6. Consideraciones de Diseño
6. Consideraciones de Diseño bernabeu_dario Tue, 08/05/2008 - 14:366.1 Tamaño del DW
6.1 Tamaño del DW bernabeu_dario Thu, 05/14/2009 - 00:21De acuerdo al tamaño del depósito de datos, se lo puede clasificar como:
- Personal: si su tamaño es menor a 1 Gigabyte.

- Pequeño: si su tamaño es mayor a 1 Gigabyte y menor a 50 Gigabyte.

- Mediano: si su tamaño es mayor a 50 Gigabyte y menor a 100 Gigabyte.

- Grande: si su tamaño es mayor a 100 Gigabyte y menor a 1 Terabyte.
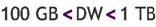
- Muy grande: si su tamaño es mayor a 1 Terabyte.
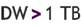
6.2 Tiempo de construcción
6.2 Tiempo de construcción bernabeu_dario Thu, 05/14/2009 - 00:23-
“El 70 % del tiempo total dedicado al proyecto se insume en definir el problema y en preparar la tabla de datos”.
-
“Estime el tiempo necesario, multiplíquelo por dos y agregue una semana de resguardo”.
-
”Regla 90 — 90”: el primer 90 % de la construcción de un sistema absorbe el 90 % del tiempo y esfuerzo asignados; el último 10 % se lleva el otro 90 % del tiempo y esfuerzo asignado.
6.3 Implementación
6.3 Implementación bernabeu_dario Thu, 05/14/2009 - 00:24Las implementaciones de los depósitos de datos varían entre sí de forma considerable, teniendo en cuenta las herramientas de software que se empleen, los modelos que se utilicen, recursos disponibles, SGBD que lo soporten, herramientas de análisis y consulta, entre otros.
6.4 Performance
6.4 Performance bernabeu_dario Thu, 05/14/2009 - 00:25Cuando se diseñan los ETLs, es muy importante que los mismos sean lo más eficientes posible, ya que una vez que se tenga un gran volumen de datos, el espacio en disco se volverá fundamental y los tiempos incurridos en el procesamiento y acceso a la información serán esenciales, y más aún si el DWH es considerado o tomado como un sistema de misión crítica.
También es muy importante configurar correctamente el SGBD en el que se almacene y mantenga el DW, así como lo es elegir las mejores estrategias para modelar las diferentes estructuras de datos que se utilizarán.
Para mejorar la performance del DWH, se pueden llevar a cabo las siguientes acciones sobre el DW y las estructuras de datos (cubos multidimensionales, Business Models, etc):
- Prestar especial atención a los tipos de datos utilizados, por ejemplo, para valores enteros pequeños conviene utilizar tinyint o smallint en lugar de int, con el fin de no asignar tamaños de datos mayores a los necesarios. Esto toma vital importancia cuando se aplica en las claves primarias, debido a que formarán parte de la tabla de hechos que es la que contiene el volumen del almacén de datos.
- Utilizar Claves Subrogadas.
- Utilizar técnicas de indexación.
- Utilizar técnicas de particionamiento.
- Crear diferentes niveles de sumarización.
- Crear vistas materializadas.
- Utilizar técnicas de administración de datos en memoria caché.
- Utilizar técnicas de multiprocesamiento, con el objetivo de agilizar la obtención de resultados, a través de la realización de procesos en forma concurrente.
6.5 Mantenimiento
6.5 Mantenimiento bernabeu_dario Thu, 05/14/2009 - 00:26Un punto muy importante es mantener en correcto funcionamiento al DW, ya que a medida que pase el tiempo, este tenderá a crecer significativamente, y surgirán cambios, tanto en los requerimientos como en las fuentes de datos.
6.6 Impactos
6.6 Impactos bernabeu_dario Thu, 05/14/2009 - 00:27Al implementar un DWH, es fundamental que l@s usuari@s del mismo participen activamente durante todo su desarrollo, debido a que son ell@s l@s que conocen en profundidad su negocio y saben cuáles son los resultados que se desean obtener. Además, es precisamente en base a la utilización que se le de, que el depósito de datos madurará y se adaptará a las situaciones cambiantes por las que atraviese la empresa. L@s usuari@s, al trabajar junto a l@s desarrollador@s y analistas podrán comprender más en profundidad sus propios sistemas operacionales, con todo lo que esto implica.
Con la implementación del DWH, los procesos de toma de decisiones serán optimizados, al obtener información correcta al instante en que se necesita, evitando perdidas de tiempo y anomalías en los datos. Al contar con esta información, l@s usuari@s tendrán más confianza en las decisiones que tomarán y en adición a ello, poseerán una base sustentable para justificarlas.
Usualmente, los DW integrarán fuentes de datos de diversas áreas y sectores de la empresa, esto tendrá como beneficio contar con una sola fuente de información centralizada y común para tod@s l@s usuari@s. Esto posibilitará que en las diferentes áreas se compartan los mismos datos, lo cual conducirá a un mayor entendimiento, comunicación, confianza y cooperación entre las mismas.
El DWH introducirá nuevos conceptos tecnológicos y de inteligencia de negocios, lo cual requerirá que se aprendan nuevas técnicas, herramientas, métodos, destrezas, formas de trabajar, etc.
6.7 DM como subproyectos
6.7 DM como subproyectos bernabeu_dario Thu, 05/14/2009 - 00:28Al diseñar e implementar DM como partes de un proyecto DW, se debe tener en cuenta que el análisis que se efectuará, los modelos que intervendrán y el alcance, deben ser globales, con el fin de determinar, por ejemplo, tablas de dimensiones comunes entre las diferentes áreas de trabajo. Esto evitará que se realicen tareas repetidas, ahorrando tiempos y enfocándose en la consolidación, unificación y centralización de la información de los diferentes sectores.
6.8 Teoría de Grafos
6.8 Teoría de Grafos bernabeu_dario Thu, 05/14/2009 - 00:29Para evaluar la validez de la estructura lógica del depósito de datos, puede emplearse la teoría de grafos, la cual afirma que su estructura será correcta sí y solo sí está conformada únicamente por trayectorias acíclicas.
Si se encuentran trayectorias cíclicas, deberán ser transformadas para que las consultas al DW sean válidas y confiables.
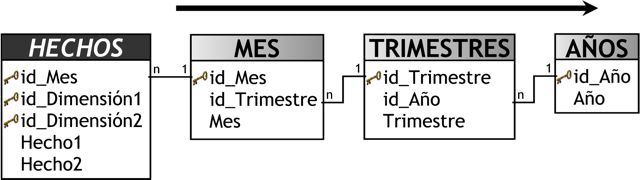
Una trayectoria acíclica, es aquella que sólo tiene una forma de recorrido (en un solo sentido). Por ejemplo, en la siguiente figura se puede apreciar que existe una sola manera de recorrer las tablas de dimensiones.
|
Figura 6.1: Trayectoria acíclica. |
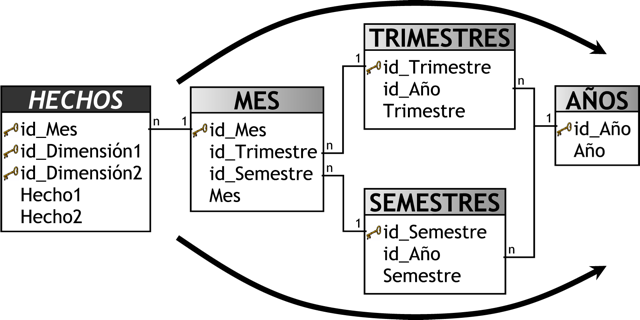
Una trayectoria cíclica, es aquella que se puede recorrer en dos o más secuencias diferentes. Por ejemplo, en la siguiente imagen se pueden distinguir dos sentidos por los cuales recorrer las tablas de dimensiones.
|
Figura 6.2: Trayectoria cíclica. |
6.9 Elección de Columnas
6.9 Elección de Columnas bernabeu_dario Thu, 05/14/2009 - 00:31Cuando se seleccionan los campos que integrarán el DW, se debe tener en cuenta lo siguiente:
-
Se deben descartar aquellos campos cuyos valores tengan muy poca variabilidad.
-
Se deben descartar los campos que tengan valores diferentes para cada objeto, por ejemplo el número de D.N.I. cuando se analizan personas.
-
En los casos en que no existan jerarquías dentro de alguna tabla de dimensión, en la cual la cantidad de registros que posee la misma son demasiados, es conveniente, conjuntamente con l@s usuari@s, definirlas. Pero, si llegase a suceder que no se encontrase ningún criterio por el cual jerarquizar los campos, es una buena práctica crear jerarquías propias. El objetivo de llevar a cabo esta acción, es la de poder dividir los registros en grupos, propiciando de esta manera una exploración más amena y controlable. Para ejemplificar este punto, se utilizará como referencia la tabla de dimensión de la siguiente figura. La misma no posee ninguna jerarquía definida y la cantidad de registros con que cuenta son cientos:
Figura 6.3: Tabla de dimensión ”PRODUCTO”.
Entonces, lo que se realizará será crear una nueva jerarquía a partir de los campos disponibles:
-
Se añadirá a la tabla un nuevo campo (“Letra”), el mismo estará formado por la primera letra del atributo “Producto” que lo acompaña. Por ejemplo, si el valor de “Producto” es “Lapicera”, “Letra” será “L”; si es “Cartuchera” será “C”, etc.
El resultado será el siguiente:
Figura 6.4: Jerarquía de ”PRODUCTO”.
Además, se pueden aplicar algunas de las acciones que se expondrán a continuación sobre los valores de los campos que se incluirán en el depósito de datos:
-


-
Factorizar: se utiliza para descomponer un valor en dos o más componentes. Por ejemplo, el campo “código” perteneciente a un producto está formado por tres identificadores separados por guiones medios, que representan su rubro, marca y tipo (“idRubro-idMarca-idTipo”), entonces este campo puede factorizarse y separarse en tres valores independientes (“idRubro”, “idMarca” e “idTipo”).
-
Estandarizar: se utiliza para ajustar valores a un tipo de formato o norma preestablecida. Por ejemplo, se puede emplear esté método cuando se desea que todos lo campos del tipo texto sean convertidos a mayúscula.
-
Codificar: es utilizado para representar valores a través de las reglas de un código preestablecido. Por ejemplo, en el campo “estado” se pueden codificar sus valores, “0” y “1”, para transformarlos en “Apagado” y “Encendido” respectivamente.
-
Discretizar: es empleado para convertir un conjunto continuo de valores en uno discreto. Por ejemplo, cuando se especificaron los tamaños del DW se realizó está operación.
6.10 Claves Primarias en Tablas de Dimensiones
6.10 Claves Primarias en Tablas de Dimensiones bernabeu_dario Thu, 05/14/2009 - 00:32Al momento de añadir la clave principal a una tabla de dimensión, se puede establecer:
- Una única columna que sea clave primaria e identifique unívocamente cada registro.
- Varias columnas que sean clave primaria e identifiquen en conjunto, unívocamente cada registro.
La primera opción requiere menos espacio de almacenamiento en el DW y permite que las consultas SQL sean más sencillas. La segunda opción requiere más espacio de almacenamiento en el DW, provoca que las consultas SQL sean más complejas y por consiguiente hace que se demore más tiempo en procesar los resultados. Sin embargo, esta última alternativa hace que los procesos ETL sean menos complejos y más eficientes.
Más allá de estas dos grandes opciones, es totalmente recomendable la utilización de Claves Subrogadas.
6.11 Balance de Diseño
6.11 Balance de Diseño bernabeu_dario Thu, 05/14/2009 - 00:34El siguiente gráfico muestra los tres puntos más importantes que se deben balancear al momento de diseñar y construir el modelo lógico de datos del DW:
|
Figura 6.5: Balance de diseño. |
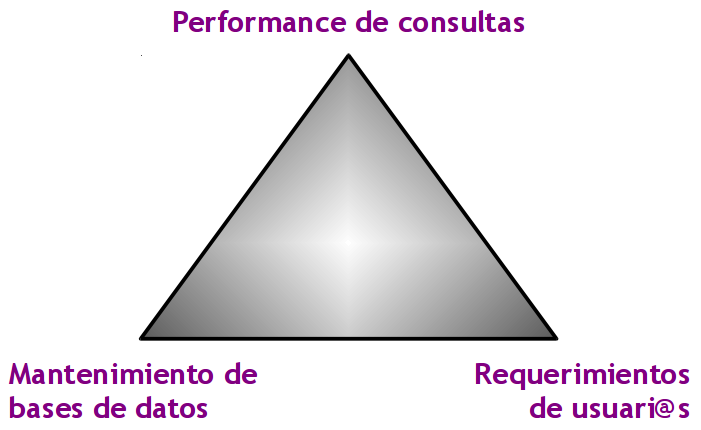
Estas tres características están fuertemente relacionadas y condicionadas entre sí, por lo cual, el valor que adopte cada una de ellas, afectará a las otras de manera significativa.
Por ejemplo, si se enfoca la atención en los requerimientos de l@s usuari@s, se obtendrá un DW muy complejo que cubrirá todas las necesidades de análisis. Sin embargo, traerá como contrapartida una disminución en la performance de las consultas y un aumento del mantenimiento de las bases de datos.
6.12 Relación muchos a muchos
6.12 Relación muchos a muchos bernabeu_dario Thu, 05/14/2009 - 00:35Siempre que sea posible, se debe evitar mantener en el DW tablas de dimensiones con relaciones muchos a muchos entre ellas, ya que esta situación puede, entre otros inconvenientes, provocar la pérdida de la capacidad analítica de la información y conducir a una sumarización incorrecta de los datos.
Para explicar esta problemática, se tomará como ejemplo la relación existente entre ríos y provincias, es decir:
-
Una provincia tiene uno o más ríos, y un río pertenece a una o más provincias.
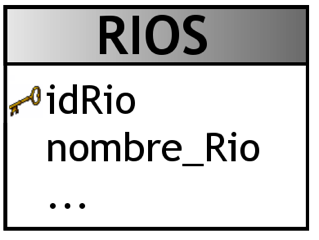
Además, se tomará como referencia las siguientes tablas pertenecientes a un OLTP, que contienen básicamente los datos relacionados a ríos y provincias:
|
Figura 6.6: Tabla ”RIOS”. |
|
Figura 6.7: Tabla ”PROVINCIAS”. |

Cuando existe este tipo de relación (muchos a muchos) entre dos o más tablas, se pueden realizar diferentes acciones para solventar esta situación. Una posible solución, sería llevar a cabo los siguientes pasos:
-
Crear una tabla de dimensión por cada entidad que pertenece a la relación. Cada una de estas tablas no debe incluir ninguna correspondencia a las demás. En este caso se crearán dos tablas de dimensiones, DIM_RIOS (correspondiente a la entidad “RIOS”) y DIM_PROV (correspondiente a la entidad “PROVINCIAS”).
-
Crear otra tabla de dimensión (en este caso DIM_RELACION), que sea hija de las tablas de dimensiones recientemente confeccionadas (en este caso DIM_RIOS y DIM_PROV), que estará compuesta de los siguientes campos:
-
Clave principal: dato autonumérico o autoincrementable (en este caso “id_dim_Relacion”).
-
Claves foráneas: se deben añadir cada una de las columnas que representan la clave principal de las tablas de dimensiones en cuestión (en este caso “id_dim_Rio” y “id_dim_Prov”).
-
Otros campos de información adicional.
-
-
Incluir el campo clave principal creado en el paso anterior (en este caso “id_dim_Relacion”) en la tabla de Hechos.
Gráficamente, el resultado sería el siguiente:
|
Figura 6.8: Posible solución al modelado de la relación muchos a muchos. |
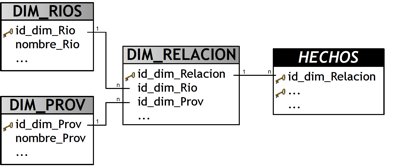
Otra posible solución sería agregar las dos claves primarias de las tablas de dimensiones DIM_RIOS y DIM_PROV en la tabla de hechos.
Existen otras soluciones para solventar esta brecha, pero la primera propuesta posee mucha performance, ya que:
-
Elimina la relación muchos a muchos.
-
Solo se necesita un campo clave en la tabla de Hechos.
-
Las relaciones entre las tablas resultantes es simple y fácil de visualizar.
La única desventaja es en cuanto a los procesos ETL, ya que se aumenta su complejidad y tiempo de proceso.
6.13 Claves Subrogadas
6.13 Claves Subrogadas bernabeu_dario Wed, 08/25/2010 - 02:51Las claves existentes en los OLTP se denominan claves naturales; en cambio, las claves subrogadas son aquellas que se definen artificialmente, son de tipo numérico secuencial, no tienen relación directa con ningún dato y no poseen ningún significado en especial.
Lo anterior, es solo una de las razones por las cuales utilizar claves subrogadas en el DW, pero se pueden definir una serie de ventajas más:
- Ocupan menos espacio y son más performantes que las tradicionales claves naturales, y más aún si estas últimas son de tipo texto.
- Son de tipo numérico entero (autonumérico o secuencial).
- Permiten que la construcción y mantenimiento de índices sea una tarea sencilla.
- El DW no dependerá de la codificación interna del OLTP.
- Si se modifica el valor de una clave en el OLTP, el DW lo tomará como un nuevo elemento, permitiendo de esta manera, almacenar diferentes versiones del mismo dato.
- Permiten la correcta aplicación de técnicas SCD (Dimensiones lentamente cambiantes).
Esta clave subrogada debe ser el único campo que sea clave principal de cada tabla de dimensión.
Una forma de implementación sería, a través de la utilización de herramientas ETL, mantener una tabla que contenga la clave primaria de la tabla del OLTP y la clave subrogada correspondiente a la dimensión del DW.
En la tabla de dimensión Tiempo, es conveniente hacer una excepción y mantener un formato tal como "yyyymmdd", ya que esto provee dos grandes beneficios:
- Se simplifican los procesos ETL.
- Brinda la posibilidad de realizar particiones de la tabla de hechos a través de ese campo.
6.14 Dimensiones lentamente cambiantes
6.14 Dimensiones lentamente cambiantes bernabeu_dario Wed, 08/25/2010 - 02:59Las dimensiones lentamente cambiantes o SCD (Slowly Changing Dimensions) son dimensiones en las cuales sus datos tienden a modificarse a través del tiempo, ya sea de forma ocasional o constante, o implique a un solo registro o la tabla completa. Cuando ocurren estos cambios, se puede optar por seguir alguna de estas dos grandes opciones:
- Registrar el historial de cambios.
- Reemplazar los valores que sean necesarios.
A continuación se detallará cada tipo de estrategia SCD:
- SCD Tipo 1: Sobreescribir.
- SCD Tipo 2: Añadir fila.
- SCD Tipo 3: Añadir columna.
- SCD Tipo 4: Tabla de Historia separada.
- SCD Tipo 6: Híbrido.
Es importante señalar que si bien hay diferentes maneras de implementar cada técnica, es indispensable contar con claves subrogadas en las tablas de dimensiones para aplicar poder aplicar dichas técnicas.
Al aplicar las diferentes técnicas SCD, en muchos casos se deberá modificar la estructura de la tabla de dimensión con la que se este trabajando, por lo cual estas modificaciones son recomendables hacerlas al momento de modelar la tabla; aunque también puede hacerse una vez que ya se ha modelado y contiene datos, para lo cual al añadir por ejemplo una nueva columna se deberá especificar los valores por defecto que adoptarán los registros de la tabla.
NOTA: para todos los ejemplos a continuación, "id_Producto" es una clave subrogada que es clave principal de la tabla utilizada.
SCD Tipo 1: Sobreescribir
En este caso cuando un registro presente un cambio en alguno de los valores de sus campos, se debe proceder simplemente a actualizar el dato en cuestión, sobreescribiendo el antiguo. Para ejemplificar este caso, se tomará como referencia la siguiente tabla:
| id_Producto | Rubro | Tipo | Producto |
| 1 | Rubro 1 | Tipo 1 | Producto 1 |
| id_Producto | Rubro | Tipo | Producto |
| 1 | Rubro 2 | Tipo 1 | Producto 1 |
Esta estrategia requiere que se agreguen algunas columnas adicionales a la tabla de dimensión, para que almacenen el historial de cambios.
Las columnas que suelen agregarse son:
- FechaInicio: fecha desde que entró en vigencia el registro actual. Por defecto suele utilizarse una fecha muy antigua, ejemplo: "01/01/1000".
- FechaFin: fecha en la cual el registro actual dejó de estar en vigencia. Por defecto suele utilizarse una fecha muy futurista, ejemplo: "01/01/9999".
- Versión: número secuencial que se incrementa cada nuevo cambio. Por defecto suele comenzar en "1".
- Versión actual: especifica si el campo actual es el vigente. Este valor puede ser en caso de ser verdadero: "true" o "1"; y en caso de ser falso: "flase" o "0".
Para ejemplificar este caso, se tomará como referencia la siguiente tabla:
| id_Producto | Rubro | Tipo | Producto |
| 1 | Rubro 1 | Tipo 1 | Producto 1 |
| id_Producto | Rubro | Tipo | Producto | FechaInicio | FechaFin | Version | VersionActual |
| 1 | Rubro 1 | Tipo 1 | Producto 1 | 01/01/1000 | 01/01/9999 | 1 | true |
| id_Producto | Rubro | Tipo | Producto | FechaInicio | FechaFin | Version | VersionActual |
| 1 | Rubro 1 | Tipo 1 | Producto 1 | 01/01/1000 | 06/11/2009 | 1 | false |
| 2 | Rubro 2 | Tipo 1 | Producto 1 | 07/11/2009 | 01/01/9999 | 2 | true |
- Se añade una nueva fila con su correspondiente clave subrogada ("id_Producto").
- Se registra la modificación ("Rubro").
- Se actualizan los valores de "FechaInicio" y "FechaFin", tanto de la fila nueva, como la antigua (la que presentó el cambio).
- Se incrementa en uno el valor del campo "Version" que posee la fila antigua.
- Se actualizan los valores de "VersionActual", tanto de la fila nueva, como la antigua; dejando a la fila nueva como el registro vigente (true).
SCD Tipo 3: Añadir columna
Esta estrategia requiere que se agregue a la tabla de dimensión una columna adicional por cada columna cuyos valores se desea mantener un historial de cambios.
Para ejemplificar este caso, se tomará como referencia la siguiente tabla:
| id_Producto | Rubro | Tipo | Producto |
| 1 | Rubro 1 | Tipo 1 | Producto 1 |
| id_Producto | Rubro | RubroAnterior | Tipo | Producto |
| 1 | Rubro 1 | - | Tipo 1 | Producto 1 |
| id_Producto | Rubro | RubroAnterior | Tipo | Producto |
| 1 | Rubro 2 | Rubro 1 | Tipo 1 | Producto 1 |
- En la columna "RubroAnterior" se coloca el valor antiguo.
- En la columna "Rubro" se coloca el nuevo valor vigente.
SCD Tipo 4: Tabla de Historia separada
Esta tabla histórica indicará por ejemplo que tipo de operación se ha realizado (Insert, Update, Delete), sobre que campo y en que fecha. El objetivo de mantener esta tabla es el de contar con un detalle de todos los cambios, para luego analizarlos y poder tomar decisiones acerca de cuál técnica SCD podría aplicarse mejor. Por ejemplo, la siguiente tabla histórica registra los cambios de la tabla de dimensión "Productos", la cual supondremos emplea el SCD Tipo 2:
| id_Producto | Rubro_Cambio | Tipo_Cambio | Producto_Cambio | FechaDeCambio |
| 1 | Insert | - | - | 05/06/2000 |
| 2 | Insert | Insert | - | 25/10/2002 |
| 3 | - | Insert | - | 17/01/2005 |
| 4 | - | - | Insert | 18/02/2009 |
- El día "05/06/2000", el registro de la tabla de dimensión "Productos" con "id_Producto" igual a "1" sufrió un cambio de "Rubro", por lo cual se debío insertar ("Insert") una nueva fila con los valores vigentes.
SCD Tipo 6: Híbrido
Se denomina SCD Tipo "6", simplemente porque: 6 = 1 + 2 +3.
6.15 Dimensiones Degeneradas
6.15 Dimensiones Degeneradas bernabeu_dario Wed, 08/25/2010 - 03:02El término Dimensión Degenerada, hace referencia a un campo que será utilizado como criterio de análisis y que es almacenado en la tabla de hechos.
Esto sucede cuando un campo que se utilizará como criterio de análisis posee el mismo nivel de granularidad que los datos de la tabla de hechos, y que por lo tanto no se pueden realizar agrupaciones o sumarizaciones a través de este campo. Los "números de orden", "números de ticket", "números de transacción", etc, son algunos ejemplos de dimensiones degeneradas
La inclusión de estos campos en las tablas de hechos, se lleva a cabo para reducir la duplicación y simplificar las consultas.
6.16 Dimensiones Clustering
6.16 Dimensiones Clustering bernabeu_dario Wed, 08/25/2010 - 03:21Las dimensiones Clustering, son aquellas que están relacionadas a dos o más dimensiones y que brindan información diferente a cada una de ellas.
Por ejemplo, en el siguiente esquema, se puede apreciar que dos tablas de dimensiones (“CLIENTES” y “PROVEEDORES”) comparten otra en común (“CIUDADES”), además esta última provee diferente información dependiendo de la tabla de dimensión que la consulte, es decir, devuelve el nombre de la ciudad de l@s client@s o bien la de l@s proveedor@s. En este caso y debido a lo dicho anteriormente, la dimensión ”CIUDADES”, es una dimensión Clustering.
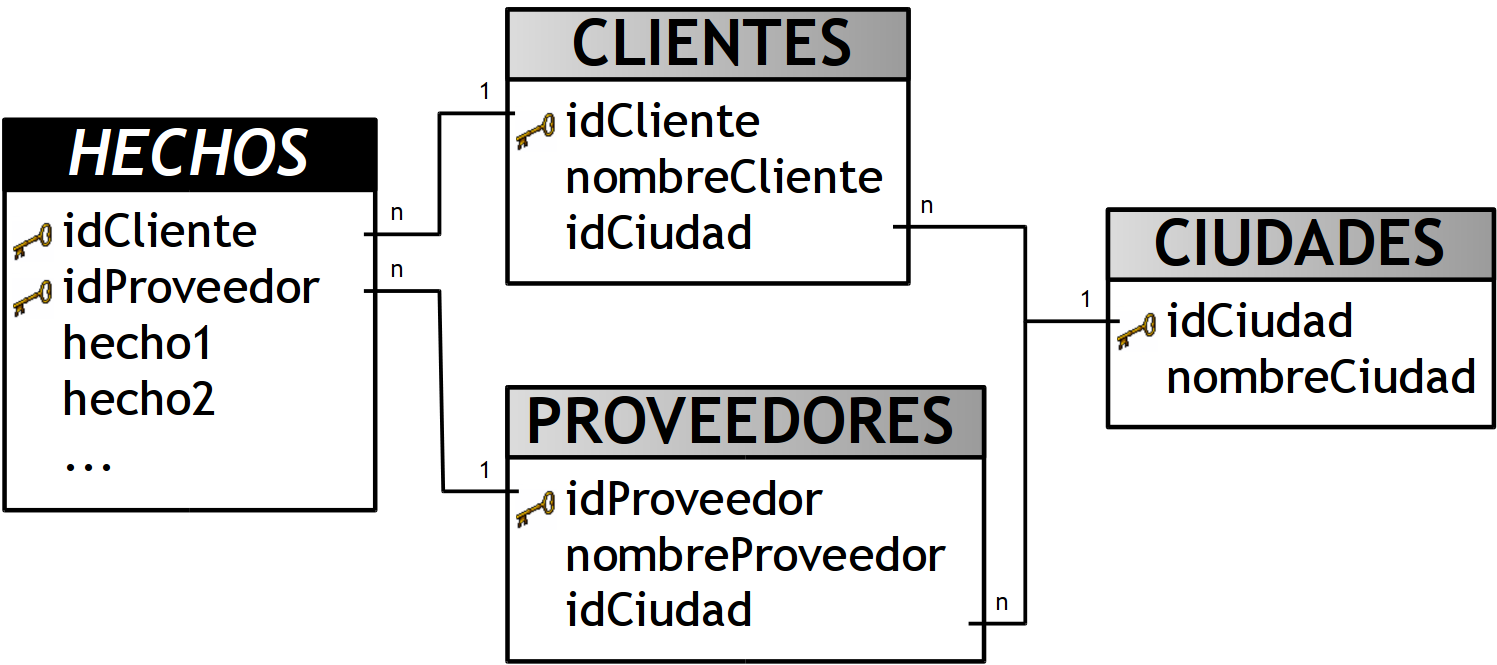
Figura 6.18: Dimensión Clustering: "CIUDADES"
Obviamente no se puede mantener este esquema si se pretende analizar los hechos de acuerdo a la ciudad de l@s proveedor@s y de l@s client@s simultáneamente.
Para solucionar esta situación pueden llevarse a cabo diferentes estrategias, cada una de las cuales trae aparejadas sus ventajas y desventajas, por lo cual dependiendo cual sea el contexto se elegirá entre una y otra.
A continuación se destacarán algunas soluciones a esta situación:
- Se pueden incluir todos los campos de la dimensión Clustering en cada tabla de dimensión con que se relacione y eliminar luego la dimensión Clustering. En este caso:
- Agregar el campo “nombreCiudad” de la dimensión Clustering “CIUDADES” a la tabla de dimensión ”CLIENTES”.
- Agregar el campo “nombreCiudad” de la dimensión Clustering “CIUDADES” a la tabla de dimensión ”PROVEEDORES”.
-
Eliminar la dimensión Clustering ”CIUDADES”.
- Ventajas: Elimina los JOINs entre las tablas.
- Desventajas: Ante cualquier cambio en los nombres de las ciudades se debe modificar/actualizar todas las dimensiones implicadas.
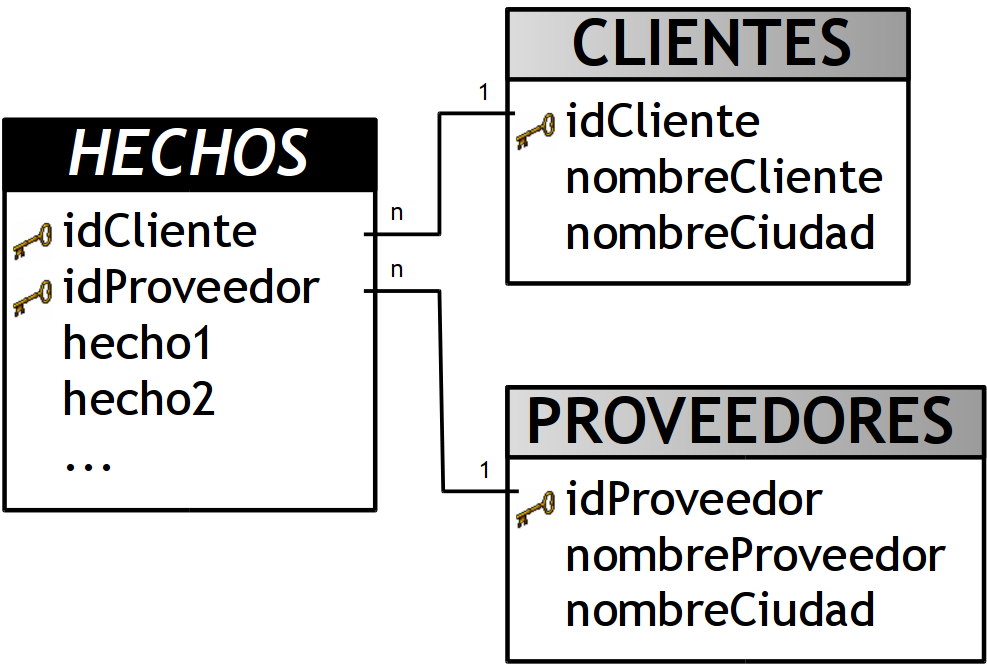
Figura 6.19: Dimensión Clustering: primera posible solución.
-
Se puede crear una nueva tabla de dimensión basada en la dimensión Clustering por cada tabla que se relacione con esta y luego eliminar la dimensión Clustering. En este caso:
-
Crear la tabla de dimensión “CIUDADES_CLI”, esta estará basada en la dimensión Clustering ”CIUDADES”.
-
Crear la tabla de dimensión “CIUDADES_PROV”, esta estará basada en la dimensión Clustering ”CIUDADES”.
-
Eliminar la dimensión Clustering ”CIUDADES”.
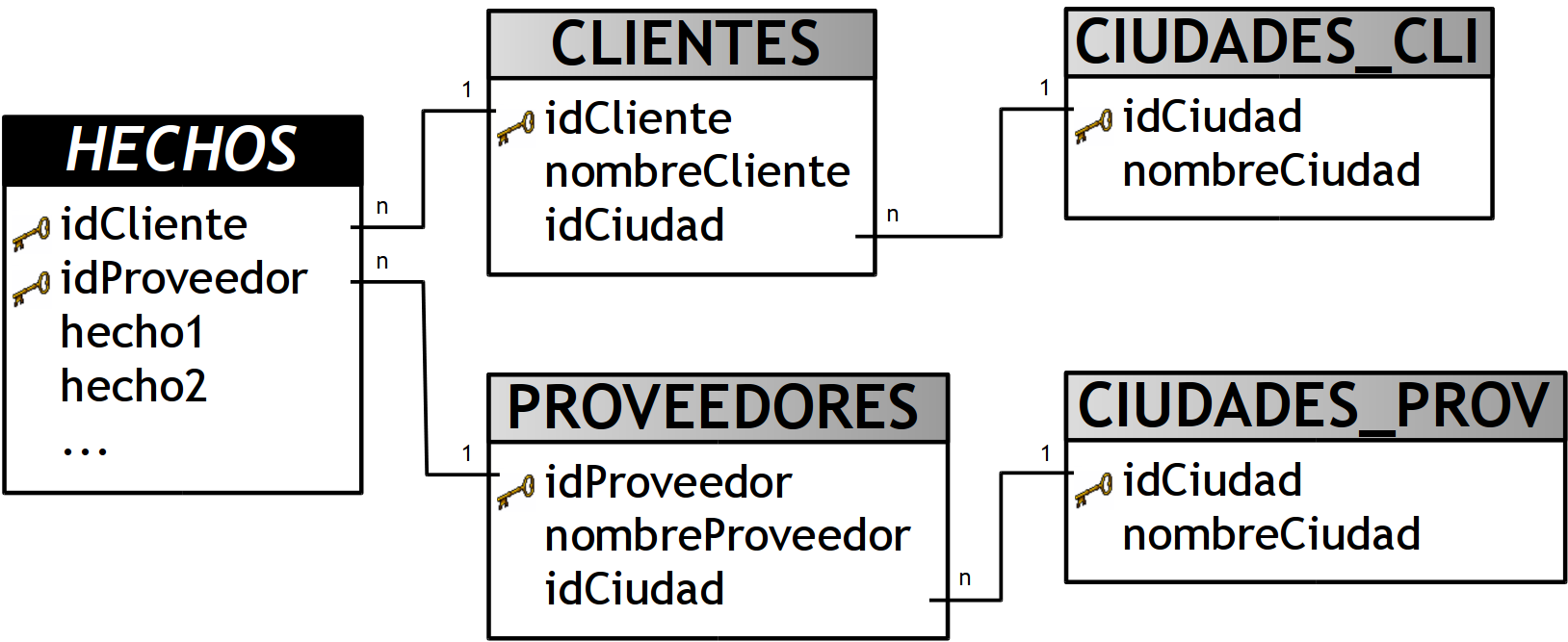
Figura 6.20: Dimensión Clustering: segunda posible solución.
- Ventajas: Ante cualquier cambio en los nombres de las ciudades, solo se deben modificar/actualizar las nuevas dimensiones que están basadas en la dimensión Clustering.
- Desventajas: Mantiene los JOINs entre las tablas.
-