
A simple definition of Regression-
Regression is a type of visionary displaying method which researches the connection between a needy (target) and free factor (s) (indicator). This procedure is utilized for determining, time series analysis and finding the causal impact connection between the respective factors.
The below image shows you the regression line.
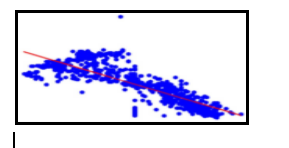
In all actuality, there are countless types of Regression, which can be performed. Each structure has its own significance and a particular condition where they are most appropriate to apply. Here we will study the four most wanted types of regression methods used in data science.
1- Simple Linear Regression
Simple linear regression is utilized to discover the best connection between a solitary data variable (indicator, free factor, input highlight, input boundary) and yield variable (anticipated, subordinate variable, yield include, yield boundary) given that the two factors are nonstop in nature. This relationship addresses how a data variable is identified with the yield variable and how it is addressed by a straight line.
Below scatter plot gives a graphical portrayal of the relationship of two continuous vectors.
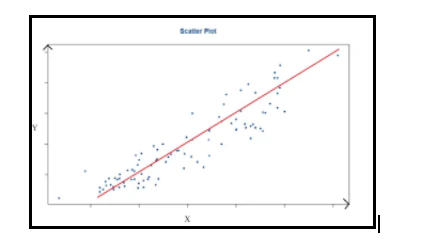
With this fig, you can get an idea about three terms
A.The direction
B.The strength
C. The linearity
The above qualities are between factor Y and variable X. The above disperse plot shows us that variable Y and variable X have a solid positive direct relationship. Consequently, we can project a straight line that can characterize the data in the most precise manner conceivable.
In the event that the connection between factor X and variable Y is solid and straight, at that point we presume that specific autonomous variable X is the compelling info variable to foresee subordinate variable Y.
To check the collinearity between factor X and variable Y, we have a connection coefficient (r), which will give you a mathematical estimation of the relationship between's two factors. You can have a solid, moderate, or frail relationship between's two factors. Higher the estimation of "r", higher the inclination is given for specific info variable X for foreseeing yield variable Y. Hardly any properties of "r" are recorded as follows:
-
Range of r: -1 to +1
-
Perfect positive relationship: +1
-
Perfect negative relationship: -1
-
No Linear relationship: 0
-
Strong correlation: r > 0.85 (depends on business scenario)
> cor(X, Y)
where, X: autonomous variable and Y: subordinate variable Now, on the off chance that the aftereffect of the above order is more noteworthy than 0.85, at that point pick straightforward direct relapse.
On the off chance that r < 0.85, at that point use change of information to expand the estimation of "r" and afterward assemble a basic straight relapse model on changed information.
Steps to Implement Simple Linear Regression:
1- Examine information (investigate dissipate plot for linearity)
2- Get test information for model structure
3-At that point plan a model that clarifies the information
What's more, utilize a similar created model in the general populace to make forecasts.
The condition that addresses how a free factor X is identified with a reliant variable Y.
2- Logistic Regression
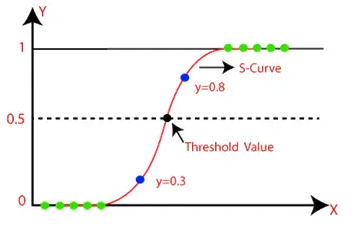
Logistic Regression is one of the AI calculations utilized for tackling grouping issues. It is utilized to gauge the likelihood if an occasion has a place with a class. In the event that the assessed likelihood is more prominent than an edge, at that point, the model predicts that the case has a place with that class, or, in all likelihood, it predicts that it doesn't have a place with the class as demonstrated in fig 1. This makes it a parallel classifier. Strategic relapse is utilized where the estimation of the reliant variable is 0/1, valid/bogus, or yes/no.
3- Ridge Regression
Ridge Regression is a procedure utilized when the information experiences multicollinearity (free factors are exceptionally related). In multicollinearity, despite the fact that the least-squares gauges (OLS) are fair, their differences are huge which strays the noticed an incentive a long way from the genuine worth. By adding a level of predisposition to the relapse gauges, edge relapse lessens the standard blunders.
Edge relapse tackles the multicollinearity issue through shrinkage boundary λ (lambda). Take a gander at the condition beneath.
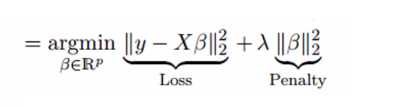
In this condition, we have two segments. The initial one is a least-square term and another one is lambda of the summation of β2 (beta-square) where β is the coefficient. This is added to the least-square term to contract the boundary to have an extremely low difference.
4- Lasso Regression
This regularization procedure performs L1 regularization. In contrast to Ridge Regression, it changes the RSS by adding the punishment (shrinkage amount) comparable to the amount of the outright estimation of coefficients.
Taking a gander at the condition beneath, we can see that like Ridge Regression, Lasso (Least Absolute Shrinkage and Selection Operator) likewise punishes the supreme size of the relapse coefficients. Likewise, it is very equipped for decreasing the fluctuation and improving the precision of direct relapse models.
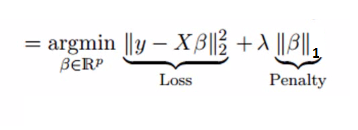
This regression contrasts from Ridge Regression such that it utilizes total qualities inside the punishment work, as opposed to that of squares. This prompts punishing (or proportionately obliging the amount of the supreme estimations of the assessments) values which causes a portion of the boundary appraisals to turn out precisely zero. The more punishment is applied, the more the appraisals get contracted towards a total zero. This serves to variable determination out of the given scope of n factors.
Final Words
These regression procedures ought to be applied thinking about the states of information. A standout amongst another stunt to discover which strategy to utilize is by checking the group of factors for example discrete or ceaseless.
If are interested in finding detailed information about the above topics with examples do visit here.
