
In this blog post we are following the official documentation for the configuration of disaster recovery for the OIC. We are focusing only on the networking required to have this disaster recovery. The provisioning of the Service and the replication to the second region is not in the scope of this blog.
Publicaciones en la red sobre
Base de datos
Sistemas de gestión de Bases de datos y almacenamiento
Configuring a Disaster Recovery Solution for Oracle
Integration Cloud
Leer en:
4 tips to help you achieve ‘Inbox Zero’ in Gmail

Reaching Inbox Zero in Gmail will be much easier if you follow this advice. Solen Feyissa / Unsplash
...
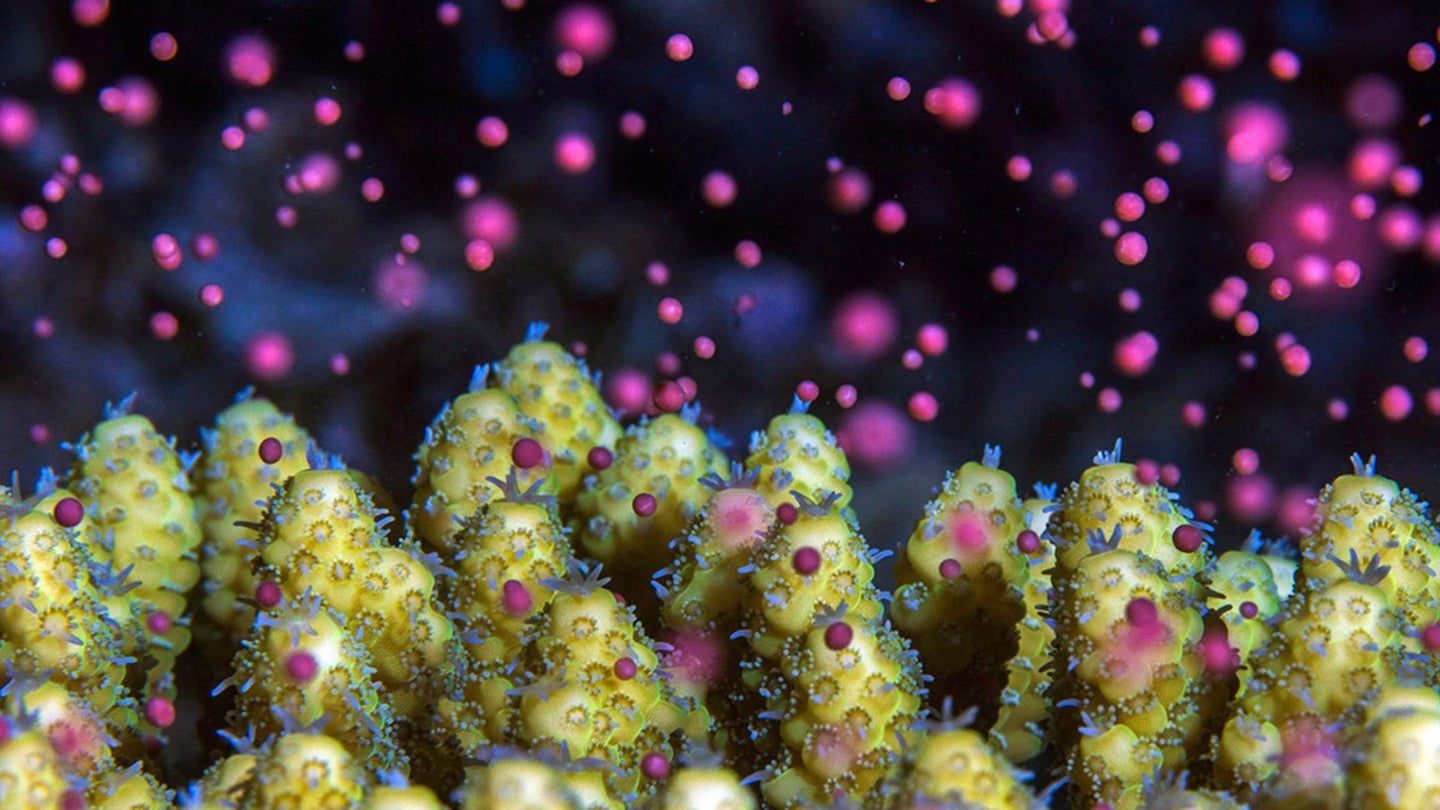
Scientists are finally getting into the rhythm of sea
creatures’ lunar cycle
Create a custom endpoint for Oracle Integration
Cloud
Oracle Integration cloud is a PaaS service part of Oracle Cloud Infrastructure. By default, when you provision the service, your service console will be part of the domain integration.ocp.oraclecloud.com. This blog is showing how to configure a custom endpoint for the service.
