Tips y utilidades sobre bases de datos MYSQL
Tips y utilidades sobre bases de datos MYSQL Dataprix 20 Marzo, 2022 - 10:58
Recopilación de información, utilidades y dudas sobre bases de datos Mysql, administración, rendimiento, SQL..
Mejora de rendimiento de MySQL ajustando algunos parámetros
Mejora de rendimiento de MySQL ajustando algunos parámetros Carlos 19 Abril, 2010 - 15:40MySQL, al igual que la mayoría de gestores de bases de datos, permite modificar fácilmente sus parámetros que controlan tamaños de memoria dedicados a determinadas tareas, utilización de recursos, límites de concurrencia, etc.
Ajustando adecuadamente estos parámetros se pueden obtener muchas mejoras de rendimiento de la base de datos, sobretodo si el servidor/es de BD no va sobrado de recursos, y si por la parte de optimización SQL no se puede mejorar mucho más.
Yo hace poco he realizado algunos ajustes básicos para mejorar el rendimiento de MySQL, así que voy aprovechar para explicar un poco el proceso que he seguido para quien busque una manera sencilla de hacer una primera optimización de parámetros en la base de datos. Con esto no quiero decir que esta sea la mejor manera de hacerlo, sólo la que a mi me ha resultado bien ;)
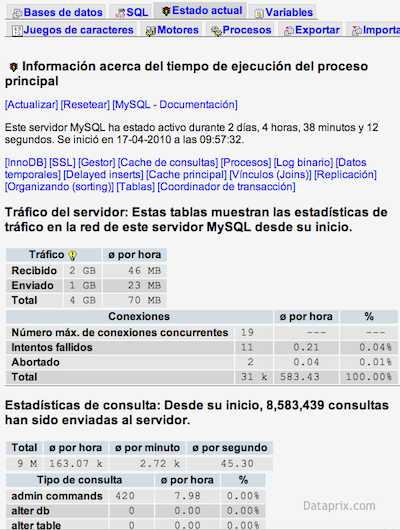
Lo primero comentar que puede ser muy útil echar un vistazo dentro de phpMyAdmin a las secciones 'Mostrar información de tiempo de ejecución de MySQL' y 'Mostrar las variables del sistema MySQL', normalmente accesibles desde la página principal de la aplicación.
La primera muestra información y estadísticas que el sistema recopila y mantiene desde su arranque. Hay que prestar especial atención a los valores de variables que se muestran en color rojo, y a los consejos que se indican a la derecha de estos valores.
Consultar las variables sirve para saber los valores actuales de los parámetros que más adelante podríamos modificar para mejorar el rendimiento de nuestro MySQL.
Una vez hecho esto seguramente ya tendremos alguna pista de por donde hay que atacar, pero lo que interesa es algo más concreto que nos sugiera qué parámetros podríamos tocar exactamente para mejorar el rendimiento de MySQL. Para ello yo he utilizado mysqltunner.pl, que es un script en perl que analiza el rendimiento de la base de datos y los valores de los parámetros y tras el análisis realiza sugerencias de modificación de algunos de estos valores.
Si se cumplen los requerimientos, utilizar el script en un sistema Linux/Unix es tan sencillo como ejecutar desde linea de comandos:
> wget mysqltuner.pl
> chmod 755 mysqltuner.pl
> perl mysqltuner.pl
Una vez hecho esto, el script te puede devolver unos resultados similares a estos:
MySQLTuner 1.0.1 - Major Hayden <major@mhtx.net>
Bug reports, feature requests, and downloads at https://mysqltuner.com/
Run with '--help' for additional options and output filtering
-------- General Statistics --------------------------------------------------
[--] Skipped version check for MySQLTuner script
[OK] Currently running supported MySQL version 5.0.45
[OK] Operating on 32-bit architecture with less than 2GB RAM
-------- Storage Engine Statistics -------------------------------------------
[--] Status: -Archive -BDB -Federated +InnoDB -ISAM -NDBCluster
[--] Data in MyISAM tables: 156M (Tables: 390)
[--] Data in InnoDB tables: 2M (Tables: 126)
[!!] Total fragmented tables: 46
-------- Performance Metrics -------------------------------------------------
[--] Up for: 18m 8s (296K q [272.847 qps], 689 conn, TX: 1B, RX: 39M)
[--] Reads / Writes: 94% / 6%
[--] Total buffers: 35.0M global + 2.7M per thread (100 max threads)
[OK] Maximum possible memory usage: 303.7M (33% of installed RAM)
[OK] Slow queries: 0% (0/296K)
[OK] Highest usage of available connections: 8% (8/100)
[OK] Key buffer size / total MyISAM indexes: 8.0M/52.0M
[OK] Key buffer hit rate: 99.2% (2M cached / 21K reads)
[OK] Query cache efficiency: 81.6% (237K cached / 291K selects)
[!!] Query cache prunes per day: 3650717
[OK] Sorts requiring temporary tables: 0% (0 temp sorts / 5K sorts)
[!!] Joins performed without indexes: 33
[!!] Temporary tables created on disk: 26% (1K on disk / 7K total)
[!!] Thread cache is disabled
[OK] Table cache hit rate: 48% (128 open / 265 opened)
[OK] Open file limit used: 11% (229/2K)
[OK] Table locks acquired immediately: 99% (73K immediate / 73K locks)
[!!] InnoDB data size / buffer pool: 2.0M/2.0M
-------- Recommendations -----------------------------------------------------
General recommendations:
Run OPTIMIZE TABLE to defragment tables for better performance
MySQL started within last 24 hours - recommendations may be inaccurate
Enable the slow query log to troubleshoot bad queries
Adjust your join queries to always utilize indexes
When making adjustments, make tmp_table_size/max_heap_table_size equal
Reduce your SELECT DISTINCT queries without LIMIT clauses
Set thread_cache_size to 4 as a starting value
Variables to adjust:
query_cache_size (> 8M)
join_buffer_size (> 128.0K, or always use indexes with joins)
tmp_table_size (> 60M)
max_heap_table_size (> 16M)
thread_cache_size (start at 4)
innodb_buffer_pool_size (>= 2M)
En temas de optimización nunca hay que tocar las cosas alegremente, por lo que ahora lo que toca es estudiar la información y las recomendaciones que propone el script e ir aplicando las que nos parezcan más acertadas para mejorar el rendimiento.
- La primera recomendación es que se ejecute el comando OPTIMIZE TABLE sobre varias tablas en las que ha detectado que existe fragmentación. Para ello hay que averiguar qué tablas pueden requerir una defragmentación y aplicar este comando sobre ellas.
- Las siguientes recomendaciones ya son sugerencias sobre los parámetros de la BD.
La aplicación muestra unos valores de inicio en los casos en que la propuesta es aumentar el valor. Lo mejor es ir subiendo poco a poco e ir validando si obtenemos mejoras de velocidad, y también que no llegamos a utilizar más memoria de la que tenemos disponible.
Para modificar los valores de los parámetros se puede editar el fichero my.cnf, que suele encontrarse en el directorio /etc
En este caso, por ejemplo, podríamos haber insertado en nuestro my.cnf las lineas
# Parametros modificados por recomendaciones de sqltuner query-cache-size = 16M join-buffer-size = 256K tmp-table-size = 90M max-heap-table-size = 90M thread-cache-size = 4 innodb-buffer-pool-size = 4M # Fin de modificaciones de optimizacion
Después hay que reiniciar la base de datos para que estos cambios surtan efecto.
Comentar por último que para que la información que nos proporciona el script sea fiable, la base de datos debería llevar funcionando ininterrumpidamente por lo menos 24 horas, por lo que para ir ajustando los valores con ejecuciones de sqltuner no sirve modificar los parámetros y volver a ejecutar el script al momento.
Después de reiniciar la BD para aplicar los cambios hay que esperar un dia o dos antes de volver a pedir ayuda al script para tunear nuestra base de datos.
Consulta, ¿Como podria yo
Consulta,
¿Como podria yo ejecutar este script pero sobre un motor MySQL montado en Windows?
Muchas Gracias
- Inicie sesión para enviar comentarios

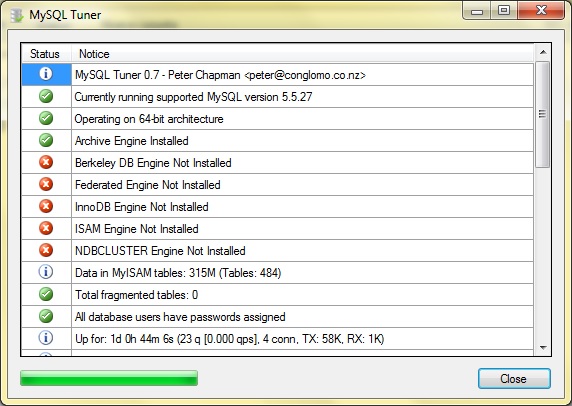
Creo que vas a tener suerte
Creo que vas a tener suerte porque existe un proyecto de migración del script de Perl a una aplicación Windows. Te enlazo la página de CodePlex donde puedes descargar esta utilidad de tuning de MySQL.
Sólo tienes que descargarla, descomprimir el zip, y ejecutar MySQLTuner.exe
Ya nos dirás si te va bien, porque aún es una aplicación en fase beta. Yo la acabo de probar y al menos te puedo decir que me ha funcionado:
- Inicie sesión para enviar comentarios
Estructura de la Dimensión Tiempo y Procedure de carga para MySQL
Estructura de la Dimensión Tiempo y Procedure de carga para MySQL bernabeu_dario 29 Julio, 2009 - 17:22Buenas.
Este post esta basado en el de il-masacratore, más precisamente en su última entrada: Estructura de la dimensión tiempo y script de carga para SQLServer. Tal y como dice il-masacratore casi siempre existen una serie de dimensiones que son comunes para todo DW, la dimensión Tiempo es una de ellas.
El objetivo de este post es traducir lo hecho por il-masacratore (SQLServer) para que pueda ser ejecutado en MySQL.
Cabe destacar que esta estructura y su consiguiente procedure, tienen fines explicativos y ejemplificadores, para que cada unx pueda luego crear su propia Dimensión Tiempo de acuerdo a sus necesidades y preferencias.
CREACION DE ESTRUCTURA DE LA DIMENSION TIEMPO
CREATE TABLE `dwventas`.`DIM_TIEMPO` (
`FechaSK` int(11) NOT NULL,
`Fecha` date NOT NULL,
`Anio` smallint(6) NOT NULL,
`Trimestre` smallint(6) NOT NULL,
`Mes` smallint(6) NOT NULL,
`Semana` smallint(6) NOT NULL,
`Dia` smallint(6) NOT NULL,
`DiaSemana` smallint(6) NOT NULL,
`NTrimestre` varchar(7) NOT NULL,
`NMes` varchar(15) NOT NULL,
`NMes3L` varchar(3) NOT NULL,
`NSemana` varchar(11) NOT NULL,
`NDia` varchar(15) NOT NULL,
`NDiaSemana` varchar(15) NOT NULL,
PRIMARY KEY (`FechaSK`)
) ENGINE=MyISAM DEFAULT CHARSET=latin1
CREACION DEL PROCEDURE DE CARGA
DELIMITER $$
DROP PROCEDURE IF EXISTS `dwventas`.`antDIM_TIEMPO`$$
CREATE DEFINER=`root`@`localhost` PROCEDURE `antDIM_TIEMPO`()
BEGIN
delete from DIM_TIEMPO;
SELECT '2006-01-01' INTO @fi;
SELECT '2009-07-29' INTO @ff;
while (@fi <= @ff) DO
INSERT INTO DIM_TIEMPO
(
FechaSK,
Fecha,
Anio,
Trimestre,
Mes,
Semana,
Dia,
DiaSemana,
NTrimestre,
NMes,
NMes3L,
NSemana,
NDia,
NDiaSemana
)
SELECT year(@fi)*10000+month(@fi)*100+day(@fi) as FechaSK,
(@fi) Fecha,
year(@fi) Anio,
quarter(@fi) Trimestre,
month(@fi) Mes,
week(@fi) Semana,
RIGHT(concat('0',day(@fi)),2) Dia,
weekday(@fi) DiaSemana,
concat('T',quarter(@fi),'/',year(@fi))NTrimestre,
monthname(@fi) NMes,
LEFT(monthname(@fi),3) NMes3L,
concat('Sem ',week(@fi) ,'/', year(@fi)) NSemana,
concat(RIGHT(concat('0',day(@fi)),2),' ',monthname(@fi)) NDia,
dayname(@fi) NDiaSemana;
set @fi = DATE_ADD(@fi, INTERVAL 1 DAY);
END WHILE;
END$$
DELIMITER ;
il-masacratore gracias por compartir!
Espero les sea útil.
Saludos.
Excelente!!! Muchas gracias
Excelente!!! Muchas gracias por compartir. Lo único que agregué fue la localización con lc_time_names = 'es_AR' para Español Argentina.
- Inicie sesión para enviar comentarios
MySql Query Profiling
MySql Query Profiling il_masacratore 24 Diciembre, 2013 - 10:44Desde la versión 5 de MySql se incorpora al cliente esta funcionalidad para conocer más al detalle los tiempos de ejecución de cada consulta. Si activamos esta opción podremos ver desglosadas las partes que la forman y en como se distribuye el tiempo total de la consulta. Para buscar problemas en determinados procesos o descubrir donde está el cuello de botella es un opción bastante útil. En si, de una manera muy simplificada, nos puede mostrar información similar a la que nos puede dar MS SQL Server Profiler aunque con una diferencia muy importante: solo podemos analizar las consultas de nuestra sesión actual y las que ejecutamos a partir de su activación con un cambio de parámetro.
Eso quiere decir que no podemos atacar directamente a las aplicaciones si no que debemos cazar las consultas problemáticas al vuelo del log de slow-querys o del log de mysql...
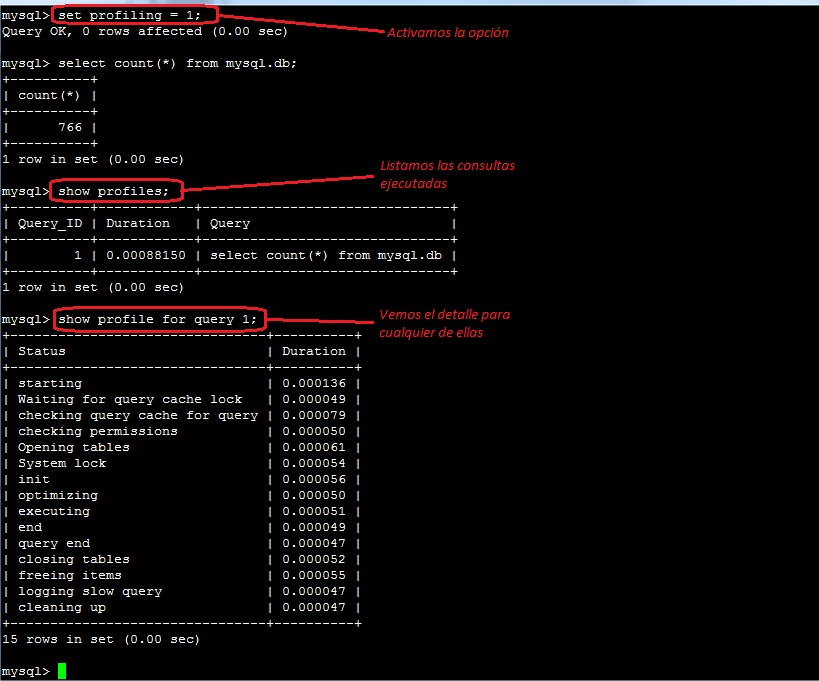
Vamos a ver como funciona. Primero lo habilitamos para la sesión actual:
mysql> set profiling = 1; Query OK, 0 rows affected (0.00 sec)
A continuación ejecutamos una consulta de ejemplo:
mysql> select count(*) from mysql.db; +----------+ | count(*) | +----------+ | 766 | +----------+ Query OK, 0 rows affected (0.00 sec)
Luego, para ver el detalle usamos show profile:
mysql> show profile for query 1; +--------------------------------+----------+ | Status | Duration | +--------------------------------+----------+ | starting | 0.000143 | | Waiting for query cache lock | 0.000048 | | checking query cache for query | 0.000070 | | checking permissions | 0.000050 | | Opening tables | 0.000058 | | System lock | 0.000052 | | init | 0.000054 | | optimizing | 0.000050 | | executing | 0.000052 | | end | 0.000048 | | query end | 0.000047 | | closing tables | 0.000051 | | freeing items | 0.000055 | | logging slow query | 0.000047 | | cleaning up | 0.000048 | +--------------------------------+----------+ Query OK, 0 rows affected (0.00 sec)
El caso anterior es un ejemplo muy trivial, vemos que los tiempos son ínfimos y el resultado es el esperado. Realmente no hay nada que buscar. También es útil saber que si usamos un script, podemos ver con posterioridad un listado con las consultas que se han ejecutado, aunque vereis que a cada consulta desde la activación del parámetro se le asigna un autoincremental. También sirve simplemente para comparar tiempos totales de ejecución de consultas consecutivas ejecutadas con el profiling acivado. Para listarlas ejecutamos show profiles:
mysql> show profiles; +----------+------------+-------------------------------+ | Query_ID | Duration | Query | +----------+------------+-------------------------------+ | 1 | 0.00086975 | select count(*) from mysql.db | +----------+------------+-------------------------------+ 1 rows in set (0.00 sec)
En otros casos, quizás más reales, podemos tener una consulta que tarda mucho en ejecutarse en mysql y lo descubrimos porque tenemos habilitado y/o controlamos de vez en cuando las slow querys que se ejecutan sobre la base de datos. Investigamos más, vemos su plan de ejecución y aparentemente usa índice aunque está haciendo una join entre dos tablas además de tener una ordenación. Nada raro... Aparentemente. Por ejemplo, hemos podido creer que se estaban usando los índices, pero existe la posibilidad de que sin darnos cuenta los estemos inhabilitando porque sin percatarnos estamos usando una conversión implicita en la condición de unión que está obligando a la base de datos a crear una copia temporal de la tabla (además para aplicar una ordenación!). La salida del profiler podría ser algo así:
mysql> show profile for query 4; +--------------------------------+-----------+ | Status | Duration | +--------------------------------+-----------+ | starting | 0.000100 | | Waiting for query cache lock | 0.000048 | | checking query cache for query | 0.000116 | | checking permissions | 0.000048 | | checking permissions | 0.000046 | | checking permissions | 0.000047 | | checking permissions | 0.000048 | | Opening tables | 0.000065 | | System lock | 0.000051 | | Waiting for query cache lock | 0.000067 | | init | 0.000081 | | optimizing | 0.000061 | | statistics | 0.000099 | | preparing | 0.000070 | | executing | 0.000047 | | Sending data | 0.078635 | | Waiting for query cache lock | 0.000075 | | Sending data | 0.000047 | | storing result in query cache | 16.043585 | | end | 0.000119 | | query end | 0.000051 | | closing tables | 0.000052 | | freeing items | 0.000061 | | logging slow query | 0.000047 | | logging slow query | 0.000047 | | cleaning up | 0.000050 | +--------------------------------+-----------+ 26 rows in set (0.00 sec)
Viendo esto pensamos wow! Algo falla con la cache. Pues entonces miramos de deshabilitarla para la sesión actual y entonces volvemos a ejecutar la consulta para finalmente ver el profile...
mysql> SET SESSION query_cache_type = OFF; Query OK, 0 rows affected (0.00 sec)
mysql> show profile for query 7; +----------------------+-----------+ | Status | Duration | +----------------------+-----------+ | starting | 0.000206 | | checking permissions | 0.000049 | | checking permissions | 0.000047 | | checking permissions | 0.000047 | | checking permissions | 0.000048 | | Opening tables | 0.000067 | | System lock | 0.000052 | | init | 0.000081 | | optimizing | 0.000062 | | statistics | 0.000103 | | preparing | 0.000073 | | executing | 0.000048 | | Sending data | 16.554224 | | end | 0.000124 | | query end | 0.000048 | | closing tables | 0.000052 | | freeing items | 0.000062 | | logging slow query | 0.000048 | | logging slow query | 0.000048 | | cleaning up | 0.000049 | +----------------------+-----------+ 20 rows in set (0.00 sec)
Finalmente ya vemos ya que el problema es en el envío de datos. Esto ya nos tiene que llevar a pensar que la consulta puede ser optimizable. Usaremos explain para ver el plan de ejecución y pensar si es mejorable la consulta, la indexación etc...
En conclusión...
... Mysql Query Profiler me parece útil como algo complementario al EXPLAIN para ver planes de ejecución. Si con EXPLAIN podremos ver problemas derivados de la planificación o la forma de la consulta, con Query Profiler podremos ver otro tipo de incidencias. Me imagino que en ocasiones donde tengamos problemas a nivel de servidor, demasiada concurrencia, algun parámetro olvidado que ralentiza (slow querys), falta de memoria etc saltarán malos tiempos a la vista si sabemos cuales son los tiempos base o los aceptables, aunque para temas de optimización general de MySQL es mejor utilizar otros métodos para mejorar el rendimiento.
En otro post explicaré un poquito como funciona EXPLAIN y lo que no nos gustará encontrar al utilizarlo.
Como hacer un update from select en MySQL
Como hacer un update from select en MySQL Carlos 9 Marzo, 2018 - 21:17
Una de las sentencias más útiles en SQL es la de Update a partir de una Select mediante una join entre la tabla que se va a actualizar y la tabla de la que se van a buscar los nuevos valores que se escribirán.
En MySQL esta sentencia se puede hacer con esta sencilla sintaxis:
update tabla1 inner join tabla2 on tabla1.id_tabla2 = tabla2.id set tabla1.campo=tabla2.language
Un ejemplo real:
update field_data_body inner join node on field_data_body.entity_id=node.nid set field_data_body.language=node.language
Ojo con la correspondencia entre campos mejor de 1 a 1
.jpg) Lo único que hay que tener en cuenta es que el campo por el que se hace la join lo ideal es que sea clave en la segunda tabla, porque si no a cada valor de un registro del campo a actualizar le podría corresponder más de un valor en la tabla con la que se hace la join.
Lo único que hay que tener en cuenta es que el campo por el que se hace la join lo ideal es que sea clave en la segunda tabla, porque si no a cada valor de un registro del campo a actualizar le podría corresponder más de un valor en la tabla con la que se hace la join.
En ese caso, podemos encontrarnos con resultados no esperados, ya que la actualización se realizará con el valor de sólo uno de los registros con los que enlace cada registro de la primera tabla.
Si es lo que buscamos ya está bien, pero si la correspondencia es de uno a varios registros y lo que queremos es guardar en cada campo de la primera tabla un valor agregado, como la suma, la media o el valor máximo, de todos los registros que tienen correspondencia en la segunda tabla, tendremos que complicar un poco más la sentencia.
Este tema lo comento en detalle el post Como hacer en SQLServer un update a partir de una select con registros agregados, es sobre SQL Server, pero para aplicarlo a MySQL sólo hay que adaptar la sintaxis.
Cómo revisar el estado de una base de datos MySQL que no responde
Cómo revisar el estado de una base de datos MySQL que no responde Carlos 8 Marzo, 2018 - 08:51 Comandos básicos para revisar el estado de una base de datos mysql que no responde, y para pararla, arrancarla o reiniciarla desde consola si es necesario. Estos comandos con para un MySQL instalado sobre Linux CentOS:
Comandos básicos para revisar el estado de una base de datos mysql que no responde, y para pararla, arrancarla o reiniciarla desde consola si es necesario. Estos comandos con para un MySQL instalado sobre Linux CentOS:
Comprobar estado de mysql
/etc/init.d/mysqld status
Arrancar mysql
/etc/init.d/mysqld start
Parar mysql
/etc/init.d/mysqld stop
Reiniciar mysql
/etc/init.d/mysqld restart
Si el estado devuelve algún error, o al reiniciar falla algo, como por ejemplo:
# /etc/init.d/mysqld restart Stopping mysqld: [ OK ] Timeout error occurred trying to start MySQL Daemon. Starting mysqld: [FAILED]
Revisar el fichero de log de MySQL
Para ir a ver directamente las últimas líneas registradas en el log:
# tail /var/log/mysqld.log
Si hay que examinar más líneas, editar el fichero con vi y, una vez dentro, pulsar la tecla 'Escape' y escribir 'G' para ir al final, donde están los registros más recientes:
# vi /var/log/mysqld.log
En el fichero de log puedes encontrarte un problema como este, por ejemplo:
180225 9:17:08 [Warning] Disk is full writing './mydatabase/watchdog.MYD' (Errcode: 28). Waiting for someone to free space... (Expect up to 60 secs delay for server to continue after freeing disk space)
(Para salir del editor vi, pulsar 'Escape' y escribir ':wq!')
Si se tratara de un problema de espacio, que es lo que a mi me pasa casi siempre, enlazo otro tema con comandos para comprobar el estado de las particiones, ocupación y cómo buscar ficheros grandes para hacer limpieza y liberar el espacio del servidor.
Cuando hay problemas en un
Cuando hay problemas en un servidor con LAMP, otra cosa que es importante comprobar es el estado del servidor Apache, estos son los comandos para hacerlo en un Linux CentOS:
Comprobar estado de Apache
/etc/init.d/httpd status
Arrancar el servicio de Apache
/etc/init.d/httpd start
Parar el servicio de Apache
/etc/init.d/httpd stop
Reiniciar Apache
/etc/init.d/httpd restart
Directorio de logs de Apache
El directorio de logs de Apache en CentOS suele estar en /var/log/httpd, así que para consultar las últimas entradas del fichero de log de errores de Apache se puede utilizar:
# tail /var/log/httpd/error_log
(si los logs de Apache no están en este directorio, en el fichero '/etc/httpd.conf' se puede consultar dónde se encuentran los logs de Apache)
- Inicie sesión para enviar comentarios
Conectar con una base de datos MySQL remota
Conectar con una base de datos MySQL remota Carlos 19 Octubre, 2011 - 17:29MySQL tiene algunas particularidades a la hora de realizar una conexión desde un cliente remoto que si no las sabemos nos pueden complicar un poco el acceso a una base de datos MySQL desde una máquina diferente a la que aloja la BD.
Con otras bases de datos, como Oracle o SQL Server, una vez que ningún firewall ni nada por el estilo nos impide acceder desde la máquina cliente a la servidora, con utilizar los datos de acceso de un usuario de base de datos normalmente ya se puede 'entrar'.
Con MySQL, aunque el acceso al puerto, normalmente el 3306, esté abierto, la base de datos puede estar configurada para no dejar pasar conexiones externas, y el resultado es el mismo que si el puerto estuviera cerrado por un firewall:
telnet mysql.dataprix.es 3306 Trying 188.166.233.199... telnet: connect to address 188.166.233.199: Connection refused telnet: Unable to connect to remote host
Si se obtiene este resultado conviene consultar en el servidor de MySQL el fichero 'my.cnf', ubicado normalmente en /etc en Linux, o el 'my.ini' ubicado normalmente en la raíz del directorio de datos en el que se ha instalado MySQL en sistemas Windows, y comprobar si contiene las variables bind-address o skip-networking.
Si se encuentra skip-networking y no está comentada, hay que editar el fichero y eliminarla, o convertirla en un comentario para que no tenga efecto y se permitan conexiones externas:
#skip-networking
Si se encuentra bind-address=127.0.0.1 o bind-address= localhost también hay que editarlo y cambiar el valor por el de la ip externa desde la que se quiera conectar (sólo se permite una), o por 0.0.0.0 para dejar pasar todas, y después filtrarlas por otros medios (firewall o seguridad a nivel de control de acceso)
bind-address=0.0.0.0
Con esto, después de reiniciar la base de datos, el telnet anterior ya debería aceptar nuestra conexión externa por el puerto 3306
MySQL tiene además un mecanismo de seguridad de control de acceso que tiene en cuenta, aparte del usuario y contraseña, la IP o el dominio de la máquina desde la que se realiza la conexión. Desde el mismo servidor (localhost) normalmente se puede conectar, pero si se accede desde un cliente o servidor externo hay que asegurarse de que la combinación IP/Dominio + Usuario tiene permiso de acceso a la base de datos.
Si hemos pasado la prueba del telnet y al intentar conectar con un usuario/password correcto obtenemos un mensaje de error parecido a este:
Access denied for user 'miuser'@'55.66.77.88' (using password: YES)
Es cuestión de conectar a la base de datos con el usuario administrador, abriendo una sesión en el servidor por ssh, o con phpMyAdmin, por ejemplo, y en la base de datos 'mysql', consultar el valor del campo 'Host' para el 'User' con el que se intenta conectar.
Si el valor es 'localhost', este usuario sólo puede conectar desde el mismo server, por eso se rechaza la conexión remota. Si el valor fuera '%' se podría conectar desde cualquier máquina, y habría que buscar otra razón para el mensaje de error.
Este valor se puede modificar por el dominio o el valor de la ip de la máquina desde la que se quiere conectar, y se pueden utilizar caracteres comodín como % para permitir rangos de ip's.
Para consultar las diferentes opciones, el capítulo Control de acceso, nivel 1: Comprobación de la conexión del manual de referencia de MySQL lo explica detalladamente.
Por ejemplo, para dar acceso y privilegios a 'miuser' para todas las bases de datos del server desde la ip '55.66.77.88':
GRANT ALL PRIVILEGES ON db.* to miuser@'55.66.77.88' IDENTIFIED BY 'password'; flush privileges;
Nota: Para saber qué bases de datos tenemos disponibles en el servidor de MySQL se puede utilizar el comando 'Show databases'. Así se puede consultar el nombre de la base de datos a escribir en lugar del * en 'db.*' si se quiere conceder acceso sólo a alguna BD concreta:
mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | dwh_dataprix | | mysql | | performance_schema | | practico | | stg_dataprix | | sys | +--------------------+ 7 rows in set (0.00 sec)
Waiting for table metadata lock en MySql
Waiting for table metadata lock en MySql il_masacratore 28 Enero, 2014 - 12:01 "Waiting for table metadata lock"... Este error nos lo encontramos en MySql al lanzar una consulta del tipo DDL. Se produce normalmente al lanzar una consulta para modificar un objeto que está siendo usado actualmente en nuestra base de datos. Empezaremos a lidiar con él a partir de la versión 5.5 de MySql y a consecuencia de la introducción de un nuevo tipo de bloqueos: "metadata locking".
"Waiting for table metadata lock"... Este error nos lo encontramos en MySql al lanzar una consulta del tipo DDL. Se produce normalmente al lanzar una consulta para modificar un objeto que está siendo usado actualmente en nuestra base de datos. Empezaremos a lidiar con él a partir de la versión 5.5 de MySql y a consecuencia de la introducción de un nuevo tipo de bloqueos: "metadata locking".
Por que sucede
Mysql 5.5 usa el bloqueo a nivel de metadatos (metadata locking) para controlar el acceso a los diferentes tipos de objetos ya sean tablas, triggers etc. El motor de la base de datos lo usa para asegurar la consistencia pero a la vez supone un posible cambio en la manera de trabajar. La gracia del metadata lock es evitar cambios en la estructura de tablas mientras se esta trabajando con ella en una transacción anterior al cambio. En versiones anteriores esto no tenia lugar porque este bloqueo tenia lugar a nivel de consulta, no de transacción. Durante la transacción de la conexión a, podemos hacer un cambio desde la conexión b que mysql se la come.
Volviendo a Mysql 5.5 vamos a poner una situación de ejemplo para entenderlo. Antes estábamos en un nuevo desarrollo y modificábamos las tablas en el entorno de desarrollo a nuestro gusto para luego trasladar los cambios al entorno de producción "on-the-fly". Ahora, si no queremos problemas, esto ya no nos valdrá por este nuevo tipo de bloqueos. Ese cambio en producción será más tedioso. Aunque sepamos que a nivel lógico no supone un problema trasladar el cambio al entorno de producción, debemos asegurarnos que no hayan transacciones abiertas que impliquen al objeto. Generalmente lo haremos parando la aplicación que pueda usar esa tabla por muy pocos segundos, ya que la alternativa sería lanzar el alter y matar una a una las sesiones anteriores. En el último caso podemos hacer trampa si la tabla involucrada es Innodb y podemos usar SHOW ENGINE InndoDb STATUS para ver transacciones abiertas. Si es myisam no podremos saberlo más que por la antigüedad de la sesión.
Reflexionando un poco y contrariamente a lo que podríamos pensar la primera vez que lo vemos, una sesión que se queda en estado "Waiting for metadata lock" puede usar solo tablas myisam. Este tipo de bloqueos es independiente y no va ligado a tablas innodb, sino a cualquier tipo.
Vamos con un ejemplo específico
Para ejemplificarlo de forma sencilla, basta con abrir una conexión Mysql (a), deshabilitamos para esa sesión el autocommit, creamos una tabla y hacemos un select sobre ella. A continuación abrimos una nueva conexión para lanzar un alter table sobre la tabla creada por la primera conexión y ya tenemos el bloqueo.
/*Conexión (a)*/ CREATE TABLE test (ID int) ENGINE=myisam; SET @@autocommit=0; SELECT * FROM test;
/*Conexión (b)*/ ALTER TABLE test RENAME TO prueba;
/*Conexión (c) para ver como se queda esperando:*/ mysql> show full processlist; +----+---+-------+---------------------------------+------------------------------------+ | Id |...| Time | State | Info | +----+---+-------+---------------------------------+------------------------------------+ | 1 |...| 1653 | | NULL | | 2 |...| 0 | NULL | show full processlist | | 3 |...| 18012 | Waiting for table metadata lock | ALTER TABLE test RENAME TO prueba | +----+---+-------+---------------------------------+------------------------------------+
Como vemos, tiene lugar el bloqueo aunque sea una tabla myisam. Aunque en esta prueba hemos cambiado a saco el nombre de la tabla, podemos hacer algo menos a saco como añadir nuevos campos. En el anterior, para deshacer el bloqueo y que termine el alter de la segunda tabla basta con cerrar la transacción de la primera conexión.
Convivir con ello
Por el momento y que yo sepa, no hay manera directa de saber quién mantiene este tipo de bloqueo sobre un objeto. Entonces no nos queda otra que lidiar con ello y solo podemos hacerlo proveyendo este tipo de situaciones. Según nuestro entorno podemos intentar adaptarnos de la siguiente manera:
- De forma preventiva, Si no usamos conexiones persistentes contra la base de datos, podemos cambiar el valor de wait_tiemout y ajustarlo al mínimo posible. Wait_timeout es el número de segundos que el servidor espera para recibir actividad en una conexión no interactiva antes de cerrarla. Me imagino que en un entorno web, esto es fácilmente ajustable a 30-60 segundos, mientras que en otro tipo de aplicaciones no será posible.
- Detener momentáneamente las aplicaciones que potencialmente usan los objetos implicados. Obvio aunque no siempre es posible hacerlo.
- Garantizar un tratamiento correcto a nivel de transacciones por nuestras aplicaciones. Si nos encontramos con bloqueos del tipo waiting for metadata lock a menudo, deberíamos hacer un repasillo para conocer como funcionan exactamente las transacciones que usan las tablas implicadas.
- Chequear las sesiones abiertas en producción que sean anteriores a la que va a ejecutar el ALTER. En el entorno de desarrollo no importa si nos cuesta y si matamos sesiones de manera indiscriminada. Incluso, podemos reiniciar mysql y ejecutar el alter lo primero antes de que entren nuevas conexiones. En cambio, en producción nos interesa mucho ser más selectivos y cerrar conexiones de forma quirúrgica. La manera más fácil puede ser consultar la tabla information_schema.processlist y buscar las sesiones por id (asignado de forma secuencial por mysql). Por ejemplo así obtenemos los Kill necesarios:
SELECT concat('KILL ',ID, ';')
FROM INFORMATION_SCHEMA.PROCESSLIST
WHERE ID < connection_id();Por último, es interesante saber como se relaciona el bloqueo de metadatos y la query_cache. No había caído en la cuenta pero es posible que el bloqueo no tenga lugar para consultas sql posteriores mientras dure el bloqueo si la consulta está cacheada. Esto esta bien saberlo y nos puede explicar alguna excepción que nos encontremos, pero no creo que lo podemos considerar para beneficiarnos de ello. Comentar que en MariaDb también podemos sufrir metadata locking.

En conclusión...
... con esta nueva forma de proceder del motor de MySql incluyendo este nuevo tipo bloqueo, están garantizando realmente la integridad de las transacciones en sus tablas implicadas. Es tedioso tenerlo en cuenta al principio y sorprende cuando lo ves por primera vez, pero de peores hemos salido.
Migrar Pentaho 6 a MySQL en 10 pasos
Migrar Pentaho 6 a MySQL en 10 pasosbernabeu_dario
Recursividad en MYSQL con Java
Recursividad en MYSQL con Java magm 13 Diciembre, 2012 - 14:28Hola Estimd@s,
He sacado algunas cosas del baúl y las quiero compartir, en este caso se trata de una clase Java que permite ejecutar consultas recursivas en MySQL, la idea surgió a partir de una necesidad en primera instancia y luego me base en la forma en que DB2 la lleva a cabo. Tengo la idea (cuando me haga de algún tiempo) de escribir algún articulo relacionado con recursividad en DB2 ya que es muy útil y por demás interesante. Por ahora solo esto.
Pueden descargar la clases desde aquí:
Copio el readme.txt que escribí para poder usar esta clase.
Esta clase está basada en la idea de recursividad de DB2.
La clase ar.com.magm.jdbc.SQLRecursivo permite implementar
recursividad en MySQL.
Aún no está bien testeada la indexación que es fundamental
cuando se trabaja con muchos datos
La tabla con la que funciona la demo (clase Test) es:
CREATE TABLE `practico`.`arbol` (
`idPadre` integer NOT NULL,
`idHijo` integer NOT NULL,
`cantidad` integer NOT NULL,
PRIMARY KEY (`idPadre`, `idHijo`)
)
Algunos datos:
INSERT INTO `practico`.`arbol` VALUES
(3,8,1),
(5,6,3),
(2,5,2),
(1,4,2),
(1,3,2),
(1,2,1);
Forma el siguiente árbol:
1
+--2
| +--5
| +--6
|
+--3
| +--8
|
+--4
El uso es muy simple, solo hay que crear una instancia de la clase
SQLRecursivo, el constructor pideuna conexión JDBC, ejemplo;
SQLRecursivo sqlRec = new SQLRecursivo(cn);
Luego llamar al método:
recursivo(consultaInicial, aliasTablaPadre, consultaRecursiva, indexKey)
Este método retornará el resultado en forma de ResultSet.
Los parámetros son:
@param consultaInicial
consulta que produce la población inicial de datos.
@param aliasTablaPadre
alias que se utilizará en la consulta recursiva para la tabla padre
@param consultaRecursiva
consulta que obtiene el resto de los datos en forma recursiva.
Esta consulta contiene la lógica de corte de cotrol.
Se hace referencia a la tabla padre con: //TablaPadre//
@param indexKey
representa la clave del índice/indices que se crearán sobre la
tabla padre, la forma es:
(opciones indice1)\t(clave indice1)\n(opciones indice2)\t(clave indice2),
en otras palabras el \n determina la cantidad de índices a crear,
el \t separa las opciones de la clave.
Para no crear ningún índice enviar "" o null.
Ejemplo:
UNIQUE CLUSTERED\tidHijo,idFiltroArbol,idFiltroGeneral\nNONCLUSTERED\tcc
Se crearán:
CREATE UNIQUE CLUSTERED INDEX IX0_##TablaPadre ON ##TablaPadre (idHijo,idFiltroArbol,idFiltroGeneral)
y
CREATE NONCLUSTERED INDEX IX1_TablaPadre ON ##TablaPadre (cc)
Se recomienda probar en el test las siguientes consultas:
String consultaInicial = "SELECT idPadre,idHijo FROM arbol where idPadre=1";
//Obtiene el árbol completo
para obtener el árbol completo o:
String consultaInicial = "SELECT idPadre,idHijo FROM arbol where idPadre=2";
//Obtiene el subarbol del nodo 2
En la consulta recursiva se puede (y en general se debe) hacer referencia a
la tabla padre (consulta inicial), esto se hace con la expresión: //TablaPadre//,
esto se puede ver en el ejemplo. La tabla tiene un alias, que este ejemplo
es 'padre' y es el segundo argumento del método recursivo.
Por ello en la consulta se ve:
... a.idPadre=padre.idHijo
String consultaRecursiva =
"SELECT a.idPadre,a.idHijo FROM arbol a,//TablaPadre// WHERE a.idPadre=padre.idHijo";
Enjoy,
Mariano
ERROR 1146 (42S02): Table 'mysql.servers' doesn't exist
ERROR 1146 (42S02): Table 'mysql.servers' doesn't exist Carlos 12 Enero, 2011 - 18:10Tras hacer una actualización con YUM UPDATE he tenido algunos problemas con una BD MySQL. Concretamente me salía el Error 1146 (42S02): Table 'mysql.servers' doesn't exist cada vez que quería ejecutar el comando flush privileges, o al crear usuarios con PLESK, que supongo que al final debe ejecutar el mismo comando.
El problema lo he solucionado creando la tabla manualmente, que es lo que he podido encontrar buscando información sobre este error:
mysql> USE mysql;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> CREATE TABLE `servers` (
-> `Server_name` char(64) NOT NULL,
-> `Host` char(64) NOT NULL,
-> `Db` char(64) NOT NULL,
-> `Username` char(64) NOT NULL,
-> `Password` char(64) NOT NULL,
-> `Port` int(4) DEFAULT NULL,
-> `Socket` char(64) DEFAULT NULL,
-> `Wrapper` char(64) NOT NULL,
-> `Owner` char(64) NOT NULL,
-> PRIMARY KEY (`Server_name`)
-> ) ENGINE=MyISAM DEFAULT CHARSET=utf8
-> COMMENT='MySQL Foreign Servers table';
Query OK, 0 rows affected (0.04 sec)
De momento funciona bien, ya puedo crear usuarios tranquilamente y ejecutar flush privileges sin problemas, pero no me quedo muy tranquilo, supongo que el problema real es que la actualización no fue del todo bien.
Durante la actualización todo estaba OK, pero me daba un warning sobre un script de update. Yo entendí que me decía que lo había ejecutado, pero podría ser que me faltara por ejecutar este script manualmente? Tengo la versión 5.1 de MySQL sobre un SO Linux CentOS.
Buenas, Después de una
Buenas,
Después de una actualización de mysql a una versión superior, ante cualquier problema de creación o alteración de una tabla de sistema (mysql.) puedes hacer lo mismo que has hecho de forma automática ejecutando en linea de comandos la utilidad mysql_upgrade --force. Esta lo que hace es adecuar las tablas de sistema y dejarlas niqueladas para la versión actual: creando tablas y campos faltantes...
Si eso antes de liarla, si la base de datos arranca con algun warning siempre estas a tiempo de hacer un backup lógico o una simple copia de ficheros con la bbd parada antes de liarla más...
Saludos,
- Inicie sesión para enviar comentarios
Cuatro planteamientos distintos para migrar mysql cambiando de servidor
Cuatro planteamientos distintos para migrar mysql cambiando de servidor il_masacratore 8 Noviembre, 2013 - 16:09
Hay diferentes maneras de migrar de un servidor a otro una base de datos MySql. Hay factores como la versión, capacidad del servidor/res, volumen de datos, tiempo sin servicio y demás que nos limitan para elegir la mejor manera de hacerlo. También es otro factor si tenemos cluster, si migramos a un nuevo servidor etc. En este caso os expongo cuatro maneras de hacerlo para cambiar de servidor y/o versión.
- Copy&paste
Si tenemos la suerte que la versión de mysql será la misma que la actual podemos arriesgarnos a transferir los datafiles y binlogs(si es el caso) de un servidor a otro. No es del todo adecuada pero si paramos de forma correcta la base de datos en el momento de la copia no nos debería suponer ningún problema. Aquí el tiempo del corte vendrá determinado por la duración de la transferencia de archivos de un servidor a otro.
- Upgrade+Copy+paste
Si queremos hacer algo similar a lo anterior pero tenemos en el servidor actual una versión anterior a la nueva lo mejor que podemos hacer es actualizar la versión de MySql en origen antes de transferir los archivos a destino. Supone algo más de tiempo, entre que actualizamos y probamos, pero no debería suponer mayor problema.
#mysql_upgrade --user root --password --force
- Exportación e importación
En algún caso por algún motivo especial necesitaremos hacer la migración mediante un dump usando mysqldump. Un ejemplo sería tener una base de datos con tablas innoDb que han crecido demasiado (gb) y nos interesa separar el fichero propio de innoDb de datos e índices y que nos quede uno por cada tabla (incluyendo inno_db_file_per_table). Aquí no hay más que reconstruir tabla a tabla o directamente esperar al dump. De esta manera la duración del corte de servicio vendrá condicionado por el tiempo de generación del dump con mysqldump, su transferencia al otro servidor y la importación; pero adelanto que seguramente es la manera que más tiempo requiere.
#exportamos todas las bbdd # -A = alldatabases, -F = flush logs mysqldump -A -F -u root --password #importamos a saco todo el fichero mysql -u root -p < dump.sql
- Exportación e importación con replicación de por medio
Si nos vemos forzados a hacer una migración “lógica” como en el caso anterior podemos hacer trampa y reducir el tiempo total quitando del corte la importación del dump. El corte nos quedará partido en dos: el dump e inicio de replicación en el servidor anterior y el cambio final de servidores una importada la información en destino y una vez el slave esté al dia en la replicación. Esta manera es algo más complicada pero solo se tienen que tener en cuentra cuatro cosas: hacer el dump bloqueando tablas o parando con -b, iniciar la replicación después, para el slave hecho el cambio y SOBRETODO comprobar la compatibilidad de la replicación si tenemos diferentes versiones de mysql entre master/slave y con la forma en la que insertamos datos (uso de funciones no determinísticas como USER() y alguna más no son compatibles). Más info sobre la replicación aquí.
Recapitulando, la última opción (d) nos permite reducir mucho el tiempo de la parada pero es algo más complicada. La primera es la más sencilla siempre que sea posible. Como he dicho antes hay factores que nos condicionan para elegir cualquier de estas u otras formas de hacerlo y también depende de las ganas de complicarnos que tengamos o sobretodo el tiempo que nos podamos permitir tener la base de datos parada. Para gustos colores...
Cómo controlar y reducir la fragmentación de tablas MySQL consultando information_schema
Cómo controlar y reducir la fragmentación de tablas MySQL consultando information_schema il_masacratore 15 Marzo, 2011 - 13:02La fragmentación tiene lugar sobretodo en tablas donde hay mucho movimiento insert/delete. Este crece mucho cuando el volumen de datos de la tabla es muy variable en el tiempo: por ejemplo en tablas de control de transacciones, de logueos de usuarios, de tablas intermedias, etc. El primer sintoma de fragmentación sería lentitud en las consultas, principalmente perceptible en tablas con muchos registros..
La fragmentación tiene lugar sobretodo en tablas donde hay mucho movimiento insert/delete. Este crece mucho cuando el volumen de datos de la tabla es muy variable en el tiempo: por ejemplo en tablas de control de transacciones, de logueos de usuarios, de tablas intermedias, etc. El primer sintoma de fragmentación sería lentitud en las consultas, principalmente perceptible en tablas con muchos registros. Para conocer información al respecto podemos consultando la vista information_schema.tables donde podemos ver rápidamente el estado de las tablas y algunos datos interesantes de las mismas.
El indice de fragmentación lo sacaremos de la relación entre el espacio liberado(data_free) por registros eliminados respecto al total de tabla(data_lenght), lo haremos porcentaje y ordenaremos de más a menos:
mysql> select table_schema, table_name,data_length, data_free, (data_free/data_length)*100 frag_percent , engine from information_schema.tables where table_schema not in ('information_schema', 'mysql') and data_free > 0 order by frag_percent desc;
+--------------+-------------------------+-------------+-----------+--------------+--------+
| table_schema | table_name | data_length | data_free | frag_percent | engine |
+--------------+-------------------------+-------------+-----------+--------------+--------+
| db1 | alumnos_logueados | 143484340 | 136095052 | 94.8501 | MyISAM |
| db1 | incidencias_puntualidad | 131917692 | 112362116 | 85.1759 | MyISAM |
| db1 | incidencias_asistencia | 7901568 | 6265364 | 79.2927 | MyISAM |
| db1 | usuarios_logueados | 1813192 | 1004284 | 55.3876 | MyISAM |
Con los datos de esta consulta nos daremos cuenta de las tablas fragmentadas con espacio disponible a liberar. Para eliminar la fragmentación basta con ejecutar la sentencia OPTIMIZE TABLE tabla. La única pega es que al hacerlo nos bloquea la tabla por lo que debemos elegir un buen momento para hacerlo. La fragmentación tampoco es que nos tenga que quitar el sueño ya que la mejora en el 90% de los casos será imperceptible pero tampoco está de más controlarlo de vez en cuando. Incluso en nuevas bases de datos controlarlo nos ayuda a conocer las tablas con más movimiento.
Muy buena consulta, me a
Muy buena consulta, me a servido mucho.
Gracias.
- Inicie sesión para enviar comentarios
Tamaño de columnas en Mysql
Tamaño de columnas en Mysql dani 1 Marzo, 2010 - 12:47Hola a todos,
Tengo una tabla en mysql bastante grande.
Me gustaría saber si sabeis alguna consulta para saber cuanto acupa cada columna.
En oracle utilizaba esta consulta:
select sum(vsize('NOMBRECOLUMNA'))/1024/1024 MB from NOMBRETABLA
Pero en Mysql no funciona.
Saludos!!
Con SHOW TABLE STATUS puedes
Con SHOW TABLE STATUS puedes mirar el tamaño que ocupa la tabla entera. A lo mejor ya te sirve.
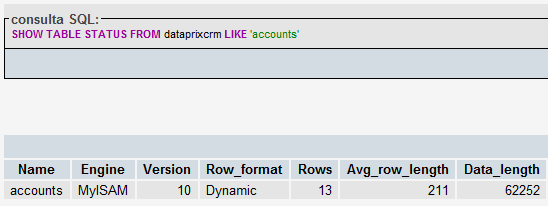
El tamaño está en el campo Data_length, y por defecto lo devuelve en bytes.
- Inicie sesión para enviar comentarios
Tips y consultas útiles de MySQL
Tips y consultas útiles de MySQL Carlos 4 Noviembre, 2011 - 13:36Si en un campo de tipo BLOB, objeto binario y de longitud variable, sabemos que se almacenan valores de string 'inteligibles', para consultar este valor se puede utilizar la función SUBSTRING:
mysql> SELECT campo_de_tipo_string, SUBSTRING(campo_de_tipo_BLOB,1,60)
-> FROM tabla
-> WHERE campo_de_tipo_string LIKE '%contenido';
+-----------------------------------+--------------------------------------------------------------+
| campo_de_tipo_string | SUBSTRING(campo_de_tipo_BLOB,1,60) |
+-----------------------------------+--------------------------------------------------------------+
| mi contenido | Valor del string 1 almacenado en BLOB |
| campo con contenido | Valor del string 2 almacenado en BLOB |
+-----------------------------------+--------------------------------------------------------------+
Breve historia de MySQL
Breve historia de MySQLDataprix
Algunas novedades y recursos de MySQL
Algunas novedades y recursos de MySQL Carlos 13 Enero, 2011 - 10:27Enlazo algunas novedades y recursos interesantes sobre MySQL anunciados en la última newsletter de MySQL
Blogs del Planet MySQL
- MySQL Server and NUMA architectures
- Looking for a hack - Passing comment-like info through the binary log
- Tuning InnoDB Configuration
- A step by step guide to upgrading to MySQL 5.5
Web de MySQL
- MySQL Enterprise Monitor 2.3: What's New
- MySQL Reference Architectures for Massively Scalable Web Infrastructure
- New Release of MySQL Community Server 5.1.54 (GA)
- Visual Guide to Installing MySQL on Windows
| Adjunto | Size |
|---|---|
| Visual_Guide_to_Installing_MySQL_Windows.pdf | 162 bytes |
| Visual_Guide_to_Installing_MySQL_Windows.pdf | 162 bytes |
| wp_high-availability_webrefarchs.en_.pdf | 162 bytes |
| wp_high-availability_webrefarchs.en_.pdf | 162 bytes |
| wp_mysql-enterprise_WhatsNewMonitor2.3.en_.pdf | 162 bytes |
| wp_mysql-enterprise_WhatsNewMonitor2.3.en_.pdf | 162 bytes |