Administración de Microsoft SQL Server 2008
Administración de Microsoft SQL Server 2008 Dataprix 23 May, 2014 - 19:27Acceder a MySql desde Sql Server 2008
Acceder a MySql desde Sql Server 2008 il_masacratore 30 December, 2009 - 12:55Se puede dar el caso que necesitemos acceder a MySql desde Sql Server 2008. Para hacerlo podemos crear un servidor vinculado que use una conexión odbc. Como hacerlo paso a paso:
1. Descargar el cliente ODBC de Mysql para la plataforma del sevidor sql. Lo podeis hacer aquí.
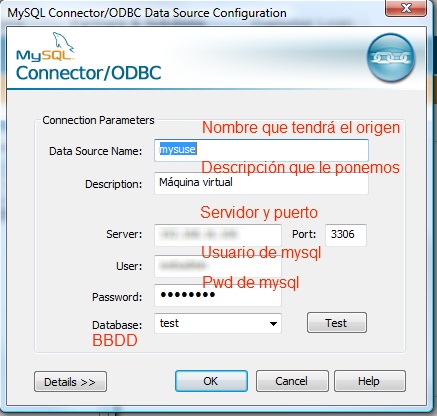
2. Instalarlo (siguiente, siguiente, siguiente) y configurar un DSN de sistema. Para ello en el Administrador de orígenes de datos ODBC, en la pestaña DSN de sistema pulsamos Agregar y seleccionamos MySQL ODBC 5.1 driver. Acepatemos y aparece un formulario como el siguiente. Lo rellenaremos y probaremos pulsando Test para comprobar que funciona.
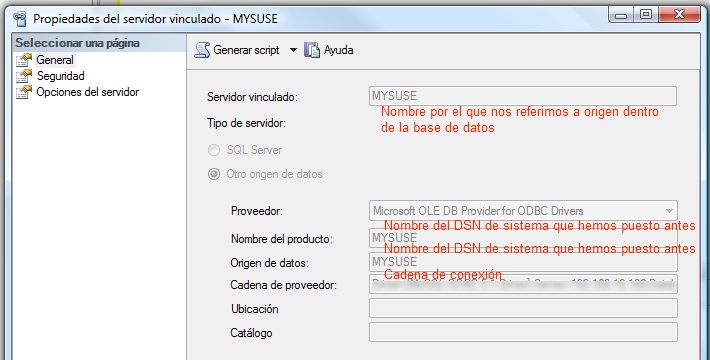
3. Añadir el servidor vinculado en la base de datos. Para ello nos conectamos a la base de datos y en el árbol de objetos vamos a Objetos de servidor, pulsamos botón derecho en Servidores vinculados y clickamos en Nuevo Servidor Vinculado, rellenamos los datos y ya lo tenemos.
4. Al finalizar el paso anterior ya tendremos acceso al servidor. Podemos verlo en la lista de servidores vinculados y opdremos navegar para ver las tablas que hay en la base de datos que hemos vinculado. También podremos usarlo para hacer consultas mediante la función tsql openquery.
Sintaxis: select [campo,] from OPENQUERY([servidor vinculado], [select mysql]).
SQLServer 2008: Actualizar estadísticas de tabla de forma dinámica en toda una base de datos
SQLServer 2008: Actualizar estadísticas de tabla de forma dinámica en toda una base de datos il_masacratore 3 March, 2010 - 17:36Al igual que en Oracle existe una tabla donde se listan todas las tablas de la base de datos (dba_tables) y podemos usarla para realizar operaciones de mantenimiento de forma dinámica, en Sql Server podemos hacer lo mismo consultando la tabla [basededatos].dbo.sysobjects.
En el ejemplo inferior (como en otros que he colgado) actualizo las estadísticas de todas las tablas de una base de datos de Sql Server de forma dinámica consultando el diccionario de datos. Este se podría encapsular en un stored procedure o directamente ejecutarlo en un job del Agente de Sql Server para mantener actualizadas las estadísticas de todas las tablas de una base de datos de forma automática.
-- Declaración de variables
DECLARE @dbName sysname
DECLARE @sample int
DECLARE @SQL nvarchar(4000)
DECLARE @ID int
DECLARE @Tabla sysname
DECLARE @RowCnt int
--Filtro por base de datos y porcentaje para recalculo de estadísticas
SET @dbName = 'AdventureWorks2008'
SET @sample = 100
--Tabla temporal
CREATE TABLE ##Tablas
(
TableID INT IDENTITY(1, 1) NOT NULL,
TableName SYSNAME NOT NULL
)
--Alimentamos la tabla con la lista de tablas
SET @SQL = ''
SET @SQL = @SQL + 'INSERT INTO ##Tablas (TableName) '
SET @SQL = @SQL + 'SELECT [name] FROM ' + @dbName + '.dbo.sysobjects WHERE xtype = ''U'' AND [name] <> ''dtproperties'''
EXEC sp_executesql @statement = @SQL
SELECT TOP 1 @ID = TableID, @Tabla = TableName
FROM ##Tablas
ORDER BY TableID
SET @RowCnt = @@ROWCOUNT
--Por cada tabla
WHILE @RowCnt <> 0
BEGIN
SET @SQL = 'UPDATE STATISTICS ' + @dbname + '.dbo.[' + @Tabla + '] WITH SAMPLE ' + CONVERT(varchar(3), @sample) + ' PERCENT'
EXEC sp_executesql @statement = @SQL
SELECT TOP 1 @ID = TableID, @Tabla = TableName
FROM ##Tablas
WHERE TableID > @ID
ORDER BY TableID
SET @RowCnt = @@ROWCOUNT
END
--Eliminamos la tabla
DROP TABLE ##Tablas
La forma de proceder arriba
La forma de proceder arriba indicada dará problemas para tablas que no esten contenidas en el esquema dbo. Por ello para solventar este problema primero debemos cambiar la forma de alimentar la tabla temporal para usar el siguiente bloque SQL:
use <base de datos a usar>
SET @SQL = 'INSERT INTO ##Tablas(TableName) '
SET @SQL = @SQL + ' select ''['' + TABLE_CATALOG + ''].['' + TABLE_SCHEMA + ''].['' + TABLE_NAME + '']'' from INFORMATION_SCHEMA.TABLES'
EXEC sp_executesql @statement = @SQL
-- Luego solamente usamos el nombre de la tabla para actualizar estadísticas:
SET @SQL = 'UPDATE STATISTICS ' + @Tabla + ' WITH SAMPLE ' + CONVERT(varchar(3), @sample) + ' PERCENT'
EXEC sp_executesql @statement = @SQL
- Log in to post comments
Cambiar en SQLServer 2008 la columna clave de una tabla a una nueva del tipo integer que sea identidad usando OVER
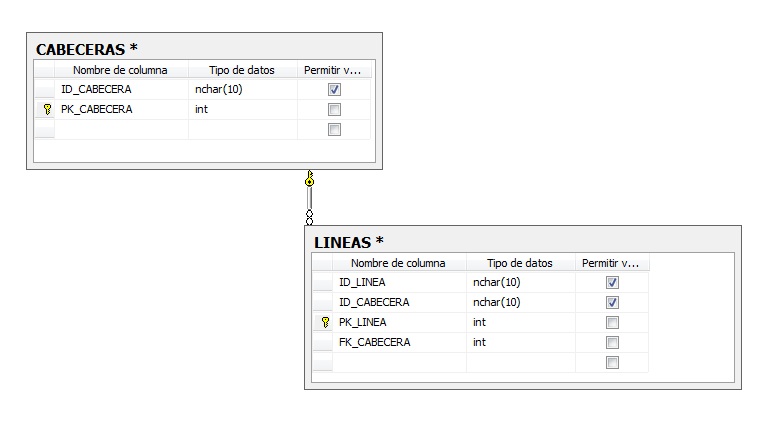
Cambiar en SQLServer 2008 la columna clave de una tabla a una nueva del tipo integer que sea identidad usando OVER il_masacratore 28 October, 2013 - 13:37Puede ser que en algun momento pueda ser necesario cambiar el tipo de columna clave para nuestra tabla/s por un mal diseño o un cambio posterior x que nos obliga a ello. Si lo hacemos y la nueva tiene que ser una columna del tipo entero, quizás identity, podemos hacerlo con algun criterio para que quede ordenado (pk=indice clusterizado=order by en disco por ese campo). En este ejemplo para hacerlo más completo, lo hacemos en dos tablas Maestro-Detalle donde los campos claves son de tipo nchar (CABECERAS.ID_CABECERA y LINEAS.ID_LINEA). Pasos a seguir...
- Empezamos por elegir el tipo de columna y la añadimos a la tabla principal, CABECERAS. Seguimos con un update que parte de una join con una select sobre la misma tabla incluyendo la función ROW_NUMBER() para el contador de linea que nos servira como valor autoincremental (identity?).
- A coninuacións seguimos con el detalle, LINEAS, donde hacemos lo mismo que antes con su propia PK. Para mantener el mismo orden hacemos una join con la tabla CABECERAS y aprovechamos también para asignar también el valor de la nueva foreign key.
Ahora que ya tenemos los nuevos candidatos a campo clave, los marcaremos como NOT NULL, como campo clave y optaremos si es necesario por ponerlos como identity. También modificaremos la FOREIGN KEY o añadiremos una nueva. Una forma muy fácil de hacer lo anterior es hacerlo de forma visual, usando Management Studio, en la parte de Diagramas de Bases de datos (en el árbol del Explorador de objetos).
Por cierto, si finalmente hace falta que las nuevas claves sea identity deberemos recuperar antes el valor máximo del campo en las dos tablas para asignar el valor inicial de la identidad. Si queremos ser más puristas, debemos saber que desde SqlServer 2012 existen las secuencias y ya podríamos hacer lo mismo usándolas. Es interesante saber por una eventual migración de tipo de base de datos. A saber, Oracle también permite el uso de secuencias pero no existe equivalente a campos identity. MySql en cambio si tiene identity y es AUTO_INCREMENT.
Como deshabilitar el autocommit en SQL Server Management Studio
Como deshabilitar el autocommit en SQL Server Management Studio il_masacratore 23 April, 2010 - 13:24¿Alguna vez os habeis preguntado como deshabilitar el autocommit en el Management Studio de Sql Server? Pues la respuesta es rápida. Lo podeís cambiar activando en el menú Herramientas > Opciones > Ejecución de la consulta > SQL Server > Ansi > SET IMPLICIT_TRANSACTIONS.
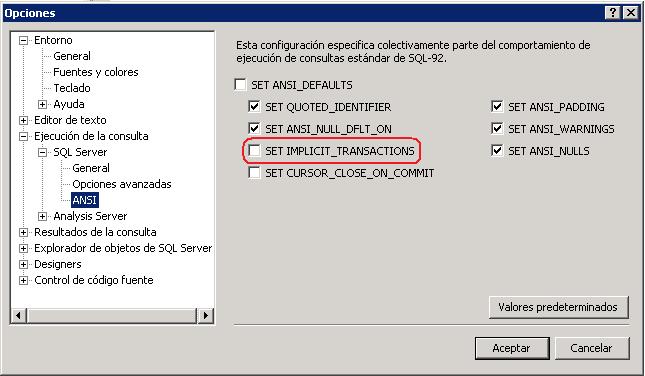
Parece algo simple pero como me lo han preguntado un par de veces...
Como recuperar la clave del usuario sa en Sql Server
Como recuperar la clave del usuario sa en Sql Server il_masacratore 23 October, 2013 - 11:54Hay muchas maneras de liarla con nuestra base de datos SqlServer y una de ellas es olvidar o no tener a nuestra disposición la clave del usuario sa. Puede ser debido a que nunca la usemos, porque tenemos nuestro propio usuario administrador y realmente no iniciamos sesión con esa cuenta. Puede ser que hayamos heredado esa maravillosa base de datos y no tengamos ningún usuario ni de dominio que sea administrador. O peor aún, que incluso desde el mismo día de la instalación no sepamos esa clave y acabamos de eliminar el único login con los permisos adecuados... Para cualquiera de estas historias tristes puede haber una solución que no sea reinstalar.
Desde SqlServer 2005 (y hasta SqlServer 2025 que yo sepa) existe, como plan de recuperación para este tipo de desastre, la posibilidad de arrancar la base de datos SqlServer en modo "single-user" y poder acceder a ella con cualquier usuario de miembro del grupo de administradores del sistema. Arrancar la base de datos en single-user está pensado para realizar tareas de mantenimiento, como por ejemplo aplicar patches y realizar otras tareas. En nuestro caso, donde hemos perdido la clave del usuario sa, nos permitirá, una vez limitado el acceso, conectarnos por ejemplo via sqlcmd y agregar un usuario de la base de datos al rol sysadmin dentro de Sql Server. A continuación un resumen...
Pasos a seguir:
- Abrimos el Administrador de Configuración de SqlServer. Buscamos el Servicio de SqlServer y miramos las Propiedades, en la pestaña Opciones Avanzadas o Parámetros de inicio añadimos un -m al final de la linea. (puede variar segun la versión). Presionamos aceptar y reiniciamos el servicio.
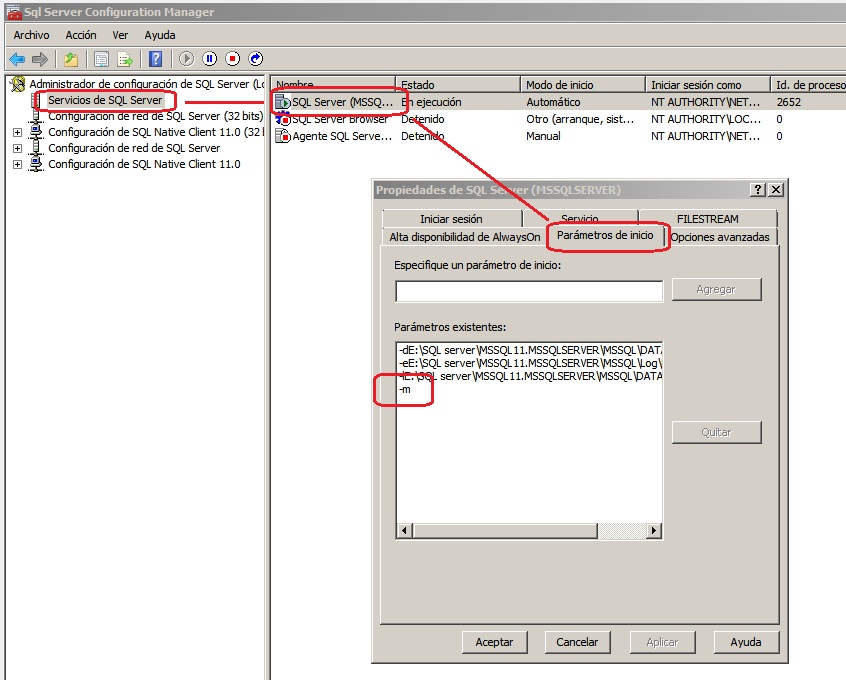
- Una vez reiniciado, abrimos la linea de comandos y el cliente sqlcmd. Ejecutamos lo siguiente:
sqlcmd -S localhost 1> EXEC sp_addsrvrolmember 'DOMINIO\Dba','sysadmin';
- Volvemos al Administrador de Configuración de SqlServer, quitamos el -m que hemos añadido en el primer punto y volvemos a reiniciar el servicio. Finalmente probamos de acceder con el usuario de dominio anterior y restauramos la clave del usuario sa (y la guardamos en lugar seguro). Misión cumplida.
Existe una variante sobre el uso del parámetro -m para arrancar la bbdd en modo usuario único, es -m"Nombre app" (En el nombre de la aplicación cliente se distinguen mayúsculas y minúsculas). Este uso del parámetro limita las conexiones a una aplicación cliente con el nombre especificado. Por ejemplo, -m"SQLCMD" limita las conexiones a una conexión única y esa conexión se debe identificar como el programa cliente SQLCMD. Se puede usar esta opción cuando estemos iniciando SQL Server en modo de usuario único y una aplicación cliente desconocida esté usando la única conexión disponible. Para limitarlo al Management Studio, usamos -m"Microsoft SQL Server Management Studio - Query".
Libros de SQL Server
¿Quieres profundizar más en Transact-SQL o en administración de bases de datos SQL? Puedes hacerlo consultando alguno de estos libros de SQL Server.
SQLServer 2008: Consulta uniendo datos de SSAS con los de una tabla de cualquier otra bbdd mediante openquery
SQLServer 2008: Consulta uniendo datos de SSAS con los de una tabla de cualquier otra bbdd mediante openquery il_masacratore 22 October, 2013 - 17:01En ocasiones podemos necesitar hacer un informe que debe contener datos de nuestro cubo de ventas (por ejemplo) y complementarlo con datos que nos faltan y que solo podemos encontrar en el esquema relacional del origen o directamente de otra fuente de datos.
Si la bbdd complementaria está en una instancia de sql server, una solución bastante comoda es crear un servidor vinculado. Eso nos permita hacer la consulta MDX desde la propia instancia de SQL Server y hacer una JOIN para conseguir los datos que no tenemos en el cubo. Si nos paramos a pensarlo, quizás no es lo más elegante e incluso puede ocultar alguna carencia de diseño, pero seguro que cosas peores hemos hecho.
A continuación los cuatro pasos a seguir para crear el servidor vinculado y la construcción de la query trivial para completar el total de ventas anual con el nombre del encargado de la tienda.
Primero preparamos la consulta MDX con los datos del cubo que podamos necesitar y un campo clave con el que luego podamos relacionar la otra tabla:
SELECT [Measures].[Sales amount] ON COLUMNS, [Business].[Store id].members ON ROWS FROM [Sales] WHERE [Time].[Year].&[2013]
Empezamos por ir al Explorador de objetos y buscamos en nuestra instancia el apartado Objetos del servidor>Servidores vinculados> Nuevo servidor vinculado. Complementamos con los datos de la instancia SSAS que corresponda.
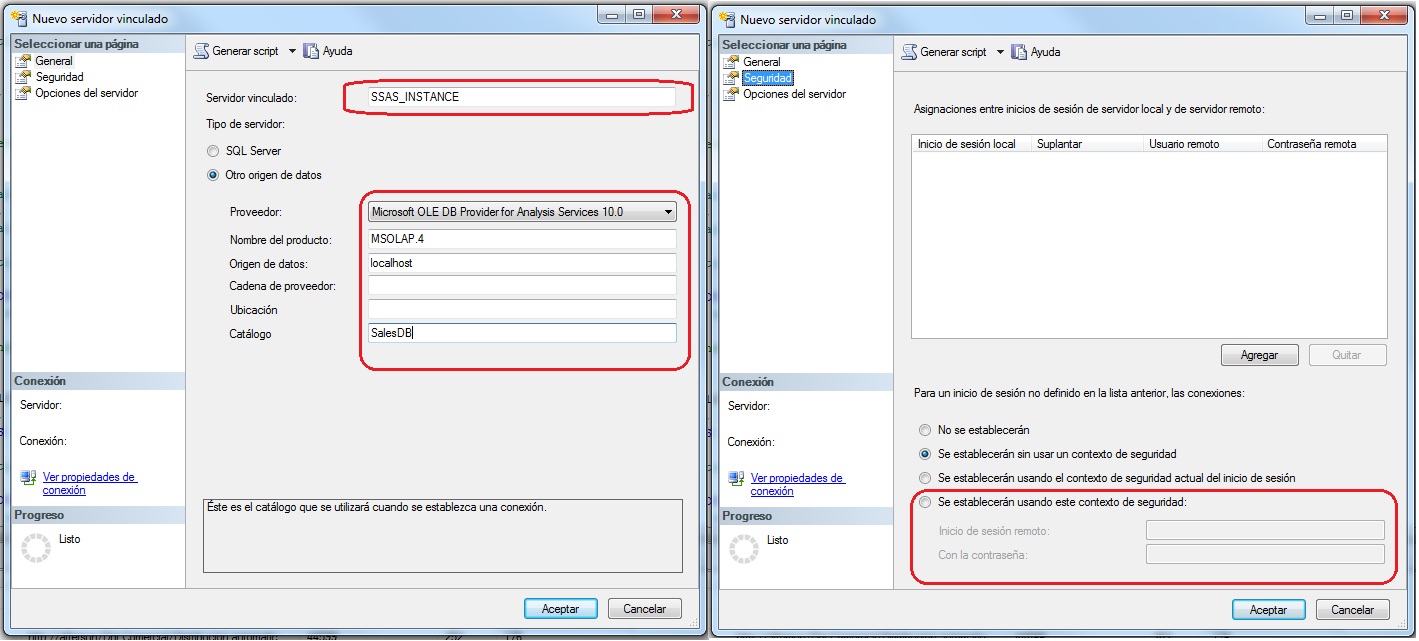
Editamos la consulta sobre la instancia de Sql Server. Aquí encapsulamos la consulta MDX en una nueva consulta SQL con openquery. El tip aquí para facilitar la selección de campos es usar alias ya que por defecto el encabezado de la columna nos saldra con el formato mdx del atributo/medida. Luego simplemente hacemos la JOIN como queramos con la otra tabla y listos.
SELECT ssas.Store_id ,ssas.Sales_Amount ,store.manager FROM (SELECT "[Business].[Store id].[MEMBER_CAPTION]" as Store_id,"[Measures].[Sales amount]" AS Sales_Amount
FROM openquery( SSAS_INSTANCE, 'SELECT [Measures].[Sales amount] ON COLUMNS,
[Business].[Store id].members ON ROWS
FROM [Sales]
WHERE [Time].[Year].&[2013]')) ssas
LEFT JOIN [dbo].[Stores] store ON ssas.Store_id = store.Store_id
Create table condicionado usando el diccionario de datos de Sql Server 2008
Create table condicionado usando el diccionario de datos de Sql Server 2008 il_masacratore 13 May, 2011 - 14:54En ciertas ocasiones necesitamos comprobar la existencia de una tabla en un script o tarea programada para poder registrar eventos de erro, primeras ejecuciones etc... Pongamos un ejemplo, un paquete de integration services que solemos distribuir o ejecutar allà a donde vamos y que deja trazas en un tabla personalizada que no es la predefinida para los logs de carga. Podríamos incluir siempre una Tarea de ejecución sql o de script, que se ejecute bien o mal, sea la primera en ejecutarse en el paquete y luego continue. Siendo puristas esto solo no es del todo “prolijo”:
CREATE TABLE LogsEtl (Ejecucion int PRIMARY KEY, Paquete varchar(50), Fecha datetime); GO
En la primera ejecución la salida será correcta pero en posteriores fallará en la creación de la tabla. Esto lo podemos suplir consultando la vista sys.Objects, donde existe un registro por cada objeto de la base de datos, y comprobar la existencia de la tabla antes de crearla. La visibilidad de los metadatos se limita a los elementos protegibles y que son propiedad del usuario o sobre los que el usuario tiene algún permiso. La estructura de la vista es la siguiente:
name (sysname) object_id (int) principal_id (int) schema_id (int) parent_object_id (int) type (char(2)) type_desc (nvarchar(60)) create_date (datetime) modify_date (datetime) is_ms_shipped (bit) is_published (bit) is_schema_published (bit)
Si cambiamos la sentencia anterior por un create table condicionado por una consulta sobre la vista buscando por el nombre de la tabla como parámetro de object_id(función que devuelve el identificador único de un objeto por su nombre) tendremos algo así:
IF NOT EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[LogsEtl]') AND TYPE = N'U') CREATE TABLE LogsEtl (Ejecucion int PRIMARY KEY, Paquete varchar(50), Fecha datetime); GO
De esta manera lo estamos haciendo “prolijo” y la ejecución siempre será correcta (a no ser por la falta de permisos).
Realmente esto tiene otras aplicaciones porque podríamos hacer cualquier tipo de script condicionado por la existencia o no de objetos en la bbdd o modificación. Por ejemplo uno mismo podría hacer una consulta o script universal que actualizara/reconstruyera índices en base al tiempo que ha pasado desdela última modificación. Podríamos controlar a nivel de administración que esta “inventando” aquel usuario con permisos de más etc etc... en msdn hay algun ejemplo más.
Cómo solventar el error 'No se permite guardar los cambios' en SQL Server 2008
Cómo solventar el error 'No se permite guardar los cambios' en SQL Server 2008 il_masacratore 17 November, 2009 - 10:39Dado que es algo que se suele repetir y ya me lo han comentado más de una vez, creo oportuno crear un post donde se describa el problema y la solución en Sql server 2008 para newbies. Más que nada para que no perdaís tiempo buscando...
Problema:
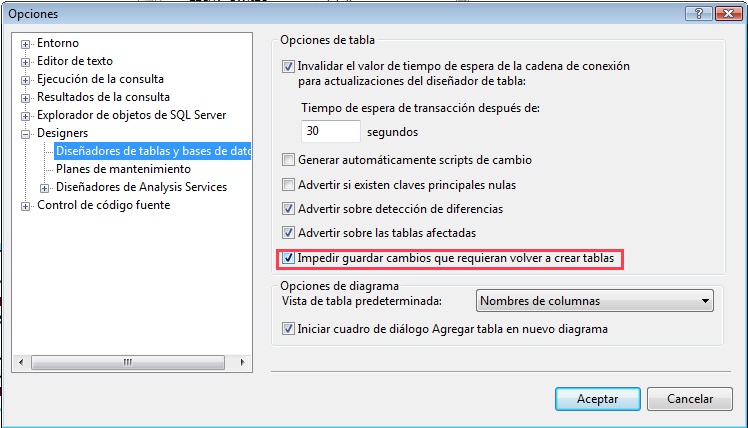
Al modificar el tipo de campo en una tabla ya creada (pero vacía) o al añadir alguna clave foránea me aperece un mensaje como el siguiente:"No se permite guardar los cambios. Los cambios que ha realizado requieren que se quiten y se vuelvan a crear las tablas".
Ejemplo:
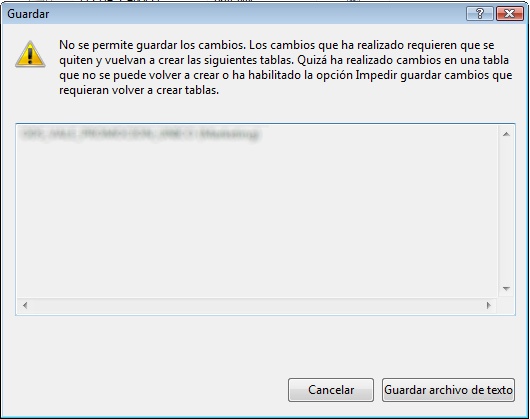
Solución:
Desmarcar la opción que impide hacer este tipo de cambios. Para ello debemos abrir la pantalla de opciones (Herramientas>Opciones), y en el apartado Designers>Diseñadores de tabla y base de datos desmarcar la opción Impedir guardar cambios que requieran volver a crear tablas. Captura:

Un tip muy útil
Pues sí, es algo muy tonto pero que si no lo sabes te deja bastante descolocado cuando empiezas con SQLServer
- Log in to post comments
Gracias ya lo había hecho
Gracias ya lo había hecho antes pero no recordaba.
- Log in to post comments
Nuevas bases de datos en nuestro servidor SQL Server 2008. Pensemos y evitemos valores por defecto
Nuevas bases de datos en nuestro servidor SQL Server 2008. Pensemos y evitemos valores por defecto il_masacratore 30 November, 2010 - 14:24
Con SQL Server podemos caer muy fácilmente en lo que se dice habitualmente sobre los productos Microsoft "Siguiente, siguiente y listo". No vamos a negarlo, Microsoft consigue hacer que gente sin mucha idea salga adelante y es todo un mérito. Pero vayamos al tema. Si se empieza una nueva aplicación y tenemos que crear la estructura de datos, no dejemos solos a los desarroladores y tampoco que usen el MS Management Studio. Normalmente, en lo que a la base de datos se refiere, cuando se crean se tienen en cuenta varias cosas:
- Ajuste adecuado de los tipos de datos para cada columna
- Foreign Keys e índices
- Tamaños por defecto en ficheros de log
- Fillfactor en los índices
Los dos primeros puntos son las buenas prácticas que se suelen comentar pero poca cosa podemos hacer como administradores de la base de datos, más que asegurarnos que tiene lugar y ayudar si es necesario. Además el tema índices es algo que se puede plantear más tarde. Pero de los dos últimos puntos somos los responsables. Deberíamos conocer el tipo de aplicación, el uso que tendrá(lect/escr) y estimar el volumen de crecimiento de los datos para poder aportar nuestro granito de arena.
Inicialmente podemos ajustar el tamaño de los archivos de la base de datos (propiedades de la base de datos). Si esperamos montar una base de datos que crecerá muy rápido incrementaremos el tamaño inicial si hace falta y ajustaremos el crecimiento de los archivos de Registro(.ldf) y de Datos de filas (.mdf). Si por el contrario es pequeña podríamos dejar los valores por defecto. Ajustando este valor evitaremos diseminar los datos por el disco (son las dos imágenes de abajo).
Otro tema a tener en cuenta y que también tiene impacto es jugar con los valores de fillfactor de los índices, en base también al porcentaje de lectura/escritura y el volumen de datos.
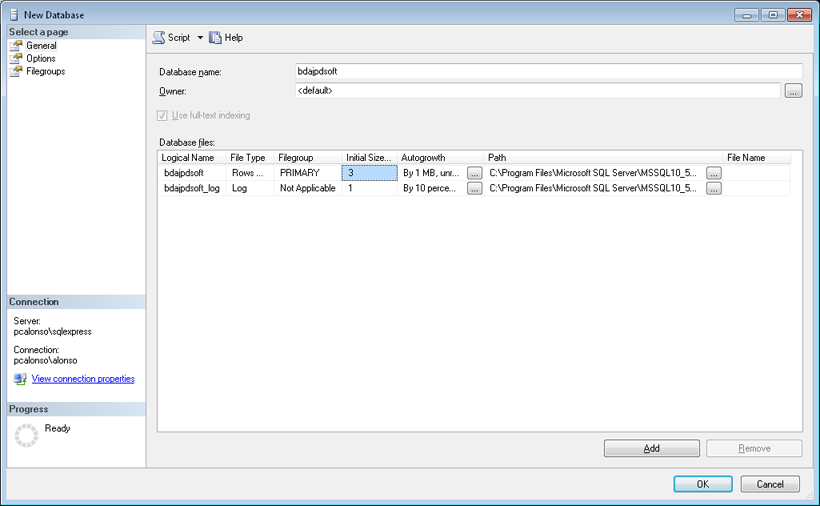
Archivos de la base de datos
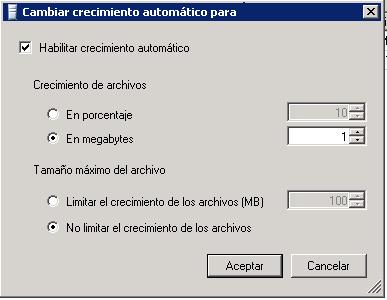
Configuración del crecimiento automático.
Eso entre otras cosas de las que ya hablaré. También es interesante que si tenemos poco espacio en disco para datos y ya no vale solo con el SHRINKFILE para vaciar logs, ante una situación de crisis podemos jugar con las prioridades y poner límites en el crecimiento automático para ciertas bases de datos que crecen de forma desmesurada ...
Politíca de backup simple para SQL Server 2008. BACKUP y RESTORE
Politíca de backup simple para SQL Server 2008. BACKUP y RESTORE il_masacratore 1 February, 2010 - 13:37A continuación dejo un par de ejemplos de como funciona el backup simple de sqlserver 2008 y como hacer un restore. En el primer ejemplo hacemos un drop de la base de datos que en un entorno real puede significar la perdida de un datafile o disco etc etc. El segundo ejemplo es algo más rebuscado y lo que se hace es restaurar la copia de la base de datos para recuperar una tabla y extraer sus datos. En ambos ejemplos se trabaja con bases de datos de ejemplo descargables aquí.
Ejemplo 1. BACKUP Y RECUPERACION SIMPLE EN CASO DE PERDIDA DE LA BASE DE DATOS
En el siguiente ejemplo se hace una copia simple y una diferencial de la base de datos AdventureWorks2008. Una vez hecho se hace un drop de la base de datos para luego restaurar la base de datos al último estado antes de borrar la base de datos.
USE master;
--Modo de recuperació simple para la base de datos en cuestion
ALTER DATABASE AdventureWorks2008 SET RECOVERY SIMPLE;
GO
--Backup simple
BACKUP DATABASE AdventureWorks2008 TO DISK='F:\SQL08\BACKUPDATA\AW2008_Full.bak'
WITH FORMAT;
GO
--Backup diferencial
BACKUP DATABASE AdventureWorks2008 TO DISK='F:\SQL08\BACKUPDATA\AW2008_Diff.bak'
WITH DIFFERENTIAL;
GO
--Destrucción!!!!
DROP DATABASE AdventureWorks2008;
GO
--Restauración del último backup
RESTORE DATABASE AdventureWorks2008 FROM DISK='F:\SQL08\BACKUPDATA\AW2008_Full.bak'
WITH FILE=1, NORECOVERY;
--Restauración de los diferenciales
RESTORE DATABASE AdventureWorks2008 FROM DISK='F:\SQL08\BACKUPDATA\AW2008_Diff.bak'
WITH FILE=1, RECOVERY;
Para este ejemplo cabe destacar que cada vez que restauramos utilizamos la opción NORECOVERY hasta importar el último fichero. También es bueno saber que el parámetro WITH FILE=X indica que "fichero" se importa. En el caso de que estuvieramos añadiendo al primer fichero la copia diferencial en lugar de crear un nuevo fichero, en el momento de restaurar el segundo fichero deberíamos poner WITH FILE=2. Por último, WITH FORMAT elimina el contenido en lugar de añadir.
Ejemplo 2. BACKUP Y RECUPERACIÓN SIMPLE EN CASO DE PERDIDA DE UNA TABLA
Este es el típico caso en el que en una base de datos conviven distintas aplicaciones y hemos perdido alguna tabla o se han hecho modificaciones que requieren recuperar datos. En este caso es posible que por ello no podamos restaurar la base de datos actual con la copia. A continuación muestro como recuperar la base de datos en una nuevo con otro fichero y otro nombre para poder traspasar o comprobar datos:
Partimos de un caso como el anterior donde se tiene una copia full y diferenciales. Suponemos que sabemos cuando se ha producido el error.
USE master;
--Modo de recuperació simple para la base de datos en cuestion
ALTER DATABASE AdventureWorksDW2008 SET RECOVERY SIMPLE;
GO
--Backup simple
BACKUP DATABASE AdventureWorksDW2008 TO DISK='F:\SQL08\BACKUPDATA\AWDW2008.bak'
WITH FORMAT;
GO
--Creación de tabla
CREATE TABLE AdventureWorksDW2008.dbo.Prueba
(
F1 char(2000),
F2 char(2000)
)
--Backup diferencial
BACKUP DATABASE AdventureWorksDW2008 TO DISK='F:\SQL08\BACKUPDATA\AWDW2008_D1.bak'
WITH DIFFERENTIAL;
--Drop de la tabla
DROP TABLE AdventureWorksDW2008.dbo.Prueba;
--Segundo backup diferencial
BACKUP DATABASE AdventureWorksDW2008 TO DISK='F:\SQL08\BACKUPDATA\AWDW2008_D2.bak'
WITH DIFFERENTIAL;
GO
--Restauración del último backup completo en otra base de datos
RESTORE DATABASE AdventureWorks2008DWTemp FROM DISK='F:\SQL08\BACKUPDATA\AWDW2008.bak'
WITH FILE=1,
MOVE N'AdventureWorksDW2008_Data' TO 'F:\SQL08\DATA\MSSQL10.TEST\MSSQL\DATA\AdventureWorksDW2008Temp_Data.mdf',
MOVE N'AdventureWorksDW2008_Log' TO 'F:\SQL08\DATA\MSSQL10.TEST\MSSQL\DATA\AdventureWorksDW2008Temp_Log.mdf',
NORECOVERY;
--Restauración de los diferenciales
RESTORE DATABASE AdventureWorks2008DWTemp FROM DISK='F:\SQL08\BACKUPDATA\AWDW2008_D1.bak'
WITH FILE=1,
RECOVERY;
Este segundo caso sería más sencillo en un entorno donde se incluyera copia de los ficheros de transacciones y pudieramos hacer una restauración point-in-time.
El código que aquí encontramos perfectamente se puede partir y podemos programar ya las copias (full y/o diferenciales) en jobs del agente de sql server. Por ejemplo podríamos hacer la copia full el domingo y de lunes a sabado seguir con los diferenciales, pero esto también se puede programar usando SQL Server Management Studio y hacerlo de forma visual (aunque saber hacerlo desde código no está de más)...
Sincronización de la base de datos de Microsoft Dynamics AX 2009 sobre Sql Server 2008
Sincronización de la base de datos de Microsoft Dynamics AX 2009 sobre Sql Server 2008 il_masacratore 26 February, 2010 - 12:02Para aquellos administradores de bases de datos que deban tratar con un tal Dynamics Ax 2009 y sus secuaces (desarrolladores, consultores, etc  ) dejo aquí un par de cosillas que se deben saber(o te deben decir) cuando unimos ax2009 y sql server 2008. A veces se puede apuntar a la base de datos como fuente del problema pero no siempre es así. Algunos requerimientos a tener en cuenta para la instalación de Ax2009 son que el usuario con el que quieran acceder para hacer la instalación debe ser usuario de DOMINIO y en sql server debe ser miembro de rol dbcreator y securityadmin para poder crear la nueva base de datos desde el instalador de Ax. Una vez instalado (o durante el proceso de instalación) los problema con la base de datos que nos podemos encontrar pueden ser:
) dejo aquí un par de cosillas que se deben saber(o te deben decir) cuando unimos ax2009 y sql server 2008. A veces se puede apuntar a la base de datos como fuente del problema pero no siempre es así. Algunos requerimientos a tener en cuenta para la instalación de Ax2009 son que el usuario con el que quieran acceder para hacer la instalación debe ser usuario de DOMINIO y en sql server debe ser miembro de rol dbcreator y securityadmin para poder crear la nueva base de datos desde el instalador de Ax. Una vez instalado (o durante el proceso de instalación) los problema con la base de datos que nos podemos encontrar pueden ser:
Caso 1:
Otro problema conocido en la sincronización de datos puede producirse por la falta de permisos. El mensaje dice algo así:
The SQL database has issued an error.
Problems during SQL data dictionary synchronization.
The operation failed.
Synchronize failed on 1 table(s)"
Este caso en concreto se soluciona dando permisos db_ddladmin sobre la base de datos en cuestión. Segun el documento oficial de instalación de Dynamics Ax 2009 el usuario de AOS debe tener los roles db_ddladmin, db_datareader, y db_datawriter sobre su base de datos activados para que todo funcione correctamente.
Caso 2:
Puede ocurrir que en Ax2009 al añadir un campo sobre una tabla puede no reflejarse en la base de datos pero sí en el AOT
de Axapta. Si es algo que ocurre solo con ese campo, o más bien con ese tipo de campo ( Extended Data Type ) la base de datos no tiene nada que ver. El problema seguramente es que la funcionalidad de la que cuelga este tipo de campo esta deshabilitada. Esto suele pasar en una nueva instalación donde no se ha activado nada (Gracias Alejandro por la ayuda!!  ).
).
En otro post espero comentar cuales son los pasos que sigue Ax cuando sincroniza una tabla.
Cómo montar dos entornos en un mismo servidor SQL Server 2008 sin que se "pisen"
Cómo montar dos entornos en un mismo servidor SQL Server 2008 sin que se "pisen" il_masacratore 16 April, 2010 - 13:54Nos ponemos en situación
En nuestro entorno es posible que necesitemos disponer de dos replicas de una/s base de datos en entornos diferenciados (el clásico ejemplo sería producción y test). Para decidir como lo hacemos las preguntas más comunes que nos debemos hacer son:
-¿Este nuevo entorno será temporal? ¿Contiene bases de datos grande en cuanto a volumen y/o la carga que debe soportar es elevada(aunque sea test)?
-¿Dispongo de la versión de desarrollo de SqlServer2008? Que solo está a tu alcance si tienes una suscripción Msdn...
-¿Dispongo de un servidor adicional?
En base a estas preguntas y todas las que se le puedan a uno ocurrir se puede optar por diferentes soluciones:
-Lo más sencillo y si la base de datos más la carga a soportar son pequeñas podemos usar el mismo servidor para todas las bases de datos (creamos en el mismo servidor con nombres distintos (_Test) y Santas pascuas...). Para que no se molesten entre si podemos usar Resource Governor.
-Lo más "aseptico" si los recursos lo permiten y siempre que merezca la pena sería montarlo en servidores distintos (si disponemos de la versión de desarrollo)
-Otra opción es una mezcla de las anteriores. Montar los dos entornos en un mismo servidor pero en instancias diferentes.
-Etc...
1 Servidor de n cpu (n > 1) + 2 instancias = 2 entornos
Una opción que me gusta de las anteriores es la tercera, donde montamos dos instancias para separar los dos entornos y configuramos la afinidad de procesadores para controlar la dedicación de cada procesado a cada instancia. También debemos controlar la memoria que asignamos a cada instancia(server memory y max server memory).
Ejemplo:
En un servidor de 6 núcleos dedicamos 2 de los cuatro procesadores a dar servicio al entorno de test mientras los 6 restantes se los adjudica el entorno de producción. Para hacerlo solo debemos abrir el SSMS y en las Propiedades del servidor:XXXX en la parte de Procesadores habilitar cada procesador manualmente (desmarcando la adjudicación automática). Ver imagen.
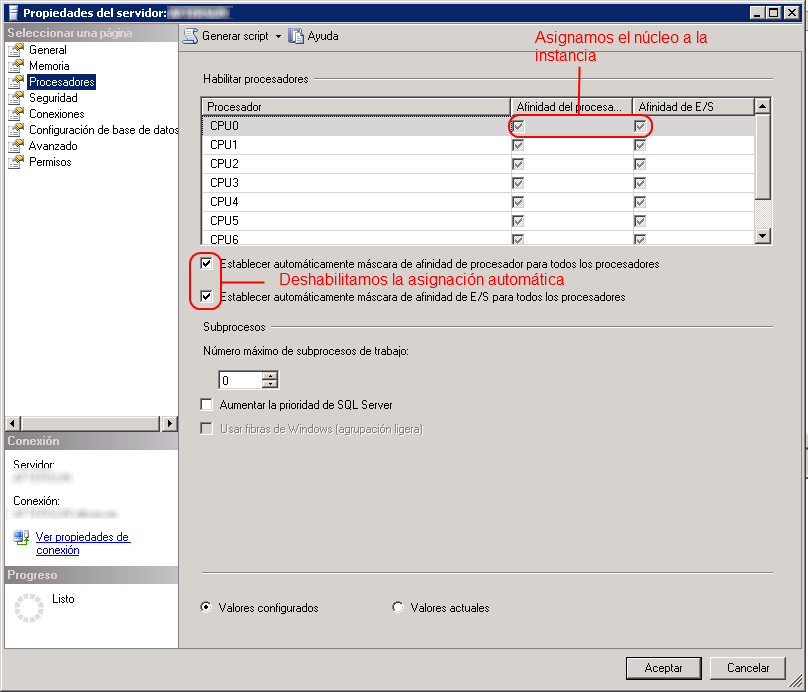
Es bueno saber también que podemos asignar y desasignar a conveniencia ya que se puede variar de forma dinámica para cada instancia. En caso de necesidad es bueno modificar la capacidad de aguante si se nos viene encima. Pero no es oro todo lo que reluce y debemos saber que al estar gestionando dos instancias ya estamos consumiendo más que si gestionáramos solo una.
Conceptos: affinity mask, affinity io mask
Cómo habilitar conexiones remotas a un servidor SQL Server sobre Windows
Cómo habilitar conexiones remotas a un servidor SQL Server sobre Windows Carlos 4 March, 2020 - 20:23Tras la instalación de un servidor SQL Server en una máquina con Windows Server, el siguiente paso lógico es configurarlo para permitir conexiones remotas a la base de datos desde otros equipos.

Para ello hay que utilizar primero el Administrador de configuración de SQL Server para habilitar el protocolo TCP/IP sobre la dirección IP del server, y después abrir los puertos necesarios (el 1433 por defecto), desde el Firewall de Windows.
Estos son los pasos básicos que yo suelo seguir, probando a conectar desde una máquina cliente como mi PC o portátil al servidor.
Comprobar que hay conexión entre el cliente y el servidor (ip 192.168.1.116)
Nunca está de más comprobar con un simple ping que hay conectividad entre las dos máquinas abriendo una consola de comandos (cmd) desde el cliente:
C:\Users\Administrador>ping 192.168.1.116 Pinging 192.168.1.116 with 32 bytes of data: Reply from 192.168.1.116: bytes=32 time<1ms TTL=128 Reply from 192.168.1.116: bytes=32 time<1ms TTL=128 Reply from 192.168.1.116: bytes=32 time<1ms TTL=128 Reply from 192.168.1.116: bytes=32 time<1ms TTL=128
(Pruebo todo directamente con la IP para descartar posibles problemas de resolución de nombres de servidor)
Comprobar con telnet que no esté abierto ya el puerto
Telnet se utiliza también desde la linea de comandos. Si tienes windows 10 y no lo tienes activado consulta aqui cómo habilitarlo.
En este ejemplo utilizamos el puerto por defecto de SQL Server 1433, aunque para más seguridad es recomendable utilizar puertos diferentes, pero ese es otro tema..
C:\Users\Administrador>telnet 192.168.1.116 1433 Connecting To 192.168.1.116...Could not open connection to the host, on port 1433: Connect failed
Habilitar el protocolo TCP/IP sobre la dirección IP del server
Abrir en el servidor el programa Administrador de configuración de SQL Server (Sql Server Configuration Manager), desde el menú de aplicaciones de SQL Server, o buscando el programa en el buscador del server.
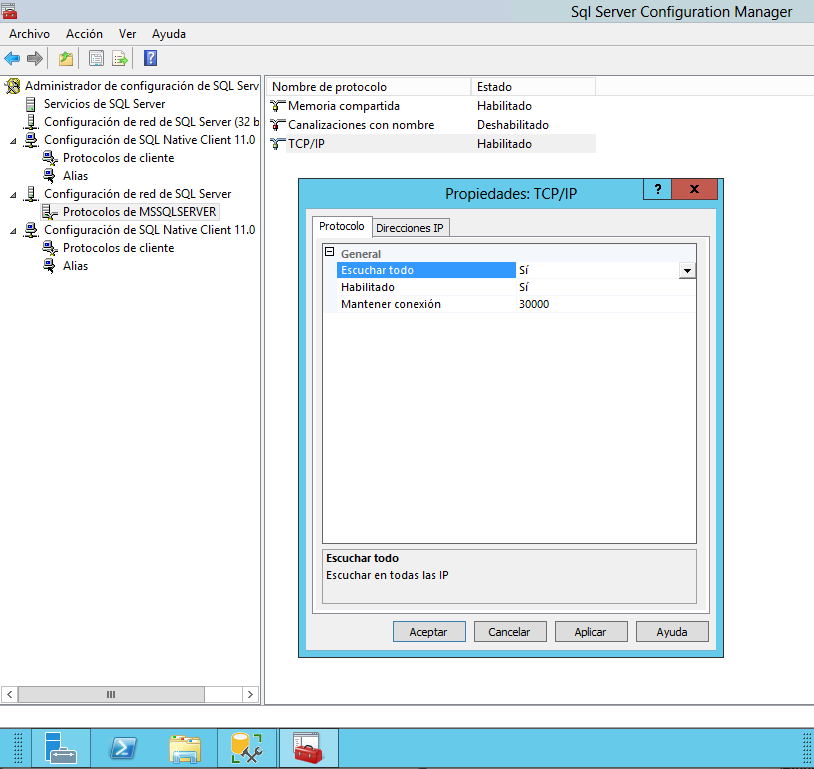
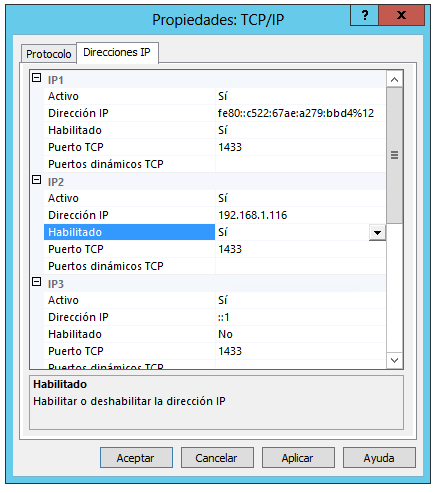
Una vez abierto, en el menú de la izquierda, en 'Configuración de red de SQL Server', Seleccionar 'Protocolos de [Nombre de la instancia]', y hacer doble click sobre el Nombre de protocolo TCP/IP para acceder a sus propiedades y seleccionar 'Si' en 'Habilitado', y en la pestaña de Direcciones IP, seleccionar también 'Si' en 'Habilitado' de la IP del server, este caso 192.168.1.116, y asegurarse de que el puerto es correcto (en este caso 1433 ya estaba bien porque es el puerto por defecto, pero si no hay que modificarlo)
Después de estas modificaciones hay que reiniciar el servicio principal de SQL Server desde la misma aplicación, en el menú 'Servicios de SQL Server'
Abrir el puerto TCP desde el Firewall de Windows Server
El siguiente paso es abrir la aplicación Firewall de Windows, desde el panel de control (Panel de control\Sistema y seguridad\Firewall de Windows), o buscando Firewall en el buscador de aplicaciones.
Una vez abierto, seleccionar 'Configuración avanzada' en el menú de la izquierda, y después, en el menú hacer click con el botón derecho sobre 'Reglas de entrada', y seleccionar 'Nueva Regla' (También se puede hacer desde la opción de menú 'Acción')
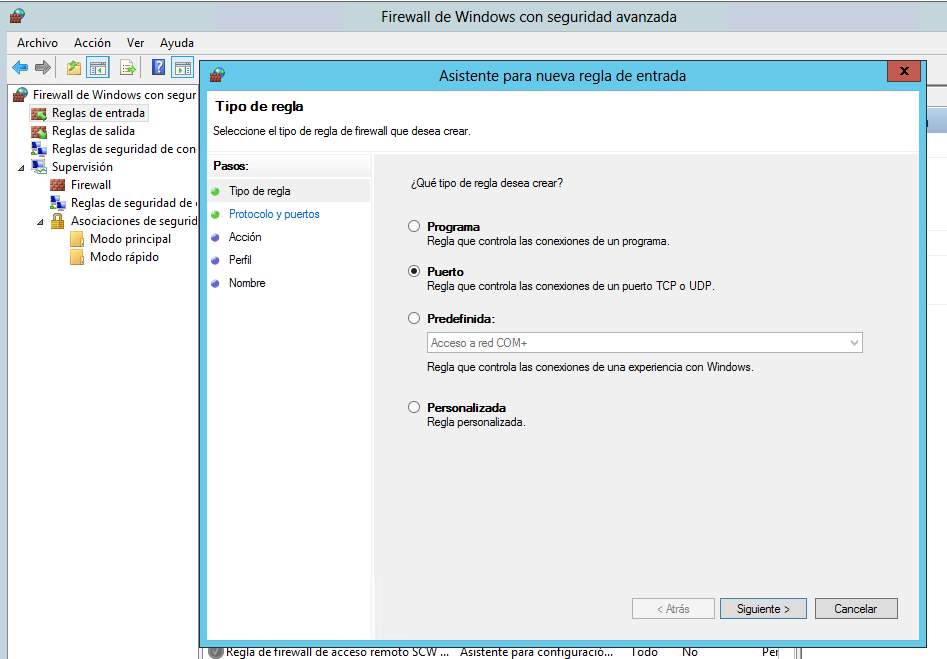
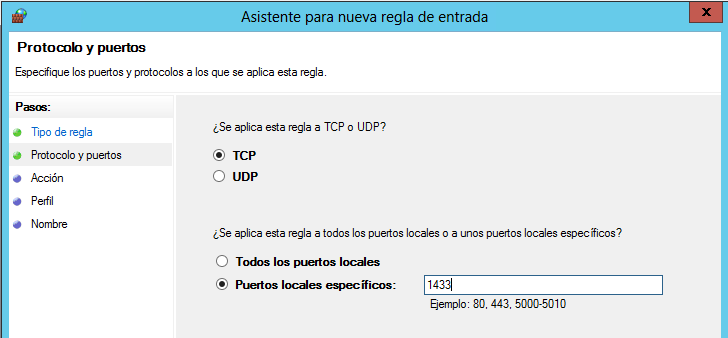
Seleccionar regla tipo 'Puerto', y después 'TCP', y escribir 1433 en la opción 'Puerto específico local'. Esta es la configuración más sencilla, y sirve si esta es la única instancia de SQL Server instalada en el Servidor Windows.
Si hubiera más instancias sería necesario abrir más puertos, activar el servicio SQL Server Browser, y abrir otro puerto UDP, y también crear una nueva regla personalizada en el firewall para el servicio.
Seleccionando las siguientes opciones (normalmente las que vienen por defecto ya van bien) se finaliza la creación de la regla del firewall, y el telnet por el puerto 1433 desde la máquina cliente ya debería responder:
C:\Users\Administrador>telnet 192.168.1.116 1433

Una vez que el telnet responde, ya se podrá conectar con SQL Server Management Studio u otra aplicación cliente, al menos por IP ;)