
9.600 millones de euros en software de gestión que no se utiliza (infografía)

 Las empresas europeas están desperdiciando 9.600 millones de euros de inversión en tecnología cada año al no utilizar plenamente sus soluciones de gestión. Esta es una de las principales conclusiones del estudio que Sage ha presentado en Lisboa en el marco de su “Global Convention” y en la que han colaborado 600 responsables de TI de empresas de la Unión Europea..
Las empresas europeas están desperdiciando 9.600 millones de euros de inversión en tecnología cada año al no utilizar plenamente sus soluciones de gestión. Esta es una de las principales conclusiones del estudio que Sage ha presentado en Lisboa en el marco de su “Global Convention” y en la que han colaborado 600 responsables de TI de empresas de la Unión Europea..
 La base de datos Oracle 12c destaca por la gran cantidad de mejoras que incorpora con respecto a cualquier otra versión. Como se puede deducir de su nombre, las nuevas características de esta versión se orientan especialmente hacia el Cloud Computing. Larry Ellison ya destacó en la sesión inaugural del OpenWorld 2012 que, de hecho, es la release de base de datos más importante que han lanzado en mucho tiempo. Para esta versión, se han realizado drásticos cambios de arquitectura que han dado como resultado más de 500 nuevas características!..
La base de datos Oracle 12c destaca por la gran cantidad de mejoras que incorpora con respecto a cualquier otra versión. Como se puede deducir de su nombre, las nuevas características de esta versión se orientan especialmente hacia el Cloud Computing. Larry Ellison ya destacó en la sesión inaugural del OpenWorld 2012 que, de hecho, es la release de base de datos más importante que han lanzado en mucho tiempo. Para esta versión, se han realizado drásticos cambios de arquitectura que han dado como resultado más de 500 nuevas características!...jpg) Dentro de las actividades habituales en minería de datos, se encuentra el estudio de correlaciones entre variables. En este post vamos a realizar un ejemplo sencillo de estudio de correlación entre variables realizado con la herramienta SAS.
Dentro de las actividades habituales en minería de datos, se encuentra el estudio de correlaciones entre variables. En este post vamos a realizar un ejemplo sencillo de estudio de correlación entre variables realizado con la herramienta SAS. Las pymes se enfrentan cada día a las dificultades particulares de sus mercados y sectores en los que se mueve. La tecnología les sirve para para dar soporte a su negocio en distintas áreas y como herramienta para ser más eficientes, para llegar mejor a los clientes, para desarrollar mejores productos y servicios, para coordinar a los distintos actores que participan en el negocio (proveedores, clientes, colaboradores, entre otros) y para ayudar en muchas otras tareas en el día día..
Las pymes se enfrentan cada día a las dificultades particulares de sus mercados y sectores en los que se mueve. La tecnología les sirve para para dar soporte a su negocio en distintas áreas y como herramienta para ser más eficientes, para llegar mejor a los clientes, para desarrollar mejores productos y servicios, para coordinar a los distintos actores que participan en el negocio (proveedores, clientes, colaboradores, entre otros) y para ayudar en muchas otras tareas en el día día.. En el siguiente post mostramos con ejemplos los diferentes métodos de agregación de los que disponemos en el módulo BASE de SAS. Se incluye un script con ejemplos utilizando el procedimiento generalista ‘proc sql’ o bien procedimientos propios de agregación como ‘proc means’ o ‘proc summary’.
En el siguiente post mostramos con ejemplos los diferentes métodos de agregación de los que disponemos en el módulo BASE de SAS. Se incluye un script con ejemplos utilizando el procedimiento generalista ‘proc sql’ o bien procedimientos propios de agregación como ‘proc means’ o ‘proc summary’..jpg) A raíz de una consulta recibida en el post anterior a continuación mostramos las principales diferencias entre el “schema on write” que es el que ya conocemos de las BBDD tradicionales y el “schema on read” más ligado a la arquitectura Big Data.
A raíz de una consulta recibida en el post anterior a continuación mostramos las principales diferencias entre el “schema on write” que es el que ya conocemos de las BBDD tradicionales y el “schema on read” más ligado a la arquitectura Big Data. 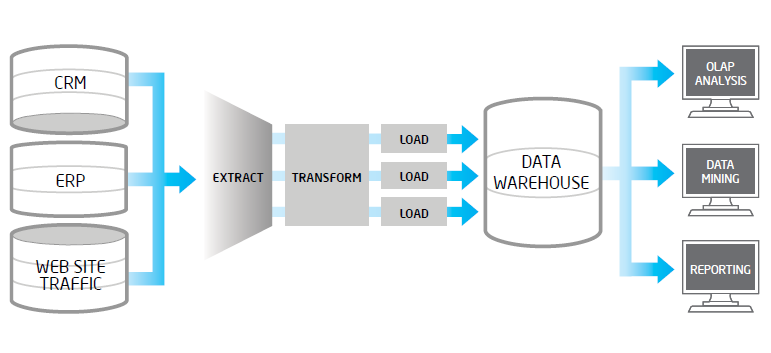 En el presente post pretendemos mostrar la problemática que con frecuencia encontramos en los procesos de extracción, validación y carga de datos en los entornos Big Data. Un proceso ETL tradicional, extrae datos desde múltiples fuentes origen, después los valida, normaliza, realiza determinadas transformaciones y vuelca los mismos en un entorno datawarehouse para su posterior análisis. Cuando en los datos fuentes, tenemos volúmenes altos, una frecuencia de actualización alta en origen o bien son datos no estructurados, estos procesos ETL suelen tener problemas..
En el presente post pretendemos mostrar la problemática que con frecuencia encontramos en los procesos de extracción, validación y carga de datos en los entornos Big Data. Un proceso ETL tradicional, extrae datos desde múltiples fuentes origen, después los valida, normaliza, realiza determinadas transformaciones y vuelca los mismos en un entorno datawarehouse para su posterior análisis. Cuando en los datos fuentes, tenemos volúmenes altos, una frecuencia de actualización alta en origen o bien son datos no estructurados, estos procesos ETL suelen tener problemas.. .png) Una de las herramientas más maduras en el mundo Big Data es el framework de licencia libre Apache Hadoop. En este post exponemos de forma resumida la integración entre Hadoop y uno de los fabricantes líder en analítica de negocio: SAS.
Una de las herramientas más maduras en el mundo Big Data es el framework de licencia libre Apache Hadoop. En este post exponemos de forma resumida la integración entre Hadoop y uno de los fabricantes líder en analítica de negocio: SAS.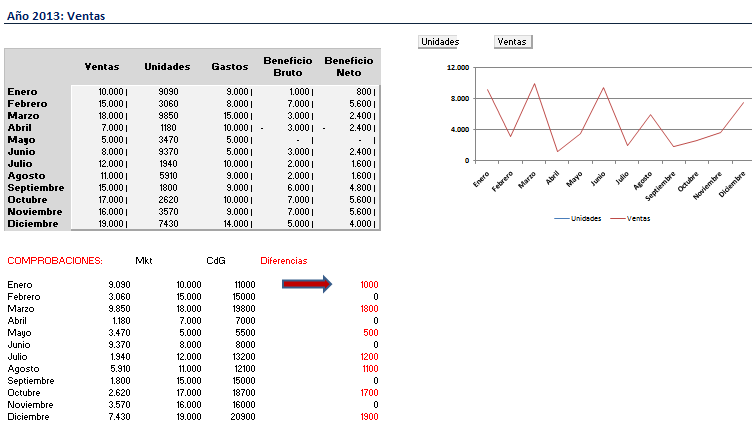 En muchas ocasiones nos encontramos en las compañías, información equivalente generada por diferentes departamentos, que aunque tenga diferentes matices y perspectivas de análisis (Ventas, Marketing, Control de Gestión) la información en su base debe ser la misma. Es habitual encontrarse con discrepancias, lo que nos hace dudar de la fiabilidad del dato y de los sistemas B.I. que los sustentan. Lo deseable es siempre disponer de maestros de datos que sirvan de fuente para todos los departamentos y de procesos sistemáticos de calidad del dato que garanticen su consistencia, integridad y trazabilidad.
En muchas ocasiones nos encontramos en las compañías, información equivalente generada por diferentes departamentos, que aunque tenga diferentes matices y perspectivas de análisis (Ventas, Marketing, Control de Gestión) la información en su base debe ser la misma. Es habitual encontrarse con discrepancias, lo que nos hace dudar de la fiabilidad del dato y de los sistemas B.I. que los sustentan. Lo deseable es siempre disponer de maestros de datos que sirvan de fuente para todos los departamentos y de procesos sistemáticos de calidad del dato que garanticen su consistencia, integridad y trazabilidad. Los triggers o desencadenadores son disparadores que saltan cuando realizamos la acción o evento al que van asociados. En MS SQL Server, además de los triggers clásicos relacionados con acciones DML (insert, update, delete) que se ejecutan en su lugar (instead of) y después (after triggers), desde SQL Server 2008 (por lo menos) existe otro tipo que son los triggers asociados a acciones que se producen por consultas DDL. Este segundo tipo de trigger está más pensado para labores administrativas como la propia auditoria, para el control de cierto tipo de operaciones e incluso evitar esos cambios.
Los triggers o desencadenadores son disparadores que saltan cuando realizamos la acción o evento al que van asociados. En MS SQL Server, además de los triggers clásicos relacionados con acciones DML (insert, update, delete) que se ejecutan en su lugar (instead of) y después (after triggers), desde SQL Server 2008 (por lo menos) existe otro tipo que son los triggers asociados a acciones que se producen por consultas DDL. Este segundo tipo de trigger está más pensado para labores administrativas como la propia auditoria, para el control de cierto tipo de operaciones e incluso evitar esos cambios.