
Características de un modelo cluster
En general sigue los siguientes patrones:
- Alta similitud entre los casos dentro de cada cluster.
- Cada cluster debería ser tan único como se pueda, en comparación a los restantes.
Presentaremos un ejemplo en donde cada caso, representa un país, y construiremos un modelo (k-means) con 3 clusters.
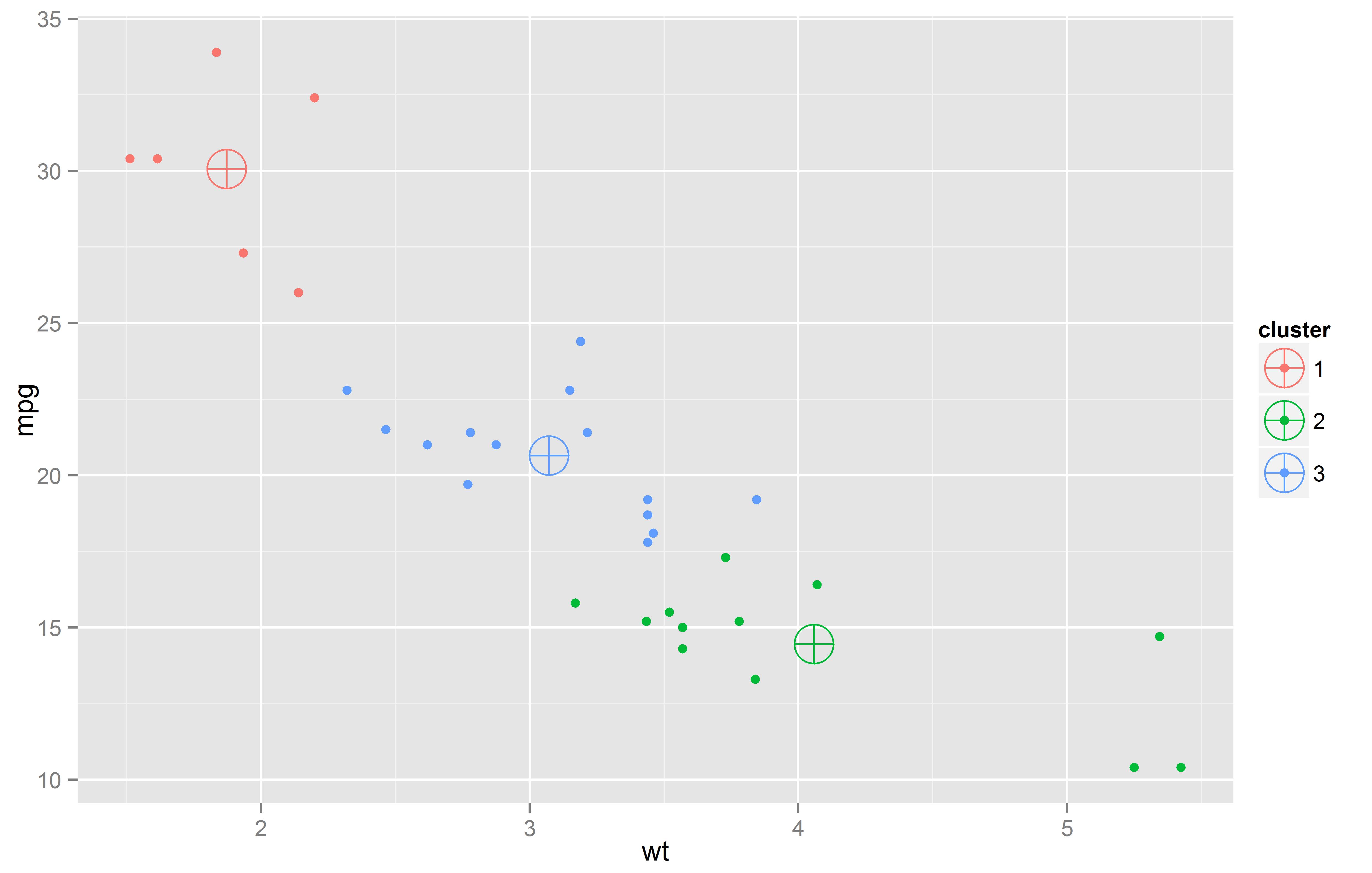
Ilustración de un modelo cluster, hecho con 2 variables y 3 clusters. Los círculos indican el centro del cluster.
Gráfico de coordenadas
Este es el gráfico que describe las principales características del modelo:
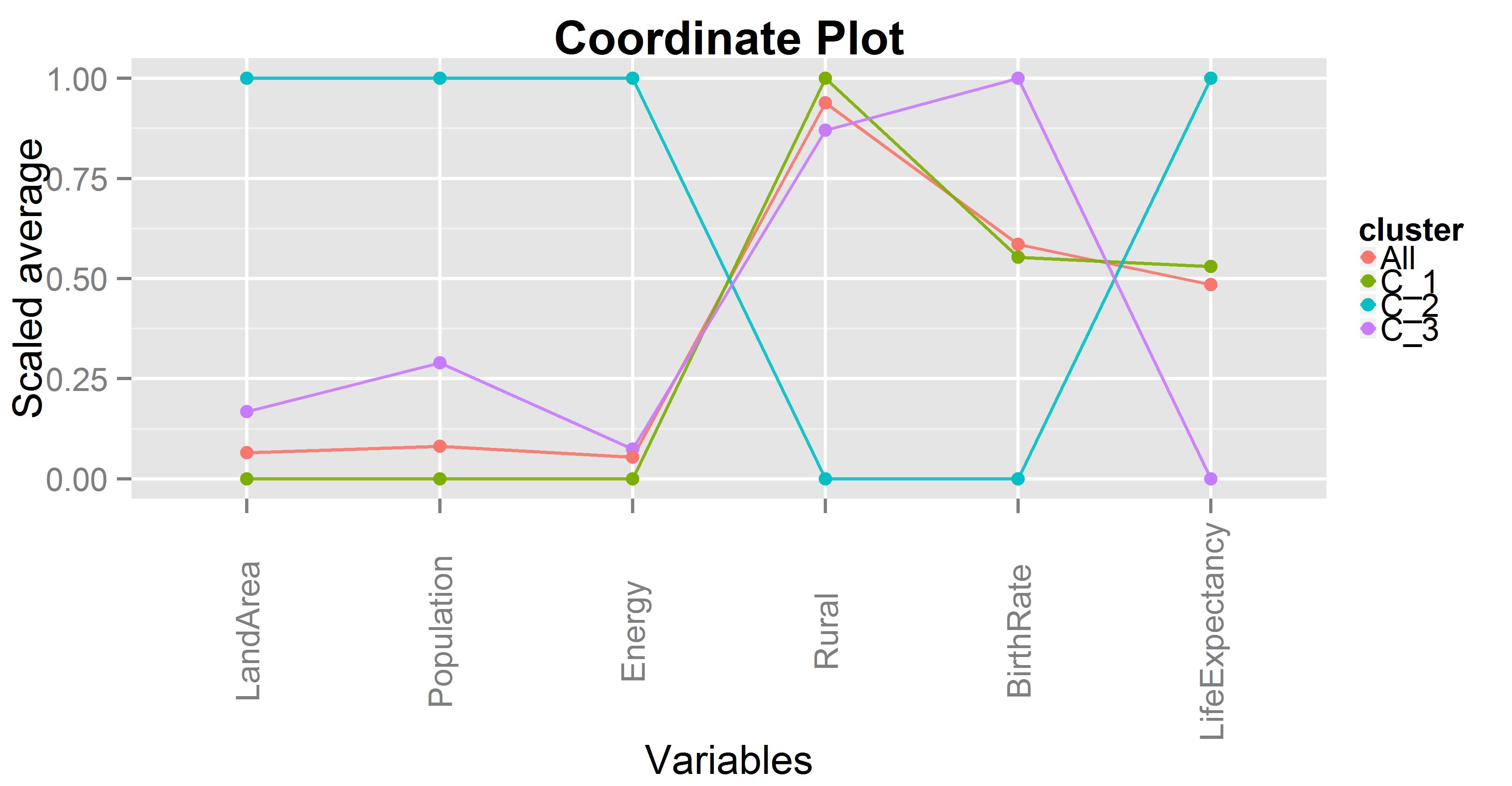
Características del gráfico de coordenadas
- Cada linea de color representa un cluster, mas una línea extra “All” que representa el promedio de todo el set de datos.
- Cada cluster posee un promedio por cada variable. *Dicho promedio va desde 0 a 1 para así poder visualizar todas las variables en un gráfico.
- Para cada variable, siempre habrá un número que se corresponde con 0 y otro con 1. Representando el mín y máx respectivamente.
- El gráfico debería ser leído verticalmente.
¿Cómo se construye “scaled average”?
Mirando la variable “LandArea” (la cual representa kilómetros cuadrados), podemos decir que C_2 (cluster 2) tiene el menor promedio en lo que respecta a la superficie. Seguido por C_1. Por otro lado, C_3 tiene el valor mas alto y bastante alejado del resto de los clusters.
En otras palabras, los países mas grandes están en C_3, mientras que los más pequeños en C_2.
A continuación, se mostrarán los valores originales de la variables -no representados en el gráfico debido a la transformación- y el valor de la escala correspondiente (“scaled average”).
- 1886206 es convertido en: 0.17
- 243509 es convertido en: 0.00
- 10014500 es convertido en: 1.00
El promedio de todos los datos, (sin considerar la segmentación hecha por clustering), es 884633, por lo que es convertido a: 0.06. Éste es el valor representado por la linea “All”.
Aquí ya tenemos nuestros 4 puntos, para representar la variable LandArea.
Extrayendo conclusiones
Describiendo el Cluster 3
En C_3 están los países con el valor más alto de LandArea y Population (los cuales no siempre están correlacionados). Respecto de las variables Energy y LifeExpectancy, también posee los valores más altos, lo cual podría ser un indicativo de un país bien desarrollado.
Sin embargo, posee el menor promedio de tasa de nacimiento (BirthRate), y no es nuevo que algunos paises desarrollados tiene una valor bajo en ésta variable.
Describiendo el Cluster 2
C_2 es muy parecido a “All”, es decir a toda la población, por lo que no aporta mucha información. Mirando todas sus variables comparte valores muy similares a la población en general.
Describiendo el Cluster 1
C_1 puede ser visto como el punto medio respecto a: LandArea, Population, Energy y Rural. Pero es interesante notar que poseen la tasa de crecimiento (BirthRate) más alta y la menor esperanza de vida (LifeExpectancy), así como también un valor elevado en la variable Rural (porcentaje de la población viviendo en una zona rural). Éste sería el caso opuesto a C_3.
En resumen se puede decir que:
- C_3 => Países con alto desarrollo
- C_1 => Países con bajo desarrollo
Contacto
Hecho por Pablo C. de Data Science Heroes ![]()
-
Este material es una breve adaptación del curso e-learning Data Science with R en el cual se pueden encontrar guías paso a paso para construir, entender y validar modelos. Demo gratuita disponible .
-
Código de R utilizado: Instalación del gráfico de coordenadas y su uso disponible en GitHub
-
¿Preguntas acerca data science? Escribirlas en nuestro grupo de Linkedin
