
El proyecto ENOBI sigue avanzando en la parte mas compleja y que seguramente mas recursos consumira, los procesos ETL. Como ya indicamos, en algunos proyectos puede suponer hasta el 80% del tiempo de implantación. Y no solo eso, el que los procesos esten desarrollados con la suficiente consistencia, rigor, calidad, etc. va a determinar el exito posterior del proyecto y que la explotación del sistema de Business Intelligence sea una realidad. Seguramente si los procesos de extraccion, transformación y carga no esta bien desarrollados, eso pueda acabar afectando al uso correcto del sistema
Para concluir los procesos ETL de las Dimensiones del proyecto, vamos a abordar la carga de la Dimensión Cliente, que incluye todos los atributos por los que analizaremos a nuestros clientes. Vamos a obviar la publicación de los proceso de carga de la Dimensión Logistica y Promoción, pues son muy sencillos y no aportan nada nuevo.
Al detallar los procesos de la carga de la Dimension Cliente, entraremos en detalle en las diferente formas que tiene Talend de realizar los mapeos de tablas de lookup. Es decir, cuando tenemos un valor para el que tenemos que recuperar un valor adicional en otra tabla de la base de datos (por ejemplo, para un código de cliente recuperar su nombre; para la familia de producto, introducida en el maestro de materiales, recuperar de la tabla de parametrización su descripción, etc ), ver de que maneras Talend nos permite realizar dicha consulta.
Igualmente, veremos mas ejemplos de utilización de Java dentro de los componentes, y la potencia que ello nos proporciona (aunque nos obliga a tener conocimientos amplios de este lenguaje).
Para completar el ejemplo, aunque en realidad en nuestra dimensión no vamos a gestionar las dimensiones lentamente cambiantes (SCD Slowly Change Dimension), vamos a incluir un ejemplo de tratamiento de este tipo de dimensiones, utilizando el componente que tiene Talend para ese cometido, que implementa el algoritmo correspondiente para su procesamiento (elemento tMySQLSCD).
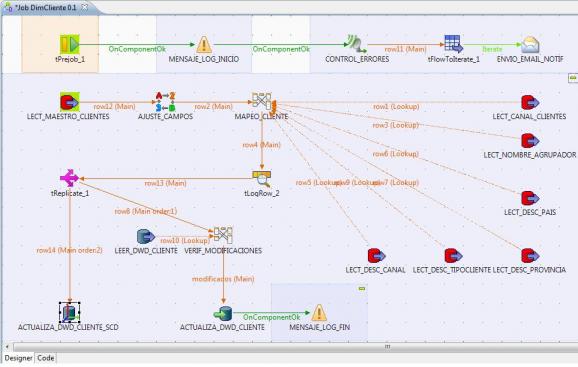
Proceso ETL en Talend completo para la dimensión Cliente
Tal y como vemos en la imagen anterior, los pasos del proceso ETL para llenar la Dimensión Cliente serán los siguientes:
1) Ejecución de un prejob que lanzará un generara en el log un mensaje de inicio del proceso y un logCatcher (para recoger las excepciones Java o errores en el proceso). Este generará el envio de un email de aviso en el caso de que se produzca algún problema en cualquier paso del job.
- Lanzador Prejob (componente tPrejob): sirve para realizar el lanzamiento de un pretrabajo, anterior al proceso principal.
- Mensaje Log Inicio (componente tWarn): genera un mensaje de log indicando que se comienza la ejecución del job.
- Control Errores (componente tLogCatcher): activamos el componente que “escuchara” durante toda la ejecución del job, esperando que se produzca algún tipo de error. En ese momento se activara para recuperar el error y pasarlo al componente siguiente para el envio de un email de notificación.
- tFlowtoIterate: convertimos el flujo de registros de log a una iteración para poder realizar el envio del correo electrónico.
- Envio Email Notif (componente tSendMail): generamos el envio de un email de notificación de errores, incluyendo el paso donde se paro el proceso, y el mesaje de error generado. Es una forma de avisar que ha fallado algo en el proceso. En la siguiente imagen tenéis un ejemplo de un email de notificación de error enviado a una cuenta de gmail.
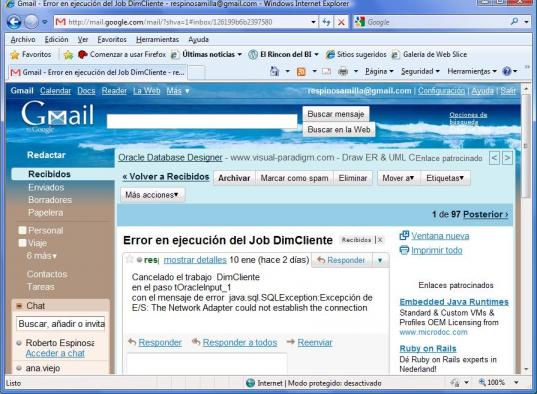
Ejemplo envio Email de notificacion de error
2) Recuperamos del maestro de cliente en el ERP, todos los clientes existentes en el fichero maestro (con el componente tOracleInput).
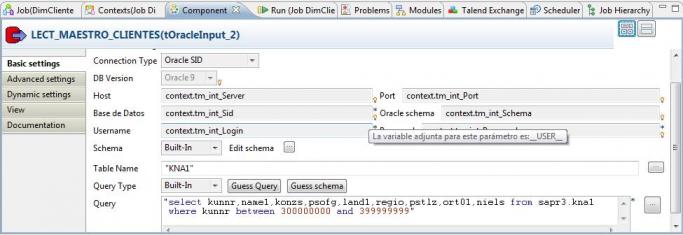
Job DimCliente - Lectura Maestro Clientes Sap
3) Realizamos una sustitución de valores erroneos o en blanco en los registros seleccionados según los criterios establecidos (con el componente tReplace), como ya vimos en los procesos ETL de la Dimensión Producto.
4) Completamos el mapeo de dimensión Cliente, llenando el resto de campos que provienen de otras tablas en la base de datos (los campos de lookup), con sus correspondientes consultas SQL (utilizando el componente tMap).
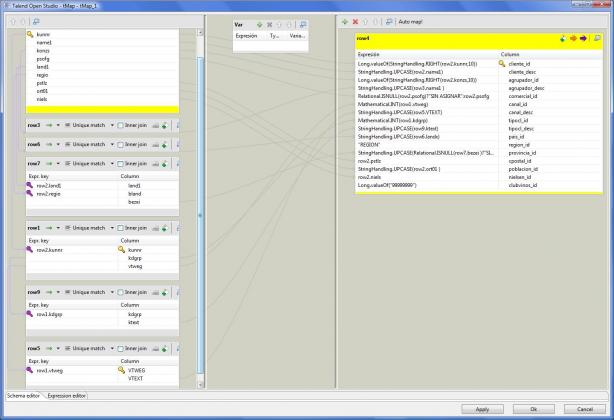
Job DimCliente - Mapeo Cliente
Podeis observar como al realizar el mapeo del maestro de clientes con las correspondientes tablas de lookup (donde estan el resto de campos y descripciones), hemos estado utilizado sintaxis del lenguaje Java. Esto nos da mayor potencia a las transformaciones y nos permitirán hacer casi de todo, aunque tendremos que conocer bien Java, sus tipos de datos, la forma de convertirlos. Algunos ejemplos son:
- Relational.ISNULL(row2.psofg)?”SIN ASIGNAR”:row2.psofg : el operador Java que nos permite asignar un valor u otro a un resultado segun si se cumple una condición o no. En este caso, si row2.psofg es nulo, al resultado se le dara el valor “SIN ASIGNAR”. En caso contrario, se le dara el valor del campo row.psofg.
- StringHandling.UPCASE(row2.ort01 ) : es un metodo de la clase StringHandling, que nos permite pasar una cadena a mayúsculas.
- Long.valueOf(StringHandling.RIGHT(row2.konzs,10)) : utilizamos el metodo RIGHT de la clase StringHandling para obtener una subcadena, y el resultado lo convertimos al tipo de datos numérico Long con el metodo de este valueOf.
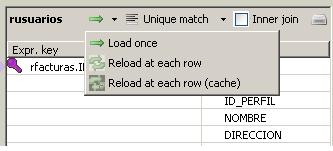
Tipos de Mapeo en el componente tMap
Cuando utilizamos el componente tMap para completar los datos de nuestro flujo con valores proveniente de otras tablas (u otros ficheros u origenes de datos), vemos que siempre tenemos un flujo Main (en nuestro caso con los datos que llegan del fichero maestro de Sap) y uno o varios flujos lookup (lo podeis observar en la imagen anterior). Estos flujos de lookup nos permiten “rellenar” valores que residen en otro lugar, buscandolos por una clave determinada. La clave puede venir del propio flujo Main o de otros flujos de lookup (de forma anidada). Pensar por elemplo el caso de recuperar, a partir del código de cliente, un dato asociado (como el comercial asignado). Posteriormente, para el código de comercial, busco en otro lookup, utilizando ese código, el nombre de dicho comercial.
Los flujos de lookup pueden ser de tres tipos, como vemos en la imagen. Veamos en que consiste cada uno de ellos:
- Load Once: la rama de lookup del componente tMap se ejecuta una unica vez y siempre antes de la ejecución del componente tMap. En este caso, la ejecución unica de la rama de lookup ha de generar todos los registros para poder buscar valores en ellos (será una carga de todo un fichero maestro, por ejemplo). Si los datos para el lookup tuvieran muchos registros, podría ser un cuello de botella para el proceso, e igual convendría utilizar el tipo Reload at each row.
- Reload at each row: la rama del lookup se ejecuta para cada registro que llegan del flujo Main. Este tipo de mapeo nos permite ejecutar la consulta de lookup para un valor concreto (podremos pasar un valor unico que sera el que realmente busquemos. Ver ejemplo posterior de este tipo de lookup). Puede tener sentido utilizarlo con tablas de lookup muy grandes que no tiene sentido gestionar en una consulta de atributos (pensar en una tabla maestro de clientes de millones de registros).
- Reload at each row (cache): idem al anterior, pero los registros que se van recuperando se guardan en la cache. En las siguientes consultas, se mira primero en la cache, y si ya existe, no se lanza el proceso. En el caso de que no exista, entonces si se relanza la ejecución para buscar los valores que faltan.
En este caso, en todos los flujos de lookup hemos utilizado el tipo Load Once (mas adelante veremos un ejemplo de uso Reload at each row).
5) Verificamos que realmente haya modificaciones con los datos existentes en la base de datos del DW (también con el componente tMap), y para los registros que si tienen modificaciones (o son nuevos registros), realizamos la actualización. En principio, no vamos a realizar gestión de Dimensiones Lentamente Cambiantes, sino que siempre tendremos la foto de los datos tal y como están los ficheros maestros en el momento actual.
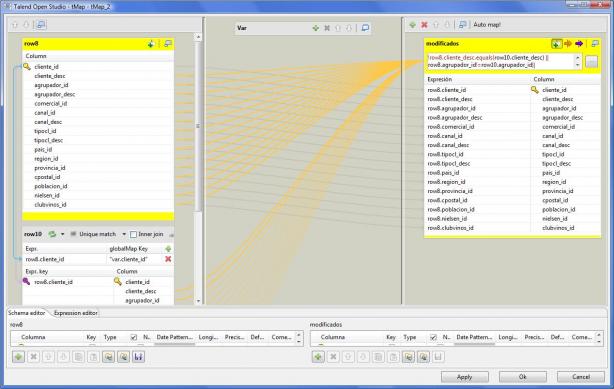
Job DimCliente - Verificacion Modificaciones
Para discriminar el paso de registros al paso siguiente de actualización en la base de datos del DW, se ejecuta la siguiente expresión condicional (vemos que es 100% lenguaje Java). La expresión va comparando campo por campo entre los valores recuperados de nuestro ERP y los existentes en la tabla de la dimensión cliente DWD_CLIENTE.
!row8.cliente_desc.equals(row10.cliente_desc) || row8.agrupador_id!=row10.agrupador_id|| !row8.agrupador_desc.equals(row10.agrupador_desc)|| !row8.comercial_id.equals(row10.comercial_id)|| row8.canal_id!=row10.canal_id|| !row8.canal_desc.equals(row10.canal_desc)|| row8.tipocl_id!=row10.tipocl_id|| !row8.tipocl_desc.equals(row10.tipocl_desc)|| !row8.pais_id.equals(row10.pais_id)|| !row8.region_id.equals(row10.region_id)|| !row8.provincia_id.equals(row10.provincia_id)|| !row8.cpostal_id.equals(row10.cpostal_id)|| !row8.poblacion_id.equals(row10.poblacion_id)|| !row8.nielsen_id.equals(row10.nielsen_id)|| row8.clubvinos_id!=row10.clubvinos_id
Cuando el lookup lo ejecutamos para cada registro que llega al control tMap (en este caso utilizamos el tipo Reload at each row), la sentencia SQL que se ejecuta en el flujo de lookup es la siguiente (observa que en la condición del where utilizamos una variable que hemos generado en el control tMap, y será la que contiene el código de cada cliente que queremos verificar). En este caso, el paso asociado al flujo lookup se ejecuta una vez para cada registro que llegue al componente tMap y siempre posteriormente:
"SELECT dwd_cliente.cliente_id,
dwd_cliente.cliente_desc,
dwd_cliente.agrupador_id,
dwd_cliente.agrupador_desc,
dwd_cliente.comercial_id,
dwd_cliente.canal_id,
dwd_cliente.canal_desc,
dwd_cliente.tipocl_id,
dwd_cliente.tipocl_desc,
dwd_cliente.pais_id,
dwd_cliente.region_id,
dwd_cliente.provincia_id,
dwd_cliente.cpostal_id,
dwd_cliente.poblacion_id,
dwd_cliente.nielsen_id,
dwd_cliente.clubvinos_id
FROM dwd_cliente
WHERE cliente_id = " + (globalMap.get("var.cliente_id"))
En este caso, la sentecia SQL (y el correspondiente componente que la contiene), se ejecutara una vez por cada registro que llega por el flujo Main al componente tMap. Y la sentencia SQL solo recuperara un registro de la base de datos, aunque se estará ejecutando continuamente (le hemos pasado con la variable var.cliente_id el valor a buscar).
6) Concluimos el proceso guardándonos en el log el correspondiente mensaje de finalización correcta del proceso, con el componente MENSAJE_LOG_FIN del tipo tWarn.
TRATAMIENTO DE LAS DIMENSIONES LENTAMENTE CAMBIANTES
Como ejemplo y para estudiar su funcionamiento, incluimos un paso para la gestión de las dimensiones lentamente cambiantes (que se grabaran en una tabla paralela a la de la dimensión cliente). El tipo de componente en Talend para realizar esto será el tMySqlSCD.
Para entender que son exactamente las dimensiones lentamente cambiantes, os recomiendo un poco de literatura. En el blog Business Intelligence Facil, se explican de una forma muy clara que son y como gestionarlas ( ver aquí ), así como de las claves subrogadas. Tambien Jopep Curto nos da muy buenas definiciones en su blog.
Una vez tengamos clara la teoria, vamos a ver como aplicarlo a la practica utilizando los componentes de Talend.
Componente para gestion dimensión lentamente cambiante
El algoritmo de la dimensión SCD se gestiona con el correspondiente editor, tal y como vemos en la imagen siguiente:
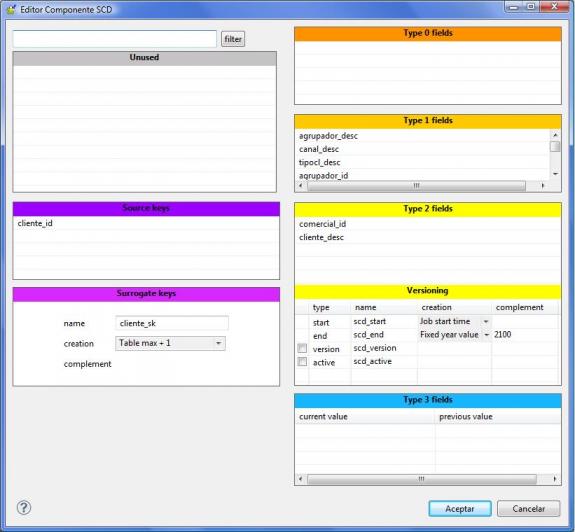
Editor Componente SCD
Para utilizar el editor, se indica un nombre de tabla existente en la base de datos, que sera la tabla para la cual vamos a gestionar la SCD (ha de incluir los campos necesarios para la gestión de versiones según lo indicado en el editor SCD). El control recibirá un flujo con los registros a procesar contra la tabla indicada. En el editor SCD indicamos como se va a comportar la actualización contra la tabla según los diferentes tipos de atributos.
Los controles que forman el editor de dimensiones SCD son los siguientes:
- Unused: aquí apareceran todos los campos disponibles para utilizar en el editor SCD. Desde este sitio iremos arastrando los campos al resto de sitios.
- Source keys: son las claves principales de los datos (la clave en el sistema original). Para un maestro de clientes, aquí indicaremos la clave que identifica a este en el sistema origen.
- Surrogate keys: es el nombre que le damos a la clave subrogada. Es decir, aquella clave inventada que nos va a permitir gestionar versiones de nuestros datos en el DW.
- Type 0 fields: aqui indicaremos los campos que son irrelevantes para los cambios. Si aqui metemos, por ejemplo, el campo nombre, cualquier cambio en el sistema origen con respecto a los datos existentes en el DW no se va a tener en cuenta (se ignorará).
- Type 1 fields: aquí indicaremos los campos para los que, cuando haya un cambio, se machacará el valor existente con el valor recibido, pero sin gestionar versionado.
- Type 2 fields: aquí indicaremos los campos para los que queremos que, cuando haya un cambio, se produzca un nuevo registro en la tabla (con una nueva subrogated key). Es decir, aquí pondremos los campos que son dimensiones lentamente cambiantes y para los que queremos gestionar un versionado completo.
- Versioning: aqui indicamos los valores para el versionado (fecha de inicio y fecha de fin), y si queremos llevar un control de numero de versión o flags de registro activo (requeriran campos adicionales en la tabla para este cometido).
- Type 3 fields: aquí indicaremos los campos para los que queremos guardarnos una versión anterior del valor (es decir, cuando haya un cambio, siempre tendremos dos versiones, la ultima y la anterior).
Para concluir la explicación de las dimensiones SCD, observar las diferencias de catalogo entre el flujo de entrada y el flujo de salida (en el de salida se han incluido atributos propios para la gestión de la dimension lentamente cambiante, gestión de versiones, fechas de validez, etc):
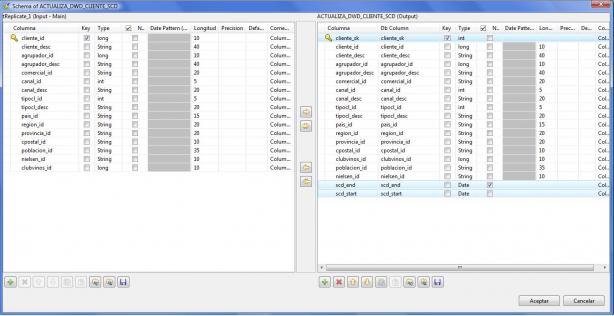
Esquema de traspaso de Datos en Dimensiones SCD
Para entender mejor el ejemplo, observar las entradas en MySql de la tabla DWD_CLIENTE_SCD. Observar como el cliente tuvo un cambio en su nombre y se generó un nuevo registro en la tabla con una nueva clave subrogada. Todo se ha realizado de una forma automatica por el componente de Talend, sin tener que gestionar nosotros nada.
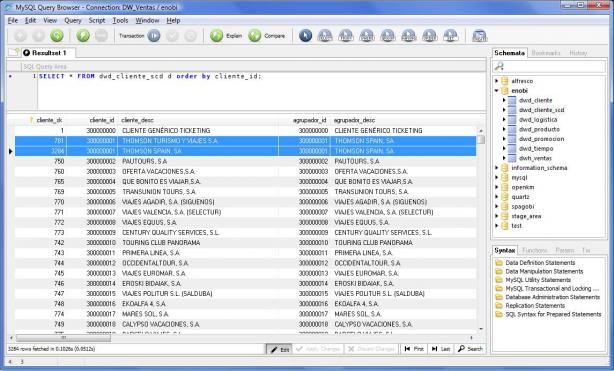
Registros para el mismo cliente en MySql con Subrogated key
Finalmente, observar que hemos utilizado un componente nuevo para duplicar un flujo de datos (el componente tReplicate). Este componente nos permite a partir de un unico flujo, generar tantos flujos como sea necesarios (todos serán iguales y procesarán los mismos registros).
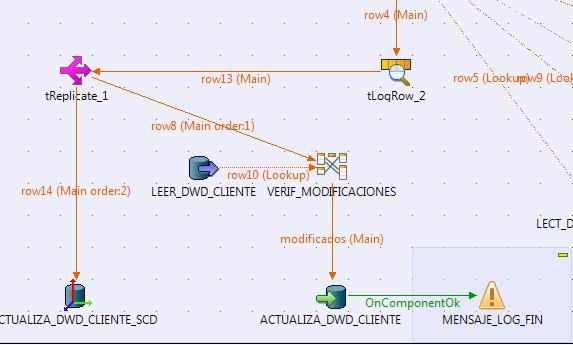
Duplicacion de flujos de datos con el componente tReplicate
Para ver en detalle como hemos definido cada componente del Job, podeís acceder a la documentación HTML completa generada por Talend. Podeis descargaros el fichero zip que contiene dicha documentación aquí.
