
En una entrada anterior del Blog (2.4. DataMining o Mineria de Datos.) intentamos hacer una aproximación inicial a la teoria del Data Mining. Los procesos de data mining tratan de extraer información oculta en los datos mediante el uso de diferentes técnicas (la mayoría relacionadas con la estadística y los modelos matemáticos, en combinación con aplicaciones informáticas).
Dada la complejidad de estas técnicas, y no siendo el cometido de esta blog entrar en profundidad en esta materia (por cuestiones de tiempo y de conocimientos), nos limitaremos a ver un par de metodologias de datamining, enumerar las técnicas mas habituales y a recordar los conceptos de tres de estas técnicas mediante ejemplos prácticos. Esos mismos ejemplos nos permitirán la posterior utilización de las herramientas de DataMining que proporciona Microstrategy 9 (también incluidas en la Microstrategy Reporting Suite) y explicar que visión tiene el producto de las técnicas de Data Mining.
Antes de comenzar, os recomiendo ver la presentación Data Mining.Extracción de Conocimiento en Grandes Bases de Datos, realizada por José M. Gutiérrez, del Dpto. de Matemática Aplicada de la Universidad de Cantabria, Santander.
Para quien quiera o necesite profundizar en la teoria de data mining, sus técnicas y posibilidades, os dejo la lista de referencias a algunos de los libros mas importantes en este ámbito:
- Data mining: practical machine learning tools and techniques.
- Data Mining Techniques: For Marketing, Sales, and Customer Relationship.
Management, 2nd Edition - The elements of statistical learning : data mining, inference, and prediction.
- Advanced Data Mining Techniques.
- Data Mining: Concepts and Techniques.
- Data Preparation for Data Mining.
Pasos a seguir en un proyecto de Data Mining
Existen varias metodologias estandar para desarrollar los analisis DataMining de una forma sistematica. Algunas de las mas conocidas son el CRISP, que es un estandar de la industria que consiste en una secuencia de pasos que son habitualmente utilizados en un estudio de data mining. El otro metodo es el SEMMA, especifico de SAS. Este metodo enumera los pasos a seguir de una forma mas detallada. Veamos un poco en que consiste cada uno.
CRISP-DM (Cross-Industry Standard Process for Data Mining).
El modelo consiste en 6 fases relacionadas entre si de una forma cíclica (con retroalimentación). Podeis ampliar información de la metodologia en la sección de manuales de Dataprix.com. Igualmente, podeis acceder la web del proyecto Crisp aquí. Las fases son las siguientes:
- Business Understanding: comprensión del negocio incluyendo sus objetivos, evaluación de la situación actual, estableciendo unos objetivos que habran de cumplir los estudios de data mining y desarrollando un plan de proyecto. En esta fase definiremos cual es el objeto del estudio y porque se plantea. Por ejemplo, un portal de ventas de viajes via web quiere analizar sus clientes y habitos de compra para hacer segmentación de ellos y lanzar campañas de marketing especificas sobre cada target con el objetivo de aumentar las ventas. Ese sera el punto de partida de un proyecto de datamining. Información detallada de la fase en Dataprix.com.
- Data Understanding: una vez establecidos los objetivos del proyecto, es necesario la comprensión de los datos y la determinación de los requerimientos de información necesarios para poder llevar a cabo nuestro proyecto. En esta fase se pueden incluir la recogida de datos, descripción de ellos, exploración y la verificación de la calidad de estos. En esta fase podemos utilizar técnicas como resumen de estadísticas (con visualización de variables) o realizar analisis de cluster con la intención de identificar patrones o modelos dentro de los datos. Es importante en esta fase que este definido claramente lo que se quiere analizar, para poder identificar la información necesaria para describir el proceso y poder analizarlo. Luego habrá que ver que información es relavante para el analisis (pues hay aspectos que se podrán desestimar) y finalmente habrá que verificar que las variables identificadas son independientes entre si. Por ejemplo, estamos en un proyecto de data mining de analisis de clientes para segmentación. De toda la información disponible en nuestros sistemas o de fuentes externas, habrá que identificar cual esta relacionada con el problema (datos de clientes, edad, hijos, ingresos, zona de residencia), de toda esa información, cual es relevante (no nos interesan, para el ejemplo, las aficiones de los clientes) y finalmente, de las variables seleccionadas, verificar que no estan relacionadas entre si (el nivel de ingresos y la zona de residencia no son variables independientes, por ejemplo). La información normalmente se suele clasificar en Demografica (ingresos, educación, numero de hijos, edad), sociografica (hobbys, pertenencia a clubs o instituciones), transaccional (ventas, gastos en tarjeta de credito, cheques emitidos), etc. Ademas, los datos pueden ser del tipo Cuantitativo (datos medidos usando valores numericos) o Cualitativo (datos que determinan categorias, usando nominales u ordinales). Los datos Cuantitativos pueden ser representados normalmente por alguna clase de distribución de probabilidad (que nos determinara como los datos se dispersan y agrupan). Para los Cualitativos, habrá que previamente codificarlos a numeros que nos describiran las distribuciones de frecuencia. Información detallada de la fase en Dataprix.com.
- Data Preparation: una vez los recursos de datos estan identificados, es necesario que sean seleccionados, limpiados, tranformados a la forma deseada y formateados. En esta fase se llevara a cabo los procesos de Data Cleaning y Data Transformation, necesarios para el posterior modelado. En esta fase se puede realizar exploración por los datos a mayor profundidad para encontrar igualmente patrones dentro de los datos. En el caso de estar utilizando un Data Warehouse como origen de datos, ya se habran realizado estas tareas al cargar los datos en el. También puede darse el caso de que necesitemos información agregada (por ejemplo, acumulación de ventas de un periodo), información que podremos extraer de nuestro DW con las herramientas tipicas de un sistema BI. Otro tipo de transformaciónes pueden ser convertir rangos de valores a un valor identificativo (ingresos desde/hasta determinan la categoria de ingresos n), o relizar operaciones sobre los datos (para determinar la edad de un cliente utilizamos la fecha actual y su fecha de nacimiento), etc. Ademas, cada herramienta software de Data Mining puede tener unos requerimientos especificos que nos obliguen a preparar la información en un formato determinado (por ejemplo, Clementine o PolyAnalyst tienen diferentes tipos de datos). Información detallada de la fase en Dataprix.com.

Esquema del Metodo CRISP
- Modeling: en la fase de modelización, utilizaremos software especifico de data mining como herramientas de visualización (formateo de datos para establecer relaciones entre ellos) o analisis de cluster (para identificar que variables se combinan bien). Estas herramientas pueden ser utiles para un analisis inicial, que se podran complementar con reglas de inducción para desarrollar las reglas de asociación iniciales y profundizar en ellas. Una vez se profundiza en el conocimiento de los datos (a menudo a traves de patrones de reconocimiento obtenidos al visualizar la salida de un modelo), se pueden aplicar otros modelos apropiados de analisis sobre los datos (como por ejemplo arboles de decisión). En esta fase dividiremos los conjuntos de datos entre de aprendizaje y de test. Las herramientas utilizadas nos permitiran generar resultados para varias situaciones. Ademas, el uso interactivo de multiples modelos nos permitira profundizar en el descubrimiento de los datos. Información detallada de la fase en Dataprix.com.
- Evaluation: el modelo resultante debera de ser evaluado en el contexto de los objetivos de negocio establecidos en la primera fase. Esto nos puede llevar a la identificación de otras necesidades que pueden llevarnos a volver a fases anteriores para profundizar (si encontramos por ejemplo, una variable que afecta al analisis pero que no hemos tenido en cuenta al definir los datos). Esto sera un proceso interactivo, en el que ganaremos comprensión de los procesos de negocio como resultado de las tecnicas de visualización, tecnicas estadísticas y de inteligencia artificial, que mostraran al usuario nuevas relaciones entre los datos, y que permitiran conocer mas a fondo los procesos de la organización. Es la fase mas critica, pues estamos haciendo una interpretacion de los resultados. Información detallada de la fase en Dataprix.com.
- Deployment: la mineria de datos puede ser utilizada tanto para verificar hipotesis previamente definidas (pensamos que si hacemos un descuento de un 5% aumentaran las ventas, pero no lo hemos comprobado con un modelo antes de aplicar la medida), o para descubrir conocimiento (identificar relaciones utiles y no esperadas). Este conocimiento descubierto nos puede servir para aplicarlo a los diferentes procesos de negocio y aplicar cambios en la organización donde sea necesario. Por ejemplo, pensar en el tipico ejemplo de la compañia de telefonos moviles que detecta que hay fuga de clientes de larga duración por un mal servicio de atención al cliente. Ese aspecto detectado hará que se realicen cambios en la organización, para mejorar ese aspecto. Los cambios aplicados se podrán monitorizar, para verificar en un tiempo determinado su corrección o no, o si tienen que ser ajustados para incluir nuevas variables. Tambien será importante documentarlos para ser utilizados como base en futuros estudios. Información detallada de la fase en Dataprix.com.
El proceso de seis fases no es un modelo rígido, donde usualmente hay mucha retroalimentación y vuelta a fases anteriores. Ademas, los analistas experimentados no tendran la necesidad de aplicar cada fase en todos los estudios.
SEMMA (Sample, Explore, Modify, Model and Assess).
Con el objetivo de ser aplicadas correctamente, una solución de datamining debe de ser vista como un proceso mas que como un conjunto de herramientas o técnicas. Esto es lo que pretende la metodologia desarrollada por el instituto SAS, llamada SEMMA, que significa sample=muestreo, explore=explora, modify=modifica, model=modeliza y assess=evalua. Este metodo pretende hacer mas facil la realización de exploración estadistica y las tecnicas de visualización, seleccionar y transformar las variables predictivas mas significantes, modelizar las variables para predecir resultados y finalmente confirmar la fiabilidad de un modelo. Al igual que el modelo Crisp, es posible la retroalimentación y el volver a fases anteriores durante el proceso. La representación grafica es la siguiente:
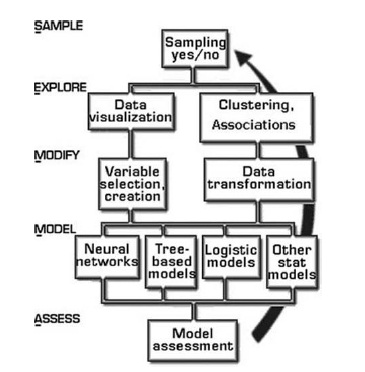 Las fases serían las siguientes:
Las fases serían las siguientes:
- Sample: de un gran volumen de información, extraemos una muestra lo suficientemente significativa y con el tamaño apropiado para poder manipularla con agilidad. Esta reducción del tamaño de los datos nos permite realizar los analisis de una forma mas rapida y conseguimos también obtener información crucial de los datos de una forma mas inmediata. Las muestras de datos las podemos clasificar en tres grupos, segun el objeto para el que se usan: Training (usadas para la construcción del modelo), Validation( usadas para la evaluación del modelo) y Test (usadas para confirmar como se generalizan los resultados de un modelo).
- Explore: en esta fase de exploración el usuario busca tendencias imprevistas o anomalias para obtener una mejor comprensión del conjunto de datos. En esta fase se explora visualmente y numericamente buscando tendencias o agrupaciones. Esta exploracion ayuda a refinar y a redirigir el proceso. En el caso de que los analisis visuales no den resultados, se exploraran los datos con tecnicas estadisticas como analisis de factor, analisis de correspondencia o clustering.
- Modify: aqui es donde el usuario, crea, selecciona y transforma las variables con el objetivo puesto en la construcción del modelo. Basandonos en los descubrimientos de la fase de exploración, modificaremos los datos para incluir información de las agrupaciones o para introducir nuevas variables que pueden ser relevantes, o eliminar aquellas que realmente no lo son.
- Model: cuando encontramos una combinación de variables que predice de forma fiable un resultado deseado. En este momento estamos preparados para construir un modelo que explique los patrones en los datos. Las tecnicas de modelado incluyen las redes neuronales, arboles de decision, modelos logisticos o modelos estadisticos como series de tiempo, razonamientos basados en memoria, etc.
- Assess: en esta fase el usuario evalua la utilidad y fiabilidad de los descubrimientos realizados en el proceso de datamining. Verificaremos aqui lo bien que funciona un modelo. Para ello, podremos aplicarlo sobre muestreos de datos diferentes (de test) o sobre otros datos conocidos, y asi confirmar su vaildez.
Tecnicas de DataMining
Análisis estadístico:
Utilizando las siguientes herramientas:
1.ANOVA: o Análisis de la Varianza, contrasta si existen diferencias significativas entre las medidas de una o más variables continuas en grupo de población distintos.
2.Regresión: define la relación entre una o más variables y un conjunto de variables predictoras de las primeras.
3.Ji cuadrado: contrasta la hipótesis de independencia entre variables. Componentes principales: permite reducir el número de variables observadas a un menor número de variables artificiales, conservando la mayor parte de la información sobre la varianza de las variables.
4.Análisis cluster: permite clasificar una población en un número determinado de grupos, en base a semejanzas y desemejanzas de perfiles existentes entre los diferentes componentes de dicha población.
5.Análisis discriminante: método de clasificación de individuos en grupos que previamente se han establecido, y que permite encontrar la regla de clasificación de los elementos de estos grupos, y por tanto identificar cuáles son las variables que mejor definan la pertenencia al grupo.
Métodos basados en árboles de decisión:
El método Chaid (Chi Squared Automatic Interaction Detector) es un análisis que genera un árbol de decisión para predecir el comportamiento de una variable, a partir de una o más variables predictoras, de forma que los conjuntos de una misma rama y un mismo nivel son disjuntos. Es útil en aquellas situaciones en las que el objetivo es dividir una población en distintos segmentos basándose en algún criterio de decisión.
El árbol de decisión se construye partiendo el conjunto de datos en dos o más subconjuntos de observaciones a partir de los valores que toman las variables predictoras. Cada uno de estos subconjuntos vuelve después a ser particionado utilizando el mismo algoritmo. Este proceso continúa hasta que no se encuentran diferencias significativas en la influencia de las variables de predicción de uno de estos grupos hacia el valor de la variable de respuesta.
La raíz del árbol es el conjunto de datos íntegro, los subconjuntos y los subsubconjuntos conforman las ramas del árbol. Un conjunto en el que se hace una partición se llama nodo.
El número de subconjuntos en una partición puede ir de dos hasta el número de valores distintos que puede tomar la variable usada para hacer la separación. La variable de predicción usada para crear una partición es aquella más significativamente relacionada con la variable de respuesta de acuerdo con test de independencia de la Chi cuadrado sobre una tabla de contingencia.
Algoritmos genéticos:
Son métodos numéricos de optimización, en los que aquella variable o variables que se pretenden optimizar junto con las variables de estudio constituyen un segmento de información. Aquellas configuraciones de las variables de análisis que obtengan mejores valores para la variable de respuesta, corresponderán a segmentos con mayor capacidad reproductiva. A través de la reproducción, los mejores segmentos perduran y su proporción crece de generación en generación. Se puede además introducir elementos aleatorios para la modificación de las variables (mutaciones). Al cabo de cierto número de iteraciones, la población estará constituida por buenas soluciones al problema de optimización.
Redes neuronales:
Genéricamente son métodos de proceso numérico en paralelo, en el que las variables interactúan mediante transformaciones lineales o no lineales, hasta obtener unas salidas. Estas salidas se contrastan con los que tenían que haber salido, basándose en unos datos de prueba, dando lugar a un proceso de retroalimentación mediante el cual la red se reconfigura, hasta obtener un modelo adecuado.
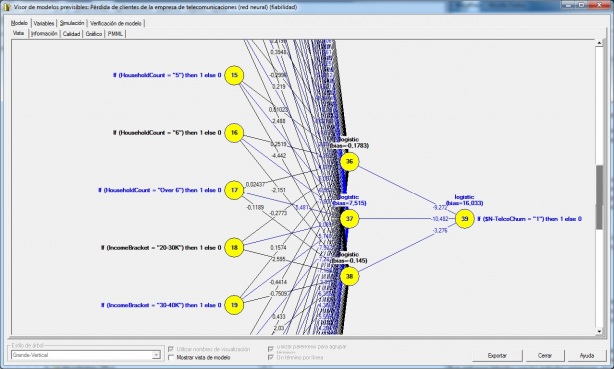
Red Neuronal en Microstrategy
Lógica difusa:
Es una generalización del concepto de estadística. La estadística clásica se basa en la teoría de probabilidades, a su vez ésta en la técnica conjuntista, en la que la relación de pertenencia a un conjunto es dicotómica (el 2 es par o no lo es). Si establecemos la noción de conjunto borroso como aquel en el que la pertenencia tiene una cierta graduación (¿un día a 20ºC es caluroso?), dispondremos de una estadística más amplia y con resultados más cercanos al modo de razonamiento humano.
Series temporales:
Es el conocimiento de una variable a través del tiempo para, a partir de ese conocimiento, y bajo el supuesto de que no van a producirse cambios estructurales, poder realizar predicciones. Suelen basarse en un estudio de la serie en ciclos, tendencias y estacionalidades, que se diferencian por el ámbito de tiempo abarcado, para por composición obtener la serie original. Se pueden aplicar enfoques híbridos con los métodos anteriores, en los que la serie se puede explicar no sólo en función del tiempo sino como combinación de otras variables de entorno más estables y, por lo tanto, más fácilmente predecibles.
Clasificación de las técnicas de Data Mining
Las tecnicas de Data Mining las podemos clasificar en Association, Classification, Clustering, Predictions y Series Temporales.
- Association (asociacion): la relacion entre un item de una transaccion y otro item en la misma transacción es utilizado para predecir patrones. Por ejemplo, un cliente compra un ordenador (X) y a la vez compra un raton(Y) en un 60% de los casos. Este patron ocurre en un 5,6% de las compras de ordenadores. La regla de asociación en esta situación es que “X implica Y, donde 60% es el factor de confianza y 5,6% el factor de soporte. Cuando el factor de confianza y al factor de soporte estan representados por las variables linguisticas alto y bajo, la regla de asociacion se puede escribir en forma de logica difusa, como: “cuando el factor de suporte es bajo, X implica Y es alto”. Este seria el tipico ejemplo de datamining de estudio realizado en supermercados con la asociación entre la venta de pañales de bebe y cerveza (ver entrada del blog Bifacil). Usan los algoritmos de reglas de asociación y arboles de decisión.
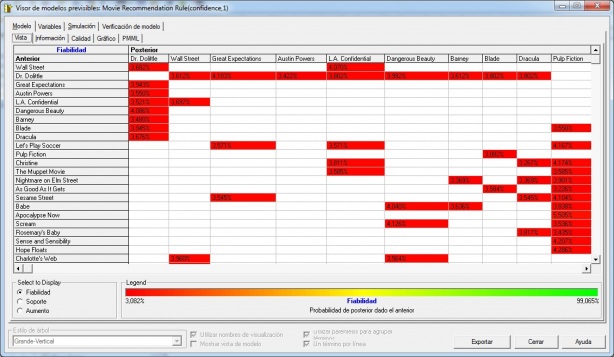
Modelo Asociacion en Microstrategy - Compra de Peliculas de DVD
- Classification (clasificacion): en la clasificación, los metodos tienen la intención de aprender diferentes funciones que clasifiquen los datos dentro de un conjunto predefinido de clases. Dado un nuevo de clases predefinidas, un numero de atributos y un conjunto de datos de aprendizaje o entrenamiento, los metodos de clasificación pueden automaticamente predecir la clase de los datos previamente no clasificados. Las claves mas problematicas relacionadas con la clasificación son las evaluacion de los errores de clasificación y la potencia de predicción. Las tecnicas matematicas mas usadas para la clasificación son los arboles de decisión binarios, las redes neuronales, programación lineal y estadistica. Utilizando un arbol de decisión binario, con un modelo de inducción de arbol en el formato Si-No, podremos posicionar los datos en las diferentes clases según el valor de sus atributos. Sin embargo, esta clasificación puede no ser optima si la potencia de predicción es baja. Con el uso de redes neuronales, se puede construir un modelo de inducción neuronal. En este modelo, los atributos son capas de entrada y las clases asociadas con los datos son las capas de salida. Entre las capas de entrada y de salida hay un gran numero de conexiones ocultas que aseguran la fiabilidad de la clasificación (como si fuesen las conexiones de una neurona con las de su alrededor).El modelo de induccion neuronal ofrece buenos resultados en muchos analisis de data mining, cuando hay un gran numero de relaciones se complica la implementación del metodo por el gran numero de atributos. Usando tecnicas de programación lineal, el problema de la clasificación es visto como un caso especial de programación lineal. La programación lineal optimiza la clasificación de los datos, pero puede dar lugar a modelos complejos que requieran gran tiempo de computación. Otros metodos estadisticos, como la regresión lineal, regresion discriminante o regresión logistica tambien son populares y usados con frecuencia en las procesos de clasificación.
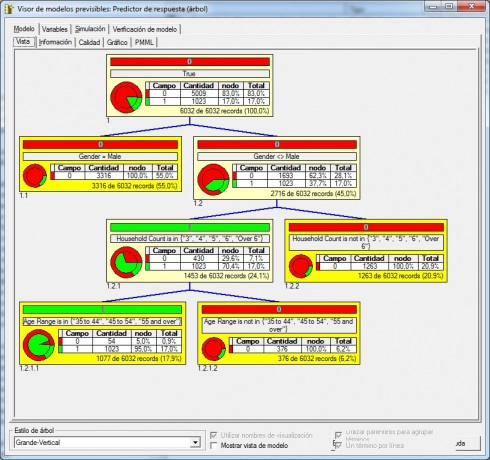
Arbol Decision en Microstrategy
- Clustering (segmentación): el analisis de cluster toma datos sin agrupar y mediante el uso de tecnicas automaticas realiza la agrupación de estos. El clustering no esta supevisado y no requiere un set de datos de aprendizaje. Comparte un conjunto de metodologias con la clasificación. Es decir, muchos de los modelos matematicos utilizados en la clasificación pueden ser aplicados al analisis cluster tambien. Usan los algoritmos de clustering y de sequence clustering.
- Prediction (predicción)/Estimación: el analisis de predicción esta relacionado con la tecnicas de regresión. La idea principal del analisis de predicción es descubrir las relaciones entre variables dependientes e independientes y las relaciones entre variables independientes. Por ejemplo, si las ventas es una variable independientes, el benefición puede ser una variable dependiente.
- Series Temporales (pronostico): utilizando datos historicos junto con tecnicas de regresión lineal o no lineal, podemos producir curvas de regresión que se utilizaran para establecer predicciones a futuro. Usan los algoritmos de series de tiempo.
Ejemplo 1. Analisis de cesta de la compra (Asociacion).
Es el tipico ejemplo que se utiliza para explicar los ambitos de utilización del datamining ( con la asociación entre la venta de pañales de bebe y cerveza ). En nuestro caso, utilizando los ejemplos que proporciona Microstrategy en su plataforma, en el proyecto de aprendizaje que llaman Microstrategy Tutorial, veremos un ejemplo de utilización de técnicas de analisis de asociacion.
En el ejemplo, se analizan las ventas de DVD´s de unos grandes almacenes y se trata de encontrar la asociación entre la venta de diferentes peliculas. Es decir, intentamos encontrar que títulos se venden conjuntamente con el objetivo de establecer posteriormente promociones comerciales de esas peliculas (por ejemplo, venta de packs, ubicación de las peliculas juntas en los pasillos, promoción de descuento por la compra de la segunda unidad, etc), con el objetivo de aumentar las ventas. Para este tipo de analisis utilizaremos analisis de reglas de asociación.
Ejemplo 2. Segmentación de clientes (Analisis de cluster).
Con este analisis pretendemos analizar nuestros clientes y utilizando información demográfica de ellos (edad, educación, numero de hijos, estado civil o tipo de hogar), realizar una segmentación de mercado para preparar el lanzamiento de determinados productos o la realización de ofertas promocionales.
En este caso, realizaremos un analisis de cluster, utilizando el algoritmo k-means, que es el que soporta Microstrategy.
Ejemplo 3. Predicción de ventas en una campaña (Arbol de decisión).
En este analisis utilizaremos un arbol de decisión para determinar la respuesta de un determinado grupo de clientes a rebajas en determinados productos en la epoca de vuelta al colegio. Para ello, utilizaremos arboles de decisión del tipo binario (recordemos que los arboles de decisión se pueden utilizar tanto para clasificación como para analisis de regresión, como en este caso). Intentaremos determinar como influyen factores como la edad, el sexo o el numero de hijos en la probabilidad de realizar compras en esa campaña de rebajas.
En la proxima entrada del blog detallaremos estos ejemplos utilizando las herramientas de Data Mining de Microstrategy.
