


As more developers shift to cloud-native practices, more applications are developed and deployed using containerization. The goal is typically to to enable micro-services architecture, which is highly scalable.
To manage containerization, developers use container orchestration platforms, like Kubernetes. However, it is not only developers who can make use of Kubernetes. Read on to learn how to use Kubernetes for big data.
What Is Kubernetes?
Kubernetes (K8s) is an open-source framework you can use for container orchestration. It was created by Google to help run their own container deployments and is the most widely adopted framework today.
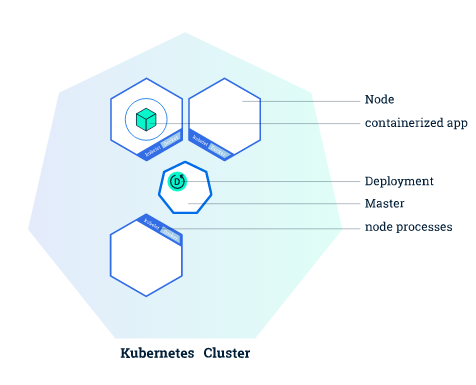
Source: Kubernetes.io
Kubernetes primary features include:
- Service discovery
- Load balancing
- Storage orchestration, including persistent storage
- Automated rollouts and rollbacks for updates
- Self-healing
- Secrets and configuration management
What Is Big Data?
Big data is high-volume data that is used to enable automation, inform decision making, or enhance insight. Data is often collected in real or near-real-time and covers a wide variety of data points or individuals.
Big data solutions enable organizations to capture, store, process, analyze, and visualize big data. These solutions provide the administrative controls necessary to manage the complex infrastructures needed to use big data. Often, these solutions include features for AI-powered queries, data sharing and collaboration, and data security features.
Kubernetes for Big Data
When creating a big data solution, determining and implementing the right architecture can be a challenge. To handle big data requirements, solutions must be capable of handling exponentially growing data at scale. Ideally, solutions should be reliable, highly-available, and secure. Solutions also need to be capable of smoothly connecting massive amounts of data to analytics applications and low-level infrastructure.
Kubernetes meets these requirements and enables you to deploy applications and scale resources as needed. With K8s, you can manage batch workloads and reliably transfer data to your analytics or machine learning applications. K8s also makes it possible to easily incorporate existing big data tools, such as Hadoop or HPCC, to any infrastructure you choose. This includes cloud, on-premises, and hybrid infrastructures.
A large part of the appeal of Kubernetes is its scalability and extensibility. For example, Google recently announced that they are transitioning to using Kubernetes as a Spark scheduler instead of the standard, YARN. Spark is one of the top solutions used to perform compute-heavy operations with big data. Alongside this announcement, Spark is currently working to add support for using the native k8s scheduler on Spark jobs.
Best Practices in Deploying Containers with Big Data
When using containers with big data, there are several best practices you can implement.
Clearly define your goals
If you are considering transitioning your big data to the cloud or have just migrated, make sure that your business goals are clearly defined. While it may seem like a great idea to migrate with a bang and implement containers all at once, this may not be the best option for you. Consider how containerization complements your goals and be aware of aspects that don’t match up.
Container management adds another level to the complexity of using big data in the cloud that you may not be prepared for. Additionally, the scalability of containers can quickly exceed your expected cloud costs if not carefully managed. To avoid these issues, you may find it easier to first start with simpler aspects, such as data storage or ingestion.
Stay cloud agnostic
One of the greatest benefits of K8s and containers is that you can use these tools across environments. This means you can selectively choose the best cloud services for your needs with less concern for vendor lock-in or restrictions. When deploying big data with containers, take advantage of this benefit.
Evaluate your data and applications to determine the most effective host solution. When doing this, you should take into account availability, data priority, and network latency. Try to choose services that already provide support for Kubernetes deployments. Additionally, make efforts to centralize your management and monitoring. Doing so will make multi-cloud strategies more efficient.
Consider a managed service
Kubernetes can be a challenge to use. It requires significant expertise and dedicated staff to implement effectively. If you do not have this expertise or staffing available in-house, you can still benefit from k8s with managed services. All of the major cloud providers offer managed services at some level. There is also a variety of third-party managed KaaS services you can use.
Managed services can reduce the amount of effort needed to deploy K8s, letting you focus on managing and drawing insights from your data. When choosing a managed provider, make sure that they are familiar with big data processes. Many providers offer pre-configured images of containers to ease deployment. Ideally, the provider you chose will already have configurations available for your analytics tooling and data pipelines.
Manage data security
While a container can be more secure due to its isolated nature, it does not provide surefire protection for your data. Additionally, the use of containers requires extensive networking over which data is frequently transferred. To ensure that your data remains secure, you need to implement strict security protocols for your containers and underlying infrastructure.
Ensure that your data is encrypted both during transfer and at-rest whenever possible. Do keep in mind, however, that encryption can affect the speed of your processes. For containers, try to limit root permissions and apply whitelist controls to access when possible.
Implementing a service mesh, such as Istio or Linkerd, can also increase security. Service mesh technologies can add visibility and centralized control to your container communications.
Conclusion
The term big data may refer to huge amounts of data, or to the various uses of the data generated by devices, systems, and applications. You can manage big data workloads with Kubernetes, and you can also add additional services dedicated to big data, to extend the built-in features.
When deploying containers with big data, it is important to clearly define goals, stay cloud agnostic, and manage data security. For this purpose, you can use any of the built-in Kubernetes features, or extend native capabilities with third-parties and add-ons.
