
TOP software Plataforma de datos
- Ranking Dataprix -
SAP HANA
SAP HANA (High-performance ANalytic Appliance) es una base de datos multimodelo que almacena datos en su memoria en lugar de en un disco. Este diseño basado en columnas permite ejecutar análisis avanzados junto con transacciones de alta velocidad en un único sistema. SAP HANA permite a las empresas procesar grandes cantidades de datos con una latencia casi nula..
IBM DB2
IBM DB2 es una base de datos relacional de alto rendimiento diseñada para gestionar grandes volúmenes de datos y proporcionar transacciones de baja latencia. Con décadas de experiencia, DB2 se ha convertido en una solución confiable para cargas de trabajo críticas, ofreciendo escalabilidad casi infinita, análisis en tiempo real y soporte multinube..
Cloudera Data Platform
Cloudera Data Platform es una solución de bases de datos híbrida diseñada para gestionar y analizar datos en entornos de nube pública, privada y multinube. Ofrece una plataforma unificada que permite a las organizaciones almacenar, procesar y analizar datos de manera eficiente y segura, con capacidades avanzadas para la gestión de datos, análisis y aprendizaje automático..
Huawei GaussDB
Huawei GaussDB es una base de datos distribuida de clase empresarial distribuida, con motor nativo de IA, con arquitectura de procesamiento masivo paralelo (MPP).
GaussDB admite tanto almacenamiento orientado a filas como a columnas y es capaz de procesar petabytes de datos. Permite administrar conjuntos de datos masivos y es compatible con una amplia gama de sistemas de almacenamiento de datos, sistemas de BI y de soporte a decisiones..
Apache Hive
Hive es un software que trabaja sobre clusters de Hadoop creando una capa que permite al desarrollador abstraerse de la gestión de ficheros HDFS y de MapReduce mediante operaciones de consulta de datos basadas en SQL, con el lenguaje HiveQL..
Apache Spark
Spark es un framework open source de Apache Software Foundation para procesamiento distribuído sobre clusters de ordenadores de grandes cantidades de datos, ideado para su uso en entornos de Big Data, y creado para mejorar las capacidades de su predecesor MapReduce.
Spark hereda las capacidades de escalabilidad y tolerancia a fallos de MapReduce, pero lo supera ampliamente en cuanto a velocidad de procesamiento, facilidad de uso y capacidades analíticas..
Apache Hadoop
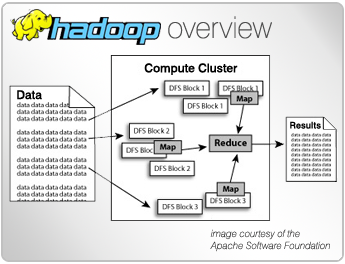
La librería de software de Hadoop es un framework que permite el procesamiento distribuído de juegos de datos de gran volumen utilizando clusters de ordenadores o servidores, utilizado modelos de programación sencilla.
Hadoop está diseñado para escalar fácilmente desde sistemas de servidores únicos a miles de máquinas..
Amazon RDS
Amazon RDS (Relational Database Service) es un servicio administrado que facilita la configuración, operación y escalado de bases de datos relacionales en la nube.
Ofrece soporte para múltiples motores de bases de datos, incluyendo MySQL, PostgreSQL, y Oracle.
Su capacidad para automatizar tareas administrativas reduce significativamente el tiempo y esfuerzo necesarios para gestionar bases de datos..
