Extracción de Conocimiento con Pentaho Business Intelligence
Extracción de Conocimiento con Pentaho Business Intelligence alfonsocutro 16 Marzo, 2010 - 12:207.1 Concepto de Inteligencia de Negocios Business Intelligence
7.1 Concepto de Inteligencia de Negocios Business Intelligence alfonsocutro 16 Marzo, 2010 - 12:23La Inteligencia de Negocios o Busines Intelligence (BI ) hace referencia a un conjunto de productos y servicios para acceder a los datos, analizarlos y convertirlos en información (ver fig. 7.1).

E-Business es la compleja fusión de los procesos de negocios, aplicaciones empresariales y estructura organizacional necesaria para crear un modelo de negocios altamente competitivo (Kalakota y Robinson).
La inteligencia en el negocio electrónico (e-business), incluye actividades como el procesamiento analítico en línea (OLAP) y aprovechamiento de datos, también llamada extracción de datos o Minería de Datos.
Para obtener más información acerca de Inteligencia de Negocios o Busines Intelligence ver el Capítulo No 1 (Introducción a la Minería de Datos).
7.2 Pentaho Business Intelligence (BI)
7.2 Pentaho Business Intelligence (BI) alfonsocutro 16 Marzo, 2010 - 12:32Pentaho Business Intelligence (BI) es una iniciativa en curso por la comunidad de Open Source que provee organizaciones con mejores soluciones para las necesidades de Business Intelligence (BI) a las empresa (ver fig. 7.2)

La plataforma Open Source Pentaho Business Intelligence cubre amplias necesidades de análisis de los datos y de los informes empresariales.
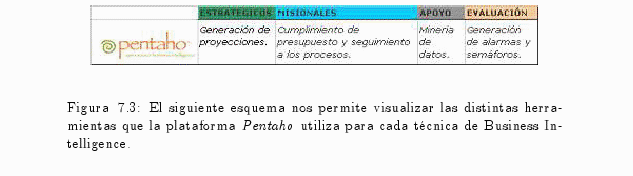
Las soluciones de Pentaho están desarrolladas en Java y tienen un ambiente de implementación también basado en Java. Eso hace que Pentaho es una solución muy flexible para cubrir una amplia gama de necesidades empresariales tanto las típicas como las sofisticadas y específicas del negocio (ver fig.7.3).
Las soluciones que Pentaho pretende ofrecer se componen fundamentalmente de una infraestructura de herramientas de análisis e informes integrados con un motor de workflow de procesos de negocio.
La plataforma será capaz de ejecutar las reglas de negocio necesarias, expresadas en forma de procesos y actividades y de presentar y entregar la información adecuada en el momento adecuado, mediante analisis OLAP, Cuadros de Mando, etc.
7.2.1 Arquitectura de Pentaho
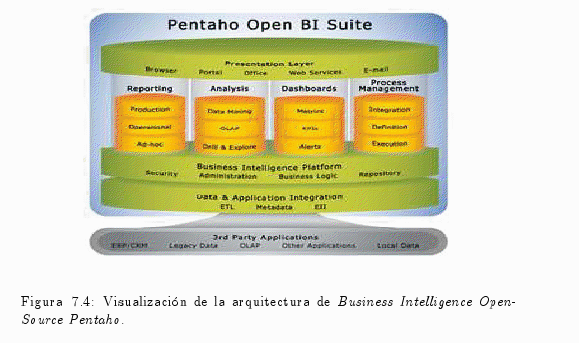
7.2.1 Arquitectura de Pentaho alfonsocutro 16 Marzo, 2010 - 12:39La solución Business Intelligence OpenSource Pentaho pretende ser una alternativa a las soluciones propietarias tradicionales más completas: Business Objects, Cognos, Microstrategy, Microsoft, IBM, etc., por lo que incluye todos aquellos componentes que se pueden encontrar en las soluciones Business Intelligence (BI) propietarias más avanzadas:
- Reporting.
- Análisis.
- Dashboards.
- Workflow.
- Data Mining.
- ETL.
- Single Sign-On. Ldap.
- Auditoría de uso y rendimiento.
- Planificador.
- Notificador.
- Seguridad. Perfiles.
La fig. 7.4 permite visualizar la arquitectura estructurada de las diferentes componentes que forman parte de Pentaho.
7.2.2 Componentes del Pentaho
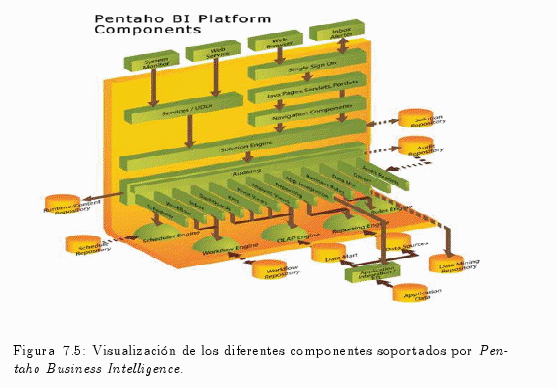
7.2.2 Componentes del Pentaho alfonsocutro 16 Marzo, 2010 - 12:45Business Intelligence Pentaho es una solución realizada en Java de código abierto flexible y muy potente que cubre prácticamente todas las necesidadesde una empresa.
Como la misma fue creada con el 100% J2EE, asegurando de esta forma la escalabilidad, integración y portabilidad.
Componentes Soportados
Servidor: Pentaho puede correr en servidores compatibles con J2EE como JBOSS AS, IBM WebSphere, Tomcat, WebLogic y Oracle AS.
Base de datos: Vía JDBC, IBM DB2, Microsft SQL Server, MySQL, Oracle, PostgreSQL, NCR Teradata, Firebird.
Sistema operativo: No existe dependencia; lenguaje interpretado.
Lenguaje de programación: Java, Javascript, JSP, XSL (XSLT / XPath / XSL-FO).
Interfaz de desarrollo: Java SWT, Eclipse, Web-based.
Todos los componentes están expuestos vía Web Services para facilitar la integración con Arquitecturas Orientadas a Servicios (SOA) .
También todos los repositorios de datos del Business Intelligence Pentaho están basados en XML.
La fig. 7.5 visualiza la interacción entre los diferentes componentes de Pentaho.
7.2.3 Características de Pentaho
7.2.3 Características de Pentaho alfonsocutro 16 Marzo, 2010 - 13:04Pentaho Business Intelligence abarca las siguientes aéreas de reporte:
Pentaho Reporting
La solución proporcionada por la plataforma Business Intelligence OpenSource Pentaho e integrada en su suite para el desarrollo de informes se llama Pentaho Reporting (ver fig. 7.6).

Existen tres productos con diferentes enfoques y dirigidos a diferentes tipos de usuarios:
- Pentaho Report Designer
Es un editor basado en Eclipse con prestaciones profesionales con capacidad de personalización de informes a las necesidades de los negocios destinado a desarrolladores.
Esta herramienta está estructurada de forma que los desarrolladores puedan acceder a sus prestaciones de forma rápida.
Incluye un editor de consultas para facilitar la confección de los datos que serán utilizados en un informe.
- Pentaho Report Design Wizard
Es una herramienta de diseño de informes, que facilita el trabajo y permite a los usuarios obtener resultados de forma inmediata. Está destinada a usuarios con menos conocimientos técnicos.
- Web ad-hoc reporting
Es el similar a la herramienta Pentaho Report Design Wizard, pero via web.
Esta herramienta extiende la capacidad de los usuarios finales para la creación de informes a partir de plantillas preconfiguradas y siguiendo un asistente de creación.
La fig. 7.7 permite visualizar los distintos tipos de reportes desarrollados con cualquiera de las harramientas de Pentaho Reporting.

Pentaho Análisis
Ayuda a operar con máxima efectividad para ganar perspicacia y entender lo necesario para tomar optimas decisiones.
Las características generales son:
- Vista dimensional de datos (por ventas, por período, por empleados, etc.).
- Navegar y explorar (Análisis Ad Hoc, Drill-down, etc.).
- Interactuar con alto rendimiento mediante tecnologías optimizadas para la rápida respuesta interactiva.
La fig. 7.8 y la fig. 7.9 nos permite visualizar las distintas formas de análisis e interpretación de los datos que posee el Pentaho Análisis.
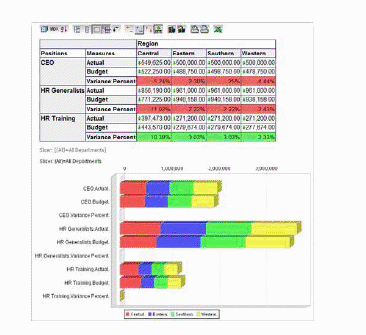
Figura 7.8: Visualización de los diferentes paneles de analisis con el Pentaho Análisis.
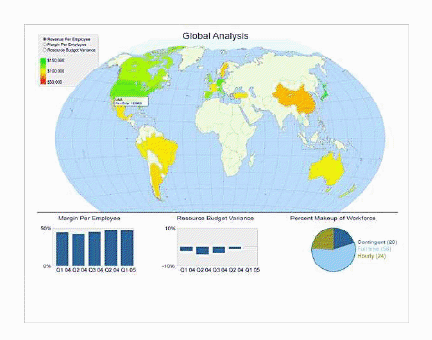
Figura 7.9: Pentaho Análisis permitira a el ususario final realizar diferentes
analisis de las variables o de los campos de la bases de datos de estudio.
Pentaho Dashboards
Esta solución provee inmediata perspicacia en un rendimiento individual, departamental o empresarial. Pentaho Dashboards facilita a los usuarios de los negocios información crítica que necesitan para entender y mejorar el rendimiento organizacional.
El Pentaho Dashboards es una potente herramienta que cuenta con las siguientes características:
- Identificación de métricas clave (KPIs, Key Performance Indicators), mediante la generación de Monitoreo/Métricas.
- Realización de investigaciones de detalles subyacentes, con reportes de soportes.
- Ejecución de seguimientos de excepciones, permitiendo pre-establecer alertas basadas en reglas del negocio.
Como se puede apreciar en la fig. 7.10, se ovservan todas las características antes mencionadas.
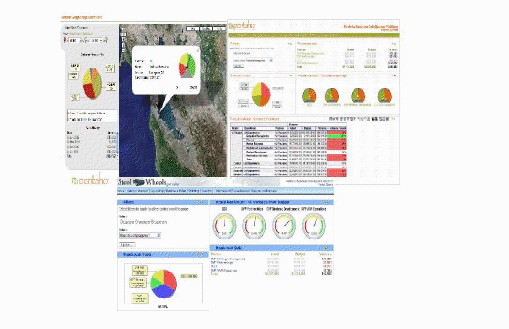
Figura 7.10: El Pentaho Dashboards es una potente herramienta que permite
la incorporación de múltiples tipos de gráficos, tablas y velocímetros a un
determinado proyecto de Business Intelligence.
Pentaho Data Integration
Los datos que alimentan a un sistema data warehouse (DW) proviene de diferentes fuentes, estas fuentes son los distintos sistemas operacionales que la empresa posee, generalmente ni son homogéneos entre sí ni concuerdan exactamen con lo que se necesita, por lo que será necesario realizar todas las adaptaciones pertinentes.
También muchas organizaciones tienen información disponible en aplicaciones y base de datos separadas.
Pentaho Data Integration abre, limpia e integra esta valiosa información y la pone en manos del usuario. Provee una consistencia, una sola versión de todos los recursos de información, que es uno de los más grandes desafíos para las organizaciones TI hoy en día.
Pentaho Data Integration permite una poderosa ETL (Extract, Transform, Load) Extracción, Transformación y Carga.
El uso de la solución Kettle permite evitar grandes cargas de trabajo manual frecuentemente difícil de mantener y de desplegar.
La arquitectura de Pentaho Data Integration viene representada por el esquema de la fig. 7.11.
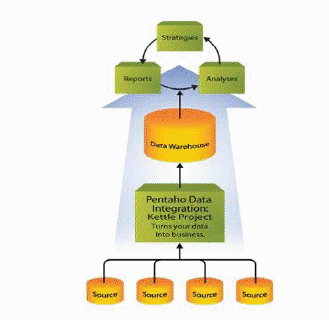
Figura 7.11: Visualización del esquema de Pentaho Data Integration.
Data Mining
La plataforma Business Intelligence OpenSource Pentaho ofrece diferentes soluciones para el desarrollo de un proyecto de Business Intelligence.
En este caso se hará referencia a la solución integrada al paquete Business Intelligence Pentaho para el desarrollo de proyectos de Data Mining.
El Weka (Waikato Enviroment for Knowledge Analysis) es un conjunto de librerías JAVA para la extracción de conocimientos desde bases de datos (ver fig. 7.12).
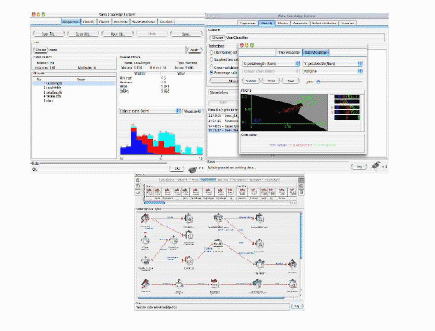
Figura 7.12: Weka (Waikato Enviroment for Knowledge Analysis)
Es un software que ha sido desarrollado bajo licencia GPL lo cual ha impulsado que sea una de las suites más utilizadas en el área en los últimos años.
Características Generales del Weka Esta herramienta Open Source incluye las siguientes características:
- Diversas fuentes de datos (ASCII, JDBC).
- Interfaz visual basada en procesos / flujos de datos (rutas).
- Distintas herramientas de minería de datos:
— Reglas de asociación (a priori, Tertius, etc.).
— Agrupación / segmentación / conglomerado (cobweb, EM y k-medias).
— Clasificación (redes neuronales, reglas y árboles de decisión, aprendizaje bayesiano).
— Regresión (regresión lineal, SVM, etc.).
— Manipulación de datos (pick & mix, muestreo, combinación, separación, etc.).
— Combinación de modelos (bagging, boosting, etc.).
— Entorno de experimentos, con la posibilidad de realizar pruebas estadísticas (T-test).
Entorno de Trabajo del Weka En la fig. 7.13 se visualizará el ambiente de trabajo del weka y posteriormente se podrá analizar en detalle cada entornos de trabajo que esta potente herramienta onpen source posee.
Figura 7.13: Visualización de la ventana principal del Weka.
Como se puede ver en la parte inferior de la fig. 7.13, Weka define cuatro entornos de trabajo diferentes.
Estos entornos son los siguientes:
- Simple CLI : Es un entorno consola que permite la invocación directa mediante Java a todos los paquetes de weka.
- Explorer : Es un entorno visual que ofrece una interfaz gráfica para el uso de los paquetes de weka.
- Experimenter : Entorno centrado en la automatización de tareas de manera que se facilite la realización de experimentos a gran escala.
- KnowledgeFlow: Permite generar proyectos de minería de datos mediante la generación de flujos de información o workflow.
En este apartado se tratará únicamente el entorno Explorer, ya que permite el acceso a la mayoría de las funcionalidades integradas en Weka de una manera más sencilla.
La siguiente imagen permiten visualizar el entorno de trabajo que posee Explorer (ver fig. 7.14).
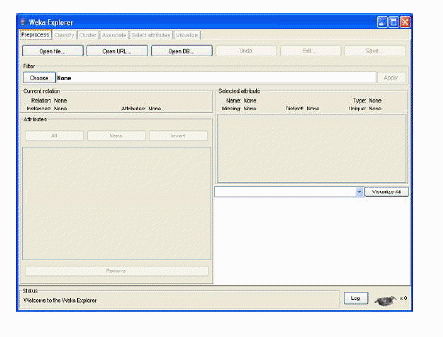
Figura 7.14: Visualización de la ventana del Explorador.
Como se puede observar en la fig. 7.14, existen seis subentornos de ejecución:
- Preprocess: Incluye las herramientas y filtros para cargar y manipular los datos.
- Classification: Acceso a las técnicas de clasificación y regresión.
- Cluster: Integra varios métodos de agrupamiento.
- Associate: Incluye una pocas técnicas de reglas de asociación.
- Select Attributes: Permite aplicar diversas técnicas para la reducción del número de atributos.
- Visualice: En este apartado podemos estudiar el comportamiento de los datos mediante técnicas de visualización.
7.3 Proceso de Minería de Datos Aplicando Business Intelligence OpenSource Pentaho
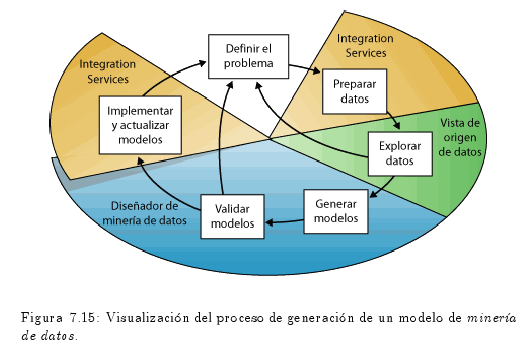
7.3 Proceso de Minería de Datos Aplicando Business Intelligence OpenSource Pentaho alfonsocutro 18 Marzo, 2010 - 11:03Como se había mencionado anteriormente, el Proceso de Minería, está compuesto por los siguientes pasos:
- Definir el problema.
- Preparar los datos.
- Explorar los datos.
- Generar modelos.
- Explorar y validar los modelos
. - Implementar y actualizar los modelos.
En el diagrama de la fig. 7.15 se describen las relaciones existentes entre cada paso de un proceso de generación de un modelo de minería de datos.
Aunque el proceso que se ilustra en la fig. 7.15 es circular, esto no significa que cada paso conduzca directamente al siguiente.
La creación de un modelo de minería de datos es un proceso dinámico e iterativo.
El objetivo de este apartado no es más que de utilizar las mismas problemáticas volcadas en el capítulo No 6, en la sección “Proceso de Minería Aplicada a la EPH”, donde la principal diferencia se basará en que en este caso se manejarán herramientas del ámbito Open Source.
7.3.1 Definición de los Problemas
7.3.1 Definición de los Problemas alfonsocutro 18 Marzo, 2010 - 11:06Como se hacía referencia anteriormente, no se añadirá ninguna problemática a las que se establecieron en el anterior capítulo.
En esta sección se tratarán los mismos objetivos de estudio ya fijados con anterioridad.
Objetivos Específicos:
- Describir la composición del empleo en Corrientes.
- Conocer los perfiles socio demográficos de los individuos de la población de Corrientes.
7.3.2 Preparación de los Datos
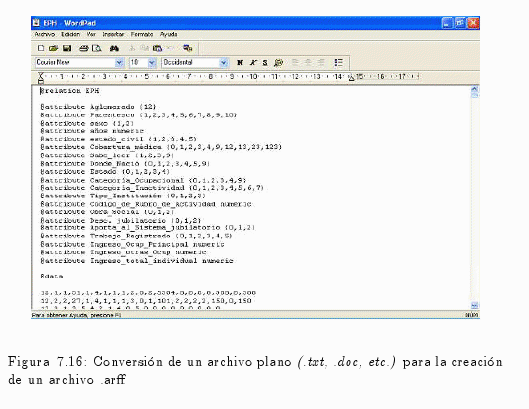
7.3.2 Preparación de los Datos alfonsocutro 18 Marzo, 2010 - 11:20Nativamente Weka trabaja con un formato denominado arff, acrónimo de Attribute-Relation File Format.
Este formato está compuesto por una estructura claramente diferenciada en tres partes:
- Cabecera: Se define el nombre de la relación. Su formato es el siguiente:
@relation <nombre-de-la-relación>
- Declaraciones de atributos: En esta sección se declaran los atributos que compondrán el archivo junto a su tipo. La sintaxis es la siguiente:
@attribute <nombre-del-atributo> <tipo>
Donde:
<nombre-del-atributo> es de tipo string.
<tipo> acepta diversos tipos, estos son:
— NUMERIC Expresa números reales.
— INTEGER Expresa números enteros.
— DATE Expresa fechas.
— STRING Expresa cadenas de texto.
- Sección de datos: Se declaran los datos que componen la relación separando con comas los atributos y con saltos de línea las relaciones.
La sintaxis es la siguiente:
@data
4,3.2
Una vez conocido el formato de los datos soportado por el Weka, se pasará al confeccionado del archivo con extensión arff.
Los mismo se pueden convertir ficheros de texto conteniendo un registro por línea con los atributos separados por comas (formato csv) a ficheror arff mediante el uso de un filtro convertidor.
Con la información recolectada a través de la EPH (Encuesta Permanente de Hogares) se han generado una base de datos Microsoft Access.
La información será recabada en una planilla de hoja de cálculos Microsoft Excel, luego se la convertirá a un documento de texto plano (.txt, .doc, etc.) para su posterior transformación a un archivo de formato específico de datos legible por el Weka, el formato .arff (ver fig. 7.16).
7.3.3 Exportación de los Datos
7.3.3 Exportación de los Datos alfonsocutro 18 Marzo, 2010 - 11:27Una vez culminada la etapa de preparación, se pasa a la etapa de exploración de datos.
En este período se comenzará a interactuar con la herramienta.
A continuación se visualizará el archivo confeccionado en el paso anterior, donde este archivo será ejecutado (ver fig. 7.17).
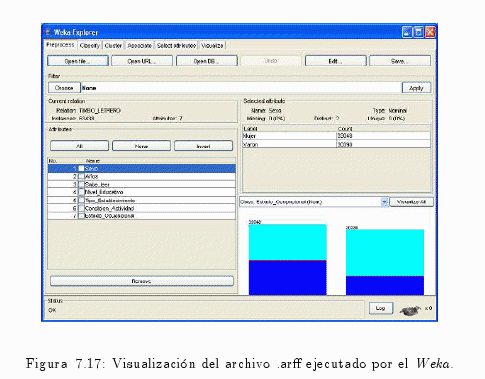
7.3.4 Generación Modelos
7.3.4 Generación Modelos alfonsocutro 18 Marzo, 2010 - 12:55En este apartado se analizarán los modelos impuestos en el apartado “Definición de los Problemas”.
Describir la composición del empleo en Corrientes.
Como se hacía referencia anteriormente, con el Weka no solamente se podrá aplicar técnicas de minería de datos.
En el transcurso del estudio relacionado con este objetivo se utilizará únicamente análisis de las variables.
A continuación se visualizan distintos análisis de las variables referentes a los estados de actividad de los individuos de la provincia de Corrientes.
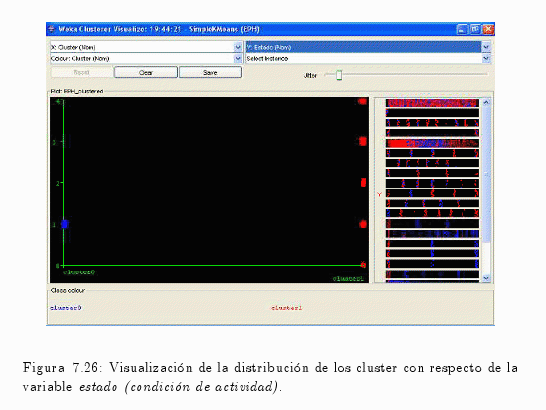
En el gráfico de la fig. 7.18 se puede visualizar la frecuencia absoluta (número de casos) de la variable de estudio que en este caso es estado (condición de actividad).
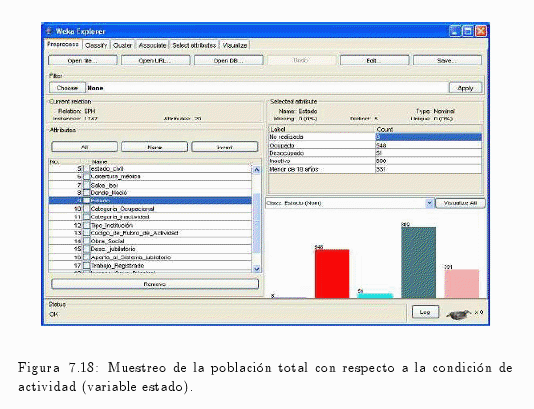
También se pude visualizar cómo se manifiesta la variable estado (condición de actividad) con las demás variables de la muestra (ver fig. 7.19).
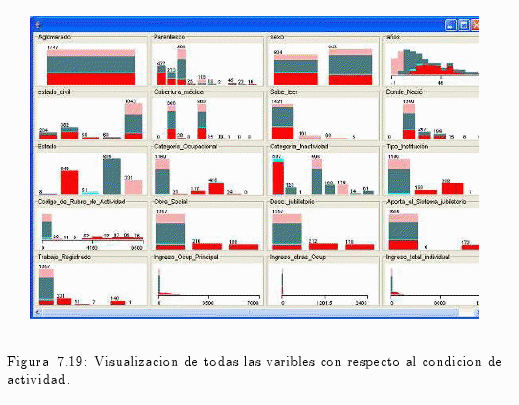
Como resultado de esta clasificación, se visualizó el número de ocupado, desocupados, inactivos, etc.
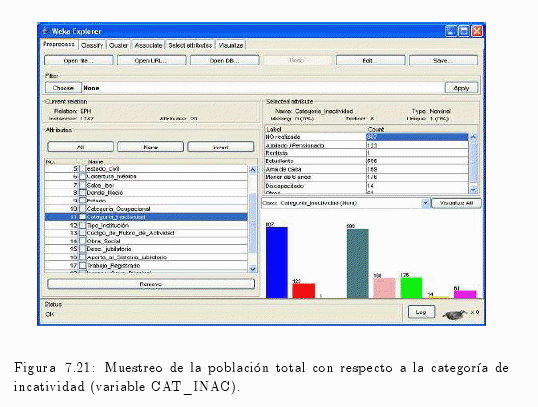
Similar al anterior procedimiento, se puede realizar con las variables cat_ocup (categoría ocupacional) o incluso con cat_inac (categoría de inactividad) (ver fig. 7.20 y fig. 7.21).
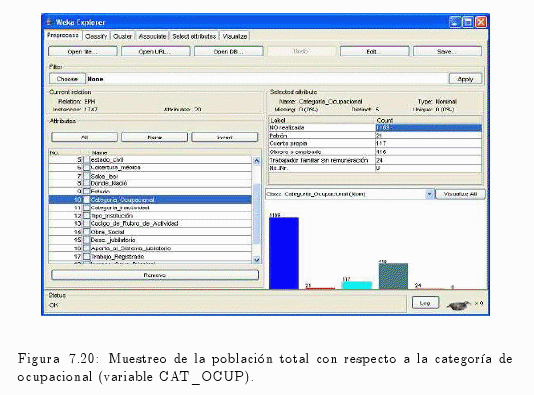
Conocer los perfiles socio demográficos de los individuos de la población de Corrientes.
A diferencia del anterior apartado, en este se utilizarán técnicas de Minería de Datos.
Lo que interesa en este caso es descubrir los diferentes perfiles de los individuos que poseen planes asistenciales en la provincia de Corrientes.
Para ello se empleará la técnica de Clustering con un algoritmo SimplekMeans , utilizando el atributo sexo para la distribución de los grupos.
Se obtendrá un modelo de minería de datos donde se dividirán todos los individuos de la población de Corrientes en los grupos correspondientes a la variable sexo.
Una vez culminado el proceso de Clustering la herramienta nos permite observar los resultados de modo textual (ver fig. 7.22) o también de manera grafica (ver fig. 7.24).
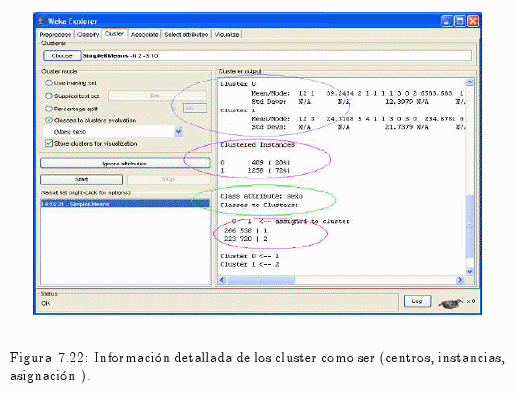
En la fig. 7.22 se puede apreciar la información sobre el número de clusters involucrados, las instancias de estos, como así también las clases y los atributos que participan en este análisis.
También se visualiza a los dos grupos, donde:
Cluster 0 <— 1 (Varón)
Cluster 1 <— 2 (Mujer)
Además se pude apreciar en la 7.22 a cuatro círculos de diferentes colores; cada uno de estos destacan la siguiente información:
- El primero círculo de color violeta destaca la distribución de los atributos en cada cluster.
- El segundo, de color rosado muestra en porcentaje y en frecuencia el número de instancias por cluster.
- El tercer círculo visualiza el atributo en este caso es la variable sexo con el cual se realizó el análisis.
- El último muestra la asignación de cada cluster por cada valor de la variable sexo, con su respectivo número de casos.
Si se presiona con el botón derecho del ratón sobre la lista de resultado (ver fig. 7.23) se puden observar los correspondientes resultados extraídos de la técnica de Clustering en forma gráfica (ver fig. 7.24).
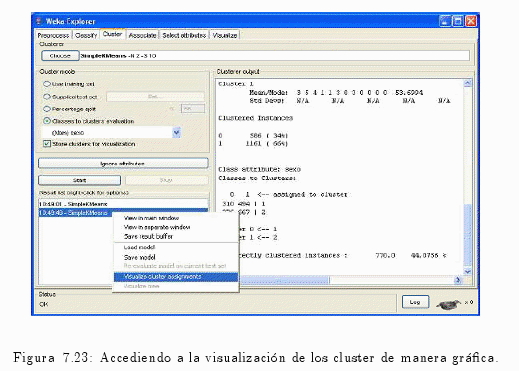
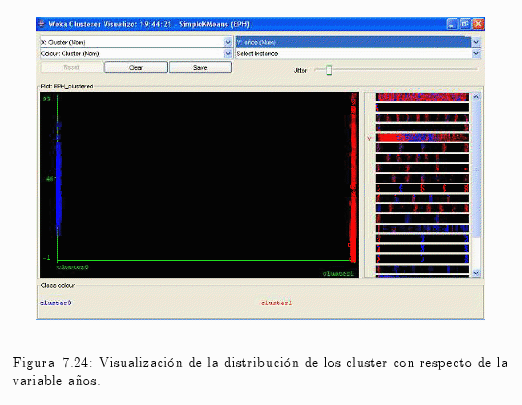
A continuación se visualizarán los resultados resultados extraídos de la técnica de Clustering.
En la fig. 7.24 se muestra la dispersión de la variable años en cada cluster.
Donde:
- Cluster 0 de colo azul.
- Cluster 1 de color rojo.
En la fig. 7.25 se pueden observar los valores que toma cada cluster de la variable que indica el analfabetismo.
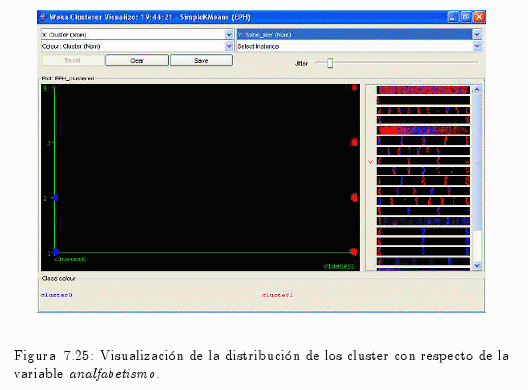
En el gráfico de la fig. 7.25 permite extraer la siguiente infomación:
- El Cluster 0 asume el valor 1 (1= Sí sabe leer y escribir; 2= No sabe leer y escribir).
- El Cluster 1 asume todos los valores restantes.
Como se puede comprobar en la fig. 7.26, el Cluster 0 asume únicamente el valor 1 (Ocupado), en cambio el Cluster 1 el resto de los valores.
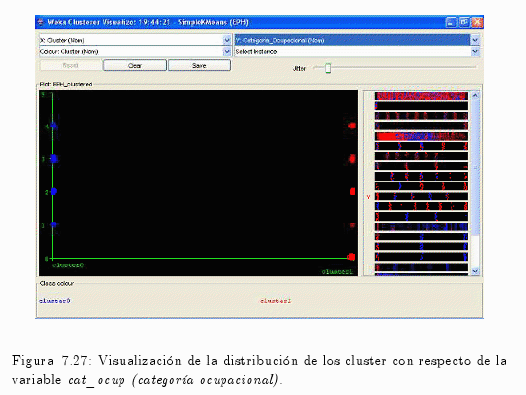
Cuando se contrasta la variable cat_ocup (categoria ocupacional) con respecto a los cluster se puede comprobar lo siguiente:
- Cluster 0 asume todos los valores exepto el 0 (cero), con mayor presencia de instancia en el valor 3 y con un importante número menor en la opción 4.
- Cluster 1 asume todos los valores inclusive el 0 (cero).
Donde:
— 0 = Entrevista individual no realizada.
— 1 = Patrón.
— 2 = Cuenta propia.
— 3 = Obrero o empleado.
— 4 = Trabajador familiar sin remuneración.
— 9 = Ns./Nr.
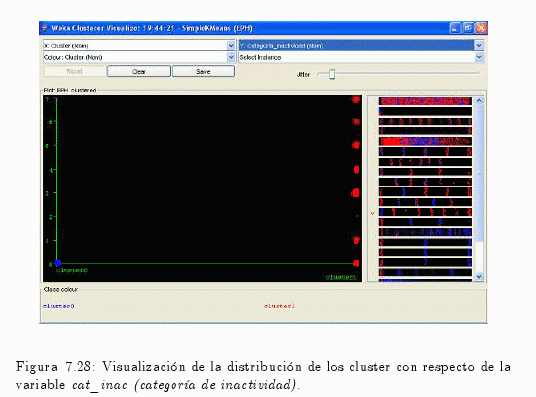
En la fig. 7.28 permite observar los valores que poseen los diferentes cluster.
Como por ejemplo:
- Cluster 0 asume el único valor 0 (cero), 0 = Entrevista individual no realizada.
- Cluster 1 toma todos los valores que asume la variable, es decir:
— 1 = Jubilado / Pensionado.
— 2 = Rentista.
— 3 = Estudiante.
— 4 = Ama de casa.
— 5 = Menor de 6 años.
— 6 = Discapacitado.
— 7 = Otros.
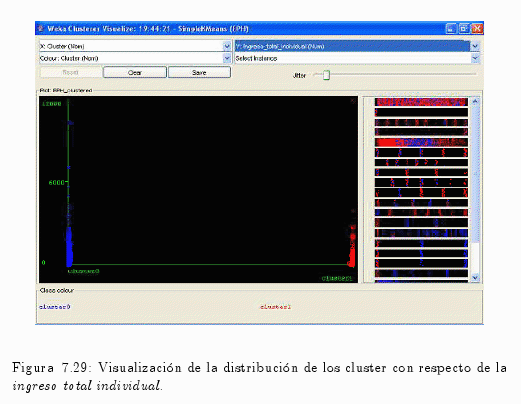
En la fig. 7.29 se puede visualizar que la distribución de los ingresos de los individuos en el Cluster 0 es superior que el Cluster 1.
El gráfico 7.29 permite comprobar que el Cluster 0 supera los 6000 pesos y el Cluster 1 no solamente no supera esta cifra si no que también posee menor número de casos.
Lo que se realizó hasta aquí es una descripción de perfiles de los individuos por la variable sexo.
Si se quisiera conocer la representación de los perfiles pero en este caso utilizando la variable estado, se procederá como se detalla a continuación.
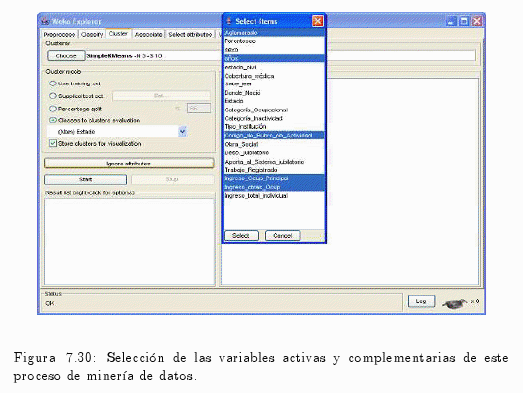
Como se puede visualizar en la fig. 7.30 la variable estado es la variable activa y parentesco, sexo, estado civil, cobertura médica, sabe leer, donde nació, categoría ocupacional, categoría inactividad, tipo de institución, obra social, desc. jubilatorio, aporta al sistema jubilatorio, trabajo registrado y ingreso total individual son las variables complementarias de dicho proceso.
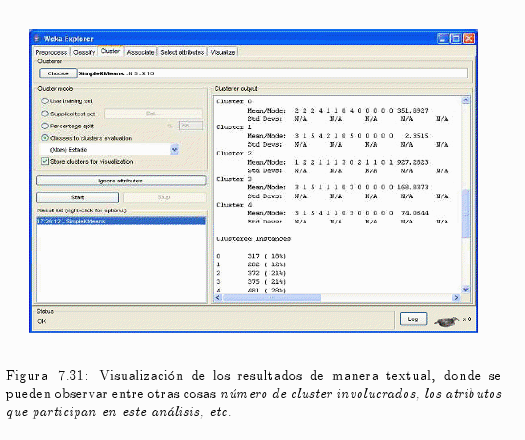
Una vez ejecutado dicho proceso se obtienen los siguientes resultados, ya sea en formato textual como gráfico (ver fig. 7.31 y fig. 7.32).
En la fig. 7.31 se puede observar la siguiente información: el número de cluster involucrados, las instancias de estos, como así también las clases y los atributos que participan en este análisis.
En la fig. 7.32 se puede observar la formación de los diferentes clústers, donde los mismos representan distintos estados.
Por ejemplo:
- El clúster No 0 asume los siguientes valores (ocupado, desocupado e inactivo).
- El clúster No 1 está compuesto por mayor presencia de la población menor de 10 años y con una inferior representación en las poblaciones inactivas y ocupadas.
- El clúster No 2 posee únicamente a los individuos que se encuentren ocupados.
- Los clúster No 3 y 4 poseen casi la misma distribución, con la diferencia que el clúster No 4 asume el valor 0 (cero) que es la no respuesta al cuestionario individual.
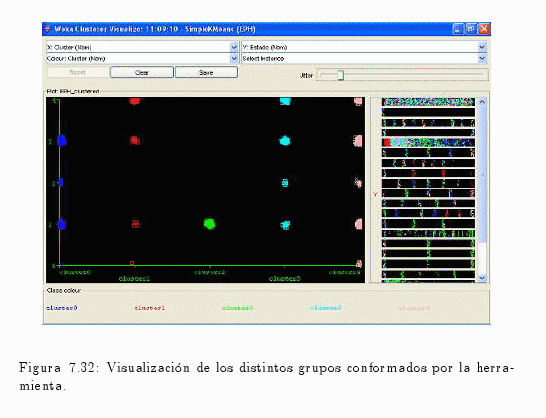
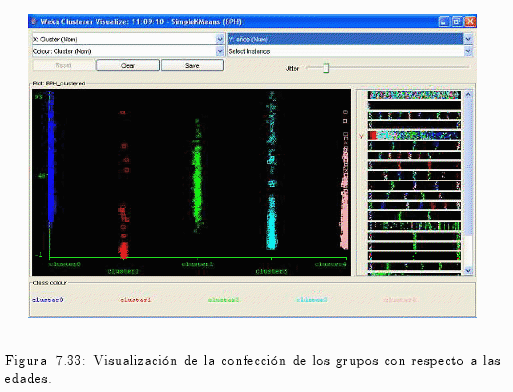
Como se puede visualizar en el gráfico 7.31, las edades están estrechamente relacionadas a los estados (condición de actividad) de los individuos:
- El clúster No 0 corresponde a los individuos que no respondieron al cuestionario individual.
- El clúster No 1 (población menor de 10 años de edad) contiene a los menores de 10 años en el gráfico.
- El clúster No 2 (población ocupada) siendo estas las edades más productivas de la población.
- El clúster No 3 (población inactiva) posee una distribución de edades diferente a la anterior distribución ya que en este grupo se encuentran estudiantes, amas de casa, etc., entre otros.
- El clúster No 4 (población desocupada) corresponde a los desocupados, con su respectiva distribución de edades.