
Informatica Intelligent Data Management es una plataforma integral diseñada para abordar de forma unificada todos los aspectos del ciclo de vida de los datos en la empresa. En su núcleo, combina capacidades de catálogo de metadatos, descubrimiento automático de datos y mapeo de linaje, lo que permite a las organizaciones entender de dónde provienen sus datos, cómo se transforman y en qué sistemas se consumen. Gracias a su arquitectura modular, puede escalar desde implementaciones locales hasta entornos híbridos o en la nube, adaptándose a infraestructuras de cualquier tamaño y complejidad.
La solución de gobernanza de datos de Informatica se articula en torno a varios componentes clave: el catálogo empresarial (Enterprise Data Catalog) que indexa y clasifica activos de datos tanto estructurados como no estructurados; el repositorio de gobernanza (Axon Data Governance), que facilita políticas colaborativas, reglas de negocio y el seguimiento del cumplimiento normativo; y las herramientas de calidad de datos (Data Quality) que evalúan y aseguran la confiabilidad de la información. Estos módulos trabajan de manera nativa integrada, con flujos de trabajo que permiten desde la creación de glosarios empresariales hasta la automatización de sanciones y la generación de informes de auditoría.
Para simplificar la adopción, Informatica ofrece una interfaz web basada en estándares modernos que sirve a perfiles técnicos y de negocio, con vistas adaptadas según el rol del usuario. Además, dispone de APIs y conectores preconstruidos para interoperar con plataformas de BI, data lakes, sistemas transaccionales y herramientas de machine learning. Gracias a estas capacidades, los equipos multidisciplinares pueden colaborar en tiempo real, reducir silos de información y acelerar proyectos de analítica y compliance, garantizando la gobernanza efectiva de los datos a lo largo de toda la organización.
Funcionalidades principales
Catálogo de metadatos y descubrimiento
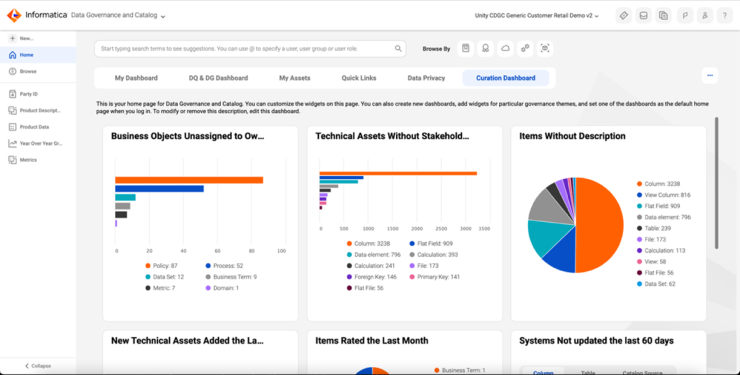
Permite inventariar de manera automática y centralizada todos los activos de datos, tanto estructurados como no estructurados. Emplea crawlers y analizadores inteligentes para identificar diferentes orígenes —bases de datos, ficheros planos, servicios en la nube— y extrae metadatos técnicos y de negocio. Ofrece facetas de búsqueda avanzadas, filtrado por etiquetas y perfiles personalizados, lo que facilita localizar información relevante en segundos. Esto acelera proyectos de analítica y ciencia de datos al reducir el tiempo dedicado a entender el contexto y la procedencia de los datos. Además, incorpora capacidades de aprendizaje continuo que ajustan las clasificaciones a medida que evolucionan los repositorios.
Gobernanza colaborativa y definición de políticas
Proporciona un entorno colaborativo donde roles de negocio, técnicos y cumplimiento trabajan sobre un mismo panel. Las políticas de datos, reglas de negocio y glosarios se definen de forma gráfica mediante flujos de trabajo que incluyen aprobaciones, comentarios y notificaciones automáticas. Cualquier cambio queda registrado en un historial de auditoría, garantizando trazabilidad y responsabilidad. Los responsables de datos pueden asignar supervisores de políticas y delegar tareas de revisión, lo que asegura que las normativas internas o regulatorias se apliquen de forma homogénea en toda la organización.
Calidad de datos
Ofrece mecanismos de perfilado, validación y limpieza continua de la información según reglas definidas por el negocio. Tras el análisis inicial de calidad, genera dashboards con métricas claves —completitud, unicidad, validez— que alertan proactivamente sobre desviaciones. Incorpora transformaciones de forma masiva, limpieza de duplicados y estandarización de formatos, todo ello orquestado en pipelines automáticos. Asimismo, permite simular el impacto de nuevas reglas de calidad antes de desplegarlas en producción para mitigar riesgos de interrupción.
Linaje de datos
Visualiza de forma gráfica el recorrido de cada dato desde su origen hasta su destino final, mostrando transformaciones, cálculos y dependencias en cada paso. Este trazado incluye procesos batch, flujos en tiempo real y scripts custom, ofreciendo una visión holística de los ciclos de vida de la información. Al integrar el linaje con los módulos de catálogo y calidad, se simplifica la localización de alarmas y se acelera la resolución de incidencias. Esta claridad resulta imprescindible para auditorías, diagnósticos de errores y demostración de cumplimiento normativo.
Gestión de políticas de privacidad y riesgo
Incorpora controles de privacidad y enmascaramiento de datos automáticos para proteger información sensible según requisitos GDPR, CCPA u otras normativas. Detecta y clasifica datos personales, proponiendo políticas de anonimización o pseudonimización basadas en plantillas configurables. A su vez, evalúa riesgos asociados a exposiciones indebidas y genera informes de mitigación. Esto permite a las empresas equilibrar la necesidad de análisis con la privacidad de los usuarios y minimizar posibles sanciones regulatorias.
Data Marketplace y autoservicio
Centraliza en un portal los conjuntos de datos validados y certificados para su consumo por analistas, desarrolladores y científicos de datos. Cada activo publicado incluye descripciones, niveles de calidad, linaje asociado y permisos de acceso. Los usuarios pueden solicitar nuevos datos, suscribirse a cambios y puntuar los recursos, creando un círculo de mejora continua. Gracias al autoservicio controlado, se reduce la carga operativa del equipo de TI y se democratiza el uso de datos.
APIs, conectores y extensibilidad
Dispara integraciones con ERP, CRM, plataformas cloud y herramientas de BI mediante más de 200 conectores preconstruidos. Las APIs REST y SDKs permiten orquestar procesos, consultar metadatos o lanzar escaneos de calidad desde sistemas externos. Su arquitectura basada en microservicios facilita añadir nuevos plugins o personalizar transformaciones sin afectar el núcleo de la plataforma. Esto asegura que la solución evolucione en paralelo con el ecosistema tecnológico de la empresa.
Inteligencia artificial y automatización de procesos
Emplea algoritmos de machine learning para sugerir clasificaciones de datos, detectar patrones de calidad atípicos y predecir tendencias de uso. Los asistentes basados en IA aceleran la definición de glosarios y políticas, proponiendo automáticamente relaciones entre términos. Asimismo, automatiza tareas repetitivas —como reevaluar reglas de calidad o actualizar linajes tras cambios en fuentes— liberando al equipo de operaciones para tareas de mayor valor estratégico.
Reseña técnica de Informatica Intelligent Data Management
Informatica Intelligent Data Management es una plataforma diseñada para unificar la gestión del ciclo de vida de los datos empresariales, abarcando desde la catalogación y el descubrimiento hasta la gobernanza y la calidad. Su arquitectura modular facilita la adopción gradual de componentes según necesidades, mientras que el enfoque basado en metadatos impulsa la automatización y la trazabilidad en entornos locales, híbridos o en la nube.
La catalogación automática recorre fuentes heterogéneas (bases de datos, data lakes, aplicaciones SaaS) con técnicas de machine learning y procesamiento de lenguaje natural para extraer, clasificar y enriquecer metadatos. Los usuarios acceden a búsquedas tipo “Google‑like” y reciben sugerencias de relaciones entre activos, lo que agiliza la identificación de conjuntos de datos críticos y reduce la duplicidad de esfuerzos en el análisis.
El componente de gobernanza ofrece un repositorio colaborativo donde se definen políticas, se documentan términos de negocio y se asignan responsabilidades a data stewards y propietarios de datos. Flujos de aprobación configurables aseguran el cumplimiento de normativas (GDPR, CCPA, ISO 27001) y generan evidencias de auditoría, proporcionando visibilidad completa del estado de conformidad en tiempo real.
La capa de Calidad de datos aplica reglas de validación, limpieza y enriquecimiento en pipelines orquestados mediante microservicios. Dashboards interactivos muestran métricas como completitud, consistencia y precisión, generando alertas proactivas ante desviaciones de umbrales definidos.
El linaje documenta el recorrido de cada dato, desde el origen hasta los sistemas finales, incluyendo transformaciones batch y en streaming. Visualizaciones interactivas permiten a los equipos detectar impactos de cambios de esquema, mapear dependencias entre procesos ETL/ELT y optimizar rutas de datos para minimizar latencias y cuellos de botella operativos.
La gestión centralizada de metadatos integra información técnica, operativa y de negocio en un único repositorio accesible vía API REST. Versionado y comparación de metadatos facilitan auditorías detalladas y sincronizaciones con sistemas externos como CMDB o herramientas de BI, reforzando la coherencia en todo el ecosistema de datos.
Los amplios conectores nativos cubren bases tradicionales, plataformas Big Data y servicios cloud (AWS, Azure, GCP), junto a aplicaciones corporativas (SAP, Salesforce) y mensajería (Kafka). SDKs en Python y Java permiten personalizar integraciones, garantizando autenticación segura, optimización de transferencia y resiliencia ante fallos.
Finalmente, la seguridad se articula mediante SSO, control de acceso basado en roles y atributos, cifrado en tránsito y reposo, así como funcionalidades de descubrimiento de PII, tokenización y mascaramiento dinámico. Registros de auditoría detallados documentan cada consulta y modificación, fortaleciendo la confianza y facilitando la gestión de riesgos en entornos regulados.
Fortalezas y debilidades de IDMC
| Fortalezas | Debilidades |
|---|---|
| Arquitectura modular que permite activar solo los componentes necesarios y escalar con facilidad. | Curva de aprendizaje pronunciada, especialmente para usuarios sin experiencia previa en gobernanza. |
| Catálogo automático con ML y NLP que acelera el descubrimiento y mapeo de activos de datos. | Coste elevado de licenciamiento, especialmente en escenarios multinube o con alto volumen de datos. |
| Integración nativa con más de 200 conectores para sistemas legacy, Big Data y SaaS. | Dependencia de recursos para proyectos de implantación, requiere perfiles especializados (data stewards, arquitectos). |
| Visibilidad completa de linaje y metadatos, facilitando auditorías y análisis de impacto. | Interfaz compleja en algunos módulos, con menús y opciones que pueden resultar abrumadores. |
| Herramientas de calidad que permiten automatizar perfiles, limpieza y estandarización. | Rendimiento puede verse afectado en catálogos muy grandes si no se dimensiona adecuadamente la infraestructura. |
| Políticas de seguridad avanzadas (SSO, RBAC/ABAC, cifrado, mascaramiento dinámico). | Actualizaciones periódicas que a veces introducen cambios disruptivos en la configuración. |
| APIs abiertas y SDKs para personalizar integraciones y orquestar flujos de datos complejos. | Soporte multilingüe limitado en la documentación y en algunas interfaces de usuario. |
| Portal de Data Marketplace que facilita el autoservicio y democratiza el acceso a datos certificados |
Licenciamiento e instalación
Informatica Intelligent Data Management se ofrece principalmente bajo un modelo de suscripción por usuario o por capacidad de datos gestionados, con opciones de licencia perpetua para grandes implantaciones on-premise. Está orientado a medianas y grandes empresas que necesitan un gobierno de datos exhaustivo y cuentan con equipos multidisciplinares de TI, analistas y compliance. En cuanto al tipo de instalación, soporta despliegues locales, en entornos híbridos (on-premise más cloud) y completamente en la nube, lo que permite a las organizaciones elegir entre gestión interna de la plataforma o un servicio gestionado por Informatica.
Referencias
Página oficial de Informatica Intelligent Data Management: Intelligent Data Management Cloud
- Printer-friendly version
- Log in to post comments
