3.4 Datawarehouse manager
3.4 Datawarehouse manager bernabeu_dario 6 May, 2009 - 18:093.4 Data Warehouse Manager
3.4.1 Base de datos multidimensional
3.4.2 Tablas de Dimensiones
3.4.2.1 Tabla de Dimensión Tiempo
3.4.3 Tablas de Hechos
3.4.3.1 Tablas de hechos agregadas y preagregadas
3.4.4 Cubo Multidimensional: introducción
3.4.4.1 Indicadores
3.4.4.2 Atributos
3.4.4.3 Jerarquías
3.4.4.4 a) Relación
3.4.4.5 b) Granularidad
3.4.5 Tipos de modelamiento de un DW
3.4.5.1 Esquema en Estrella
3.4.5.2 Esquema Copo de Nieve
3.4.5.3 Esquema Constelación
3.4.6 OLTP vs DW
3.4.7 Tipos de implementación de un DW
3.4.7.1 ROLAP
3.4.7.2 MOLAP
3.4.7.3 HOLAP
3.4.7.4 ROLAP vs MOLAP
3.4.8 Cubo Multidimensional: produndización
3.4.9 Metadatos
3.4.9.1 Mapping
3.4. Data Warehouse Manager
|
Figura 3.9: Data Warehouse Manager.
|
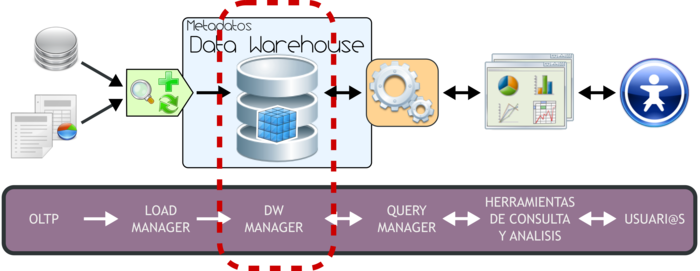
El DW Manager presenta las siguientes características y funciones principales:
- Se constituye típicamente al combinar un SGBD con software y aplicaciones dedicadas.
- Almacena los datos de forma multidimensional, es decir, a través de tablas de hechos y tablas de dimensiones.
- Gestiona las diferentes estructuras de datos que se construyan o describan sobre el DW, como Cubos Multidimensionales, Business Models, etc.
- Gestiona y mantiene metadatos.
Además, el DW Manager se encarga de:
- Transformar e integrar los datos fuentes y del almacenamiento intermedio en un modelo adecuado para la toma de decisiones.
- Realizar todas las funciones de definición y manipulación del depósito de datos, para poder soportar todos los procesos de gestión del mismo.
- Ejecutar y definir las políticas de particionamiento. El objetivo de realizar esto, es conseguir una mayor eficiencia y performance en las consultas al no tener que manejar todo el grueso de los datos. Esta política debe aplicarse sobre la tabla de hechos que, como se explicará más adelante, es en la que se almacena toda la información que será analizada.
- Realizar copias de resguardo incrementales o totales de los datos del DW.
3.4.1. Base de datos multidimensional
Una base de datos multidimensional es una base de datos en donde su información se almacena en forma multidimensional, es decir, a través de tablas de hechos y tablas de dimensiones.
Proveen una estructura que permite, a través de la creación y consulta a una estructura de datos determinada (cubo multidimensional, Business Model, etc), tener acceso flexible a los datos, para explorar y analizar sus relaciones, y consiguientes resultados.
Las bases de datos multidimensionales implican tres variantes posibles de modelamiento, que permiten realizar consultas de soporte de decisión:
-
Esquema en Estrella (Star Scheme).
-
Esquema Copo de Nieve (Snowflake Scheme).
-
Esquema Constelación o copo de estrellas (Starflake Scheme).
Los mencionados esquemas pueden ser implementados de diversas maneras, que, independientemente al tipo de arquitectura, requieren que toda la estructura de datos este desnormalizada o semi desnormalizada, para evitar desarrollar uniones (Join) complejas para acceder a la información, con el fin de agilizar la ejecución de consultas. Los diferentes tipos de implementación son los siguientes:
3.4.2. Tablas de Dimensiones
Las tablas de dimensiones definen como están los datos organizados lógicamente y proveen el medio para analizar el contexto del negocio. Contienen datos cualitativos.
Representan los aspectos de interés, mediante los cuales l@s usuari@s podrán filtrar y manipular la información almacenada en la tabla de hechos.
En la siguiente figura se pueden apreciar algunos ejemplos:
|
Figura 3.10: Tablas de Dimensiones. |

Como se puede observar, cada tabla posee un identificador único y al menos un campo o dato de referencia que describe los criterios de análisis relevantes para la organización, estos son por lo general de tipo texto.
Los datos dentro de estas tablas, que proveen información del negocio o que describen alguna de sus características, son llamados datos de referencia.
Más detalladamente, cada tabla de dimensión podrá contener los siguientes campos:
- Clave principal o identificador único.
- Clave foráneas.
- Datos de referencia primarios: datos que identifican la dimensión. Por ejemplo: nombre del cliente.
- Datos de referencia secundarios: datos que complementan la descripción de la dimensión. Por ejemplo: e-mail del cliente, fax del cliente, etc.
Usualmente la cantidad de tablas de dimensiones, aplicadas a un tema de interés en particular, varían entre tres y quince.
Debe tenerse en cuenta, que no siempre la clave primaria del OLTP, se corresponde con la clave primaria de la tabla de dimensión relacionada. Es recomendable manejar un sistema de claves en el DW (Claves Subrogadas) totalmente diferente al de los OLTP, ya que si estos últimos son recodificados, el almacén quedaría inconsistente y debería ser poblado nuevamente en su totalidad.
3.4.2.1. Tabla de Dimensión Tiempo
En un DW, la creación y el mantenimiento de una tabla de dimensión Tiempo es obligatoria, y la definición de granularidad y estructuración de la misma depende de la dinámica del negocio que se este analizando. Toda la información dentro del depósito, como ya se ha explicado, posee su propio sello de tiempo que determina la ocurrencia de un hecho específico, representando de esta manera diferentes versiones de una misma situación.
Es importante tener en cuenta que la dimensión tiempo no es sola una secuencia cronológica representada de forma numérica, sino que mantiene niveles jerárquicos especiales que inciden notablemente en las actividades de la organización. Esto se debe a que l@s usuari@s podrán por ejemplo analizar las ventas realizadas teniendo en cuenta el día de la semana en que se produjeron, quincena, mes, trimestre, semestre, año, estación, etc.
Existen muchas maneras de diseñar esta tabla, y en adición a ello no es una tarea sencilla de llevar a cabo. Por estas razones se considera una buena práctica evaluar con cuidado la temporalidad de los datos, la forma en que trabaja la organización, los resultados que se esperan obtener del almacén de datos relacionados con una unidad de tiempo y la flexibilidad que se desea obtener de dicha tabla.
Así mismo, si se requiere analizar los datos por Fecha (año, mes, día, etc) y por Hora (hora, minuto, segundo, etc), lo más recomendable es confeccionar dos tablas de dimensión Tiempo; una contendrá los datos referidos a la Fecha y la otra los referidos a la Hora.
Si bien, el lenguaje SQL ofrece funciones del tipo DATE, en la tabla de dimensión Tiempo, se modelan y presentan datos temporales que no pueden calcularse a través de consultas SQL, lo cual le añade una ventaja más.
Es conveniente mantener en la tabla de dimensión Tiempo un campo que se refiera al día Juliano. El día juliano se representa a través de un número secuencial e identifica unívocamente cada día. Mantener este campo permitirá la posibilidad de realizar consultas que involucren condiciones de filtrado de fechas desde-hasta, mayor que, menor que, etc, de manera sencilla e intuitiva; ya que si por ejemplo a partir de tal fecha se desea analizar los datos de los 81 días siguientes, el valor "desde" sería el día Juliano de la fecha en cuestión y el valor "hasta" sería igual a "desde" más 81.
3.4.3. Tablas de Hechos
Las tablas de hechos contienen, precisamente, los hechos que serán utilizados por l@s analistas de negocio para apoyar el proceso de toma de decisiones. Contienen datos cuantitativos.
Los hechos son datos instantáneos en el tiempo, que son filtrados, agrupados y explorados a través de condiciones definidas en las tablas de dimensiones.
Los datos presentes en las tablas de hechos constituyen el volumen de la bodega, y pueden estar compuestos por millones de registros dependiendo de su granularidad y antigüedad de la organización. Los más importantes son los de tipo numérico.
El registro del hecho posee una clave primaria que está compuesta por las claves primarias de las tablas de dimensiones relacionadas a este.
En la siguiente imagen se puede apreciar un ejemplo de lo antes mencionado:
|
Figura 3.11: Tablas de Hechos. |

Como se muestra en la figura anterior, la tabla de hechos “VENTAS” se ubica en el centro, e irradiando de ella se encuentran las tablas de dimensiones “CLIENTES”, “PRODUCTOS” y “FECHAS”, que están conectadas mediante sus claves primarias. Es por ello que la clave primaria de la tabla de hechos es la combinación de las claves primarias de sus dimensiones. Los hechos en este caso son “ImporteTotal” y “Utilidad”.
A continuación, se entrará más en detalle sobre la definición de un hecho, también llamado dato agregado:
- Los hechos son aquellos datos que residen en una tabla de hechos y que son utilizados para crear indicadores, a través de sumarizaciones preestablecidas al momento de crear un cubo multidimensional, Business Model, etc. Debido a que una tabla de hechos se encuentra interrelacionada con sus respectivas tablas de dimensiones, permite que los hechos puedan ser accedidos, filtrados y explorados por los valores de los campos de estas tablas de dimensiones, obteniendo de este modo una gran capacidad analítica.
Las sumarizaciones no están referidas solo a sumas, sino también a promedios, mínimos, máximos, totales por sector, porcentajes, fórmulas predefinidas, etc, dependiendo de los requerimientos de información del negocio.
Para ejemplificar este nuevo concepto de hechos, se enumerarán algunos que son muy típicos y fáciles de comprender:
- ImporteTotal = precioProducto * cantidadVendida
- Rentabilidad = utilidad / PN
- CantidadVentas = cantidad
- PromedioGeneral = AVG(notasFinales)
A la izquierda de la igualdad se encuentran los hechos; a la derecha los campos de los OLTP que son utilizados para representarlos. En el último ejemplo se realiza un precálculo para establecer el hecho.
Existen dos tipos de hechos, los básicos y los derivados, a continuación se detallará cada uno de ellos, teniendo en cuenta para su ejemplificación la siguiente tabla de hechos:
|
Figura 3.12: Hechos básicos y derivados. |

- Hechos básicos: son los que se encuentran representados por un campo de una tabla de hechos. Los campos ”precio” y ”cantidad” de la tabla anterior son hechos básicos.
- Hechos derivados: son los que se forman al combinar uno o más hechos con alguna operación matemática o lógica y que también residen en una tabla de hechos. Estos poseen la ventaja de almacenarse previamente calculados, por lo cual pueden ser accedidos a través de consultas SQL sencillas y devolver resultados rápidamente, pero requieren más espacio físico en el DW, además de necesitar más tiempo de proceso en los ETL que los calculan. El campo ”total” de la tabla anterior en un hecho derivado, ya que se conforma de la siguiente manera:
- total = precio * cantidad
Los campos ”precio” y ”cantidad”, también pertenecen a la tabla ”HECHOS”. Cabe resaltar, que no es necesario que los hechos derivados se compongan únicamente con hechos pertenecientes a una misma tabla.
Los hechos son gestionados con el principal objetivo de que se construyan indicadores basados en ellos, a través de la creación de un cubo multidimensional, Business Model, u otra estructura de datos.
3.4.3.1. Tablas de hechos agregadas y preagregadas
Las tablas de hechos agregadas y preagregadas se utilizan para almacenar un resumen de los datos, es decir, se guardan los datos en niveles de granularidad superior a los que inicialmente fueron obtenidos y/o gestionados.
Para obtener tablas agregadas o preagregadas, es necesario establecer un criterio por el cual realizar el resumen. Por ejemplo, esto ocurre cuando se desea obtener información de ventas sumarizadas por mes.
Cada vez que se requiere que los datos en una consulta se presenten en un nivel de granularidad superior al que se encuentran alojados en el Data Warehouse, se debe llevar a cabo un proceso de agregación.
El objetivo general de las tablas de hechos agregadas y preagregadas es similar, pero cada una de ellas tiene una manera de operar diferente:
- Tablas de hechos agregadas: se generan luego de que se procesa la consulta correspondiente a la tabla de hechos que se resumirá. En general, la agregación se produce dinámicamente a través de una instrucción SQL que incluya sumarizaciones.
- Tablas de hechos preagregadas: se generan antes de que se procese la consulta correspondiente a la tabla de hechos que se resumirá. De esta manera, la consulta se realiza contra una tabla que ya fue previamente sumarizada. Habitualmente, estas sumarizaciones se calculan a través de procesos ETL.
Las tablas de hechos preagregadas cuentan con los siguientes beneficios:
- Reduce la utilización de recursos de hardware que normalmente son incurridos en el cálculo de las sumarizaciones.
- Reduce el número de registros que serán analizados por l@s usuari@s.
- Reduce el tiempo utilizado en la generación de consultas por parte de l@s usuari@s.
Las tablas de hechos preagregadas son muy útiles en los siguientes casos generales:
- Cuando los datos a nivel detalle (menor nivel granular) son innecesarios y/o no son requeridos.
- Cuando una consulta sumarizada a determinado nivel de granularidad es solicitado con mucha frecuencia.
- Cuando los datos son muy abundantes, y las consultas demoran en ser procesadas demasiado tiempo.
Como contrapartida, las tablas de hechos preagregadas presentan una serie de desventajas:
- Requieren que se mantengan y gestionen nuevos procesos ETL.
- Demandan espacio de almacenamiento extra en el depósito de datos.
3.4.4. Cubo Multidimensional: introducción
Si bien existen diversas estructuras de datos, a través de las cuales se puede representar los datos del DW, solamente se entrará en detalle acerca de los cubos multidimensionales, por considerarse que esta estructura de datos es una de las más utilizadas y cuyo funcionamiento es el más complejo de entender.
Un cubo multidimensional o hipercubo, representa o convierte los datos planos que se encuentran en filas y columnas, en una matriz de N dimensiones.
Los objetos más importantes que se pueden incluir en un cubo multidimensional, son los siguientes:
- Indicadores: sumarizaciones que se efectúan sobre algún hecho o expresiones basadas en sumarizaciones, pertenecientes a una tabla de hechos.
- Atributos: campos o criterios de análisis, pertenecientes a tablas de dimensiones.
- Jerarquías: representa una relación lógica entre dos o más atributos.
De esta manera en un cubo multidimensional, los atributos existen a lo largo de varios ejes o dimensiones, y la intersección de las mismas representa el valor que tomará el indicador que se está evaluando.
En la siguiente representación matricial se puede ver más claramente lo que se acaba de decir:
|
Figura 3.13: Cubo multidimensional. |
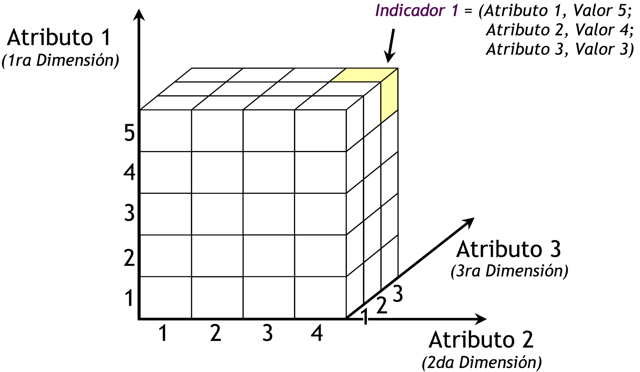
Para la creación del cubo de la figura anterior, se definieron tres Atributos (“Atributo 1”, “Atributo 2” y “Atributo 3”) y se definió un Indicador (“Indicador 1”). Entonces el cubo quedo compuesto por 3 dimensiones o ejes (una por cada Atributo), cada una con sus respectivos valores asociados. También, se ha seleccionado una intersección al azar para demostrar la correspondencia con los valores de las Atributos. En este caso, el indicador “Indicador 1”, representa el cruce del Valor “5” de “Atributo 1”, con el Valor “4” de “Atributo 2” y con el Valor “3” de “Atributo 3”.
Se puede observar, que el resultado del análisis está dado por los cruces matriciales de acuerdo a los valores de las dimensiones seleccionadas.
Más específicamente, para acceder a los datos del DW, se pueden ejecutar consultas sobre algún cubo multidimensional previamente definido. Dicho cubo debe incluir entre otros objetos: indicadores, atributos, jerarquías, etc, basados en los campos de las tablas de dimensiones y de hechos, que se deseen analizar. De esta manera, las consultas son respondidas con gran performance, minimizando al máximo el tiempo que se hubiese incurrido en realizar dicha consulta sobre una base de datos transaccional.
3.4.4.1. Indicadores
Los indicadores son sumarizaciones efectuadas sobre algún hecho o expresiones basadas en sumarizaciones, que serán incluidos en algún cubo multidimensional, con el fin de analizar los datos almacenados en el DW. El valor que estos adopten estará condicionado por los atributos/jerarquías que se utilicen para analizarlos.
Los indicadores, además de hechos, pueden estar compuestos por otros indicadores, pero no ambos simultáneamente. Pueden utilizarse para su creación funciones de sumarización (suma, conteo, promedio, etc), funciones matemáticas, estadísticas, operadores matemáticos y lógicos.
3.4.4.2. Atributos
Los atributos constituyen los criterios de análisis que se utilizarán para analizar los indicadores dentro de un cubo multidimensional. Los mismos se basan, en su gran mayoría, en los campos de las tablas de dimensiones y/o expresiones.
Dentro de un cubo multidimensional, los atributos son los ejes del mismo.
3.4.4.3. Jerarquías
Una jerarquía representa una relación lógica entre dos o más atributos pertenecientes a un cubo multidimensional; siempre y cuando posean su correspondiente relación “padre-hijo”.
Las jerarquías poseen las siguientes características:
-
Pueden existir varias en un mismo cubo.
-
Están compuestas por dos o más niveles.
-
Se tiene una relación “1-n” o “padre-hijo” entre atributos consecutivos de un nivel superior y uno inferior.
Por lo general, las jerarquías pueden identificarse fácilmente, debido a que existen relaciones “1-n” o “padre-hijo” entre los propios atributos de un cubo.
La principal ventaja de manejar jerarquías, reside en poder analizar los datos desde su nivel más general al más detallado y viceversa, al desplazarse por los diferentes niveles.
La siguiente figura muestra un pequeño ejemplo de lo recién expuesto:
|
Figura 3.14: Jerarquía Fechas. |

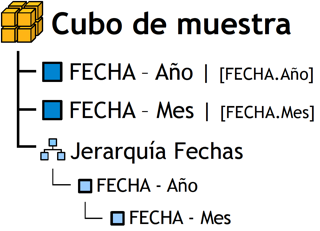
Aquí, se puede apreciar claramente como se construye una jerarquía:
-
Se crearon dos atributos, ”FECHA - Año” y ”FECHA - Mes”, los cuales están constituidos de la siguiente manera:
-
”FECHA - Año” = FECHA.Año
-
”FECHA - Mes” = FECHA.Mes
A la izquierda de la igualdad se encuentra el nombre del atributo; a la derecha el nombre del campo de la tabla de dimensión “FECHA”.
-
-
Se creó la jerarquía llamada ”Jerarquía Fechas”, en la cual se colocó el atributo más general en la cabecera y se comenzó a disgregar los niveles hacia abajo. En este caso, la figura se explica como sigue:
-
Un mes del año pertenece solo a un año. Un año puede poseer uno o más meses del año.
-
3.4.4.4. a) Relación
Una relación representa la forma en que dos atributos interactúan dentro de una jerarquía. Existen básicamente dos tipos de relaciones:
-
Explícitas: son las más comunes y se pueden modelar a partir de atributos directos y están en línea continua de una jerarquía, por ejemplo, un país posee una o más provincias y una provincia pertenece solo a un país.
-
Implícitas: son las que ocurren en la vida real, pero su relación no es de vista directa, por ejemplo, una provincia tiene uno o más ríos, pero un río pertenece a una o más provincias. Como se puede observar, este caso se trata de una relación muchos a muchos.
3.4.4.5. b) Granularidad
La granularidad representa el nivel de detalle al que se desea almacenar la información sobre el negocio que se esté analizando. Por ejemplo, los datos referentes a ventas o compras realizadas por una empresa, pueden registrarse día a día, en cambio, los datos pertinentes a pagos de sueldos o cuotas de socios, podrán almacenarse a nivel de mes.
Mientras mayor sea el nivel de detalle de los datos, se tendrán mayores posibilidades analíticas, ya que los mismos podrán ser resumidos o sumarizados. Es decir, los datos que posean granularidad fina (nivel de detalle) podrán ser resumidos hasta obtener una granularidad media o gruesa. No sucede lo mismo en sentido contrario, ya que por ejemplo, los datos almacenados con granularidad media podrán resumirse, pero no tendrán la facultad de ser analizados a nivel de detalle. O sea, si la granularidad con que se guardan los registros es a nivel de día, estos datos podrán sumarizarse por semana, mes, semestre y año, en cambio, si estos registros se almacenan a nivel de mes, podrán sumarizarse por semestre y año, pero no lo podrán hacer por día y semana.
3.4.5. Tipos de modelamiento de un DW
3.4.5.1. Esquema en Estrella
El esquema en estrella, consta de una tabla de hechos central y de varias tablas de dimensiones relacionadas a esta, a través de sus respectivas claves. En la siguiente figura se puede apreciar un esquema en estrella estándar:
|
Figura 3.15: Esquema en Estrella. |
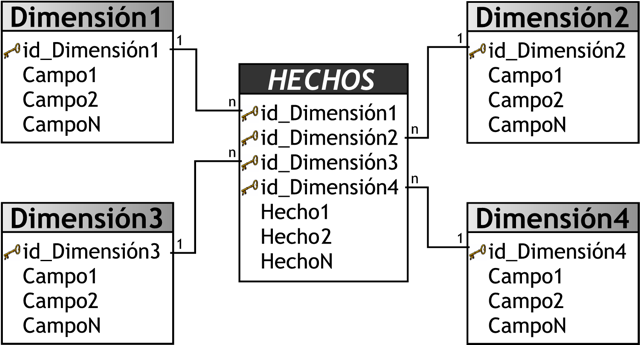
El modelo ejemplificado cuando se abordo el tema de las tablas de hechos, es un esquema en estrella, por lo cual se lo volverá a mencionar para explicar sus cualidades.
|
Figura 3.16: Esquema en Estrella, ejemplo. |

Este modelo debe estar totalmente desnormalizado, es decir que no puede presentarse en tercera forma normal (3ra FN), es por ello que por ejemplo, la tabla de dimensión “PRODUCTOS” contiene los campos “Rubro”, “Tipo” y “NombreProducto”. Si se normaliza esta tabla, se obtendrá el siguiente resultado:
|
Figura 3.17: Desnormalización. |
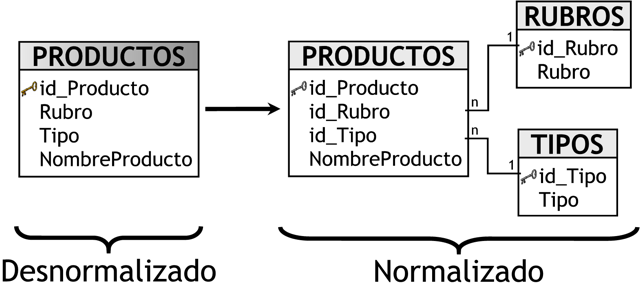
Cuando se normaliza, se pretende eliminar la redundancia, la repetición de datos y que las claves sean independientes de las columnas, pero en este tipo de modelos se requiere no evitar precisamente esto.
Las ventajas que trae aparejada la desnormalización, son las de obviar uniones (Join) entre las tablas cuando se realizan consultas, procurando así un mejor tiempo de respuesta y una mayor sencillez con respecto a su utilización. El punto en contra, es que se genera un cierto grado de redundancia, pero el ahorro de espacio no es significativo.
El esquema en estrella es el más simple de interpretar y optimiza los tiempos de respuesta ante las consultas de l@s usuari@s. Este modelo es soportado por casi todas las herramientas de consulta y análisis, y los metadatos son fáciles de documentar y mantener, sin embargo es el menos robusto para la carga y es el más lento de construir.
A continuación se destacarán algunas características de este modelo, que ayudarán a comprender mejor el por qué de sus ventajas:
- Posee los mejores tiempos de respuesta.
- Su diseño es fácilmente modificable.
- Existe paralelismo entre su diseño y la forma en que l@s usuari@s visualizan y manipulan los datos.
- Simplifica el análisis.
- Facilita la interacción con herramientas de consulta y análisis.
3.4.5.2. Esquema Copo de Nieve
Este esquema representa una extensión del modelo en estrella cuando las tablas de dimensiones se organizan en jerarquías de dimensiones.
|
Figura 3.18: Esquema Copo de Nieve. |
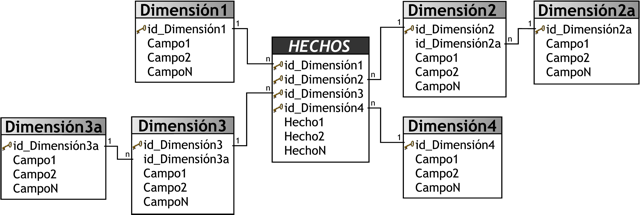
Como se puede apreciar en la figura anterior, existe una tabla de hechos central que está relacionada con una o más tablas de dimensiones, quienes a su vez pueden estar relacionadas o no con una o más tablas de dimensiones.
Este modelo es más cercano a un modelo de entidad relación, que al modelo en estrella, debido a que sus tablas de dimensiones están normalizadas.
Una de los motivos principales de utilizar este tipo de modelo, es la posibilidad de segregar los datos de las tablas de dimensiones y proveer un esquema que sustente los requerimientos de diseño. Otra razón es que es muy flexible y puede implementarse después de que se haya desarrollado un esquema en estrella.
Se pueden definir las siguientes características de este tipo de modelo:
-
Posee mayor complejidad en su estructura.
-
Hace una mejor utilización del espacio.
-
Es muy útil en tablas de dimensiones de muchas tuplas.
-
Las tablas de dimensiones están normalizadas, por lo que requiere menos esfuerzo de diseño.
-
Puede desarrollar clases de jerarquías fuera de las tablas de dimensiones, que permiten realizar análisis de lo general a lo detallado y viceversa.
A pesar de todas las características y ventajas que trae aparejada la implementación del esquema copo de nieve, existen dos grandes inconvenientes de ello:
-
Si se poseen múltiples tablas de dimensiones, cada una de ellas con varias jerarquías, se creará un número de tablas bastante considerable, que pueden llegar al punto de ser inmanejables.
-
Al existir muchas uniones y relaciones entre tablas, el desempeño puede verse reducido.
Las existencia de las diferentes jerarquías de dimensiones debe estar bien fundamentada, ya que de otro modo las consultas demorarán más tiempo en devolver los resultados, debido a que se deben realizar las uniones entre las tablas.
3.4.5.3. Esquema Constelación
Este modelo está compuesto por una serie de esquemas en estrella, y tal como se puede apreciar en la siguiente figura, está formado por una tabla de hechos principal (“HECHOS_A”) y por una o más tablas de hechos auxiliares (“HECHOS_B”), las cuales pueden ser sumarizaciones de la principal. Dichas tablas yacen en el centro del modelo y están relacionadas con sus respectivas tablas de dimensiones.
No es necesario que las diferentes tablas de hechos compartan las mismas tablas de dimensiones, ya que, las tablas de hechos auxiliares pueden vincularse con solo algunas de las tablas de dimensiones asignadas a la tabla de hechos principal, y también pueden hacerlo con nuevas tablas de dimensiones.
|
Figura 3.19: Esquema Constelación. |
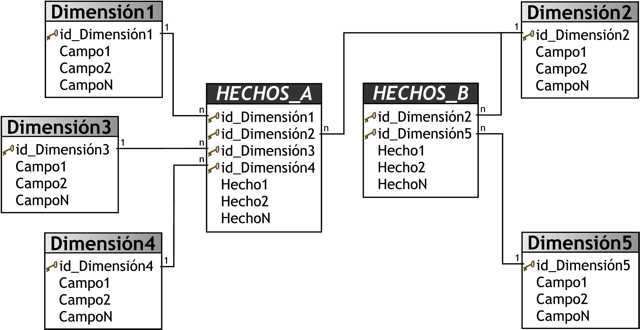
Su diseño y cualidades son muy similares a las del esquema en estrella, pero posee una serie de diferencias con el mismo, que son precisamente las que lo destacan y caracterizan. Entre ellas se pueden mencionar:
-
Permite tener más de una tabla de hechos, por lo cual se podrán analizar más aspectos claves del negocio con un mínimo esfuerzo adicional de diseño.
-
Contribuye a la reutilización de las tablas de dimensiones, ya que una misma tabla de dimensión puede utilizarse para varias tablas de hechos.
-
No es soportado por todas las herramientas de consulta y análisis.
3.4.6. OLTP vs DW
Debido a que, ya se han explicado y caracterizado los distintos tipos de esquemas del DW, se procederá a exponer las razones de su utilización, como así también las causas de por qué no se emplean simplemente las estructuras de las bases de datos tradicionales:
-
Los OLTP son diseñados para soportar el procesamiento de información diaria de las empresas, y el énfasis recae en maximizar la capacidad transaccional de sus datos. Su estructura es altamente normalizada, para brindar mayor eficiencia a sistemas con muchas transacciones que acceden a un pequeño número de registros y están fuertemente condicionadas por los procesos operacionales que deben soportar, para la óptima actualización de sus datos. Esta estructura es ideal para llevar a cabo el proceso transaccional diario, brindar consultas sobre los datos cargados y tomar decisiones diarias, en cambio los esquemas de DW están diseñados para poder llevar a cabo procesos de consulta y análisis para luego tomar decisiones estratégicas y tácticas de alto nivel.
A continuación se presentará una tabla comparativa entre los dos ambientes, que resume sus principales diferencias:
|
Figura 3.20: OLTP vs Data Warehouse. |
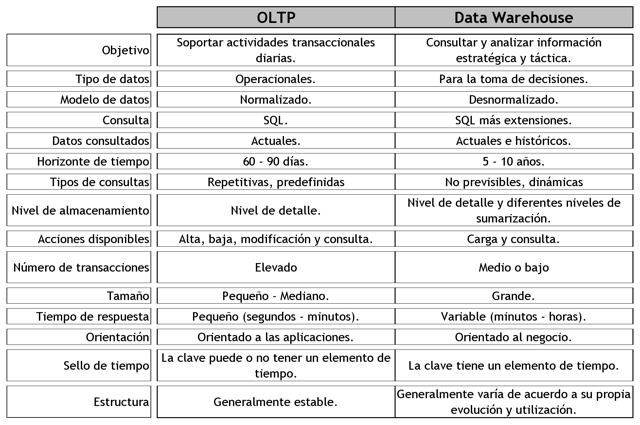
3.4.7. Tipos de implementación de un DW
3.4.7.1. ROLAP
Este tipo de organización física se implementa sobre tecnología relacional, pero disponen de algunas facilidades para mejorar el rendimiento.
Es decir, ROLAP (Relational On Line Analytic Processing) cuenta con todos los beneficios de una SGBD Relacional a los cuales se les provee extensiones y herramientas para poder utilizarlo como un Sistema Gestor de DW.
En los sistemas ROLAP, los cubos multidimensionales se generan dinámicamente al instante de realizar las diferentes consultas, haciendo de esta manera el manejo de cubos transparente l@s usuari@s. Este proceso se puede resumir a través de los siguientes pasos:
- Se seleccionan los indicadores, atributos, jerarquías, etc, que compondrán el cubo multidimensional.
- Se ejecutan las consultas sobre los atributos, indicadores, etc, seleccionados en el paso anterior. Entonces, de manera transparente a l@s usuari@s se crea y calcula dinámicamente el cubo correspondiente, el cual dará respuesta a las consultas que se ejecuten.
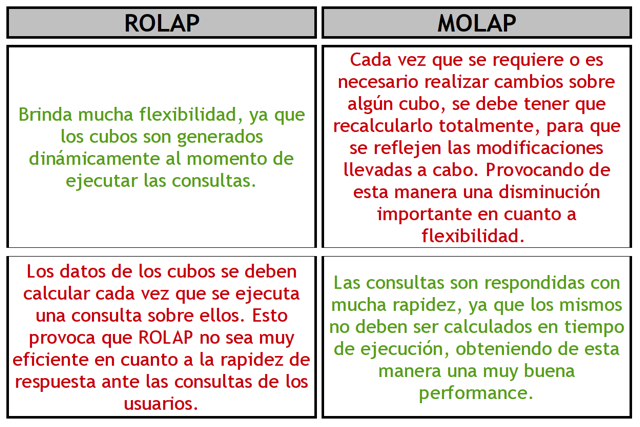
Al no tener que intervenir l@s usuari@s en la creación y el mantenimiento explícito de los cubos, ROLAP brinda mucha flexibilidad, ya que dichos cubos son generados dinámicamente al momento de ejecutar las consultas. Posibilitando de esta manera la obtención de consultas ad hoc.
La principal desventaja de los sistemas ROLAP, es que los datos de los cubos se deben calcular cada vez que se ejecuta una consulta sobre ellos. Esto provoca que ROLAP no sea muy eficiente en cuanto a la rapidez de respuesta ante las consultas de l@s usuari@s.
Para incrementar la velocidad de respuesta, en algunos casos se puede optar por almacenar los resultados obtenidos de ciertas consultas en la memoria caché (ya sea en el servidor o en una terminal), para que en un futuro, cuando se desee volver a ejecutar dicha consulta, los valores sean obtenidos más velozmente.
Cabe aclarar que si los datos del DW son almacenados y gestionados a través de un SGBD Relacional, no se requiere de otro software que administre y gestione los datos de manera Multidimensional.
Entre las características más importantes de ROLAP, se encuentran las siguientes:
-
Almacena la información en una base de datos relacional.
-
Utiliza índices de mapas de bits.
-
Utiliza índices de Join.
-
Posee optimizadores de consultas.
-
Cuenta con extensiones de SQL (drill-up, drill-down, etc).
Como se aclaró anteriormente, el almacén de datos se organiza a través de una base de datos multidimensional, sin embargo, puede ser soportado por un SGBD Relacional. Para lograr esto se utilizan los diferentes esquemas, en estrella, copo de nieve y constelación, los cuales transformarán el modelo multidimensional y permitirán que pueda ser gestionado por un SGDB Relacional, ya que solo se almacenarán tablas.
3.4.7.2. MOLAP
El objetivo de los sistemas MOLAP (Multidimentional On Line Analytic Processing) es almacenar físicamente los datos en estructuras multidimensionales de manera que la representación externa y la interna coincidan.
Para ello, se dispone de estructuras de almacenamiento específicas (Arrays) y técnicas de compactación de datos que favorecen el rendimiento del DW.
MOLAP requiere que en una instancia previa se generen y calculen los cubos multidimensionales, para que luego puedan ser consultados. Este proceso se puede resumir a través de los siguientes pasos:
-
Se seleccionan los indicadores, atributos, jerarquías, etc., que compondrán el cubo multidimensional.
-
Se precalculan los datos del cubo.
-
Se ejecutan las consultas sobre los datos precalculados del cubo.
El principal motivo de precalcular los datos de los cubos, es que posibilita que las consultas sean respondidas con mucha rapidez, ya que los mismos no deben ser calculados en tiempo de ejecución, obteniendo de esta manera una muy buena performance.
Existen una serie de desventajas que están directamente relacionadas con la ventaja de precalcular los datos de los cubos multidimensionales, ellas son:
-
Cada vez que se requiere o es necesario realizar cambios sobre algún cubo, se debe tener que recalcularlo totalmente, para que se reflejen las modificaciones llevadas a cabo. Provocando de esta manera una disminución importante en cuanto a flexibilidad.
-
Se precisa más espacio físico para almacenar dichos datos (esta desventaja no es tan significativa).
Habitualmente, los datos del DW son almacenados y gestionados a través de SGBD Relacionales, ya que estos tienen la ventaja de poder realizar consultas directamente a través del lenguaje SQL. En estos casos, para la generación de los cubos multidimensionales se requiere de otro software que administre y gestione los datos de manera Multidimensional.
3.4.7.3. HOLAP
HOLAP (Hybrid On Line Analytic Processing) constituye un sistema híbrido entre MOLAP y ROLAP, que combina estas dos implementaciones para almacenar algunos datos en un motor relacional y otros en una base de datos multidimensional.
Los datos agregados y precalculados se almacenan en estructuras multidimensionales y los de menor nivel de detalle en estructuras relacionales. Es decir, se utilizará ROLAP para navegar y explorar los datos, y se empleará MOLAP para la realización de tableros.
Como contrapartida, hay que realizar un buen análisis para identificar los diferentes tipos de datos.
3.4.7.4. ROLAP vs MOLAP
En la siguiente tabla comparativa se pueden apreciar las principales diferencias entre estos dos tipos de implementación:
|
Figura 3.21: ROLAP vs MOLAP. |
3.4.8. Cubo Multidimensional: profundización
Ahora que ya se tiene una visión general de los tipos de modelamiento e implementación de un DW, se volverá a abordar el tema de los cubos multidimensionales, pero esta vez se hará énfasis en su construcción y se ejemplificará cada paso, a fin de que se puedan visualizar mejor los resultados de cada acción.
La forma que se utilizará para graficar el cubo que se creará, será la siguiente:
|
Figura 3.22: Cubo estándar. |

Tal y como podemos observar, el gráfico toma una estructura de árbol, en la cuál en la raíz figura el cubo en cuestión y dependiendo de este sus diferentes objetos relacionados. En el caso de las jerarquías, los atributos que la componen, también deben estructurarse en forma de árbol, teniendo en cuenta su respectiva relación padre-hijo.
Se tomará como base para la realización de los ejemplos, el siguiente esquema en estrella:
|
Figura 3.23: Esquema en Estrella. |

Como primer paso se creará un cubo multidimensional llamado ”Cubo de Ventas”, gráficamente:
|
Figura 3.24: Cubo multidimensional, paso 1. |

Luego se crearán dos atributos:
-
De la tabla de dimensión “PRODUCTOS”, se tomará el campo “Producto” para la creación del atributo denominado:
-
“PRODUCTOS - Producto”.
-
-
De la tabla dimensión “MARCAS”, se tomará el campo “Marca” para la creación del atributo denominado:
-
“MARCAS - Marca”.
-
Gráficamente:
|
Figura 3.25: Cubo multidimensional, paso 2. |

También se creará un indicador:
-
De la tabla de hechos “VENTAS”, se sumarizará el hecho “Venta” para crear el indicador denominado:
-
“VENTAS - Venta”.
La fórmula utilizada para crear este indicador es la siguiente:
-
“VENTAS - Venta” = SUM(VENTAS.Venta).
-
Gráficamente:
|
Figura 3.26: Cubo multidimensional, paso 3. |

En este momento, tenemos un cubo multidimensional de dos dimensiones, cuya representación matricial sería la siguiente:
|
Figura 3.27: Cubo multidimensional de dos dimensiones. |
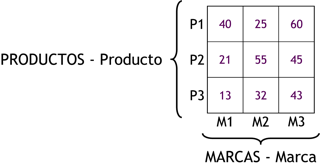
Este cubo posee dos ejes o dimensiones, “PRODUCTOS - Producto” y “MARCAS - Marca”. La intersección de los ejes representa las ventas de cada producto con su respectiva marca (indicador “VENTAS - Venta”).
Por ejemplo:
-
Las ventas asociadas al producto “P1” y a la marca “M1” son 40.
-
Las ventas asociadas al producto “P1” y a la marca “M2” son 25.
-
Las ventas asociadas al producto “P1” y a la marca “M3” son 60.
Ahora, al cubo planteado se le agregará un nuevo atributo:
-
De la tabla de dimensión “CLIENTES”, se tomará el campo “Cliente” para la creación del atributo denominado:
-
“CLIENTES - Cliente”.
-
Gráficamente:
|
Figura 3.28: Cubo multidimensional, paso 4. |

De esta manera, ahora tenemos un cubo multidimensional de tres dimensiones, cuya representación matricial sería la siguiente:
|
Figura 3.29: Cubo multidimensional de tres dimensiones. |
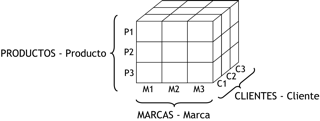
En este caso los valores del indicador “VENTAS - Venta” están dados de acuerdo a las ventas de cada producto, de cada marca, a cada cliente.
Para finalizar, se añadirá un cuarto atributo al cubo:
-
De la tabla de dimensión “TIEMPO”, se tomará el campo “Año” para la creación del atributo denominado:
-
“TIEMPO - Año”.
-
Gráficamente:
|
Figura 3.30: Cubo multidimensional, paso 5. |

Entonces, la representación matricial del cubo multidimensional resultante sería la siguiente:
|
Figura 3.31: Cubo multidimensional de cuatro dimensiones. |
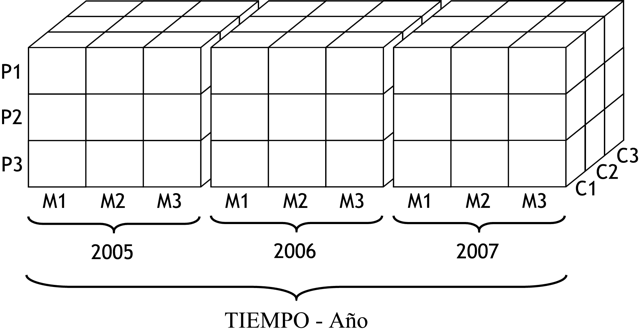
Los valores del indicador “VENTAS - Venta” en este momento, estarán condicionados por las ventas de cada producto, de cada marca, a cada cliente, en cada año.
Esta última imagen, demuestra claramente los conceptos expuestos de la tabla de dimensión tiempo, donde se decía que pueden existir diferentes versiones de la situación del negocio.
Cabe aclarar que pueden crearse tantos cubos se deseen y que los mismos pueden coexistir sin ningún inconveniente.
3.4.9. Metadatos
Los metadatos son datos que describen o dan información de otros datos, que en este caso, existen en la arquitectura del Data Warehousing. Brindan información de localización, estructura y significado de los datos, básicamente mapean los mismos.
El concepto de metadatos es análogo al uso de índices para localizar objetos en lugar de datos.
Es importante aclarar que existen metadatos también en las bases de datos transaccionales, pero los mismos son transparentes a l@s usuari@s. La gran ventaja que trae aparejada el Data Warehousing en relación con los metadatos es que l@s usuari@s pueden gestionarlos, exportarlos, importarlos, realizarles mantenimiento e interactuar con ellos, ya sea manual o automáticamente.
Las funciones que cumplen los metadatos en el ambiente Data Warehousing son muy importantes y significativas, algunas de ellas son:
-
Facilitan el flujo de trabajo, convirtiendo datos automáticamente de un formato a otro.
-
Contienen un directorio para facilitar la búsqueda y descripción de los contenidos del DW, tales como: bases de datos, tablas, nombres de atributos, sumarizaciones, acumulaciones, reglas de negocios, estructuras y modelos de datos, relaciones de integridad, jerarquías, etc.
-
Poseen un guía para el mapping, de cómo se transforman e integran los datos de las fuentes operacionales y externos al ambiente del depósito de datos.
-
Almacenan las referencias de los algoritmos utilizados para la esquematización entre el detalle de datos actuales, con los datos ligeramente resumidos y éstos con los datos altamente resumidos, etc.
-
Contienen las definiciones del sistema de registro desde el cual se construye el DW.
Se pueden distinguir tres diferentes tipos de Metadatos:
-
Los metadatos de los procesos ETL, referidos a las diversas fuentes utilizadas, reglas de extracción, transformación, limpieza, depuración y carga de los datos al depósito.
-
Los metadatos operacionales, que son los que básicamente almacenan todos los contenidos del DW, para que este pueda desempeñar sus tareas.
-
Los metadatos de consulta, que contienen las reglas para analizar y explotar la información del almacén, tales como drill-up y drill-down. Son estos metadatos los que las herramientas de análisis y consulta emplearán para realizar documentaciones y para navegar por los datos.
3.4.9.1. Mapping
El término mapping, se refiere a relacionar un conjunto de objetos, tal como actualmente están almacenados en memoria o en disco, con otros objetos. Por ejemplo: una estructura de base de datos lógica, se proyecta sobre la base de datos física.