
Dimensionality Reduction
We are creating a gigantic measure of data day by day. Indeed, 90% of the data on the planet has been created in the last 3-4 years! The numbers are really stunning. The following are only a portion of the instances of the sort of data being gathered:
-
Facebook gathers data of what you like, share, post, places you visit, eateries you like, and so forth
-
Your cell phone applications gather a ton of individual data about you
-
Amazon gathers data of what you purchase, see, click, and so forth on their site
-
Gambling clubs monitor each move every client makes
As data age and assortment continues expanding, envisioning it and drawing surmisings turns out to be increasingly difficult. Quite possibly the most well-known method of doing perception is through diagrams. Assume we have 2 factors, Age and Height. We can utilize a dissipate or line plot among Age and Height and envision their relationship without any problem:
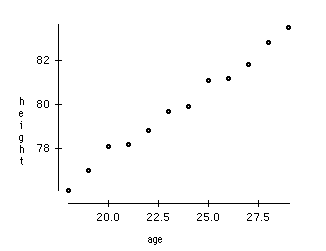
Presently consider a case wherein we have, say 100 factors (p=100). For this situation, we can have 100(100-1)/2 = 5000 unique plots. It doesn't bode well to picture every one of them independently, correct? In such situations where we have an enormous number of factors, it is smarter to choose a subset of these factors (p<<100) which catches as much data as the first arrangement of factors.
Allow us to comprehend this with a basic model. Think about the underneath picture:
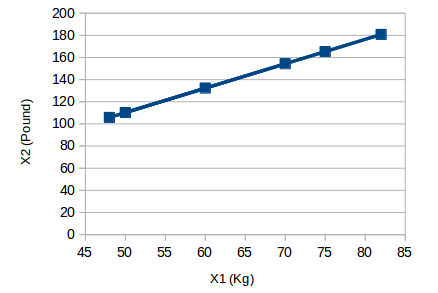
Here we have loads of comparable items in Kg (X1) and Pound (X2). On the off chance that we utilize both of these factors, they will pass on comparable data. Thus, it would bode well to utilize just a single variable. We can change over the data from 2D (X1 and X2) to 1D (Y1) as demonstrated underneath:
Essentially, we can lessen p measurements of the data into a subset of k measurements (k<<n). This is called dimensionality reduction.
Why it is required?
Here is a portion of the advantages of applying dimensionality decrease to a dataset:
Space needed to store the data is diminished as the number of measurements descends
Fewer measurements lead to less calculation/preparation time.
A few calculations don't perform well when we have enormous measurements. So diminishing these measurements needs to occur for the calculation to be valuable
It deals with multicollinearity by eliminating excess highlights. For instance, you have two factors – 'time spent on the treadmill in minutes' and 'calories consumed'. These factors are profoundly related as the additional time you spend running on a treadmill, the more calories you will consume. Henceforth, there is no reason for putting away both as only one of them does what you require
It helps in picturing data. As examined before, it is hard to imagine data in higher measurements so lessening our space to 2D or 3D may permit us to plot and notice designs all the more unmistakably
Final Words-
Managing thousands and millions of highlights is an absolute necessity have ability for any data scientist. The measure of data we are creating every day is remarkable and we need to discover various approaches to sort out some way to utilize it. Dimensionality decrease is a helpful method to do this and has done some incredible things for me, both in an expert setting just as in AI hackathons.
Author Bio:-
Akash Praharaj is a creative content and copywriter. He is interested in trending technologies like data science, machine learning, artificial intelligence. His writing is a treasure of insights into the latest trends and technologies. He uses his 4+ years of writing and 2+ years of digital marketing experience to make his articles more interactive and engaging. With a persuasive copy throughout, he is a copywriter in the making.
https://www.linkedin.com/in/akash-praharaj/

