Analitica de datos de Twitter con hojas de cálculo de Google: Hashtags influyentes de un topic
 En el primer artículo de esta serie tratamos cómo obtener datos de Twitter desde triggers o disparadores. En este punto deberíamos empezar a pensar qué campos incluimos en nuestro análisis e ir estudiando el formato de los mismos.
En el primer artículo de esta serie tratamos cómo obtener datos de Twitter desde triggers o disparadores. En este punto deberíamos empezar a pensar qué campos incluimos en nuestro análisis e ir estudiando el formato de los mismos.
Para ello, recomendamos consultar la página de desarrollo de la API de Twitter, donde se enumeran todos los campos generados por cada tweet y su formato exacto.
En nuestro caso hemos definido un trigger que nos guarda una fila por cada nuevo tweet con el hashtag #datascience y con un número de retweets mayor a 5..

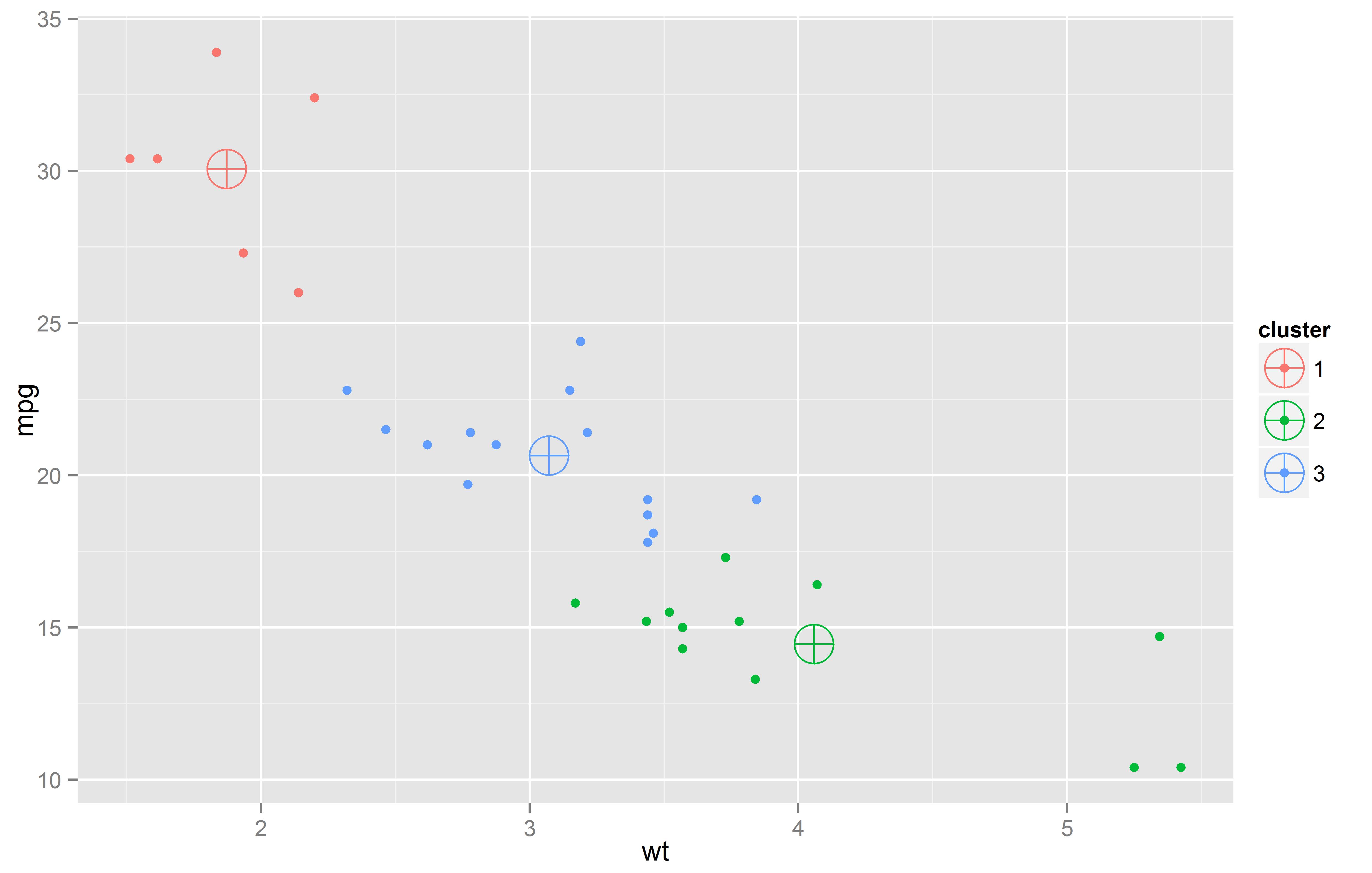
 para los que buscan tendencias locales o globales. No sólo eso, sino que podemos encontrar rápidamente los personajes o ideas más influyentes en dicha red analizando los datos que nos proporciona la API de Twitter.
para los que buscan tendencias locales o globales. No sólo eso, sino que podemos encontrar rápidamente los personajes o ideas más influyentes en dicha red analizando los datos que nos proporciona la API de Twitter. La figura del data scientist es clave para ser capaz de ir de los datos a la información, y de la información a la decisión.
La figura del data scientist es clave para ser capaz de ir de los datos a la información, y de la información a la decisión.  ole para su posterior utilización de manera libre. Ya en 2010 conseguía uno de sus primeros hitos con la liberación de una licencia para la libre utilización de datos del Archivo Nacional del Reino Unido. Esta misma web, en 2011, dedicaba un
ole para su posterior utilización de manera libre. Ya en 2010 conseguía uno de sus primeros hitos con la liberación de una licencia para la libre utilización de datos del Archivo Nacional del Reino Unido. Esta misma web, en 2011, dedicaba un