Lenguaje Oracle SQL, PL/SQL y desarrollo
Lenguaje Oracle SQL, PL/SQL y desarrollo Dataprix Tue, 09/08/2009 - 09:49Cómo hacer o mejorar sentencias Oracle SQL, utilizar PL/SQL y los procedimientos almacenados, o cualquier cosa relacionada con el desarrollo o explotación de bases de datos Oracle
Construcción de scripts Oracle SQL con ayuda del diccionario
Construcción de scripts Oracle SQL con ayuda del diccionario Carlos Thu, 06/07/2007 - 23:12Es bastante habitual si se trabaja con bases de datos que a menudo se tenga que realizar alguna tarea de creación o alteración de estructuras, análisis, recompilación, etc. sobre objetos de la base de datos. Para ello se suele crear un script con numerosas sentencias DDL, en las que la mayoría de las veces lo único que cambia es el nombre del objeto a tratar.
Crear sentencia Oracle SQL que genera sentencias Oracle
En estos casos puede ahorrarnos mucho trabajo la utilización del diccionario de la base de datos para construir estas sentencias dinámicamente. Pondremos como ejemplo la creación de un nuevo campo para almacenar la fecha de creación de los registros en todas las tablas de un esquema de una base de datos ORACLE. Para ello utilizaríamos la siguiente sentencia de SQL Oracle:
SELECT 'ALTER TABLE ' || OWNER || '.' || TABLE_NAME || ' ADD FECHA_CREACION DATE DEFAULT SYSDATE;'
FROM ALL_TABLES WHERE OWNER ='HR'; El resultado de esta sentencia SQL Oracle sería algo como esto, las sentencias SQL que queremos utilizar en realidad:
ALTER TABLE HR.DEPARTMENTS ADD FECHA_CREACION DATE DEFAULT SYSDATE; ALTER TABLE HR.EMPLOYEES ADD FECHA_CREACION DATE DEFAULT SYSDATE; ALTER TABLE HR.JOB_HISTORY ADD FECHA_CREACION DATE DEFAULT SYSDATE; ALTER TABLE HR.JOBS ADD FECHA_CREACION DATE DEFAULT SYSDATE; ALTER TABLE HR.LOCATIONS ADD FECHA_CREACION DATE DEFAULT SYSDATE; ALTER TABLE HR.REGIONS ADD FECHA_CREACION DATE DEFAULT SYSDATE; ALTER TABLE HR.COUNTRIES ADD FECHA_CREACION DATE DEFAULT SYSDATE;
Crear script con Oracle SQL para ejecutar sentencias SQL
Ahora sólo restaría guardar estas sentencias en un script y ejecutarlo, o lanzarlas directamente desde la aplicación que utilicemos para interactuar con nuestra base de datos.
Para el que tenga que (o prefiera) trabajar desde un terminal o linea de comandos, la manera de hacer esto mismo con SQLPLUS sería la siguiente:
SQL> SET HEADING OFF
SQL> SET FEEDBACK OFF
SQL> SPOOL C:\campo_auditoria.sql
SQL> SELECT 'ALTER TABLE ' || OWNER || '.' || TABLE_NAME || ' ADD FECHA_CREACION DATE DEFAULT SYSDATE;'
FROM ALL_TABLES WHERE OWNER ='HR';
SQL> SPOOL OFF;
SQL> SET FEEDBACK ON
SQL> SET HEADING ON Y finalmente ejecutar el script generado, aunque es recomendable una revisión previa de las sentencias generadas:
SQL> @C:\campo_auditoria.sql
Estructura de la Dimension Tiempo y Script de carga con Oracle SQL
Estructura de la Dimension Tiempo y Script de carga con Oracle SQL Carlos Sat, 08/29/2009 - 23:47Con este script de Oracle SQL se crea una tabla DIM_TIEMPO y se rellena con los valores comprendidos entre las fechas que se indiquen en las variables FechaDesde y FechaHasta. Puede ser muy útil para la creación de la tabla de tiempo de cualquier Data Warehouse.
Esta es la versión para una base de datos Oracle, con Oracle SQL, que se suma a las que han creado anteriormente il_masacratore y Dario Bernabeu para Microsoft SQL Server y Oracle MySQL en sus respectivos blogs:
Estructura de la Dimensión Tiempo y Script de carga para Ms SQL Server
Estructura de la Dimensión Tiempo y Procedure de carga para MySQL
----------------------------------------------------
-- SQL de Creación de la tabla DIM_TIEMPO --
----------------------------------------------------
drop table DIM_TIEMPO;
create table DIM_TIEMPO
(
FechaSK number not null,
Fecha date not null PRIMARY KEY,
Año number not null,
Trimestre number not null,
Mes number not null,
Semana number not null,
Dia number not null,
DiaSemana number not null,
NTrimestre varchar2(7) not null,
NMes varchar2(15) not null,
NMes3L varchar2(3) not null,
NSemana varchar2(10) not null,
NDia varchar2(6) not null,
NDiaSemana varchar2(10) not null
);------------------------------------------------------------
-- Script Oracle SQL de carga de los datos entre fechas --
------------------------------------------------------------
DECLARE
FechaDesde date;
FechaHasta date;
BEGIN
--Borrar datos actuales, si fuese necesario
--TRUNCATE TABLE DIM_TIEMPO
--Rango de fechas a generar: del 01/01/2006 al 31/12/Año actual+2
FechaDesde := TO_DATE('20060101','YYYYMMDD');
FechaHasta := TO_DATE((TO_CHAR(sysdate,'YYYY')+2 || '1231'),'YYYYMMDD');
WHILE FechaDesde <= FechaHasta LOOP
INSERT INTO DIM_TIEMPO
(
FechaSK,
Fecha,
Año,
Trimestre,
Mes,
Semana,
Dia,
DiaSemana,
NTrimestre,
NMes,
NMes3L,
NSemana,
NDia,
NDiaSemana
)
VALUES
(
to_char(FechaDesde,'YYYYMMDD'),
FechaDesde,
to_char(FechaDesde,'YYYY'),
to_char(FechaDesde, 'Q'),
to_char(FechaDesde,'MM'),
to_char(FechaDesde,'WW'),
to_char(FechaDesde,'DD'),
to_char(FechaDesde,'D'),
'T'||to_char(FechaDesde, 'Q')||'/'||to_char(FechaDesde,'YY'),
to_char(FechaDesde,'MONTH'),
to_char(FechaDesde,'MON'),
'Sem '||to_char(FechaDesde,'WW')||'/'||to_char(FechaDesde,'YY'),
to_char(FechaDesde,'DD MON'),
to_char(FechaDesde,'DAY')
);
--Incremento del bucle
FechaDesde := FechaDesde + 1;
END LOOP;
END;
Como cada uno se adaptará el formato de las fechas al que más le convenga, aprovecho para adjuntar esta tabla de ayuda obtenida de Oradev. Contiene descripciones de la sintaxis que se puede utilizar en las máscaras de formato de fechas de las funciones TO_CHAR y TO_DATE de Oracle:
| Format mask | Description |
|---|---|
| CC | Century |
| SCC | Century BC prefixed with - |
| YYYY | Year with 4 numbers |
| SYYY | Year BC prefixed with - |
| IYYY | ISO Year with 4 numbers |
| YY | Year with 2 numbers |
| RR | Year with 2 numbers with Y2k compatibility |
| YEAR | Year in characters |
| SYEAR | Year in characters, BC prefixed with - |
| BC | BC/AD Indicator * |
| Q | Quarter in numbers (1,2,3,4) |
| MM | Month of year 01, 02...12 |
| MONTH | Month in characters (i.e. January) |
| MON | JAN, FEB |
| WW | Weeknumber (i.e. 1) |
| W | Weeknumber of the month (i.e. 5) |
| IW | Weeknumber of the year in ISO standard. |
| DDD | Day of year in numbers (i.e. 365) |
| DD | Day of the month in numbers (i.e. 28) |
| D | Day of week in numbers(i.e. 7) |
| DAY | Day of the week in characters (i.e. Monday) |
| FMDAY | Day of the week in characters (i.e. Monday) |
| DY | Day of the week in short character description (i.e. SUN) |
| J | Julian Day (number of days since January 1 4713 BC, where January 1 4713 BC is 1 in Oracle) |
| HH | Hournumber of the day (1-12) |
| HH12 | Hournumber of the day (1-12) |
| HH24 | Hournumber of the day with 24Hours notation (1-24) |
| AM | AM or PM |
| PM | AM or PM |
| MI | Number of minutes (i.e. 59) |
| SS | Number of seconds (i.e. 59) |
| SSSSS | Number of seconds this day. |
| DS | Short date format. Depends on NLS-settings. Use only with timestamp. |
| DL | Long date format. Depends on NLS-settings. Use only with timestamp. |
| E | Abbreviated era name. Valid only for calendars: Japanese Imperial, ROC Official and Thai Buddha.. (Input-only) |
| EE | The full era name |
| FF | The fractional seconds. Use with timestamp. |
| FF1..FF9 | The fractional seconds. Use with timestamp. The digit controls the number of decimal digits used for fractional seconds. |
| FM | Fill Mode: suppresses blianks in output from conversion |
| FX | Format Exact: requires exact pattern matching between data and format model. |
| IYY or IY or I the last 3,2,1 digits of the ISO standard year. Output only | |
| RM | The Roman numeral representation of the month (I .. XII) |
| RR | The last 2 digits of the year. |
| RRRR | The last 2 digits of the year when used for output. Accepts fout-digit years when used for input. |
| SCC | Century. BC dates are prefixed with a minus. |
| CC | Century |
| SP | Spelled format. Can appear of the end of a number element. The result is always in english. For example month 10 in format MMSP returns "ten" |
| SPTH | Spelled and ordinal format; 1 results in first. |
| TH | Converts a number to it's ordinal format. For example 1 becoms 1st. |
| TS | Short time format. Depends on NLS-settings. Use only with timestamp. |
| TZD | Abbreviated time zone name. ie PST. |
| TZH | Time zone hour displacement. |
| TZM | Time zone minute displacement. |
| TZR | Time zone region |
| X | Local radix character. In america this is a period (.) |
Insert entre bases de datos remotas enlazadas por dblink de Oracle
Insert entre bases de datos remotas enlazadas por dblink de Oracle cfb Tue, 08/19/2008 - 22:28Para hacer un insert con Oracle SQL desde una tabla de una base de datos TablaBD1 a otra base de datos TablaBD2 a través de un dblink debería haber dos maneras:
1- Crear el database link en la base de datos origen BD1 y hacer el insert hacia la tabla de la base de datos destino BD2 a través de este dblink
SQL en la base de datos Oracle BD1:
CREATE [PUBLIC] DATABASE LINK BD1toBD2_dblink
CONNECT TO usuario2
IDENTIFIED BY password2
USING 'BD2';
INSERT INTO TablaBD2@BD1toBD2_dblink
(SELECT * FROM TablaBD1);
* Para simplificar suponemos que las tablas tienen la misma estructura
2- Crear el database link en la base de datos destino BD2 y hacer el insert seleccionando los registros de la tabla de la base de datos origen BD1 a través de este dblink:
SQL en la base de datos Oracle BD2:
CREATE [PUBLIC] DATABASE LINK BD2toBD1_dblink
CONNECT TO usuario1
IDENTIFIED BY password1
USING 'BD1';
INSERT INTO TablaBD2
(SELECT * FROM TablaBD1@BD2toBD1_dblink);
Yo hasta ahora he utilizado siempre el SQL de la segunda opción para enlazar bases de datos Oracle, supongo que porque parece más simple utilizar un dblink para seleccionar datos de una tabla de una base de datos remota que para insertarlos remotamente. Pues parece que lo mejor es buscar las cosas simples porque he podido comprobar que la primera opción no funciona, por lo menos a mi.
He probado a hacerlo creando con SQL un dblink entre dos bases de datos Oracle 10g y la inserción no se realizaba. Lo curioso es que la sentencia SQL, en lugar de devolverme un error me devolvía un mensaje de '0 registros insertados', cuando haciendo la SELECT sí que obtenía registros.
Yo he llegado a la conclusión de que la opción de insertar datos directamente en una tabla de una base de datos Oracle remota a través de un database link no funciona, hay que hacer una SELECT desde la base de datos 'destino'. Para simplificar, la @ ha de estar en la tabla de la sentencia SQL de SELECT, no en la de INSERT.
Si alguien tiene una explicación mejor le agradecería que lo comentara, porque el tema me parece bastante curioso.
Saludos Cordiales, Tengo dos
Saludos Cordiales,
Tengo dos base de datos en Oracle 9i y necesito efectuar replicacion de datos entre ellos, ahora mismo uso DBLINK para mantener actualizada la información, pensamos cambiar a vistas materializadas, pero recientemente eschamos el STREAMS de Oracle, lo ha utilizado? podria sugerirme algunos link o información al respecto? el problema básico es que tengo una TABLA A en una DB 1 que constantemente se incrementa en el número de registros (Ocurren INSERT constantemente) y debemos actualizar la TABLA B en una BD 2. Cuando insertamos en la TABLA B cada vez que se inserte en la TABLA A se quedan conexiones abiertas que nunca se cierran y degrada el performance de la BD 1 y de la BD 2.
Puedes Ayudarnos?
Gracias de antemano
- Log in to post comments

Las vistas materializadas
Las vistas materializadas pueden ser un buena opción para gestionar esta replicación, pero si las inserciones son muy frecuentes donde vas a notar mejora, con cualquier método que utilices para refrescar, es si en lugar de actualizar cada vez que insertas en la tabla origen, lo haces de manera agrupada, seleccionando los registros que han cambiado cada cierto tiempo para hacer un sólo insert cada x tiempo en lugar de un insert/update por registro creado o modificado.
Sobre STREAMS de Oracle yo no los he utilizado nunca, así que si los pruebas y nos explicas qué tal funcionan te lo agradezco.
Sobre vistas materializadas, te enlazo un artículo que explica cómo utilizar las vistas materializadas, e incluye enlaces a la documentación oficial de Oracle, espero que te ayude.
Y si te quedan dudas, en el foro tenemos abierto un tema sobre vistas materializadas de Oracle.
Saludos,
- Log in to post comments
Hola, Muy buen aporte! Sólo
Hola, Muy buen aporte!
Sólo me queda una consulta... Haciendo el dblink éste permite que las modificaciones sean bidireccionales?
Muchas gracias!
Saludos.-
- Log in to post comments
Hola Manuel. El DBLink es
Hola Manuel.
El DBLink es para utilizarlo desde la instancia de base de datos en la que se define, y desde esta poder enlazar con otras, pero de manera unidireccional, tanto para modificaciones como para consultas.
Es decir, que desde las bases de datos que se enlazan con el database link no se puede utilizar ni se ve este mismo dblink para conectar con la primera. Para hacerlo habria que definir un nuevo dblink en la otra base de datos.
Saludos!
- Log in to post comments
Perfecto! Muchisimas gracias!
Perfecto! Muchisimas gracias!
- Log in to post comments
Amigo necesito realizar un
Amigo necesito realizar un insert desde una bd SQL Server a Oracle, como hago para ejecutar o hacer un llamado a un Stored Procedure que realice un insert en la BD Oracle desde una Bd SQL Server
- Log in to post comments
Oracle 10g: Posible optimización de volcado masivo de datos
Oracle 10g: Possible optimization in massive data dump il_masacratore Tue, 02/16/2010 - 13:592) Semantic Validation
3) Optimization
4) Generation of the QEP (Query Execution Plan)
5) Implementation of the QEP (Query Execution Plan)
Creating the necessary table for testing:
create table TEST ( NUM number (22), TEXT varchar (100) ); Loading parameters by value:
declare v_i number;
begin
loop
INSERT INTO TEST VALUES (3, '50');
v_i := v_i + 1;
exit when v_i > 1000000;
end loop;
rollback;
end;
declare v_i number;
begin
loop
execute immediate 'INSERT INTO TEST VALUES (:x, :y)' using 3, '50';
v_i := v_i + 1;
exit when v_i > 1000000;
end loop;
rollback;
end;  )
)
| ROWS | BY VALUE | WITH BIND VARIABLES |
| 10000 | 5,3350 | 0,4370 |
| 100000 | 58,5160 | 6,1000 |
| 1000000 | (A)570,1060 | (B)54,1950 |
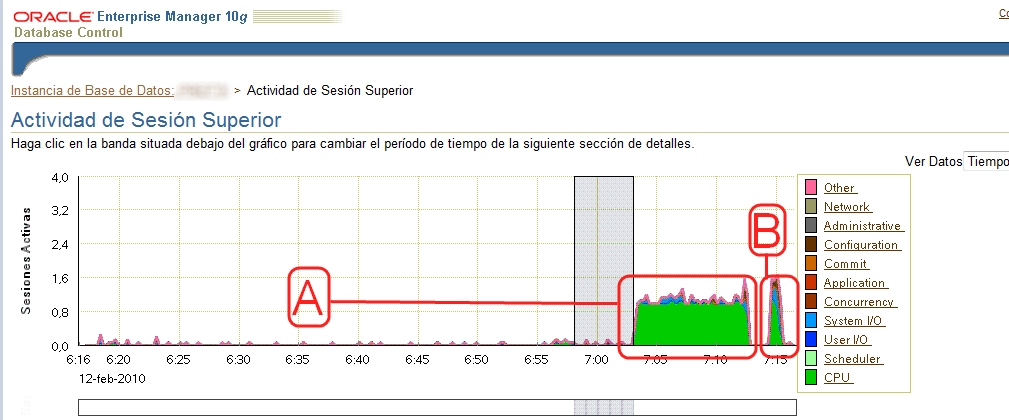
Oracle Flashback Query
Oracle Flashback Query Juan_Vidal Tue, 09/13/2011 - 09:53
Revisamos brevemente en este post la funcionalidad flashback query que aporta el gestor de BBDD de Oracle desde su versión 9i.
Básicamente se trata de un tipo de sql de Oracle que accede a datos que existían en la base de datos en un momento anterior, pero que en el momento en el que se ejecuta la sql pueden no existir o haber sufrido modificaciones. Para ello, Oracle utiliza los datos que quedan disponibles durante un tiempo en el segmento de UNDO. Este segmento, como es sabido, almacena los datos anteriores a una serie de modificaciones. Se utiliza para asegurar la consistencia en la lectura de una consulta previa a la confirmación de las modificaciones (commit) y pueden ser utilizados en una posible recuperación (rollback).
La sentencia de Oracle SQL flashback query nos permite ver datos de la tabla que han sido borrados o modificados. Ejecutando una flashback query accedemos a datos de una foto de datos consistentes en un punto determinado, especificando para ello la hora del sistema o bien el número de cambio del sistema (SCN). La base de datos debe estar configurada para trabajar en Automatic Undo Management (AUM). Para ello revisar los siguientes parámetros de la base de datos Oracle:
undo_management = auto undo_tablespace = UNDOTBS001 (tablespace que alberga el segmento de undo) undo_retention = 3600 (tiempo en segundos que tenemos retenido el dato en el segmento de undo)
Hay que tener en cuenta respecto al parámetro undo_retention que si el tablespace de UNDO no es lo suficientemente grande como para mantener ese tiempo todas las transacciones, el gestor de base de datos las va a sobreescribir. Igualmente, considerar que para poder ejecutar el comando flashback query de Oracle SQL debemos tener permisos sobre el package BDMS_FLASHBACK. Para ello:
sys> grant execute on dbms_flashback to usuario1;
Veamos un ejemplo. Supongamos que queremos realizar una consulta SQL sobre una tabla que contiene facturas de clientes y queremos acceder a los datos de un cliente que previamente hemos borrado:
sys> select to char(sysdate, ‘dd-mm-yyyy hh24:mi’) fecha_sistema from dual; fecha_sistema ------------------------- 12-09-2011 12:05 sys> delete from t_facturas where cod_cliente = ‘00125’; 4 registros borrados sys> commit;
Media hora después ejecutamos:
sys> select to char (sysdate, ‘dd-mm-yyyy hh24:mi’) fecha_sistema from dual
fecha_sistema
-------------------------
12-09-2011 12:35
sys> exec dbms_flashback.enable_at_time (to_date('12-09-2011 12:05, 'DD-MM-YYYY HH24:MI'));
sys> select to char (sysdate, ‘dd-mm-yyyy hh24:mi’) fecha_sistema from dual
fecha_sistema
-------------------------
12-09-2011 12:35
sys> exec dbms_flashback.enable_at_time (to_date(’12-09-2011 12:05, ‘DD-MM-YYYY HH24:MI’));
Procedimiento PL/SQL terminado correctamente.
sys> select * from t_facturas where cod_cliente = ‘00125’;
……
……
……
……
4 registros seleccionados.
sys> execute dbms_flasback.disable;
sys> select count(*) from t_facturas where cod_cliente = ‘00125’;
count(*)
------
0
Se puede obtener lo mismo accediendo por el número de cambio SCN:
sys> select dbms_flashback.get_system_change_number from dual; GET_SYSTEM_CHANGE_NUMBER ------------------------ 1307125 sys> exec dbms_flashback.enable_at_system_change_number(1307125); Procedimiento PL/SQL terminado correctamente
Existe también la posibilidad de emplear la sentencia ‘select ... as of...’:
sys> select * from t_facturas where cod_cliente = ‘00125’ as of timestamp to_timestamp (’12-09-2011 12:05', ‘DD-MM-YYYY HH24:MI’); sys> select * from t_facturas where cod_cliente = ‘00125’ as of scn 1307125;
Hay que tener en cuenta que mientras la sesión está en el modo Flashback Query, solo podemos ejecutar sentencias SELECT. Las sentencias SQL de actualización (insert, delete y update) no están permitidas.
En el trabajo diario con esta opción es útil el uso de tablas temporales para trabajar con los datos recuperados:
sys> create table t_facturas_ant as (select * from t_facturas where cod_cliente = ‘00125’ as of timestamp to_timestamp (’12-09-2011 12:05, ‘DD-MM-YYYY HH24:MI’);
Otras opciones Flashback Query
A continuación listamos algunas funcionalidades que aporta Oracle relacionadas con operaciones Flashback Query:
- Flashback Version Query: Acceso al histórico de cambios de una tabla.
- Flashback Transaction Query: Acceso al histórico de cambios de una transacción determinada.
- Flashback Table: Acceso a datos anteriores, pero para una única tabla.
- Flashback Drop: Recuperar una tabla borrada (‘papelera reciclaje’).
- Flashback Database: Permite dejar la BBDD tal y como se encontraba en un tiempo pasado. Similar a restaurar un backup, pero con las limitaciones temporales de los procesos flashback, aunque mucho más rápido que recuperar la copia del backup. Es necesario tener el modo flashback activado, así como la flash recovery area.
Algunas de estas opciones requieren que el gestor sea 'Enterprise Edition'.
Se trata, como se ha dicho, de una sentencia de Oracle SQL bastante útil, con múltiples opciones de “rebobinado” y que nos puede sacar de más de un apuro.
Recopilación scripts y consultas útiles de Oracle
Useful Oracle SQL queries and scripts Carlos Tue, 05/20/2008 - 00:06Don't you have a chop with useful queries to use in your daily adventures and desventures with the database?
I include in this first post a list of queries, most of them over Oracle metadata dictionary, and extracted from the site Cibermanuales.com.
I encourage everyone that has his own useful queries or scripts to share it answering to this post. The objective is to create a little online repository that we could consult when we are working with the database.
•• Oracle SQL query over the view that shows database state: select * from v$instance
•• Oracle SQL query that shows if database is opened select status from v$instance
•• Oracle SQL query over the view that show Oracle database general parameters select * from v$system_parameter
•• Oracle SQL query to know Oracle version select value from v$system_parameter where name = 'compatible'
•• Oracle SQL query to know the path and name of spfile select value from v$system_parameter where name = 'spfile'
•• Oracle SQL query to know the localization and number of control files select value from v$system_parameter where name = 'control_files'
•• Oracle SQL query to show the database name. select value from v$system_parameter where name = 'db_name'
•• Oracle SQL query over the view that shows actual Oracle conections. •• To use it the user need administrator privileges.select osuser, username, machine, program from v$session order by osuser
•• Oracle SQL query that show the opened conections group by the program that opens the connection. select program Aplicacion, count(program) Numero_Sesiones from v$session group by program order by Numero_Sesiones desc
•• Oracle SQL query that shows Oracle users connected and the sessions number for user select username Usuario_Oracle, count(username) Numero_Sesiones from v$session group by username order by Numero_Sesiones desc
•• Objects owners number of objects for owner select owner, count(owner) Numero from dba_objects group by owner order by Numero desc
•• Oracle SQL query over the data Dictionary (includes all views and tables of the database) select * from dictionary
•• Oracle SQL query that shows definition data from a specific table •• (in this case, all tables with string "XXX") select * from ALL_ALL_TABLES where upper(table_name) like '%XXX%'
•• Oracle SQL query to know tables from actual user select * from user_tables
•• Oracle SQL query to know all the objects of the connected user select * from user_catalog
•• Oracle SQL query for Oracle DBA that shows tablespaces, disk used, free space and datafiles: SELECT t.tablespace_name "Tablespace", t.status "Estado", ROUND(MAX(d.bytes)/1024/1024,2) "MB Tamaño", ROUND((MAX(d.bytes)/1024/1024) - (SUM(decode(f.bytes, NULL,0, f.bytes))/1024/1024),2) "MB Usados", ROUND(SUM(decode(f.bytes, NULL,0, f.bytes))/1024/1024,2) "MB Libres", t.pct_increase "% incremento", SUBSTR(d.file_name,1,80) "Fichero de datos"FROM DBA_FREE_SPACE f, DBA_DATA_FILES d, DBA_TABLESPACES tWHERE t.tablespace_name = d.tablespace_name AND f.tablespace_name(+) = d.tablespace_name AND f.file_id(+) = d.file_id GROUP BY t.tablespace_name, d.file_name, t.pct_increase, t.status ORDER BY 1,3 DESC
•• Oracle SQL query to know Oracle products installed and version number. select * from product_component_version
•• Oracle SQL query to know roles and roles privileges select * from role_sys_privs
•• Oracle SQL query to know integrity rules select constraint_name, column_name from sys.all_cons_columns
•• Oracle SQL query to know tables owned by a user, in this case "xxx":SELECT table_owner, table_name from sys.all_synonyms where table_owner like 'xxx'
•• Oracle SQL query for the same as last query SELECT DISTINCT TABLE_NAME FROM ALL_ALL_TABLES WHERE OWNER LIKE 'HR' •• Oracle parameters, actual value and its description. SELECT v.name, v.value value, decode(ISSYS_MODIFIABLE, 'DEFERRED', 'TRUE', 'FALSE') ISSYS_MODIFIABLE, decode(v.isDefault, 'TRUE', 'YES', 'FALSE', 'NO') "DEFAULT", DECODE(ISSES_MODIFIABLE, 'IMMEDIATE', 'YES','FALSE', 'NO', 'DEFERRED', 'NO', 'YES') SES_MODIFIABLE, DECODE(ISSYS_MODIFIABLE, 'IMMEDIATE', 'YES', 'FALSE', 'NO', 'DEFERRED', 'YES','YES') SYS_MODIFIABLE , v.description FROM V$PARAMETER v WHERE name not like 'nls%' ORDER BY 1
•• Oracle SQL query that shows Oracle users and his data Select * FROM dba_users
•• Oracle SQL query to know tablespaces and its owner: select owner, decode(partition_name, null, segment_name, segment_name || ':' || partition_name) name, segment_type, tablespace_name,bytes,initial_extent, next_extent, PCT_INCREASE, extents, max_extents from dba_segments Where 1=1 And extents > 1 order by 9 desc, 3
•• Last SQL queries executed on Oracle and user: select distinct vs.sql_text, vs.sharable_mem, vs.persistent_mem, vs.runtime_mem, vs.sorts, vs.executions, vs.parse_calls, vs.module, vs.buffer_gets, vs.disk_reads, vs.version_count, vs.users_opening, vs.loads, to_char(to_date(vs.first_load_time, 'YYYY-MM-DD/HH24:MI:SS'),'MM/DD HH24:MI:SS') first_load_time, rawtohex(vs.address) address, vs.hash_value hash_value , rows_processed , vs.command_type, vs.parsing_user_id , OPTIMIZER_MODE , au.USERNAME parseuser from v$sqlarea vs , all_users au where (parsing_user_id != 0) AND (au.user_id(+)=vs.parsing_user_id) and (executions >= 1) order by buffer_gets/executions desc
•• Oracle SQL query to know all the tablespaces: select * from V$TABLESPACE
•• Oracle SQL query to know free and used Shared_Pool
select name,to_number(value) bytes
from v$parameter where name ='shared_pool_size'
union all
select name,bytes
from v$sgastat where pool = 'shared pool' and name = 'free memory'
Cursores abiertos por usuario
select b.sid, a.username, b.value Cursores_Abiertos
from v$session a,
v$sesstat b,
v$statname c
where c.name in ('opened cursors current')
and b.statistic# = c.statistic#
and a.sid = b.sid
and a.username is not null
and b.value >0
order by 3
•• Oracle SQL query to know cache hits (it must be more than 1%)
select sum(pins) Ejecuciones, sum(reloads) Fallos_cache,
trunc(sum(reloads)/sum(pins)*100,2) Porcentaje_aciertos
from v$librarycache
where namespace in ('TABLE/PROCEDURE','SQL AREA','BODY','TRIGGER');•• Complete SQL queries executed with a specific text in SQL sentence. SELECT c.sid, d.piece, c.serial#, c.username, d.sql_text FROM v$session c, v$sqltext d WHERE c.sql_hash_value = d.hash_value and upper(d.sql_text) like '%WHERE CAMPO LIKE%' ORDER BY c.sid, d.piece
•• A SQL query (filtered by sid) SELECT c.sid, d.piece, c.serial#, c.username, d.sql_text FROM v$session c, v$sqltext d WHERE c.sql_hash_value = d.hash_value and sid = 105 ORDER BY c.sid, d.piece
•• Oracle SQL query to know the database size select sum(BYTES)/1024/1024 MB from DBA_EXTENTS
•• Oracle SQL query to calculate the size of the database data files select sum(bytes)/1024/1024 MB from dba_data_files
•• Oracle SQL query to calculate the size of a concrete table excluding the indexes select sum(bytes)/1024/1024 MB from user_segments where segment_type='TABLE' and segment_name='TABLENAME'
•• Oracle SQL query to calculate the size of a concrete table including the indexes
select sum(bytes)/1024/1024 Table_Allocation_MB from user_segments
where segment_type in ('TABLE','INDEX') and
(segment_name='TABLENAME'or segment_name in
(select index_name from user_indexes where table_name='TABLENAME'))
•• Oracle SQL query to know the memory used by a column in a table
select sum(vsize('COLUMNNAME'))/1024/1024 MB from 'TABLENAME'•• Oracle SQL query to calculate memory used by a user SELECT owner, SUM(BYTES)/1024/1024 MB FROM DBA_EXTENTS group by owner
•• Oracle SQL query to calculate size from the diferent segments •• (tables, indexes, undo, rollback, cluster, ...) SELECT SEGMENT_TYPE, SUM(BYTES)/1024/1024 MB FROM DBA_EXTENTS group by SEGMENT_TYPE
•• Oracle SQL query to obtain all the Oracle functions: NVL, ABS, LTRIM, ... SELECT distinct object_name FROM all_arguments WHERE package_name = 'STANDARD' order by object_name
•• Oracle SQL query to calculate the size of all the database objects, ordering from more to less SELECT SEGMENT_NAME, SUM(BYTES)/1024/1024 MB FROM DBA_EXTENTS group by SEGMENT_NAME order by 2 desc
SSRS: #Error en una celda de importe decimal de reporte utiliza Oracle SQL
SSRS: #Error en una celda de importe decimal de reporte utiliza Oracle SQL il_masacratore Wed, 04/27/2011 - 16:41Hasta el momento desconozco exactamente como o donde se detalla cada tipo de error en la ejecución de un informe de reporting services de Microsoft SQL Server. He tratado con derivados de falta de permisos, procesados incompletos de cubos pero hasta ahora ningun #Error en una celda por que sí.
El error en cuestión me aparece en la ejecución de un pequeño informe que tira de un origen de datos ODBC contra una base de datos Oracle donde se muestran totales (sumas, no porcentajes) y me ha sorprendido mucho la falta de detalle sobre el error que se produce. Para más dificultad, encima es en una combinación de parámetros concreta (las n ejecuciones anteriores han funcionado) y no en toda la columna sino en una celda. Además arrastra todo subtotal o total en el que se incluya...
Después de mirar el log del servidor de Reporting Services, después de comprobar la consulta en un cliente externo con la misma, tras pensar mal del formato me da por comprobar en el diseñador de informes el origen de datos, me hago una prueba con parámetros al tuntun y bien, pero al poner los valores problemáticos consigo que se al menos aparezca el error:
Error al leer datos del conjunto de resultados de la consulta. OCI-22053: error de desbordamiento.Pues nada, encontrado esto ya estoy más feliz ya que el error es que ado.net+oracle+odbc no lleva muy bien los números de 38 digitos...
Para esto podemos hacer un workaround que consiste en usar en la consulta la función trunc(número, decimales) de Oracle SQL para que nos trunque el valor en su parte decimal donde nosotros decidamos.
Traducción de terminología Oracle - DB2 LUW
Translation of terminology Oracle - DB2 LUW Oscar_paredes Sat, 06/18/2011 - 17:11With 9.7 DB2 LUW version, IBM makes a nod to all Oracle DBAs, much more numerous in the DB2 market.
For this reason, 9.7 version has introduced Oracle compatibility modes that let you perform tasks in DB2 with the ease and knowledge that all Oracle DBAs have. However, it is important to know the terminology's translation between Oracle and DB2 if you intend to get into the DB2 world.
In this first article, I relate a number of items from which this introduction is simple and can be read DB2 documentation easily, including general terminology, updates, utilities, and views.
| GENERAL COMPONENTS | |
| ORACLE | DB2 LUW |
| Instance | Instance |
| File/Datafile | Container |
| Database | Database |
| Tablespace | Tablespace |
| Schema | Schema |
| Table | Table |
| Index | Index |
| View | View |
| Trigger | Trigger |
| Packages | Modules |
| Stored Procedures | Stored Procedures |
| SQL Plus | DB2 CLP |
| Data Block | Data Page |
| Dictionary | Catalog |
| Alert Log | Diag log |
| Redo Log | Log File |
| Segments | Space Consumming Objects |
| SGA | Instance/DB Shared Memory |
| CATALOG VIEWS | |
| ORACLE | DB2 LUW |
|
ALL_ |
SYSIBM.* SYSSTAT.* SYSCAT.* |
| UTILITIES | |
| ORACLE | DB2 LUW |
| RMAN IMPORT EXPORT SQL*loader DB_VERIFY ANALYZE |
BACKUP IMPORT EXPORT LOAD RESTORE REORG REORGCHK RUNSTATS |
| VERSIONS | |
| ORACLE | DB2 LUW |
| EXPRESS EDITION | EXPRESS-C |
| STANDARD EDITION ONE | EXPRESS EDITION |
| STANDARD EDITION | WORKGROUP EDITION |
| ENTERPRISE EDITION | ENTERPRISE SERVER EDITION |
I hope you find it useful.
Oscar Paredes
UPDATE con JOIN en ORACLE SQL
UPDATE con JOIN en ORACLE SQL hminguet Tue, 07/08/2008 - 10:16Supongamos que queremos actualizar en nuestra base de datos ORACLE el campo de costes de la tabla de hechos FAC_TABLE con el coste unitario de nuestra tabla de COSTES.
Con Oracle SQL podemos hacerlo de dos maneras:
- Consulta Lenta, pero si es para pocos datos o para lanzarlo esporádicamente nos puede valer
update FAC_TABLE ft set COSTE_UNITARIO =
(select distinct COSTE_UNITARIO
from COSTES ct
where (ft.id_articulo = ct.id_articulo);
- La mejor manera es esta, y el rendimimento es óptimo si tiene constraints)
UPDATE (SELECT ft.COSTE_UNITARIO AS old_coste,
ct.COSTE_UNITARIO AS new_coste
FROM FAC_TABLE ft INNER JOIN COSTES ct ON ft.id_articulo = ct.id_articulo)
) SET old_coste = new_coste;Para que esta segunda opción funcione necesitamos tener UNIQUE or PRIMARY KEY constraint en ct.id_articulo.
Si no tienes esta constraint, puedes utilizar el hint /*+BYPASS_UJVC*/ después de la palabra UPDATE (bypass update join view constraint).
El rendimiento aumenta si tenemos la constraint pero aún sin ella debe correr mucho más que la primera opción.
Espero que os ayude.
Héctor Minguet.
Pruebas del UPDATE con JOIN
He tenido la oportunidad de probar este tipo de update con tablas grandes, de varios millones de registros, y realmente funciona como comentas.
He lanzado un update con la primera opción y he decidido cancelarlo cuando he visto que comenzaba a afectar negativamente al rendimiento de la base de datos. El tiempo estimado que me daba la consola de Enterprise Manager para terminar era de 1 hora y media.
Después de cancelar he probado la segunda opción y me he encontrado con el error ORA-01779 porque no tenía una clave única definida sobre el campo de la tabla con la que hacía la join. Como la tabla era demasiado grande para crear un índice único sin estudiarlo primero, he probado la opción de incluir el hint /*+BYPASS_UJVC*/ (para hacer esto hay que asegurarse antes de que la correspondencia es realmente de 1:1, si no podemos obtener resultados inesperados), y el update se ha realizado correctamente en menos de 15 minutos, una diferencia considerable.
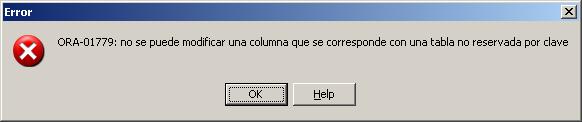
Ahora a ver si alguien se anima y nos cuenta la mejora que se obtiene con la segunda opción, pero creando una clave única en la tabla 'enlazada', y sin utilizar el hint.
- Log in to post comments
Hola se agradece este
Hola se agradece este bypass.
Justamente tenía que actualizar unas tablas que tenian correlativos repetidos y tenian que ser secuenciales, realicé una tabla temporal y despues aplicar un update. De igual forma tenia que hacer un procedimiento almacenado pero en fin... con este bypass, todo bien.
El tiempo de respuesta en la actualizacion el descuebe GRACIAS!!!
gracias.
atte.
Maricela de CHILE
- Log in to post comments
Gracias. Lo utilice para una
Gracias.
Lo utilice para una actualizacion de varios campos y se comporto de maravilla.
- Log in to post comments
Utilice un script con este
Utilice un script con este hint /*+BYPASS_UJVC*/ y funciona una muy bien... Bajo un script de 9 hs a 6 segungos....
Pero cuando lo quiero utilizar dentro de un Package aparece un error "PL/SQL: ORA-01031: Insufficient privileges"
¿ALGUIEN PUEDE AYUDARME CON ESTE TEMA?
DESDE YA MUCHAS GRACIAS.
- Log in to post comments
Bueno lo mas probable es que
Bueno lo mas probable es que sea esto, mira una cosa son los permisos que tienes tu o tu usario y otra los permisos que tiene el paquete por ejemplo digamos que tu tienes el usuario au0001 y cuando corres esto si puedes hacerlo debido a tus permisos, pero cuando pones esto dentro del paquete que esta en el esquema au0002 y dicho esquema no tiene esos priviliegios, pues es claro que te truena aun si tu como usuario au0001 si tengas el permiso y seas tu el que corre el paquete , el paquete truena por ser el o su esquema mejor dicho el que no tiene los permisos.
- Log in to post comments
Hola intente hacerlo de las
Hola intente hacerlo de las dos maneras, el update tradicional y con el hint, con el primero se tarda bastante, lo cancele, con el segundo me marca el error ORA-01031 - Insufficient privileges, lo estoy haciendo en el mismo esquema, la tabla de la que quiero actualizar tiene llave unique en el campo que uso para unir con la tabla que tiene la información ¿A que se debe que con uno no me marque el error y con el segundo si?
- Log in to post comments
¡¡¡ UPS !!! Perdón. Gracias
¡¡¡ UPS !!! Perdón. Gracias por la ayuda.
- Log in to post comments
Muchisimas gracias por tu
- Log in to post comments
Me ha servido su update con
- Log in to post comments
La explicación es muy buena y
La explicación es muy buena y me ha servido en varios proyectos cuando la base de datos es Oracle 10g, sin embargo en Oracle 11g el hint ha desaparecido y no se puede utilizar, he leído algo acerca del tema y en todos lados lo que dice es que debo cambiar la instrucción y no utilizar más el hint bypass_ujvc.
¿Como han hecho para mitigar la eliminación del hint? ¿Es correcto mejor hacerlo por merge?
Gracias!
- Log in to post comments
Pues sí, si a partir de la
Pues sí, si a partir de la versión 11g R2 el HINT BYPASS_UJVC ya no es válido porque Oracle lo ha dejado como deprecated hay que dejar de utilizarlo, y además hay que tenerlo en cuenta en upgrades o migraciones desde versiones anteriores, ya que si se utilizaba este HINT en versiones anteriores a la 11g, al lanzar las queries que contengan el hint BYPASS_UJVC el analizador devolverá un error y la query fallará.
Una buena alternativa, tal como ya apuntas, es utilizar un MERGE para este tipo de operaciones en que se haya recurrido al HINT al no disponer de una clave primaria para el campo por el que se hace la join de la SELECT del UPDATE, aunque si se puede conseguir la clave primaria o única para ese campo, seguramente el UPDATE será más rápido.
Al utilizar el MERGE, hay que asegurarse igualmente de que la JOIN entre tabla origen y destino sea INNER, que no existan duplicados en las tablas para esos registros, porque entonces podemos encontrarnos el error ORA-30926, o efectos inesperados en los resultados. Si se diera el caso, habría que anular los duplicados eliminándolos antes de hacer la join, o modificando la query añadiendo un group by para aplicar un SUM, MAX, MIN u otra operación sobre el campo con valores duplicados.
Libros de Administración Oracle (DBA) y PL/SQL
¿Quieres profundizar más en PL/SQL de Oracle o en administración de bases de datos Oracle? Puedes hacerlo consultando alguno de estos libros de Oracle.
- Log in to post comments
Hola! Necesito algo de ayuda
Hola!
Necesito algo de ayuda con un Update de toda una columna..
La idea es actualizar la columna reintegro de la tabla tarjeta, la cual está relacionada con otras tablas (empresa, certificado,persona,institucion) donde ley=S de la tabla institucion
Les comento las consultas que he realizado sin éxito:
================== update tarjeta set reintegro ='0' where (select reintegro, ley_anterior from tarjeta , institucion where ley='S') ================== ================== Update tarjeta SET reintegro= '0' INNER JOIN empresa on tar_emp_codigo = empcodigo INNER JOIN certificado on empcodigo = cem_empcodigo INNER JOIN persona on per_documento = cem_perdocumento INNER JOIN institucion on per_inscodigo = inscodigo WHERE (ley='S') ==================
Me podrían ayudar?
Gracias
- Log in to post comments
Hola buenas tardes, no se si
- Log in to post comments
Hola, me ha sido muy útil
- Log in to post comments
Vistas materializadas de Oracle para optimizar un Datawarehouse
Vistas materializadas de Oracle para optimizar un Datawarehouse Carlos Wed, 08/13/2008 - 09:21Como las cargas de un Data warehouse se realizan de manera periódica, y además es habitual la creación de tablas agregadas para mejorar la eficiencia y tiempo de respuesta de nuestros informes, un recurso de optimización física que puede aportar grandes mejoras es la utilización de vistas materializadas.
Qué es una vista materializada
La vista materializada no es más que una vista, definida con una sentencia SQL de Oracle, de la que además de almacenar su definición, se almacenan los datos que retorna, realizando una carga inicial y después cada cierto tiempo un refresco de los mismos.

Así, si tenemos un Datawarehouse que se actualiza diariamente, podríamos utilizar vistas materializadas para ir actualizando tablas intermedias que alimenten nuestros esquemas de DWH, o directamente para implementar tablas agregadas que se refrescarán a partir de nuestras tablas base.
La creación de este tipo de vistas con Oracle SQL no es tan compleja como puede parecer, lo más importante es tener claro cada cuánto tiempo queremos actualizar la información de las vistas, y qué método de refresco utilizar.
También tendremos que asegurarnos de que nuestra licencia de base de datos nos permite utilizarlas (ha de ser una versión Enterprise).
Sintaxis básica de Oracle SQL para la creación de una vista materializada
CREATE MATERIALIZED VIEW mi_vista_materializada
[TABLESPACE mi_tablespace]
[BUILD {IMMEDIATE | DEFERRED}]
[REFRESH {ON COMMIT | ON DEMAND | [START WITH fecha_inicio] NEXT fecha_intervalo } |
{COMPLETE | FAST | FORCE} ]
[{ENABLE|DISABLE} QUERY REWRITE] AS
SELECT t1.campo1, t2.campo2
FROM mi_tabla1 t1 , mi_tabla2 t2
WHERE t1.campo_fk = t2.campo_pk AND …
Comentarios sobre las diferentes opciones de la sentencia Oracle SQL de creación de la vista:
-
Carga de datos en la vista
BUILD IMMEDIATE:
Los datos de la vista se cargan en el mismo momento de la creación
BUILD DEFERRED:
Sólo se crea la definición, los datos se cargarán más adelante. Para realizar esta carga se puede utilizar la función REFRESH del package DBMS_MVIEW:
begin
dbms_mview.refresh('mi_vista_materializada');
end;
-
Método y temporalidad del refresco de los datos
Cada cuánto tiempo se refrescarán:
REFRESH ON COMMIT:
Cada vez que se haga un commit en los objetos origin definidos en la select
REFRESH ON DEMAND:
Como con la opción DEFERRED del BUILD, se utilizarán los procedures REFRESH, REFRESH_ALL_MVIEWS o REFRESH_DEPENDENT del package DBMS_MVIEW
REFRESH [START WITH fecha_inicio] NEXT fecha_intervalo:
START WITH indica la fecha del primer refresco (fecha_inicio suele ser un SYSDATE)
NEXT indica cada cuánto tiempo se actualizará (fecha_intervalo podría ser SYSDATE +1 para realizar el refresco una vez al día)
-
De qué manera se refrescarán
REFRESH COMPLETE:
El refresco se hará de todos los datos de la vista materializada, la recreará completamente cada vez que se lance el refresco
REFRESH FAST:
El refresco será incremental, es la opción más recomendable, lo de fast ya da una idea del porqué.
Este tipo de refresco tiene bastantes restricciones según el tipo de vista que se esté creando.
Se pueden consultar en General Restrictions on Fast Refresh de la documentación oficial de Oracle
Una de las cosas importantes a tener en cuenta es que para poder utilizar este método casi siempre es necesario haber creado antes un LOG de la Vista materializada, indicando los campos clave en los que se basará el mantenimiento de la vista.
Se utiliza la instrucción de Oracle SQL "CREATE MATERIALIZED VIEW LOG ON":
CREATE MATERIALIZED VIEW LOG ON mi_tabla_origen WITH PRIMARY KEY INCLUDING NEW VALUES;
REFRESH FORCE:
Con esta opción se indica que si es posible se utilice el metodo FAST, y si no el COMPLETE.
Para saber si una vista materializada puede utilizar el método FAST, el package DBMS_MVIEW proporciona el procedure EXPLAIN_MVIEW
-
Activación de la reescritura de consultas para optimizar el Data warehouse
ENABLE QUERY REWRITE:
Se permite a la base de datos la reescritura de consultas
DISABLE QUERY REWRITE:
Se desactiva la reescritura de consultas
La opción QUERY REWRITE es la que más vamos a utilizar si queremos las vistas materializadas para optimizar nuestro Data warehouse.
Esta opción permite crear tablas agregadas en forma de vistas materializadas, y que cuando se lance una SELECT la base de datos pueda reescribirla para consultar la tabla o vista que vaya a devolver los datos solicitados en menos tiempo, todo de manera totalmente transparente al usuario
Lo único que hay que hacer es crear las tablas agregadas como vistas materializadas con QUERY REWRITE habilitado.
Ejemplos de vistas materializadas de Oracle
Son muchas combinaciones, pero la sentencia final no es tan compleja.
Primer paso de la ETL de un Data warehouse
Si quisiéramos crear con SQL de Oracle una vista materializada de una tabla que se refresque un día a la semana, y de manera incremental haríamos lo siguiente:
CREATE MATERIALIZED VIEW LOG ON mi_tabla_origen WITH PRIMARY KEY INCLUDING NEW VALUES; CREATE MATERIALIZED VIEW mi_vista_materializada REFRESH FAST NEXT SYSDATE + 7 AS SELECT campo1, campo2, campo8 FROM mi_tabla_origen WHERE campo2 > 5000;
Esta vista podría servirnos para alimentar la carga de un Data Mart que se realizara semanalmente. Podríamos programarla para que se refrescara justo antes del inicio del proceso de carga, o como primer paso en la ETL, y ya tendríamos los datos necesarios actualizados, e independientes del origen de datos (no tendríamos que molestar más al operacional). Otra ventaja a tener en cuenta es que si hay algún problema con el acceso a los datos de origen, si no los hemos eliminado, en la vista materializada aún tendremos los datos del último refresco, con lo que aunque el refresco fallara no nos encontraríamos un error que truncara la carga de nuestro Data Warehouse, o una tabla vacía.
Por supuesto, en las condiciones del WHERE de la sentencia SQL de creación podríamos seleccionar sólo los registros necesarios, sólo los del último mes, etc.
Tablas agregadas para optimizar el Data Warehouse
Otro ejemplo importante sería la utilización de vistas materializadas para la creación de tablas agregadas.
-- Oracle SQL para crear agregadas con materilized views CREATE MATERIALIZED VIEW ventas_agregadas_mv BUILD IMMEDIATE REFRESH COMPLETE ENABLE QUERY REWRITE AS SELECT id_producto, sum(importe) total_ventas FROM ventas GROUP BY id_producto;
Con esta sencilla sentencia de Oracle SQL se crearía una tabla agregada de total de ventas por producto de una supuesta tabla de ventas que seria la tabla de hechos.
A nivel de sesión también habría que asegurarse de que la opción QUERY_REWRITE estuviera activada. Por si acaso, desde SQL Plus, se puede habilitar con la sentencia SQL:
SQL> ALTER SESSION SET QUERY_REWRITE_ENABLED=TRUE;
Si ahora dentro de esta sesión se ejecuta la sentencia SQL
SQL> SELECT sum(importe)
FROM ventas;la base de datos preparará el plan de ejecución teniendo en cuenta la vista materializada creada e internamente realizará la selección sobre la vista ventas_agregadas_mv.
Una manera sencilla de comprobarlo, aparte de examinar el plan de ejecución, o de comparar tiempos antes y después de la creación de la vista, o desactivando el QUERY_REWRITE, es comprobar que esta query SQL devuelve resultados en el mismo tiempo que la query
SELECT sum(importe) FROM ventas_agregadas_mv;
Para consultar más detalles, o la sintaxis SQL completa de la creación de vistas materializadas Oracle, el capítulo Create Materialized View del manual de referencia SQL de Oracle es un buen recurso.
Con Oracle Enterprise Manager (OEM), o con la consola web de la base de datos también se pueden crear las vistas materializadas de una manera más asistida, pero igualmente es importante tener claros los conceptos antes de hacerlo.
Libros de Administración Oracle (DBA) y PL/SQL
¿Quieres profundizar más en PL/SQL de Oracle o en administración de bases de datos Oracle? Puedes hacerlo consultando alguno de estos libros de Oracle.
Los libros que ves a continuación son una selección de los que a mi me parecen más interesantes para aprender administración y desarrollo PL/SQL, teniendo en cuenta precio y temática, espero que te puedan ser de utilidad:
- eBooks de Oracle gratuítos para la versión Kindle, o muy baratos (menos de 4€):
Adjunto procedimiento
Submitted by Anonim. (not verified) on Mon, 07/19/2010 - 02:11
Adjunto procedimiento completo de PL/SQL de Oracle al que se le adicionan 3 campos: periodo que no es relevante, fecha de corte que es el ultimo dia del trimestre de la fecha, la fecha de corte anterior que es la fecha del anterior trimestre.
Espero les sirva.
CREATE OR REPLACE PROCEDURE CARGADIMTIEMPO IS
tmpVar NUMBER;
FechaDesde date;
FechaHasta date;
FechaDesdeStr VARCHAR2(8);
err_num NUMBER;
err_msg VARCHAR2(255);
BEGIN
tmpVar := 0;
FechaDesde := TO_DATE('19941231','YYYYMMDD');
FechaHasta := TO_DATE('20181231','YYYYMMDD');
WHILE FechaDesde <= FechaHasta LOOP
FechaDesdeStr := to_char( FechaDesde, 'YYYYMMDD') ;
INSERT INTO DIM_TIEMPO
(
FechaSK,
Fecha,
Año,
Trimestre,
Mes,
Semana,
Dia,
DiaSemana,
NTrimestre,
NMes,
NMes3L,
NSemana,
NDia,
NDiaSemana,
Periodo,
FechaCorte,
FechaCorteAnt
)
VALUES
(
to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD') ,'YYYYMMDD'),
FechaDesde,
to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'YYYY'),
to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'), 'Q'),
to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'MM'),
to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'WW'),
to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'DD'),
to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'D'),
'T'||to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'), 'Q')||'/'||to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'YY'),
to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'MONTH'),
to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'MON'),
'Sem '||to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'WW')||'/'||to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'YY'),
to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'DD MON'),
to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'DAY'),
CASE
WHEN to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'), 'Q') = 1 THEN 3
WHEN to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'), 'Q') = 2 THEN 6
WHEN to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'), 'Q') = 3 THEN 9
WHEN to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'), 'Q') = 4 THEN 12
END,
CASE
WHEN to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'), 'Q') = 1 THEN TO_DATE('31/03/' || to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'YYYY'), 'DD/MM/YYYY')
WHEN to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'), 'Q') = 2 THEN TO_DATE('30/06/' || to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'YYYY'), 'DD/MM/YYYY')
WHEN to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'), 'Q') = 3 THEN TO_DATE('30/09/' || to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'YYYY'), 'DD/MM/YYYY')
WHEN to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'), 'Q') = 4 THEN TO_DATE('31/12/' || to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'YYYY'), 'DD/MM/YYYY')
END,
CASE
WHEN to_char(to_date(FechaDesdeStr,'YYYYMMDD'), 'Q') = 1 THEN TO_DATE('31/12/' || to_char(to_number(to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'YYYY'))-1), 'DD/MM/YYYY')
WHEN to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'), 'Q') = 2 THEN TO_DATE('31/03/' || to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'YYYY'), 'DD/MM/YYYY')
WHEN to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'), 'Q') = 3 THEN TO_DATE('30/06/' || to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'YYYY'), 'DD/MM/YYYY')
WHEN to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'), 'Q') = 4 THEN TO_DATE('30/09/' || to_char(TO_DATE( FechaDesdeStr,'YYYYMMDD'),'YYYY'), 'DD/MM/YYYY')
END
);
-- Incremento del bucle
commit ;
FechaDesde := FechaDesde + 1;
END LOOP;
EXCEPTION
WHEN NO_DATA_FOUND THEN
NULL;
WHEN OTHERS THEN
-- Consider logging the error and then re-raise
err_num := SQLCODE;
err_msg := SQLERRM;
DBMS_OUTPUT.put_line('Error Problemas :'||TO_CHAR(err_num) || ' ' || err_msg );
DBMS_OUTPUT.put_line(err_msg);
END CARGADIMTIEMPO;
Gracias por la aportación de
Submitted by Carlos on Mon, 07/19/2010 - 11:05
In reply to Adjunto procedimiento by Anonim. (not verified)
Gracias por la aportación de esta ampliación :)