
Una base de datos Oracle en Standby es una copia exacta de una base de datos operativa en un servidor remoto, usada como backup, como copia para consulta, recuperación de desastres, etc.
Una base de datos en modo Standby es algo más que un backup normal ya que se puede poner en producción en caso de desastre en un tiempo menor que si tuvieramos que restaurar una copia (ya sea desde rman o un simple export).
Restaurar una copia desde fichero tarda tiempo, y durante este periodo el sistema no está disponible. Con una base de datos adicional en modo standby no hay nada (o casi nada que restaurar) en caso de desastre. En cuestión de minutos se hace el cambio permitiendo continuidad en el servicio. No nos ofrece las ventajas de rendimiento de un cluster o la seguridad del espejo pero la relación de costes de tiempo y licencia versus ventajas me parece correcta.
Desde un punto de vista global:
- Disponemos de una copia de la base de datos de forma remota, que podemos contabilizar como segundo juego de copias.
- A diferencia de un simple backup, la copia se mantiene viva y los datos son actualizados con mayor frecuencia.
- En caso de desastre la podemos usar en cuestión de minutos sin esperar a restaurar un backup entero, ya sea lógico(export) o físico(rman).
- Sirve como entorno de pruebas más real para la prueba de parches y estimación de tiempos. El volumen de datos es idéntico.
- Tengo entendido que una base de datos en standby se puede usar hasta 10 dias al año sin coste de licencia (aunque mira por donde Microsoft te deja 30 dias... )
Desde un punto de vista técnico:
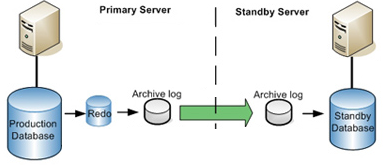
- Los cambios en la base de datos principal se captura en los archivos de redo log.
- Los archivos de redo no son permanentes, son sobreescritos de forma rotativa (en este estado aún no se copia al segundo servidor).
- Se hace una copia del redo log. La copia permanente se llama archive log.
- Los archive logs(copias de redo log) se transfieren al servidor en standby. En sistemas linux por ejemplo podemos hacerlo mediante rsync.
- Se aplican los archive logs transferidos a la base de datos en standby quedando actualizada.
A nivel global los pasos a seguir para montar el chiringuito pueden ser los siguientes:
- Configurar la base de datos principal para que funcione en modo archivelog.
- Preparar un script para hacer una copia en caliente (usando rman).
- Crear un fichero de control standby (control file) en la base de datos principal.
- Copiarlo todo (fichero de configuración, de control y copia rman) en el segundo servidor (donde montamos la base de datos en standby).
- Reconfigurar rutas (usando DB_FILE_NAME_CONVERT en init.ora o a manita).
- Iniciar la segunda base de datos en modo mount standby database.
- Restaurar datos (recover database).
- Sincronizar de forma periódica(cron) transportando (rsync?) y aplicando los archive logs.
En otro post intentaré entrar en más detalle con un ejemplo... y las utilidades que le podemos dar.

No olvidemos la vuelta atrás
Submitted by Carlos on 16 March, 2010 - 17:08
Sólo comentar que también es conveniente planificar como último paso la vuelta atrás a la base de datos de producción original en caso de que se tenga que utilizar la base de datos en Standby.
En un tiempo aceptable habrá que volver a recrear o actualizar la BD de producción inicial, pero incluyendo los cambios que se produzcan en el tiempo que esté activa la BD en Standby, y eso puede llegar a ser bastante complicado según las condiciones del entorno..
Hola, Respecto al punto
Submitted by Mario G (not verified) on 13 May, 2016 - 22:29
Hola,
Respecto al punto de:
En un ambiente de recuperación ante desastres con un server en Standby, Oracle le requerirá licenciar la Base de Datos en standby en misma métrica y cantidad de licencia que la Base de Datos en producción. (asociada a ella).
Para más detalle acceder a: http://www.oracle.com/us/corporate/pricing/sig-070616.pdf
Saludos,
Hola Mario Lo que yo
Submitted by Carlos on 17 May, 2016 - 13:51
In reply to Hola, Respecto al punto by Mario G (not verified)
Hola Mario
Lo que yo recuerdo de hace tiempo es que si se monta un RAC en modo activo, es decir, con los servidores Oracle que conforman el cluster funcionando al 100% para dar servicio a las instancias, tienes que licenciar todos los servidores de base de datos que tengas funcionando, pero si se monta en modo Activo/pasivo, con un server activo funcionando en producción, y otro (el pasivo) en standby, con la licencia del activo es suficiente para poder mantener este interesante sistema de recuperación, que ante cualquier problema en el server activo permite tomar el control temporalmente al pasivo.
Eso sí, el pasivo sólo ha de estar activo el tiempo necesario para resolver el problema en el server activo, después el servidor licenciado ha de volver a tomar el control, y el otro volver al modo standby, por eso la licencia sólo permite la utilización del server en Standby como activo durante 10 días.
En el documento de Oracle que mencionas, en la página 18, se enlaza otro documento que aclara el licenciamiento de los entornos de recuperación:
Backup/Failover/Standby/Remote Mirroring – Please see the Licensing Data Recovery Environments document: http://www.oracle.com/us/corporate/pricing/data-recovery-licensing-0705… for more information.
Consultando el otro documento, veo que este método se incluye dentro de Data Recovery using Clustered Environments (Failover), y este párrafo creo que es bastante aclaratorio:
The failover data recovery method is an example of a clustered deployment; where multiple nodes/servers have access to one Single Storage/SAN. In such cases your license for the programs listed on the US Oracle Technology Price, includes the right to run the licensed program(s) on an unlicensed spare computer in a failover environment for up to a total of ten separate days in any given calendar year..
Y, sin embargo, el standby lo menciona dentro del apartado 'Data Recovery Environments using Copying, Synchronizing or Mirroring':
Standby and Remote Mirroring are commonly used terms to describe these methods of deploying Data Recovery environments. In these Data Recovery deployments, the data, and optionally the Oracle binaries, are copied to another storage device..
Yo entiendo entonces que no son necesarias licencias extra siempre que se utilice el método de failover para dos servidores que compartan la unidad de almacenamiento.