Tabla Hechos Venta. Particionado en MySql.
Tabla Hechos Venta. Particionado en MySql. respinosamilla Thu, 02/25/2010 - 09:50Antes de comenzar la implementación del proceso ETL para la carga de la tabla de Hechos de Ventas, vamos a realizar alguna consideración sobre el particionado de tablas.
Cuando estamos costruyendo un sistema de business intelligence con su correspondiente datawarehouse, uno de los objetivos (aparte de todas las ventajas de sistemas de este tipo: información homogenea, elaborada pensando en el analisis, dimensional, centralizada, estatica, historica, etc., etc.) es la velocidad a la hora de obtener información. Es decir, que las consultas se realicen con la suficiente rapidez y no tengamos los mismos problemas de rendimiento que suelen producirse en los sistemas operacionales (los informes incluso pueden tardar horas en elaborarse).
Para evitar este problema, hay diferentes técnicas que podemos aplicar a la hora de realizar el diseño fisico del DW. Una de las técnicas es el particionado.Pensar que estamos en un dw con millones de registros en una unica tabla y el gestor de la base de datos ha de mover toda la tabla. Ademas, seguramente habrá datos antiguos a los que ya no accederemos casi nunca (datos de varios años atras). Si somos capaces de tener la tabla “troceada” en segmentos mas pequeños seguramente aumentaremos el rendimiento y la velocidad del sistema.
El particionado nos permite distribuir porciones de una tabla individual en diferentes segmentos conforme a unas reglas establecidas por el usuario. Según quien realize la gestión del particionado, podemos distinguir dos tipos de particionado:
Manual: El particionado lo podriamos realizar nosotros en nuestra lógica de procesos de carga ETL (creando tablas para separar los datos, por ejemplo, tabla de ventas por año o por mes/año). Luego nuestro sistema de Business Intelligence tendrá que ser capaz de gestionar este particionado para saber de que tabla tiene que leer según los datos que le estemos pidiendo (tendra que tener un motor de generación de querys que sea capaz de construir las sentencias para leer de las diferentes tablas que incluyen los datos). Puede resultar complejo gestionar esto.
Automatico: Las diferentes porciones de la tabla podrán ser almacenadas en diferentes ubicaciones del sistema de forma automatica según nos permita el SGBDR que estemos utilizando.La gestión del particionado es automática y totalmente transparente para el usuario, que solo ve una tabla entera (la tabla “lógica” que estaria realmente partida en varias tablas “fisicas”). La gestión la realiza de forma automática el motor de base de datos tanto a la hora de insertar registros como a la hora de leerlos.
La partición de tablas se hace normalmente por razones de mantenimiento, rendimiento o gestión.
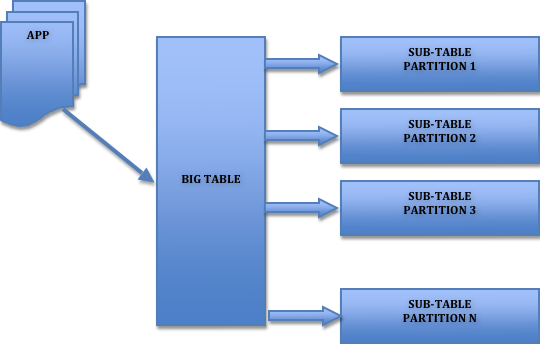
Lógica Particionado de tablas
Según la forma de realizar el particionado, podriamos distinguir:
Partición horizontal (por fila): consiste en repartir las filas de una tabla en diferentes particiones. Por ejemplo, los clientes de un pais estan incluidos en una determinada partición y el resto de clientes en otra. En cada partición se incluyen los registros completos de cada cliente.
Partición vertical( por columna): consiste en repartir determinadas columnas de un registro en una partición y otras columnas en otra (partimos la tabla verticalmente,). Por ejemplo, en una partición tenemos las columnas de datos de direcciones de los clientes, y en otra partición las columnas de datos bancarios.
Cada motor de base de datos implementa el particionado de forma diferente. Nosotros nos vamos a centrar en la forma de implementarlo utilizando Mysql, que es la base de datos que estamos utilizando para nuestro proyecto.
Particionado de tablas en MySql
MySql implementa el particionado horizontal. Basicamente, se pueden realizar cuatro tipos de particionado, que son:
- RANGE: la asignación de los registros de la tabla a las diferentes particiones se realiza según un rango de valores definido sobre una determinada columna de la tabla o expresión. Es decir, nosotros indicaremos el numero de particiones a crear, y para cada partición, el rango de valores que seran la condicion para insertar en ella, de forma que cuando un registro que se va a introducir en la base de datos tenga un valor del rango en la columna/expresion indicada, el registro se insertara en dicha partición.
- LIST: la asignación de los registros de la tabla a las diferentes particiones se realiza según una lista de valores definida sobre una determinada columna de la tabla o expresión. Es decir, nosotros indicaremos el numero de particiones a crear, y para cada partición, la lista de valores que seran la condicion para insertar en ella, de forma que cuando un registro que se va a introducir en la base de datos tenga un valor incluido en la lista de valores, el registro se insertara en dicha partición.
- HASH: este tipo de partición esta pensado para repartir de forma equitativa los registros de la tabla entre las diferentes particiones. Mientras en los dos particionados anteriores eramos nosotros los que teniamos que decidir, según los valores indicados, a que partición llevamos los registros, en la partición HASH es MySql quien hace ese trabajo. Para definir este tipo de particionado, deberemos de indicarle una columna del tipo integer o una función de usuario que devuelva un integer. En este caso, aplicamos una función sobre un determinado campo que devolvera un valor entero. Según el valor, MySql insertará el registro en una partición distinta.
- KEY: similar al HASH, pero la función para el particionado la proporciona MySql automáticamente (con la función MD5). Se pueden indicar los campos para el particionado, pero siempre han de ser de la clave primaria de la tabla o de un indice único.
- SUBPARTITIONS: Mysql permite ademas realizar subparticionado. Permite la división de cada partición en multiples subparticiones.
Ademas, hemos de tener en cuenta que la definición de particiones no es estática. Es decir, MySql tiene herramientas para poder cambiar la configuración del particionado a posteriori, para añadir o suprimir particiones existentes, fusionar particiones en otras, dividir una particion en varias, etc. (ver aquí ).
El particionado tiene sus limitaciones y sus restricciones, pues no se puede realizar sobre cualquier tipo de columna o expresión (ver restricciones al particionado aquí), tenemos un limite de particiones a definir y habrá que tener en cuenta algunas cosas para mejorar el rendimiento de las consultas y evitar que estas se recorran todas las particiones de una tabla ( el artículo MySql Partitions in Practice, se nos explica con un ejemplo trabajando sobre una base de datos muy grande, como realizar particionado y que cosas tener en cuenta para optimizar los accesos a las consultas). Para entender como funciona el particionado, hemos replicado los ejemplos definidos en este articulo con una tabla de pruebas de 1 millón de registros (llenada, por cierto,con datos de prueba generados con Talend y el componente tRowGenerator).
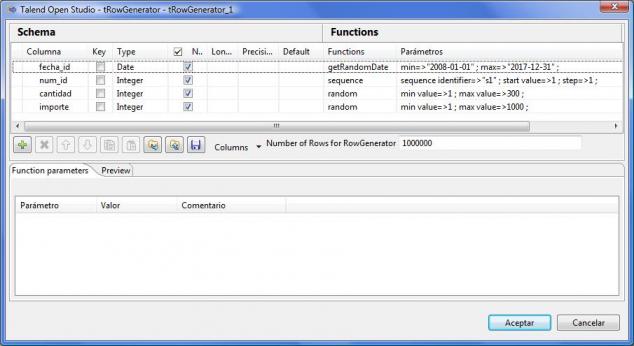
Ejemplo componente tRowGenerator para producir datos de test
En concreto, hemos creado dos tablas iguales (con la misma estructura). Una con particionado por año en un campo de la clave del tipo fecha, y la segunda con la misma estructura sin particionado. En ambas tablas tenemos un millon de registros repartidos entre los años 2008 y 2017. Una vez creadas las tablas, utilizamos la sentencia de MySql explain y explain partitions para analizar como se ejecutaran las sentencias sql (analisis de indices). Ademas, comprobamos tiempos de ejecución con diferentes tipos de sentencia SQL. Los resultados son mas que obvios:

Analisis tiempos ejecucion
En las mayoria de los casos se obtiene un mejor tiempo de respuesta de la tabla particionada, y en los casos en los que no, el tiempo de ejecución es practicamente igual al de la tabla no particionada (diferencias de milesimas de segundo). Observar cuando indicamos condiciones fuera del indice (ultima sentencia SQL), como los tiempos de respuesta son aun mas relevantes. Y siempre conforme vamos leyendo de mas particiones (por incluir mas años en la condición), el tiempo de respuesta de la consulta entre una y otra tabla se va acercando.
Particionado de la tabla de hechos de Ventas en nuestro DW
Para nuestro DW, hemos decidir implementar un particionado del tipo LIST. Como os habreis podido dar cuenta, seguramente los particionados por RANGE o por LIST son los mas adecuados para un sistema de Business Intelligence pues nos van a permitir de una forma facil reducir el tamaño de las casi siempre monstruosas tablas de hechos, de una forma fácil y automática.
Vamos a crear 10 particiones y repartiremos los diferentes años en cada una de las particiones, empezando por 2005 –> Particion 1, 2006 –> Particion 2, 2007 –> Particion 3, …, 2013 –> Particion 9, 2014 –> Partición 10. A partir de 2015, volvemos a asignar cada año a las particiones y así hasta el año 2024 (tiempo de sobra para lo que seguramente será la vida de nuestro DW).
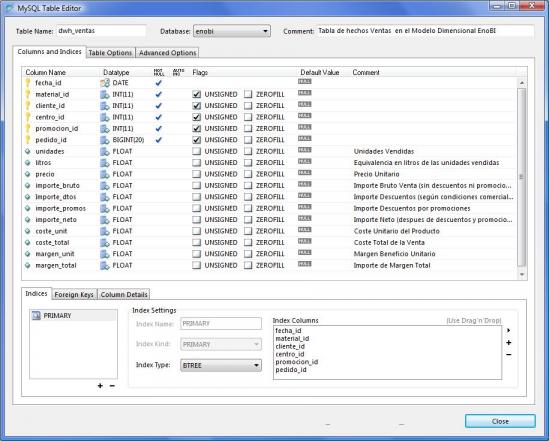
Como el campo año no lo tenemos en el diseño físico de la tabla de hechos, aplicaremos sobre la columna fecha la funcion YEAR para realizar el particionado. La sentencia para la creación de la tabla de hechos quedaría algo parecido a esto:
CREATE TABLE IF NOT EXISTS `enobi`.`dwh_ventas` ( `fecha_id` DATE NOT NULL , `material_id` INT(11) NOT NULL , `cliente_id` INT(11) NOT NULL , `centro_id` INT(11) NOT NULL , `promocion_id` INT(11) NOT NULL , `pedido_id` INT(11) NOT NULL , `unidades` FLOAT NULL DEFAULT NULL COMMENT 'Unidades Vendidas' , `litros` FLOAT NULL DEFAULT NULL COMMENT 'Equivalencia en litros de las unidades vendidas' , `precio` FLOAT NULL DEFAULT NULL COMMENT 'Precio Unitario' , `coste_unit` FLOAT NULL DEFAULT NULL COMMENT 'Coste Unitario del Producto')
PARTITION BY LIST(YEAR(fecha_id)) (
PARTITION p1 VALUES IN (2005,2015),
PARTITION p2 VALUES IN (2006,2016),
..................................
PARTITION p9 VALUES IN (2013,2023),
PARTITION p10 VALUES IN (2014,2024)
);Con este forma de definir el particionado estamos sacando ademas partido de la optimización de lo que en MySql llaman “Partitioning Pruning”. El concepto es relativamente simple y puede describirse como “No recorras las particiones donde no puede haber valores que coincidan con lo que estamos buscando”. De esta forma, los procesos de lectura serán mucho mas rápidos.
A continuación, veremos en la siguiente entrada del Blog los ajustes de diseño de nuestro modelo físico en la tabla de hechos (teniendo en cuenta todo lo visto referente al particionado) y los procesos utilizando la ETL Talend para su llenado.
Tabla Hechos Venta. Ajuste diseño fisico y procesos carga ETL. Contextos en Talend.
Tabla Hechos Venta. Ajuste diseño fisico y procesos carga ETL. Contextos en Talend. respinosamilla Thu, 02/25/2010 - 09:50Vamos a desarrollar los procesos de carga de la tabla de hechos de ventas de nuestro proyecto utilizando Talend. Antes de esto, vamos a hacer algunas consideraciones sobre la frecuencia de los procesos de carga que nos van a permitir introducir el uso de un nuevo elemento de Talend, los contextos.
En principio, vamos a tener varios tipos de carga de datos:
- Carga inicial: será la primera que se realice para la puesta en marcha del proyecto, e incluira el volcado de los datos de venta desde una fecha inicial (a seleccionar en el proceso) hasta una fecha final.
- Cargas semanales: es el tipo de carga mas inmediato. Se realiza para cada semana pasada (por ejemplo, el martes de cada semana se realiza la carga de la semana anterior), para tener un primer avance de información de la semana anterior (que posteriormente se refrescara para consolidar los datos finales de ese periodo). La carga de una semana en concreto también se podrá realizar a petición (fuera de los procesos batch automáticos).
- Recargas mensuales: una vez se cierra un periodo mensual (lo que implica que ya no puede haber modificaciones sobre ese periodo), se refresca por completo el mes en el DW para consolidar la información y darle el status de definitiva para ese periodo. La ejecución es a petición y se indicara el periodo de tiempo que se quiere procesar.
Teniendo en cuenta esto, definiremos un unico proceso de traspaso al cual se pasaran los parametros que indicaran el tipo de carga a realizar. Para ello utilizaremos los contextos de Talend. Cada tipo de carga tendra un contexto personalizado que definira como se va a comportar el proceso.
Contextos en Talend
Los contextos de Talend son grupos de variables contextuales que luego podemos reutilizar en los diferentes jobs de nuestras transformaciones. Nos pueden ser utiles para muchas cosas, como para tener definidas variables con los valores de paths de ficheros, valores para conexión a bases de datos (servidor, usuario, contraseña, puerto, base de datos por defecto, etc), valores a pasar a los procesos (constantes o definidos por el usuario en tiempo de ejecución). Los valores de los contextos se inicializan con un valor que puede ser cambiado por el usuario mediante un prompt (petición de valor). Un mismo contexto puede tener diferentes “grupos de valores”. Es decir, en el contexto “conexion a base de datos”, podemos tener un grupo de valores llamado “test”, que incluira los valores para conectarnos al sistema de pruebas y un grupo llamado “productivo”, que incluira los valores para la conexión a la base de datos real (tal y como vemos en el ejemplo).
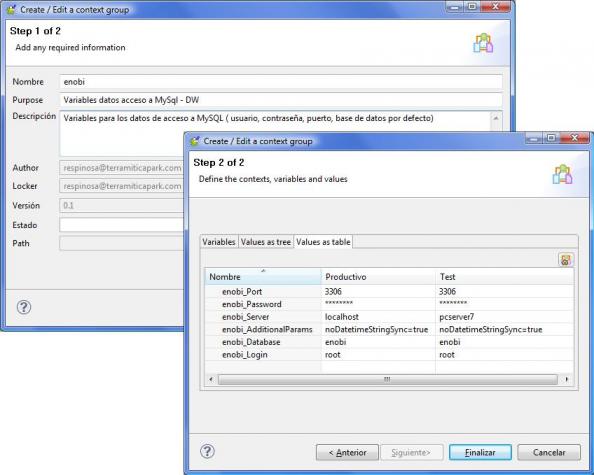
Definición de Contextos en Talend
Dentro del contexto, definiremos que grupo de valores es el que se utilizara por defecto. Esto nos va a permitir trabajar con los jobs y sus componentes olvidandonos de contra que sistema estamos trabajando. Tendremos, por ejemplo, el contexto de test activo, y es el que utilizaremos para las pruebas. Y podremos cambiar en cualquier momento, al ejecutar un job, para decirle que utilice el contexto “productivo”. Igualmente, podremos preparar un fichero o una tabla de base de datos con los valores de las variables de contexto, que serán pasadas al job para su utilización en la ejecución de un proceso (utilizando el componente tContextLoad).
Definición del proceso de carga
El diseño físico definitivo de la tabla de hechos será el siguiente:
Una vez hechas todas las consideraciones, veamos el esquema de como quedaria nuestro proceso de transformación.
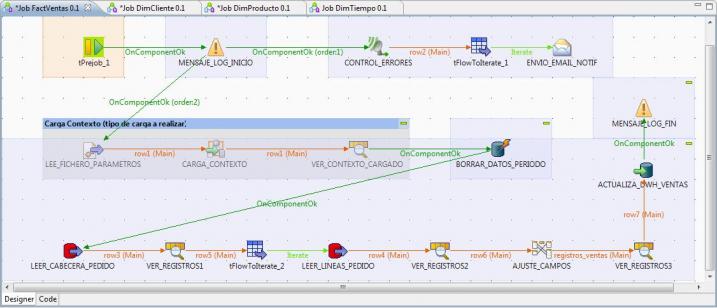
Job completo en Talend para la carga de la tabla de Hechos
Vamos a ver en detalle cada uno de los pasos que hemos definido para realizar la lectura de datos del sistema origen y su transformación y traspaso al sistema destino (y teniendo en cuenta varios procesos auxiliares y la carga del contexto de ejecución).
1) Ejecución de un prejob que lanzará un generara en el log un mensaje de inicio del proceso y un logCatcher (para recoger las excepciones Java o errores en el proceso). Este generará el envio de un email de aviso en el caso de que se produzca algún problema en cualquier paso del job (al igual que hemos incluido en todos los jobs de carga del DW vistos hasta ahora).
- Lanzador Prejob (componente tPrejob): sirve para realizar el lanzamiento de un pretrabajo, anterior al proceso principal.
- Mensaje Log Inicio (componente tWarn): genera un mensaje de log indicando que se comienza la ejecución del job.
- Control Errores (componente tLogCatcher): activamos el componente que “escuchara” durante toda la ejecución del job, esperando que se produzca algún tipo de error. En ese momento se activara para recuperar el error y pasarlo al componente siguiente para el envio de un email de notificación.
- tFlowtoIterate: convertimos el flujo de registros de log a una iteración para poder realizar el envio del correo electrónico.
- Envio Email Notif (componente tSendMail): generamos el envio de un email de notificación de errores, incluyendo el paso donde se paro el proceso, y el mesaje de error generado. Es una forma de avisar que ha fallado algo en el proceso.
2) Carga del contexto de ejecución: para que el proceso sepa que tipo de carga ha de realizar y para que periodo de fechas, es necesario proporcionarle la información. Esto lo haremos utilizando los contextos. En este caso, tal y como vemos en la imagen, el contexto tendrá 3 variables, donde indicaremos el tipo de carga y la fecha inicio y fin del periodo a procesar.
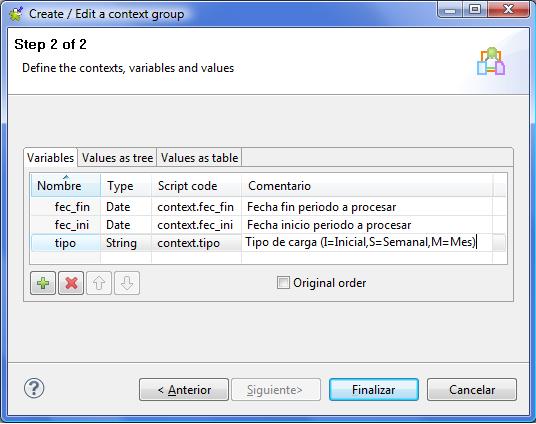
Contexto para la ejecución del Job
Los valores para llenar el contexto los recuperaremos de un fichero de texto (también lo podiamos haber recuperado de los valores existentes en una tabla de la base de datos). El fichero contendrá lineas con la estructura “clave=valor”, donde clave sera el nombre de la variable y valor su contenido.
Para abrir el fichero, utilizaremos el paso LEE_FICHERO_PARAMETROS (componente tFileInputProperties), que nos permite leer ficheros de parametros. A continuación cargaremos los valores recuperados en el contexto utilizando el paso CARGA_CONTEXTO, del tipo tContextLoad. A partir de este momento ya tenemos cargado en memoria el contexto con los valores que nos interesan y podemos continuar con el resto de pasos.
Podriamos haber dejado preparados los valores de contexto en una tabla de base de datos y utilizar un procedimiento parecido para recuperarlos y con el componente tContextLoad cargarlos en el job. Tened en cuenta que los ficheros que va a leer el job habrán sido previamente preparados utilizando alguna herramienta, donde se definira el tipo de carga a realizar y el periodo (y dichos valores se registraran en el fichero para su procesamiento).
3) Borrado previo a la recarga de los datos del periodo en la tabla de hechos (para hacer un traspaso desde cero): antes de cargar, vamos a hacer una limpieza en la tabla DWH_VENTAS para el periodo a tratar. De estar forma, evitamos inconsistencia en los datos, que podrían haber sido cargados con anterioridad y puede haber cambios para ellos. Con el borrado, nos aseguramos que se va a quedar la última foto completa de los datos. Para hacer esto, utilizamos el paso BORRAR_DATOS_PERIODO (del tipo tMySqlRow).
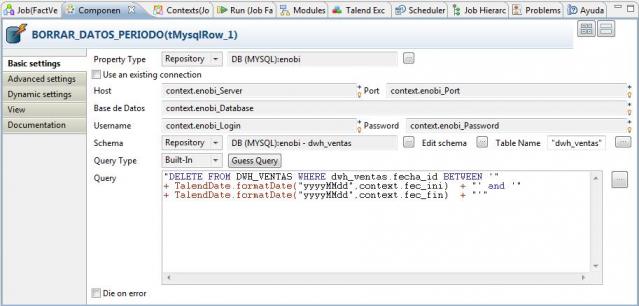
Observad como en el paso hemos incluido la ejecución de una sentencia sql de borrado (DELETE), y le hemos pasado como valores en las condiciones del where las fechas del periodo, utilizando las variables de contexto.
4) Lectura de datos desde los pedidos de venta (cabecera) y a partir de cada pedido, de las lineas (desde el ERP).
A continuación, procederemos a recuperar todos los pedidos de venta del periodo para obtener los datos con los que llenar la tabla de Hechos. Para ello, utilizamos el paso LEER_CABECERA_PEDIDO (del tipo tOracleInput), con el que accedemos a oracle y obtenemos la lista de pedidos que cumplen las condiciones (observar como también en la sentencia SQL ejecutada por este componente hemos utilizado las variables de contexto).
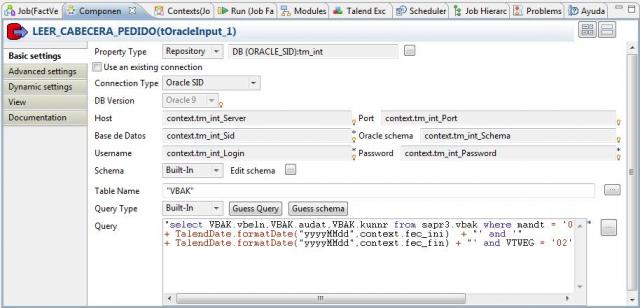
A continuación, para cada pedido, recuperamos todas las lineas que lo componen con el paso LEER_LINEAS_PEDIDO (también del tipo tOracleInput) y pasamos todos los datos al componente tMap para realizar las transformaciones, normalización y operaciones, antes de cargar en la base de datos.
5) Transformación de los campos, normalización, operaciones.
Los valores de los datos de cabeceras y lineas de pedido recuperados desde Sap los transformamos a continuación conforme a la especificaciones que hicimos en el correspondiente análisis (ver entrada blog). En este proceso realizamos conversión de tipos, llenado de campos vacios, cálculos, operaciones. Todo con el objetivo de dejar los datos preparados para la carga en la tabla de Hechos de la base de datos.
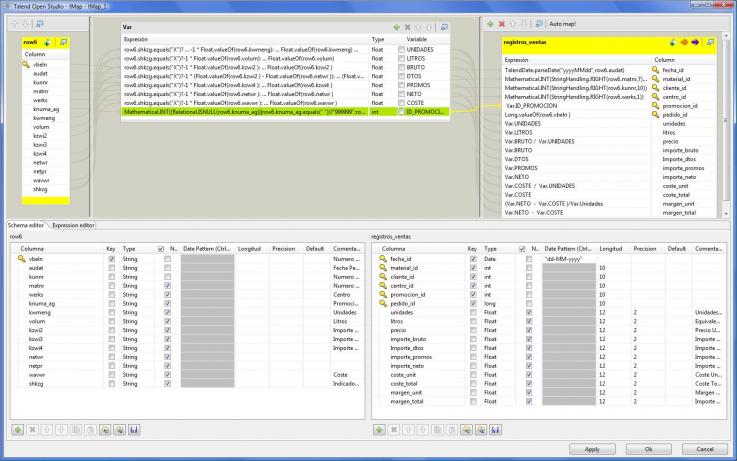
Transformaciones de los datos de pedidos antes de grabar en tabla Hechos
En este ejemplo, hemos utilizado un elemento nuevo del control tMap, que son las variables (ver la parte central superior). Las variables nos permiten trabajar de forma mas agil con los procesos de transformación, filtrado, conversión y luego se pueden utilizar para asignar a los valores de salida (o ser utilizadas en expresiones que las contengan).
Por ejemplo, observar que hemos creado la variable UNIDADES, y en ella hemos hecho un calculo utilizando elementos del lenguaje Java:
row6.shkzg.equals("X")?-1 * Float.valueOf(row6.kwmeng):Float.valueOf(row6.kwmeng)El campo SHKZG de los pedidos nos indica si un pedido es venta o abono. Por eso, si dicho campo tiene el valor X, hemos de convertir los importe a negativo. Observad también como luego utilizamos las variables definidas en la sección VAR en el mapeo de campos de salida.
Para los campos que son clave foranea de las correspondientes tablas de dimensiones (código de cliente, material, etc), hemos realizado las mismas transformaciones que realizamos cuando cargamos dichas tablas, para que todo quede de forma coherente y normalizada.
6) Inserción en la tabla de hechos y conclusión del proceso.
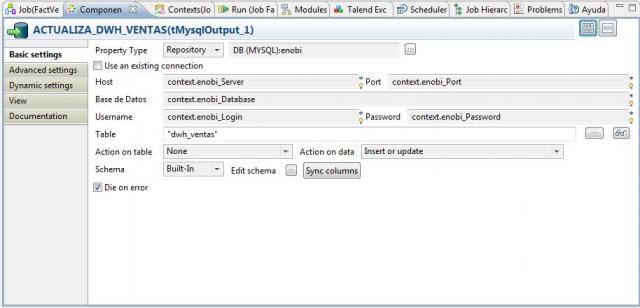
Como paso final, vamos realizando el insertado de los registros en la tabla DWH_VENTAS utilizando el componente tMysqlOutput (tal y como vemos en la imagen).
Una vez realizada toda la lectura de datos e inserción, concluiremos el proceso generando un mensaje de conclusión correcta del Job en la tabla de Logs con el paso MENSAJE_LOG_FIN (componente tipo tWarn).
Observad como hemos incluido, intercalados en los diferentes pasos del job, unos llamados VER_REGISTROS (del tipo tLogRow). Es un paso añadido para depuración y comprobación de los procesos (aparece en consola los valores de los registros que se van procesando). En el diseño definitivo del job estos pasos se podrían eliminar.
Para ver en detalle como hemos definido cada componente, podeís acceder a la documentación HTML completa generada por Talend aquí. Podeis descargaros el fichero zip que contiene dicha documentación aquí.
Conclusiones
Hemos terminado el desarrollo de todos los procesos de carga para llenar nuestro DW. Para cada una de las dimensiones y para la tabla de hechos, hemos construido un proceso con Talend para llenarlos. Como ultima actividad, nos quedaría combinar todos esos procesos para su ejecución conjunta y planificarlos para que la actualización del DW se produzca de forma regular y automatica.
Igualmente, veremos la forma de exportar los procesos en Talend para poder ejecutarlos independientemente de la herramienta gráfica (nos permitira llevar a cualquier sitio los procesos y ejecutarlos, pues al fin y al cabo es código java).
Todo esto lo veremos en la siguiente entrada del blog.
cuando los procesos utilizan
cuando los procesos utilizan cursores que elemento se deberia usar? estoy tratando de hacer un cursor que va generando variables que al final hacen un merge a la base. pero no he encontrado la manera de hacerlo desde el talend.
- Log in to post comments