
Introducción
El post se divide en la interpretacion de los datos de entrada, el analisis de sus resultados y la extracción de reglas de negocio a lo largo del mismo. Por último se elaboran las conclusiones pero sientase libres realizar las propias. Sin duda, es un tema que requiere de mucho tiempo, sobretodo para el desarrollo de un buen modelo de Clustering, como no es objetivo del Post explicar la realización del mismo, al final hay un link para mas información (Ref. 1)
| Este caso es solo una ejemplificación muy resumida de la realidad, que pretende mostrar didacticamente como pueden extraerse algunas conclusiones con herramientas visuales de un modelo ya realizado. Seguramente pueden hallarse muchas más conclusiones... solo es cuestion de seguir los datos con el objetivo que deseen... |
Acerca de los datos
Los datos ficticios analizados son de comportamiento bancario, en donde la cantidad de casos son poco más de 800, y cada uno representa una cuenta. Los mismos se encuentran disponibles para su descarga.
| Las columnas (o variables) de cada cuenta son las siguientes: ● Edad: edad del titular de la cuenta ● Prom_Cant_compra_por_Mes: promedio de la cantidad de compras que realiza por mes ● Prom_Monto_compra_por_mes: promedio del monto en u$s que gasta por mes ● Limite_Credito: límite de crédito que posee para gastar ● Ingreso_Mensual: ingreso de u$s mensuales a la cuenta ● Antiguedad: antiguedad desde la apertura de la cuenta ● Cant_Compras: cantidad de compras totales que realizo desde que la cuenta está activa ● Total_Monto_compra: total de u$s que compró desde que se abrió la cuenta ● Cluster: Es el cluster o segmento que el modelo data mining generó |
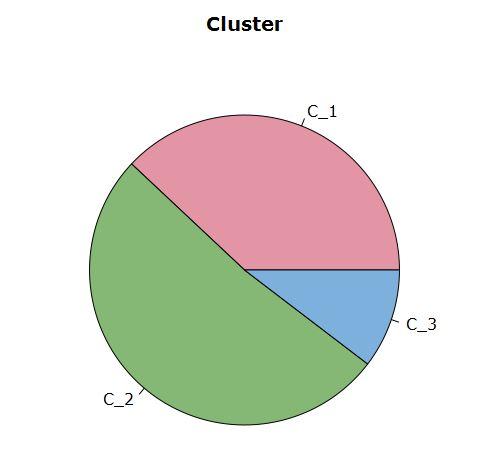
En total se generaron 3 clusters, el Cluster 1 (C_1) tiene el 38% del total de la cartera, mientras que el Cluster 2 (C_2) y Cluster 3 (C_3) tienen 51 y 11% respectivamente.
Analisis Visual del Modelo
Vamos a empezar analizando una de las variables más comunes: Edad
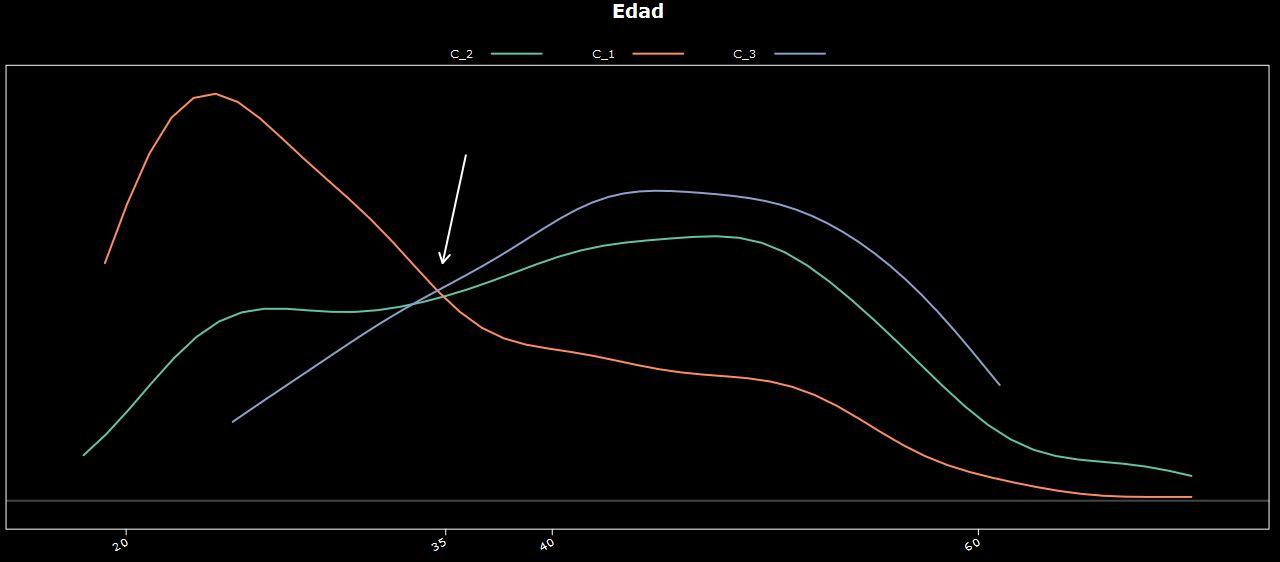
En el gráfico podemos ver la distribución de la edad de acuerdo al cluster al que pertenecen (un tipo de gráfico muy útil por cierto).
Rápidamente y de manera visual podemos observar que en el Cluster 1 está el segmento de “Jóvenes”, mientras que en el Cluster 3 estan los más “Adultos”. Por último en el Cluster 2 hay tanto Jóvenes como Adultos, lo cual no aporta mucha información.
| → Uno de los objetivos que se persigue con estos modelos es que cada segmento tenga características únicas y que lo diferencie del resto. |
Otra cuestión muy útil para realizar tareas operativas (y que Marketing suele necesitar), es cuantificar, asignarle un valor numérico a “Jóvenes” y otro a “Adultos”: ¿Cuál es el valor que hace que un cliente caiga en una categoria u otra?
Para responder a esta cuestión rápidamente se puede utilizar el gráfico, en que se observa una flecha que separa esta brecha en los 35 años (aproximadamente).
Por lo que vamos viendo el modelo segmentó fuertemente de acuerdo a la edad: “Alguien es Jóven si tiene entre 20 y 35 años, y Adulto si tiene entre 35 y 60 años.”
Sin embargo, hace falta hacer este tipo de análisis para todas las variables, para luego armar un informe a la gerencia.
Vamos a concentrarnos debido a la acción que desea marketing, en los segmentos C_1 (Jóvenes, marcado con rojo) y C_3 (Adultos, marcado con azul).
Seguimos con otra variable: promedio de u$s que el cliente gasta por mes.
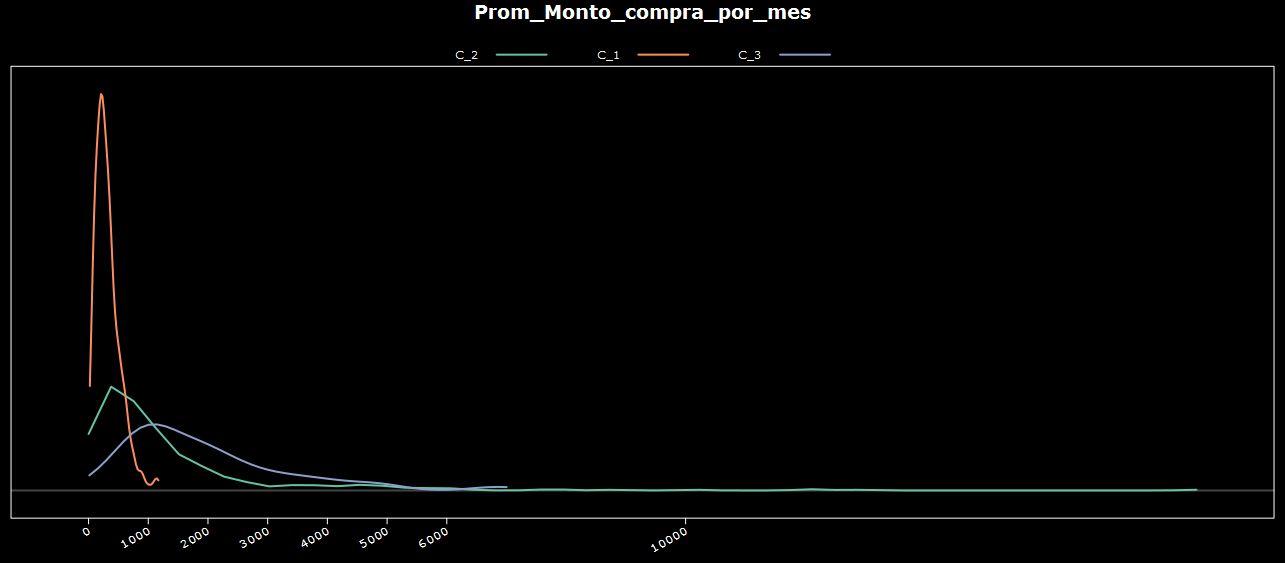
De nuevo, solamente utilizando el gráfico vemos que el segmento de Jóvenes (C_1) se caracteriza por tener casi todas sus compras por debajo de los u$s 800.
Mientras que los Adultos (C_3 ) gastan entre 800 y 3000 u$s.
| Hasta aquí hemos podido caracterizar el modelo de clustering de acuerdo a la edad y al consumo mensual. Habiendo decidido quedarnos con los Jóvenes y Adultos, y cuantificando cuanto gasta cada grupo en promedio mensualmente. |
Por último, y para finalizar nuestro análisis visual para marketing analizaremos la variable Ingresos_Mensuales:
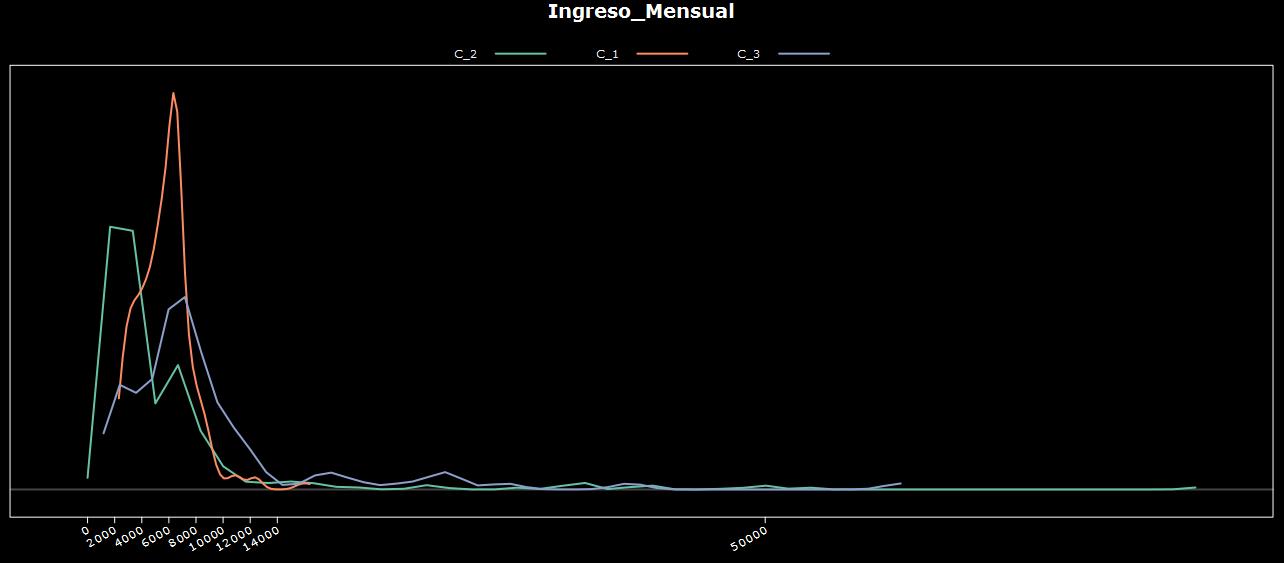
Observamos que el segmento Adultos (C_3) tiene ingresos mensuales entre 4.000 y 12.000 u$s, mientras que el segmento Jóvenes posee ingresos muy similares a los del segmento Adultos, y rondan entre 4.000 y 10.000 u$s.
Este dato puede resultar de mucho interés para marketing ya que significa que el segmento de Jóvenes estaría pudiendo gastar más, y sin embargo no lo hace.
| Este comportamiento puede verse en nuestras vidas cuando por ejemplo tenemos dos tarjetas de crédito (emitidas por dos bancos distintos), y tenemos el límite de crédito en una de ellas completamente lleno. Si queremos seguir comprando probablemente empecemos a usar la del otro banco. El 1er banco se está perdiendo de canalizar más de nuestras compras por no tener un límite de crédito acorde a nuestro consumo (y claro está, suponiendo que somos buenos pagadores...) |
Conclusiones
Podemos observar que existen 2 comportamientos marcados, el del segmento Jóvenes y el de Adultos.
Jóvenes: tienen una edad que oscila entre los 20 y 35 años, un gasto mensual menor a 800 u$s y unos ingresos mensuales que rondan entre los 4.000 y 10.000 u$s.
Adultos: su edad es mayor a 35 años, poseen un gasto mensual mayor a los Jóvenes, rondando entre los 800 y 3.000 u$s, así como también unos ingresos mensuales muy similares: entre 4.000 y 12.000 u$s
| La Gerencia de Marketing podrá decidir un precio más adecuado para realizar una promoción en productos que estén acordes al perfil y gasto promedio de cada segmento. Además podrá buscar realizar una campaña de fidelización específica con el segmento Jóvenes ya que si el beneficio para ellos es atractivo, podría resultar en una alta rentabilidad a corto plazo. |
Referencias
● Ref. 1: Un modelo de clustering agrupa los datos en forma automática de acuerdo a la similitud entre los casos. Cada segmento debería reflejar características únicas que lo diferencie del resto. La técnica utilizada para el ejemplo es el K-Means. Para más información: http://es.wikipedia.org/wiki/Algoritmo_de_agrupamiento
| Adjunto | Size |
|---|---|
| datos3_es.txt | 162 bytes |
