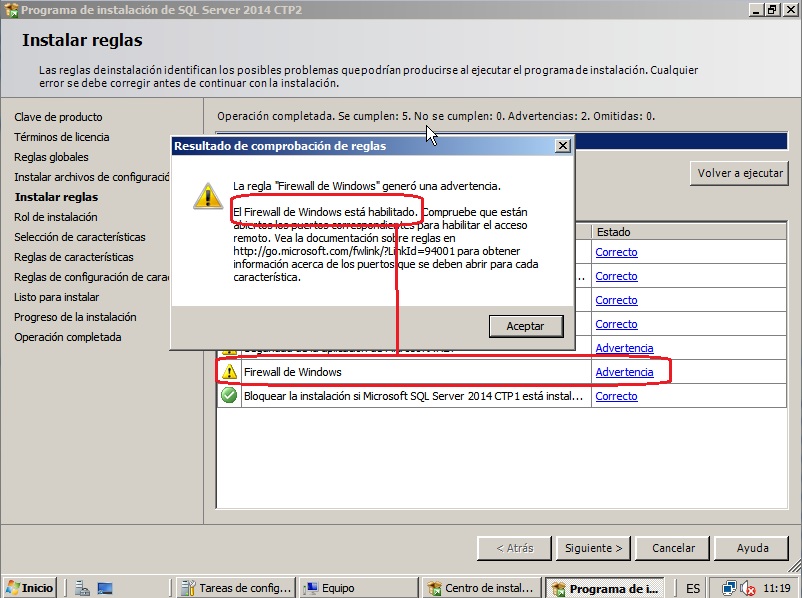
- Seguimos con el Rol de la instalación donde seleccionamos Instalación de características de SQL Server. Siguiente y ya podemos elegir lo que vamos a instalar (en mi caso para probar las tablas en memoria y Power View es lo que veis en pantalla: motores de base de datos y analisys services, conectividad de cliente y herramientas de administración).
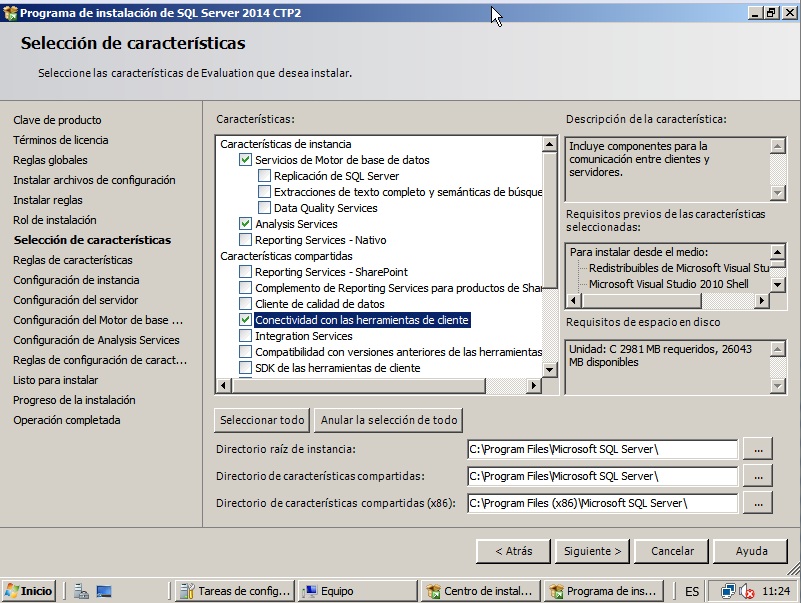
- A continuación podemos configurar el nombre de la instancia (dejamos el valor por defecto si es la primera en este servidor). Después elegimos las cuentas de ejecución para cada servicio. Podemos dejar los cuentas por defecto o alguna otra cuenta, pero la gracia aquí es aplicar aquello de que la cuenta tenga los permisos justos y necesarios. Pulsamos siguiente.
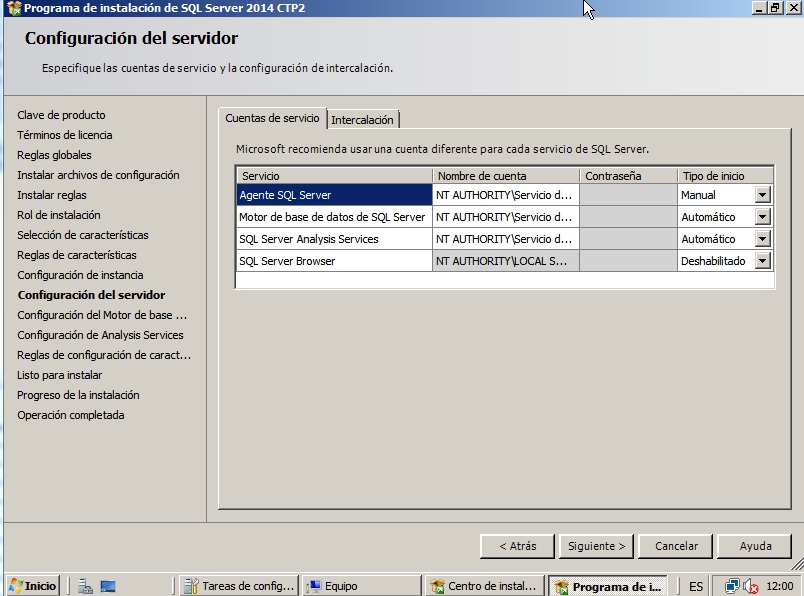
- En la configuración de cada servicio (en mi caso el motor y analisys services) debemos recordar añadir algun usuario al grupo de administradores. Además debemos elegir si toca, el tipo de autentificación para los usuarios.
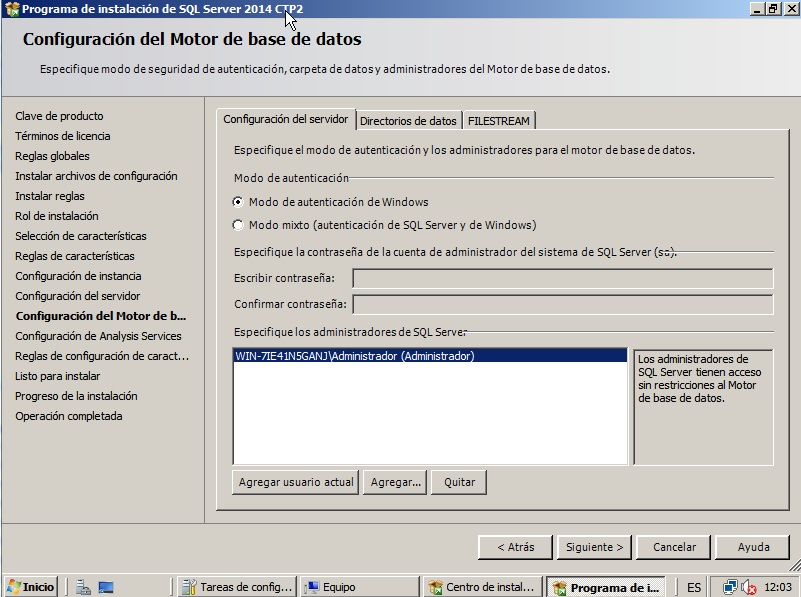
- Pulsamos siguiente y ya tenemos el resumen final de lo que vamos a instalar. Siguiente y a esperar. Cuando acabe reiniciamos y listos!
Ya tenemos nuestro SQL Server 2014 a punto para empezar a probar...
Monitorización de SQL Server 2014 mediante contadores de rendimiento
Monitorización de SQL Server 2014 mediante contadores de rendimiento il_masacratore 12 December, 2013 - 13:33
 Una de las tareas básicas en la administración de bases de datos es la monitorización de nuestro servidor y nuestra base de datos. Para servidores Windows con SQL Server una de las maneras más básicas (y gratuitas) es hacerlo mediante los contadores de rendimiento del sistema.
Una de las tareas básicas en la administración de bases de datos es la monitorización de nuestro servidor y nuestra base de datos. Para servidores Windows con SQL Server una de las maneras más básicas (y gratuitas) es hacerlo mediante los contadores de rendimiento del sistema.
Estos contadores de rendimiento del sistema se añaden en el Monitor de rendimiento de Windows (perfmon) y con ellos podemos visualizar valores de métricas relativas incluso a aplicaciones como Dynamics Ax que añaden sus propios contadores al instalarse en el servidor. De los contadores que elijamos, también podemos almacenar sus valores a lo largo del tiempo con la creación de conjuntos de recopiladores de datos e incluso podemos enviarnos alertas uniendo recopiladores e informes predefinidos.
Para monitorizar nuestro SQL Server, los principales contadores de rendimiento podrían ser (en el servidor actual y en el idioma que lo tengáis):
- Disco físico
Escrituras en disco/s
Lecturas de disco/s
Longitud actual de la cola de disco
Longitud promedio de cola de escritura de disco
Los dos primeros sirven para conocer la métrica y los valores medios por unidad o en total. El valor de la longitud promedio de cola de escritura de disco siempre debe tender a 0 en cada unidad y tampoco debería pasar de 2.
- Procesador
% de tiempo de procesador
¿Que decir? Es el uso de la cpu (de cada procesador o mejor el _Total para ver el promedio). Mejor evitar sobrepasar el 80%. Lo siguiente sería ver que es lo que está causando esa presión sobre el procesador.
- Memoria
Mbytes disponibles
Memoria sin asignar por el sistema. Debería ser mayor que 0 porque deberíamos contar con algo sobrante para otros procesos puntuales que puedan lanzarse en el servidor u otros servicios fijos como Analisys Services o Reporting Services.
- SQLServer: Acces Methods
Full Scans/sec
Index Searches/sec
Tipo de acceso. Un valor alto de Full scans a lo largo del tiempo indica la falta de indices. Si empezáramos a indizar en consecuencia deberíamos ver como compensamos con un incremento de Index Searches.
- SQLServer:Buffer Manager
Buffer cache hit ratio
Page life expectancy
El primer contador es el porcentaje de veces que el motor usa la caché frente al disco. Debe tender al 100%. Page Life expectancy es el tiempo en segundos que permanece una página en memoria sin tener ninguna referencia que la retenga allí. Cuanto más tiempo, mejor. Un valor bajo puede significar problemas de cache o incluso falta de memoria.
- SQLServer:General Statistics
Processes blocked
User connections
El primero indica los procesos bloqueados y el segundo el número de conexiones actual. Es bueno saberlos en todo momento para detectar anomalías e incluso alertarnos cuando los procesos bloqueados son mayores que 0.
- SQLServer:Memory Manager
Target Server Memory (KB)
Total server memory (KB)
Sirve para ver la asignación de memoria del sistema a Sqlserver por el sistema y el valor configurado dentro de Sqlserver. Un valor real menor al configurado indicaría falta de memoria.
- SQLServer:SQL Statistics
Batch Requests/sec
SQL Compilations/sec
SQL Re-Compilations/sec
Peticiones por segundo. Sirve también para detectar puntas de trabajo o procesos inusuales. El segundo y tercero permiten ver problemas de cache.
- SQLServer:Wait Statistics
Lock Waits
Log buffer waits
Log write waits
Memory grant queue waits
Network IO Waits
Page IO latch waits
Page latch waits
Eso son las esperas para las consultas. Con estos valores es fácil apuntar a una fuente de problemas para focalizar nuestra atención: problemas de red, de acceso a disco, de memoria. Existen otros tipos, pero sea cual sea debemos analizar en conjunto para cada contador las esperas en curso, las iniciadas por segundo y el tiempo medio de espera. Valores altos de forma continua deben llamar nuestra atención.
Además de todos los anteriores, podemos necesitar controlar otros más específicos a alguna característica o función de sql server. Por ejemplo, podemos monitorizar el tiempo de trasvase en un espejo asíncrono de cada transacción a la replica mirando el valor del contador SQLServer:Database Mirroring>Transaction Delay. Todos los contadores relativos al motor de SQL Server empiezan por SQLSERVER, los de Analisys Services empiezan por MSAS y los de Reporting Services con MSRS.
Para empezar a añadir nuestros propios contadores, abrimos el perfmon.exe, vamos al Monitor de rendimiento y seleccionamos la visualización tipo informe para trabajar más fácilmente.
A continuación, pulsamos el botón derecho del ratón sobre el área vacía del informe de color blanco y seleccionamos Agregar contadores. Ahí podemos buscar cualquiera de los anteriores para añadirlo o seleccionar el que queramos visualizar. La gracia también es que una vez seleccionados los que nos interesan podemos guardar la configuración (por ejemplo en el escritorio) para poder acceder en cualquier momento al Monitor de Rendimiento con nuestros contadores ya en la pantalla o poder elegir entre distintas configuraciones (una simple, una avanzada, etc etc).
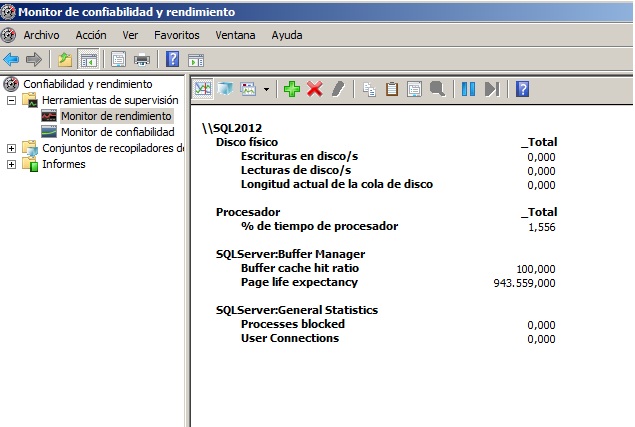
Todos estos valores que hemos visto pueden irse recopilando a lo largo del día e incluso podemos definir valores "umbral" a partir de los cuales podemos realizar alguna acción e incluso enviarnos un correo electrónico para avisarnos del suceso. Esta es una forma de complementar o sustituir una motorización con herramientas tipo Nagios.
En resumen...
... es básico conocer como funciona el tema de los contadores de rendimiento, configurarlos y lo que podemos llegar a hacer con ellos. Además, casi igual de importante es conocer los valores de referencia estándares y con sus máximos y mínimos aceptados, como conocer los reales de funcionamiento de nuestro entorno. Creo que debemos saber y hasta donde tolerar, sin caer en la dejadez ni olvidarse, valores de ciertos contadores y separar lo que es normal y lo que no. Sabemos que siempre hay grandes o pequeñas aplicaciones que pueden hacer un mal uso o tener algún proceso mal planteado que a la práctica es imposible de modificar y tenemos que vivir con él.
También se debe saber que existen otras maneras de obtener esta información y tratarla. Desde el propio sql server podemos consultar la vista sys.dm_os_performance_counters que nos ofrece los valores actuales. Podemos filtrar por su columna object_name para elegir los mismos contadores por su nombre.
SELECT * FROM sys.dm_os_performance_counters WHERE OBJECT_NAME = 'SQLServer:Buffer Manager'
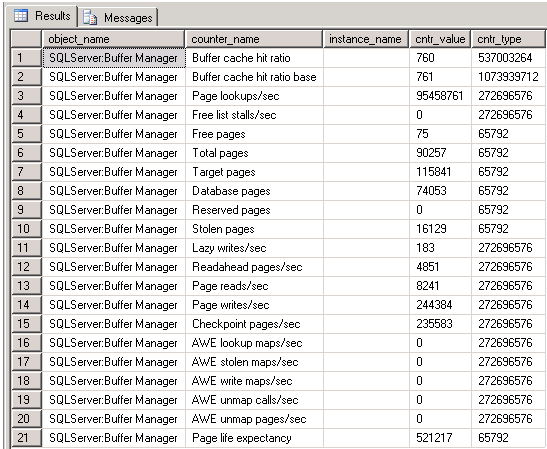
el problema que yo observo y
- Log in to post comments
Probando InMemory OLTP (Hekaton) en SQL Server 2014
Probando InMemory OLTP (Hekaton) en SQL Server 2014 il_masacratore 11 November, 2013 - 10:32En la versión 2014 de Sql Server introducirán un nuevo motor en la base de datos que permitirá trabajar con tablas en memoria (inmemory o hekaton, su nombre en clave). Podemos imaginar que eso puede suponer una mejora considerable en el rendimiento si sabemos elegir para este nuevo las tablas adecuadas. Su funcionamiento es lógico y es el que cabe esperar. Según la MSDN, las tablas y sus registros se mantienen principalmente en memoria y una segunda copia se mantiene en disco para disponer de los datos si reiniciásemos la instancia. Tenemos también la posibilidad de elegir el tiempo que tarda en trasladarse un cambio en los datos de la tabla en memoria a la tabla en disco. También existe la posibilidad de crear tablas on-the-fly (non-durable table) y que no se persistan en disco. En cualquier caso hemos de tener en cuenta que en caso de desastre o reinicio de servidor, cualquier dato no trasladado a disco seguro que lo perdemos. Vamos a hacer unas pruebas.
Primero de todo, para poder usar tablas en memoria tenemos crear un grupo de ficheros del tipo adecuado. En este caso, anticipándome al futuro, combinamos uno de cada tipo (el normal por que sí y luego añadimos uno para datos en memoria después):
CREATE DATABASE [InMemoryTest] CONTAINMENT = NONE ON PRIMARY ( NAME = N'InMemoryTest', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\InMemoryTest.mdf' , SIZE = 5120KB , MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB ) LOG ON ( NAME = N'InMemoryTest_log', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\InMemoryTest_log.ldf' , SIZE = 1024KB , MAXSIZE = 2048GB , FILEGROWTH = 10%) GO ALTER DATABASE InMemoryTest ADD FILEGROUP InMemoryTest_im CONTAINS MEMORY_OPTIMIZED_DATA ALTER DATABASE InMemoryTest ADD FILE (name='InMemoryTest_im1', filename='C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\InMemoryTest_im1') TO FILEGROUP InMemoryTest_im GO
--*** Si os aparece un error de que el procesador no es compatible usando VBox mirar al pie de página
A continuación vamos con nuestras tablas de ejemplo por cada tipo (la de toda la vida, DURABILITY = SCHEMA_ONLY y DURABILITY = SCHEMA_AND_DATA ):
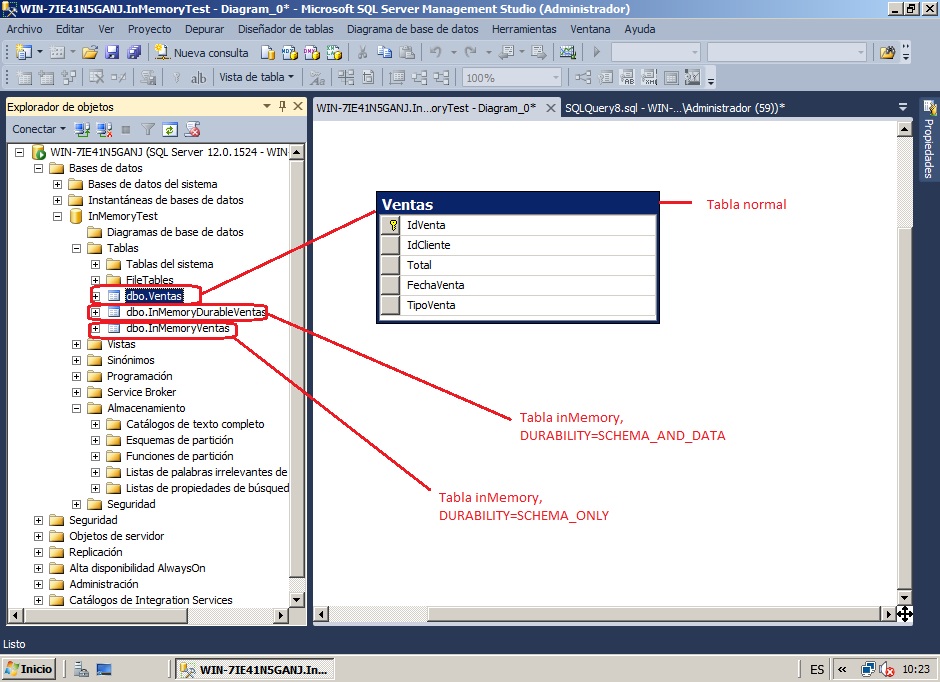
-- Creación de la tabla normal (en el fg por defecto) use InMemoryTest CREATE TABLE Ventas ( IdVenta int identity PRIMARY KEY NOT NULL ,IdCliente int NOT NULL ,Total int NOT NULL ,FechaVenta date NOT NULL ,TipoVenta char(1) NOT NULL ,INDEX Ventas_FechaVenta NONCLUSTERED (FechaVenta) ) -- Creación de la tabla en memoria, solo con estructura en disco use InMemoryTest CREATE TABLE InMemoryVentas ( IdVenta int NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT=1000000) ,IdCliente int NOT NULL ,Total int NOT NULL ,FechaVenta date NOT NULL ,TipoVenta char(1) NOT NULL ,INDEX InMemoryVentas_FechaVenta NONCLUSTERED HASH (FechaVenta) WITH (BUCKET_COUNT = 365) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY) -- Creación de la tabla en memoria con datos y estructura en disco (DURABLE) use InMemoryTest CREATE TABLE InMemoryDurableVentas ( IdVenta int NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT=1000000) ,IdCliente int NOT NULL ,Total int NOT NULL ,FechaVenta date NOT NULL ,TipoVenta char(1) NOT NULL ,INDEX InMemoryVentas_FechaVenta NONCLUSTERED HASH (FechaVenta) WITH (BUCKET_COUNT = 365) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
Seguiremos con la carga de datos. Añado el mensage de output para ver cuanto tarda en cada tabla. Cuidado porque en este caso, la segunda tabla no se persiste en disco (DURABILITY = SCHEMA_ONLY) Si reiniciamos la instancia perderemos los datos. La tercera sí la persistimos en disco pero trabajamos con la copia en memoria.
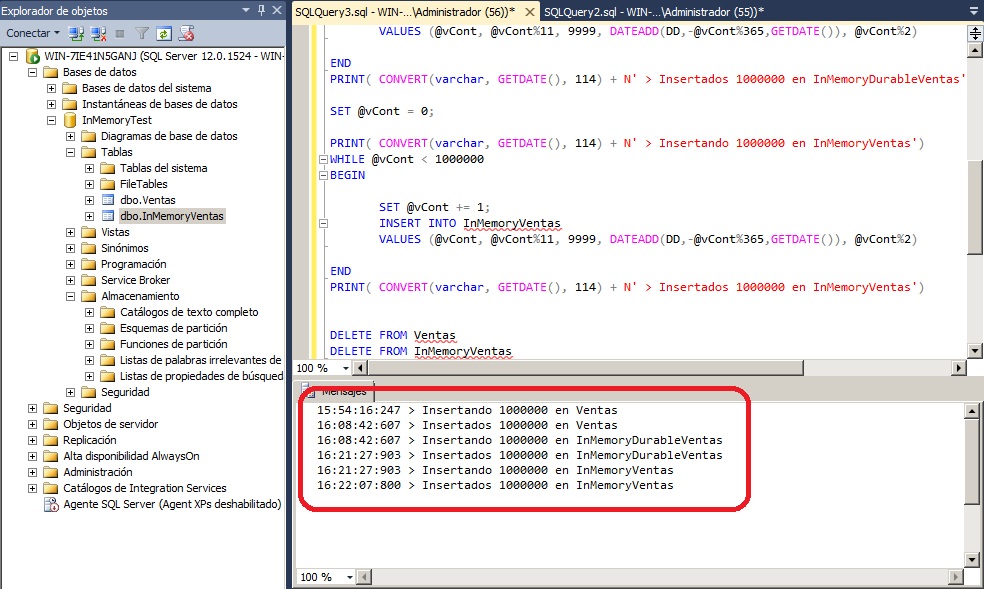
-- Carga de datos para las tres tablas SET NOCOUNT ON; USE InMemoryTest DECLARE @vCont int = 0; PRINT( CONVERT(varchar, GETDATE(), 114) + N' > Insertando 1000000 en Ventas') WHILE @vCont < 1000000 BEGIN SET @vCont += 1; INSERT INTO Ventas VALUES (@vCont%11, 9999, DATEADD(DD,-@vCont%365,GETDATE()), @vCont%2) END PRINT( CONVERT(varchar, GETDATE(), 114) + N' > Insertados 1000000 en Ventas') SET @vCont = 0; PRINT( CONVERT(varchar, GETDATE(), 114) + N' > Insertando 1000000 en InMemoryDurableVentas') WHILE @vCont < 1000000 BEGIN SET @vCont += 1; INSERT INTO InMemoryDurableVentas VALUES (@vCont, @vCont%11, 9999, DATEADD(DD,-@vCont%365,GETDATE()), @vCont%2) END PRINT( CONVERT(varchar, GETDATE(), 114) + N' > Insertados 1000000 en InMemoryDurableVentas') SET @vCont = 0; PRINT( CONVERT(varchar, GETDATE(), 114) + N' > Insertando 1000000 en InMemoryVentas') WHILE @vCont < 1000000 BEGIN SET @vCont += 1; INSERT INTO InMemoryVentas VALUES (@vCont, @vCont%11, 9999, DATEADD(DD,-@vCont%365,GETDATE()), @vCont%2) END PRINT( CONVERT(varchar, GETDATE(), 114) + N' > Insertados 1000000 en InMemoryVentas')
En mi caso, la ejecución con de este último script de tabla me muestra que tarda cerca de 14 minutos en cargar la tabla en disco, cerca de 12 minutos la tabla en memoria persistida en disco al completo y apenas 1 solo minuto para la tabla de la que solo tenemos la estructura en disco (pero de la que al reiniciar la instancia perderemos sus datos). Esta prueba ya empieza a mostrar diferencias y sobretodo ventajas para trabajar con tablas en memoria...
Ahora vamos a probar y medir algunas consultas que haremos contra cada tipo de tabla. Para ello las ejecutamos previa limpieza de cache y buffers:
USE InMemoryTest; GO DBCC FREEPROCCACHE WITH NO_INFOMSGS; DBCC DROPCLEANBUFFERS WITH NO_INFOMSGS; SET NOCOUNT ON; SET STATISTICS IO ON; SET STATISTICS TIME ON; PRINT(N'Sobre Ventas...') SELECT DISTINCT IdCliente FROM Ventas WHERE FechaVenta = '01/01/2013'; PRINT(N'Sobre InMemoryDurableVentas...') SELECT DISTINCT IdCliente FROM InMemoryDurableVentas WHERE FechaVenta = '01/01/2013'; PRINT(N'Sobre InMemoryVentas...') SELECT DISTINCT IdCliente FROM InMemoryVentas WHERE FechaVenta = '01/01/2013';
Mi salida (que adjunto abajo) es la siguiente. No parece muy descriptiva pero ya vemos que el tiempo transcurrido es prometedor ya que pasamos de casi 400ms, a 1 y 0 milisegundos. Prometedor. Podéis probar de desordenar lo selects para modificar el orden si no os lo creéis y veréis que el resultado es muy similar. En mi opinión esto promete.
Sobre Ventas...
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 0 ms.
Tabla 'Worktable'. Recuento de exámenes 0, lecturas lógicas 0, lecturas físicas 0,
lecturas anticipadas 0, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tabla 'Workfile'. Recuento de exámenes 0, lecturas lógicas 0, lecturas físicas 0,
lecturas anticipadas 0, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tabla 'Ventas'. Recuento de exámenes 3, lecturas lógicas 6302, lecturas físicas 1,
lecturas anticipadas 6225, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 250 ms, tiempo transcurrido = 397 ms.
Sobre InMemoryDurableVentas...
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 0 ms.
Tabla 'Worktable'. Recuento de exámenes 0, lecturas lógicas 0, lecturas físicas 0,
lecturas anticipadas 0, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tabla 'Workfile'. Recuento de exámenes 0, lecturas lógicas 0, lecturas físicas 0,
lecturas anticipadas 0, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 2 ms.
Sobre InMemoryVentas...
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 0 ms.
Tabla 'Worktable'. Recuento de exámenes 0, lecturas lógicas 0, lecturas físicas 0,
lecturas anticipadas 0, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tabla 'Workfile'. Recuento de exámenes 0, lecturas lógicas 0, lecturas físicas 0,
lecturas anticipadas 0, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 1 ms.
Aunque, en el ejemplo hay trampa, porque si miramos los planes de ejecución veremos que en el caso de la tabla de toda la vida tenemos un index scan mientras que en el caso de las tablas en memoria tenemos index seek (scan vs seek, gana seek) sobre el HASH INDEX. Eso es porque de forma inherente los indices de tablas en memoria ya son punteros directos a los datos de fila parecidos a los covering indexes. Es más, nos propone crearlo.
CREATE NONCLUSTERED INDEX Ventas_FechaVentaIncIdCliente ON [dbo].[Ventas] ([FechaVenta]) INCLUDE ([IdCliente])
Lo crearemos, volveremos a ejecutar la consulta y el resultado debe ser como el siguiente.
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 0 ms.
Tabla 'Worktable'. Recuento de exámenes 0, lecturas lógicas 0, lecturas físicas 0,
lecturas anticipadas 0, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tabla 'Workfile'. Recuento de exámenes 0, lecturas lógicas 0, lecturas físicas 0,
lecturas anticipadas 0, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tabla 'Ventas'. Recuento de exámenes 1, lecturas lógicas 15, lecturas físicas 0,
lecturas anticipadas 12, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 10 ms.
Como vemos sigue ganando la tabla en memoria... de momento. Ahora cambiamos el tipo de consulta a una sin igualdad, cambiaremos a una de rango.
USE InMemoryTest; GO DBCC FREEPROCCACHE WITH NO_INFOMSGS; DBCC DROPCLEANBUFFERS WITH NO_INFOMSGS; SET NOCOUNT ON; SET STATISTICS IO ON; SET STATISTICS TIME ON; PRINT(N'Sobre Ventas...') SELECT DISTINCT IdCliente FROM Ventas WHERE FechaVenta >= '01/01/2013' AND FechaVenta < '01/02/2013'; PRINT(N'Sobre InMemoryDurableVentas...') SELECT DISTINCT IdCliente FROM InMemoryDurableVentas WHERE FechaVenta >= '01/01/2013' AND FechaVenta < '01/02/2013'; PRINT(N'Sobre InMemoryVentas...') SELECT DISTINCT IdCliente FROM InMemoryVentas WHERE FechaVenta >= '01/01/2013' AND FechaVenta < '01/02/2013';
El resultado es este:
Sobre Ventas...
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 0 ms.
Tabla 'Worktable'. Recuento de exámenes 0, lecturas lógicas 0, lecturas físicas 0,
lecturas anticipadas 0, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tabla 'Workfile'. Recuento de exámenes 0, lecturas lógicas 0, lecturas físicas 0,
lecturas anticipadas 0, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tabla 'Ventas'. Recuento de exámenes 1, lecturas lógicas 362, lecturas físicas 0,
lecturas anticipadas 125, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 78 ms, tiempo transcurrido = 71 ms.
Sobre InMemoryDurableVentas...
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 0 ms.
Tabla 'Worktable'. Recuento de exámenes 0, lecturas lógicas 0, lecturas físicas 0,
lecturas anticipadas 0, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tabla 'Workfile'. Recuento de exámenes 0, lecturas lógicas 0, lecturas físicas 0,
lecturas anticipadas 0, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 266 ms, tiempo transcurrido = 255 ms.
Sobre InMemoryVentas...
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 0 ms.
Tabla 'Worktable'. Recuento de exámenes 0, lecturas lógicas 0, lecturas físicas 0,
lecturas anticipadas 0, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tabla 'Workfile'. Recuento de exámenes 0, lecturas lógicas 0, lecturas físicas 0,
lecturas anticipadas 0, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 250 ms, tiempo transcurrido = 252 ms.
El resultado ya no mola tanto pero esto se soluciona añadiendole un nuevo indice de rango, más adecuado si esperamos hacerle consultas del tipo. Por desgracia la única manera de hacerlo es recrear la tabla.
Mis conclusiones...
...son que este tipo de tablas pueden ser muy útiles pero hay que saber cuando usarlas. Me vale que podamos mantener los dos tipos de grupos de fichero (normales y preparados para persistir en memoria). También creo que en rendimiento puro no hay mucha diferencia en las tablas que están en memoria, entre la que persiste en disco y de la que solo mantenemos la estructura. En todo caso, puede ser interesante investigar el tema de DELAYED_DURABILITY para posponer la propagación de los cambios a disco.

*** The model of the processor on the system does not support creating filegroups with MEMORY_OPTIMIZED_DATA. This error typically occurs with older processors.
Este error aparece al crear el tipo de filegroup con la clausula MEMORY_OPTIMIZED_DATA si estamos usando por lo menos la versión 4.1 de Oracle VirtualBox. Actualizando la versión podríamos tener suficiente para solventar el problema. Si no ejecutamos lo siguiente en el directorio de VirtualBox:
VBoxManage setextradata [nombre_maquina_virtual] VBoxInternal/CPUM/CMPXCHG16B 1
SQL Server 2014 DQS (Data Quality Services)
SQL Server 2014 DQS (Data Quality Services) il_masacratore 21 November, 2013 - 12:53Microsoft Sql Server Data Quality Services (DQS) es una herramienta, cliente-servidor, que se introdujo en Sql Server 2012 y que permite permite velar por la integridad de los datos basada en unos datos previos, la base de datos de conocimiento, que usamos para validar otros datos posteriores. Esta herramienta permite incluso limpiar datos entrantes en paquetes de SSIS. Su propósito es conseguir datos de calidad, construyendo primero una fuente de conocimiento sobre la calidad objetivo de nuestros datos, creando dominios (valores de referencia para asignar validez o no) y reglas para definir actuaciones.
Generalmente los datos incorrectos son un problema que se genera por usuarios o clientes en el momento de su introducción. Otras veces, los problemas pueden venir al unir diferentes orígenes de datos en un mismo almacén de datos destino. Con herramientas como DQS podemos, de alguna manera, validar nuestros datos o incluso corregirlos para obtener finalmente datos válidos y de mayor valor empresarial. En teoría, una de las ventajas que dice Microsoft sobre DQS es que permite a usuarios de distintos niveles (usuario final o profesional IT) el crear, ejecutar y mantener las operaciones de calidad de datos...
Antes empezar necesitaremos tener instalado en nuestro servidor lo necesario para empezar a probar. Lanzamos el instalador de SqlServer y añadimos a nuestra instancia de SqlServer Data Quality Services, bajo el motor de la base de datos y en el caso de probar con una máquina virtual también el cliente de calidad de datos.
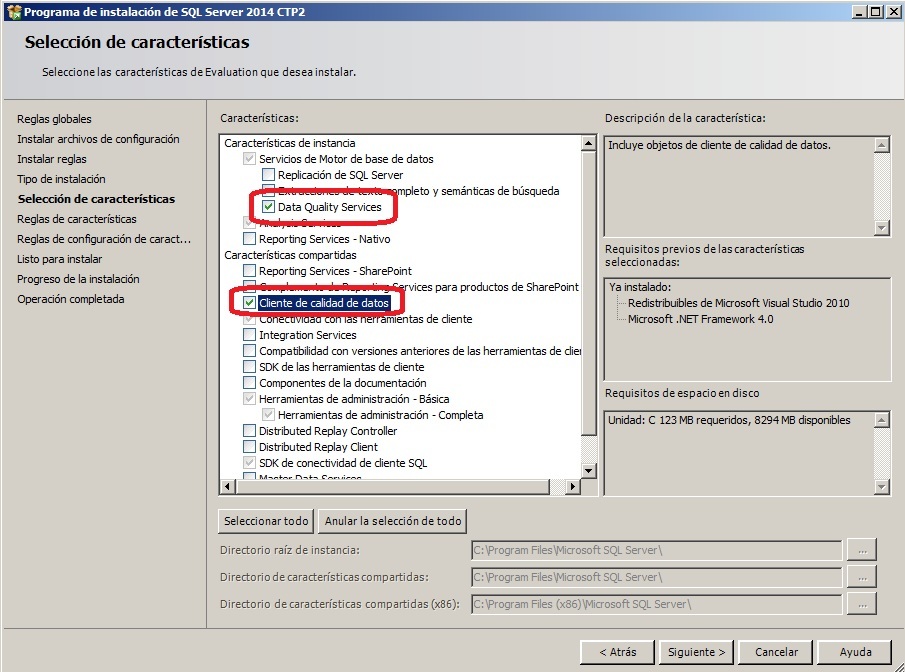
Una vez completada la instalación activamos la parte del Servidor. Lo encontramos en el menú Inicio > Programas > Microsoft SQL Server 2014 CTP>Data Quality Server Installer
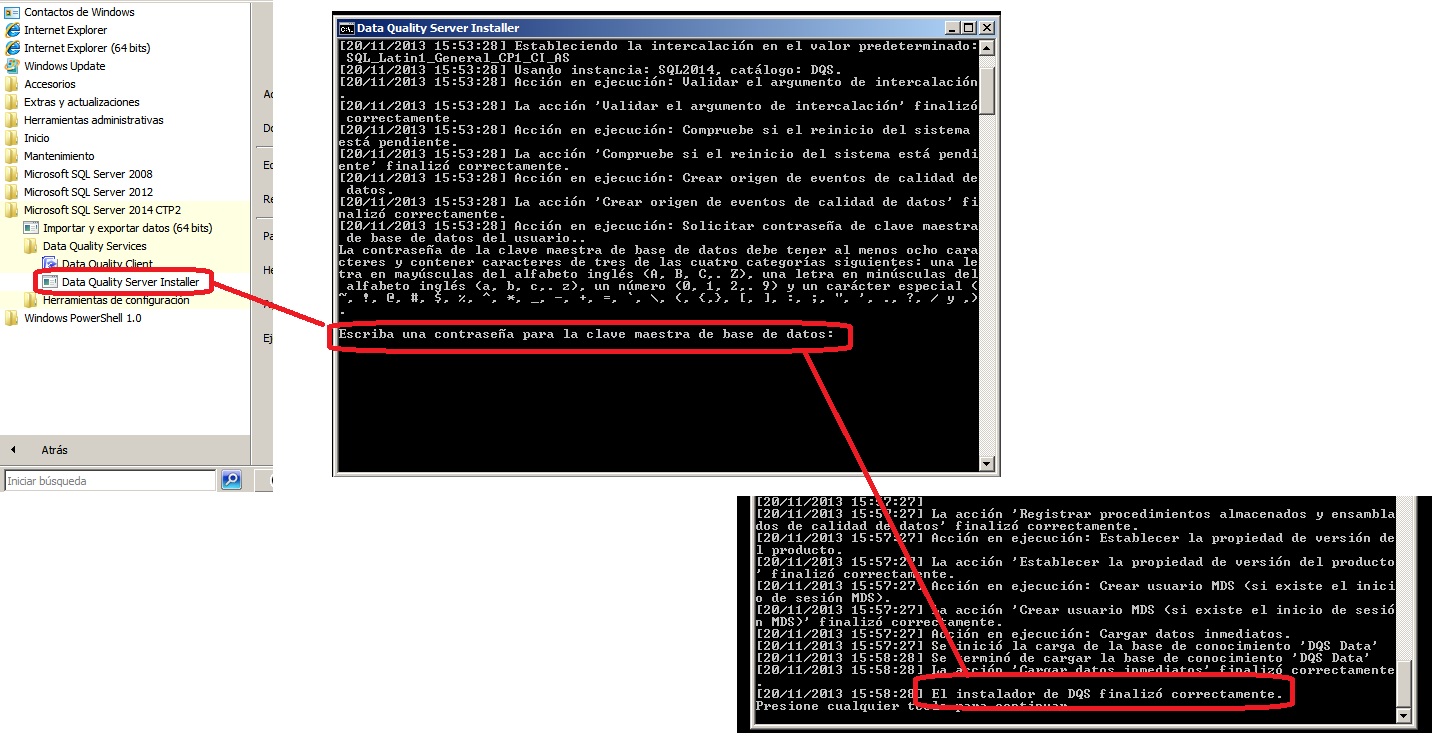
Además de los componentes de servidor, eso también copia una base de conocimento de ejemplo, DQS Data, que incluye algunos dominios predefinidos. Superado este paso ya podemos empezar con nuestro ejemplo. Para las pruebas tendremos dos tablas de empleados como esta que usaremos primero como base para crear las reglas para nuestra base de datos de conocimiento y una vez definidos dominios con sus reglas de validación, las usaremos para probar de corregir los datos y exportarlos a otra tabla de sqlserver.
--Script de carga para las tablas de ejemplo. CREATE TABLE [dbo].[EmpleadosA]( [Nombre] [varchar](20) NULL, [Genero] [varchar](10) NULL, [Edad] [tinyint] NULL ) ON [PRIMARY] INSERT INTO [dbo].[EmpleadosA] VALUES ('John','Male',18) INSERT INTO [dbo].[EmpleadosA] VALUES ('Mike', 'Hombre',18) INSERT INTO [dbo].[EmpleadosA] VALUES ('Rahul', 'Ind',NULL) INSERT INTO [dbo].[EmpleadosA] VALUES ('Sara','Mujer',23) INSERT INTO [dbo].[EmpleadosA] VALUES ('Alberto','H',48) INSERT INTO [dbo].[EmpleadosA] VALUES ('Carlos','Hombre',18) GO CREATE TABLE [dbo].[EmpleadosB]( [Nombre] [varchar](20) NULL, [Email] [varchar](40) NULL, [Titulo] [varchar](20) NULL ) ON [PRIMARY] INSERT INTO [dbo].[EmpleadosB] VALUES ('John','jhon@test.com',NULL) INSERT INTO [dbo].[EmpleadosB] VALUES ('Mike','Mike test.com','Bachillerato') INSERT INTO [dbo].[EmpleadosB] VALUES ('Rahul',' ','Primaria) INSERT INTO [dbo].[EmpleadosB] VALUES ('Sara','sara@test.com','PM') INSERT INTO [dbo].[EmpleadosB] VALUES ('Alberto','alberto@test','Secundaria') INSERT INTO [dbo].[EmpleadosB] VALUES ('Carlos','test@test.com','Licenciado') GO
A continuación ya podemos abrir el Cliente de Calidad de Datos (Microsoft SQL Server 2014>Data Quality Client) para empezar a trastear. Nada más clicar nos pide el nombre del servidor (pensemos en nuestra instancia de servidor SQLSERVER). Lo primero que debemos hacer es crear una Nueva base de Conocimiento.
Lo siguiente será crear una nueva. Le ponemos Nombre y pulsamos siguiente. Cerramos y volvemos al menú principal. A continuación Lo que haremos será elegir de nuestra base de datos la "Detección de conocimiento". Esta opción permite elegir una fuente de datos (excel, sqlserver) y definir dominios a partir de columnas de datos. En mi caso me conecto a la bbdd, elijo una de los tablas de ejemplo para empezar a definir para cada columna que me interese un dominio con parámetros específicos en cada columna que lo necesite... Particularmete interesante la opción de poder elegir, en el caso de una columna de texto, el idioma del mismo, pasarle el corrector ortográfico y también formatear la salida (MAY/MIN para abreviaturas?).
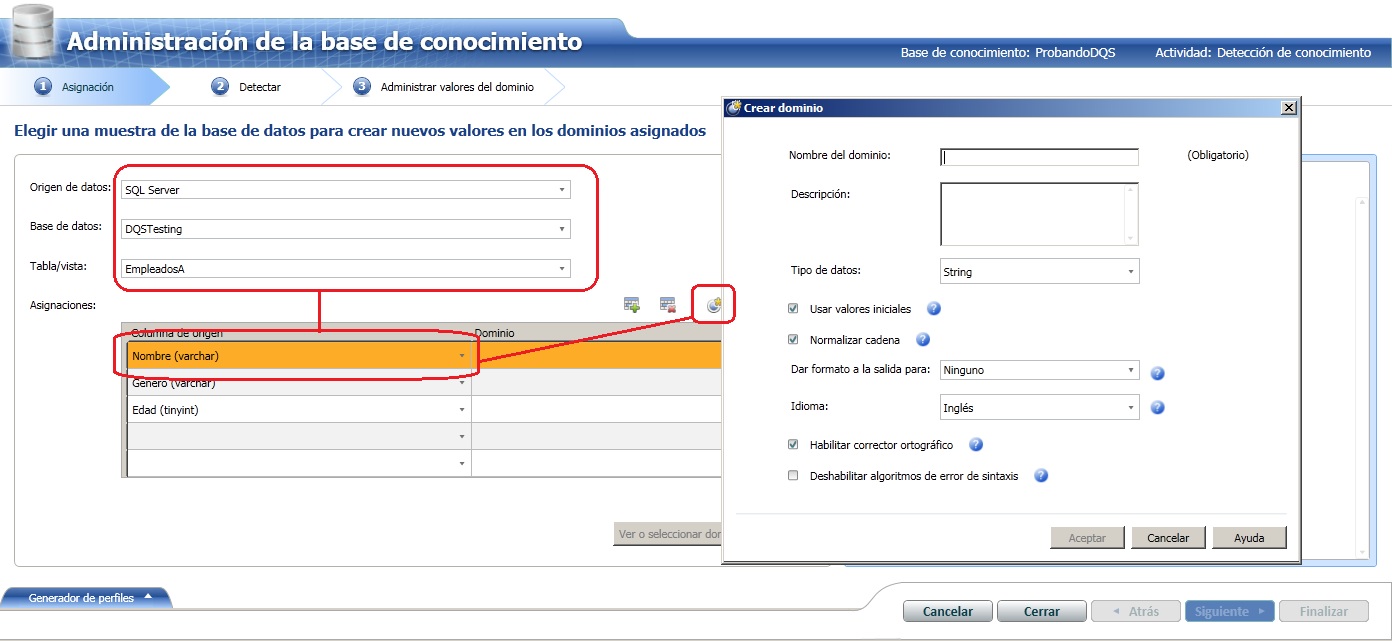
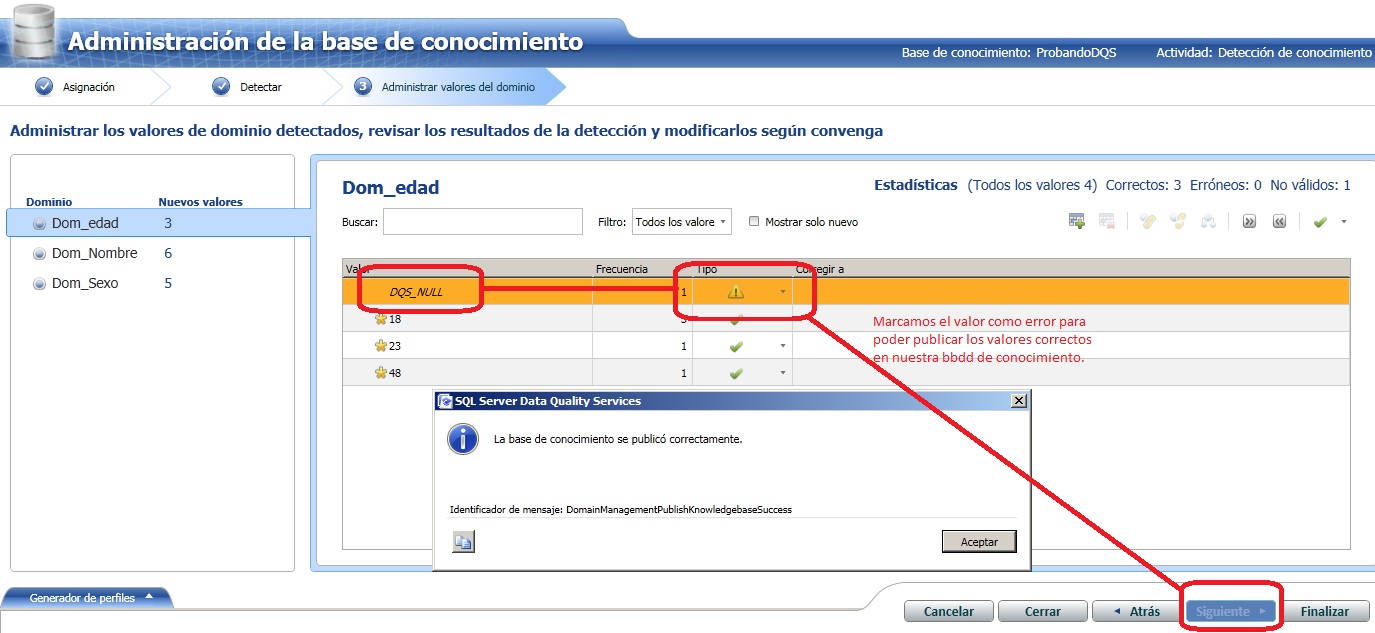
El paso siguiente es el "análisis de detección de datos en el origen seleccionado". Se escanea el origen y se determina por cada columna los valores únicos, los validos y los que infringen la integridad (valores null etc). Si hemos probado sobre EmpleadosA solo vemos un error de integridad debido a un NULL en la columna Edad. Pulsamos siguiente y podemos elegir que hacer con los nuevos valores que sean validos, así como ignorar los incorrectos marcándolos como error.
(
Ahora, antes de validar de nuevo, definiremos un dominio más complejo para los campos de email. En este caso será una regla de validación de formato. Primero vamos como a antes a la detección de dominios para definir sobre la segunda tabla el dominio sobre la columna email (como el los ejemplos anteriores). Una vez hemos creado el dominio para el campo email, la diferencia es que saldremos y entraremos en el Administrador de dominios sobre nuestra base de datos de conocimiento y modificaremos las Reglas de Dominio (fijaros también que aquí podemos explorar los Valores del Dominio que forman parte de él) para añadir una del tipo: "El valor coincide con la expresión regular": ^[_a-z0-9-]+(\.[a-z0-9-]+)*@[a-z0-9-]+(\.[a-z0-9-]+)*(\.[a-z]{2,4})$
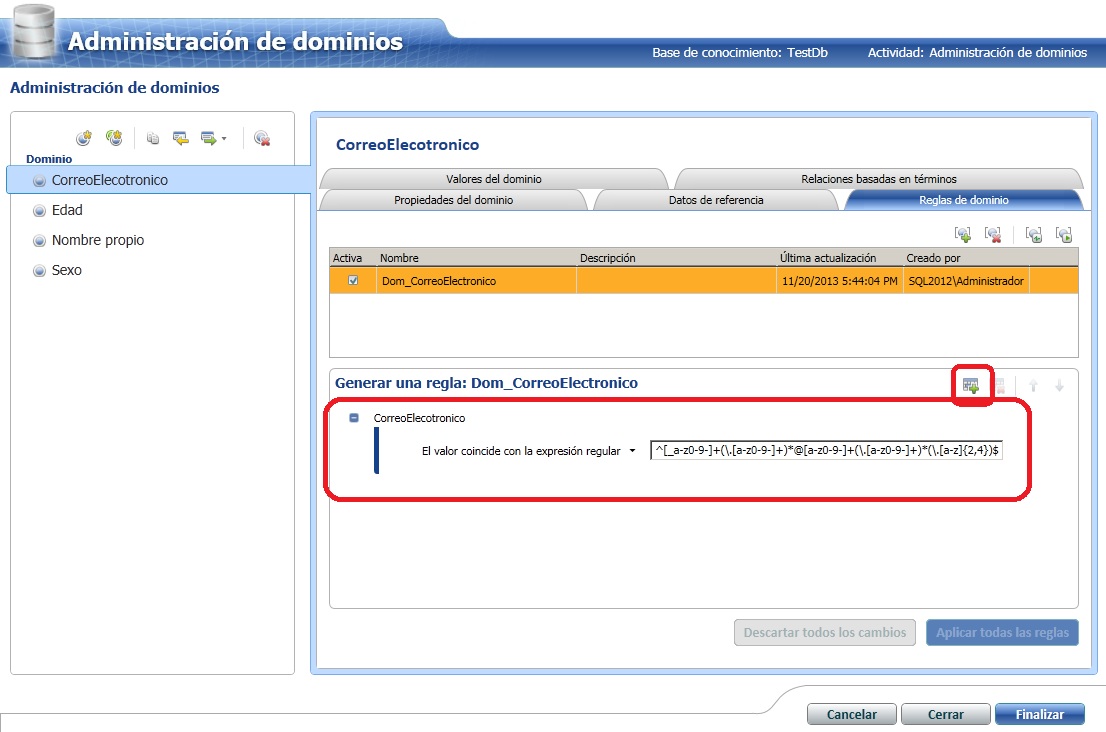
Al final publicamos este último cambio de este dominio y ya estamos listos para continuar.
El último paso ya para acabar con esta prueba es validar una tabla real, corregir los datos y exportar a una nueva con los datos que no cumplan las reglas y decidamos corregir. Para hacerlo abrimos de nuevo el Data Quality Client y creamos un nuevo proyecto de calidad de datos. Le pondremos nombre, elegimos la base de conocimiento que hemos definido antes y elegimos limpieza. Los pasos a partir de aquí son parecidos a los anteriores cuando explorábamos la tabla. En el siguiente paso elegimos la tabla a limpiar y para cada columna, si es necesario, un dominio para aplicar sobre ella. Pulsamos siguiente y escaneamos los datos. Con los datos de ejemplo, detectara dos valores para email erróneos que podremos corregir (si han sido corregidos anteriormente los auto-corrige y aparecen como "Corregido"). Finalmente, en el siguiente paso podemos elegir donde exportar nuestros datos pulidos (por ejemplo a una nueva tabla).
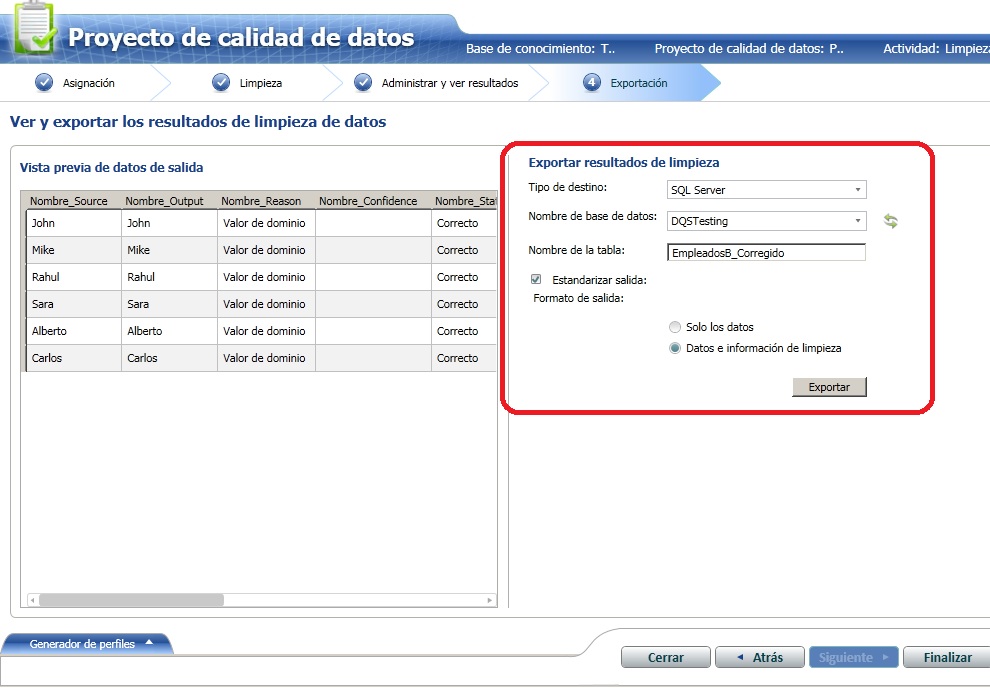
Mis conclusiones son...
... que esta es otra herramienta Microsoft bastante fácil de usar y puede que bastante útil para pulir datos maestros de cualquier base de datos o para incluir validaciones como paso intermedio en nuestras cargas para el dwh. Su sencillez (la misma prueba con el proyecto de calidad de datos) hace fácil compartir la carga de corrección manual de los datos con alguien que no sea técnico de bbdd ni programador, más bien una persona dentro de la organización con conocimiento de causa que coja los datos del origen, los interprete y los deje donde tu le digas para cargarlos en algún sitio.
Articulo muy interesante,
- Log in to post comments
SQL Sentry Plan Explorer de SQL Server 2014, herramienta complementaria a Management Studio
SQL Sentry Plan Explorer de SQL Server 2014, herramienta complementaria a Management Studio il_masacratore 16 January, 2014 - 13:22SentryOne dispone de diferentes aplicaciones para ayudarnos en la administración y el día a día con nuestra base de datos SQL Server, dwh o como desarrolladores. SentryOne Plan Explorer permite hacer un análisis más gráfico de una consulta que lanzamos sobre SQL Server y deforma interactiva profundizar en diferentes aspectos relacionados como coste de operaciones, peso sobre el lote, índices involucrados...
Plan Explorer tiene versión free y versión PRO. La versión free podemos descargarla directamente de SentryOne donde tenemos el instalador de la aplicación y adicionalmente un addon para SQL Server Management Studio. La instalación no tiene misterio y es del estilo siguiente siguiente.
A primera vista, como otras herramientas parecidas, muestra lo que nos da el propio Management Studio cuando vemos el plan de ejecución estimado/real de una consulta. Lo que es distinto es que de forma predeterminada ya focaliza nuestra atención a las áreas problemáticas que van con nuestra consulta. Por ejemplo, en la pestaña de Plan Diagram, ya nos marca las operaciones más costosas mediante colores. Otro ejemplo es la pestaña Plan Tree que muestra los datos más concretos donde también nos marca de otro color si existe una gran diferencia entre las filas estimadas con las filas reales (estadísticas desactualizadas!).
La forma de empezar a trabajar es bastante sencilla. Basta con hacer un Copy & Paste de la consulta en la pestaña que vemos por defecto en la pantalla inicial, Command Text. A continuación ya podemos pulsar ver el Plan Estimado o el Real, como en Management Studio. Es en ese momento cuando nos pide a que servidor y base de datos conectarse.
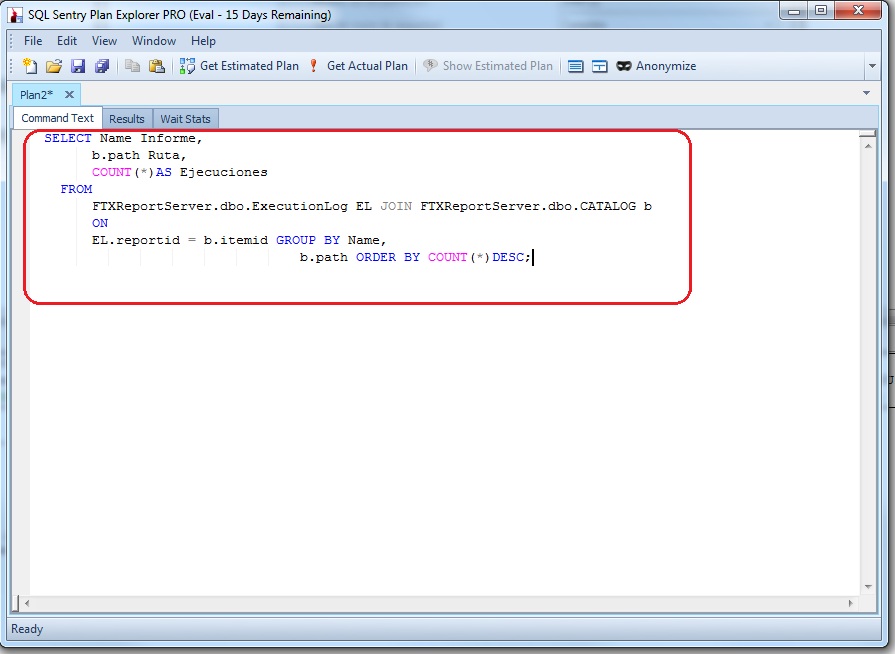
Una vez conectados y obtenido el plan estimado de ejecución ya vemos en la parte inferior su diagrama. En el ya nos marca en % relativos al coste total las operaciones y en colores remarcadas las más costosas. A diferencia de Management Studio, si falta un indice nos aparece el símbolo warning en el SELECT en lugar de la parrafada en el encabezado de la pestaña.
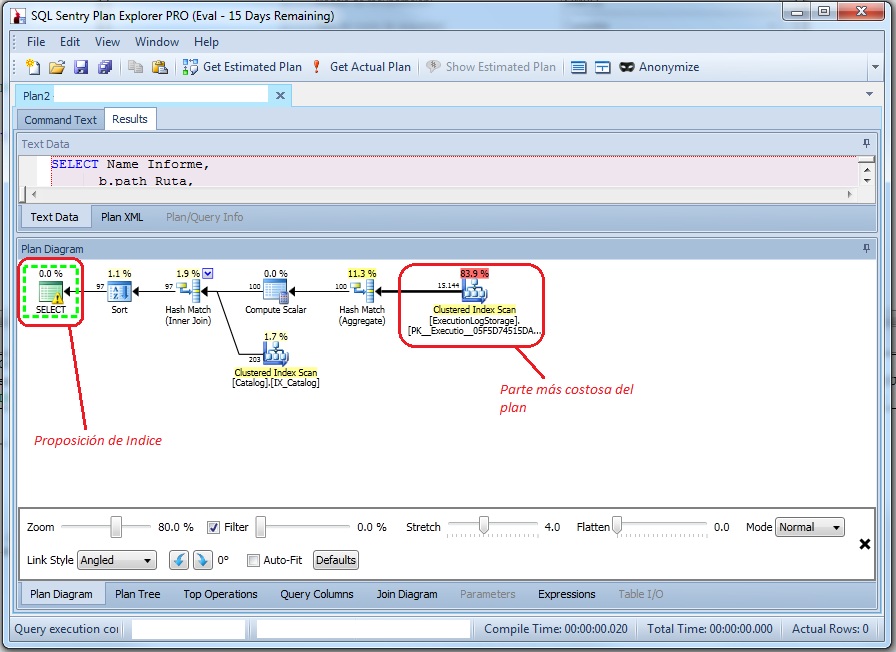
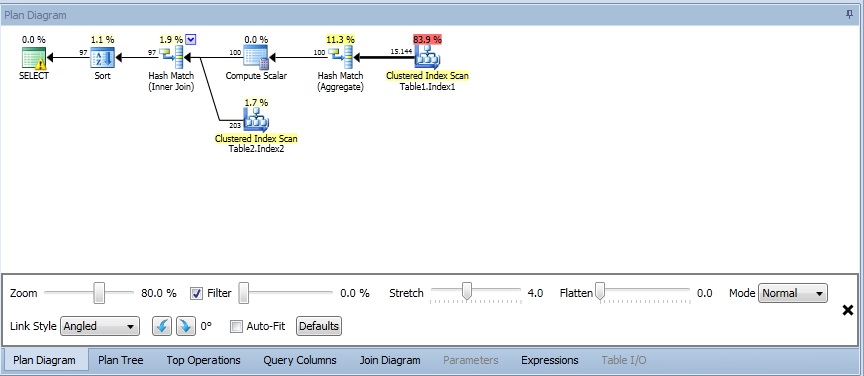
Los porcentajes que vemos, por defecto corresponde a la suma de I/O+CPU, pero también podemos elegir solo por I/O o CPU según nos convenga. También podemos hacer que varíe el grueso de las lineas de datos según su volumen (todo esto en el menú contextual del área del gráfico).
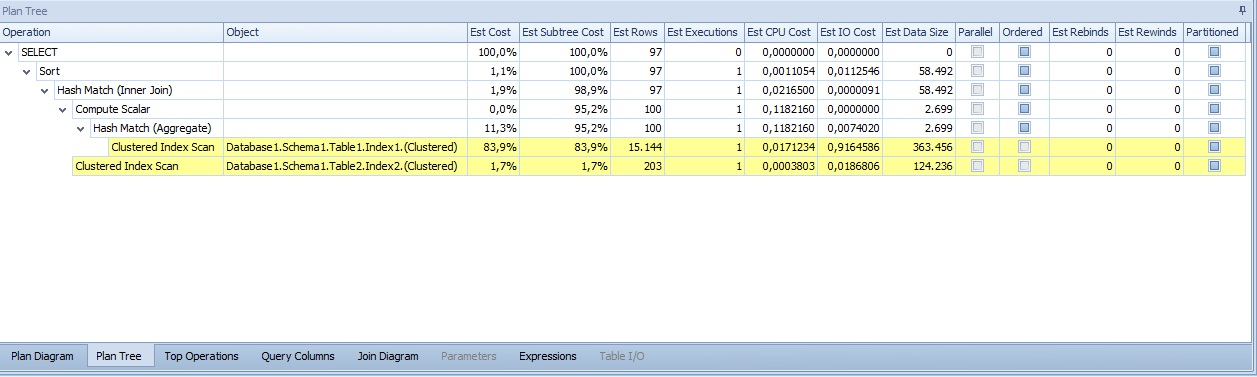
En la segunda pestaña del panel inferior, Plan Tree, vemos jerarquizadas las operaciones con los datos más relevantes por defecto (Coste estimado, Coste del subarbol, filas estimadas que pasan, etc...). Podemos añadirle según nuestras necesidades o gustos mas columnas.
En la tercera pestaña, Top Operations, podemos comparar directamente mediante una tabla costes de cpu y de I/O las diferentes operaciones dentro de la consulta. Como en la pestaña anterior, podemos añadir más columnas según nuestros gustos.
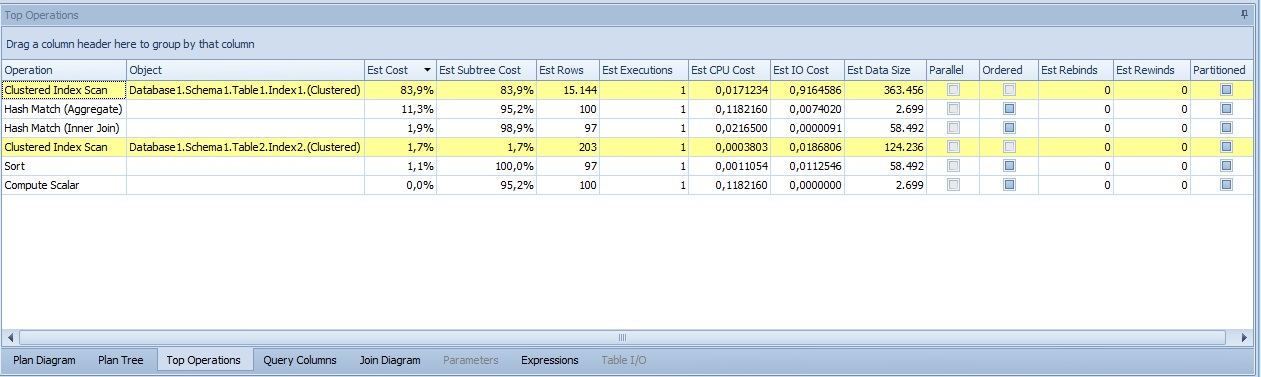
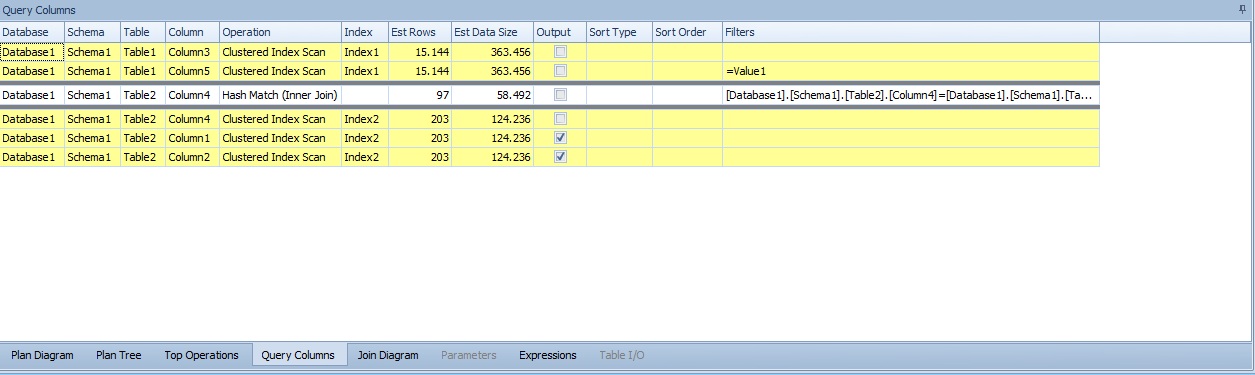
En la cuarta, Query Columns, vemos los índices que se usan en la consulta y que filtros aplican. También vemos el tipo de operación (Index Seek, Clustered Index Seek, Index Scan...). En la versión PRO de Plan Explorer desde aquí podemos ver las estadísticas de estos índices e incluso crear uno nuevo.
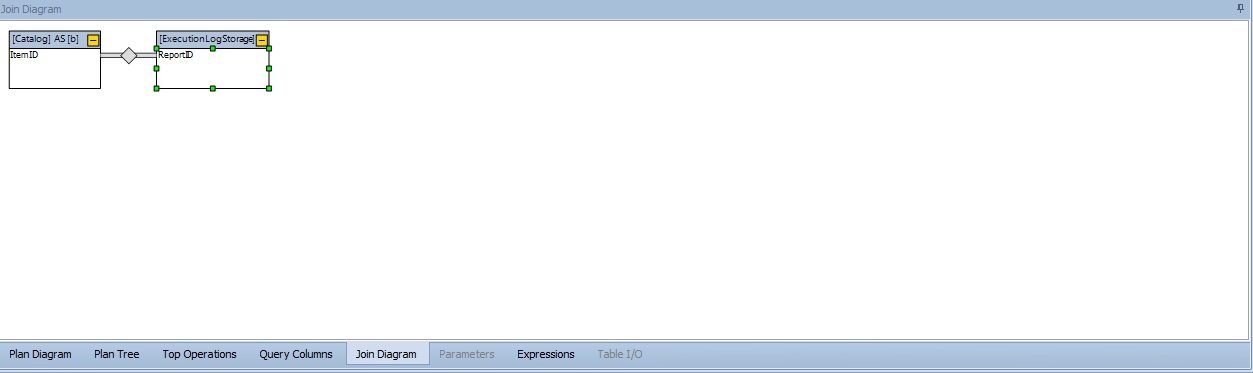
La quinta pestaña, Join Diagram, muestra de manera directa y muy simplificada las tablas involucradas solo con los campos que usamos en la relación entre ellas.
Parameters muestra los parámetros incluidos en la consulta, incluso los no declarados explícitamente. La pestaña Expressions muestra datos adicionales por cada expresión de agregado: SUM, MIN etc... Realmente no aporta demasiado pero tampoco molesta. Por último, la pestaña Table I/O muestra los datos relativos a entrada y salida de datos: cantidad de scans, lecturas físicas, lógicas.
Una de las diferencias entre trabajar con el plan estimado (Get Estimated PLan) y el real (Get Actual Plan) es que además de las estadísticas de I/O que se muestran en la pestaña Table I/O, también se comparan las filas estimadas con las reales, algo que puede indicar que las estadísticas están desactualizadas.
Otra de las opciones, como mínimo curiosas, es la opción de menú Anonymize. Esta lo que hace es abrir una nueva ventana donde nos ha reemplazado los nombres de nuestras bases de datos, los índices, nombres de usuario, alias, parámetros... con toda la info relativa a la query. La gracia es poder compartir esta información y pedir consejo si hiciera falta.
El addon de SentryOne Plan Explorar para SQL Server Management Studio es un simple vínculo que permite desde la visualización de cualquier plan de ejecución desde el menú contextual, haciendo clic derecho en el área "View with SQL Sentry Plan Explorer". Para instalarlo basta con descargarlo de aquí y reiniciar Management Studio para que podamos usarlo. Es un requisito haber instalado antes la propia aplicación Plan Explorer. El addon de momento funciona con Management Studio incluido en SQL Server 2005, SQL Server 2008, SQL Server 2008 R2 y SQL Server 2012.
En resumen...
... Me parece una herramienta útil pero no esencial. Ofrece alguna cosa más que el propio Management Studio y lo hace más bonito pero podemos vivir sin ella. Uno de los motivos por los quizás que me parece recomendable es para alguien que anda perdido y no sabe por donde empezar.
No es lo mismo enfrentarte con la ventana del plan de SSMS que con los colores y pestañas de SQLSentry Plan Explorer. Para el resto, mi conclusión es que lo que más aporta es facilidad de acceso a todos los aspectos relacionados con la query.