Tutorial de RapidMiner 5.0
Tutorial de RapidMiner 5.0 bernabeu_dario 5 Noviembre, 2010 - 12:21
 .
.
documento momentáneamente.
Ejemplo 1: Árbol de Decisión.
Ejemplo 1: Árbol de Decisión. bernabeu_dario 25 Octubre, 2010 - 13:18
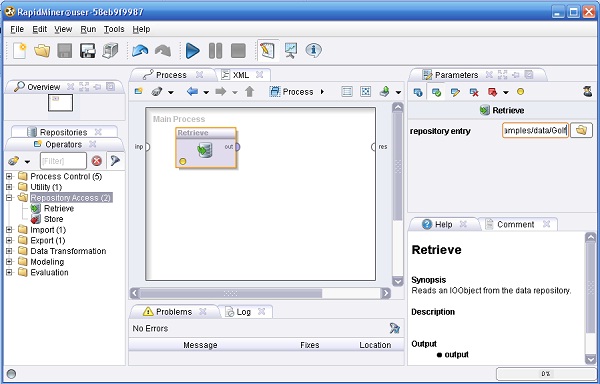
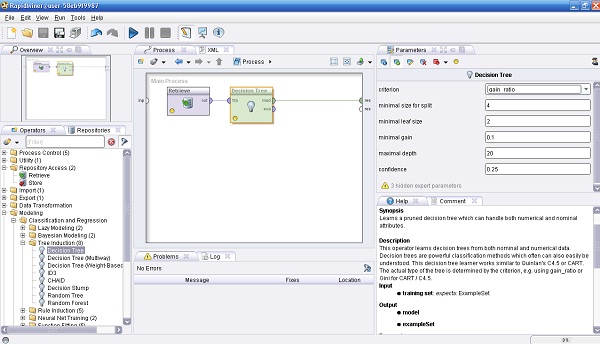
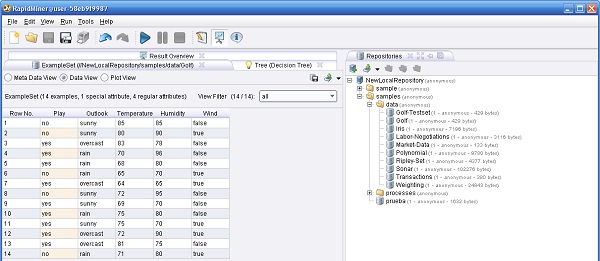
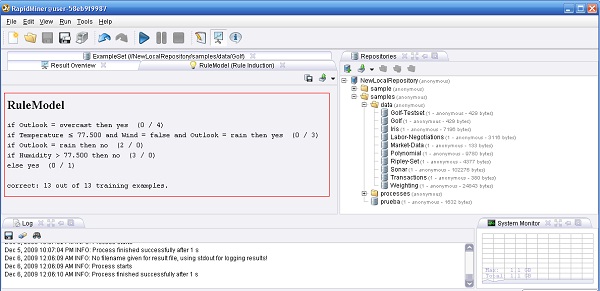
 en la barra de iconos de la parte superior del marco. El proceso debería comenzar y luego de un corto tiempo el visor de mensajes de la parte inferior del marco muestra el mensajede que el proceso finalizó correctamente. El marco principal cambia a la vista de "Resultados", que muestrael árbol de decisión aprendido (una hipótesis que en RapidMiner se denomina Modelo).
en la barra de iconos de la parte superior del marco. El proceso debería comenzar y luego de un corto tiempo el visor de mensajes de la parte inferior del marco muestra el mensajede que el proceso finalizó correctamente. El marco principal cambia a la vista de "Resultados", que muestrael árbol de decisión aprendido (una hipótesis que en RapidMiner se denomina Modelo). de la barra de iconos, o presionando la tecla de función <F8>.
de la barra de iconos, o presionando la tecla de función <F8>.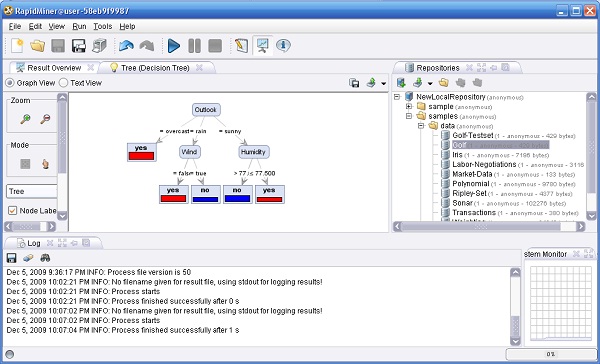
Ejemplo 2: Reglas de Asociación
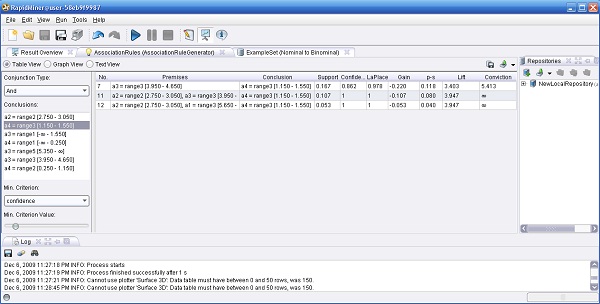
Ejemplo 2: Reglas de Asociación bernabeu_dario 25 Octubre, 2010 - 13:20Segundo, el operador filtro nominal a binominal crea para cada posible valor nominal de un atributo polinominal una nueva característica binominal (binaria) que es verdadera si el ejemplo tiene el valor nominal particular.
Ejemplo 3: Stacking
Ejemplo 3: Stacking bernabeu_dario 25 Octubre, 2010 - 13:22
Ejemplo 4: K-Medias
Ejemplo 4: K-Medias bernabeu_dario 25 Octubre, 2010 - 13:23esquemas de clustering que se pueden utilizar de la misma forma que cualquier otro esquema de aprendizaje. Esto incluye la combinación con todos los operadores de preprocesamiento.
dimensiones.
operador y la salida clu (cluster model) de éste último al conector res del panel.
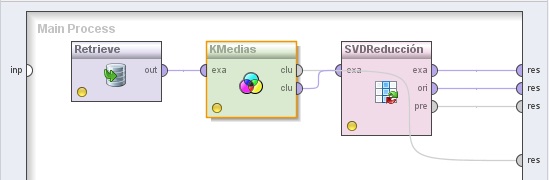
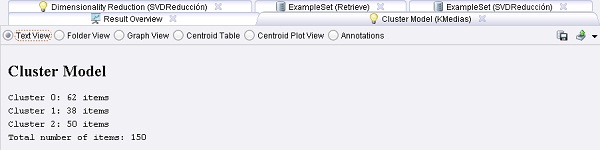
Ejemplo 5: Visualización de SVM
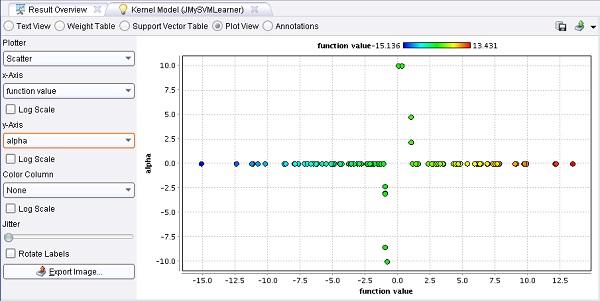
Ejemplo 5: Visualización de SVM bernabeu_dario 25 Octubre, 2010 - 13:24SVM para el cual se puede cambiar a la vista gráfica. Se proporcionan varias dimensiones para propósitos de graficación incluyendo las etiquetas del conjunto de entrenamiento, los valores alfa (multiplicadores de
Lagrange), la información de si un ejemplo de entrenamiento es un vector soporte, los valores de la función (predicciones) para los ejemplos de entrenamiento y por supuesto los valores de los atributos para todos los ejemplos de entrenamiento. Estos datos junto con el potente mecanismo graficador de RapidMiner permiten diferentes tipos de visualizaciones de SVM. Sólo pruebe alguna de ellas.
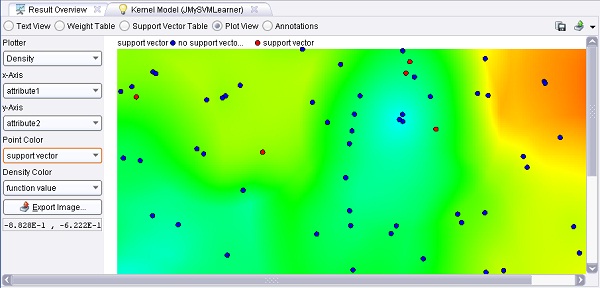
“Densidad”, seleccionando dos atributos para los ejes x e y, “atributo1” y “atributo2” en este ejemplo, y estableciendo la “Densidad de Color” para la columna “valor de la función”. Esto conducirá al diagrama de
densidad deseado. Si se configura el “Color de la Punta” a “vector soporte” o “alfa”, también obtendrá información sobre en qué puntos están los vectores soporte.
Ejemplo 6: Rellenado de valores faltantes
Ejemplo 6: Rellenado de valores faltantes bernabeu_dario 25 Octubre, 2010 - 13:26
manejar valores infinitos.
 . Este modo también puede activarse/desactivarse presionando <F4> o en la barra de opciones superior con la opción “View → Expert Mode”.
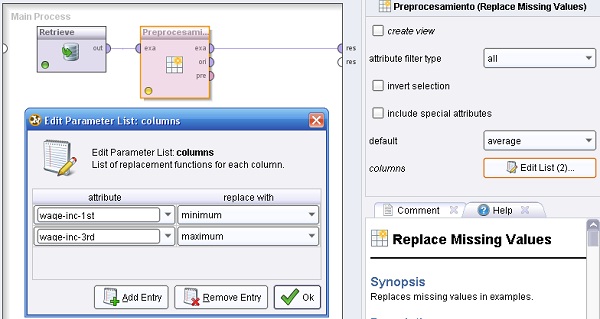
. Este modo también puede activarse/desactivarse presionando <F4> o en la barra de opciones superior con la opción “View → Expert Mode”.desplegable de la columna “attribute” especificar los atributos cuyos valores faltantes serán reemplazados: “wage-inc-1st” y “wage-inc-3rd”. En la lista desplegable de la columna “replace with” seleccionar la
función que se utilizará para determinar el reemplazo de los valores faltantes de estos atributos: “minimum” y “maximum”, respectivamente.
4. Seleccionar el operador Retrieve. La pestaña “Parameters” de la derecha muestra los parámetros de este operador. El operador “Retrieve” sólo tiene el parámetro repository entry. Presionar <F7> o hacer
clic derecho en este operador y luego se seleccionar Breakpoint After (  ). Con esta acción se ha establecido un punto de interrupción, es decir, el proceso detendrá su ejecución después de este operador.
). Con esta acción se ha establecido un punto de interrupción, es decir, el proceso detendrá su ejecución después de este operador.
5. Ejecutar el proceso presionando el botón “Play” (<F11>). Como puede observarse el proceso comienza y se detiene después del punto de interrupción del operador “Retrieve”. En este momento RapidMiner
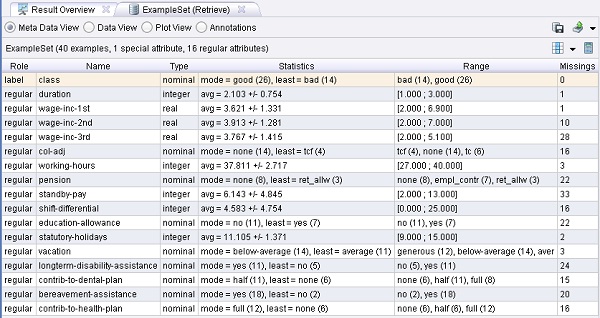
muestra la salida del operador “Retrieve” en la pestaña ExampleSet (Retrieve). La columna “Missings” indica la cantidad de valores faltantes de un campo, por ej., el campo “pension” tiene 22 valores faltantes.
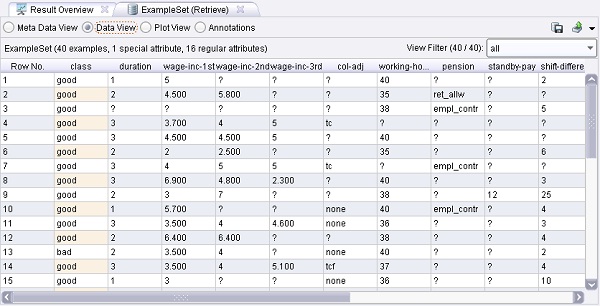
Cambiar de Meta Data View a Data View para observar los valores faltantes. En la tabla de datos se pueden encontrar algunos signos de interrogación, que indican un valor faltante para una muestra (fila). El cuadro
“View Filter” en la esquina superior derecha de la pestaña permite filtrar el conjunto de datos mediante ciertos criterios. Probar algunos filtros para ver qué muestras están completas y cuáles tienen valores faltantes.
6. Volver a la perspectiva de diseño (barra de menú: View/Perspectives/Design). Para sustituir los valores faltantes en los datos seleccionamos el operador Prepocesamiento (Replace Missing Values). Debemos
asegurarnos que el modo experto este habilitado. El parámetro attribute filter type determina los atributos a los cuales se les aplicará el preprocesador. El parámetro default determina el valor con el que será
reemplazado un valor faltante. Se pueden seleccionar varias opciones, por ej., el valor medio del atributo. Se pueden concatenar varios operadores de preprocesamiento para sustituir diferentes atributos con diferentes tipos de valores por defecto.
Ejemplo 7: Generador de ruido
Ejemplo 7: Generador de ruido bernabeu_dario 25 Octubre, 2010 - 13:56El NoiseOperator se puede utilizar para agregar ruido controlado o la característica de ruido al conjunto de datos. Esto es especialmente útil para estimar la performance de un preprocesamiento de características o la
robustez de un aprendiz específico.
RapidMiner también proporciona muchos otros operadores de preprocesamiento incluyendo un filtro de TFIDF, ofuscar, manejar series de valores y otros.
1. Agregar el operador Repository Access → Retrieve a la zona de trabajo y localizar el archivo //Samples/data/Polynomial con el navegador del parámetro repository entry.
2. Agregar el operador Utility → Data Generation → Add Noise a la zona de trabajo. Cambiar el nombre del mismo a “GeneradorRuido” y los valores de los parámetros random attributes a 3 (cantidad de atributos
aleatorios a agregar), offset a 5.0 (desplazamiento agregado a los valores de cada atributo aleatorio) y linear factor a 2.0 (factor lineal multiplicado por los valores de cada atributo aleatorio).
3. Conectar la salida del operador Retrieve a la entrada exa (example set input) del operador GeneradorRuido (Add Noise) y la salida exa (example set output) de éste último al puerto res.

4. Ejecutar el proceso y observar el resultado.
Ejemplo 8: Unión de Conjuntos de Ejemplos.
Ejemplo 8: Unión de Conjuntos de Ejemplos. bernabeu_dario 26 Octubre, 2010 - 11:09El operador ExampleSetJoin de este proceso construye la unión de dos conjuntos dados de ejemplos. Observe que los atributos con nombres iguales serán renombrados durante el proceso de unión. Los conjuntos de ejemplos deben proporcionar un atributo de Id para determinar los ejemplos correspondientes. Después de alcanzar el punto de interrupción se pueden examinar los conjuntos de ejemplos de entrada. Después de reanudar el proceso, el resultado será el conjunto de ejemplos unidos.
1. Agregar 2 operadores Utility → Data Generation → Generate Data a la zona de trabajo. Cambiar el nombre de los mismos a “PriGeneradorConjEjs” y “SegGeneradorConjEjs”. Establecer el parámetro target function (función objetivo) de ambos en “sum classification” y el parámetro number of attributes (cantidad de atributos) en 5 y 10 respectivamente.
2. Agregar 2 operadores Data Transformation → Attribute Set Reduction and Transformation → Generation → Generate ID. Cambiar el nombre de los mismos a “PriIdEtiquetador” y “SegIdEtiquetador”.
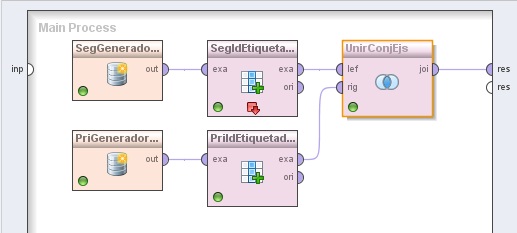
3. Conectar las salidas de los operadores PriGeneradorConjEjs (Generate Data) y SegGeneradorConjEjs (Generate Data) a las entradas exa (example set input) de los operadores PriIdEtiquetador (Generate ID) y SegIdEtiquetador (Generate ID), respectivamente.
4. Agregar un operador Data Transformation → Set Operations → Join. Cambiar el nombre del mismo a “UnirConjEjs” y quitar la tilde del parámetro remove double attributes (visible en modo experto).
5. Conectar las salidas exa (example set output) de los operadores PriGeneradorConjEjs y SegGeneradorConjEjs a las entradas rig (right) y lef (left) del operador UnirConjsEjs (Join), respectivamente, y la salida joi (join) de éste último al puerto res.
6. Seleccionar el operador SegGeneradorConjEjs y presionar F7 para establecer un punto de interrupción.
7. Ejecutar el proceso, observador el resultado parcial y reanudarlo luego de la interrupción presionando nuevamente el botón play, que ahora es de color verde.
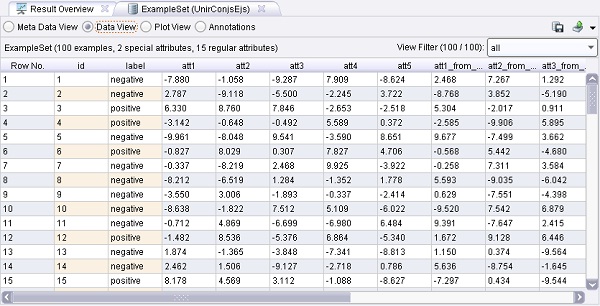
Ejemplo 9: Validación Cruzada Numérica.
Ejemplo 9: Validación Cruzada Numérica. bernabeu_dario 26 Octubre, 2010 - 11:22En muchos casos el modelo aprendido no es de interés sino la exactitud del modelo. Una posible solución para estimar la precisión del modelo aprendido es aplicarlo a datos de prueba etiquetados y calcular la cantidad de errores de predicción (u otros criterios de performance). Debido a que los datos etiquetados son poco frecuentes, a menudo se usan otros enfoques para estimar la performance de un esquema de aprendizaje. Este proceso muestra la “validación cruzada” en RapidMiner.
La validación cruzada divide los datos etiquetados en conjuntos de entrenamiento y de prueba. Los modelos se aprenden sobre los datos de entrenamiento y se aplican sobre los datos de prueba. Los errores de predicción se calculan y promedian para todos los subconjuntos. Este bloque de construcción se puede utilizar como operador interno para varios wrappers (contenedores) como los operadores de generación/selección de características.
Este es el primer ejemplo de un proceso más complejo. Los operadores construyen una estructura de árbol. Por ahora esto es suficiente para aceptar que el operador de validación cruzada requiere un conjunto de ejemplos como entrada y entrega un vector de valores de performance como salida. Además gestiona la división en ejemplos de entrenamiento y de prueba. Los ejemplos de entrenamiento se utilizan como entrada para el aprendiz de entrenamiento, el cual entrega un modelo. Este modelo y los ejemplos de prueba forman la entrada de la cadena de aplicadores que entregan la performance para este conjunto de prueba. Los resultados para todos los posibles conjuntos de prueba son recogidos por el operador de validación cruzada. Finalmente se calcula el promedio y se entrega como resultado.
Una de las cosas más difíciles para el principiante de RapidMiner es a menudo tener una idea del flujo de datos. La solución es sorprendentemente simple: el flujo de datos se asemeja a una búsqueda primero en profundidad a través de la estructura de árbol. Por ejemplo, después de procesar el conjunto de entrenamiento con el primer hijo de la validación cruzada del modelo aprendido, se entrega al segundo hijo (la cadena de aplicadores). Esta idea básica de flujo de datos es siempre la misma para todos los procesos y pensar en este flujo será muy conveniente para el usuario experimentado.
1. Agregar el operador Repository Access → Retrieve a la zona de trabajo y localizar el archivo //Samples/data/Polynomial con el navegador del parámetro repository entry.
2. Agregar el operador Evaluation → Validation → X-Validation. Cambiar el nombre del mismo a “XVal” y el valor del parámetro sampling type (tipo de muestreo) a “shuffled sampling” (modo experto). Conectar la salida del operador Retrieve a la entrada tra (training) de este operador y la salida ave (averagable, promediable) de éste último al conector res (result) del panel.
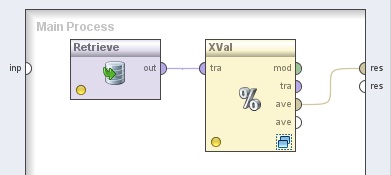
3. Hacer doble clic sobre el operador XVal (X-Validation). En el panel Training del nivel inferior, agregar el siguiente operador:
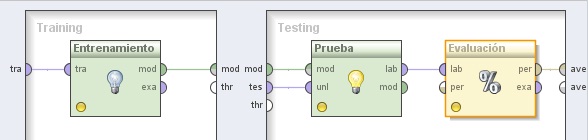
3.1 Modeling → Classification and Regression → Support Vector Modeling → Support Vector Machine (LibSVM). Cambiar el nombre del mismo a “Entrenamiento” y los valores de los parámetros svm type a “epsilon-SVR”, kernel type a “poly” y C a 1000.0. Conectar la entrada tra (training) y salida mod (model) de este operador a los puertos tra y mod del panel, respectivamente
En el panel Testing de la derecha, agregar los siguientes operadores:
3.2 Modeling → Model Application → Apply Model. Cambiar el nombre del mismo a “Prueba” y conectar las entradas mod y tes del panel a las entradas mod y unl de este operador, respectivamente.
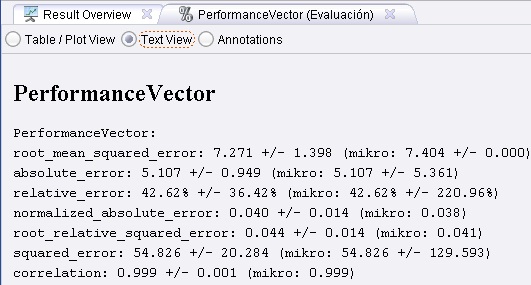
3.3 Evaluation → Performance Measurement → Classification and Regression → Performance (Regression). Cambiar el nombre del mismo a “Evaluación” y tildar las siguientes opciones (además de las que están tildadas por defecto): absolute error (error absoluto), relative error (error relativo), normalized absolute error (error absoluto normalizado), root relative squared error (raíz cuadrada del error relativo al cuadrado), squared error (error al cuadrado), y correlation (correlación). Conectar la salida lab (labeled
data, datos etiquetados) del operador Prueba (Apply Model) a la entrada lab de este operador y la salida per (performance) de éste último al conector ave (averagable 1) del panel.
4. Ejecutar el proceso. El resultado es una estimación de la performance del esquema de aprendizaje sobre los datos de entrada.
5. Seleccionar el operador de evaluación y elejir otros criterios de performance. El criterio principal se utiliza para las comparaciones de performance, por ejemplo, en un wrapper.
6. Sustituir la validación cruzada XVal por otros esquemas de evaluación y ejecutar el proceso con ellos. Alternativamente, se puede verificar cómo funcionan otros aprendices sobre estos datos y sustituir el operador de entrenamiento.
Ejemplo 10: Aprendizaje sensitivo al costo y gráfico ROC
Ejemplo 10: Aprendizaje sensitivo al costo y gráfico ROC bernabeu_dario 26 Octubre, 2010 - 11:37Utilizamos los valores de confianza entregados por el aprendiz empleado en este proceso (predicciones flexibles en lugar de clasificaciones rígidas). Todos los aprendices de RapidMiner entregan estos valores de confianza, además de los valores pronosticados. Estos se pueden interpretar como una especie de garantía del aprendiz de que la predicción rígida (crisp) correspondiente es en realidad la etiqueta verdadera. En consecuencia, esto se denomina confianza.
En muchos escenarios de clasificación binaria, un error de predicción equivocada no ocasiona los mismos costos para ambas clases. Un sistema de aprendizaje debe tomar en cuenta estos costos asimétricos. Mediante el uso de las confianzas de predicción podemos convertir todos los aprendices de clasificación en aprendices sensibles al costo. Por lo tanto, ajustamos el umbral de confianza para hacer algunas predicciones (generalmente 0,5).
Un operador ThresholdFinder se puede utilizar para determinar el mejor umbral con respecto a los pesos de la clase. El siguiente operador ThresholdApplier mapea las predicciones flexibles (confianzas) a clasificaciones rígidas con respecto al valor del umbral determinado. El operador ThresholdFinder también puede producir una curva ROC para varios umbrales. Esta es una buena visualización de la performance de un esquema de aprendizaje. El proceso se detiene cada vez que se grafica la curva ROC hasta que se pulsa el botón Ok (5 veces). El parámetro show_ROC_plot determina si el gráfico ROC se debe mostrar para todos.
Se puede encontrar información adicional sobre los operadores de validación utilizados en este proceso en el correspondiente directorio de ejemplos y, por supuesto, en la referencia de operadores del tutorial de RapidMiner.
1. Agregar el operador Utility → Data Generation → Generate Data a la zona de trabajo. Cambiar el nombre del mismo a “GeneradorConjEjs”. Establecer los parámetros target function (función objetivo) en “random dots classification”, number examples (cantidad de ejemplos) en 500, number of attributes (cantidad de atributos) en 2, attributes lower bound (límite inferior de los atributos) en 0.0 y attributes upper bound (límite superior de los atributos) en 25.0.
2. Agregar el operador Evaluation → Validation → X-Validation. Cambiar el nombre del mismo a “XVal” y el valor del parámetro number of validations (cantidad de validaciones) en 5. Conectar la salida del operador GeneradorConjEjs (Generate Data) a la entrada tra (training) de este operador y la salida ave (averagable, promediable) de este último al conector res (result) del panel.
3. Hacer doble clic sobre el operador XVal (X-Validation). En el panel Training del nivel inferior, agregar el siguiente operador:
3.1 Modeling → Classification and Regression → Support Vector Modeling → Support Vector Machine (LibSVM). Cambiar el nombre del mismo a “AprendizLibSVM” y el valor del parámetro gamma a 1.0. Conectar la entrada tra (training) y salida mod (model) de este operador a los puertos tra y mod del panel, respectivamente
En el panel Testing de la derecha, agregar los siguientes operadores:
3.2 Modeling → Model Application → Apply Model. Cambiar el nombre del mismo a “AplicadorModelo” y conectar los puertos mod y tes del panel a las entradas mod y unl de este operador, respectivamente.
3.3 Modeling → Model Application → Thresholds → Find Threshold. Cambiar el nombre del mismo a “BuscadorUmbral” y tildar la opción show roc plot (mostrar gráfico ROC), además de la opción use example weights (utilizar pesos de las muestras), que está seleccionada por defecto. Conectar la salida lab (labelled data, datos etiquetados) del operador AplicadorModelo (Apply Model) a la entrada exa (example set) de este operador.
3.4 Modeling → Model Application → Thresholds → Apply Threshold. Cambiar el nombre del mismo a “AplicadorUmbral”. Conectar las salidas exa (example set, conjunto de ejemplos) y thr (threshold, umbral) del operador BuscadorUmbral (Find Threshold) a la entradas exa y thr de este operador, respectivamente.
3.5 Evaluation → Performance Measurement → Performance. Conectar la salida exa (example set) del operador AplicarModelo a la entradas lab (labelled data) de este operador y la salida per de éste último al conector ave (averagable) del panel.

4. Ejecutar el proceso y observar el resultado.
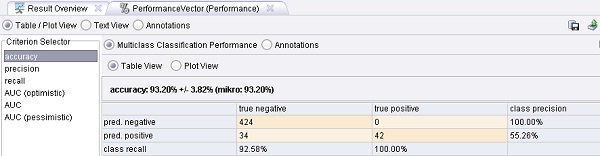
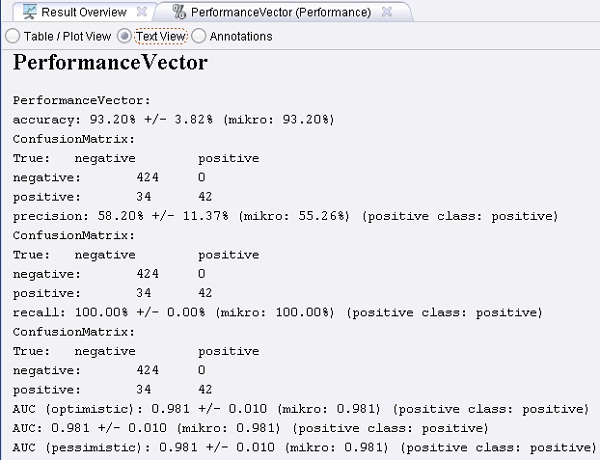
Ejemplo 11: Aprendizaje de Costos Asimétricos
Ejemplo 11: Aprendizaje de Costos Asimétricos bernabeu_dario 26 Octubre, 2010 - 12:16Este proceso muestra cómo se puede obtener un umbral de un clasificador soft (flexible) y aplicarlo a un conjunto independiente de prueba.
El aprendiz utilizado en este proceso realiza predicciones flexibles (soft) en lugar de clasificaciones rígidas (crisp). Las confianzas de predicción entregadas por todos los aprendices de RapidMiner que pueden manejar etiquetas nominales (clasificación) serán utilizadas como predicciones flexibles.
El operador ThresholdFinder se utiliza para determinar el mejor umbral con respecto a los pesos de la clase. En este caso, una clasificación errónea de la primera clase (negativo) tendrá un costo 5 veces mayor que el otro error.
Observe que se debe ejecutar un operador ModelApplier sobre el conjunto de prueba antes de que se pueda encontrar un umbral. Debido a que este modelo debe ser aplicado de nuevo más tarde, el aplicador del modelo guarda el modelo de entrada.
El IOConsumer asegura que la predicción se realiza sobre el conjunto de datos correcto.
Los últimos pasos aplican el modelo y el umbral sobre el conjunto de datos en cuestión.
1. Agregar el operador Utility → Data Generation → Generate Data a la zona de trabajo. Cambiar el nombre del mismo a “GeneradorConjEntren” y los parámetros target function a “polynomial classification” y number of attributes a 20.
2. Agregar el operador Modeling → Classification and Regression → Lazy Modeling → k-NN. Cambiar el nombre del mismo a “VecinosMásCercanos” y el parámetro k a 10. Conectar la salida del operador GeneradorConjEntren (Generate Data) a la entrada tra (training set) de este operador.
3. Agregar otro operador Utility → Data Generation → Generate Data. Cambiar el nombre del mismo a “GeneradorConjPrueba” y los valores de los parámetros target function a “polynomial classification” y number of attributes en 20.
4. Agregar el operador Modeling → Model Application → Apply Model y cambiar el nombre del mismo a “PruebaModelo”. Conectar la salida mod del operador VecinosMásCercanos (k-NN) y la salida del operador GeneradorConjPrueba (Generate Data) a las entradas mod (model) y unl (unlabelled data) de este operador, respectivamente.
5. Agregar el operador Modeling → Model Application → Thresholds → Find Threshold. Cambiar el nombre del mismo a “BuscadorUmbral” y el parámetro misclassification costs second a 2.0. Conectar la salida lab (labelled data) del operador PruebaModelo (Apply Model) a la entrada exa (example set) de este operador.
6. Agregar otro operador Utility → Data Generation → Generate Data. Cambiar el nombre del mismo a “GeneradorConjAplic” y los valores de los parámetros target function a “polynomial classification”, number examples a 200 y number of attributes a 20.
7. Agregar otro operador Modeling → Model Application → Apply Model y cambiar el nombre del mismo a “AplicaciónModelo”. Conectar la salida mod del operador PruebaModelo y la salida del operador GeneradorConjAplic (Generate Data) a las entradas mod y unl de este operador, respectivamente.
8. Agregar el operador Modeling → Model Application → Thresholds → Apply Threshold y cambiar el nombre del mismo a “AplicadorUmbral”. Conectar la salida thr del operador BuscadorUmbral (Find Threshold) y la salida lab del operador AplicaciónModelo (Apply Model) a la entradas y thr y exa de este operador, respectivamente.
9. Agregar el operador Evaluation → Performance Measurement → Performance. Conectar la salida exa (example set) del operador AplicadorUmbral (Apply Threshold) a la entradas lab de este operador y la salida per de éste último al conector res del panel.

| PerformanceVector: accuracy: 74.00% ConfusionMatrix: True: negative positive negative: 86 35 positive: 17 62 precision: 78.48% (positive class: positive) ConfusionMatrix: True: negative positive negative: 86 35 positive: 17 62 recall: 63.92% (positive class: positive) ConfusionMatrix: True: negative positive negative: 86 35 positive: 17 62 AUC (optimistic): 0.843 (positive class: positive) AUC: 0.797 (positive class: positive) AUC (pessimistic): 0.750 (positive class: positive) |
Ejemplo 12: Aprendizaje Sensible al Costo
Ejemplo 12: Aprendizaje Sensible al Costo bernabeu_dario 27 Octubre, 2010 - 11:23Este proceso es otro ejemplo de aprendizaje sensible al costo, es decir, para el caso donde diferentes errores de predicción causarían diferentes costos. Además del operador de preprocesamiento ThresholdFinder, que también es capaz de entregar gráficos ROC para 2 clases, hay otro operador que se puede utilizar para aprendizaje sensible al costo.
Este operador es parte del aprendiz, grupo Meta, y se denomina MetaCost. Se utiliza como cualquier otro esquema de meta-aprendizaje y debe contener otro operador de aprendizaje interno, en este caso se utiliza el
aprendiz de árbol de decisión.
La matriz de costos utilizada para el aprendizaje sensible al costo se puede definir mediante el editor de matrices (en el operador MetaCost, presionar “Edit Matrix...” del parámetro cost matrix). El formato básico
del parámetro cost matrix es [K11 K12 ... K1m, K21 K22 ... K2m, ... ; Kn1 ... Knm], por ejemplo, para una matriz de costos de 2x2 de un problema de clasificación binaria es [0 1 ; 10 0]. Este ejemplo quiere decir
que tanto los costos para los errores de predicción de la primera clase como para los de la segunda son 10 veces más altos que los otros tipos de errores.
1. Agregar el operador Utility → Data Generation → Generate Data. Cambiar el nombre del mismo a “GeneradorConjEjs” y los valores de los parámetros target function a “polynomial classification” y number examples a 300.
2. Agregar el operador Evaluation → Validation → X-Validation. Cambiar el nombre del mismo a “Validación” y el valor del parámetro number of validations a 5. Conectar la salida del operador GeneradorConjEjs (Generate Data) a la entrada tra (training) de este operador y la salida ave (averagable 1) de este último al conector res del panel.
3. Hacer doble clic sobre el operador Validación (X-Validation). En el panel Training del nivel inferior, agregar el siguiente operador:
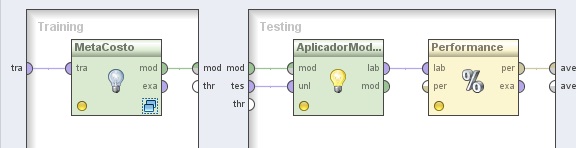
3.1 Modeling → Classification and Regression → Meta Modeling → MetaCost. Cambiar el nombre del mismo a “MetaCosto” y utilizar el editor de matrices del parámetro cost matrix para ingresar los valores de
la matriz de costos [0 1; 10 0]. , Conectar la entrada tra y salida mod de este operador a los puertos tra y mod del panel, respectivamente.
En el panel Testing de la derecha, agregar los siguientes operadores:
3.2 Modeling → Model Application → Apply Model. Cambiar el nombre del mismo a “AplicadorModelo” y conectar los puertos mod y tes del panel a las entradas mod y unl de este operador, respectivamente.
3.3 Agregar el operador Evaluation → Performance Measurement → Performance. Conectar la salida lab del operador AplicadorModelo (Apply Model) a la entradas lab de este operador y la salida per de éste último al conector ave del panel.
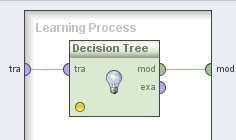
4. Hacer doble clic sobre el operador MetaCosto (MetaCost). En el panel Learning Process del nivel inferior, agregar el siguiente operador:
4.1 Modeling → Classification and Regression → Tree Induction → Decision Tree. Conectar la entrada tra y la salida mod del mismo a los puertos tra y mod del panel, respectivamente.
Resultado:
| PerformanceVector: accuracy: 83.33% +/- 6.58% (mikro: 83.33%) ConfusionMatrix: True: negative positive negative: 145 49 positive: 1 105 precision: 99.20% +/- 1.60% (mikro: 99.06%) (positive class: positive) ConfusionMatrix: True: negative positive negative: 145 49 positive: 1 105 recall: 68.28% +/- 13.00% (mikro: 68.18%) (positive class: positive) ConfusionMatrix: True: negative positive negative: 145 49 positive: 1 105 AUC (optimistic): 0.985 +/- 0.005 (mikro: 0.985) (positive class: positive) AUC: 0.978 +/- 0.013 (mikro: 0.978) (positive class: positive) AUC (pessimistic): 0.976 +/- 0.014 (mikro: 0.976) (positive class: positive) |
Ejemplo 13: Analisis de Componentes Principales
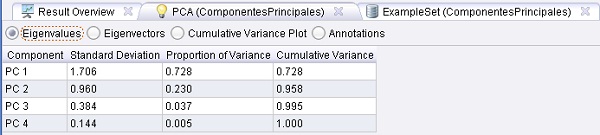
Ejemplo 13: Analisis de Componentes Principales bernabeu_dario 28 Octubre, 2010 - 11:32El cálculo de componentes principales se usa con frecuencia como un paso de procesamiento de la transformación de características. Puede reducir la dimensionalidad del conjunto de datos en cuestión, mientras se preservan las varianzas más importantes de los datos. Ejecutar el proceso y comprobar la salida en la vista gráfica del conjunto de datos Iris cargado y transformado por este proceso.
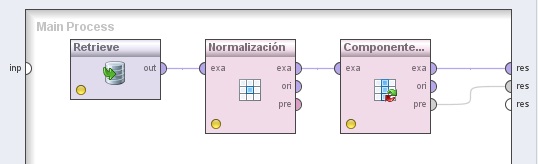
1. Agregar el operador Repository Access → Retrieve a la zona de trabajo y localizar el archivo //Samples/data/Iris con el navegador del parámetro repository entry.
2. Agregar el operador Data Transformation → Value Modification → Numerical Value Modification → Normalize. Cambiar el nombre del mismo a “Normalización” y conectar la salida del operador Retrieve a la entrada exa (example set input) de este operador.
3. Agregar el operador Data Transformation → Attribute Set Reduction and Transformation → Principal Component Analysis. Cambiar el nombre del mismo a “Componentes Principales” y conectar la salida exa del operador Normalización (Normalize) a la entrada exa de este operador, y las salidas exa y pre a sendos conectores res del panel.
Resultados:
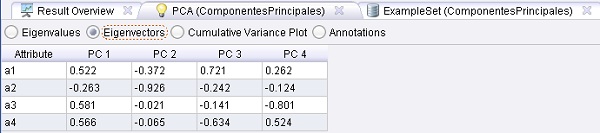
Ejemplo 14: Selección Forward
Ejemplo 14: Selección Forward bernabeu_dario 28 Octubre, 2010 - 13:05Las transformaciones del espacio de atributos pueden facilitar el aprendizaje de manera que simples esquemas de aprendizaje puedan ser capaces de aprender funciones complejas. Esta es la idea básica de la
función kernel. Pero incluso sin esquemas de aprendizaje basados en kernel, la transformación del espacio de características, puede ser necesaria para alcanzar buenos resultados de aprendizaje.
RapidMiner ofrece varios métodos diferentes de selección, construcción, y extracción de características. Este proceso de selección (la muy conocida selección forward) utiliza una validación cruzada interna para la
estimación de la performance. Este elemento sirve como evaluación de la aptitud para todos los conjuntos candidatos de características. Debido a que se toma en cuenta la performance de un determinado esquema
de aprendizaje, nos referimos a los procesos de este tipo como “enfoques wrapper”.
Además, el operador log del proceso grafica los resultados intermedios.
1. Agregar el operador Repository Access → Retrieve a la zona de trabajo y localizar el archivo //Samples/data/Polynomial con el navegador del parámetro repository entry.
2. Agregar el operador Data Transformation → Attribute Set Reduction and Transformation →Selection → Optimization → Optimize Selection. Cambiar el nombre del mismo a “SC” y conectar la salida del operador Retrieve a la entrada exa de este operador, y las salidas exa (example set out), wei (weights) y per (performance) a conectores res del panel.
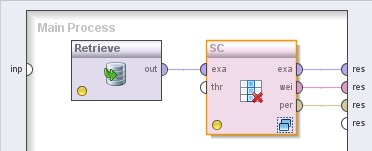
3. Hacer doble clic sobre el operador SC (Optimize Selection). En el panel Evaluation Process del nivel inferior, agregar los siguientes operadores:
3.1 Evaluation → Validation → X-Validation. Cambiar el nombre del mismo a “XValidación” y el parámetro sampling type a “shuffled sampling”. Conectar la entrada exa del panel a la entrada tra (training) de este operador.
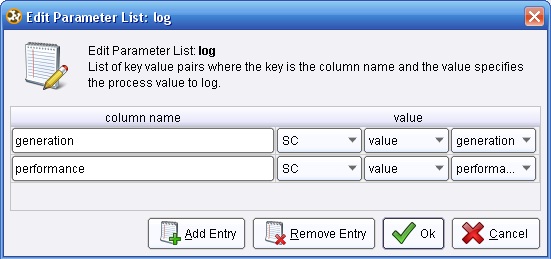
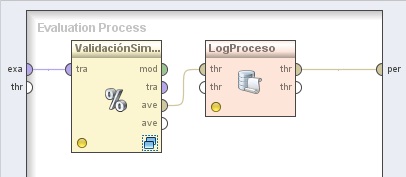
3.2 Utility → Logging → Log. Cambiar el nombre del mismo a “LogProceso” y conectar la salida ave (averagable 1) del operador XValidación (X-Validation) a la entrada thr (through 1) de este operador y la salida (through 1) del mismo, al conector per (performance) del panel. En el parámetro log de este operador editar la lista de parámetros para incluir los campos “generation” y “performance”:
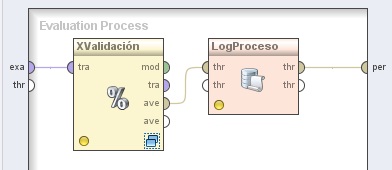
4. Hacer doble clic sobre el operador Validación (X-Validation). En el panel Training del nivel inferior, agregar el siguiente operador:
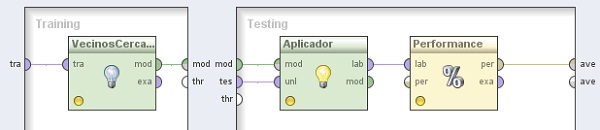
4.1 Modeling → Classification and Regression → Lazy Modeling → k-NN. Cambiar el nombre del mismo a “VecinosCercanos” y el parámetro k a 5. Conectar la entrada tra y salida mod de este operador a los puertos tra y mod del panel, respectivamente
En el panel Testing de la derecha, agregar los siguientes operadores:
4.2 Modeling → Model Application → Apply Model. Cambiar el nombre del mismo a “Aplicador” y conectar los puertos mod y tes del panel a las entradas mod y unl de este operador, respectivamente.
4.3 Evaluation → Performance Measurement → Performance. Conectar la salida lab del operador Aplicador (Apply Model) a la entradas lab de este operador y la salida per de éste último al conector ave del panel.
5. Ejecutar el proceso y cambiar en la vista “Result”, seleccionar la pestaña “Log”. Graficar “performance” contra “generation” del operador de selección de características.
6. Seleccionar el operador de selección de características en el panel del proceso principal. Cambiar el parámetro selection direction de “forward” (selección hacia adelante) a “backward” (eliminación hacia
atrás). Reiniciar el proceso. Todas las características serán seleccionadas.
7. Seleccionar el operador de selección de características. Hacer clic derecho para abrir el menú contextual y reemplazar el operador por otro esquema de selección de características (por ejemplo un algoritmo
genético).
8. Observar la lista del operador de registro del proceso. Cada vez que se aplica recoge los datos especificados. Consultar el Tutorial RapidMiner para más explicaciones. Después de cambiar el operador de selección de características al enfoque de algoritmos genéticos, hay que especificar los valores correctos. Utilizar el operador de registro de proceso para registrar los valores en línea.
Ejemplo 15: Selección Multiobjetivos
Ejemplo 15: Selección Multiobjetivos bernabeu_dario 8 Noviembre, 2010 - 11:22Este es otro enfoque muy simple de selección genética de características. Debido a otro esquema de selección, el operador de selección de características no sólo intenta maximizar la performance entregada
por el evaluador del conjunto de características, sino que también intenta minimizar el número de características. El resultado es un gráfico de Pareto diagramado durante la optimización.
Después de finalizada la optimización, el usuario puede hacer doble clic en las soluciones óptimas de Pareto y ver qué conjunto de características está representado por un punto. El gráfico de Pareto no sólo brinda una mejor comprensión de la cantidad total de características necesarias, sino también la compensación entre la cantidad de características y el rendimiento, y un ranking de características.
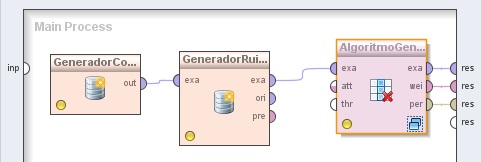
1. Agregar el operador Utility → Data Generation → Generate Data. Cambiar el nombre del mismo a “GeneradorConjEjs” y los valores de los parámetros target function a “sum classification”, number examples a 200, y number of attributes a 10.
2. Agregar el operador Utility → Data Generation → Add Noise. Cambiar el nombre del mismo a “GeneradorRuido” y los valores de los parámetros random attributes a 10 y label noise a 0.0. Conectar la salida del operador GeneradorConjEjs (Generate Data) a la entrada exa de este operador.
3. Agregar el operador Data Transformation → Attribute Set Reduction and Transformation → Selection → Optimization → Optimize Selection (Evolutionary). Cambiar el nombre del mismo a “AlgoritmoGenético” y los valores de los parámetros population size (tamaño de la población) a 30 y máximum number of generations a 15. Conectar la salida exa del operador GeneardorRuido (Add Noise) a la entrada exa de este operador, y las salidas exa (example set out), wei (weights) y per (performance) a conectores res del panel.
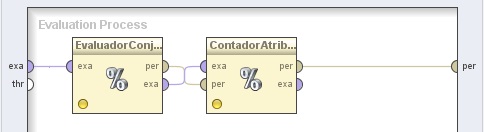
4. Hacer doble clic sobre el operador AlgoritmoGenético (Optimize Selection (Evolutionary)). En el panel Evaluation Process del nivel inferior, agregar los siguientes operadores:
4.1 Evaluation → Attributes → Performance (CFS). Cambiar el nombre del mismo a “EvaluadorConjCaractsCFS” y conectar la entrada exa del panel a la entrada exa de este operador.
4.2 Evaluation → Attributes → Performance (Attribute Count) y cambiar el nombre del mismo a “ContadorAtributos”. Conectar las salidas per y exa del operador EvaluadorConjCaractsCFS (Performance (CFS)) a las entradas per y exa de este operador, respectivamente, y la salida per de éste último al conector per del panel.
Ejemplo 16: Validación Wrapper
Ejemplo 16: Validación Wrapper bernabeu_dario 8 Noviembre, 2010 - 12:01Así como en el aprendizaje, también es posible que ocurra overfitting (sobreajuste) durante el preprocesamiento. Para estimar la performance de generalización de un método de preprocesamiento, RapidMiner soporta varios operadores de validación para los pasos de preprocesamiento. La idea básica es la misma que para todos los otros operadores de validación con una ligera diferencia: el primer operador interno debe producir un conjunto de ejemplos transformado, el segundo debe producir un modelo de ese conjunto de datos transformado y el tercer operador debe producir un vector de performance de ese modelo
sobre un conjunto de prueba apartado y transformado de la misma forma.
Este es un proceso más complejo que muestra la capacidad de RapidMiner para construir procesos a partir de elementos ya conocidos. En este proceso, se utiliza una variante especial de un operador de validación cruzada para estimar la performance de una transformación del espacio de características, es decir, la simple selección de características forward en este caso.
El bloque de construcción completo de selección de características es ahora el primer operador interno de un WrapperXValidation que, al igual que la validación cruzada normal, utiliza un subconjunto para la
transformación del espacio de características y el aprendizaje basado en el conjunto de características determinado. Una segunda cadena de aplicadores se utiliza para estimar la performance sobre un conjunto
de pruebas que no fue utilizado para el aprendizaje y la selección de características. La performance estimada y un vector de pesos de atributos se devuelven como resultado.
Observe el MinMaxWrapper después del evaluador de performance interno. Este operador encapsula los criterios de performance dados de tal manera que no sólo los valores medios, sino también los valores
mínimos se calculan durante la validación cruzada. Arbitrariamente las combinaciones lineales ponderadas de las medias mínima y normal conducen a mejorar la capacidad de generalización. Sólo cambiar el parámetro weighting (ponderación) a 0,0 o desactivar el operador en el menú contextual o eliminarlo del proceso para ver el efecto. La performance disminuye rápidamente cuando se utiliza solamente la performance media como criterio de selección.
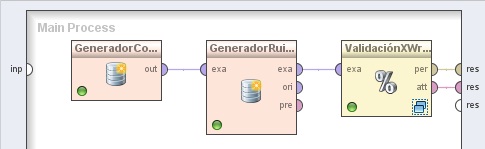
1. Agregar el operador Utility → Data Generation → Generate Data. Cambiar el nombre del mismo a “GeneradorConjEjs” y los valores de los parámetros target function a “sum”, number examples a 60, y number of attributes a 3.
2. Agregar el operador Utility → Data Generation → Add Noise. Cambiar el nombre del mismo a “GeneradorRuido” y el valor del parámetro random attributes a 3. Conectar la salida del operador GeneradorConjEjs (Generate Data) a la entrada exa de este operador.
3. Agregar el operador Evaluation → Validation → Wrapper-X-Validation y cambiar el nombre del mismo a “ValidaciónXWrapper”. Conectar la salida exa del operador GeneradorRuido (Add Noise) a la entrada exa de este operador, y las salidas per (performance vector out) y att (attribute weights out) de éste último a los conectores res del panel.
4. Hacer doble clic sobre el operador ValidaciónXWrapper (Wrapper-X-Validation). En el panel Attribute Weighting del nivel inferior, agregar el siguiente operador:
4.1 Agregar el operador Data Transformation → Attribute Set Reduction and Transformation → Selection → Optimization → Optimize Selection. Cambiar el nombre del mismo a “SelecciónCaracterísticas”. Conectar la entrada wei (weighting set source) del panel a la entrada exa de este operador y la salida wei (weights) del mismo al conector att (attribute weights sink) del panel.
En el panel Model Building central, agregar el siguiente operador:
4.2 Agregar el operador Modeling → Classification and Regression → Support Vector Modeling → Support Vector Machine y cambiar el nombre del mismo a “Aprendiz”. Conectar la entrada tra del panel a la entrada tra de este operador y la salida mod del mismo al conector mod del panel.
En el panel Model Evaluation de la derecha, agregar los siguientes operadores:
4.3 Modeling → Model Application → Apply Model. Cambiar el nombre del mismo a “AplicadorModelo” y conectar los puertos mod y tes del panel a las entradas mod y unl de este operador, respectivamente.
4.4 Evaluation → Performance Measurement → Classification and Regression → Performance (Regression) y cambiar el nombre del mismo a “EvaluaciónWrapper”. Quitar la tilde de la opción root mean squared error y tildar la opción squared error. Conectar la salida lab del operador AplicadorModelo (Apply Model) a la entradas lab de este operador y la salida per de éste último al conector per del panel.

5. Hacer doble clic sobre el operador SelecciónCaracterísticas (Optimize Selection) del panel izquierdo.
En el panel Evaluation Process del nivel inferior, agregar el siguiente operador:
5.1 Evaluation → Validation → X-Validation. Cambiar el nombre del mismo a “ValidaciónXFS” y el valor del parámetro sampling type (tipo de muestreo) a “shuffled sampling”. Conectar la entrada exa del panel a la entrada tra de este operador y la salida ave (averagable 1) del mismo al conector per del panel
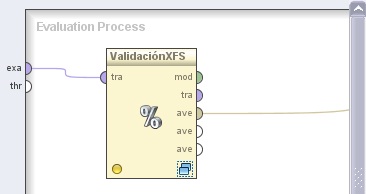
6. Hacer doble clic sobre el operador ValidaciónXFS (X-Validation) anterior. En el panel Training del nivel inferior, agregar el siguiente operador:
6.1 Modeling → Classification and Regression → Support Vector Modeling → Support Vector Machine y cambiar el nombre del mismo a “AprendizFS”. Conectar la entrada tra del panel a la entrada tra de este operador y las salidas mod y wei del mismo a los conectores mod y thr del panel, respectivamente
En el panel Testing de la derecha, agregar los siguientes operadores:
6.2 Modeling → Model Application → Apply Model. Cambiar el nombre del mismo a “AplicadorModeloFS” y conectar los puertos mod y tes del panel a las entradas mod y unl de este operador, respectivamente.
6.3 Evaluation → Performance Measurement → Classification and Regression → Performance (Regression) y cambiar el nombre del mismo a “EvaluaciónFS”. Quitar la tilde de la opción root mean squared error y tildar la opción squared error. Conectar la salida lab del operador AplicadorModeloFS (Apply Model) a la entradas lab de este operador.
6.4 Evaluation → Performance Measurement → Performance (Min-Max) y cambiar el nombre del mismo a “FSMinMaxWrapper” y el parámetro mínimum weights a 0.5. Conectar la salida per del operador EvaluaciónFS (Performance (Regression)) a la entradas per de este operador y la salida per de éste último al conector ave (averagable 1) del panel. Conectar además el puerto thr de este panel al conector ave
(averagable 2) del mismo.

Ejemplo 17: YAGGA
Ejemplo 17: YAGGA bernabeu_dario 8 Noviembre, 2010 - 12:21Algunas veces la selección de características sola no es suficiente. En estos casos se deben realizar otras transformaciones del espacio de características. La generación de nuevos atributos a partir de los atributos dados amplía el espacio de características. Tal vez se pueda encontrar fácilmente una hipótesis en el espacio ampliado de características.
YAGGA (Yet Another Generating Genetic Algorithm) es un wrapper híbrido de selección/generación de características. La estimación de la performance se hace con un elemento interno de validación cruzada. Por
supuesto, otras formas de estimación de la performance también son posibles. La probabilidad de generación de características depende de la probabilidad para la eliminación de características. Esto asegura
que la longitud media de los conjuntos de características se mantenga hasta que los conjuntos de características más cortos o más largos demuestran ser mejores.
Cuando YAGGA termina la transformación, se construyeron nuevas características. En muchos casos, este conjunto óptimo de características debería utilizarse sobre otros datos, también. Por lo tanto, el conjunto
óptimo de atributos se escribe en un archivo. En el siguiente ejemplo veremos cómo se pueden utilizar estos archivos para transformar nuevos datos en la representación óptima de aprendizaje.
1. Agregar el operador Repository Access → Retrieve a la zona de trabajo y localizar el archivo //Samples/data/Polynomial con el navegador del parámetro repository entry.
2. Agregar el operador Data Transformation → Attribute Set Reduction and Transformation → Generation → Optimization → Optimize by Generation (YAGGA). Cambiar el nombre del mismo a “YAGGA” y los valores de los parámetros population size a 100, maximum number of generations a 10 y quitar la tilde de use plus. Conectar la salida del operador Retrieve a la entrada exa de este operador.
3. Agregar el operador Export → Attributes → Write Constructions. Cambiar el nombre del mismo a “GrabadorConstrucciones”. Con el navegador del parámetro attibute constructions file localizar la ubicación para un archivo que se va a denominar yagga.att. Conectar la salida exa del operador YAGGA (Optimize by Generation) a la entrada inp de este operador y la salida thr de este último al conector res del panel.
4. Agregar el operador Export → Attributes → Write Weights. Cambiar el nombre del mismo a “GrabadorPesos”. Con el navegador del parámetro attibute weights file localizar la ubicación para un archivo que se va a denominar yagga.wgt. Conectar la salida att del operador YAGGA a la entrada inp de este operador y la salida thr de este último a otro conector res del panel.
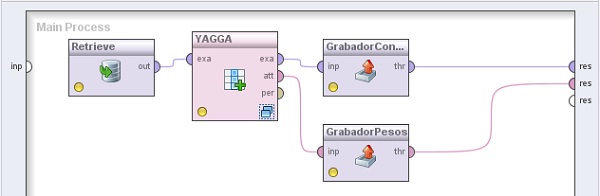
5. Hacer doble clic sobre el operador YAGGA. En el panel Evaluation Process del nivel inferior, agregar los siguientes operadores:
5.1 Evaluation → Validation → Split Validation y cambiar el nombre del mismo a “ValidaciónSimple”. Conectar la entrada exa del panel a la entrada tra (training) de este operador.
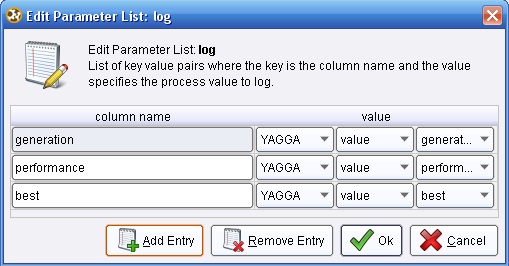
5.2 Utility → Logging → Log. Cambiar el nombre del mismo a “LogProceso”. Conectar la salida ave (averagable 1) del operador ValidaciónSimple (Split Validation) a la entrada thr (through 1) de este operador y la salida (through 1) del mismo, al conector per (performance) del panel. En el parámetro log de este operador editar la lista de parámetros para incluir los campos “generation”, “performance” y “best”:
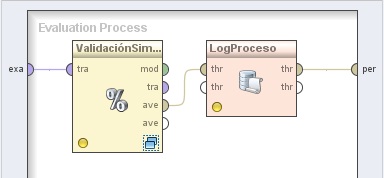
6. Hacer doble clic sobre el operador ValidaciónSimple. En el panel Training del nivel inferior, agregar el siguiente operador:
6.1 Modeling → Classification and Regression → Function Fitting → Linear Regression y cambiar el nombre del mismo a “Regresión Lineal”. Conectar la entrada tra y salida mod de este operador a los puertos tra y mod del panel, respectivamente
En el panel Testing de la derecha, agregar los siguientes operadores:
6.2 Modeling → Model Application → Apply Model. Cambiar el nombre del mismo a “Aplicador” y conectar los puertos mod y tes del panel a las entradas mod y unl de este operador, respectivamente.
6.3 Agregar el operador Evaluation → Performance Measurement → Classification and Regression → Performance (Regression). Conectar la salida lab del operador Aplicador (Apply Model) a la entradas lab de este operador y la salida per de éste último al conector ave del panel.
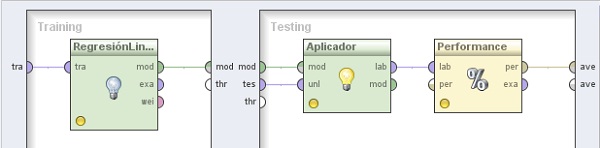
7. Ejecutar el proceso. Se entrega como resultado el conjunto transformado de ejemplos de entrada, la estimación de la performance, y un vector de pesos.
8. Intente agregar un operador log (registro) de proceso. Debido a que YAGGA sólo permite un operador interno, hay que agregar una cadena de un solo operador (desde el grupo “core”) a YAGGA. Hacer clic
derecho sobre el operador de validación cruzada y seleccionar cortar y pegar la validación cruzada en la cadena agregada. Agregar un operador log de proceso en la cadena. Agregar los valores que desea graficar a
la lista de parámetros del operador log de proceso. Consultar el Tutorial RapidMiner para más explicaciones.
- Una cadena de un solo operador para combinar varios operadores.
- Corta un operador del árbol de operadores.
- Pega un operador previamente cortado en la cadena de operadores seleccionada.
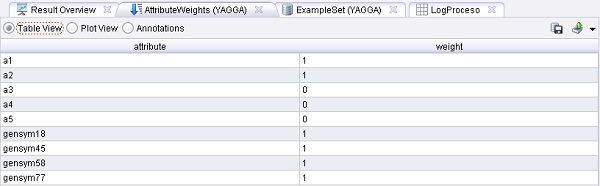
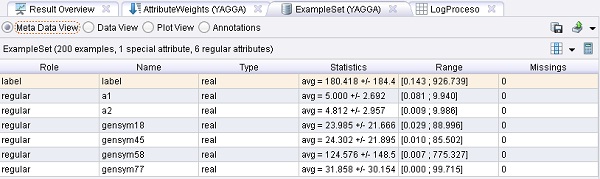
Ejemplo 18: Configuración atributos resultantes de YAGGA
Ejemplo 18: Configuración atributos resultantes de YAGGA bernabeu_dario 8 Noviembre, 2010 - 13:47En el proceso anterior se buscó un conjunto óptimo de atributos (por favor, asegurarse de ejecutar los procesos anteriores, antes de iniciar este proceso). Este conjunto óptimo de atributos se carga y se aplica a
otros datos de entrada. Esto es necesario para aplicar un modelo aprendido a partir de datos con la misma representación de entrada.
1. Agregar el operador Repository Access → Retrieve a la zona de trabajo y localizar el archivo //Samples/data/Polynomial con el navegador del parámetro repository entry.
2. Agregar el operador Import → Attributes → Read Constructions. Cambiar el nombre del mismo a “CargadorConstrucAtrib”. Con el navegador del parámetro attibute constructions file localizar el archivo yagga.att. Tildar la opción keep all. Conectar la salida del operador Retrieve a la entrada exa de este operador.
3. Agregar el operador Import → Attributes → Read Weights. Cambiar el nombre del mismo a “CargadorPesosAtributos”. Con el navegador del parámetro attibute weights file localizar el archivo yagga.wgt.
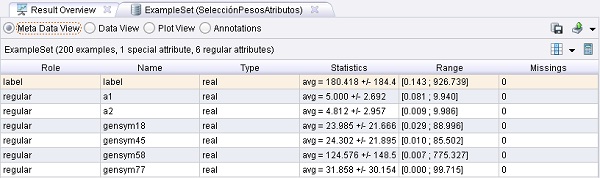
4. Agregar el operador Data Transformation → Attribute Set Reduction and Transformation → Selection → Select by Weights. Cambiar el nombre del mismo a “SelecciónPesosAtributos”. Conectar la salida exa del operador CargadorConstrucAtrib (Read Constructions) y la salida out del operador CargadorPesosAtributos (Read Weights) a las entradas exa y wei de este operador, respectivamente. También conectar la salida exa de este operador al conector res del panel.
5. Ejecutar el proceso. Después de unos momentos, el conjunto de ejemplos de entrada utiliza la representación óptima de características que fueron encontradas en el proceso anterior.
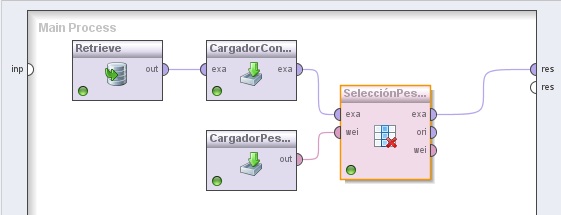
Ejemplo 19: Generación de Características Definidas por el Usuario
Ejemplo 19: Generación de Características Definidas por el Usuario bernabeu_dario 9 Noviembre, 2010 - 10:51Este proceso carga datos numéricos desde el archivo y genera algunos atributos con el operador de generación de características. La lista de parámetros functions del operador de generación debe ser editada
para definir las funciones que se deben generar.
1. Agregar el operador Repository Access → Retrieve a la zona de trabajo y localizar el archivo //Samples/data/Polynomial con el navegador del parámetro repository entry.
2. Agregar el operador Data Transformation → Attribute Set Reduction and Transformation → Generation → Generate Attributes. Cambiar el nombre del mismo a “Generación”. Conectar la salida del operador Retrieve a la entrada exa de este operador y la salida exa de este último al conector res del panel.
Con el editor del parámetro function descritions, agregar las siguientes funciones:
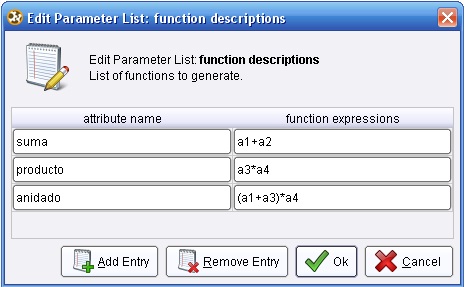
3. Ejecutar el proceso. Utilizar puntos de interrupción para comprobar el paso de generación. El parámetro keep_all (modo experto) define si todos los atributos deben ser utilizados para el conjunto de ejemplos
resultante o sólo los atributos recientemente generados.
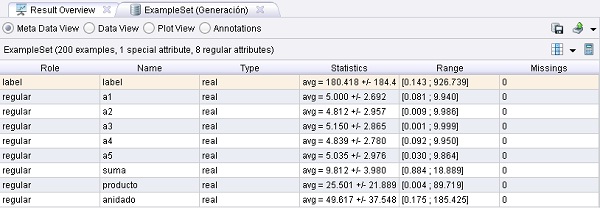
4. Editar la lista de parámetros functions y agregar algunas otras funciones. Se pueden utilizar la mayoría de las funciones matemáticas conocidas.
Ejemplo 20: Ponderación Evolutiva
Ejemplo 20: Ponderación Evolutiva bernabeu_dario 9 Noviembre, 2010 - 11:34Este es otro proceso de ejemplo más complejo. Utiliza una cadena de validación interna (en este caso una validación simple en lugar de una validación cruzada) para estimar la performance de un aprendiz con
respecto a los pesos de los atributos. Estos son adaptados con un enfoque de ponderación evolutiva.
Como se puede observar, la estructura general del proceso es muy similar a los procesos de selección y generación de características. En todos los casos se utiliza una cadena de validación interna como bloque de construcción para estimar la performance. El operador padre ("EvolutionaryWeighting" en este caso) realiza algunas operaciones sobre el conjunto de características que es evaluado por el operador hijo (validación simple).
1. Agregar el operador Repository Access → Retrieve a la zona de trabajo y localizar el archivo //Samples/data/Weighting con el navegador del parámetro repository entry.
2. Agregar el operador Modeling → Attribute Weighting → Optimization → Optimize Weights (Evolutionary). Cambiar el nombre del mismo a “PonderaciónEvolutiva” y los parámetros population size y maximum number of generations a 1 y 10, respectivamente. Conectar la salida del operador Retrieve a la entrada exa de este operador, y las salidas exa (example set out), wei (weights) y per (performance) a conectores res del panel.
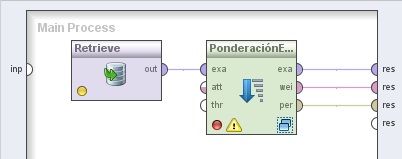
3. Hacer doble clic sobre el operador PonderaciónEvolutiva (Optimize Weights (Evolutionary)). En el panel Evaluation Process del nivel inferior, agregar los siguientes operadores:
3.1 Evaluation → Validation → Split Validation. Cambiar el nombre del mismo a “ValidaciónSimple”. Conectar la entrada exa del panel a la entrada tra (training) de este operador.
3.2 Utility → Logging → Log. Cambiar el nombre del mismo a “LogProceso” y conectar la salida ave (averagable 1) del operador ValidaciónSimple (Split Validation) a la entrada thr (through 1) de este operador y la salida (through 1) del mismo, al conector per (performance) del panel. En el parámetro log de este operador editar la lista de parámetros para incluir los campos “Generación”, “MejorPerf” y “Performance”:
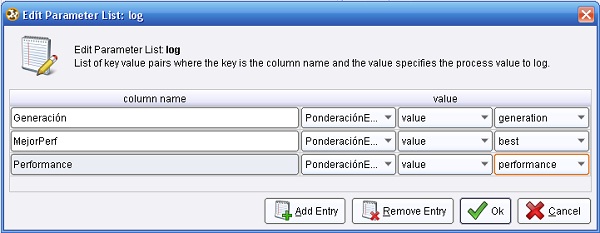
4. Hacer doble clic sobre el operador ValidaciónSimple. En el panel Training del nivel inferior, agregar el siguiente operador:
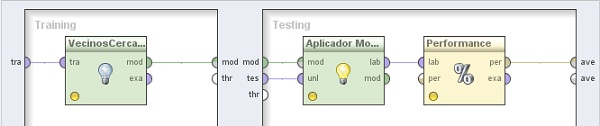
4.1 Modeling → Classification and Regression → Lazy Modeling → k-NN. Cambiar el nombre del mismo a “VecinosCercanos”. Conectar la entrada tra y salida mod de este operador a los puertos tra y mod del panel, respectivamente
En el panel Testing de la derecha, agregar los siguientes operadores:
4.2 Modeling → Model Application → Apply Model. Cambiar el nombre del mismo a “AplicadorModelo” y conectar los puertos mod y tes del panel a las entradas mod y unl de este operador, respectivamente.
4.3 Evaluation → Performance Measurement → Performance. Conectar la salida lab del operador AplicadorModelo (Apply Model) a la entradas lab de este operador y la salida per de éste último al conector ave del panel.
5. Ejecutar el proceso. Cambiar a la vista “Result” y utilizar el graficador en línea. Presionar el icono “stop”  de la barra de iconos para detener el proceso. El operador actual finalizará su operación en segundo plano y puede durar algún tiempo hasta que el proceso sea detenido completamente. Aunque puede cambiar el proceso actual y reiniciarlo, se ejecutará más lento hasta que el proceso anterior sea detenido completamente.
de la barra de iconos para detener el proceso. El operador actual finalizará su operación en segundo plano y puede durar algún tiempo hasta que el proceso sea detenido completamente. Aunque puede cambiar el proceso actual y reiniciarlo, se ejecutará más lento hasta que el proceso anterior sea detenido completamente.
Ejemplo 21: Visualización del Conjunto de Datos y Pesos
Ejemplo 21: Visualización del Conjunto de Datos y Pesos bernabeu_dario 9 Noviembre, 2010 - 12:42En este proceso se carga un conjunto de datos y se aplica uno de los esquemas de ponderación de características disponible en RapidMiner sobre este conjunto de datos. Después de que el proceso ha terminado, cambiar a la vista gráfica del conjunto de ejemplos, y observar los graficadores de alta dimensionalidad disponibles, como el gráfico paralelo, el gráfico survey, los gráficos RadViz o GridViz, matriz de histograma, matriz de cuartiles y las variantes coloreadas de estos gráficos. Notará que algunas de las columnas están marcadas con un color amarillento, por ejemplo, por un rectángulo alrededor o directamente en el gráfico. Estas marcas amarillas indican el peso de los atributos correspondientes y el color es más intenso si el peso correspondiente es mayor.
Este proceso demuestra la capacidad de RapidMiner para presentar varios resultados mediante la combinación de ellos. Por supuesto, todavía se puede tener una vista de la tabla de pesos o las diferentes vistas gráficas de los pesos de los atributos.
1. Agregar el operador Repository Access → Retrieve a la zona de trabajo y localizar el archivo //Samples/data/Sonar con el navegador del parámetro repository entry.
2. Agregar el operador Modeling → Attribute Weighting → Weight by Chi Squared Statistic. Cambiar el nombre del mismo a “PonderaciónChiCuadrado”. Conectar la salida del operador Retrieve a la entrada exa de este operador y las salidas wei y exa de este último a conectores res del panel.
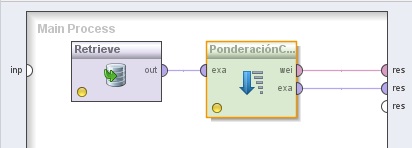
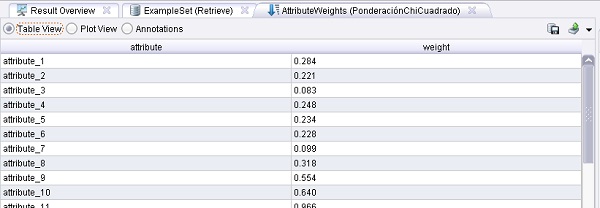
Ejemplo 22: Optimización de Parámetros
Ejemplo 22: Optimización de Parámetros bernabeu_dario 9 Noviembre, 2010 - 12:59A menudo los diferentes operadores tienen muchos parámetros y no está claro qué valores de los parámetros son los mejores para la tarea de aprendizaje en cuestión. El operador de optimización de parámetros ayuda a encontrar un conjunto óptimo de parámetros para los operadores utilizados.
La validación cruzada interna estima la performance para cada conjunto de parámetros. En este proceso se afinan 2 parámetros de la SVM. El resultado puede ser graficado en 3D (utilizando gnuplot) o en modo de
color.
1. Agregar el operador Repository Access → Retrieve a la zona de trabajo y localizar el archivo //Samples/data/Polynomial con el navegador del parámetro repository entry.
2. Process Control → Parameter → Optimize Parameters (Grid). Cambiar el nombre del mismo a “OptimizaciónParámetros”. Conectar la salida del operador Retrieve a la entradas inp (input 1) de este operador y la salida per de éste último al conector res del panel.
3. Agregar el operador Repository Access → Store a la zona de trabajo y la ruta //RapidMiner/results/Parameter-set en el parámetro repository entry. Cambiar el nombre del mismo a “OptimizaciónParámetros”. Conectar la salida par del operador Optimize Parameters (Grid) a la entradas inp (input) de este operador y la salida thr (through) de éste último a otro conector res del panel.
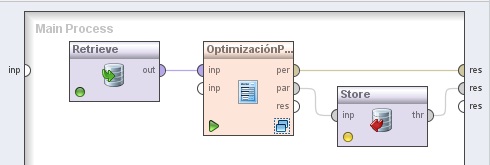
4. Hacer doble clic sobre el operador OptimizaciónParámetros (Optimize Parameters (Grid)). En el panel Optimization Process del nivel inferior mostrado, agregar los siguientes operadores:
4.1 Evaluation → Validation → X-Validation. Cambiar el nombre del mismo a “Validación” y el valor del parámetro sampling type (tipo de muestreo) a “shuffled sampling”. Conectar la entrada inp del panel a la entrada tra de este operador.
4.2 Utility → Logging → Log. Conectar la salida ave (averagable 1) del operador Validación (XValidation) a la entrada thr (through 1) de este operador y la salida (through 1) del mismo, al conector per (performance) del panel.
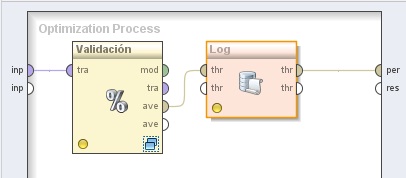
5. Hacer doble clic sobre el operador Validación (X-Validation). En el panel Training del nivel inferior, agregar el siguiente operador:
5.1 Modeling → Classification and Regression → Support Vector Modeling → Support Vector Machine (LibSVM). Cambiar el nombre del mismo a “Entrenamiento” y los valores de los parámetros svm type a “epsilon-SVR”, kernel type a “poly”, degree a 5 y C a 250.0. Conectar la entrada tra (training) y salida mod (model) de este operador a los puertos tra y mod del panel, respectivamente
En el panel Testing de la derecha, agregar los siguientes operadores:
5.2 Modeling → Model Application → Apply Model. Cambiar el nombre del mismo a “Prueba” y conectar las entradas mod y tes del panel a las entradas mod y unl de este operador, respectivamente.
5.3 Evaluation → Performance Measurement → Classification and Regression → Performance (Regression). Cambiar el nombre del mismo a “Evaluación” y tildar las siguientes opciones (además root mean squared error, tildada por defecto): absolute error (error absoluto) y normalized absolute error (error absoluto normalizado). Conectar la salida lab del operador Prueba (Apply Model) a la entrada lab de este operador y la salida per de éste último al conector ave del panel.
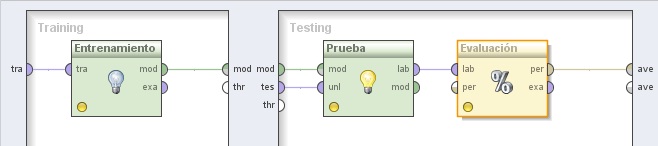
6. Subir un nivel. Seleccionar el operador Log y editar la lista de parámetros para incluir los campos “C”, “grado” y “absoluto” de la siguiente manera:
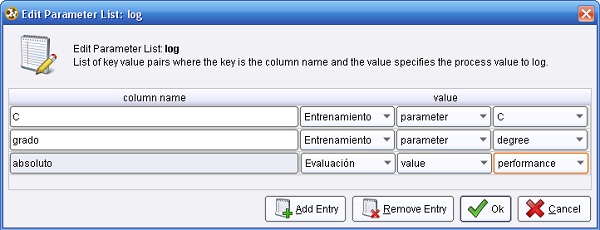
7. Volver al nivel superior (Proceso Principal), seleccionar el operador OptimizaciónParámetros y utilizar el editor para seleccionar los parámetros C y degree del operador Entrenamiento (Support Vector Machine (LibSVM)):
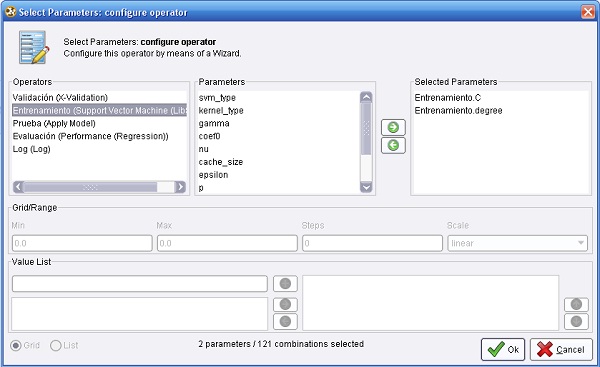
8. Ejecutar el proceso. El resultado es el mejor conjunto de parámetros y la performance lograda con ese conjunto de parámetros.
9. Editar la lista de parámetros del operador ParameterOptimization para encontrar otro conjunto de parámetros.
Ejemplo 23: Habilitador de Operadores
Ejemplo 23: Habilitador de Operadores bernabeu_dario 9 Noviembre, 2010 - 13:41Este meta-proceso muestra otra posibilidad de optimizar automáticamente el diseño del proceso. El operador "OperatorEnabler" se puede utilizar para habilitar o deshabilitar uno de sus hijos. Este se puede utilizar junto con uno de los operadores de optimización de parámetros para comprobar qué operadores se deben emplear para obtener resultados óptimos. Esto es especialmente útil para determinar qué operadores de preprocesamiento se deben usar para una combinación particular de conjunto de datos-aprendiz.
1. Agregar el operador Repository Access → Retrieve a la zona de trabajo y localizar el archivo //Samples/data/Ripley-Set con el navegador del parámetro repository entry.
2. Process Control → Parameter → Optimize Parameters (Grid). Cambiar el nombre del mismo a “GridOptimizaciónParámetros”. Conectar la salida del operador Retrieve a la entradas inp (input 1) de este operador y las salidas per (performance) y par (parameter) de éste último conectores res del panel.
3. Hacer doble clic sobre el operador OptimizaciónParámetros (Optimize Parameters (Grid)). En el panel Optimization Process del nivel inferior mostrado, agregar los siguientes operadores:
3.1 Process Control → Branch → Select Subprocess. Cambiar el nombre del mismo a “OperadorHabilitador” y el valor del parámetro select which a 2. Conectar la entrada inp del panel a la entrada inp (input 1) de este operador.
3.2 Evaluation → Validation → X-Validation. Cambiar el nombre del mismo a “XValidación” y el valor del parámetro number of validations a 5. Conectar la salida out (output 1) del operador OperadorHabilitador (Select Subprocess) a la entrada tra de este operador.
3.3 Utility → Logging → Log. Conectar la salida ave (averagable 1) del operador XValidación (XValidation) a la entrada thr (through 1) de este operador y la salida (through 1) del mismo, al conector per (performance) del panel. En el parámetro log de este operador editar la lista de parámetros para incluir los campos “habilitar_normalización” y “performance”:
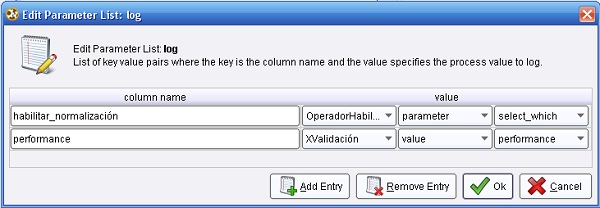
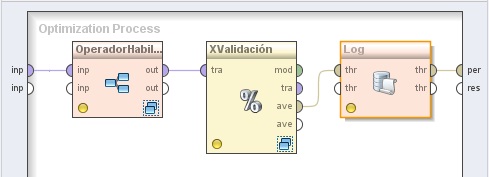
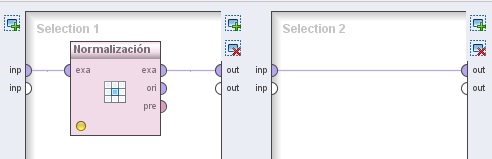
4. Hacer doble clic sobre el operador OperadorHabilitador. En el panel Selection 1 del nivel inferior mostrado, agregar el siguiente operador:
4.1 Data Transformation → Value Modification → Numerical Value Modification → Normalize. Cambiar el nombre del mismo a “Normalización”. Conectar la entrada inp del panel a la entrada exa de este operador y la salida exa de este último al conector out del panel.
4.2 En el panel Selection 2 de la derecha sólo conectar los puertos inp y out del mismo.
5. Subir un nivel y hacer doble clic sobre el operador XValidación. En el panel Training del nivel inferior mostrado, agregar el siguiente operador:
5.1 Modeling → Classification and Regression → Bayesian Modeling → Naive Bayes. Conectar la entrada tra y salida mod del mismo a los puertos tra y mod del panel, respectivamente.
6. En el panel Testing de la derecha, agregar los siguientes operadores:
6.1 Modeling → Model Application → Apply Model. Cambiar el nombre del mismo a “AplicadorModelo” y conectar los puertos mod y tes del panel a las entradas mod y unl de este operador, respectivamente.
6.2 Agregar el operador Evaluation → Performance Measurement → Performance. Conectar la salida lab del operador AplicadorModelo (Apply Model) a la entradas lab de este operador y la salida per de éste último al conector ave del panel.
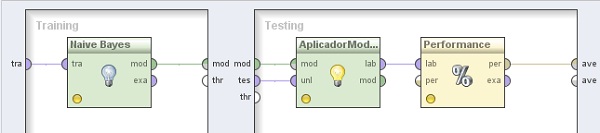
7. Volver al nivel superior (Proceso Principal), seleccionar el operador GridOptimizaciónParámetros y utilizar el editor para seleccionar el parámetro select which del operador OperadorHabilitador (Select Subprocess):
Resultado del GridOptimizaciónParámetros (Grid):
|
Conjunto de Parámetros:
Performance:
PerformanceVector [
-----accuracy: 85.20% +/- 4.12% (mikro: 85.20%)
ConfusionMatrix:
True: 0 1
0: 104 16
1: 21 109
-----precision: 84.18% +/- 4.81% (mikro: 83.85%) (positive class: 1)
ConfusionMatrix:
True: 0 1
0: 104 16
1: 21 109
-----recall: 87.20% +/- 8.54% (mikro: 87.20%) (positive class: 1)
ConfusionMatrix:
True: 0 1
0: 104 16
1: 21 109
-----AUC (optimistic): 0.934 +/- 0.026 (mikro: 0.934) (positive class: 1)
-----AUC: 0.934 +/- 0.026 (mikro: 0.934) (positive class: 1)
-----AUC (pessimistic): 0.934 +/- 0.026 (mikro: 0.934) (positive class: 1)
]
OperadorHabilitador.select_which = 1
|
Ejemplo 24: Umbral de Ponderación
Ejemplo 24: Umbral de Ponderación bernabeu_dario 10 Noviembre, 2010 - 10:50Este proceso intenta encontrar el mejor umbral de selección para los pesos proporcionados por un aprendiz de SVM. Los pesos y el conjunto de ejemplos se pasan a un optimizador de parámetros. El parámetro weight del operador de Selección se ha optimizado con una grid search. La performance de este umbral se evalúa con el bloque de construcción de validación cruzada. Por favor consulte los meta-procesos de
ejemplos anteriores para más detalles con respecto a los operadores de optimización de parámetros.
1. Agregar el operador Repository Access → Retrieve a la zona de trabajo y localizar el archivo //Samples/data/Weighting con el navegador del parámetro repository entry.
2. Agregar el operador Modeling → Classification and Regression → Support Vector Modeling → Support Vector Machine. Cambiar el nombre del mismo a “PesosIniciales” y quitar la tilde de la opción scale. Conectar la salida del operador Retrieve a la entrada tra de este operador.
3. Process Control → Parameter → Optimize Parameters (Grid). Cambiar el nombre del mismo a “GridOptimizaciónParámetros”. Conectar las salidas exa y wei del operador PesosIniciales (Support Vector Machine) a las entradas inp (input 1) e inp (input 2) de este operador, respectivamente, y las salidas per (performance), par (parameter) y res (result 1) de éste último conectores res del panel.
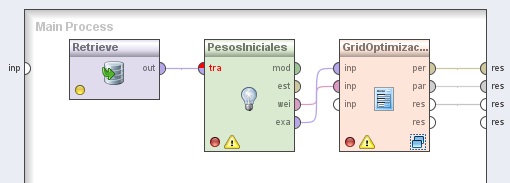
4. Hacer doble clic sobre el operador OptimizaciónParámetros (Optimize Parameters (Grid)). En el panel Optimization Process del nivel inferior mostrado, agregar los siguientes operadores:
4.1 Data Transformation → Attribute Set Reduction and Transformation → Selection → Select by Weights. Cambiar el nombre del mismo a “Selección” y el parámetro weight a 1.0. Conectar las entradas inp (input 1) e inp (input 2) del panel a las entradas exa y wei de este operador, respectivamente.
4.2 Evaluation → Validation → X-Validation. Cambiar el nombre del mismo a “XValidación”. Conectar la salida exa del operador Selección (Select by Weights) a la entrada tra de este operador y la salida ave (averagable 1) de este último al conector per del panel.
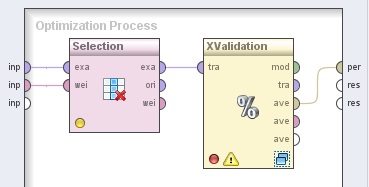
5. Hacer doble clic sobre el operador XValidación. En el panel Training del nivel inferior mostrado, agregar el siguiente operador:
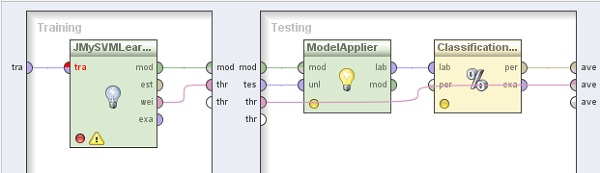
5.1 Modeling → Classification and Regression → Support Vector Modeling → Support Vector Machine. Cambiar el nombre del mismo a “JMySVMAprendiz”. Conectar la entrada tra del panel a la entrada tra de este operador y las salidas mod y wei del mismo a los conectores mod y thr del panel, repectivamente.
6. En el panel Testing de la derecha, agregar los siguientes operadores:
6.1 Modeling → Model Application → Apply Model. Cambiar el nombre del mismo a “AplicadorModelo” y conectar los puertos mod y tes del panel a las entradas mod y unl de este operador, respectivamente.
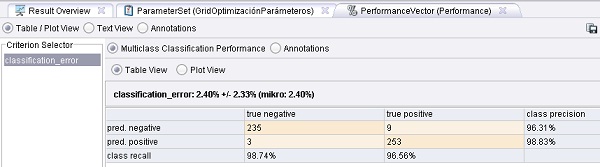
6.2 Agregar el operador Evaluation → Performance Measurement → Classification and Regression → Performance (Classification). Cambiar el nombre del mismo a “PerformanceClasificación”, quitar la tilde de la opción “accuracy” y tildar la opción “classification error”. Conectar la salida lab del operador AplicadorModelo (Apply Model) a la entradas lab de este operador y la salida per de éste último al conector ave (averagable 2) del panel. También conectar la entrada thr (through 1) del panel a la salida ave (averagable 2) del mismo.
7. Volver al nivel superior (Proceso Principal), seleccionar el operador GridOptimizaciónParámetros y utilizar el editor (“Edit Parameter Settings...”) para seleccionar el parámetro weight del operador Selección
(Select by Weights):
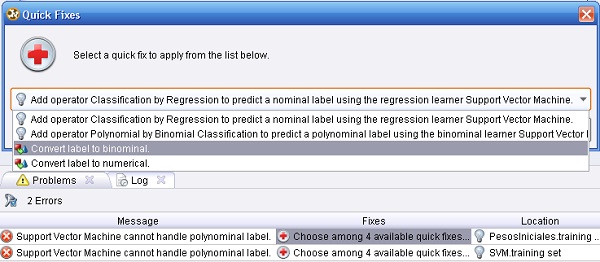
8. Observar los íconos de advertencia en la parte inferior izquierda de algunos operadores. Al detener un instante el puntero del ratón en la entrada tra del operador PesosIniciales del proceso principal, RapidMiner muestra que hay un error debido a que la SVM no puede manejar etiquetas polinomiales. En la pestaña Problems de la parte inferior, hacer doble clic en la primera fila, debajo de la columna “Fixes” para seleccionar una de las 4 soluciones rápidas disponibles (“Convert label to binominal.”):
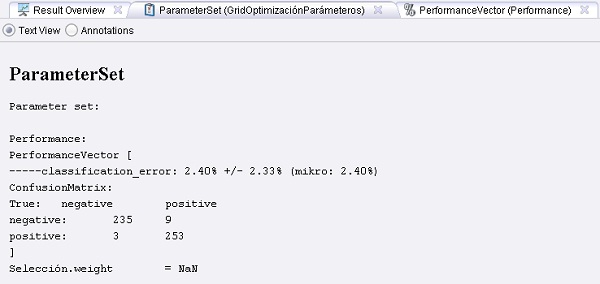
Resultados:
Ejemplo 25: Prueba de Significancia
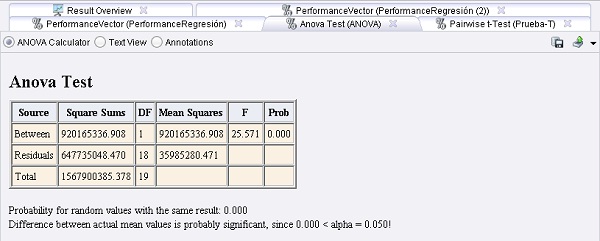
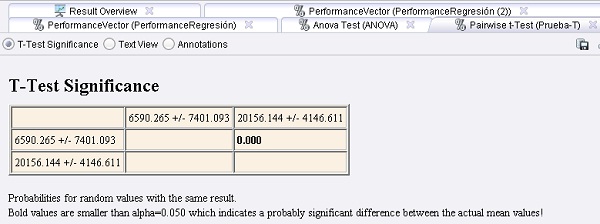
Ejemplo 25: Prueba de Significancia bernabeu_dario 10 Noviembre, 2010 - 11:15Muchos operadores de RapidMiner se pueden utilizar para estimar la performance de un aprendiz, un paso de preprocesamiento, o un espacio de características sobre uno o varios conjuntos de datos. El resultado de estos operadores de validación es un vector de performance que recoge los valores de un conjunto de criterios de performance. Para cada criterio se dan el valor medio y la desviación estándar.
La cuestión es ¿cómo se pueden comparar estos vectores de performance? Las pruebas de estadísticas de significancia como ANOVA o pruebas t por pares, se pueden utilizar para calcular la probabilidad de que
los valores medios reales sean diferentes.
Suponemos que se han obtenido varios vectores de performance y se desea compararlos. En este proceso se utiliza el mismo conjunto de datos para las validaciones cruzadas (de ahí el IOMultiplier) y para estimar la performance de un esquema de aprendizaje lineal y una RBF basada en SVM.
1. Agregar el operador Utility → Data Generation → Generate Data a la zona de trabajo. Cambiar el nombre del mismo a “GeneradorConjEjs” y los valores de los parámetros target function a “one variable non linear”, number examples a 80, number of attributes a 1, attributes lower bound a -40.0 y attributes upper bound a 30.0.
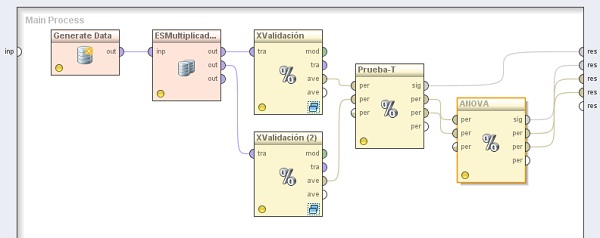
2. Agregar el operador Process Control → Multiply. Cambiar el nombre del mismo a “ESMultiplicador_1” y conectar la salida del operador GeneradorConjEjs (Generate Data) a la entrada de este operador.
3. Agregar un operador Evaluation → Validation → X-Validation. Cambiar el nombre del mismo a “XValidación” y el parámetro sampling type a “shuffled sampling”. Conectar la salida out (output 1) del operador ESMultiplicador_1 (Multiply) a la entrada tra de este operador.
4. Agregar otro operador Evaluation → Validation → X-Validation. Cambiar el nombre del mismo a “XValidación (2)” y el parámetro sampling type a “shuffled sampling”. Conectar la salida out (output 2) del operador ESMultiplicador_1 a la entrada tra de este operador.
5. Agregar el operador Evaluation → Significance → T-Test. Conectar la salida ave (averagable 1) del operador XValidación (X-Validation) a la entrada per (performance 1) de ![]() este operador y la salida ave (averagable 1) del operador XValidación (2) a la entrada per (performance 2) de este último. También conectar la salida sig (significance) de este operador al conector res del panel.
este operador y la salida ave (averagable 1) del operador XValidación (2) a la entrada per (performance 2) de este último. También conectar la salida sig (significance) de este operador al conector res del panel.
6. Agregar el operador Evaluation → Significance → ANOVA. Cambiar el nombre del mismo a “Prueba- T”. Conectar las salidas per (performance 1) y per (performance 2) del operador T-Test a las entradas per (performance 1) y per (performance 2) de este operador, y las salidas sig (significance), per (performance 1) y per (performance 2) del mismo a conectores res del panel.
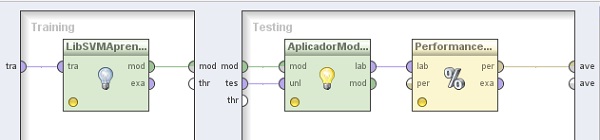
7. Hacer doble clic sobre el operador XValidación. En el panel Training del nivel inferior, agregar el siguiente operador:
7.1 Modeling → Classification and Regression → Support Vector Modeling → Support Vector Machine (LibSVM). Cambiar el nombre del mismo a “LibSVMAprendiz” y los valores de los parámetros svm type a “nu-SVR”, kernel type a “poly” y C a 10000.0. Conectar la entrada tra (training) y salida mod (model) de este operador a los puertos tra y mod del panel, respectivamente
8. En el panel Testing de la derecha, agregar los siguientes operadores:
8.1 Modeling → Model Application → Apply Model. Cambiar el nombre del mismo a “AplicadorModelo” y conectar las entradas mod y tes del panel a las entradas mod y unl de este operador, respectivamente.
8.2 Evaluation → Performance Measurement → Classification and Regression → Performance (Regression). Cambiar el nombre del mismo a “PerformanceRegresión”, quitar la tilde de la opción root mean squared error y tildar la opción absolute error. Conectar la salida lab del operador AplicadorModelo (Apply Model) a la entrada lab de este operador y la salida per (performance) de éste último al conector ave (averagable 1) del panel.
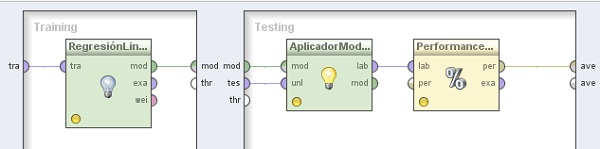
9. Subir un nivel (Proceso Principal) y hacer doble clic sobre el operador XValidación (2). En el panel Training del nivel inferior, agregar el siguiente operador:
9.1 Modeling → Classification and Regression → Function Fitting → Linear Regression. Cambiar el nombre del mismo a “RegresiónLineal” y conectar la entrada tra (training) y salida mod (model) del mismo a los puertos tra y mod del panel, respectivamente.
10. En el panel Testing de la derecha, agregar los siguientes operadores:
10.1 Modeling → Model Application → Apply Model. Cambiar el nombre del mismo a “AplicadorModelo (2)” y conectar las entradas mod y tes del panel a las entradas mod y unl de este operador, respectivamente.
10.2 Evaluation → Performance Measurement → Classification and Regression → Performance (Regression). Cambiar el nombre del mismo a “PerformanceRegresión (2)”, quitar la tilde de la opción root mean squared error y tildar la opción absolute error. Conectar la salida lab del operador AplicadorModelo (2) a la entrada lab de este operador y la salida per (performance) de éste último al conector ave (averagable 1) del panel.
11. Ejecutar el proceso y comparar los resultados: las probabilidades de una diferencia significativa son iguales, porque sólo se crearon 2 vectores de performance. En este caso, la SVM es probablemente más
adecuada para el conjunto de datos en cuestión debido a que los valores medios reales probablemente son diferentes.
12. Observar que los vectores de performance como todos los demás objetos que se pueden pasar entre los operadores de RapidMiner se pueden escribir en y cargar desde un archivo.
Ejemplo 26: Cálculos Basados en Grupos
Ejemplo 26: Cálculos Basados en Grupos bernabeu_dario 11 Noviembre, 2010 - 00:14Este proceso muestra un preprocesamiento más complejo que demuestra algunas de las funcionalidades de ETL extendidas disponibles en RapidMiner mediante el uso de conceptos tales como bucles o macros.
La primera cadena de operadores sólo encapsula una secuencia de operadores que producen datos en un formato específico. Posteriormente, el ValueIterator itera sobre todos los valores posibles del atributo
especificado, y almacena el valor actual en la macro %{loop_value}. Esta macro se utiliza luego dentro del ExampleFilter seguido por una agregación para calcular la media de otro atributo de acuerdo a los grupos
definidos por el primero. Luego se utiliza otra definición de macro, %{current_average}, para leer la media y posteriormente se la emplea en el AttributeConstruction. A continuación, todos los conjuntos de datos
resultantes, uno por cada grupo, se fusionarán al finalizar el bucle.
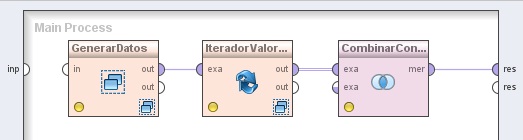
1. Agregar el operador Utility → Subprocess a la zona de trabajo. Cambiar el nombre del mismo a “GenerarDatos”.
2. Agregar el operador Process Control → Loop → Loop Values. Cambiar el nombre del mismo a “IteradorValores”. Conectar la salida out del operador GeneradorDatos (Subprocess) a la entrada exa de este operador.
3. Agregar el operador Data Transformation → Set Operations → Append. Cambiar el nombre del mismo a “CombinarConjEjs”. Conectar la salida out del operador IteradorValores (Loop Values) a la entrada exa de este operador y la salida mer (merged set) de este último al conector res del panel.
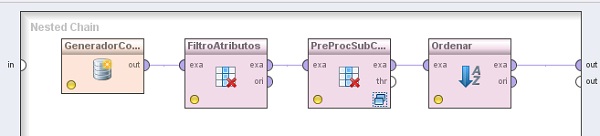
4. Hacer doble clic sobre el operador GenerarDatos (Subprocess). En el panel Nested Chain del nivel inferior, agregar los siguientes operadores:
4.1 Agregar el operador Utility → Data Generation → Generate Data a la zona de trabajo. Cambiar el nombre del mismo a “GeneradorConjEjs” y los valores de los parámetros target function a “sum”, number
examples a 12, y number of attributes a 2.
4.2 Agregar el operador Data Transformation → Attribute Set Reduction and Transformation → Selection → Select Attributes. Cambiar el nombre del mismo a “FiltroAtributos”. Conectar la salida out del operador GeneradorConjEjs (Generate Data) a la entrada exa de este operador y cambiar los valores de los parámetros attribute filter type a “regular_expression” y regular expresion a “label”, este último con ayuda del editor de expresiones regulares. Además tildar las opciones invert selection e include special attributes.
4.3 Agregar el operador Data Transformation → Attribute Set Reduction and Transformation → Selection → Work on Subset. Cambiar el nombre del mismo a “PreProcSubConjAtrib”. Conectar la salida exa del operador FiltroAtributos (Select Attributes) a la entrada exa de este operador y cambiar los valores de los parámetros attribute filetr type a “regular_expression” y regular expresion a “att1”, este último con ayuda del editor de expresiones regulares.
4.4 Agregar el operador Data Transformation → Sorting → Sort. Cambiar el nombre del mismo a “Ordenar”. Conectar la salida exa del operador PreProcSubConjAtrib (Work on Subset) a la entrada exa de este operador y la salida exa de este último al conector out del panel. Seleccionar “att1” de la lista de valores para el parámetro attribute name.
5. Hacer doble clic sobre el operador PreProcSubConjAtrib. En el panel Subset Process del nivel inferior, agregar el siguiente operador:
5.1 Data Transformation → Type Conversion → Discretization → Discretize by Frequency. Cambiar el nombre del mismo a “DiscretizaciónFrecuencias”. Conectar la entrada y salida exa de este operador a los conectores de entrada y salida exa del panel, respectivamente. Cambiar los valores de los parámetros number of bins a 2 y range name type (modo experto) a “short”.
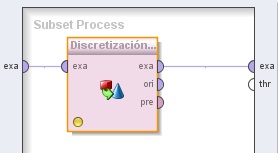
6. Volver al proceso principal y hacer doble clic sobre el operador IteradorValores (Loop Values). En el panel Iteration del nivel inferior, agregar los siguientes operadores:
6.1 Data Transformation → Filtering → Filter Examples. Cambiar el nombre del mismo a “FiltroMuestras”. Conectar la entrada exa del panel a la entrada exa de este operador. Cambiar los valores de los parámetros condition class a “attribute_value_filter”, parameter string a “att1 = %{loop_value}”.
6.2 Data Transformation → Aggregation → Aggregate. Cambiar el nombre del mismo a “Agregación”. Conectar la entrada exa del operador FiltroMuestras (Filter Examples) a la entrada exa de este operador. Con la ayuda del editor de lista (Edit List) del parámetros aggregation attributes añadir: | att2 | average |.
6.3 Utility → Macros → Extract Macro. Cambiar el nombre del mismo a “DefiniciónMacroDatos”. Conectar la salida exa del operador Agregación (Aggregate) a la entrada exa de este operador y asignar valores a los parámetros macro = “current_average”, macro type = “data value”, attribute name = “average(att2)” y example index = 1.
6.4 Data Transformation → Attribute Set Reduction and Transformation → Generation → Generate Attributes. Cambiar el nombre del mismo a “ConstrucciónAtributos”. Conectar la salida ori (original) del operador Agregación (Aggregate) a la entrada exa de este operador y la salida exa de este último al conector out del panel. Con la ayuda del editor de lista (Edit List) del parámetro function descriptions añadir: | att2_avs_avg | abs(att2 - %{current_average}) |
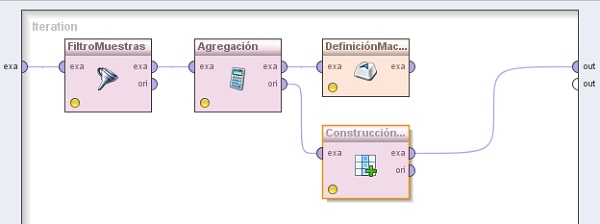
7. Volver al proceso principal y seleccionar el operador IteradorValores (Loop Values). Seleccionar “att1” de la lista de valores para el parámetro attribute.
Conclusión
Conclusión bernabeu_dario 12 Noviembre, 2010 - 12:35debería leer el capítulo del Tutorial de RapidMiner que describe la creación de operadores y el mecanismo de extensión. RapidMiner se puede ampliar fácilmente. Que se divierta!