Información, tips y utilidades sobre SQL Server Integration Services (SSIS)
Información, tips y utilidades sobre SQL Server Integration Services (SSIS) Dataprix Tue, 04/26/2022 - 12:45

Recopilación de dudas técnicas, consultas, tips y opiniones de SQL Server Analysis Services, motor de datos analíticos de Microsoft SQL Server.Recopilación de dudas técnicas, consultas, tips y opiniones de SQL Server Integration Services, la herramienta ETL de Integración de datos de Microsoft SQL Server.
Cambio del proyecto de modo implementación de paquetes a implementación de proyectos
Cambio del proyecto de modo implementación de paquetes a implementación de proyectos Carlos Tue, 12/27/2016 - 20:46Para cambiar el modo de implementación de paquetes a proyectos, y poder desplegar el proyecto en el catálogo IS de SQL Server se puede utilizar el asistente que se inicia fácilmente con un clic en el botón derecho sobre el proyecto, en el explorador de soluciones, y seleccionando la opción 'Convertir al modelo de implementación de proyectos'.
Es todo muy intuitivo menos, al menos para mi, el paso de seleccionar las configuraciones que se han de convertir. En mi caso utilizaba configuraciones para alimentar variables con valores almacenados en la tabla SSIS Configurations de SQL Server, y los paquetes que utilizaban estas configuraciones me salían con un estado 'No se puedo conectar con el servidor', error de inicio de sesión..
Este problema se soluciona con la opción 'Agregar configuraciones..', que permite volver a introducir los datos de conexión y 'leer' las configuraciones de la tabla SSIS Configurations. Se agrega una nueva configuración con el asistente para cada una de las que está en estado 'No se pudo conectar..' y después se seleccionan sólo las nuevas, que ya han de mostrar un estado 'Aceptar'.
Con esta acción se consigue pasar la validación, y el asistente ya puede realizar la conversión de los paquetes a modo proyecto, aunque el asistente en realidad no habilita la configuración en los paquetes, y si es necesario que las variables del package sigan recogiendo sus valores de los que se guardan en la tabla [SSIS Configurations] de la base de datos SQL Server, hay que habilitar después en cada paquete la configuración de paquetes, y agregar de nuevo las definiciones de configuraciones que se estaban utilizando en el modo de implementación de paquetes.
Como a partir de SSIS 2012 la tendencia es utilizar parámetros y variables de entorno en las implementaciones de proyecto, la opción de seguir utilizando configuraciones de paquetes en 'modo proyecto' está un poco escondida, pero se puede utilizar y funciona.
Para habilitar la configuración de paquetes a partir de SSIS 2012 hay que situarse en la pestaña de 'Flujo de control' y acceder a las propiedades haciendo click en la pantalla de fondo, o seleccionar propiedades después de hacer clic con el botón derecho. En la sección 'Varios' de propiedades del flujo del paquete la propiedad 'configurations' permite acceder al asistente para habilitar y crear configuraciones de paquetes. Después de habilitarlo, al crear una nueva configuración, si ya existía una configuración en la tabla [SSIS Configurations], el asistente lo detecta y permite reutilizarla.
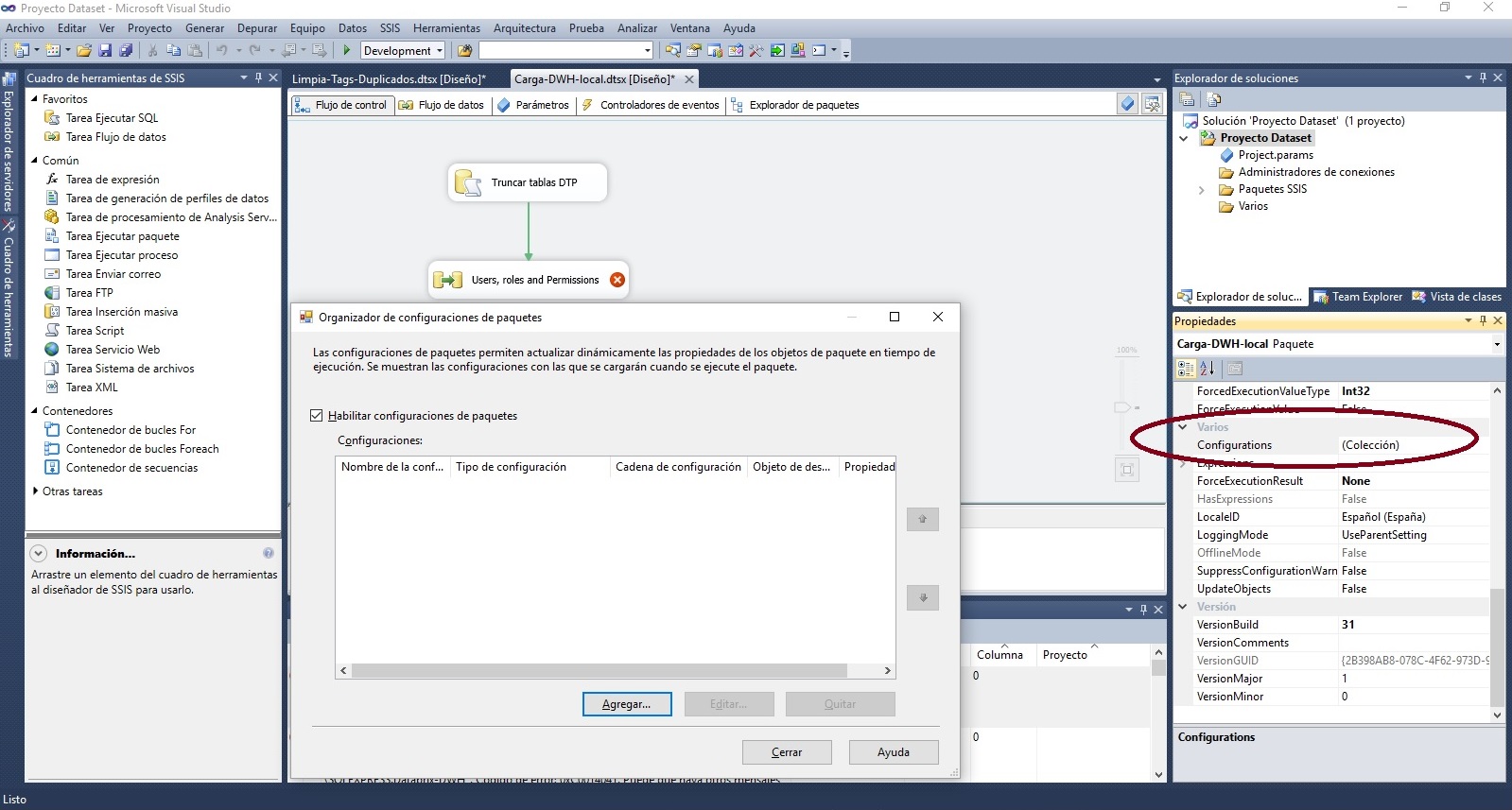
También habrá que revisar las variables del paquete, y cambiar la expresión que haya generado el asistente de conversión, que será algo así como '$Package::variable' por la variable de usuario, en este caso sería 'User::variable', y eliminar también los parámetros que el asistente genera, y que ya no se utilizarán porque se han cambiado por las variables de usuario que se alimentan ahora desde la tabla de configuración de SQL Server, [SSIS Configurations].
Carga masiva de ficheros
Carga masiva de ficheros roberto Fri, 05/22/2009 - 13:39Buenas,
tengo un problema con SSIS, estoy intentando hacer una carga sobre una tabla desde varios ficheros que tengo en un directorio pero me veo obligado a crear un origen de datos para cada fichero. El problema añadido es que los ficheros cambian de nombre segun la fecha, asi que el proceso no me sirve para posteriores cargas.
¿Hay alguna manera de definir un origen de datos que cargue todo el contenido de un directorio, o algun tipo de script que haga un union de los ficheros?
Gracias,
Roberto
Hola Roberto, a mi me paso lo
Hola Roberto,
a mi me paso lo mismo hace unas semanas, intentando hacer una carga en la que se veian involucrados varios ficheros con el mismo formato pero diferente nombre. Es algo habitual que recibas ficheros diariamente y que el sistema tenga que cargarlos sin tener que especificarle el nombre de fichero exacto.
Ya que no especificas la version, te digo lo que sé de la que yo estoy usando, SQLServer 2008.
En esta version me encontre con que el origen de tipo fichero plano te obliga a crear una conexion a fichero especificando el nombre exacto. Para hacer lo que quieres, previamente tienes que ir al panel Connection Managers (debajo del area de diseño) y crear una conexion a multiples ficheros. La conexion a multiples ficheros no esta disponible por defecto en el menu contextual, asi que tendras que ir por New Connection... y ahi te saldra una lista con todas las conexiones que acepta SSIS, seleccionas MULTIPLEFLATFILE y en el dialogo de configuracion si que te deja elegir directorio y multiples ficheros mediante mascara. Una vez hayas creado la conexion a multiples ficheros, añades el origen de datos a fichero plano en el diseñador y en vez de crear la conexion a un fichero con nombre exacto veras que tienes la conexion a multiples ficheros en la lista desplegable. La seleccionas, haces los mapeos y ya esta!
Espero que te haya servido.
- Log in to post comments
Conectar SSIS con MySQL como destino
Conectar SSIS con MySQL como destino estebi Tue, 05/19/2009 - 17:21Estoy intentando conectar desde SSIS con una base de datos MySQL como destino, para insertar datos, y no encuentro la manera de que funcione. He probado el OLEDB MySQL Provider y conecta, pero en lugar de mostrarme la BD que yo le indico, conecta con el Information_Schema de MySQL. Si pruebo igualmente a hacer algo me crea tablas, pero luego no las ve.
Alguien sabe cómo puedo hacer para cargar datos en MySQL sin problemas?
Prueba cambiando a un ODBC,
Prueba cambiando a un ODBC, ya sé que es antiguo pero funca.
- Log in to post comments

Il masacratore explica
Il masacratore explica bastante bien cómo hacerlo en el post SSIS: Solución a dos errores sin motivo aparente cuando insertamos datos en MySql.
Supongo que a estas alturas ya habrás encontrado la manera de hacer la inserción en MySQL desde SSIS o una alternativa, pero seguro que esta explicación ayuda a más gente.
- Log in to post comments
Consultas y comandos para controlar ejecuciones de packages del catálogo de SSIS
Consultas y comandos para controlar ejecuciones de packages del catálogo de SSIS Carlos Wed, 10/26/2016 - 19:53 Consultar las ejecuciones del catálogo de SSIS activas, y parar una ejecución
Consultar las ejecuciones del catálogo de SSIS activas, y parar una ejecución
Después de conectar a la base de datos del catálogo, para comprobar las ejecuciones que hay activas actualmente se puede ejecutar la siguiente query:
select * from catalog.executions where start_time is not null and end_time is null
En los resultados de esta consulta, el primer campo que podremos ver es el execution_id, que es el id de la ejecución del proceso, el mismo que podremos ver desde el entorno gráfico si consultamos las operaciones activas haciendo click con el botón derecho sobre la base de datos del catálogo, y seleccionamos la opción 'Operaciones activas'.
Desde el mismo entorno gráfico se puede utilizar el botón 'Detener' para parar una ejecución, aunque también se puede hacer con un comando de consulta utilizando el execution_id que ha salido en la consulta anterior (si, por ejemplo el id fuera 12345):
Exec catalog.stop_operation @operation_id = 12345
Consultar los mensajes de ejecuciones de paquetes del catálogo de SSIS
Query para consultar los mensajes de las ejecuciones de los paquetes (en este caso de la última ejecución realizada):
SELECT event_message_id,MESSAGE,package_name,event_name,message_source_name,package_path,execution_path,message_type,message_source_type
FROM (
SELECT em.*
FROM SSISDB.catalog.event_messages em
WHERE
em.operation_id = (SELECT MAX(execution_id) FROM SSISDB.catalog.executions)
AND event_name NOT LIKE '%Validate%'
)q
--WHERE --event_name = 'OnPostExecute' and
-- message like '%Finalizado%'and
-- package_name = 'Package.dtsx'
-- execution_path LIKE '%<ejecutable>%'
ORDER BY message_time DESCCómo utilizar Google Sheets como origen o destino de SSIS
Cómo utilizar Google Sheets como origen o destino de SSIS Carlos Wed, 09/04/2019 - 09:10 Se puede hacer descargando la API de Google, y creando un script para leer y escribir en una hoja de cálculo de Google Docs.
Se puede hacer descargando la API de Google, y creando un script para leer y escribir en una hoja de cálculo de Google Docs.
Enlazo los dos sitios que he encontrado sobre cómo hacerlo:
http://www.statslice.com/leveraging-google-docs-with-ssis
http://sqldeveloperramblings.blogspot.com.es/2010/06/ssis-google-spreadsheets-data-source.html
Otra opción más sencilla, pero de pago sería utilizar el componente que ha desarrollado cdata:
http://www.cdata.com/drivers/gsheets/ssis/
Error de SSIS al conectar con Excel ejecutando desde el catálogo
Error de SSIS al conectar con Excel ejecutando desde el catálogo Carlos Thu, 03/12/2020 - 21:20Al utilizar Excel como origen de datos en SSIS suele pasar que nuestro sistema es de 64 bits, y el conector de Excel que funciona aún es de 32 bits.
Desde Visual Studio en nuestra máquina cliente se suele solucionar marcando en las propiedades del proyecto que la ejecución se fuerce en 32 bits en lugar de 64, pero después puede pasar que despleguemos el paquete en un servidor SQL Server, y el conector no funcione.
Aunque lo ejecutemos igualmente en 32 bits, marcando en las propiedades avanzadas de la ejecución del paquete el check de '32-bit runtime', (o haciendo lo mismo en un job que lance el paquete si no queremos tener que marcar el check en cada ejecución), si el server no tiene el driver de 32 bits, que se suele instalar con las office, y en la máquina cliente sí solemos tener, el resultado suele ser un fallo en la ejecución.
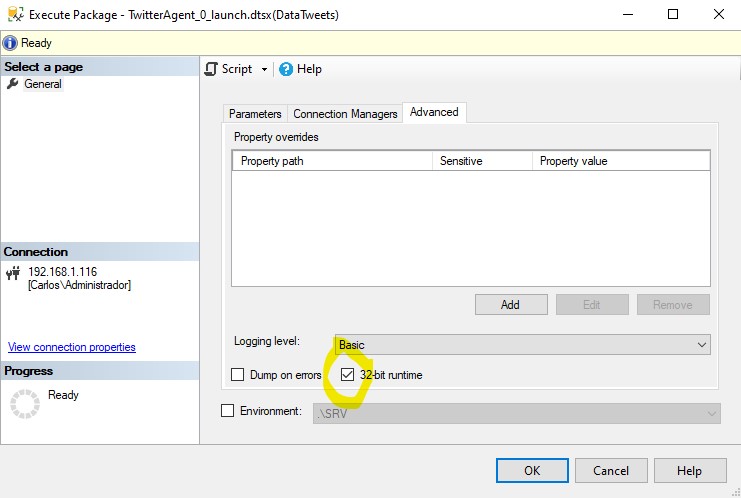
Este es el error que registra el catálogo:
Error: El proveedor OLE DB Microsoft.Jet.OLEDB.4.0 solicitado no está registrado. Si el controlador de 64 bits no está instalado, ejecute el paquete en modo de 32 bits
Si hemos hecho que paquete se ejecute en modo de 32 bits y a pesar de ello falla, entonces lo que tiene que faltar es el driver, así que normalmente la solución es tan sencilla como descargar de esta dirección de la página de descargas de Microsoft el componente redistribuible de 32 bits del motor de access y ejecutarlo en el servidor.
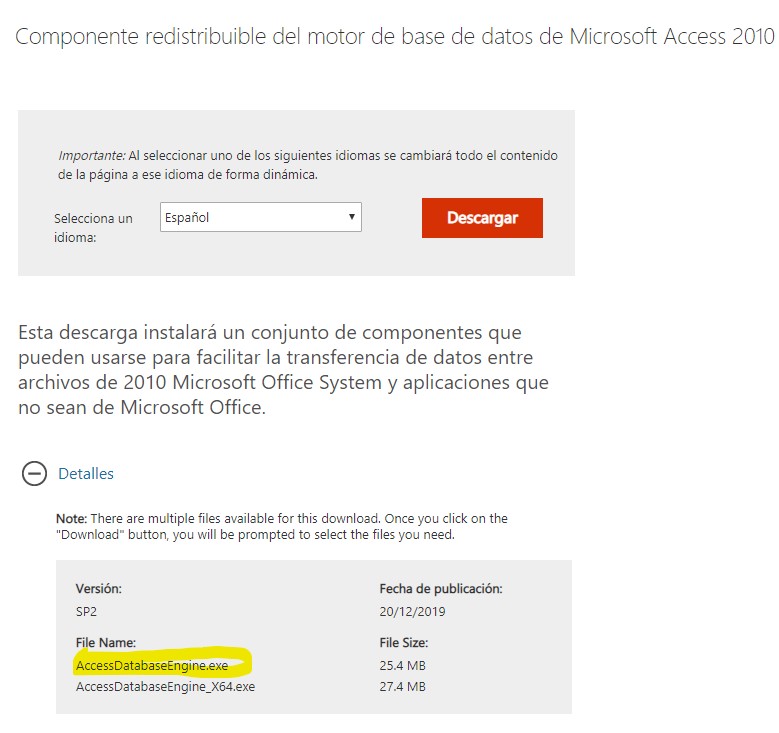
La otra solución es esperar a que Microsoft se decida a sacar un conector de 64 bits que funcione con Excel y Office, que este tema ya huele.. ;)
Error de memoria insuficiente en el buffer con SSIS
Error de memoria insuficiente en el buffer con SSIS estebi Tue, 09/08/2009 - 19:06Cuando ejecuto un flujo de SSIS me falla una tarea que se encarga de cargar una tabla a partir de los datos de otra. Se produce el siguiente error de memoria:
Hresult: 0x80004005 Description: "There is insufficient memory available in the buffer pool
La tabla es bastante grande, tiene más de 1 millón de filas. Supongo que será cuestión de tocar alguna variable o parámetro de memoria, pero no se dónde. Yo he probado a reducir los valores de DefaultBufferMaxRows, DefaultBufferSize y EngineThreads en las propiedades de la Task, pero sigo obteniendo el mismo error.
Puedo seguir probando a tocar estas cosas, pero si alguien sabe cómo solucionarlo le agradezco la ayuda.
Pues no tengo ni idea, pero
Pues no tengo ni idea, pero en Microsoft deberian hablar de ello, ya que me parece muy raro que te de un error de memoria solo por tener mas de 1 millón de filas.
Se supone que una ETL tiene que estar preparada para tratar estas cantidades de registros.
Has comentado los valores DefaultBufferMaxRows, DefaultBufferSize y EngineThreads, pero has probado "max server memory"?
Otra cosa, si trata el proceso de carga como una transaccion, ¿puedes evitarlo de alguna manera? para que no se coma el segmento de rollback.
Si lo solucionas ya nos avisaras!
Saludos!
- Log in to post comments
He ampliado el valor de
He ampliado el valor de DefaultBufferMaxRows al número de filas que tiene la tabla y por fin ha funcionado.
En el apartado Adjust the sizing of buffers del capítulo Improving the Performance of the Data Flow de la documentación online de MSDN explican que para calcular el tamaño del buffer que va a utilizar, el motor lo primero que hace (luego hace otros cálculos) es multiplicar el tamaño estimado de una fila por el valor de DefaultBufferMaxRows. Supongo que al ser el valor por defecto muy inferior al del número de filas, el buffer al final se quedaba corto.
Ya que he estado buscando información sobre este problema de memoria comparto dos enlaces que pueden resultar de ayuda:
- Documento de Microsoft sobre Resolución de problemas de rendimiento en SQL Server 2008
- Entrada MSSQL Error 802 - Insufficient memory available del foro de MonkeyClicker. Dan algunas recomendaciones, entre las que se encuentran la utilización del comando DBCC MEMORYSTATUS para controlar la memoria, y DBCC FREESYSTEMCACHE, DBCC FREESESSIONCACHE, DBCC FREEPROCCACHE para liberar las caches.
David, no he llegado a probar lo que comentas porque lo he podido solucionar antes, pero gracias por el soporte!
- Log in to post comments
Introduccion a la metodologia SQLBI
Introduccion a la metodologia SQLBI Dataprix Thu, 10/02/2008 - 00:26En SQLBI han preparado el primer borrador de un documento que propone una metodología para implementar soluciones de BI con las herramientas de la suite de Business Intelligence de Microsoft.
Aunque la metodología se enfoca hacia estas herramientas, los conceptos son extensibles a cualquier proyecto de BI. Esta es la traducción de los títulos principales del índice:
Introducción
Arquitectura de una solución de BI
Clasificación de soluciones de BI
Actores
Usuario / Cliente
Analista BI
Microsoft BI Suite
Arquitectura
Componentes de una solución de BI
La metodología de Kimball
Cuándo y porqué utilizar la metodología Kimball
La metodología Inmon
Cuándo y porqué utilizar la metodología Inmon
Construyendo la arquitectura
Diseñando los datos relacionales
Adjunto esta primera versión del documento, y espero que dentro de poco pueda actualizar el post con otra versión con nuevos capítulos..
Una vez publicada la
Una vez publicada la metodología, Alberto Ferrari y Marco Russo nos obsequian con el manual SQLBI Methodology at work, una aplicación práctica de la misma utilizando como base recursos que proporciona Microsoft para probar las funcionalidades BI de SQLServer:
- El package AWDataWarehouseRefresh
- Adventure Works DW
Los autores muestran como reconstruir la solución BI de Microsoft aplicando su propia metodología para obtener para obtener así otra versión de esta solución. No se atreven a decir que mejor que la original, eso tendremos que juzgarlo los que la probemos..
Traduzco a continuación el índice del documento:
Introducción
La imagen completa
El proceso de análisis
Análisis del paquete de ETL
Análisis de las vistas de orígenes de datos de SSAS
Utilización de esquemas
Base de datos del Data Warehouse
Área de análisis Financiera
Área de análisis Común
Área de análisis de Producción
Área de análisis de Ventas
Utilidad del Nivel del Data Warehouse
Base de datos espejo OLTP
Carga del espejo OLTP
Vistas del espejo OLTP
Base de datos de configuración
Configuración del Area de análisis de Ventas
Ficheros CSV transformados en tablas
Fase de ETL del Data Warehouse
Prestar atención a los planes compilados para las vistas
Valores Actuales/Históricos
Tipos de datos XML
Vistas de Data Mart
Fase de ETL de los Data Mart
Tratamiento de las Claves Subrogadas
Tratamiento de Valores Ficticios
Implementación de los cubos
Vista de Origen de Datos
Canal de Ventas
Promociones
Documentación del proyecto
- Log in to post comments
Ayuda - Jobs - SSIS -
Ayuda - Jobs - SSIS - jatb Wed, 07/17/2013 - 17:41Hola con todos,
Tengo el siguiente caso:
Mi carga de datos esta hecha en DTS 2000 y estamos en la migracion a SSIS, con el programa DTS Backup 2000 los migre a SSIS hasta aquí todo perfecto.
Cree las tareas dentro del paquete de SSIS lo ejecuto manualmente el resultado es ok.
El paquete lo guardo Package Collection SQL Server, pongo el servidor en la opcion de Proetction Level Do not save sensitive data, voy al Management studio me conecto a Integratios Services y en la carpeta MSDB esta el paquete le doy click derecho run package y el estado de finalizacion es ok.
Cuando creo el job me da el siguiente error al momento de ejecutar:
Porque se pierde la conexión al momento de crear el JOB, cuál puede ser una posible solución ?
Error: 2013-07-17 10:12:12.01 Code: 0xC0202009 Source: XXXX Connection manager "XXX" Description: SSIS Error Code DTS_E_OLEDBERROR. An OLE DB error has occurred. Error code: 0x80004005. An OLE DB record is available. Source: "Microsoft OLE DB Provider for ODBC Drivers" Hresult: 0x80004005 Description: "[Microsoft][ODBC Driver Manager] Data source name not found and no default driver specified". End Error Error: 2013-07-17 10:12:12.01 Code: 0xC020801C Source: Data Flow Task OLE DB Source [1] Description: SSIS Error Code DTS_E_CANNOTACQUIRECONNECTIONFROMCONNECTIONMANAGER. The AcquireConnection method call to the connection manager "XX" failed with error code 0xC0202009. There may be error messages posted before this with more information on why the AcquireConnection method call failed. End Error Error: 2013-07-17 10:12:12.01 Code: 0xC0047017 Source: Data Flow Task SSIS.Pipeline Description: component "OLE DB Source" (1) failed validation and returned error code 0xC020801C. End Error Error: 2013-07-17 10:12:12.01 Code: 0xC004700C Source: Data Flow Task SSIS.Pipeline Description: One or more component failed validation. End Error Error: 2013-07-17 10:12:12.01 Code: 0xC0024107 Source: Data Flow Task Description: There were errors during task validation. End Error DTExec: The package execution returned DTSER_FAILURE (1). Started: 10:12:11 AM Finished: 10:12:12 AM Elapsed: 0.281 seconds. The package execution failed. The step failed.
La conexión que da el error es la migrada de DB2, realice el mismo ejercicio pero solo con la conexión a sql y el resultado es ok.
Ahora al crear un new datasource , provider Native OLD BE\Micro... for DB2.
Existen algunos campos Initial Catalog, package collection y defautl schema, que debe ir ahi como obtengo esa información?
En la pestaña Advance existe DBM2 plataform, Host CCSID y PC code page que es otra duda que tengo.
Hola Jatb. El problema es la
- Log in to post comments
Carga lenta Desde AS400
Carga lenta Desde AS400 jatb Sat, 03/09/2013 - 00:55
Hola Jonathan Supongo que ya
Hola Jonathan
Supongo que ya habréis hecho pruebas, pero me parece una diferencia demasiado grande para venga sólo por el cambio de versión de DTS a SSIS. Yo antes que nada me aseguraría de que no hay algún factor más que os ralentiza esta carga, como saturación de las bases de datos, espacio, bloqueos..
De la parte de SSIS tampoco tengo gran experiencia, pero yo revisaría sobretodo los parámetros de carga, asegurándome de que estuvieran orientados a cargas masivas, sin validaciones ni transformaciones, y utilizando el máximo de memoria posible. Según cómo lo hagas suele ser la opción 'Fast Load', y revisar las opciones 'FastLoadOptions'.
Te enlazo el post Using SQL Server Integration Services to Bulk Load Data, que comenta bastante detalladamente tres métodos de carga que podrías probar. Si has utilizado OLE DB, por ejemplo, si la revisión de parámetros no te funciona, puedes probar con el componente SQL Server Destination, que según el artículo permite definir propiedades como BATCHSIZE=0 para realizar toda la carga en un solo batch.
You might have noticed that the Advanced screen does not include any options related to batch sizes. SSIS handles batch sizes differently from other batch-loading options. By default, SSIS creates one batch per pipeline buffer and commits that batch when it flushes the buffer. You can override this behavior by modifying the Maximum Insert Commit Size property in the SQL Server Destination advanced editor. You access the editor by right-clicking the component and then clicking Show Advanced Editor. On the Component Properties tab, modify the property with the desired setting:
- A setting of 0 means the entire batch is committed in one large batch. This is the same as the BULK INSERT option of BATCHSIZE = 0.
- A setting less than the buffer size but greater than 0 means that the rows are committed whenever the number is reached and also at the end of each buffer.
- A setting greater than the buffer size is ignored. (The only way to work with batch sizes larger than the current buffer size is to modify the buffer size itself, which is done in the data flow properties.)
Espero que te sea de ayuda,
- Log in to post comments
Gracias Carlos, Lei el
Gracias Carlos,
Lei el articulo que me has dicho, pero esto es mas orientado a archivos planos o conexiones entre bases sql, pero de as400 a sql server no sirve.
Te cuento un poco mas para hacer la conexion utilizo el proivder: IBM DB2 UDB for iSeries IBMDA400 OLE DB Provider, al hacer test me da ok, dentro del OLE DB Source utilizo esta conexion compartida y ingreso SQL command y pongo en preview y me muestra la data, esto le uno al OLE DB Destination utilizando la propieda fast load, mapeo los datos y previwe y todo ok.
Cuando mando ejecutar el contenderon me trae un promedio de 20000 por minuto que es un tiempo alto ya que en el DTS 2000 en 2 minutos ya trae los 7mil registros.
Para la tranfornmacion de datos e utilizado Multicast, Derived Column, entre otros pero la respuesta es igual de lenta.
Los epsacios en discos y lo relacionado con la bdd esta muy bien.
Espero alguien me ayude.
Saludos
- Log in to post comments
Bueno, te sirve toda la parte
Bueno, te sirve toda la parte de configuración de los componentes destino, OLE DB o SQL Server Destination. Si no has encontrado nada que ya no hayas probado ya es otra cosa.
Otra cosa que puedes hacer es separar la importación de datos de las transformaciones, es decir, hacer una carga directa desde OLE DB Source a OLE DB Destination, que puedes dejar en una tabla temporal de SQL Server. Después haces todas las transformaciones desde la tabla temporal hacia la definitiva, así separas entornos y seguro que lo tienes más fácil para localizar el 'cuello de botella'.
- Log in to post comments
La manera que solucione no
La manera que solucione no se si es la adecuada es con el uso de tablas vinculadas con access, con esto la respuesta fue la misma que trabajar con DTS del 2000.
Es sorprendente que una version 8 años mas a ctual sea 100% mas lenta la carga desde as400.
Saludos
- Log in to post comments
A mi me ha pasado varias
A mi me ha pasado varias veces que he intentado hacer algo utilizando los componentes de SSIS para que sea más fácil de mantener, y al final, por la manera en que Integration Services trata el flujo de datos, prácticamente registro a registro, para que la carga no se haga eterna he terminado por eliminar los componentes y hacer la mayor parte del 'trabajo' con llamadas a sentencias SQL.
De todas maneras para una simple importación de datos no tendrían que pasar estas cosas, es muy fuerte que te funcione mejor con tablas vinculadas con access, y espero que al menos el problema sea sólo al importar desde AS400, algún bug en el driver o algo así..
Muchas gracias por compartir la solución, y me alegro de que al menos hayas podido solventar el problema de lentitud, aunque haya sido 'tirando de Access' :)
- Log in to post comments
Conexiones Oracle en DTSx. Solución.
Conexiones Oracle en DTSx. Solución. josimac Thu, 08/02/2012 - 16:36Un problema bastante común cuando realizamos un proyecto que tiene lectura y/o escritura desde una dts a un oracle, es que cuando se crea un job de ejecución se pierde el password de acceso a oracle.
Una solución a esto es editar las conexiones del paquete dentro del job y ponerle a mano el password. El problema es que cada vez que cambiamos la dts se tiene que hacer lo mismo.
La solución definitiva ha esto es crear una variable de tipo string en el paquete que contiene la cadena de conexión completa.
Dicha cadena sería:
"Data Source=;User ID=;Provider=OraOLEDB.Oracle.1;Persist Security Info=True;Password=;"
Una vez hecho esto, hay que entrar en la propiedades de la conexión en el "Connection Manager" (parte inferior de la dts) y añadir una expresión clicando con el ratón en la elipse.
Añadir una expresión de tipo "ConnectionString" y arrastar en el diálogo la varible que hemos rellenado antes.
Ya está. Saludos!
Licencias de SQL Server
Licencias de SQL Server stbanti Tue, 08/11/2009 - 18:46Hola a todos
Me estoy planteando un proyecto empresarial que va tener como base tecnológica una base de datos, procesos de integración (ETL), y puede que alguna cosa de Business Intelligence.
De las opciones disponibles me gusta bastante SQL Server porque ya viene con SSIS y Analysis Services, y encuentro Integration Services muy manejable.
De cara a las licencias necesitaría un servidor de base de datos y 2 usuarios de acceso, que trabajarían desde clientes Windows. He buscado información sobre licencias para ir preparando mis previsiones, pero no sé si me aclaro bien. Lo que me ha parecido entender es que necesito una licencia para el server y dos para los clientes (CALs). Lo que pasa es que sólo he encontrado un precio para una SQLServer Standard Edition de unos 6.000 $ por procesador (para USA). Supongo que debe haber otro licenciamiento a nivel de usuario más económico, ya que yo sólo voy a necesitar que la utilicen 2 usuarios.
Alguien me puede decir donde encontrarlo, o cuánto me podría costar todo el montaje? Tampoco tengo claro como funcionan los upgrades o el coste de mantenimiento anual una vez adquirida la licencia inicial.
Gracias por anticipado,
sobre las licencias de SQL
sobre las licencias de SQL Server, te cuento que cuando compras compras la ultima version
en este momento seria SQL Server 2008 standart, sale alrededor de U$S 780 en argentina
necesitarias tambein 2 cal por usuario que salen U$S168 cada una, con esto te bastaria
para lo que necesitas. El modo de licenciamiento de microsoft no es anual, por lo que al comprar la
licencia no necesitarias pagar nada mas, los upgrade de version te salen casi como comprar
la version nueva, pero los service pack son sin costo.
saludos
- Log in to post comments
Necesito Agregar Componentes de Auditar/MAIL en Proceso de ETL
Necesito Agregar Componentes de Auditar/MAIL en Proceso de ETL alfonsocutro Sat, 01/18/2014 - 18:18Buenas esta vez, necesito una ayuda bastante basica, pero como soy novato en el mundo SQLServer todo medio complejo.
Estoy haciendo un Proyecto BI relacionado con un Banco y donde estoy en la etapa de ETL (inicial) c/SISS de AS/400 a SQLServer 2012
Resulta que traigo todas las tablas de intervinientes del Ambiente de AS/400 a SQLServer.
Hasta ahora marcha todo bien, pero estoy necesitando tener todo auditado (hora de inicio, hora de fin, etc) y ademas quiero que dispare algún mail (caso de tener algún inconveniente que envie un mail a los responsables del proceso de ETL).
Bueno era eso no mas. Disculpen
Para la auditoría, si te
Para la auditoría, si te creas un flujo de datos, dentro de las transformaciones de flujo de datos que puedes utilizar,
en el cuadro de herramientas, tienes la transformación que se llama 'Auditoría', que supongo que es la que comentas, y que puedes utilizar para añadir al flujo de datos campos de información como hora de ejecución, nombre del usuario, del equipo, de la tarea.. Luego guardas lo que te interese en un campo de la tabla destino y ya lo tienes.
Otra opción es utilizar la transformación 'Columna derivada' y añadir en la misma un campo que calcule lo que
quieras registrar, como por ejemplo la función 'GETDATE()' para calcular la fecha y hora actual.
Para enviar un email si el proceso va bien o mal, entre los elementos del flujo de control hay una tarea 'Tarea enviar correo',
pero es demasiado simple, y sólo te funcionará en determinadas condiciones. Yo cuando lo implementé al final utilicé una
'Tarea script' que ejecutaba un código de visual basic (.vb) para hacer el envío de un email utilizando el objeto 'SmtpClient'.
Esta tarea se puede ejecutar al final del flujo de control para el caso de que todo vaya bien, y también puedes llamar
a la misma tarea, o a otra del mismo tipo, una vez creada, desde el evento OnError del controlador de eventos (pestaña 'Controladores de eventos').
Espero haberte aclarado algo..
- Log in to post comments

muchisimas Gracias
muchisimas Gracias CARLOS!!!!
Vamos a ver como continua este Proceso de ETL.
Estamos en contacto.
- Log in to post comments
Carlos: Ya logre mejorar un
Carlos:
Ya logre mejorar un 80 % del Proyecto -->(Paquete SISS)
Colocando en comienzo y en al fin del Flujo de Datos la función "GETDATE()" para calcular las respectivas fechas.
Las mismas se almacenan en una Tabla donde esta toda esa data.
Me estaría faltando rescatar esos datos para mandarlos por el Conector de manda MAIL.
Seguramente hay muchas formas de hacer este Proceso, asi que escucho Mejoras!!!!!
Saludos y Muchas Gracias Carlos (x ayudarme nueva//)
Saludos!!!!
- Log in to post comments
Lo que hago yo para llevar
Lo que hago yo para llevar una auditoria para cuando falla o tiene problemas alguna tarea es lo siguiente:
1- Tengo una tabla de eventos en la cual almaceno toda la información que relevante a la ejecución del packages y del error específicamente
PERIODO
FEC_ERROR
SECUENCIA
PACKAGES
ERROR
HOST
STARTTIME
ENDTIME
2- Luego tengo 3 Tareas ScriptSQL
CAPTURA ERROR (PASO1)
LIMPIA ERROR (PASO 2)
INGRESA ERROR (PASO 3)
- Log in to post comments
Problema al ejecutar un paquete SSIS desde un proyecto del catálogo de Integration Services de SQLServer
Problema al ejecutar un paquete SSIS desde un proyecto del catálogo de Integration Services de SQLServer Carlos Thu, 06/16/2016 - 13:08 Recientemente he llevado a cabo una migración de un proyecto de SSIS 2008 a SSIS 2010 fruto de una migración de un servidor SQL Server 2008 R2 a un SQL Server 2012.
Recientemente he llevado a cabo una migración de un proyecto de SSIS 2008 a SSIS 2010 fruto de una migración de un servidor SQL Server 2008 R2 a un SQL Server 2012.
En primera instancia, tras el proceso de migración y hacer algunos ajustes, todo funcionó correctamente, y todos los paquetes se ejecutaban sin problemas, tanto desde el entorno IDE de Integracion Services, SQL Server Data Tools, como si se programaba su ejecución desde el agente de SQL Server.
Para aprovechar las nuevas características de SQL Server 2012, el siguiente paso fue la conversión de las conexiones de cada paquete a conexiones globales, y cargar el proyecto y los paquetes dentro del catálogo de Integration Services de la nueva base de datos, y configurar un entorno de producción y otro de desarrollo dentro del mismo catálogo para poder así lanzar los mismos procesos en uno u otro entorno de una manera flexible y bien controlada, un gran avance de esta versión de SSIS.
Todo bien menos un problema que surge al programar la ejecución de los paquetes del catálogo desde el agente de SQL Server. La ejecución de los paquetes se lanza correctamente, pero uno de ellos siempre produce una excepción devolviendo un error de memoria. No es problema de la llamada desde el agente porque este paquete en realidad se llama desde otro paquete, que es el que ejecuta el job del agente, y los otros packages a los que llama se ejecutan sin problemas.
Lo más extraño es que este error sólo se produce en la ejecución desde el catálogo de IS de la base de datos, pero si se ejecuta el mismo paquete desde SQL Server Data Tools, tanto directamente como llamándolo desde el otro package, el paquete se ejecuta con normalidad, no devuelve ningún error, y hace todo lo que tiene que hacer.
Es verdad que este package es uno de los que maneja mayor volumen de datos, y por eso en algún punto debe tener algún problema de memoria que lo hace fallar al ejecutarlo desde el catálogo, pero debería funcionar igual desde ambos entornos, no?
¿Alguien se ha encontrado algún problema parecido? ¿Puede ser algún problema de configuración de la base de datos o del entorno de ejecución?
El error de overflow de
El error de overflow de memoria se puede solucionar configurando los componentes para utilizar buffers de memoria en lugar de utilizar la opción por defecto que no los utiliza, y para más seguridad se puede definir un fichero donde almacenar la caché si la memoria llega a su límite, pero lo raro sigue siendo que con SQL Server 2008 no hubiera ningún problema, y con SQL Server 2012 surjan estos problemas con la gestión de la memoria.
Además me he encontrado otro cliente al que le ha pasado lo mismo al pasar de 2008 a 2012. ¿Alguien sabe si es un problema de la versión, o si no es un problema sino que la gestión de memoria se ha de llevar de otra manera?
¿A alguien le ha pasado lo mismo con SQL Server 2014 o 2016?
- Log in to post comments
Problema con los parámetros de un origen de flujo de datos OLEDB
Problema con los parámetros de un origen de flujo de datos OLEDB Carlos Mon, 05/05/2014 - 23:24Estoy preparando una carga de un Data Warehouse con Integration Services de un SQL Server 2008, y me he encontrado un problema con los parámetros de un origen de flujo de datos OLEDB de SSIS que no he podido resolver, yo le veo pinta de bug, pero lo planteo aquí por si alguien también se lo ha encontrado y me puede iluminar.
En una tarea de flujo de datos, tengo el origen de flujo de datos de OLEDB definido con una select que incluye un parámetro, que es el valor de una variable FechaActual de tipo DateTime, y que en el proceso de carga contiene la fecha actual.
La tabla sobre la que se ejecuta la consulta contiene registros con fechas hasta el día actual, y la sentencia select del origen es la siguiente:
select * from ax_almacenlote where DATEDIFF(day,max_createddatetime,?)=0 or DATEDIFF(day,max_modifieddatetime,?)=0
El resultado esperado serían los registros de esta tabla con fecha de creación o modificación a día de hoy (FechaActual), pero, aunque he comprobado que los registros existen, el flujo de datos no devuelve ningún registro.
Lo más curioso es que después de hacer un montón de pruebas me doy cuenta de que si le añado 2 días a la comparación de fechas obtengo el resultado que esperaba, es decir, los registros creados o modificados en el día actual. Esta sería la Select que me saca estos registros:
select * from ax_almacenlote where DATEDIFF(day,max_createddatetime,?)<3 or DATEDIFF(day,max_modifieddatetime,?)<3
Curioso no? Alguien me puede explicar porqué hay que añadir 2 días para que funcione esta comparación de fechas? Yo no le encuentro la lógica.
Para asegurarme de que no es un tema de la base de datos, o de la consulta, he capturado las queries que se generan en SQL Server, y los resultados siguen indicando que el problema está en la parte de Integration Services. Estas son las queries de cada caso:
Primero, esta es la consulta de base de datos que he intentado parametrizar y que, poniénle la fecha actual donde va el parámetro de SSIS devuelve correctamente los registros creados o modificados en el día actual, a la consulta o a los datos no se les puede echar la culpa:
select * from ax_almacenlote where DATEDIFF(day,max_createddatetime,getdate())=0 or DATEDIFF(day,max_modifieddatetime,getdate())=0
Después, al ejecutar el proceso con la consulta inicial en el origen OLEDB, la que no devuelve nada, la base de datos muestra esta select:
select * from ax_almacenlote where DATEDIFF(day,max_createddatetime,@P1)=0 or DATEDIFF(day,max_modifieddatetime,@P2)=0
Finalmente, al añadir los dos días a la comparación para que el flujo retorne los datos del día actual, esta es la sentencia SQL que muestra la base de datos como ejecutada:
select * from ax_almacenlote where DATEDIFF(day,max_createddatetime,@P1)<3 or DATEDIFF(day,max_modifieddatetime,@P2)<3
Si alguien lo entiene le agradezco que me lo explique porque yo no le veo ningún sentido.
Puede ser porque el formato
Puede ser porque el formato de fecha que está enviando a la select está girada porque la envia en formato texto.
Por ejemplo:
En mi caso, si hago un "select getdate()" me devuelve: "09/05/14 18:13:23"
Acto seguido, ejecuto la select tuya con lo que me devuelve el getdate():
select * from entidades where DATEDIFF(day,comodin10,'09/05/14 18:13:23')=0
El resultadoes un frustrante "0 Rows"
Pero si giras el mes y el año devuelve los registros que tiene que devolver:
select * from entidades where DATEDIFF(day,comodin10,'05/09/14 18:13:23')=0
Resultado "698 Rows"
- Log in to post comments
Vale, seguro que los tiros
Vale, seguro que los tiros van por ahí, pero a mi la select ejecutada directamente contra la base de datos me devuelve los registros que espero, la select ya está bien para el formato de fecha que utiliza la base de datos.
¿Puede ser que SSIS o el driver de OLEDB cambien el formato de la fecha?
- Log in to post comments
Podría ser. Para asegurarte
Podría ser. Para asegurarte de que el formato de fecha es el que esperas puedes probar a especificarlo, en la base de datos, o mejor en el componente, antes de la select. Algo así:
set dateformat dmy; declare @fecha datetime set @fecha = getdate() select * from Mitabla where DATEDIFF(day,CampoDeFecha,@fecha)=0
- Log in to post comments
Problema en el exceso de caracteres en la expresion de flujo de datos
Problema en el exceso de caracteres en la expresion de flujo de datos Anonymous (not verified) Fri, 12/11/2009 - 21:45Tengo un mega Query que necesito poner en la expresion de flujo de datos, pero pasa el limite de 4000 caracteres ya intente de 1000 usando variables. que se podria hacer??
Seguro que una query tan
Seguro que una query tan grande no la puedes partir, aunque sea utilizando tablas temporales intermedias? Así también tendrías más controlado lo que haces, porque normalmente meter mano y mantener consultas de estas proporciones suele ser complicado.
Otra opción sería utilizar un fichero para almacenar la query. No lo he probado, pero el SQLSourceType te permite seleccionarlo con el tipo File connection.
También, según lo que tengas que hacer, podr&ias crear un procedimiento almacenado en la base de datos, meter dentro la consulta, y llamar al procedure desde SSIS.
- Log in to post comments
Utilizar SSIS o DTS para trabajar con BBDD Oracle
Utilizar SSIS o DTS para trabajar con BBDD Oracle Carlos Sun, 08/01/2010 - 11:24Abro este tema para comentar cuestiones sobre conexiones de DTS o SQL Server Integration Services que utilicen como origen de datos una base de datos Oracle para recoger datos, ejecutar procesos, etc.
Sabes tengo rutinas en
Sabes tengo rutinas en SQLServer 2005 DTS que levantan bastos, pero necesito automatizar la ejecución.
Ya que actualmente se ejecuta cuando nos llega un correo de confirmacion donde otras rutinas han terminado.
La ejecución es manual,manualmente ejecuto el dts
Soy nueva en Oracle.
Por fa como podria automatizarlo?
- Log in to post comments
Tendrás que explicármelo
Tendrás que explicármelo mejor. Por lo que he entendido lanzas manualmente procesos de DTS que atacan una BD Oracle, y quieres que se ejecuten automáticamente cuando llegue un mail.
Eso deberías hacerlo desde el mismo DTS, no?
- Log in to post comments
Es justo lo que quisiera
Es justo lo que quisiera saber, como puedo hacer para que un DTS se ejecute cuando llegue un correo o cuando una tabla en BD Oracle esté actualizado a la fecha del día.
- Log in to post comments
No sé mucho de DTS, pero se
No sé mucho de DTS, pero se me ocurre que podrías Planificar el package DTS para ejecución para que se lanzara cada cierto tiempo, y dentro de tu package agregar una tarea que consultara el valor de la tabla de Oracle, y ejecutara las tareas que ya tienes preparadas sólo si se cumpliera la condición de la expresión que tendrías que definir en función de la fecha.
Supongo que debe haber otras soluciones más elegantes con manejadores de eventos y similares, pero esta seguro que te funciona sin complicarte mucho.
- Log in to post comments
ssis etl script
ssis etl script diego_m180 Fri, 02/08/2013 - 18:15tengo un problema, cree un etl pero ahora quiero hacer un script o algo similar para que el que lo quiera ejecutar no tenga que entrar a la herramienta y poner el botón play, si me pudiesen dar los pasos de como hacer eso lo agradecería.
Hola diego_m180, entiendo
Hola diego_m180, entiendo que tienes un paquete DTS diseñado en SSIS y quieres que se pueda ejecutar como un aplicativo. Si es así te propongo que generes un archivo .bat en el cual utilizes la utilidad dtexec, que se utiliza para configurar y ejecutar paquetes de SQL Server Integration Service. Tienes más información aquí.
- Log in to post comments