4.3 Instalación e Inicio del Intelligent Miner
4.3 Instalación e Inicio del Intelligent Miner alfonsocutro 15 Marzo, 2010 - 13:084.3.1 Instalación del Servidor para Windows
4.3.1 Instalación del Servidor para Windows alfonsocutro 15 Marzo, 2010 - 13:21- Requisitos de Hardware: El servidor Intelligent Miner para Windows se ejecuta en sistemas con procesadores a 300 MHz o superiores. Para ejecutar IBM DB2 Intelligent Miner for Data en windows, debe instalar uno de los clientes soportados, en la misma máquina o en una máquina remota. El espacio de almacenamiento necesario varía según la cantidad de datos procesados por ejecución. El mínimo es de 128 MB, pero se recomienda utilizar 512 MB de RAM. El espacio de disco necesario para una demostración del producto depende del tipo de partición del disco duro.
- Requisitos de Software: El servidor Windows requiere tener incorporado Microsoft Windows NT, 2000, XP, además un servidor DB2 Universal Database.
El servidor Intelligent Miner de Windows se inicia como un servidor windows nativo denominado IBM Intelligent Miner. El servidor IBM Intelligent Miner se inicia automáticamente al iniciar el sistema.
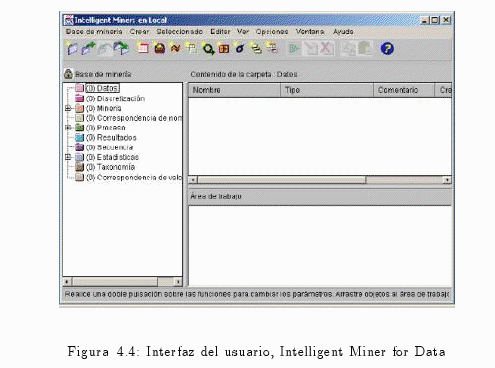
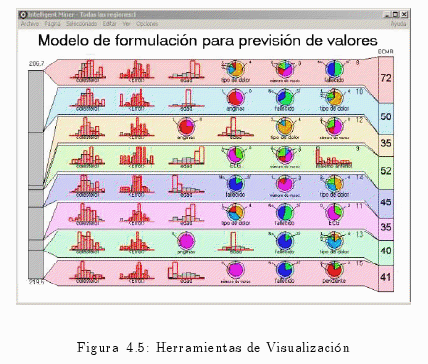
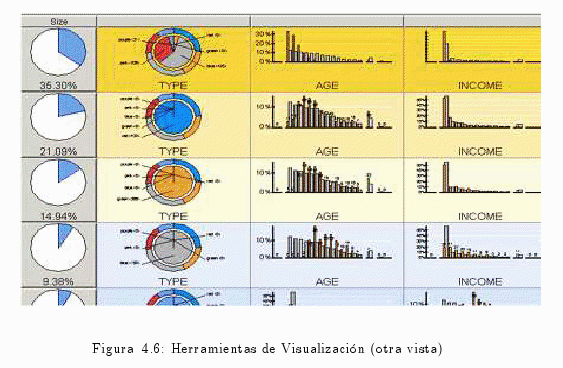
4.3.2 Instalación del Clientes Windows
4.3.2 Instalación del Clientes Windows alfonsocutro 15 Marzo, 2010 - 13:25- Requisitos de Hardware: El cliente Intelligent Miner para Windows se ejecuta en una estación de trabajo con un procesador a 300 Mhz o superior. El espacio de almacenamiento necesario varía según la cantidades de datos procesados por ejecución. El mínimo es de 128 MB, pero se recomienda utilizar 512 MB de RAM. El espacio de disco necesario para una demostración del producto depende del tipo de partición del disco duro.
- Requisitos de Software: El cliente Windows requiere tener incorporado Microsoft Windows NT, 2000, XP.
4.3.3 Conceptos Básicos del Intelligent Miner
4.3.3 Conceptos Básicos del Intelligent Miner alfonsocutro 15 Marzo, 2010 - 13:29
En general, la minería de datos en Intelligent Miner se consigue por medio de la creación de objetos interrelacionados. Estos objetos se muestran como íconos y representan el conjunto de atributos o valores que definen los datos o funciones. se crean objetos de formulación para llevar a cabo una tarea en concreto.
Intelligent Miner crea otros objetos, como objetos de resultado que contienen los elementos encontrados en una ejecucion de minerìa.
Los objetos de un proyecto de minería de datos concreto se guardan como un grupo denominado base de minería. Se puede crear una base de minería para cada objetivo o proyecto de minería.
Cuando se trabaja con Intelligent Miner, una de las tareas fundamentales consiste en crear objetos de formulación. En el próximo capítulo se indicará paso a paso como dichos objetos.
4.3.4 Funciones de Minería del Intelligent Miner
4.3.4 Funciones de Minería del Intelligent Miner alfonsocutro 15 Marzo, 2010 - 13:30Función Asociaciones
El propósito de esta técnica es encontrar elementos de una transacción que impliquen la presencia de otros elementos en la misma transacción.
Suponiendo que se tiene una base de datos con operaciones de compra, y que cada transacción consiste en un conjunto de elementos que el cliente ha adquirido, la función de minería Asociaciones podría detectar relaciones entre los elementos del conjunto.
Función Clustering Demográfico
El objetivo de descubrir clusters es agrupar registros que tengan características similares.
Intelligent Miner busca en la base de minería las características que se dan con más frecuencia y agrupa los registros relacionados de acuerdo con ello. El resultado de la función de clustering tiene el número de clusters detectados y las caracteristicas que los constituyen. Además, el resultado muestra la forma en que las características están distribuidas en los clusters.
Suponiendo que se tiene una base de un supermercado que incluye la identificación de los clientes e información acerca de la fecha y la hora de las compras. La función de minería clustering podría agrupar en clusters para permitir la identificación de diferentes tipos de compradores.
El Clustering Demográfico proporciona la agrupación de clusters rápida y deforma natural de bases de datos de gran tamaño. Determina automáticamente el número de clusters que se generarán. Las semejanzas entre registros se denominan comparando los valores de los campos. Los clusters se definen para maximizar el criterio de Condorcet. Donde el criterio de Condorcet es la suma de todas las semejanzas de registros de pares dentro del mismo cluster menos la suma de todas las semejanzas de registros de pares en diferentes cluster.
Función Clustering Neuronal
El objetivo de descubrir cluster es agrupar registros que tengan caracteristicas similares.
Intelligent Miner busca en la base de minaría las características que se dan con más frecuencia y agrupa los registros relacionados de acuerdo con ello. El resultado de la función clustering muestra el número de clusters detectados y las características que los constituyen. Además, el resultado muestra la forma en que las carasterísticas que los constituyen. Además, el resultado muestra la forma en que las características están distribuidas en los clusters.
El Clustering Neuronal utiliza una Red neuronal de mapa de características de Kohonen. Los mapas de mapa de características de Kohonen utilizan un proceso denominado organización automática para agrupar los registros de entrada similares. El usuario especifica el numéro de clusters y el número máximo de pasadas sobre los datos. Estos parámetros controlan el tiempo de proceso y el grado de granularidad que se utiliza al asignar los registros de datos a los clusters.
La función principal del Clustering Neuronal es buscar un centro para cada cluster. Este centro se denomina también prototipo de cluster. Para cada registro de los datos de entrada, la función de minería Clustering Neuronal calcula el prototipo de cluster más cercano al registro.
Con cada pasada sobre los datos de entrada, los centros se ajustan de forma que se logra una calidad mejor en el modelo de clustering global. El indicador de proceso muestra la mejor en la calidad en cada pasada durante la ejecución de la función de minería.
Función Patrones Secuenciales
El objetivo de esta técnica es encontrar todas las apariciones de subsecuencias semejantes en una base de datos de secuencias.
Por ejemplo, suponiendo que se tiene una base de datos de un comerciante que desea optimizar sus compras y el sistemas de almacenamiento de; al realizar una ejecución de minería en estas base de datos se obtendrá los nombres de parejas de secuencias con el grado de semejanza y el número de subsecuencias.
Esta técnica tambien se puede utilizar para identificar empresas con patrones de crecimiento similares, determinar productos con patrones de ventas similares o determinar acciones con movimientos de precios similares. Otro uso puede ser la detección de ondas sísmicas que no sean similares o la localización de irregularidades geológicas.
Función Clasificación en Árbol
Se hacen predicciones de las clasificaciones para crear modelos basados en datos conocidos. Estos modelos se pueden utilizar para analizar la razón por la cual se ha hecho una clasificación o para calcular la clasificación de nuevos datos.
Los datos históricos se componen frecuentemente de un conjunto de valores y de una clasificación de estos valores. Si se analizan los datos que ya se han clasificado se descubrirán las características que han contribuido a realizar la clasificación anterior. El modelo de clasificación resultante se podrá utilizar luego para predecir las clases de registros que contienen nuevos valores de atributos.
Se puede utilizar estas técnicas para aprobar o denegar reclamaciones de seguros, detectar fraudes en las trajetas de crédito, identificar defectos en imágenes de componentes manufacturados y diagnosticar condiciones de error. También se puede aplicar para determinar objetivos de márketing, en el diagnóstico médico para determinar la eficacia de los tratamientos médicos, para la reposición de inventarios o en la planificación de la ubicación de una tienda.
El algoritmo de inducción con árbol ofrece una descripción de fácil comprensión sobre la distribución subyacente de los datos. Este algoritmo realiza un ajuste proporcional con respecto al número de ejemplos de preparación y al número atributos que se encuentran en bases de datos extensas. Es conveniente utilizar este técnica para conocer mejor la estructura de la base de datos o para estructurar las bases de datos que no estén clasificadas.
Función Clasificación Neuronal
Se hacen predicciones de las clasificaciones para crear modelos basados en datos conocidos. Estos modelos se pueden utilizar para analizar la razón por la cual se ha hecho una clasificación o para calcular la clasificación de nuevos datos.
La función Clasificación Neuronal emplea una red neuronal de retropropagación para clasificar los datos. La clasificación se basa en el valor de clase y las relaciones de los atibutos descubiertos mediante un proceso de minería realizado en unos datos clasificados anteriormente. El aprendizaje de red significa desarrollar un modelo que represente dichas relaciones, Una red que ha realizado un aprendizaje es una salida de la ejecucíon de minería. El análisis de sensibilidad, otro tipo de salida, se utiliza para comprender la contribución relativa de los campos deatributos en la decisión de clasificación.
Una red nueronal con aprendizaje puede generalizar a partir de su experiencia pasada, y calcular una clasificación razonable incluso tomando como punto de partida combinaciones de atributos que no haya visto nunca.
Función Prediccíon FBR
La finalidad de la predicción de valores es descubrir la dependencia y la variación de un valor de un campo en relación con los valores de otros campos que se encuentren es el mismo registro. Se genera un modelo que puede predecir un valor para ese campo particular en un registro nuevo con el mismo formato, en base a otros valores de campo.
Por ejemplo, un comerciante desea utilizar datos históricos para calcular los ingresos por ventas que puede suponer un cliente nuevo. Una ejecución de minería sobre esos datos históricos crea un modelo. Este modelo se puede utilizar para predecir los ingresos que supondrán las ventas realizadas a un cliente nuevo en base a los datos de éste. El modelo también pude mostrar que las campañas de incentivos dirigidas a algunos clientes mejoran las ventas.
Se puede utilizar el método de función de base radial (FBR) para ajustar datos que son fución de diversas variables. El algoritmo bá sico puede formar un modelo para predecir el valor de un campo determinado partiendo de los valores de otros atributos. Una función base-radial require varios centros de ajuste. Donde un centro de ajuste es un vector del espacio de atributos. En cada uno de estos centros, se define una función de base. La función de base es una función no lineal de distancia desde el centro de ajuste. Por este motivo, las funciones de base se denominan Funcion de base radial: tienen el mismo valor en cualquier punto con la misma distancia o radio desde el centro de ajuste.
Función Prediccíon Neuronal
La finalidad de la predicción de valores es descubrir la dependencia y la variación de un valor de un campo en relacíon a los valores de otros campos que se encuentren en el mismo registro. Se genera un modelo que puede predecir un valor para ese campo particular en un registro nuevo con el mismo formato, en base a otros valores de campo.
La función de minería Prediccíon Neuronal crea un modelo que se utiliza para predecir nuevos valores para regresión y pronóstico de series temporales. Utiliza una red neuronal de retropropagación para predecir valores. La predicción se basa en el valor de predicción y en las relaciones entre los atributos descubiertas al explorar un conjunto de datos de preparación que contienen tanto la variable independiente como las dependientes. Al desarrollo de un modelo que represente estas relaciones se le denomina aprendizaje o preparación de la red neuronal.
Además de la predicción de valores estándar, también denominada regresión, la función Predicción Neuronal ofrece soporte a la predicción de series temporales al permitir que el usuario especifique un horizonte de previsión y un tamaño de ventana de entrada. Estos dos parámetros se utilizan para dar formato a los registros de preparación internamente para que la red neurinal tome un conjunto de ”m” registros consecutivos (el tamaño de la ventana) y prediga el valor dependiente de ”n” registros (el hotizonte) en el futuro.
4.3.5 Funciones Estadísticas del Intelligent Miner
4.3.5 Funciones Estadísticas del Intelligent Miner alfonsocutro 16 Marzo, 2010 - 11:23Las funciones estadísticas de Intelligent Miner ofrecen diversos métodos de estadísticas y de pronostico para dar apoyo a sus decisiones empresariales.
Se puede utilizar las funciones estadísticas para obtener más información sobre los datos, lo que permitirá tomar decisiones más acertadas cuando se apliquen los procesos de minería a los datos. Las funciones estadísticas se aplican a los datos de entrada y producen datos de salida y resultados.
Las funciones estadísticas de Intelligent Miner aplican distintos cálculos y teorías estadísticas a los datos de entrada para descubrir en ellos patrones ocultos. Dichas funciones se pueden utilizar en los pasos de transformación y minería del proceso de minería de datos.
Se puede utilizar la función estadística de regresión lineal para predecir valores mediante un modelo de ajuste lineal. Además se puede utilizar el análisis de componentes de principios para var los atributos más dominantes en sus datos.
4.3.6 Funciones de Preproceso del Intelligent Miner
4.3.6 Funciones de Preproceso del Intelligent Miner alfonsocutro 16 Marzo, 2010 - 11:26Las funciones de preproceso se utilizan para transformar los datos antes, durante y después de la ejecuciones de minería. Las funciones se ejecutan sobre datos de entrada, y cada función produce datos de salida, excepto enel caso de las funciones Ejecutar SQL y Borrar fuentes de datos.
Los datos de entrada consisten en tablas o vistas de bases de datos en un servidor. Las funciones de preproceso nunca modifican los datos de entrada. Los datos de salida se pueden escrivir en tablas o vistas de bases de datos, excepto la función Copiar registros en archivo, que sólo produce archivos. A fin de evitar la duplicación de los datos, los datos de salida acostumbran a constituir vistas. Si se desea reiteración de datos se pueden utilizar tablas.
En el paso de transformación del proceso de minería de datos, se puede utilizar las funciones de preproceso de Intelligent Miner para preparar los datos para la minería. Podrían excluirse campos o registros de los datos de entrada que no sean relevantes para la finalidad de la minería de datos o realizar operaciones matemáticas sobre los campos de los datos de entrada antes de llevar a cabo la minería de los datos.
4.3.7 Visualización de Resultados
4.3.7 Visualización de Resultados alfonsocutro 16 Marzo, 2010 - 11:30Cuando se finaliza una ejecución de minería, se puede abrir una ventana de resultados que proporcione una visión general inicial. Modificando la representación de los resultados pueden verse aspectos concretos detalladamente.
La mayoría de visores de resultados ofrecen la posibilidad de imprimirlos. En general, aparacerá el panal estándar de impresión del sistema operativo del cliente cuando seleccione la opción de impresión.
En síntesis, IBM DB2 Intelligent Miner for Data Versión 8.1 brinda una amplia gama de herramientas que posibilitan el análisis de grandes bases de datos. También ofrece herramientas de visualización para interpretar los resultados de minería.