
Una vez identificados los origenes de datos, podemos proceder a la construcción de las tablas físicas de nuestro modelo y al desarrollo de los procesos de llenado. Empezaremos el proceso con la Dimensión Tiempo. Como ya indicamos, esta dimensión no dependera de nuestro ERP u otros sistemas externos, sino que la construiremos a partir de los calendarios. Generaremos todos los registros necesarios para esta tabla para un periodo de 20 años, que va desde el 01 de Enero de 2000 (para los datos históricos anteriores que también cargaremos en nuestro DW) hasta el 31 de Diciembre de 2020.
La definición física de la tabla no ha variado tras el análisis de los origenes de datos, y será la siguiente:
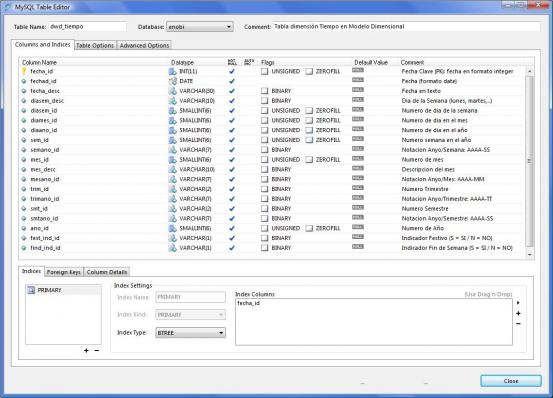
Diseño Fisico Tabla Dimensión Tiempo en MySql
Los procesos que tendremos que implementar utilizando Talend serán los siguientes (tal y como vimos en una entrada anterior del Blog):
.jpg)
Transformaciones para la creación de la Dimensión Tiempo
Vamos a utilizar Talend con la opción de generación en lenguaje Java (también podriamos utilizar el lenguaje PERL). El utilizar Java significa que todos los procesos y transformaciones que definamos se van a “traducir” a lenguaje Java a nivel interno. Aunque no es estrictamente necesario conocer el lenguaje Java para trabajar con Talend, su conocimiento nos va a facilitar mucho el trabajo con la herramienta y nos va a permitir definir nuestro propio código para la transformaciones o procesos que no se incluyen de forma estandar.
Talend esta basado en el entorno de desarrollo Eclipse. Es un entorno gráfico con amplias funcionalidades donde la definición de las transformaciones se realiza de una forma visual muy intuitiva, seleccionando y arrastrando componentes y estableciendo relaciones entre ellos. Incluye un entorno de Debug para poder analizar los procesos y sus errores, así como la posibilidad de establecer trazas para realizar un seguimiento de los procesos cuando los estamos desarrollando y validando.
En la imagen siguiente vemos un ejemplo de un job desarrollado con Talend:
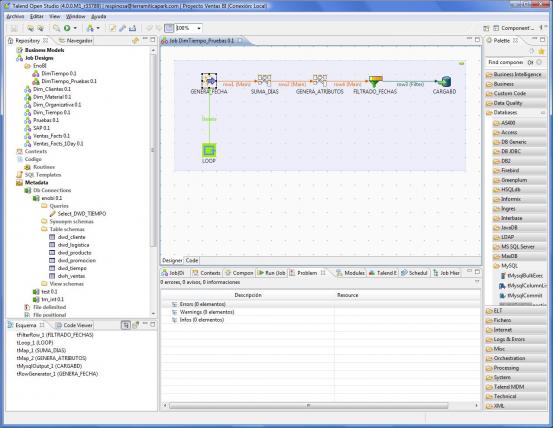
Entorno gráfico de la herramienta Talend
Los componentes mas importantes dentro del entorno gráfico son los siguientes:
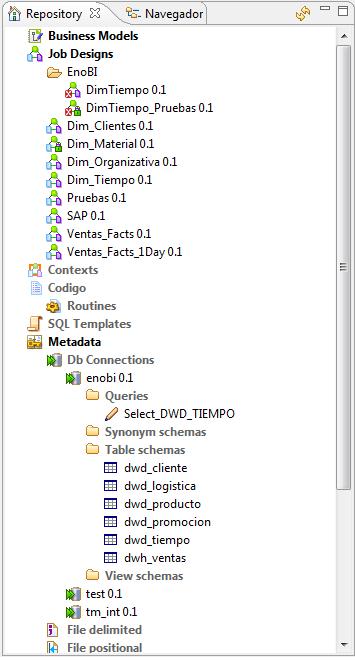
Repositorio de Objetos en Talend
Repositorio: incluye todos los objetos que podemos definir utilizando Talend, clasificado en un arbol de la siguiente manera:
- Business Models: Talend dispone de una herramienta gráfica sencilla donde podemos definir nuestros modelos de negocio. En esta carpeta se ubicaran los diferentes modelos de negocio que hayamos “dibujado” utilizando Talend. La herramienta contiene los elementos gráficos mas habituales.
- Job Designs: un proyecto de transformación o integración de datos se compone de multiples procesos o jobs que podemos definir y clasificar en una estructura de carpetas para organizarlos y clasificarlos. En esta sección vemos los diferentes jobs que hemos definido y la forma en la que los hemos clasificado.
- Contexts: son los contextos de ejecución de los procesos. En ellos podemos definir constantes o parametros que se nos piden al ejecutar un proceso y que podemos utilizar en los diferentes componentes de un job. Los contextos también se pueden cargar en tiempo de ejecución provenientes de ficheros.
- Rutinas: es el lugar donde podemos ver las rutinas de código desarrolladas por Talend(que luego podremos utilizar en las transformaciones) y donde nosotros podremos añadir nuestras propias rutinas para realizar operaciones, cálculos o transformaciones para las que no dispongamos de un método estandar. Las rutinas se programan en Java (o en Perl en el caso de haber seleccionado ese lenguaje).
- SQL Template: son templates de sentencias SQL predefinidas que podremos utilizar o personalizar.
- Metadata: es el lugar donde vamos a definir los metadatos del proyecto. Son definiciones de componentes que luego vamos a poder reutilizar en todos los procesos de diseño de las transformaciones. Por ejemplo, en el metadatos podremos definir conexiones a bases de datos, recuperar los esquemas de una base de datos y tenerlos documentados (con sus tablas, vistas, etc), definir sentencias Sql, definir patrones de diferentes tipos de ficheros, etc. Esto nos permite tener los elementos definidos en un único sitio y reutilizarlos a lo largo de los procesos. El Repositorio de metadatos centraliza la información de todos los proyectos y garantiza la coherencia en todos los procesos de integración. Los metadatos relacionados con los sistemas origen y destino de los procesos de integración se cargan fácilmente en el Repositorio de metadatos a través de utilidades avanzadas de analisis de las bases de datos o archivos, facilitada por diversos asistentes. Las características definidas en el Metadata son heredadas por los procesos que hacen uso de ellas.
- Documentacion: podemos cargar en el proyecto los ficheros de documentacion de nuestros análisis y desarrollos, clasificandolos por carpetas. La vinculación se puede hacer con un link o cargando directamente el fichero en el repositorio. Esta utilidad nos permite tener centralizado en un único lugar todos los elementos de un proyecto de integración de datos.
- Papelera de reciclaje: los objetos que borramos va a la papelera de reciclaje y de ahi los podremos recuperar en el caso de ser necesario.
Job Designer: es la herramienta desde la que manipulamos los diferentes componentes que conforman un job, estableciendo relaciones entre los diferentes elementos.
Job Designer
Cuando estamos trabajando con un job, en la parte inferior disponemos de un conjunto de pestañas desde donde podemos realizar varias acciones, tales como definir un contexto para el job, configurar las propiedades, ejecutar el job y establecer la forma de ejecución, modificar las propiedades de los componentes de los jobs, programar los jobs, establecer jerarquias en los jobs, etc.
Finalmente, en la parte derecha de la aplicación tenemos la Paleta de Componentes, que son los diferentes controles que nos proporciona Talend para utilizar en nuestros jobs. Se encuentran clasificados según su función.
Paleta de Componentes
Algunos de los componentes disponibles en Talend son los siguientes:
- Business Intelligence: grupo de conectores que cubre las necesidades de lectura o escritua en bases de datos multidimensionales u olap, salidas hacia reports Jasper, gestión de cambios en la base de datos para las dimensiones lentamente cambiantes, etc (todos ellos relacionados con Business Intelligence).
- Business: conectores para leer y escribir de sistemas tipo CRM (Centric, Microsoft CRM, Salesforce, Sugar, Vtiger) o para leer y escribir desde sistemas Sap. También permiten trabajar con el gestor documental Alfresco.
- Custom Code: componentes para definir nuestro propio código personalizado y poder utilizarlo integrado con el resto de componentes Talend. Podemos escribir componentes en Java y Perl, así como cargar librerias o personalizar comandos Groovy.
- Data Quality: componentes para la gestión de calidad de datos, como filtrados, calculos CRC, busquedas por lógica difusa, reemplazo de valores, validación de esquemas contra el metadata, limpieza de duplicados, etc.
- Databases: conectores de conexión, entrada o salida de las bases de datos mas populares ( AS400, Access, DB2, Firebird, Greenplum, HSQLdb, Informix, Ingres, Interbase, JavaDB, LDAP, MSSQL Server, MaxDB, MySql, Netezza, Oracle, Paraccel, PostreSQL, SQLite, Sas, Sybase, Teradaba, Vertica).
- ELT: componentes para trabajar con las bases de datos en modo ELT (con las tipicas transformaciones y procesos de este tipo de sistemas).
- Fichero: controles para la gestión de ficheros (verificacion existencia, copia, borrado, lista, propiedades), para lectura de ficheros de diferentes formatos (texto, excel, delimitados, XML, mail, etc) y para escritura en ellos.
- Internet: componentes para acceder a contenidos almacenados en internet, como servicios Web, flujos RSS, SCP, Mom, Email, servidores FTP y similares.
- Logs & Errors: controles para la gestión de errores y logs en la definición de procesos.
- Miscelanea: componentes varios, como ventanas de mensajes, verificación de funcionamiento de servidores, generador de registros, gestión de contextos de variables, etc.
- Orchestration: componentes para generar las secuencias y la tareas de orquestación y procesamiento de los jobs y subjobs definidos en nuestras transformaciones (generación loops, ejecución de jobs previos o posteriores, procesos de espera para ficheros o datos, etc).
- Processing: componentes para procesamiento de los flujos de datos, como agregación, mapeos, transformaciones, filtrados, desnormalización, etc.
- System: componentes para interaccion con el sistema operativo (ejecución de comandos, variables de entorno, etc).
- XML: componentes para trabajo con estructuras de datos XML, con operaciones de parsing, validación o creación de estructuras.
Para haceros una idea de la forma de trabajar con Talend, es interesante ver una demo de 5 minutos en la Web de Talend (acceder desde este link). También podeis ver el siguiente video de demostración de como generar datos de test en una tabla Mysql.
Igualmente, podeís descargaros para profundizar más el Manual de Usuario de la herramienta y la Guia de Referencia de Componentes (ambos en inglés) en este link.
Job en Talend para el llenado de la Dimensión Tiempo
Ahora que ya conocemos un poco en que consiste Talend, vamos a profundizar viendo un ejemplo práctico. Necesitamos generar un flujo de fechas que comenzando en 01.01.2000, llegue hasta el dia 31.12.2020 (con eso cargamos las fechas de 20 años en la dimensión).
Para hacer el proceso vamos a definir los siguientes pasos:
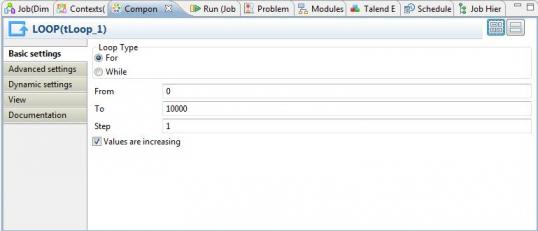
1) Loop que se ejecuta 10.000 veces, con un contador que vas desde 0 a 9999 (utilizando el componente tLoop del grupo Orchestration).
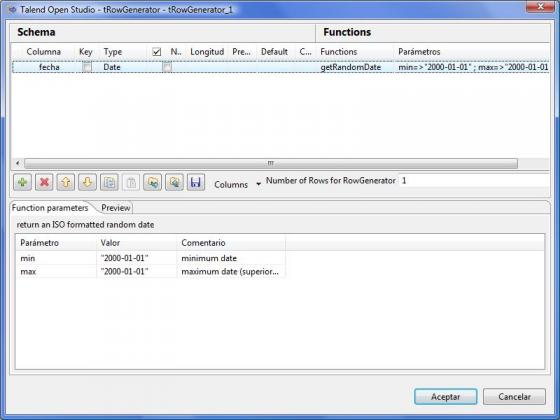
2) El loop llama al control Generador de Registros, que genera un registro con la fecha 01.01.2000 (utilizando el componente tRowGenerator del grupo Miscelaneous).
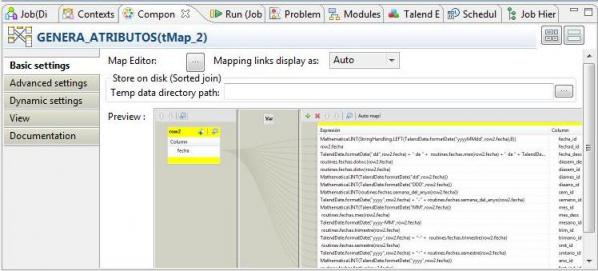
3) el RowGenerator pasa la fecha a un transformación (MAP), que le suma a la fecha el contador del paso 1 (con eso vamos incrementando la fecha de partida dia a dia y generando todas las fechas necesarias). Utilizamos el componente tMap del grupo Processing.
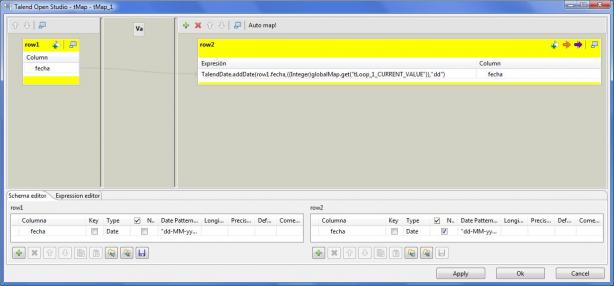
4) las fechas generadas las pasamos a otra transformación (MAP), donde para cada fecha, generamos todos los atributos de la dimensión tiempo según la tabla de transformación que hemos indicado anteriormente (mes, año, dia, dia de la semana, trimestre, semestre, etc). Utilizamos el componente tMap del grupo Processing.
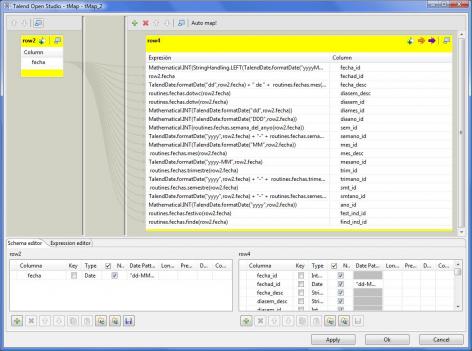
Hemos tenido que definir unas rutinas en java para la generación correcta del número de semana en el año de cada fecha, así como para la generación de los datos de trimestres, semestres, dia festivo y fin de semana. Por ejemplo, para la generación de las semanas hemos escrito el siguiente código en Java:
// template routine Java
package routines;
import java.util.Calendar;
import java.util.Date;
public class fechas {
public static String semana_del_anyo(Date date1) {Calendar c1 = Calendar.getInstance();
c1.set(Calendar.DAY_OF_WEEK,Calendar.MONDAY);
c1.setMinimalDaysInFirstWeek(1);
c1.setTime(date1);
int semana = c1.get(Calendar.WEEK_OF_YEAR);
if (semana < 10) {return ( 0 + Integer.toString(semana));
} else {return (Integer.toString(semana));
}}
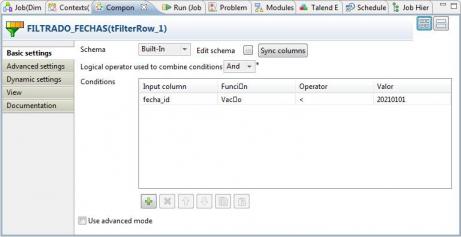
5) Filtramos los registros para desechar los que son mayores de 31.12.2020, pues esos nos los queremos cargar en la base de datos. Utilizamos el componente tFilterRow del grupo Processing.
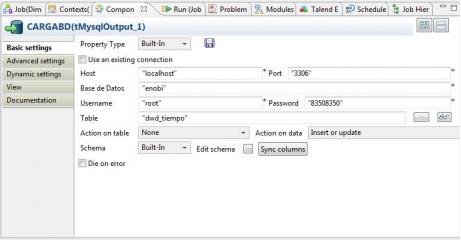
6) Insertamos los registros en la base de datos Enobi, en la tabla DWD_TIEMPO, utilizando el componente tMySqlOutput, del grupo Databases, MySql. Si los registros ya existen en la base de datos, se actualizan.
El esquema completo del Job sería el siguiente:
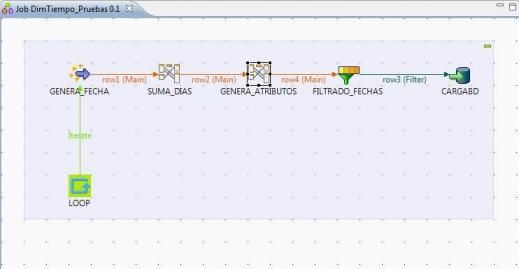
Job llenado Dimensión Tiempo
Esta ha sido nuestro primera toma de contacto con una herramienta ETL. Sin programar (o casi, pues hemos tenido que preparar una rutina en java para el tratamiento de las semanas y otros atributos de las fechas), hemos llenado con datos reales la primera tabla/dimensión de nuestro modelo.
