SSAS: Microsoft SQL Server Analysis Services
SSAS: Microsoft SQL Server Analysis Services Dataprix 23 May, 2014 - 19:35SSAS: Como monitorizar el procesamiento de cubos en Analysis Services
SSAS: Como monitorizar el procesamiento de cubos en Analysis Services il_masacratore 17 February, 2014 - 18:23Existen algunos tips que permiten mejorar el rendimiento y reducir el tiempo de procesado en nuestras bases de datos de Analysis Services. Hay unas cuantas páginas dedicadas a ello y resúmenes por ahí que marcan unas líneas a seguir (y otras que no!). En este post nombro un ejemplo y de que manera podemos medir esa posible mejora de forma objetiva basándonos en el uso de los contadores de rendimiento del sistema y de Sql Server Profiler.
Ejemplo de mejora: Evitar tablas de hechos con demasiados campos.
Imaginaros la tabla de hechos con las cabeceras de venta. Si esta tabla tiene 100 campos y solo necesitamos 10, el número de registros contenidos en cada página de 8k de datos será mucho menor que si solo se almacenaran los campos sensibles. ¿Como podemos mejorar este aspecto?
- Partición vertical de la tabla en dos diferentes. Si tenemos la posibilidad estaría bien poder hacer una partición vertical y aislar esos 10 campos que necesitamos para dejar el resto en una tabla adicional. Sin tener en cuenta el tamaño de los campos, podríamos reducir el número de páginas de datos a recorrer en un 10%. Aunque esto es lo ideal, no siempre es posible.
- Tabla derivada. En la linea de lo anterior, podríamos mantener una tabla derivada sobre la que procesar los hechos.
- Crear una Vista indizada. Con la vista hacemos la partición pero restringimos de alguna manera la tabla original e incluso podríamos ralentizar un poco la inserción de datos si es una tabla transaccional muy concurrida. No es mala opción pero hay que medir las ventajas y los inconvenientes.
Medir el procesamiento con los contadores de rendimiento de Windows Server
 La idea es trabajar sobre una linea base, una foto inicial de como está todo y después de cada cambio realizar otra monitorización para comparar las diferencias y poder medir bien que hemos cambiado y donde está la mejora o el empeoramiento. Al igual que con el motor de base de datos de Microsoft SQL Server, para monitorizar el procesado de cubos podemos usar el monitor de rendimiento del sistema para consultar los contadores de rendimiento propios de Analysis Services. En este otro post explico como se hace para la base de datos. Para la parte de Analysis Services, algunos contadores que podemos usar los siguientes:
La idea es trabajar sobre una linea base, una foto inicial de como está todo y después de cada cambio realizar otra monitorización para comparar las diferencias y poder medir bien que hemos cambiado y donde está la mejora o el empeoramiento. Al igual que con el motor de base de datos de Microsoft SQL Server, para monitorizar el procesado de cubos podemos usar el monitor de rendimiento del sistema para consultar los contadores de rendimiento propios de Analysis Services. En este otro post explico como se hace para la base de datos. Para la parte de Analysis Services, algunos contadores que podemos usar los siguientes:
- MSOLAP: Processing
Rows read/sec:
Registros que se leen por segundo en el procesado.
- MSOLAP: Proc Aggregations
Temp File Bytes Writes/sec: Ratio por segundo de escrituras en los ficheros temporales. Esto ocurre cuando se excede el límite de memoria. Cuanto más tienda a cero mejor.
Rows created/Sec : Ratio por segundo de creación por segundo. Cuanto más elevado mejor.
Current Partitions : Particiones procesadas actualmente. No sirve más que para controlar que estamos procesando y que los contadores no estén "contaminados" (por ejemplo si es mayor que 1 y no queremos procesado paralelo).
- MSOLAP: Threads
Processing pool idle threads : Puede variar según la versión, en la 2012 se separan los hilos de procesado de los de E/S. Sirve para monitorizar el paralelismo de tareas.
Processing pool job queue length : Puede variar según la versión, en la 2012 se separan los hilos de procesado de los de E/S. Sirve para monitorizar el paralelismo de tareas.
Processing pool busy threads : Puede variar según la versión, en la 2012 se separan los hilos de procesado de los de E/S. Sirve para monitorizar el paralelismo de tareas.
- MSSQL: Memory Manager
Total Server Memory : Total de memoria que está usando actualmente el motor relacional de la base de datos.
Target Server Memory : Total de memoria CONFIGURADO que debería usar el motor de base datos. Si el contador anterior es inferior a este hay algún problema y alguien se está comiendo memoria que teóricamente hemos asignado a la base de datos.
- Logical Disk
Avg. Disk sec/Transfer – All Instances - Processor:
% Processor Time – Total : % CPU consumida actualmente.
- System:
Context Switches / sec : Cambios de tarea en la cola de la cpu. Un valor bajo que tiende a 0 puede significar que algo está monopolizando el 100% de la cpu.
Controlar el uso del motor de base de datos relacional
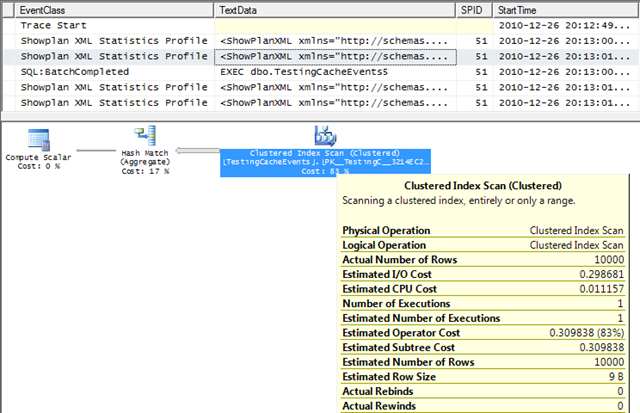
Como complemento a lo que comento en el apartado anterior, también deberíamos analizar como van las consultas SQL que tiramos sobre la base de datos relacional. Podemos complementar lo anterior con la captura de actividad desde Sql Server Profiler. Como plantilla podemos usar la de Tunning y le añadimos estos dos eventos:
- Performance/Showplan XML Statistics Profile
- TSQL/SQL:BatchCompleted
De ellos necesitamos las columnas TextData, Reads, DatabaseName, SPID y Duration. Con ellos podemos detectar cuales son las consultas que más se demoran, podemos ver su plan de ejecución y mirar los índices que pueden mejorar los tiempos en la recuperación de los datos.
En cuanto a la captura con SQL Server Profiler, es bueno saber que podemos filtrar eventos para solo mostrar lo imprescindible. En este otro post explico como funciona la captura y como filtrar para afinar la captura.
En conclusión...
... creo que conocer la manera de monitorizar el procesado de nuestros cubos nos permite ver que podemos mejorar, ya sea algo del diseño o maneras de hacer las cosas. Como comento arriba para poder empezar deberíamos comenzar con una captura inicial y tras cada posible mejora deberíamos volver a monitorizar para cuantificar la mejora. Pienso que la mayoría de contadores pueden ser evolutivos (los comparamos con anteriores) y creo que no hay un rango definido. Simplemente sabiendo lo que miden y con un poco de lógica sabremos cuando va a mejor o a peor (el contador). El único problema que podemos tener en todo esto es que podamos hacerlo de forma proactiva, el lugar de forma reactiva cuando se nos solape con otros procesos... y entonces tengamos un problema.
SSAS: Como quitarle al usuario administrador de sistema el acceso como administrador a nuestra instancia de analysis services
SSAS: Como quitarle al usuario administrador de sistema el acceso como administrador a nuestra instancia de analysis services il_masacratore 4 October, 2010 - 11:23
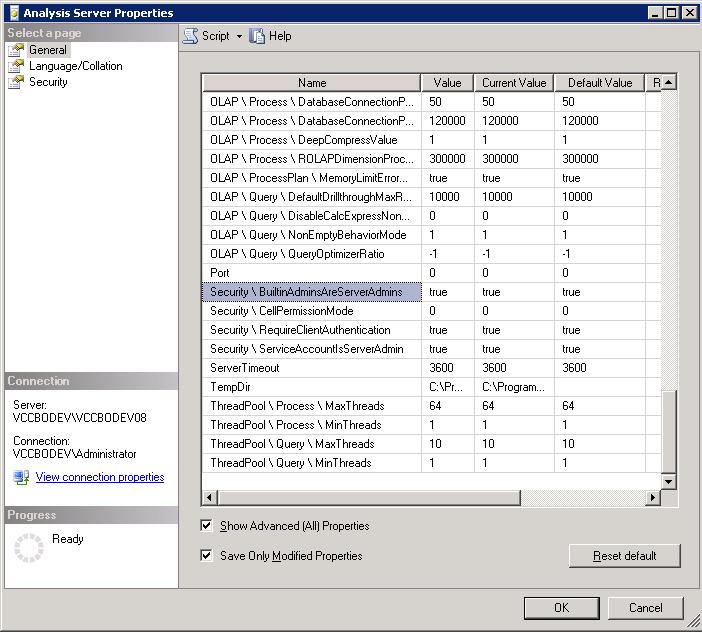
La seguridad en Analysis Services está basada en la seguridad propia de Windows. Los usuarios se autentican usando sus cuentas de Windows locales (del servidor) o de dominio y pueden tener derechos segun los roles a los que pertenecen. ¿Que quiere decir esto? Que por decreto y si no hacemos cambios en la configuración de nuestra instancia de SSAS los usuarios que pertenecen al rol de Administradores del SO pueden entrar como Administradores también en la instancia. Para cambiar este comportamiento y limitar la administración de SSAS a los usuarios que hemos marcado como tales debemos cambiar el valor de la propiedad Security\BuiltinAdminsAreServerAdmins y ponerlo a false. Pero cuidado al hacer esto, no vayamos a quedarnos sin administradores, previamente debemos asegurarnos de que tenemos otra cuenta en la lista de administradores de SSAS.
Para acceder a las propiedades de la instancia nos conectamos como administradores y hacemos click con el boton derecho en el nombre de la misma. En general la vemos y cambiamos allí el valor.
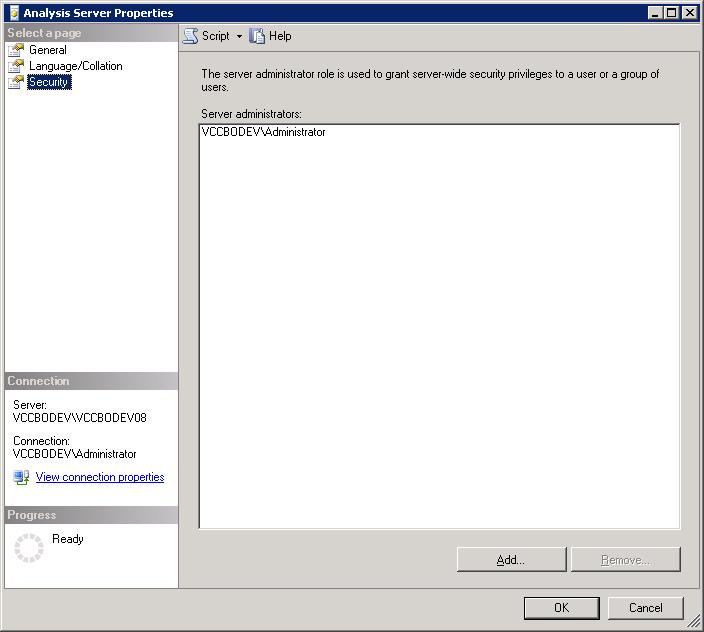
Para ver la lista de administradores actuales de la instancia que han sido añadidos explicitamente en el mismo sitio, pero en el apartado seguridad podemos consultarlo.
Tener a los administradores de sistema ahí metidos por defecto en segun que entornos puede suponer un agujero de seguridad. A mi particularmente no me gusta...

Yo creo que el agujero de
Yo creo que el agujero de seguridad suele estar más bien en la 'alegría' con la que se utilizan los usuarios administradores de Windows, si el usuario administrador se utiliza correctamente lo normal sería que también tuviera acceso para administrar SSAS, no?
- Log in to post comments
SSAS: Permitir el acceso de usuarios a los cubos
SSAS: Permitir el acceso de usuarios a los cubos il_masacratore 25 November, 2009 - 00:24Desde el punto de vista del desarrollador de bi es muy satisfactorio finalizar el diseño y la implementación de un cubo, comprobar datos y deployarlo y que todo funcione bien, al menos para tu usuario. El problema te lo puedes encontrar al desconocer como permitir el acceso a los usuarios finales a tus cubos implentados en Sql Server 2008 Analisys Services.
Adjunto una pequeña guía para obtener la satisfacción plena
permitiendo el acceso al cubo:
Para conceder permisos de lectura, procesamiento a un cubo de forma parcial, por dimensiones o medidas debemos crear una nueva Funcion dentro de nuestra base de datos ssas. Cita de los libros en pantalla de microsoft:
Las funciones se usan en Microsoft SQL Server Analysis Services para administrar la seguridad de los objetos y datos de Analysis Services.En términos simples, una función asocia los identificadores de seguridad (SID) de usuarios y grupos de Microsoft Windows que tienen derechos y permisos de acceso específicos a los objetos administrados por una instancia de Analysis Services. En Analysis Services se incluyen dos tipos de funciones:
- La función del servidor, que es una función fija que proporciona acceso de administrador a una instancia de Analysis Services.
- Las funciones de base de datos, que son funciones definidas por los administradores para controlar el acceso a los objetos y datos de los usuarios que no son administradores.
Vista la definción adjunto la localización dentro de la jerarquía del Management Studio:
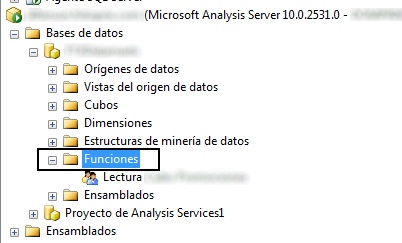
Para añadir una nueva hacemos botón derecho sobre la carpeta funciones, pulsamos nueva función y un formulario como el de la siguiente imagen. Como mínimo debemos cumplimentar:
- General. Nombre de la función y descripción. Debemos seleccionar también los permisos sobre los permisos de base de datos (mínimo leer).
- Pertenencia. Añadiremos aquí los usarios de dominios de confianza para los que queremos habilitar estos permisos.
- Orígenes de datos. Permiso de acceso al origen de datos del cubo.
- Cubos. Tipos de permiso sobre los diferentes cubos.
Los cuatro pasos anteriores son lo mínimo y cubren los permisos a nivel general, pero puede que necesitemos algo más. Conviene saber que con los apartados de Datos de Celda, Dimesiones y Datos de dimensiones podemos ocultar información sensible para ciertos usuarios.
Una vez añadida la función, editados permisos y mapeado usuarios ya nos podemos ir a tomar el café...
Cuidado!!! Esto solo vale
Cuidado!!!
Esto solo vale para cubos ya implementados y que no van a ser reprocesados desde otro sitio(management studio). Para los cubos que estan en desarrollo o que aún se procesan desde el bi development studio es mejor definirlo dentro del proyecto, ya que si no es así desapareceran las creadas desde management studio
- Log in to post comments