

Las relaciones, la materia oscura de nuestros datos
Hace miles de años que miramos el cielo. Desde los egipcios, e incluso antes, hay constancia que el ser humano ha intentado entender lo que hay más allá de lo que podía tocar con las manos. ¿Qué hemos conseguido desde entonces? Muchísimo!

Llevamos casi 400 años mirándolo con tecnología (el primer telescopio es de alrededor del año 1600), y casi 100 años mirándolo con alta tecnología, con radiotelescopios, telecopios espaciales, … hemos avanzado mucho. Ahora mismo hay miles de aparatos y de personas que escrutan el universo las 24h del día. Y ¿sabéis una cosa? Hace poquísimo que hemos descubierto un elemento gigante que está más allá de nuestro espectro visual, la Materia Oscura.
La Materia Oscura es un elemento nuevo y que aglutina una cantidad inmensa del Universo, pero que, teniéndolo delante desde hace miles de años, hasta ahora no nos hemos percatado de él. No quiero ahora entrar en discutir si la materia oscura es el 80% de la masa del Universo o sólo el 20%, lo que está claro es que es una masa gigante que ni siquiera con alta tecnología habíamos sido capaces de encontrar.
Bien, y ahora os preguntaréis ¿por qué Josep nos cuenta esto? Y será una buena pregunta, espero que la respuesta esté a la altura. Pues ahí va. De la misma manera que hemos mirado el universo, que lleva millones de años allí, y hasta ahora no nos hemos dado cuenta de la Materia Oscura, en nuestros sistemas de gestión de datos tradicionales, llevamos años analizando datos, comprendiendo cómo son nuestros clientes, nuestros productos, cómo mejorar nuestras campañas … pero para ello sólo nos hemos fijado en los datos, en esos datasets que están compuestos de tablas, que son como las estrellas del Universo, pero nos hemos olvidado de un elemento primordial, de algo que lleva allí tantos años como nuestras bases de datos, pero oculto, igual que la Materia Oscura, y no es otra cosa que las Relaciones. Sí, las relaciones en nuestros datos, ese gran desconocido que oculta un gran potencial para entender la realidad, pero que hasta ahora ni siquiera hemos tocado la punta del iceberg de lo que vamos a ser capaces de sacarle partido.
Las BBDD relacionales, como la que vemos en la imagen justo arriba, irónicamente, no tienen relaciones. Bueno, cuando nos pongamos a discutir, saldremos con que sí, que tienen Foreign Keys, que no dejan de ser relaciones, pero me refiero a que, así como las tablas son ciudadanos de primer orden, las relaciones no lo son, son entidades etéreas, inferidas en tiempo de ejecución, pero no existen persistidas en la BD.
Y las relaciones son importantes para entender la realidad. Ya no preguntamos a alguien si le gusta la comida japonesa o si hace un deporte u otro, lo que hacemos para entender a alguien es ver donde va, quienes son sus contactos, qué Apps usa, … eso nos explica quién es más que ninguna otra cosa que podamos hacer. Y eso es analizar y entender las relaciones, eso es sacar valor de negocio a las relaciones que ya tenemos hoy en nuestros datos.
BBDD de grafos
Y sí, la mejor manera de gestionar relaciones es usando un sistema gestor de datos de grafo nativo, como Neo4j. Esta tecnología no es nueva, Neo4j se fundó el año 2000, así que ya es una tecnología madura. Pero los grafos no se los inventó Neo4j, sino que el origen de los grafos se remonta al año 1736, cuando el matemático suizo Leonard Euler propuso y resolvió el problema de los puentes de Königsberg. Así que la teoría matemática detrás de los grafos también es algo con mucha historia en sus espaldas, aunque hasta hace poco no se le ha encontrado una aplicación práctica en los negocios.
Las BBDD de grafos nativas, como Neo4j, JanusGraph, … junto con algunas de tipo Multi-Model como OrientDB o ArangoDB, son las que proveen un mayor potencial de gestión de relaciones, algo que las BBDD relacionales o incluso otras de tipo NoSQL, como las Documentales, Motores de búsqueda o Clave-Valor son incapaces de gestionar.
Tecnología detrás de los grafos – Native property graph
Neo4j es de largo la BD nativa de grafos más popular del mercado. En Neo4j, sólo hay 2 objetos básicos: Nodos y Relaciones.

Las relaciones conectan nodos. Vamos a ver un grafo un poco más complejo.
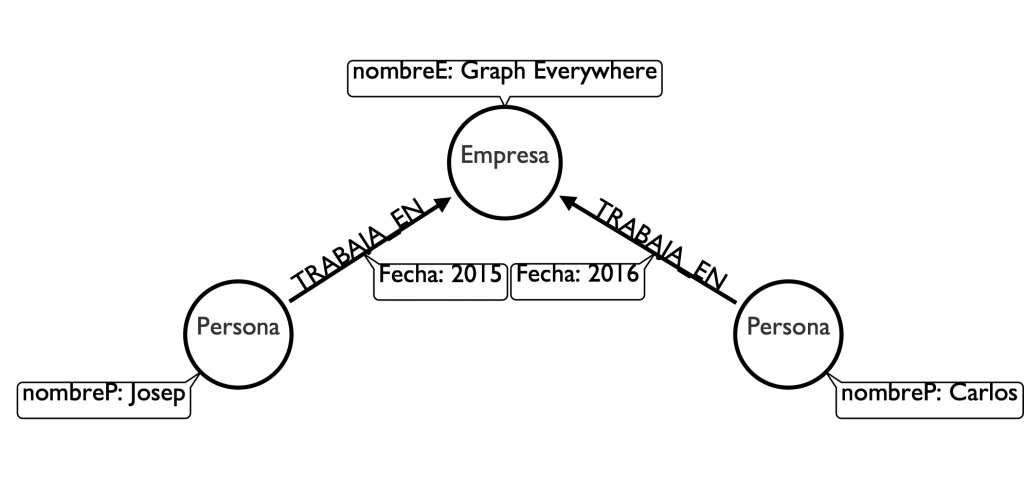
Como vemos en la imagen hay un tercer elemento primordial, las Propiedades. Estas nos permiten añadir información específica en los dos elementos básicos, tanto en los Nodos como en las Relaciones.
En el ejemplo vemos que tenemos 2 personas, una que se llama Josep y otra que se llama Carlos. Estas dos personas trabajan en la empresa Graph Everywhere desde una fecha, 2015 y 2016 respectivamente.
En las BBDD nativas de grafos, tanto los nodos como las relaciones son ciudadanos de primer orden, es decir, existen los dos realmente en la base de datos, son objetos persistidos en el disco y que se cargan en memoria cuando se requieren.
Cypher – Graph Query Language
Una de las diferencias primordiales de esta BD frente al resto es la existencia de Cypher, un lenguaje declarativo de consulta de la BD, como el SQL para las BBDD relacionales. Cypher es un lenguaje pensado para encontrar Patrones dentro del grafo. Patrón es una palabra clave cuando hablamos de los grafos. Veamos de nuevo el grafo inicial.
Cómo resolvemos esta cónsulta con Cypher?
MATCH (origen:Nodo) -[:RELACION]-> (destino:Nodo) RETURN origen, destino;
Como vemos los nodos se expresan entre paréntesis y las relaciones tienen una flecha con paréntesis cuadrados. “origen” y “destino” son variables, de tipo “Nodo” que son lo que vamos a devolver en el RETURN. Esta sentencia nos devolverá todos los pares de Nodos conectados en nuestro grafo.
Vamos a hacer una consulta un poco más compleja. Supongamos el grafo anterior.

Y queremos buscar qué personas trabajan con Josep en la misma Empresa. Esperamos que nos devuelva a Carlos. La setencia sería la siguiente.
MATCH (:Persona {nombreP:”Josep”})-->(:Empresa)<--(p:Persona)
RETURN p;Casos de Uso
Bien, los grafos parecen interesantes … pero ¿para qué sirven?
(Graphs)-[ARE]->(Everywhere)
No nos llamamos así por casualidad, la realidad es que gran parte de los problemas que ahora sentimos que están en la frontera de la capacidad de los sistemas que usamos es porque son un problema de grafos. Los grafos nos permiten responder en tiempo real preguntas extremadamente complejas, que tienen que ver con el contexto de un dato (un cliente, un producto, …). Es difícil poner la lista de todos los usos, pero vamos a intentar describirlos por sector/departamento.
|
Sector |
Caso de uso |
|
Financiero Seguros |
|
|
Logística |
|
|
eCommerce |
|
|
IT genérico |
|
|
Telco y Utilities |
|
