7.3 Proceso de Minería de Datos Aplicando Business Intelligence OpenSource Pentaho
7.3 Proceso de Minería de Datos Aplicando Business Intelligence OpenSource Pentaho alfonsocutro 18 Marzo, 2010 - 11:03Como se había mencionado anteriormente, el Proceso de Minería, está compuesto por los siguientes pasos:
- Definir el problema.
- Preparar los datos.
- Explorar los datos.
- Generar modelos.
- Explorar y validar los modelos
. - Implementar y actualizar los modelos.
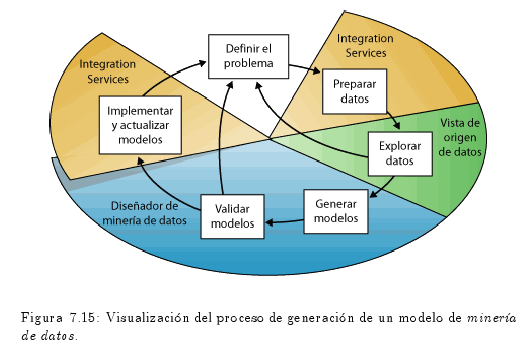
En el diagrama de la fig. 7.15 se describen las relaciones existentes entre cada paso de un proceso de generación de un modelo de minería de datos.
Aunque el proceso que se ilustra en la fig. 7.15 es circular, esto no significa que cada paso conduzca directamente al siguiente.
La creación de un modelo de minería de datos es un proceso dinámico e iterativo.
El objetivo de este apartado no es más que de utilizar las mismas problemáticas volcadas en el capítulo No 6, en la sección “Proceso de Minería Aplicada a la EPH”, donde la principal diferencia se basará en que en este caso se manejarán herramientas del ámbito Open Source.
7.3.1 Definición de los Problemas
7.3.1 Definición de los Problemas alfonsocutro 18 Marzo, 2010 - 11:06Como se hacía referencia anteriormente, no se añadirá ninguna problemática a las que se establecieron en el anterior capítulo.
En esta sección se tratarán los mismos objetivos de estudio ya fijados con anterioridad.
Objetivos Específicos:
- Describir la composición del empleo en Corrientes.
- Conocer los perfiles socio demográficos de los individuos de la población de Corrientes.
7.3.2 Preparación de los Datos
7.3.2 Preparación de los Datos alfonsocutro 18 Marzo, 2010 - 11:20Nativamente Weka trabaja con un formato denominado arff, acrónimo de Attribute-Relation File Format.
Este formato está compuesto por una estructura claramente diferenciada en tres partes:
- Cabecera: Se define el nombre de la relación. Su formato es el siguiente:
@relation <nombre-de-la-relación>
- Declaraciones de atributos: En esta sección se declaran los atributos que compondrán el archivo junto a su tipo. La sintaxis es la siguiente:
@attribute <nombre-del-atributo> <tipo>
Donde:
<nombre-del-atributo> es de tipo string.
<tipo> acepta diversos tipos, estos son:
— NUMERIC Expresa números reales.
— INTEGER Expresa números enteros.
— DATE Expresa fechas.
— STRING Expresa cadenas de texto.
- Sección de datos: Se declaran los datos que componen la relación separando con comas los atributos y con saltos de línea las relaciones.
La sintaxis es la siguiente:
@data
4,3.2
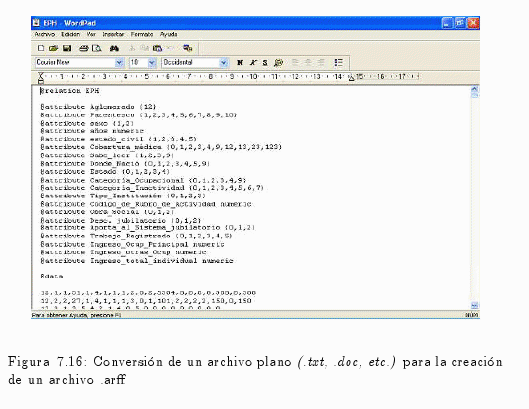
Una vez conocido el formato de los datos soportado por el Weka, se pasará al confeccionado del archivo con extensión arff.
Los mismo se pueden convertir ficheros de texto conteniendo un registro por línea con los atributos separados por comas (formato csv) a ficheror arff mediante el uso de un filtro convertidor.
Con la información recolectada a través de la EPH (Encuesta Permanente de Hogares) se han generado una base de datos Microsoft Access.
La información será recabada en una planilla de hoja de cálculos Microsoft Excel, luego se la convertirá a un documento de texto plano (.txt, .doc, etc.) para su posterior transformación a un archivo de formato específico de datos legible por el Weka, el formato .arff (ver fig. 7.16).
7.3.3 Exportación de los Datos
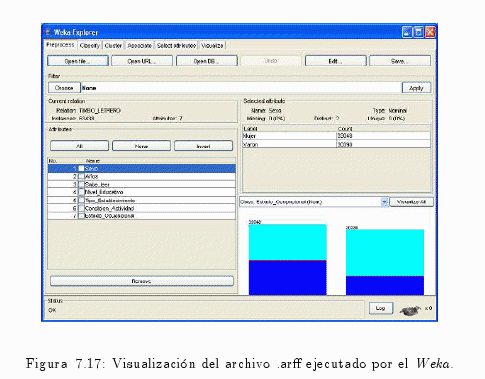
7.3.3 Exportación de los Datos alfonsocutro 18 Marzo, 2010 - 11:27Una vez culminada la etapa de preparación, se pasa a la etapa de exploración de datos.
En este período se comenzará a interactuar con la herramienta.
A continuación se visualizará el archivo confeccionado en el paso anterior, donde este archivo será ejecutado (ver fig. 7.17).
7.3.4 Generación Modelos
7.3.4 Generación Modelos alfonsocutro 18 Marzo, 2010 - 12:55En este apartado se analizarán los modelos impuestos en el apartado “Definición de los Problemas”.
Describir la composición del empleo en Corrientes.
Como se hacía referencia anteriormente, con el Weka no solamente se podrá aplicar técnicas de minería de datos.
En el transcurso del estudio relacionado con este objetivo se utilizará únicamente análisis de las variables.
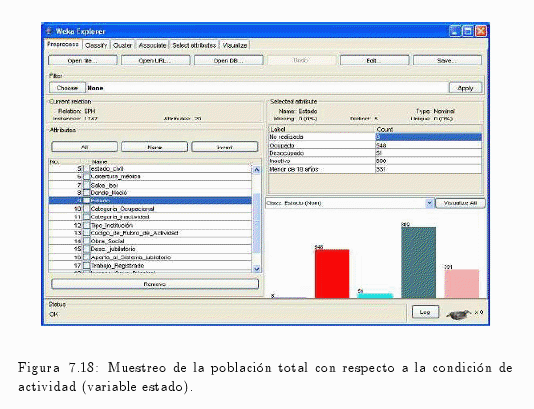
A continuación se visualizan distintos análisis de las variables referentes a los estados de actividad de los individuos de la provincia de Corrientes.
En el gráfico de la fig. 7.18 se puede visualizar la frecuencia absoluta (número de casos) de la variable de estudio que en este caso es estado (condición de actividad).
También se pude visualizar cómo se manifiesta la variable estado (condición de actividad) con las demás variables de la muestra (ver fig. 7.19).
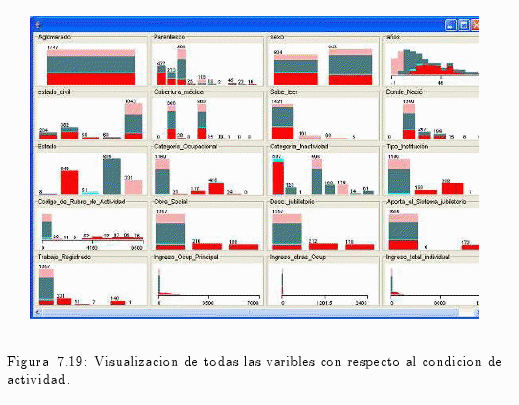
Como resultado de esta clasificación, se visualizó el número de ocupado, desocupados, inactivos, etc.
Similar al anterior procedimiento, se puede realizar con las variables cat_ocup (categoría ocupacional) o incluso con cat_inac (categoría de inactividad) (ver fig. 7.20 y fig. 7.21).
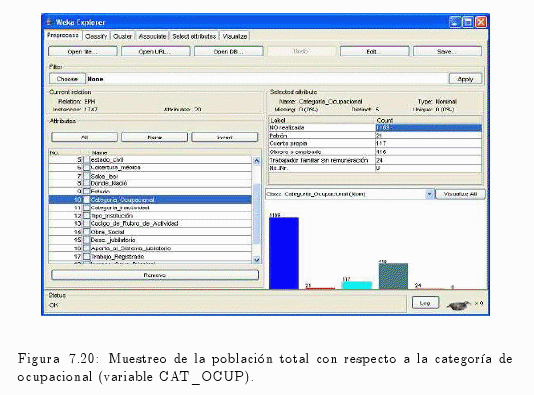
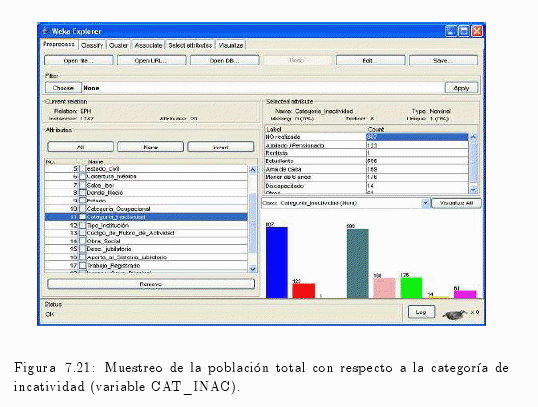
Conocer los perfiles socio demográficos de los individuos de la población de Corrientes.
A diferencia del anterior apartado, en este se utilizarán técnicas de Minería de Datos.
Lo que interesa en este caso es descubrir los diferentes perfiles de los individuos que poseen planes asistenciales en la provincia de Corrientes.
Para ello se empleará la técnica de Clustering con un algoritmo SimplekMeans , utilizando el atributo sexo para la distribución de los grupos.
Se obtendrá un modelo de minería de datos donde se dividirán todos los individuos de la población de Corrientes en los grupos correspondientes a la variable sexo.
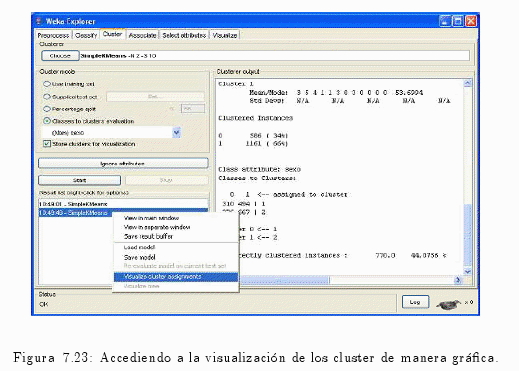
Una vez culminado el proceso de Clustering la herramienta nos permite observar los resultados de modo textual (ver fig. 7.22) o también de manera grafica (ver fig. 7.24).
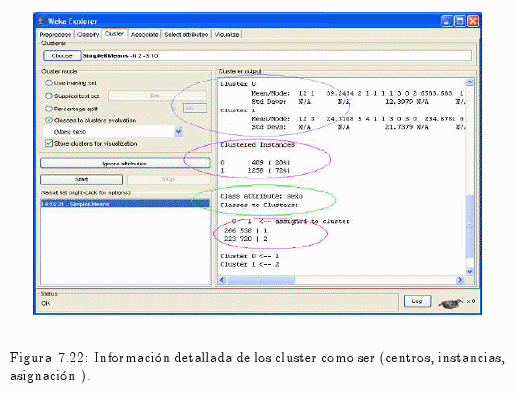
En la fig. 7.22 se puede apreciar la información sobre el número de clusters involucrados, las instancias de estos, como así también las clases y los atributos que participan en este análisis.
También se visualiza a los dos grupos, donde:
Cluster 0 <— 1 (Varón)
Cluster 1 <— 2 (Mujer)
Además se pude apreciar en la 7.22 a cuatro círculos de diferentes colores; cada uno de estos destacan la siguiente información:
- El primero círculo de color violeta destaca la distribución de los atributos en cada cluster.
- El segundo, de color rosado muestra en porcentaje y en frecuencia el número de instancias por cluster.
- El tercer círculo visualiza el atributo en este caso es la variable sexo con el cual se realizó el análisis.
- El último muestra la asignación de cada cluster por cada valor de la variable sexo, con su respectivo número de casos.
Si se presiona con el botón derecho del ratón sobre la lista de resultado (ver fig. 7.23) se puden observar los correspondientes resultados extraídos de la técnica de Clustering en forma gráfica (ver fig. 7.24).
A continuación se visualizarán los resultados resultados extraídos de la técnica de Clustering.
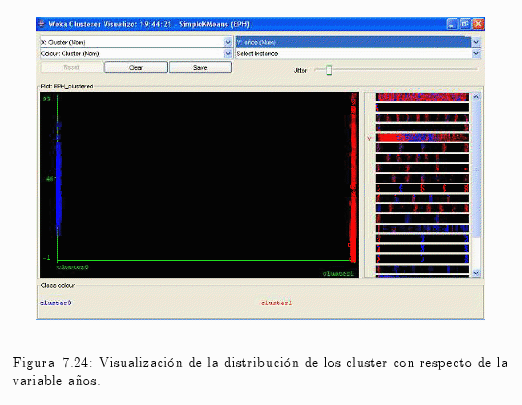
En la fig. 7.24 se muestra la dispersión de la variable años en cada cluster.
Donde:
- Cluster 0 de colo azul.
- Cluster 1 de color rojo.
En la fig. 7.25 se pueden observar los valores que toma cada cluster de la variable que indica el analfabetismo.
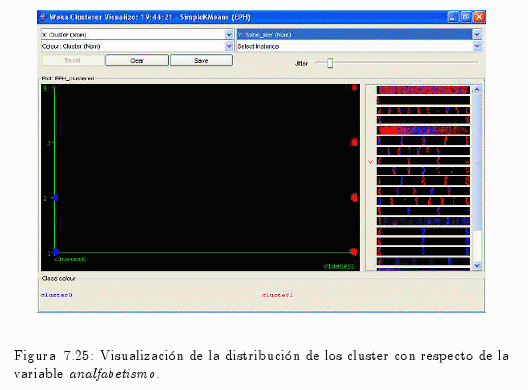
En el gráfico de la fig. 7.25 permite extraer la siguiente infomación:
- El Cluster 0 asume el valor 1 (1= Sí sabe leer y escribir; 2= No sabe leer y escribir).
- El Cluster 1 asume todos los valores restantes.
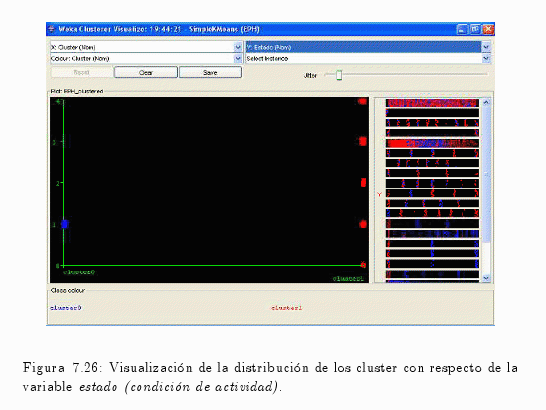
Como se puede comprobar en la fig. 7.26, el Cluster 0 asume únicamente el valor 1 (Ocupado), en cambio el Cluster 1 el resto de los valores.
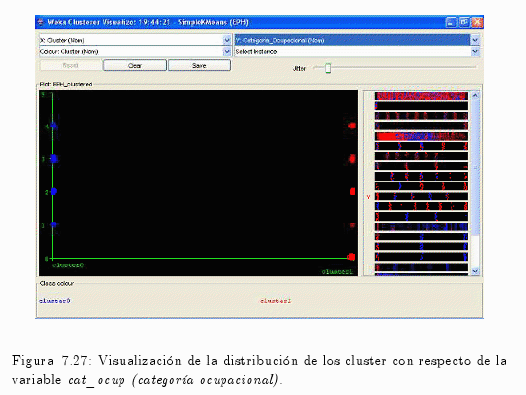
Cuando se contrasta la variable cat_ocup (categoria ocupacional) con respecto a los cluster se puede comprobar lo siguiente:
- Cluster 0 asume todos los valores exepto el 0 (cero), con mayor presencia de instancia en el valor 3 y con un importante número menor en la opción 4.
- Cluster 1 asume todos los valores inclusive el 0 (cero).
Donde:
— 0 = Entrevista individual no realizada.
— 1 = Patrón.
— 2 = Cuenta propia.
— 3 = Obrero o empleado.
— 4 = Trabajador familiar sin remuneración.
— 9 = Ns./Nr.
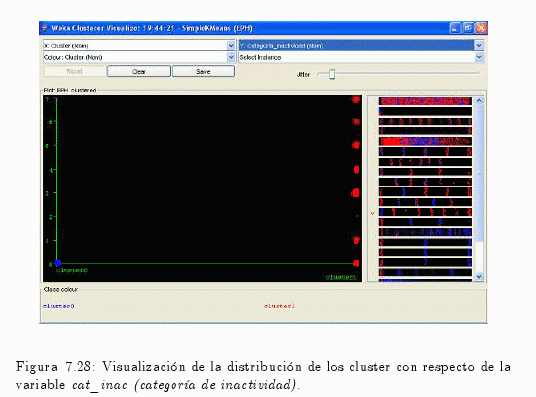
En la fig. 7.28 permite observar los valores que poseen los diferentes cluster.
Como por ejemplo:
- Cluster 0 asume el único valor 0 (cero), 0 = Entrevista individual no realizada.
- Cluster 1 toma todos los valores que asume la variable, es decir:
— 1 = Jubilado / Pensionado.
— 2 = Rentista.
— 3 = Estudiante.
— 4 = Ama de casa.
— 5 = Menor de 6 años.
— 6 = Discapacitado.
— 7 = Otros.
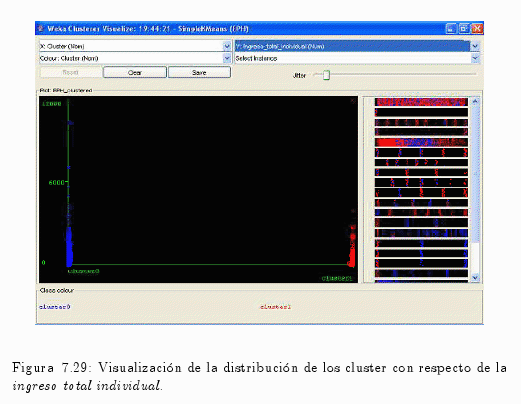
En la fig. 7.29 se puede visualizar que la distribución de los ingresos de los individuos en el Cluster 0 es superior que el Cluster 1.
El gráfico 7.29 permite comprobar que el Cluster 0 supera los 6000 pesos y el Cluster 1 no solamente no supera esta cifra si no que también posee menor número de casos.
Lo que se realizó hasta aquí es una descripción de perfiles de los individuos por la variable sexo.
Si se quisiera conocer la representación de los perfiles pero en este caso utilizando la variable estado, se procederá como se detalla a continuación.
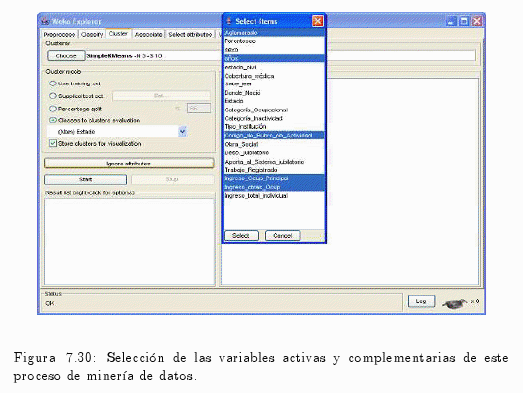
Como se puede visualizar en la fig. 7.30 la variable estado es la variable activa y parentesco, sexo, estado civil, cobertura médica, sabe leer, donde nació, categoría ocupacional, categoría inactividad, tipo de institución, obra social, desc. jubilatorio, aporta al sistema jubilatorio, trabajo registrado y ingreso total individual son las variables complementarias de dicho proceso.
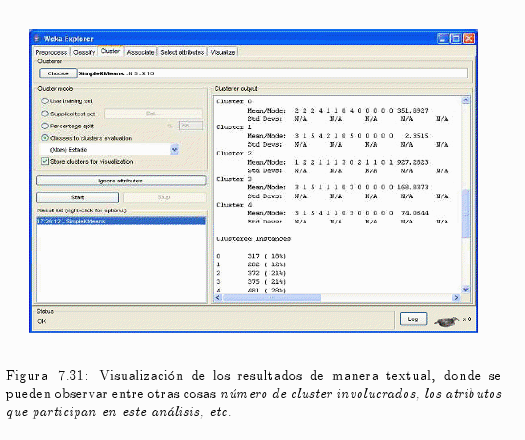
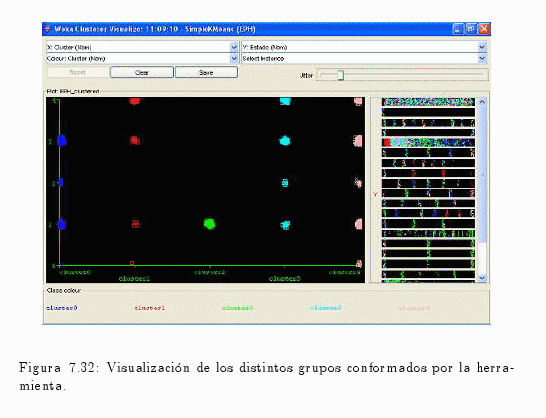
Una vez ejecutado dicho proceso se obtienen los siguientes resultados, ya sea en formato textual como gráfico (ver fig. 7.31 y fig. 7.32).
En la fig. 7.31 se puede observar la siguiente información: el número de cluster involucrados, las instancias de estos, como así también las clases y los atributos que participan en este análisis.
En la fig. 7.32 se puede observar la formación de los diferentes clústers, donde los mismos representan distintos estados.
Por ejemplo:
- El clúster No 0 asume los siguientes valores (ocupado, desocupado e inactivo).
- El clúster No 1 está compuesto por mayor presencia de la población menor de 10 años y con una inferior representación en las poblaciones inactivas y ocupadas.
- El clúster No 2 posee únicamente a los individuos que se encuentren ocupados.
- Los clúster No 3 y 4 poseen casi la misma distribución, con la diferencia que el clúster No 4 asume el valor 0 (cero) que es la no respuesta al cuestionario individual.
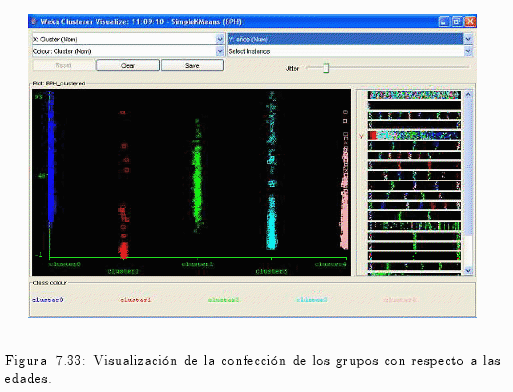
Como se puede visualizar en el gráfico 7.31, las edades están estrechamente relacionadas a los estados (condición de actividad) de los individuos:
- El clúster No 0 corresponde a los individuos que no respondieron al cuestionario individual.
- El clúster No 1 (población menor de 10 años de edad) contiene a los menores de 10 años en el gráfico.
- El clúster No 2 (población ocupada) siendo estas las edades más productivas de la población.
- El clúster No 3 (población inactiva) posee una distribución de edades diferente a la anterior distribución ya que en este grupo se encuentran estudiantes, amas de casa, etc., entre otros.
- El clúster No 4 (población desocupada) corresponde a los desocupados, con su respectiva distribución de edades.