Resto de procesos ETL para la carga del DW
Resto de procesos ETL para la carga del DW respinosamilla 25 February, 2010 - 09:50Mas ejemplos de Talend. Ejecución de sentencias SQL construidas en tiempo ejecución.
Mas ejemplos de Talend. Ejecución de sentencias SQL construidas en tiempo ejecución. respinosamilla 25 February, 2010 - 09:50Después de llenar la dimensión Tiempo con los procesos ETL utilizando Talend, al revisar los registros de la tabla DWD_TIEMPO, comprobamos que para algunos años, la ultima semana del año se ha llenado con el valor 1. La explicación es que Java utiliza la normalización ISO para el número de semana, y esta nunca puede ser superior a 52. Por tanto, para algunos años, la ultima semana del año ha quedado registrada con el valor 1.
Este problema nos sirve de base para desarrollar nuestro seguiente proceso ETL, que ira encandenado a la generación de los registros de la dimensión tiempo, y que tendrá el objetivo de arreglar los registros que han quedado erróneos en la base de datos.
El proceso tendría los siguientes pasos:
1) Recuperación para cada año, del mayor número de semana registrado en la tabla: para ello, ejecutamos una sentencia SQL , utilizando el componente TMySqlInput del grupo Databases, Mysql).
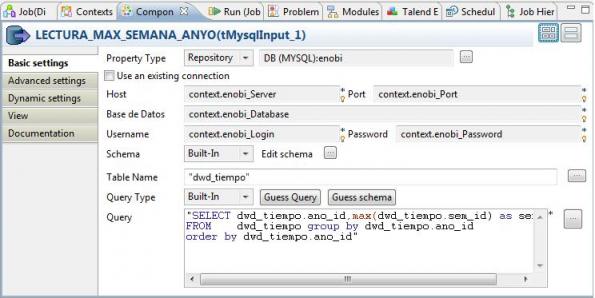
La sentencia ejecutada es la siguiente:
"SELECT dwd_tiempo.ano_id,max(dwd_tiempo.sem_id) as semana FROM dwd_tiempo group by dwd_tiempo.ano_id order by dwd_tiempo.ano_id"
Este control nos genera un flujo con todos los registros devueltos por la sentencia SQL y para cada registro realizaremos las acciones siguientes:
2) Para cada año, ejecutamos una sentencia SQL construida en tiempo de ejecución con los datos pasados por el control anterior,para arreglar el número de semana erronea (utilizando el mayor número de semana + 1). Para ello, utilizamos el control tMySqlRow. Este control nos permite ejecutar una sentencia SQL para cada registro del flujo y transmitir dicho flujo al paso siguiente del job.
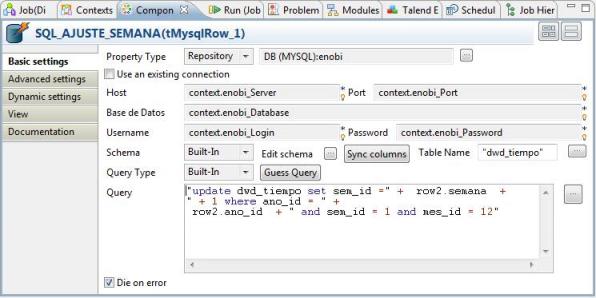
La sentencia ejecutada es la siguiente (observad como vamos construyendo la sentencia SQL concatenando trozos de texto fijo con los valores de la variable row, que seran pasados por el componente anterior de la secuencia):
"update dwd_tiempo set sem_id =" + row2.semana + " + 1 where ano_id = " + row2.ano_id + " and sem_id = 1 and mes_id = 12"
3) Terminamos el proceso de arreglo corrigiendo el campo compuesto semano_id, que también quedo erróneo y que corresponde a la Semana del año en la notacion AAAA-SS, donde AAAA es el año y SS es la semana. Para ello, utilizamos también el control tMySqlRow.
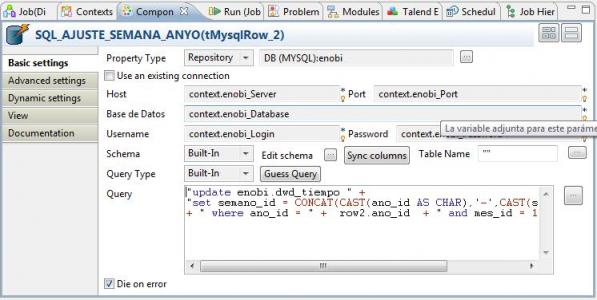
La sentencia ejecutada es la siguiente (construida igualmente concatenando trozos de texto fijo con los valores de la variable row, que seran pasados por el componente anterior de la secuencia). En este caso, también estamos utilizando funciones de Mysql (CONCAT y CAST), para hacernos una idea de la potencia del lenguaje SQL en combinación con la utilización de variables de Talend:
"update enobi.dwd_tiempo " + "set semano_id = CONCAT(CAST(ano_id AS CHAR),'-',CAST(sem_id AS CHAR))" + " where ano_id = " + row2.ano_id + " and mes_id = 12"
Los pasos 2 y 3 los podríamos haber realizado en una única sentencia SQL, pero los hemos separado para mayor claridad.
El proceso completo sería el siguiente:
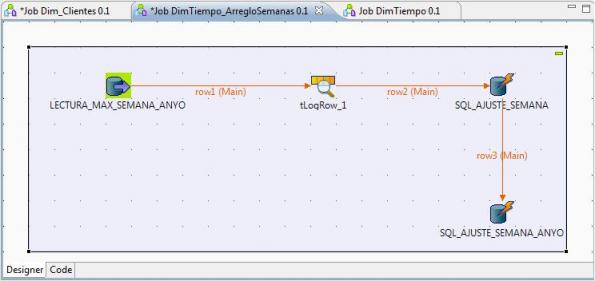
Esquema Completo del Job en Talend para el arreglo de las semanas
Seguimos avanzando en nuestro proyecto y una de las cosas que va quedando clara es que los conocimientos del consultor de BI han de cubrir muchas areas: bases de datos, sql, algo de lenguajes de programación (Java en el caso de Talend), herramientas de modelado, herramientas ETL, teoria de modelado de datos multidimensional con sus variantes, algo de estadística para el datamining, nociones de erp´s,crm´s, etc. Eso sin contar los conocimientos de las empresas, indicadores de negocio y la visión diferente que habrá que aportar a la empresa donde se realize el proyecto. Volvemos a acordarnos de lo que decía Jorge Fernández en su blog ( “El consultor de BI, ese bicho raro“).
A continuación, vamos a realizar el proceso ETL para la dimensión Producto.
ETL para carga Dimension Producto. Mas ejemplos de Talend. Uso de logs, metricas y estadisticas.
ETL para carga Dimension Producto. Mas ejemplos de Talend. Uso de logs, metricas y estadisticas. respinosamilla 25 February, 2010 - 09:50El siguiente proceso ETL que vamos a abordar es el de la carga de la Dimensión Producto. En esta dimensión se ubicarán, como ya vimos, los diferentes atributos relacionados con el producto que utilizaremos en nuestro sistema BI. Después de la revisión de la estructura física, teniendo en cuenta los origenes de datos, la estructura física de la tabla es la siguiente:
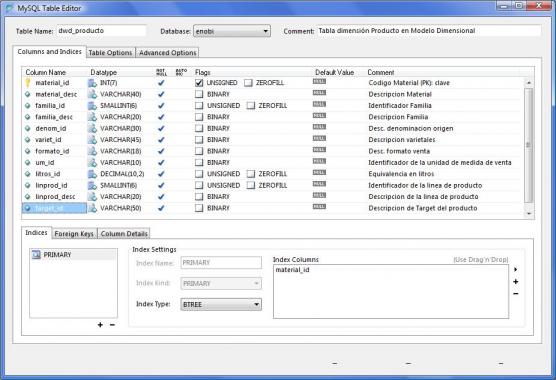
Diseño Fisico Tabla Dimensión Producto en MySql
Los procesos que tendremos que implementar utilizando Talend serán los siguientes (tal y como vimos en una entrada anterior del Blog):
.jpg)
Transformaciones para la creación de la Dimensión Producto
Para el desarrollo del proceso con Talend, vamos a ir un paso mas alla, definiendo información de logs, registro de estadísticas y métricas. Esto nos permitira conocer otra funcionalidad de Talend, y orquestar la ejecución de los jobs (para permitir, por ejemplo, la recuperación de la fecha de ultima ejecución del job para poder buscar los cambios en el maestro de materiales desde la ultima ejecución del proceso de traspaso), controlar los errores de ejecución y notificar por email en el caso de que se produzca algún problema.
El esquema completo del job con todos los pasos sería el siguiente (a continuación veremos de forma detallada cada uno de los pasos incluidos):
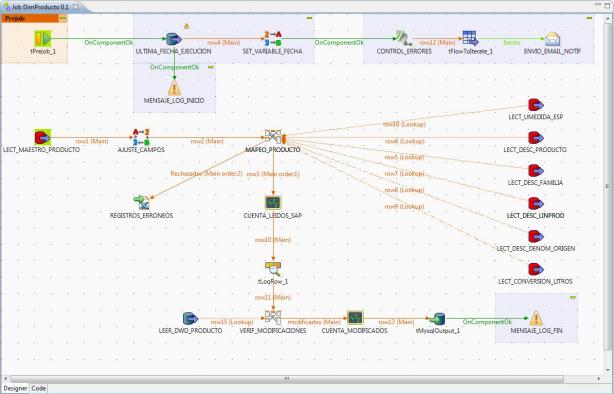
Proceso ETL en Talend completo para la dimensión Producto
Los pasos del proceso ETL para llenar la Dimensión Producto serán los siguientes:
1) Ejecución de un prejob que recuperará la fecha de ultima ejecución del proceso y registrara en el log el inicio de la ejecución del job. Además, se lanzará un logCatcher (para recoger las excepciones Java o errores en el proceso), que generará el envio de un email de aviso en el caso de que se produzca algún problema en cualquier paso del job.
2) A partir de la fecha de ultima ejecución, recuperamos del maestro de materiales en el ERP, todas las modificaciones o altas de productos realizadas en la tabla desde dicha fecha.
3) Realizamos una sustitución de valores erroneos o en blanco en los registros seleccionados según los criterios establecidos.
4) Completamos el mapeo de dimensión Producto, llenando el resto de campos que provienen de otras tablas en la base de datos (los campos de lookup), con sus correspondientes consultas SQL.
5) En el mapeo se podrán generar materiales erróneos que habrá que verificar y corregir en el sistema origen (por tener valores incorrectos). La lista de materiales se introduciran en un fichero excel. Igualmente, contaremos el número de registros leidos desde el sistema origen correctos para guardarlos en las tablas de metricas.
6) Verificamos que realmente haya modificaciones con los datos existentes en la base de datos del DW, y para los registros que si tienen modificaciones (o si son nuevos registros), realizamos la actualización. En principio, no vamos a realizar gestión de Dimensiones Lentamente Cambiantes, sino que siempre tendremos la foto de los datos tal y como están los ficheros maestros en el momento actual (mas adelante si gestionaremos una dimensión con esta casuistica para conocer los componentes de los que dispone Talend para este cometido).
7) Concluimos el proceso guardandonos en el log el correspondiente mensaje de finalización correcta del proceso.
Antes de profundizar y ver en detalle cada unos de los pasos, vamos a ver la forma de activar en Talend la gestión de logs, estadisticas y metricas. El significado de cada uno de estos elementos es el siguiente:
- Logs: sería el registro de los mensajes de error generados por los procesos, las excepciones Java al ejecutar o los mensajes generados por nosotros utilizando los componentes tDie o tWarn (para generar diferentes tipos de mensajes).
- Stats (estadísticas): es el registro de la información estadística de los diferentes pasos y componentes que forman un job. Para cada paso, se puede activar el registro de estadísticas seleccionando la opción tStatCatcher Statistics. Se guarda información de cada paso, cuando empieza, cuando termina, su status de ejecución, duración, etc.
- Meter, volumetrics (métricas): es el registro de metricas (numero de registros de un flujo) que podemos intercalar en los procesos utilizando el control tFlowMeter.
Talend nos permite trabajar de dos maneras con todos estos registros (se pueden combinar): una sería gestionando nosotros mismos los logs, stats y meters que se generan (recolectandolas en tiempo de ejecución con los componentes tLogCatcher, tStatcatcher o tFlowMeterCatcher en cada job y dandoles el tratamiento oportuno) o bien activar la gestión automática a nivel de cada proyecto o job, seleccionando en que lugar queremos guardar los registros generados(con tres opciones: visualización en consola, registro en ficheros de texto planos o registro en base de datos). Con esta ultima opción, toda la información que se genere quedara registrada en tablas y será mas fácil explotarla para revisión de procesos realizados, orquestación de procesos, verificación de cuellos de botella, corrección de errores, etc.
Para activar la gestión a nivel de proyecto seleccionaremos la opción de menú Archivo –> Edit Project Properties, opción Job Settings, Stats & Logs (tal y como vemos en la imagen):
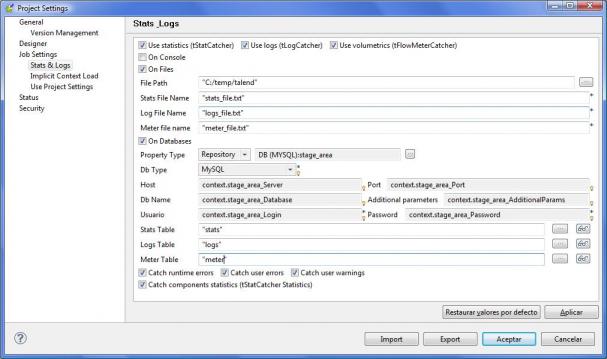
Opciones de estadísticas y logs a nivel de Proyecto
Estas propiedades quedan habilitadas para todos los jobs del proyecto, aunque luego se pueden ajustar en cada job según nos interese (puede haber jobs para los que no queremos guardar nada de información). Esto lo modificaremos en las propiedades de cada job, en la pestaña Stats & Logs. En principio, mandan las propiedades establecidas en el proyecto, pero se pueden generar excepciones (llevar los logs a un sitio diferente o no generar) para un job en concreto:
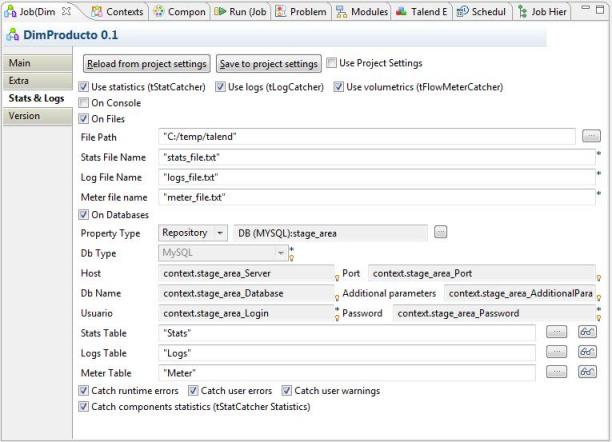
Opciones de estadísticas y logs a nivel de Job
Una vez realizada esta aclaración, veamos en detalle cada uno de los pasos del ETL:
1) Ejecución de un prejob que recuperará la fecha de ultima ejecución del proceso y registrara en el log el inicio de la ejecución del job. Además, se lanzará un logCatcher (para recoger las excepciones Java o errores en el proceso), que generará el envio de un email de aviso en el caso de que se produzca algún problema en cualquier paso del job. Los componentes utilizados en este paso inicial son los siguientes:

- Lanzador Prejob (componente tPrejob): sirve para realizar el lanzamiento de un pretrabajo, anterior al proceso principal.
- Ultima Fecha Ejecución (componente tMySqlInput): recuperamos de la tabla de registro de logs, la ultima fecha de ejecución correcta del job. Esta fecha nos servira de fecha de referencia para buscar las altas/modificaciones de productos en el ERP desde la ultima ejecución. Sino hay una ejecución anterior del job, construimos una fecha de referencia para lo que sería la carga inicial de la dimensión producto.
- Mensaje Log Inicio (componente tWarn): genera un mensaje de log indicando que se comienza la ejecución del job.
- Set Variable Fecha (componente tSetGlobalVar): la fecha de ultima ejecución recuperada en el paso anterior se registra en una variable global que se podrá utilizar posteriormente en cualquier paso del job.
- Control Errores (componente tLogCatcher): activamos el componente que “escuchara” durante toda la ejecución del job, esperando que se produzca algún tipo de error. En ese momento se activara para recuperar el error y pasarlo al componente siguiente para el envio de un email de notificación.
- tFlowtoIterate: convertimos el flujo de registros de log a una iteración para poder realizar el envio del correo electrónico.
- Envio Email Notif (componente tSendMail): generamos el envio de un email de notificación de errores, incluyendo el paso donde se paro el proceso, y el mesaje de error generado. Es una forma de avisar que ha fallado algo en el proceso.
Para ver en detalle como hemos definido cada componente, podeis pulsar en el link de cada componente o para ver la documentación HTML completa generada por Talend pulsando aquí.
2) A partir de la fecha de ultima ejecución, recuperamos del maestro de materiales en el ERP, todas las modificaciones o altas de productos realizadas en la tabla desde dicha fecha.
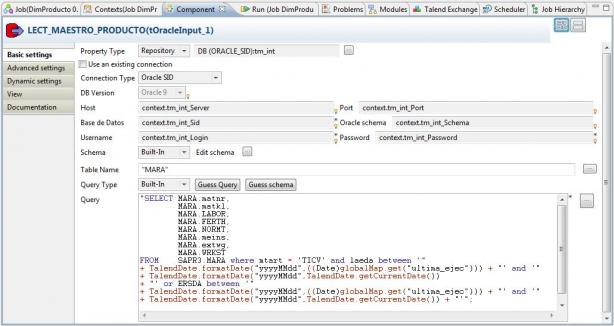
Job DimProducto - Lectura Maestro Productos Sap
Para ello, utilizamos el componente LECT_MAESTRO_PRODUC TO del tipo tOracleInput (ver detalle aqui ), que nos permite acceder a la base de datos de Sap, que en este caso es Oracle. También podiamos haber realizado la lectura de Sap utilizando los componentes tSAPConnectiony tSAPInput). Observar la sentencia SQL ejecutada en el componente, y ver como combinamos el texto escrito con el uso de una variable global y el uso de funciones de Taled (que también podrían ser Java).
3) Realizamos una sustitución de valores erroneos o en blanco en los registros seleccionados según los criterios establecidos. Utilizando el componente AJUSTE_CAMPOS, del tipo tReplace (ver detalle aqui), con el que podemos buscar valores existentes en los registros recuperados (utilizando cadena regulares) e indicar una cadena de sustitución. Puede ser util para cualquier transformación que haya que realizar para determinados valores, para normalizar, para corregir registros erróneos, etc. En nuestro caso, la vamos a utilizar para sustituir registros sin valor (se podría haber optado también por rechazar dichos registros).
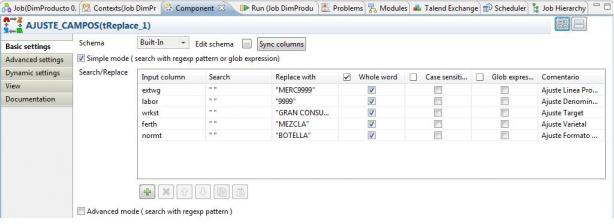
Job DimProducto - Ajuste Campos
4) Completamos el mapeo de dimensión Producto, llenando el resto de campos que provienen de otras tablas en la base de datos (los campos de lookup), con sus correspondientes consultas SQL. Para ello utilizamos el componente MAPEO_PRODUCTO del tipo tMap (ver detalle aqui ).
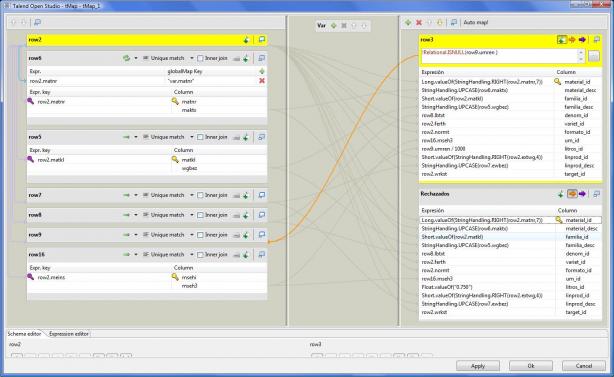
Job DimProducto - Mapeo Producto
Con este componente, juntamos en un paso los registros leidos del maestro de materiales, y los valores adicionales que estan en otras tablas del ERP que nos permiten completar cada registro (como son los valores de descripciones, unidades de medida, calculo de equivalencia de unidades de medida, etc).
En este mapeo, utilizamos una funcionalidad de Talend que no habiamos visto, que es realizar un filtrado selectivo de los registros. Esto nos permite generar en el paso dos flujos de datos, uno con los registros correctos, y otro con los registros que no cumplan unas determinadas condiciones. En nuestro caso, los registros que tengan un valor NULL en el campo umren, serán rechazados y pasados a un paso posterior donde serán grabados en un fichero excel para su revisión.
5) En el mapeo se podrán generar materiales erróneos que habrá que verificar por parte de algún usuario y corregir en el sistema origen (por tener valores incorrectos). La lista de materiales se introducira en un fichero excel a través del control REGISTROS_ERRONEOS del tipo tFileOutputExcel (ver aqui) . Igualmente, utilizando el componente CUENTA_LEIDOS_SAP del tipo tFlowMeter (ver aqui ),contaremos el número de registros correctos leidos desde el sistema origen para guardarlos en las tablas de metricas (para luego poder otener información estadística de los procesos realizados).
6) Verificamos que realmente haya modificaciones con los datos existentes en la base de datos del DW , y para los registros que si tienen modificaciones (o si son nuevos registros), realizamos la actualización. Para ello, utilizamos el componente VERIF_MODIFICACIONES del tipo tMap (ver aqui ) que recibira como flujo principal los registros que hemos leido desde Sap totalmente completados. Por otro lado, recibira como flujo de lookup (ver aqui) los registros que ya tenemos cargados en Myql en la tabla DWD_PRODUCTO (la tabla de la dimensión Producto). Con esta información, podremos realizar la comparación en el mapeo, realizarando un filtrado selectivo de los registros, pasando al siguiente componente solo aquellos que tienen modificaciones (hay alguna diferencia en alguno de los campos).
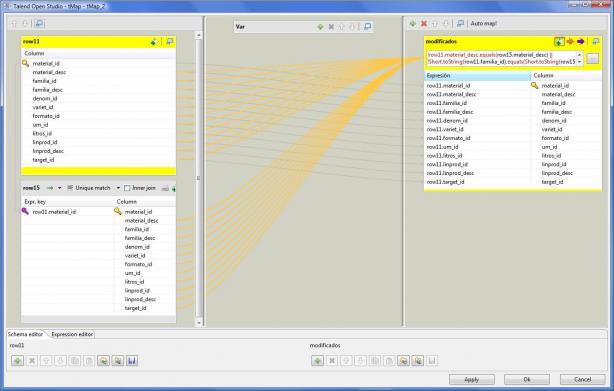
Job DimProducto - Verificacion Modificaciones
El código utilizado en el expression filter, que es la condición de filtrado, es el siguiente:
!row11.material_desc.equals(row15.material_desc) || row11.familia_id!=row15.familia_id|| !row11.familia_desc.equals(row15.familia_desc)|| !row11.denom_id.equals(row15.denom_id)|| !row11.variet_id.equals(row15.variet_id)|| !row11.formato_id.equals(row15.formato_id)|| !row11.um_id.equals(row15.um_id)|| row11.litros_id!=row15.litros_id|| row11.linprod_id!=row15.linprod_id|| !row11.linprod_desc.equals(row15.linprod_desc)|| !row11.target_id.equals(row15.target_id)
Observar como vamos realizando la comparación campo a campo de los dos flujos, para determinar si hay algún cambio entre los datos ya cargados y los provenientes del ERP.
En principio, no vamos a realizar gestión de Dimensiones Lentamente Cambiantes, sino que siempre tendremos la foto de los datos tal y como están los ficheros maestros en el momento actual (mas adelante si gestionaremos una dimensión con esta casuistica para conocer los componentes de los que dispone Talend para este cometido). Los registros que superan el mapeo, son registrados en la base de datos Mysql utilizando el control ACTUALIZA_DWD_PRODUCTO, del tipo tMySqlOutput (ver detalle aqui ), grabandose como ya hemos dicho en la tabla DWD_PRODUCTO.
Con el componente tFlowMeter, en el paso CUENTA_MODIFICADOS (ver detalle aquí ), registramos en las tablas de metricas el número de registros que van a generar actualización.
7) Concluimos el proceso guardándonos en el log el correspondiente mensaje de finalización correcta del proceso, con el componente MENSAJE_LOG_FIN del tipo tWarn (ver detalle aqui).
Para ver en detalle como hemos definido cada componente, podeís acceder a la documentación HTML completa generada por Talend aquí. Podeis descargaros el fichero zip que contiene dicha documentación aquí.
Conclusiones
Hemos realizado nuestro primer trabajo ETL complejo utilizando Talend. Ha sido un poco complicado entender como funciona la herramienta, como se vinculan y encadenan los diferentes componentes, la forma de pasar la información y los registros entre ellos, como se gestionan los errores, etc. Pero una vez comprendidos los conceptos básicos, se observa el gran potencial que tiene Talend (que ademas puede ser completado con el uso del lenguaje Java por todas partes). Os recomiendo si quereis ampliar el conocimiento de la herramienta, la lectura del Manual de Usuario de la herramienta y la Guia de Referencia de Componentes (ambos en inglés) en este link y visitar la web del proyecto Open TalendForge, donde podeis encontrar Tutoriales, Foros, gestión de bugs, etc.
También he visto lo importante que es el proceso de análisis de los origenes de información y el detallado de todas las transformaciones que hay que realizar, las excepciones, que criterio se sigue para ellas, que sustituciones realizamos, etc. Quizas deberiamos de haber realizado ese paso mas en profundidad, pues luego al realizar los procesos ETL han aparecido situaciones que no habiamos previsto. Lo tenemos en cuenta para nuestro próximo proyecto.
Igualmente hemos visto que es importante establecer un mecanismo para la gestión de todos los logs de la ejecución de procesos, estadísticas y metricas, pues luego nos serán de utilidad para montar los procesos de automatización, seguimiento y depuración de errores necesarios para la puesta en productivo del proyecto y para su mantenimiento a lo largo del tiempo.
Y como no, la documentación. El hecho de ir documentando y explicando cada componente que utilizamos en Talend (nombrado de los pasos, texto explicativo en cada componente, comentarios en los metadatos, etc), ha permitido que utilizando una funcionalidad estandar de Talend, la generación de documentación HTML, disponer de un repositorio donde poder consultar como estan construidos los procesos, de una forma muy completa y detallada, de cara a la comprensión de como están montados los procesos por parte de terceras personas, para su posterior modificación o mantenimiento en el futuro.
En la siguiente entrada del Blog, detallaremos los procesos ETL para la carga del resto de dimensiones de nuestro proyecto. Posteriormente, abordaremos el proceso ETL para la carga de la tabla de Hechos, que será la mas compleja y para la que habrá que establecer un mecanismo de orquestación para su automatización. En dicha entrada incluiremos igualmente el estudio del particionado de tablas utilizando Mysql, que veremos en profundidad.
Comparativa ETL´s OpenSource vs ETL´s Propietarias
Comparativa ETL´s OpenSource vs ETL´s Propietarias respinosamilla 25 February, 2010 - 09:50La elección de una herramienta ETL puede ser una tarea compleja que va a tener mucha repercusión en el desarrollo posterior de un proyecto. Podeis ver la comparativa de ETL´s OpenSource vs ETL´s Propietarias a continuación ( gracias a https://www.jonathanlevin.co.uk/). Aqui se habla de que las herramientas OpenSource ya estan empezando a ser una alternativa real a los productos existentes y se estan desarrollando con rapidez.
[slideshare id=1497055&doc=etl-124344719247-phpapp01]
Igualmente, os dejo el link a un documento donde se habla de todo lo que tendremos que tener en cuenta a la hora de realizar la selección de una herramienta ETL (características que habrán de tener, criterios para la evaluación, etc). Acceder al documento aquí.
Comparativa Talend / Pentaho
Si finalmente os decidis por utilizar herramientas ETL Open, la empresa francesa ATOL ha realizado una comparativa entre Pentaho y Talend con varios casos de ejemplo, comparativa de características, etc. (acceder al informe aquí , esta escrita en Frances pero es bastante completa).
Tambien os puede resultar interesante para comparar ambos productos la entrada del blog Wiki Wednesday, donde Vincent McBurney nos habla de los pros y contras de cada una de las herramientas, de una forma bastante completa (ademas hace referencia a varios sitios donde se estan analizando ambos productos).
ETL Talend Dimension Cliente.Tipos de Mapeo para lookup. Gestión de SCD (Dimensiones lentamente cambiantes).
ETL Talend Dimension Cliente.Tipos de Mapeo para lookup. Gestión de SCD (Dimensiones lentamente cambiantes). respinosamilla 25 February, 2010 - 09:50El proyecto ENOBI sigue avanzando en la parte mas compleja y que seguramente mas recursos consumira, los procesos ETL. Como ya indicamos, en algunos proyectos puede suponer hasta el 80% del tiempo de implantación. Y no solo eso, el que los procesos esten desarrollados con la suficiente consistencia, rigor, calidad, etc. va a determinar el exito posterior del proyecto y que la explotación del sistema de Business Intelligence sea una realidad. Seguramente si los procesos de extraccion, transformación y carga no esta bien desarrollados, eso pueda acabar afectando al uso correcto del sistema
Para concluir los procesos ETL de las Dimensiones del proyecto, vamos a abordar la carga de la Dimensión Cliente, que incluye todos los atributos por los que analizaremos a nuestros clientes. Vamos a obviar la publicación de los proceso de carga de la Dimensión Logistica y Promoción, pues son muy sencillos y no aportan nada nuevo.
Al detallar los procesos de la carga de la Dimension Cliente, entraremos en detalle en las diferente formas que tiene Talend de realizar los mapeos de tablas de lookup. Es decir, cuando tenemos un valor para el que tenemos que recuperar un valor adicional en otra tabla de la base de datos (por ejemplo, para un código de cliente recuperar su nombre; para la familia de producto, introducida en el maestro de materiales, recuperar de la tabla de parametrización su descripción, etc ), ver de que maneras Talend nos permite realizar dicha consulta.
Igualmente, veremos mas ejemplos de utilización de Java dentro de los componentes, y la potencia que ello nos proporciona (aunque nos obliga a tener conocimientos amplios de este lenguaje).
Para completar el ejemplo, aunque en realidad en nuestra dimensión no vamos a gestionar las dimensiones lentamente cambiantes (SCD Slowly Change Dimension), vamos a incluir un ejemplo de tratamiento de este tipo de dimensiones, utilizando el componente que tiene Talend para ese cometido, que implementa el algoritmo correspondiente para su procesamiento (elemento tMySQLSCD).
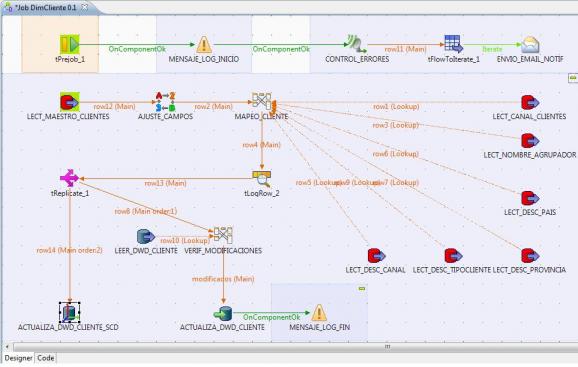
Proceso ETL en Talend completo para la dimensión Cliente
Tal y como vemos en la imagen anterior, los pasos del proceso ETL para llenar la Dimensión Cliente serán los siguientes:
1) Ejecución de un prejob que lanzará un generara en el log un mensaje de inicio del proceso y un logCatcher (para recoger las excepciones Java o errores en el proceso). Este generará el envio de un email de aviso en el caso de que se produzca algún problema en cualquier paso del job.
- Lanzador Prejob (componente tPrejob): sirve para realizar el lanzamiento de un pretrabajo, anterior al proceso principal.
- Mensaje Log Inicio (componente tWarn): genera un mensaje de log indicando que se comienza la ejecución del job.
- Control Errores (componente tLogCatcher): activamos el componente que “escuchara” durante toda la ejecución del job, esperando que se produzca algún tipo de error. En ese momento se activara para recuperar el error y pasarlo al componente siguiente para el envio de un email de notificación.
- tFlowtoIterate: convertimos el flujo de registros de log a una iteración para poder realizar el envio del correo electrónico.
- Envio Email Notif (componente tSendMail): generamos el envio de un email de notificación de errores, incluyendo el paso donde se paro el proceso, y el mesaje de error generado. Es una forma de avisar que ha fallado algo en el proceso. En la siguiente imagen tenéis un ejemplo de un email de notificación de error enviado a una cuenta de gmail.
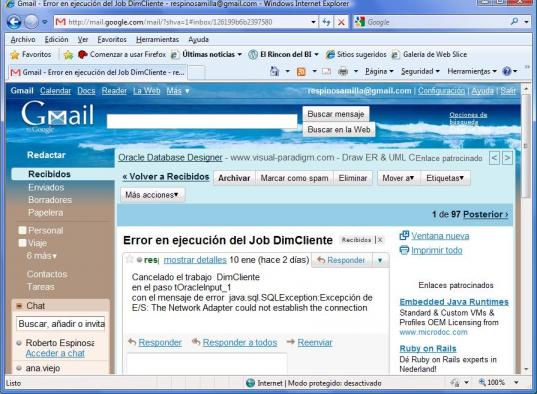
Ejemplo envio Email de notificacion de error
2) Recuperamos del maestro de cliente en el ERP, todos los clientes existentes en el fichero maestro (con el componente tOracleInput).
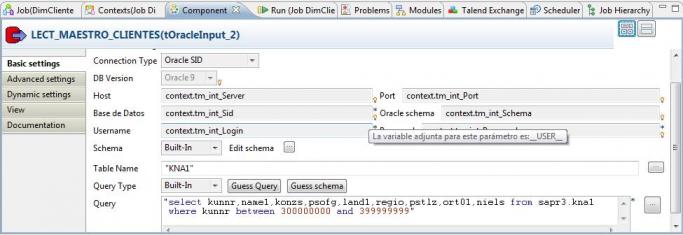
Job DimCliente - Lectura Maestro Clientes Sap
3) Realizamos una sustitución de valores erroneos o en blanco en los registros seleccionados según los criterios establecidos (con el componente tReplace), como ya vimos en los procesos ETL de la Dimensión Producto.
4) Completamos el mapeo de dimensión Cliente, llenando el resto de campos que provienen de otras tablas en la base de datos (los campos de lookup), con sus correspondientes consultas SQL (utilizando el componente tMap).
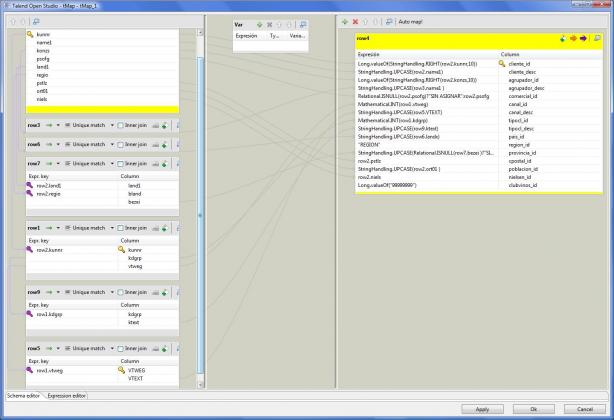
Job DimCliente - Mapeo Cliente
Podeis observar como al realizar el mapeo del maestro de clientes con las correspondientes tablas de lookup (donde estan el resto de campos y descripciones), hemos estado utilizado sintaxis del lenguaje Java. Esto nos da mayor potencia a las transformaciones y nos permitirán hacer casi de todo, aunque tendremos que conocer bien Java, sus tipos de datos, la forma de convertirlos. Algunos ejemplos son:
- Relational.ISNULL(row2.psofg)?”SIN ASIGNAR”:row2.psofg : el operador Java que nos permite asignar un valor u otro a un resultado segun si se cumple una condición o no. En este caso, si row2.psofg es nulo, al resultado se le dara el valor “SIN ASIGNAR”. En caso contrario, se le dara el valor del campo row.psofg.
- StringHandling.UPCASE(row2.ort01 ) : es un metodo de la clase StringHandling, que nos permite pasar una cadena a mayúsculas.
- Long.valueOf(StringHandling.RIGHT(row2.konzs,10)) : utilizamos el metodo RIGHT de la clase StringHandling para obtener una subcadena, y el resultado lo convertimos al tipo de datos numérico Long con el metodo de este valueOf.
Tipos de Mapeo en el componente tMap
Cuando utilizamos el componente tMap para completar los datos de nuestro flujo con valores proveniente de otras tablas (u otros ficheros u origenes de datos), vemos que siempre tenemos un flujo Main (en nuestro caso con los datos que llegan del fichero maestro de Sap) y uno o varios flujos lookup (lo podeis observar en la imagen anterior). Estos flujos de lookup nos permiten “rellenar” valores que residen en otro lugar, buscandolos por una clave determinada. La clave puede venir del propio flujo Main o de otros flujos de lookup (de forma anidada). Pensar por elemplo el caso de recuperar, a partir del código de cliente, un dato asociado (como el comercial asignado). Posteriormente, para el código de comercial, busco en otro lookup, utilizando ese código, el nombre de dicho comercial.
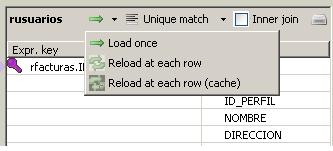
Los flujos de lookup pueden ser de tres tipos, como vemos en la imagen. Veamos en que consiste cada uno de ellos:
- Load Once: la rama de lookup del componente tMap se ejecuta una unica vez y siempre antes de la ejecución del componente tMap. En este caso, la ejecución unica de la rama de lookup ha de generar todos los registros para poder buscar valores en ellos (será una carga de todo un fichero maestro, por ejemplo). Si los datos para el lookup tuvieran muchos registros, podría ser un cuello de botella para el proceso, e igual convendría utilizar el tipo Reload at each row.
- Reload at each row: la rama del lookup se ejecuta para cada registro que llegan del flujo Main. Este tipo de mapeo nos permite ejecutar la consulta de lookup para un valor concreto (podremos pasar un valor unico que sera el que realmente busquemos. Ver ejemplo posterior de este tipo de lookup). Puede tener sentido utilizarlo con tablas de lookup muy grandes que no tiene sentido gestionar en una consulta de atributos (pensar en una tabla maestro de clientes de millones de registros).
- Reload at each row (cache): idem al anterior, pero los registros que se van recuperando se guardan en la cache. En las siguientes consultas, se mira primero en la cache, y si ya existe, no se lanza el proceso. En el caso de que no exista, entonces si se relanza la ejecución para buscar los valores que faltan.
En este caso, en todos los flujos de lookup hemos utilizado el tipo Load Once (mas adelante veremos un ejemplo de uso Reload at each row).
5) Verificamos que realmente haya modificaciones con los datos existentes en la base de datos del DW (también con el componente tMap), y para los registros que si tienen modificaciones (o son nuevos registros), realizamos la actualización. En principio, no vamos a realizar gestión de Dimensiones Lentamente Cambiantes, sino que siempre tendremos la foto de los datos tal y como están los ficheros maestros en el momento actual.
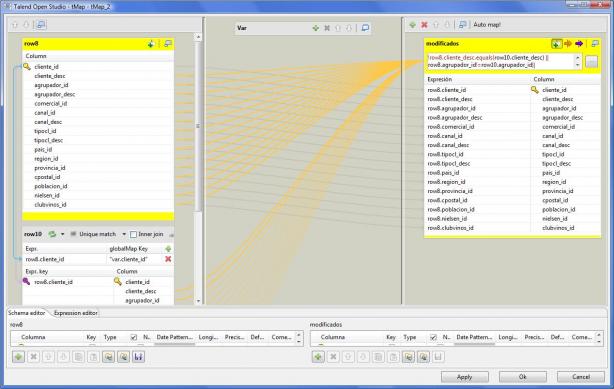
Job DimCliente - Verificacion Modificaciones
Para discriminar el paso de registros al paso siguiente de actualización en la base de datos del DW, se ejecuta la siguiente expresión condicional (vemos que es 100% lenguaje Java). La expresión va comparando campo por campo entre los valores recuperados de nuestro ERP y los existentes en la tabla de la dimensión cliente DWD_CLIENTE.
!row8.cliente_desc.equals(row10.cliente_desc) || row8.agrupador_id!=row10.agrupador_id|| !row8.agrupador_desc.equals(row10.agrupador_desc)|| !row8.comercial_id.equals(row10.comercial_id)|| row8.canal_id!=row10.canal_id|| !row8.canal_desc.equals(row10.canal_desc)|| row8.tipocl_id!=row10.tipocl_id|| !row8.tipocl_desc.equals(row10.tipocl_desc)|| !row8.pais_id.equals(row10.pais_id)|| !row8.region_id.equals(row10.region_id)|| !row8.provincia_id.equals(row10.provincia_id)|| !row8.cpostal_id.equals(row10.cpostal_id)|| !row8.poblacion_id.equals(row10.poblacion_id)|| !row8.nielsen_id.equals(row10.nielsen_id)|| row8.clubvinos_id!=row10.clubvinos_id
Cuando el lookup lo ejecutamos para cada registro que llega al control tMap (en este caso utilizamos el tipo Reload at each row), la sentencia SQL que se ejecuta en el flujo de lookup es la siguiente (observa que en la condición del where utilizamos una variable que hemos generado en el control tMap, y será la que contiene el código de cada cliente que queremos verificar). En este caso, el paso asociado al flujo lookup se ejecuta una vez para cada registro que llegue al componente tMap y siempre posteriormente:
"SELECT dwd_cliente.cliente_id,
dwd_cliente.cliente_desc,
dwd_cliente.agrupador_id,
dwd_cliente.agrupador_desc,
dwd_cliente.comercial_id,
dwd_cliente.canal_id,
dwd_cliente.canal_desc,
dwd_cliente.tipocl_id,
dwd_cliente.tipocl_desc,
dwd_cliente.pais_id,
dwd_cliente.region_id,
dwd_cliente.provincia_id,
dwd_cliente.cpostal_id,
dwd_cliente.poblacion_id,
dwd_cliente.nielsen_id,
dwd_cliente.clubvinos_id
FROM dwd_cliente
WHERE cliente_id = " + (globalMap.get("var.cliente_id"))
En este caso, la sentecia SQL (y el correspondiente componente que la contiene), se ejecutara una vez por cada registro que llega por el flujo Main al componente tMap. Y la sentencia SQL solo recuperara un registro de la base de datos, aunque se estará ejecutando continuamente (le hemos pasado con la variable var.cliente_id el valor a buscar).
6) Concluimos el proceso guardándonos en el log el correspondiente mensaje de finalización correcta del proceso, con el componente MENSAJE_LOG_FIN del tipo tWarn.
TRATAMIENTO DE LAS DIMENSIONES LENTAMENTE CAMBIANTES
Como ejemplo y para estudiar su funcionamiento, incluimos un paso para la gestión de las dimensiones lentamente cambiantes (que se grabaran en una tabla paralela a la de la dimensión cliente). El tipo de componente en Talend para realizar esto será el tMySqlSCD.
Para entender que son exactamente las dimensiones lentamente cambiantes, os recomiendo un poco de literatura. En el blog Business Intelligence Facil, se explican de una forma muy clara que son y como gestionarlas ( ver aquí ), así como de las claves subrogadas. Tambien Jopep Curto nos da muy buenas definiciones en su blog.
Una vez tengamos clara la teoria, vamos a ver como aplicarlo a la practica utilizando los componentes de Talend.
Componente para gestion dimensión lentamente cambiante
El algoritmo de la dimensión SCD se gestiona con el correspondiente editor, tal y como vemos en la imagen siguiente:
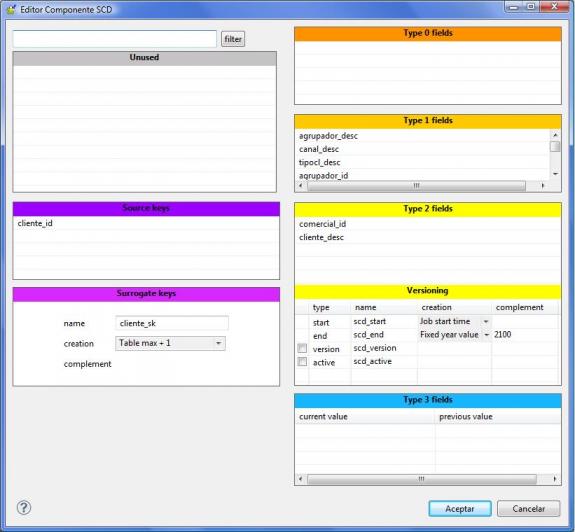
Editor Componente SCD
Para utilizar el editor, se indica un nombre de tabla existente en la base de datos, que sera la tabla para la cual vamos a gestionar la SCD (ha de incluir los campos necesarios para la gestión de versiones según lo indicado en el editor SCD). El control recibirá un flujo con los registros a procesar contra la tabla indicada. En el editor SCD indicamos como se va a comportar la actualización contra la tabla según los diferentes tipos de atributos.
Los controles que forman el editor de dimensiones SCD son los siguientes:
- Unused: aquí apareceran todos los campos disponibles para utilizar en el editor SCD. Desde este sitio iremos arastrando los campos al resto de sitios.
- Source keys: son las claves principales de los datos (la clave en el sistema original). Para un maestro de clientes, aquí indicaremos la clave que identifica a este en el sistema origen.
- Surrogate keys: es el nombre que le damos a la clave subrogada. Es decir, aquella clave inventada que nos va a permitir gestionar versiones de nuestros datos en el DW.
- Type 0 fields: aqui indicaremos los campos que son irrelevantes para los cambios. Si aqui metemos, por ejemplo, el campo nombre, cualquier cambio en el sistema origen con respecto a los datos existentes en el DW no se va a tener en cuenta (se ignorará).
- Type 1 fields: aquí indicaremos los campos para los que, cuando haya un cambio, se machacará el valor existente con el valor recibido, pero sin gestionar versionado.
- Type 2 fields: aquí indicaremos los campos para los que queremos que, cuando haya un cambio, se produzca un nuevo registro en la tabla (con una nueva subrogated key). Es decir, aquí pondremos los campos que son dimensiones lentamente cambiantes y para los que queremos gestionar un versionado completo.
- Versioning: aqui indicamos los valores para el versionado (fecha de inicio y fecha de fin), y si queremos llevar un control de numero de versión o flags de registro activo (requeriran campos adicionales en la tabla para este cometido).
- Type 3 fields: aquí indicaremos los campos para los que queremos guardarnos una versión anterior del valor (es decir, cuando haya un cambio, siempre tendremos dos versiones, la ultima y la anterior).
Para concluir la explicación de las dimensiones SCD, observar las diferencias de catalogo entre el flujo de entrada y el flujo de salida (en el de salida se han incluido atributos propios para la gestión de la dimension lentamente cambiante, gestión de versiones, fechas de validez, etc):
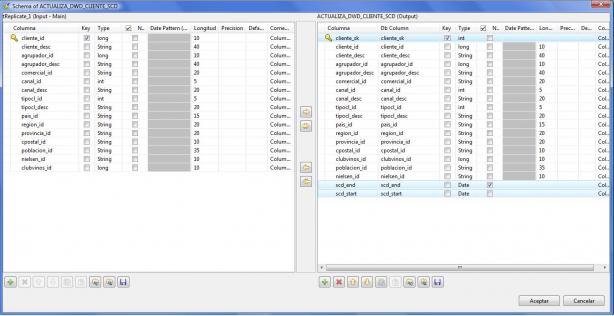
Esquema de traspaso de Datos en Dimensiones SCD
Para entender mejor el ejemplo, observar las entradas en MySql de la tabla DWD_CLIENTE_SCD. Observar como el cliente tuvo un cambio en su nombre y se generó un nuevo registro en la tabla con una nueva clave subrogada. Todo se ha realizado de una forma automatica por el componente de Talend, sin tener que gestionar nosotros nada.
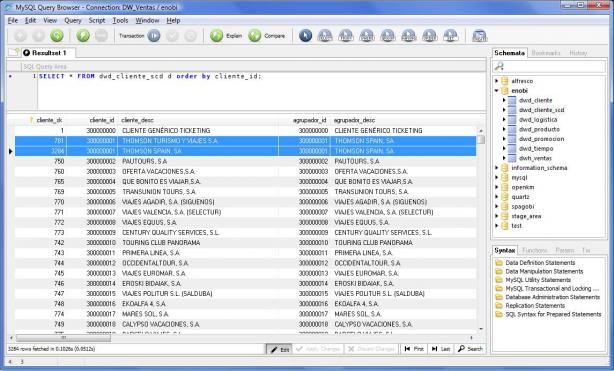
Registros para el mismo cliente en MySql con Subrogated key
Finalmente, observar que hemos utilizado un componente nuevo para duplicar un flujo de datos (el componente tReplicate). Este componente nos permite a partir de un unico flujo, generar tantos flujos como sea necesarios (todos serán iguales y procesarán los mismos registros).
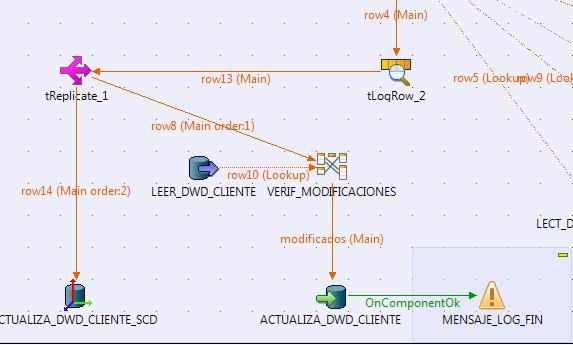
Duplicacion de flujos de datos con el componente tReplicate
Para ver en detalle como hemos definido cada componente del Job, podeís acceder a la documentación HTML completa generada por Talend. Podeis descargaros el fichero zip que contiene dicha documentación aquí.
Ejemplo Talend para conectarnos a Sap
Ejemplo Talend para conectarnos a Sap respinosamilla 25 February, 2010 - 09:50Antes de continuar con el proceso ETL para la carga de la tabla de Hechos de ventas, vamos a hacer una pausa para ver como utilizar Talend para conectarnos a Sap utilizando los componentes tSapConnection, tSapInput y tSapOutput. En nuestro proyecto, podriamos haber utilizado estos componentes para hacer la lectura de datos desde el ERP (pero hemos utilizado el componente tOracleInput para leer directamente de la base de datos).
Aunque el componente Sap de Talend es libre, para poder utilizarlo hace falta una librería Java proporcionada por Sap (sapjco.jar), que tendremos que tener instalada en nuestro sistema. Esta libreria solo se puede descargar de Sap si somos usuarios registrados (https://service.sap.com/connectors). La versión del sapjco que hemos instalado es la 2.1.8 (hay una posterior, la 3.0.4, pero con esa no funciona Talend).
La forma de instalar la libreria sapjco.jar es la siguiente:
- Una vez descargado el correspondiente fichero (según la versión de sistema operativo que estemos utilizando), lo descomprimimos en un directorio de nuestra elección. La prueba, en nuestro caso, la hemos realizado utilizando Windows Vista.
- Si tenemos una versión mas antigua de la dll librfc32.dll en el directorio de windows system32, la sustituimos con la que viene de Sap.
- Incluimos el directorio de instalación en la variable de entorno PATH (en nuestro caso c:\sapjco ).
- Finalmente, añadimos a la variable de entorno CLASSPATH el fichero sapjco.jar con su ruta completa (por ejemplo, CLASSPATH=c:\sapjco\sapjco.jar ).
A continuación, instalamos la libreria en el directorio de clases de Talend y comprobamos que este correctamente instalada. Para ello, dejamos caer el fichero sapjco.jar en el directorio <directorio_instalacion_talend>\lib\java. A continuación abrimos Talend, y en la pestaña Modules, comprobamos que aparezca el modulo sapjco.jar correctamente instalado (tal y como vemos en la imagen).
Finalmente, vamos a ver un ejemplos práctico de conexión a Sap para recuperar información, utilizando modulos de función (RFC) implementados en Sap y a las que podremos acceder desde Talend (esto es realmente lo que nos permite hacer el componente, acceder a Sap a traves de sus RFC´s y BAPIS).
Las RFC´s (Remote Function Call) son la base para la comunicación entre Sap y cualquier sistema externo. Son componentes de programación (un programa Abap, por ejemplo), encapsulado en una función, con su correspondiente interfaz de entrada y salida de datos, que ademas puede ser llamado desde dentro del propio Sap, o de forma remota si esta habilitada la opción “Modulo Acceso Remoto” (tal y como vemos en la imagen inferior). En este caso, es cuando podremos llamarlas, por ejemplo, desde Talend.
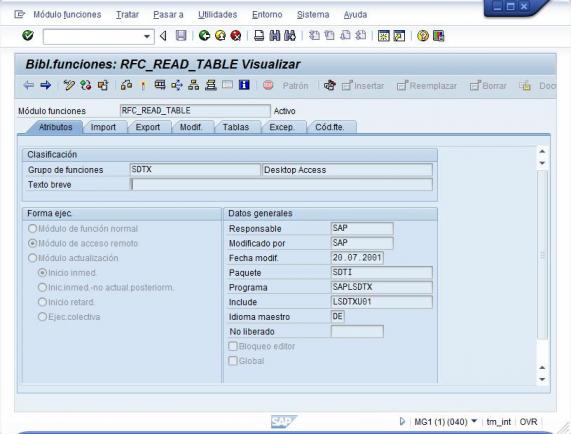
Definicion de la RFC "RFC_READ_TABLE" en Sap
Sap tiene programadas multitud de RFC´s de forma estandar, y ademas nosotros podremos construir las nuestras con codigo que realize las tareas que deseemos. Ademas, existe otro tipo de RFC´s dentro de sap, las llamadas BAPIS, que incluyen reglas adicionales integradas con el funcionamiento de la aplicación Sap (por ejemplo, la BAPI BAPI_SALESORDER_CREATEFROMDAT2 nos permite la creación de un pedido de ventas a partir de los datos que pasamos a la función en la interfaz).
Ejemplo: Lectura del contenido de una tabla utilizando la RFC “RFC_READ_TABLE”.
Vamos a realizar un Job en Talend para leer el contenido de una tabla de Sap, en concreto, vamos a recuperar todos los materiales que son de un determinado tipo. El Job completo tendrá la siguiente estructura:
En Talend utilizaremos el componente tSapInput para hacer la llamada a la RFC de Sap. Para poder hacer esto, tendremos que conocer cual es la interfaz que tiene definida esta en Sap para saber que parametros le podemos pasar y que resultados y en que tipos de estructuras de datos podemos recibir. En la transacción SE37 de Sap podemos ver como estan definidos los modulos de función, y ver como se va a realizar la comunicación con dicho componente.
Por ejemplo, en modulo de función RFC_READ_TABLE (como vemos en la imagen inferior), tiene 5 parametros de entrada, definidos en la pestaña IMPORT. Los que vamos a utilizar en nuestro ejemplo serán: QUERY_TABLE (la tabla de la que queremos obtener información), DELIMITER (delimitador para los datos obtenidos).
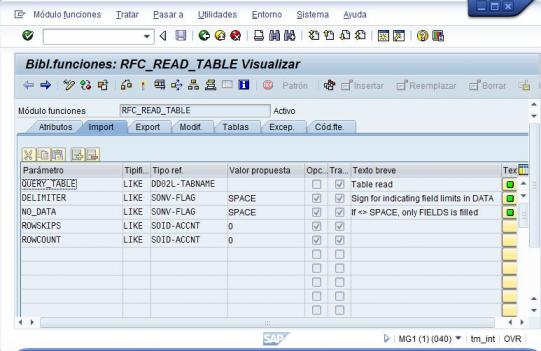
Definicion RFC en Sap - Import (parametros Entrada)
Existe tambien la pestaña EXPORT, en la que podriamos ver que parametros de salida tenemos (para el caso de variables o estructuras simples). En el caso de trabajar con tablas, estas aparecerán en la pestaña TABLAS. Las tablas son estructuras complejas de Sap (como una matriz de datos). Las tablas se pueden utilizar tanto para recibir datos de la RFC como para pasarselos. En nuestro ejemplo, utilizaremos la tabla DATA para recibir los registros recuperados de la base de datos.
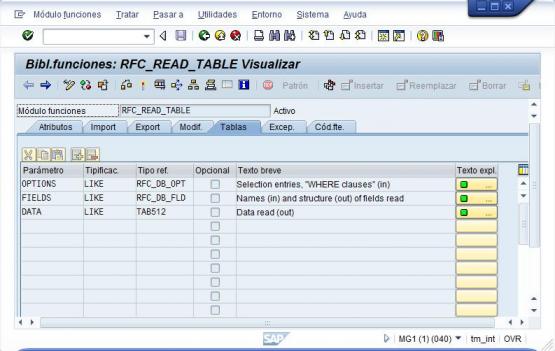
Definicion RFC en Sap - Tables (parametros Entrada/Salida)
A continuación, volveremos a Talend y completaremos los diferentes campos del componente:
- Cliente: mandante de Sap del cual recuperaremos los datos.
- Userid: usuario para la conexión. Habrá de tener permisos para ejecutar la RFC y para acceder a los datos deseados.
- Password: contraseña.
- Language: lenguaje de conexión.
- Host Name: Host donde esta ubicado el servidor Sap.
- System Number: numero de instancia Sap del servidor (normalmente la 00 donde solo hay un servidor).
- Function name: Nombre de la RFC a la cual vamos a invocar.
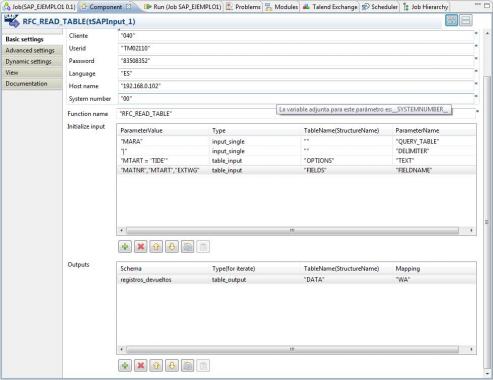
Ejemplo de Uso de componente tSapInput
- Initialize input: inicializacion de los parametros de entrada. Son los valores que vamos a pasar al módulo de función. En nuestro caso, observar que hemos pasado valores simples (variables) y también hemos pasado valores a algunas de las tablas.
- Input single: los parametros “QUERY_TABLE” y “DELIMITER” son del tipo input_single (entrada sencilla) y los inicializamos pasandoles un valor, en concreto el nombre de la tabla que queremos leer y el delimitador a utilizar.
- Table input: introducimos valores en dos tablas. En la tabla OPTIONS, en el campo TEXT, indicamos una condición para restringir la lectura de datos (como si fuera una condición del where). En la tabla FIELDS, en el campo FIELDNAME, le indicamos a Sap que campos de la tabla son los que queremos recuperar (en este caso el código del material, su tipo y su linea de producto). De esta forma, limitamos tanto el número de registros devueltos, como los campos obtenidos (no queremos ver todos los campos de cada registro de esta tabla). Observar como para indicar varios valores para el campo FIELDNAME de la tabla FIELDS, hemos puesto varias entradas separadas por coma.
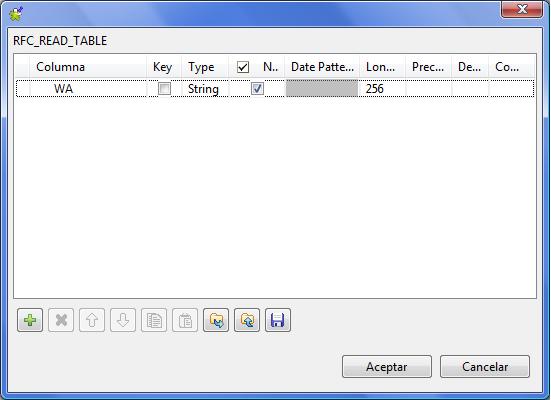
- Outputs: definición de las estructuras donde vamos a gestionar los datos devueltos por Sap. Aquí indicaremos el tipo de valor recuperado (table_output para cuando el resultado sea una tabla), el nombre de la tabla en Sap (en el campo TableName (Structure Name) y el nombre del Schema (será un nombre para el flujo de datos, podemos ponerle cualquiera). En nuestro ejemplo, estamos leyendo de la tabla de Sap DATA, que es una tabla de registros, y cada registro tiene un unico campo que se llama WA. Los pasos a seguir en esta sección para una correcta definición de intercambio de datos son los siguientes:
- Creamos en primer lugar el flujo de salida pulsado el boton del signo “+”. Pulsado en Schema le daremos un nombre a este flujo (registros_devueltos en nuestro ejemplo) e indicaremos los campos que componen la estructura de salida del componente tSapInput. En este caso, solo tendremos un campo, llamado WA (tal y como vemos en la imagen), que corresponde con el campo de la tabla DATA de Sap.
Definicion de la estructura de salida "registros_devueltos"
- A continuación, habrá que asociar esta columna a la componente de Sap donde se recuperan los datos. Para ello pulsaremos en el campo Mapping,y se nos abrira una nueva ventana. Aquí nos aparecera el flujo de datos definido en el paso anterior mas el campo Schema XPatchQuerys, que es el que nos permite Mapear el campo de Talend con el campo del diccionario de datos de Sap, y así poder recibir los datos de Sap correctamente (los valores introducidos en XPatchQuerys deberán ir entre comillas dobles, utilizando el simbolo “).
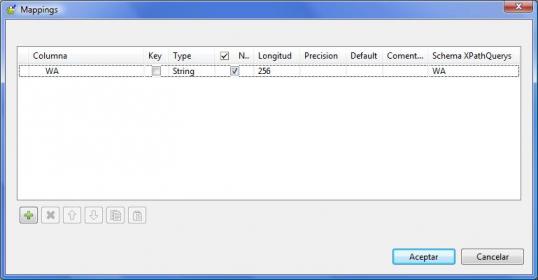
- Mapeo entre la estructura de salida en Talend y la de Sap
Con este ejemplo, hemos podido de una forma relativamente sencilla recuperar datos de Sap en un único control. Conociendo los diferentes RFC´s existentes en Sap y las Bapis, seguramente podremos realizar tareas mucho mas complejas y aprovechar funcionalidades que ya estan definidas en Sap. Incluso puede ser una forma de realizar interfases con Sap utilizando estos componentes ya definidos y paquetizados.
Tabla Hechos Venta. Particionado en MySql.
Tabla Hechos Venta. Particionado en MySql. respinosamilla 25 February, 2010 - 09:50Antes de comenzar la implementación del proceso ETL para la carga de la tabla de Hechos de Ventas, vamos a realizar alguna consideración sobre el particionado de tablas.
Cuando estamos costruyendo un sistema de business intelligence con su correspondiente datawarehouse, uno de los objetivos (aparte de todas las ventajas de sistemas de este tipo: información homogenea, elaborada pensando en el analisis, dimensional, centralizada, estatica, historica, etc., etc.) es la velocidad a la hora de obtener información. Es decir, que las consultas se realicen con la suficiente rapidez y no tengamos los mismos problemas de rendimiento que suelen producirse en los sistemas operacionales (los informes incluso pueden tardar horas en elaborarse).
Para evitar este problema, hay diferentes técnicas que podemos aplicar a la hora de realizar el diseño fisico del DW. Una de las técnicas es el particionado.Pensar que estamos en un dw con millones de registros en una unica tabla y el gestor de la base de datos ha de mover toda la tabla. Ademas, seguramente habrá datos antiguos a los que ya no accederemos casi nunca (datos de varios años atras). Si somos capaces de tener la tabla “troceada” en segmentos mas pequeños seguramente aumentaremos el rendimiento y la velocidad del sistema.
El particionado nos permite distribuir porciones de una tabla individual en diferentes segmentos conforme a unas reglas establecidas por el usuario. Según quien realize la gestión del particionado, podemos distinguir dos tipos de particionado:
Manual: El particionado lo podriamos realizar nosotros en nuestra lógica de procesos de carga ETL (creando tablas para separar los datos, por ejemplo, tabla de ventas por año o por mes/año). Luego nuestro sistema de Business Intelligence tendrá que ser capaz de gestionar este particionado para saber de que tabla tiene que leer según los datos que le estemos pidiendo (tendra que tener un motor de generación de querys que sea capaz de construir las sentencias para leer de las diferentes tablas que incluyen los datos). Puede resultar complejo gestionar esto.
Automatico: Las diferentes porciones de la tabla podrán ser almacenadas en diferentes ubicaciones del sistema de forma automatica según nos permita el SGBDR que estemos utilizando.La gestión del particionado es automática y totalmente transparente para el usuario, que solo ve una tabla entera (la tabla “lógica” que estaria realmente partida en varias tablas “fisicas”). La gestión la realiza de forma automática el motor de base de datos tanto a la hora de insertar registros como a la hora de leerlos.
La partición de tablas se hace normalmente por razones de mantenimiento, rendimiento o gestión.
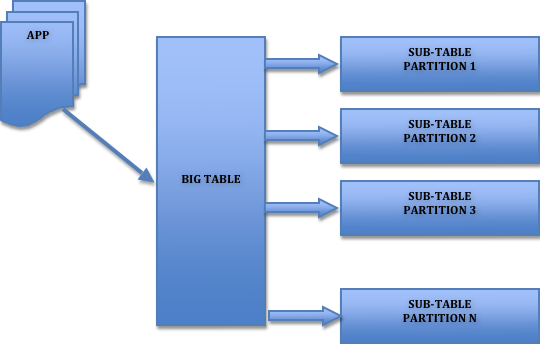
Lógica Particionado de tablas
Según la forma de realizar el particionado, podriamos distinguir:
Partición horizontal (por fila): consiste en repartir las filas de una tabla en diferentes particiones. Por ejemplo, los clientes de un pais estan incluidos en una determinada partición y el resto de clientes en otra. En cada partición se incluyen los registros completos de cada cliente.
Partición vertical( por columna): consiste en repartir determinadas columnas de un registro en una partición y otras columnas en otra (partimos la tabla verticalmente,). Por ejemplo, en una partición tenemos las columnas de datos de direcciones de los clientes, y en otra partición las columnas de datos bancarios.
Cada motor de base de datos implementa el particionado de forma diferente. Nosotros nos vamos a centrar en la forma de implementarlo utilizando Mysql, que es la base de datos que estamos utilizando para nuestro proyecto.
Particionado de tablas en MySql
MySql implementa el particionado horizontal. Basicamente, se pueden realizar cuatro tipos de particionado, que son:
- RANGE: la asignación de los registros de la tabla a las diferentes particiones se realiza según un rango de valores definido sobre una determinada columna de la tabla o expresión. Es decir, nosotros indicaremos el numero de particiones a crear, y para cada partición, el rango de valores que seran la condicion para insertar en ella, de forma que cuando un registro que se va a introducir en la base de datos tenga un valor del rango en la columna/expresion indicada, el registro se insertara en dicha partición.
- LIST: la asignación de los registros de la tabla a las diferentes particiones se realiza según una lista de valores definida sobre una determinada columna de la tabla o expresión. Es decir, nosotros indicaremos el numero de particiones a crear, y para cada partición, la lista de valores que seran la condicion para insertar en ella, de forma que cuando un registro que se va a introducir en la base de datos tenga un valor incluido en la lista de valores, el registro se insertara en dicha partición.
- HASH: este tipo de partición esta pensado para repartir de forma equitativa los registros de la tabla entre las diferentes particiones. Mientras en los dos particionados anteriores eramos nosotros los que teniamos que decidir, según los valores indicados, a que partición llevamos los registros, en la partición HASH es MySql quien hace ese trabajo. Para definir este tipo de particionado, deberemos de indicarle una columna del tipo integer o una función de usuario que devuelva un integer. En este caso, aplicamos una función sobre un determinado campo que devolvera un valor entero. Según el valor, MySql insertará el registro en una partición distinta.
- KEY: similar al HASH, pero la función para el particionado la proporciona MySql automáticamente (con la función MD5). Se pueden indicar los campos para el particionado, pero siempre han de ser de la clave primaria de la tabla o de un indice único.
- SUBPARTITIONS: Mysql permite ademas realizar subparticionado. Permite la división de cada partición en multiples subparticiones.
Ademas, hemos de tener en cuenta que la definición de particiones no es estática. Es decir, MySql tiene herramientas para poder cambiar la configuración del particionado a posteriori, para añadir o suprimir particiones existentes, fusionar particiones en otras, dividir una particion en varias, etc. (ver aquí ).
El particionado tiene sus limitaciones y sus restricciones, pues no se puede realizar sobre cualquier tipo de columna o expresión (ver restricciones al particionado aquí), tenemos un limite de particiones a definir y habrá que tener en cuenta algunas cosas para mejorar el rendimiento de las consultas y evitar que estas se recorran todas las particiones de una tabla ( el artículo MySql Partitions in Practice, se nos explica con un ejemplo trabajando sobre una base de datos muy grande, como realizar particionado y que cosas tener en cuenta para optimizar los accesos a las consultas). Para entender como funciona el particionado, hemos replicado los ejemplos definidos en este articulo con una tabla de pruebas de 1 millón de registros (llenada, por cierto,con datos de prueba generados con Talend y el componente tRowGenerator).
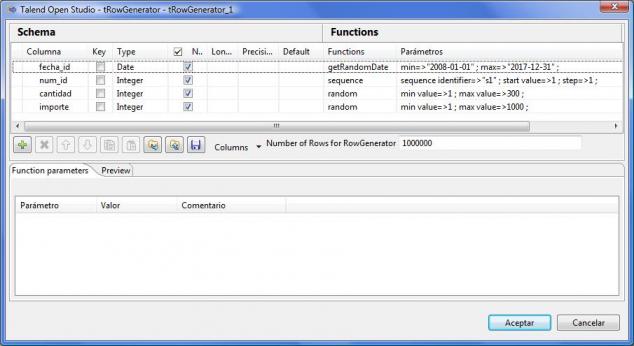
Ejemplo componente tRowGenerator para producir datos de test
En concreto, hemos creado dos tablas iguales (con la misma estructura). Una con particionado por año en un campo de la clave del tipo fecha, y la segunda con la misma estructura sin particionado. En ambas tablas tenemos un millon de registros repartidos entre los años 2008 y 2017. Una vez creadas las tablas, utilizamos la sentencia de MySql explain y explain partitions para analizar como se ejecutaran las sentencias sql (analisis de indices). Ademas, comprobamos tiempos de ejecución con diferentes tipos de sentencia SQL. Los resultados son mas que obvios:

Analisis tiempos ejecucion
En las mayoria de los casos se obtiene un mejor tiempo de respuesta de la tabla particionada, y en los casos en los que no, el tiempo de ejecución es practicamente igual al de la tabla no particionada (diferencias de milesimas de segundo). Observar cuando indicamos condiciones fuera del indice (ultima sentencia SQL), como los tiempos de respuesta son aun mas relevantes. Y siempre conforme vamos leyendo de mas particiones (por incluir mas años en la condición), el tiempo de respuesta de la consulta entre una y otra tabla se va acercando.
Particionado de la tabla de hechos de Ventas en nuestro DW
Para nuestro DW, hemos decidir implementar un particionado del tipo LIST. Como os habreis podido dar cuenta, seguramente los particionados por RANGE o por LIST son los mas adecuados para un sistema de Business Intelligence pues nos van a permitir de una forma facil reducir el tamaño de las casi siempre monstruosas tablas de hechos, de una forma fácil y automática.
Vamos a crear 10 particiones y repartiremos los diferentes años en cada una de las particiones, empezando por 2005 –> Particion 1, 2006 –> Particion 2, 2007 –> Particion 3, …, 2013 –> Particion 9, 2014 –> Partición 10. A partir de 2015, volvemos a asignar cada año a las particiones y así hasta el año 2024 (tiempo de sobra para lo que seguramente será la vida de nuestro DW).
Como el campo año no lo tenemos en el diseño físico de la tabla de hechos, aplicaremos sobre la columna fecha la funcion YEAR para realizar el particionado. La sentencia para la creación de la tabla de hechos quedaría algo parecido a esto:
CREATE TABLE IF NOT EXISTS `enobi`.`dwh_ventas` ( `fecha_id` DATE NOT NULL , `material_id` INT(11) NOT NULL , `cliente_id` INT(11) NOT NULL , `centro_id` INT(11) NOT NULL , `promocion_id` INT(11) NOT NULL , `pedido_id` INT(11) NOT NULL , `unidades` FLOAT NULL DEFAULT NULL COMMENT 'Unidades Vendidas' , `litros` FLOAT NULL DEFAULT NULL COMMENT 'Equivalencia en litros de las unidades vendidas' , `precio` FLOAT NULL DEFAULT NULL COMMENT 'Precio Unitario' , `coste_unit` FLOAT NULL DEFAULT NULL COMMENT 'Coste Unitario del Producto')
PARTITION BY LIST(YEAR(fecha_id)) (
PARTITION p1 VALUES IN (2005,2015),
PARTITION p2 VALUES IN (2006,2016),
..................................
PARTITION p9 VALUES IN (2013,2023),
PARTITION p10 VALUES IN (2014,2024)
);Con este forma de definir el particionado estamos sacando ademas partido de la optimización de lo que en MySql llaman “Partitioning Pruning”. El concepto es relativamente simple y puede describirse como “No recorras las particiones donde no puede haber valores que coincidan con lo que estamos buscando”. De esta forma, los procesos de lectura serán mucho mas rápidos.
A continuación, veremos en la siguiente entrada del Blog los ajustes de diseño de nuestro modelo físico en la tabla de hechos (teniendo en cuenta todo lo visto referente al particionado) y los procesos utilizando la ETL Talend para su llenado.
Tabla Hechos Venta. Ajuste diseño fisico y procesos carga ETL. Contextos en Talend.
Tabla Hechos Venta. Ajuste diseño fisico y procesos carga ETL. Contextos en Talend. respinosamilla 25 February, 2010 - 09:50Vamos a desarrollar los procesos de carga de la tabla de hechos de ventas de nuestro proyecto utilizando Talend. Antes de esto, vamos a hacer algunas consideraciones sobre la frecuencia de los procesos de carga que nos van a permitir introducir el uso de un nuevo elemento de Talend, los contextos.
En principio, vamos a tener varios tipos de carga de datos:
- Carga inicial: será la primera que se realice para la puesta en marcha del proyecto, e incluira el volcado de los datos de venta desde una fecha inicial (a seleccionar en el proceso) hasta una fecha final.
- Cargas semanales: es el tipo de carga mas inmediato. Se realiza para cada semana pasada (por ejemplo, el martes de cada semana se realiza la carga de la semana anterior), para tener un primer avance de información de la semana anterior (que posteriormente se refrescara para consolidar los datos finales de ese periodo). La carga de una semana en concreto también se podrá realizar a petición (fuera de los procesos batch automáticos).
- Recargas mensuales: una vez se cierra un periodo mensual (lo que implica que ya no puede haber modificaciones sobre ese periodo), se refresca por completo el mes en el DW para consolidar la información y darle el status de definitiva para ese periodo. La ejecución es a petición y se indicara el periodo de tiempo que se quiere procesar.
Teniendo en cuenta esto, definiremos un unico proceso de traspaso al cual se pasaran los parametros que indicaran el tipo de carga a realizar. Para ello utilizaremos los contextos de Talend. Cada tipo de carga tendra un contexto personalizado que definira como se va a comportar el proceso.
Contextos en Talend
Los contextos de Talend son grupos de variables contextuales que luego podemos reutilizar en los diferentes jobs de nuestras transformaciones. Nos pueden ser utiles para muchas cosas, como para tener definidas variables con los valores de paths de ficheros, valores para conexión a bases de datos (servidor, usuario, contraseña, puerto, base de datos por defecto, etc), valores a pasar a los procesos (constantes o definidos por el usuario en tiempo de ejecución). Los valores de los contextos se inicializan con un valor que puede ser cambiado por el usuario mediante un prompt (petición de valor). Un mismo contexto puede tener diferentes “grupos de valores”. Es decir, en el contexto “conexion a base de datos”, podemos tener un grupo de valores llamado “test”, que incluira los valores para conectarnos al sistema de pruebas y un grupo llamado “productivo”, que incluira los valores para la conexión a la base de datos real (tal y como vemos en el ejemplo).
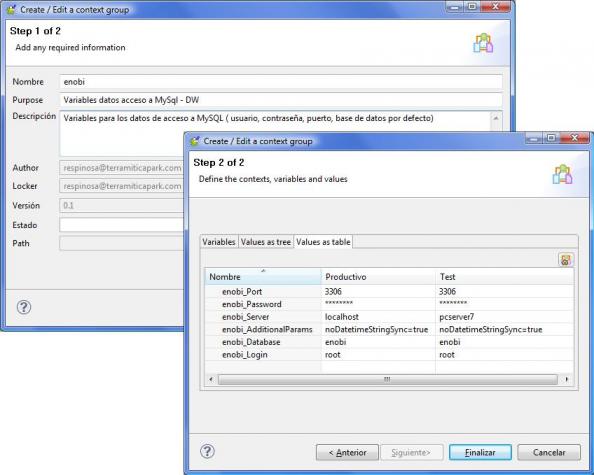
Definición de Contextos en Talend
Dentro del contexto, definiremos que grupo de valores es el que se utilizara por defecto. Esto nos va a permitir trabajar con los jobs y sus componentes olvidandonos de contra que sistema estamos trabajando. Tendremos, por ejemplo, el contexto de test activo, y es el que utilizaremos para las pruebas. Y podremos cambiar en cualquier momento, al ejecutar un job, para decirle que utilice el contexto “productivo”. Igualmente, podremos preparar un fichero o una tabla de base de datos con los valores de las variables de contexto, que serán pasadas al job para su utilización en la ejecución de un proceso (utilizando el componente tContextLoad).
Definición del proceso de carga
El diseño físico definitivo de la tabla de hechos será el siguiente:
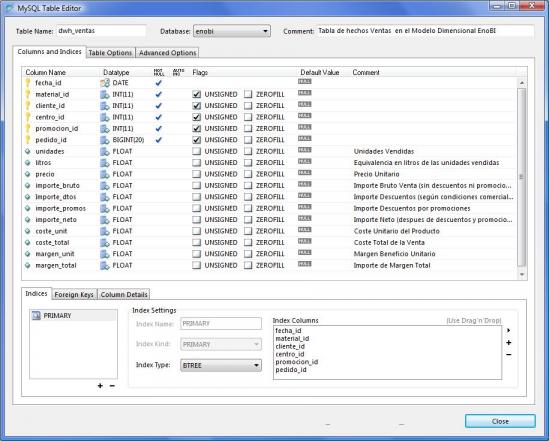
Una vez hechas todas las consideraciones, veamos el esquema de como quedaria nuestro proceso de transformación.
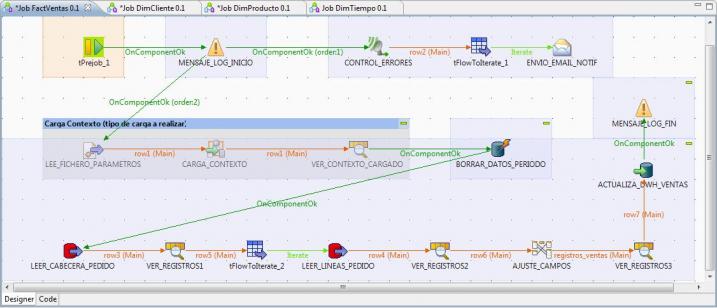
Job completo en Talend para la carga de la tabla de Hechos
Vamos a ver en detalle cada uno de los pasos que hemos definido para realizar la lectura de datos del sistema origen y su transformación y traspaso al sistema destino (y teniendo en cuenta varios procesos auxiliares y la carga del contexto de ejecución).
1) Ejecución de un prejob que lanzará un generara en el log un mensaje de inicio del proceso y un logCatcher (para recoger las excepciones Java o errores en el proceso). Este generará el envio de un email de aviso en el caso de que se produzca algún problema en cualquier paso del job (al igual que hemos incluido en todos los jobs de carga del DW vistos hasta ahora).
- Lanzador Prejob (componente tPrejob): sirve para realizar el lanzamiento de un pretrabajo, anterior al proceso principal.
- Mensaje Log Inicio (componente tWarn): genera un mensaje de log indicando que se comienza la ejecución del job.
- Control Errores (componente tLogCatcher): activamos el componente que “escuchara” durante toda la ejecución del job, esperando que se produzca algún tipo de error. En ese momento se activara para recuperar el error y pasarlo al componente siguiente para el envio de un email de notificación.
- tFlowtoIterate: convertimos el flujo de registros de log a una iteración para poder realizar el envio del correo electrónico.
- Envio Email Notif (componente tSendMail): generamos el envio de un email de notificación de errores, incluyendo el paso donde se paro el proceso, y el mesaje de error generado. Es una forma de avisar que ha fallado algo en el proceso.
2) Carga del contexto de ejecución: para que el proceso sepa que tipo de carga ha de realizar y para que periodo de fechas, es necesario proporcionarle la información. Esto lo haremos utilizando los contextos. En este caso, tal y como vemos en la imagen, el contexto tendrá 3 variables, donde indicaremos el tipo de carga y la fecha inicio y fin del periodo a procesar.
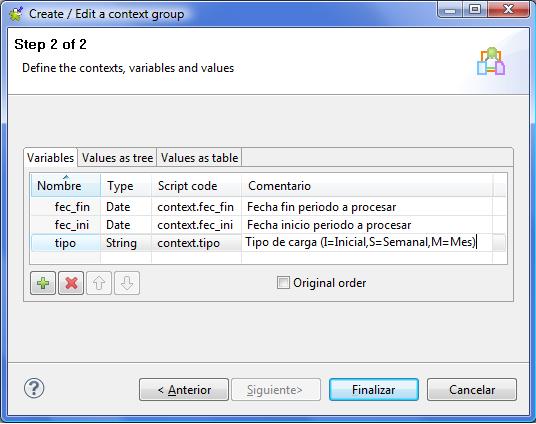
Contexto para la ejecución del Job
Los valores para llenar el contexto los recuperaremos de un fichero de texto (también lo podiamos haber recuperado de los valores existentes en una tabla de la base de datos). El fichero contendrá lineas con la estructura “clave=valor”, donde clave sera el nombre de la variable y valor su contenido.
Para abrir el fichero, utilizaremos el paso LEE_FICHERO_PARAMETROS (componente tFileInputProperties), que nos permite leer ficheros de parametros. A continuación cargaremos los valores recuperados en el contexto utilizando el paso CARGA_CONTEXTO, del tipo tContextLoad. A partir de este momento ya tenemos cargado en memoria el contexto con los valores que nos interesan y podemos continuar con el resto de pasos.
Podriamos haber dejado preparados los valores de contexto en una tabla de base de datos y utilizar un procedimiento parecido para recuperarlos y con el componente tContextLoad cargarlos en el job. Tened en cuenta que los ficheros que va a leer el job habrán sido previamente preparados utilizando alguna herramienta, donde se definira el tipo de carga a realizar y el periodo (y dichos valores se registraran en el fichero para su procesamiento).
3) Borrado previo a la recarga de los datos del periodo en la tabla de hechos (para hacer un traspaso desde cero): antes de cargar, vamos a hacer una limpieza en la tabla DWH_VENTAS para el periodo a tratar. De estar forma, evitamos inconsistencia en los datos, que podrían haber sido cargados con anterioridad y puede haber cambios para ellos. Con el borrado, nos aseguramos que se va a quedar la última foto completa de los datos. Para hacer esto, utilizamos el paso BORRAR_DATOS_PERIODO (del tipo tMySqlRow).
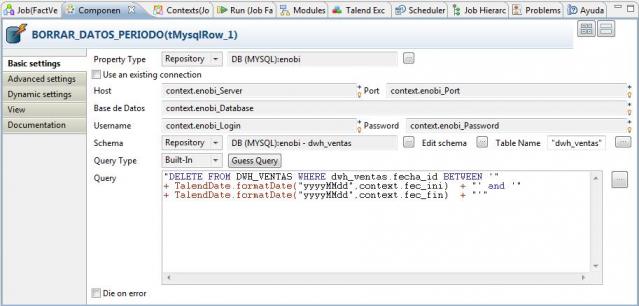
Observad como en el paso hemos incluido la ejecución de una sentencia sql de borrado (DELETE), y le hemos pasado como valores en las condiciones del where las fechas del periodo, utilizando las variables de contexto.
4) Lectura de datos desde los pedidos de venta (cabecera) y a partir de cada pedido, de las lineas (desde el ERP).
A continuación, procederemos a recuperar todos los pedidos de venta del periodo para obtener los datos con los que llenar la tabla de Hechos. Para ello, utilizamos el paso LEER_CABECERA_PEDIDO (del tipo tOracleInput), con el que accedemos a oracle y obtenemos la lista de pedidos que cumplen las condiciones (observar como también en la sentencia SQL ejecutada por este componente hemos utilizado las variables de contexto).
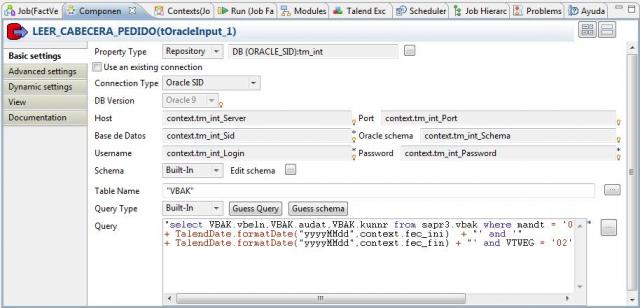
A continuación, para cada pedido, recuperamos todas las lineas que lo componen con el paso LEER_LINEAS_PEDIDO (también del tipo tOracleInput) y pasamos todos los datos al componente tMap para realizar las transformaciones, normalización y operaciones, antes de cargar en la base de datos.
5) Transformación de los campos, normalización, operaciones.
Los valores de los datos de cabeceras y lineas de pedido recuperados desde Sap los transformamos a continuación conforme a la especificaciones que hicimos en el correspondiente análisis (ver entrada blog). En este proceso realizamos conversión de tipos, llenado de campos vacios, cálculos, operaciones. Todo con el objetivo de dejar los datos preparados para la carga en la tabla de Hechos de la base de datos.
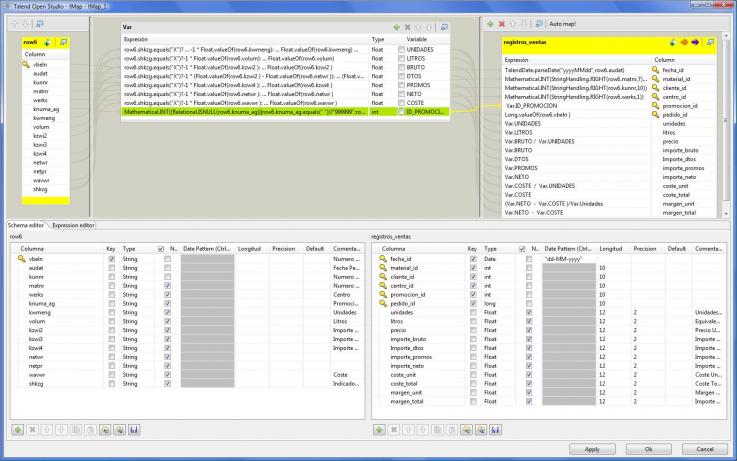
Transformaciones de los datos de pedidos antes de grabar en tabla Hechos
En este ejemplo, hemos utilizado un elemento nuevo del control tMap, que son las variables (ver la parte central superior). Las variables nos permiten trabajar de forma mas agil con los procesos de transformación, filtrado, conversión y luego se pueden utilizar para asignar a los valores de salida (o ser utilizadas en expresiones que las contengan).
Por ejemplo, observar que hemos creado la variable UNIDADES, y en ella hemos hecho un calculo utilizando elementos del lenguaje Java:
row6.shkzg.equals("X")?-1 * Float.valueOf(row6.kwmeng):Float.valueOf(row6.kwmeng)El campo SHKZG de los pedidos nos indica si un pedido es venta o abono. Por eso, si dicho campo tiene el valor X, hemos de convertir los importe a negativo. Observad también como luego utilizamos las variables definidas en la sección VAR en el mapeo de campos de salida.
Para los campos que son clave foranea de las correspondientes tablas de dimensiones (código de cliente, material, etc), hemos realizado las mismas transformaciones que realizamos cuando cargamos dichas tablas, para que todo quede de forma coherente y normalizada.
6) Inserción en la tabla de hechos y conclusión del proceso.
Como paso final, vamos realizando el insertado de los registros en la tabla DWH_VENTAS utilizando el componente tMysqlOutput (tal y como vemos en la imagen).
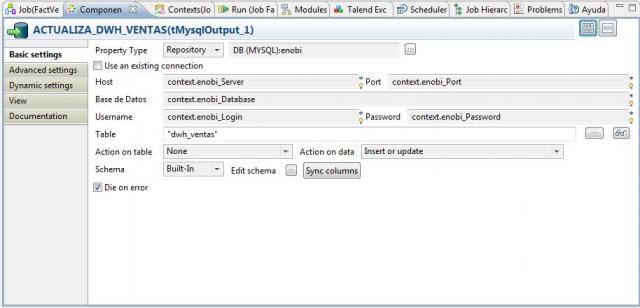
Una vez realizada toda la lectura de datos e inserción, concluiremos el proceso generando un mensaje de conclusión correcta del Job en la tabla de Logs con el paso MENSAJE_LOG_FIN (componente tipo tWarn).
Observad como hemos incluido, intercalados en los diferentes pasos del job, unos llamados VER_REGISTROS (del tipo tLogRow). Es un paso añadido para depuración y comprobación de los procesos (aparece en consola los valores de los registros que se van procesando). En el diseño definitivo del job estos pasos se podrían eliminar.
Para ver en detalle como hemos definido cada componente, podeís acceder a la documentación HTML completa generada por Talend aquí. Podeis descargaros el fichero zip que contiene dicha documentación aquí.
Conclusiones
Hemos terminado el desarrollo de todos los procesos de carga para llenar nuestro DW. Para cada una de las dimensiones y para la tabla de hechos, hemos construido un proceso con Talend para llenarlos. Como ultima actividad, nos quedaría combinar todos esos procesos para su ejecución conjunta y planificarlos para que la actualización del DW se produzca de forma regular y automatica.
Igualmente, veremos la forma de exportar los procesos en Talend para poder ejecutarlos independientemente de la herramienta gráfica (nos permitira llevar a cualquier sitio los procesos y ejecutarlos, pues al fin y al cabo es código java).
Todo esto lo veremos en la siguiente entrada del blog.
cuando los procesos utilizan
cuando los procesos utilizan cursores que elemento se deberia usar? estoy tratando de hacer un cursor que va generando variables que al final hacen un merge a la base. pero no he encontrado la manera de hacerlo desde el talend.
- Log in to post comments
Exportación jobs en Talend.Planificacion procesos ETL.
Exportación jobs en Talend.Planificacion procesos ETL. respinosamilla 25 February, 2010 - 09:50Una vez concluido el desarrollo de los procesos para la carga del DW, la siguiente tarea sera la planificación de estos para su ejecución regular, de forma que vayan reflejando en el DW todos los cambios que se vayan produciendo en el sistema operacional ( modificaciones en los datos maestros y nuevos hechos relacionados con los procesos de negocio de ventas).
Los jobs que hemos definido usando Talend se podrían ejecutar a petición desde la herramienta, o bien a nivel de sistema operativo, utilizando la correspondiente herramienta (CRON en Unix/Linux, AT en Windows). Para ello es necesario generar los ficheros de scripts a nivel de sistema operativo.
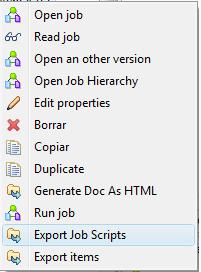 Para hacer esto, hemos de exportar el Job, pulsando con el botón derecho sobre el. Nos aparecera el correspondiente menú contextual, donde podremos seleccionar la opción “Export Job Scripts“. Como ya comentamos, Talend puede trabajar a nivel de generación de código con los lenguajes Java y Perl. Cuando creamos un proyecto, seleccionamos con que lenguaje vamos a trabajar(en nuestro caso hemos seleccionado Java), lo que determina que internamente se trabaje a todos los niveles con Java, al igual que a la hora de definir expresiones en los diferentes procesos y transformacion. De la misma manera, cuando exportemos los correspondientes scripts de un Job, estos se generarán utilizando dicho lenguaje.
Para hacer esto, hemos de exportar el Job, pulsando con el botón derecho sobre el. Nos aparecera el correspondiente menú contextual, donde podremos seleccionar la opción “Export Job Scripts“. Como ya comentamos, Talend puede trabajar a nivel de generación de código con los lenguajes Java y Perl. Cuando creamos un proyecto, seleccionamos con que lenguaje vamos a trabajar(en nuestro caso hemos seleccionado Java), lo que determina que internamente se trabaje a todos los niveles con Java, al igual que a la hora de definir expresiones en los diferentes procesos y transformacion. De la misma manera, cuando exportemos los correspondientes scripts de un Job, estos se generarán utilizando dicho lenguaje.
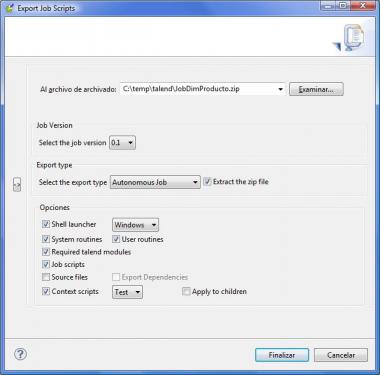 Al exportar el Job, nos aparece un cuadro de diálogo, como el que veis a la derecha, donde se nos pide un directorio para realizar la generación de todos los elementos necesarios, ademas de indicar una serie de opciones:
Al exportar el Job, nos aparece un cuadro de diálogo, como el que veis a la derecha, donde se nos pide un directorio para realizar la generación de todos los elementos necesarios, ademas de indicar una serie de opciones:
- Tipo de exportación: trabajo autonomo, Axis web service, JBoss ESB.
- Versión del job: podemos realizar una gestión de versiones de las modificaciones que vamos realizando sobre este y luego descargar una versión en concreto.
- Sistema operativo para generar el shell: indicamos para que tipo de sistema va a preparar los scripts para la posterior ejecución de los procesos.
- Incluir objetos dependientes: podemos hacer que en el directorio de exportación se incluyan todos los elementos necesarios para la ejecución independiente del trabajo (módulos talend, librerias java, rutinas del sistema). Esto nos permitirá llevarnos el job y ejecutarlo en cualquier sitio sin necesitar nada mas (solo la correspondiente maquina virtual java).
- Source files: podemos generar también el código fuente de nuestros jobs (para analizarlo o modificarlo directamente). Recordemos que Talend realmente es un generador de código, que utiliza la plataforma Eclipse.
- Contexto a utilizar: de todos los contextos que tenga definido el job, podemos indicar con cual se van a generar los scripts de ejecución (aunque luego podremos modificar el script para ejecutar con otro contexto, no es mas que un parametro de ejecución).
Una vez exportados los jobs, vemos que en la carpeta donde se ha exportado, aparecen los siguientes elementos:
- Directorio “NombreJob”: aparecen los scripts para ejecutar el job ( NombreJob_run.bat y NombreJob_run.sh), y la libreria NombreJob_version.jar, que es la que se llama desde el script para arrancar la ejecución del proceso. Es la libreria Java que se ha construido con todos los elementos y componentes que hemos utilizado para la definición de nuestro Job. Dento de estar carpeta cuelga otra donde se guardan los ficheros con los valores de las variables de contexto (en ficheros del tipo properties).
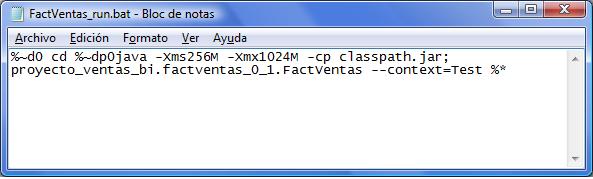
Script de ejecución de un job para Windows
En el script, observamos como se le pasa como parametro el contexto con el que queremos que se ejecute el Script. Es sencillo cambiarlo y teniendo preparados los juegos de variables correspondientes en diferentes ficheros de contexto, podremos trabajar con los mismos jobs trabajando sobre diferentes entornos o ejecutar los jobs con valores personalizados.
- Directorio “Lib”: aparecen todas las librerias java necesarias para la ejecución independiente del job. En nuestro caso, por ejemplo, que hemos utilizado controles para envio de mail (aparece la libreria mail.jar), conexión a mysql (aparece la libreria mysql-connector-java*.jar), conexión a oracle (libreria ojdbc14-9i.jar), rutinas de usuario (userRoutines.jar), etc.
Para realizar la planificación de los jobs, podriamos utilizar el CRON del sistema operativo Unix/Linux (preparando su correspondiente fichero crontab ), o bien a nivel de Windows utilizando AT o alguna herramienta similar como WinAT. Talend proporciona una herramienta para preparar los ficheros crontab. La herramienta es el OpenScheduler (tal y como vemos en la imagen).
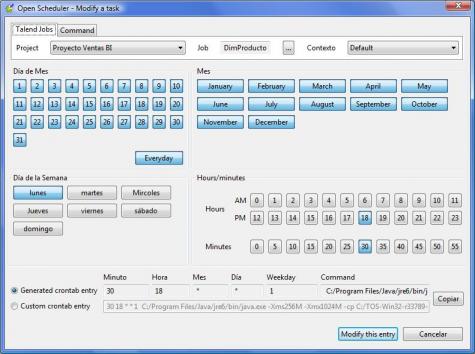
Talend Open Scheduler
De una forma visual, podemos elegir los diferentes parametros de ejecución del job (dia del mes, dia de la semana, mes, hora, minutos). A partir de las entradas grabadas en el OpenScheduler, podemos generar un fichero con los parametros necesarios para incorporar la programación de los jobs a las tablas crontab de nuestro sistema y asi planificar la ejecución de los procesos en los momento indicados.
Planificación de Jobs para el proyecto Enobi
Utilizando los scripts generados, planificaremos en nuestro sistema un lote de trabajos que ejecutará, en primer lugar, la carga de las dimensiones. Una vez concluida esta, se lanzara la carga de la tabla de hechos de venta (pues llevan incluidos datos que dependen de los existentes en las dimensiones).
La siguiente fase de nuestro proyecto será la explotación del DW utilizando la herramienta de Microstrategy 9. En primer lugar, teniendo en cuenta el diseño definitivo, configuraremos el modelo de datos dentro de el, para posteriormente abordar la explotación del sistema. Esta incluirá todos los ambitos del Business Intelligence. Veremos ejemplos de informes, cubos olap y navegación dimensional, cuadros de mando e indicadores kpi´s y también funciones de Data Mining.