


Image Source
Google Cloud offers a broad set of tools for disaster recovery (DR). A key part of any disaster recovery setup is the data - how will data be replicated to a DR site? When disaster occurs, how will you ensure your data is in sync, and how can you restore your data and meet your RTO? Rean on to learn about these practices.
Google Cloud Disaster Recovery: Data Scenarios
When setting up a disaster recovery program using Google Cloud Platform (GCP), data is critical. There are four primary scenarios for recovering data in GCP. In each scenario, we’ll explain how to set up ongoing replication of the data to a disaster recovery site in Google Cloud:
- Master data stored on-premises
- Master data stored in GCP
- Database server running on-premises
- Database server running in GCP
1. Replicating Master Data Stored On-Premises to Google Cloud
As part of your Google Cloud disaster recovery strategy, you’ll need to backup standalone master data volumes. Let’s see how this works in Google Cloud, for master data stored on-premises.
To backup data from your on-premise data center to Google Cloud Platform, you can use Google Cloud Storage. The gsutil command-line tool lets you create an automated, scheduled task to copy data from the on-premise environment.
gsutil -m cp -r [SOURCE_DIRECTORY] gs://[BUCKET_NAME]
To setup automated backup and recovery for data:
- Install gsutil on the on-premises machine that holds the data.
- Create a storage bucket using this terminal command:
gsutil mb -l [REGION] gs://[BUCKET_NAME]
- Generate a service account key using the IAM & Admin screen in the Google Cloud Console. The gsutil command uses this key to remotely connect to Google Cloud Storage. Copy the key to the on-premise machine.
- Create an IAM policy to define access to the storage bucket, referencing the service account you created.
- Test uploading and downloading files to and from in the target bucket.
- Create a data transfer script that copies your data to the storage bucket (see Google’s guidelines for this type of script).
- Create another script that uses gsutil to recover data from the storage bucket to your disaster recovery environment.
2. Safeguarding Master Data Stored on Google Cloud
The important thing to understand about master data already stored in Google Cloud Storage, is that you define your disaster recovery options when you setup your storage bucket. The critical setting for disaster recovery is called bucket locations.
When creating a bucket you have the following bucket location options:
- Region (single region)
- Dual-region
- Multi-region
If you select dual-region or multi-region, your data is always stored across two or more geographically-separated regions. This is exactly what you need for a disaster recovery scenario. Google guarantees that your data remains available even in case of a disaster that compromises Google data centers across the region.
According to Google documentation:
Cloud Storage always provides strongly consistent object listings from a single bucket, even for buckets with data replicated across multiple regions. This means a zero RTO in most circumstances for geo-redundant storage locations.
To recap - just set your Google Cloud Storage bucket to a dual-region or multi-region, and your data is automatically saved on two or more geographical regions. Even if one region goes down, you can still access the data instantly, providing an effective Recovery Time Objective of zero.
What about storage tiering?
The second thing to consider is that if data is not needed on an ongoing basis, you may want to move it to a lower cost data storage tier to conserve costs. Be aware there are costs associated with retrieving data or metadata in the cheaper Google Cloud Storage options, and some have minimum storage durations. However, Google Cloud Storage does not penalize you in terms of data access latency; even when you move data to lower cost tiers, you can still access it instantly.
Google offers the following tiers, in descending order of storage cost:
- Persistent disk on a compute engine instance
- Cloud Storage Standard
- Cloud Storage Nearline
- Cloud Storage Coldline
Google Cloud Storage buckets are assigned to one of these three classes. When you save an object to a bucket, it gets the same storage class as the bucket (for example, Cloud Storage Standard). However, you can set a different storage class for specific objects. So there are two ways to move your data to lower cost tiers:
- Set a storage class of Nearline or Coldline for the entire bucket
- Set a storage class of Nearline or Coldline for specific objects - for example, for all documents dated 2010 or earlier
3. Replicating Databases Stored On-Premises to Google Cloud
When you replicate a database to Google Cloud, it’s a good idea to use transaction logs, so you can recover your database to a specific point in time. Make sure that your recovery database system mirrors the production environment in terms of software version and mirror disk configuration.
Google recommends using a “high-availability-first approach” - data should be saved to your recovery environment first, only then to the production environment. This will minimize the time to recover in case the database server becomes unavailable.
Follow these steps to ensure you have a working replica of your on-premise database, and verify you can recover operations to it within your Recovery Time Objective (RTO):
- Create an export of your database and save it to Google Cloud Storage using the same procedure as shown above (1. Replicating Master Data Stored On-Premises). Also copy your database’s transaction logs. If you are not familiar with logging practices, you can check out this in-depth guide about cloud logging.
- Create a custom image of your production database server, by stopping the database or minimizing the amount of writes, and using the Create Image Page in Google Console.
- Start a minimum-size instance from the custom image and attach a persistent disk, setting the auto delete flag to false. Import the latest backup file into the data on the image, and copy the latest transaction log files from Cloud Storage.
- Replace the minimum-size instance with a GCP instance that is strong enough to handle your production traffic. Switch over traffic from the damaged production instance to the recovered database.
- Ensure you have a process for switching back from the recovery environment to your production environment when it is restored. To test this, after switching over to the recovery environment:
- Backup the recovery database and copy transaction log files to cloud storage.
- Stop the database system service of the recovery database to ensure it doesn’t receive new updates.
- Copy the database backup and transaction logs to the production environment and restore your production database.
- Redirect client requests back to the production environment.
4. Replicating Databases in Google Cloud Storage
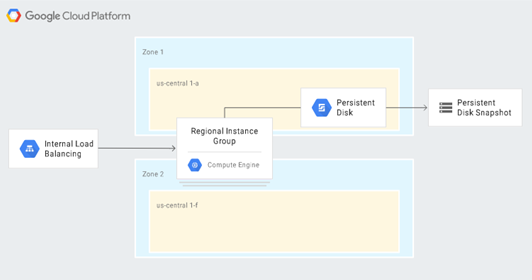
The following diagram illustrates how a database can be automatically replicated for disaster recovery purposes within the Google Cloud Platform.
 [1] Source: Google Cloud Platform
[1] Source: Google Cloud Platform
This scenario involves:
- Creating a VPC network
- Creating a custom image within the network that is configured to function exactly like the original database server.
- Creating an instance template that uses that image
- Configuring an instance group with internal load balancing. Load balancing should be configured to use health checking with Stackdriver metrics.
See the complete instructions from Google on how to set up this configuration.
The end result is that you can automatically:
- Detect failure
- Start another database server of the correct version while ensuring that up-to-date security controls transfer correctly from the production to the recovery environment
- Attach a persistent disk with the latest backup and transaction log files
- Eliminate the need for clients to reconfigure in order to switch to the recovery environment
- Ensure that the GCP security controls (IAM policies, firewall settings) that apply to the production database server apply to the recovered database server
Conclusion
Google Cloud provides a wide range of useful services, but it’s important to take measures of your own. Cloud vendors run on a shared responsibility model. This means cloud users are required to take measures to ensure data security and privacy. Unless you’re using a fully managed service, it’s best to set up your own disaster recovery policies.
URL for upload: https://cloud.google.com/solutions/images/dr-scenarios-for-data-persist…

{kind=link}