
Data Science - Breve guía para interpretar modelos cluster
- Lee más sobre Data Science - Breve guía para interpretar modelos cluster
- Inicie sesión para enviar comentarios
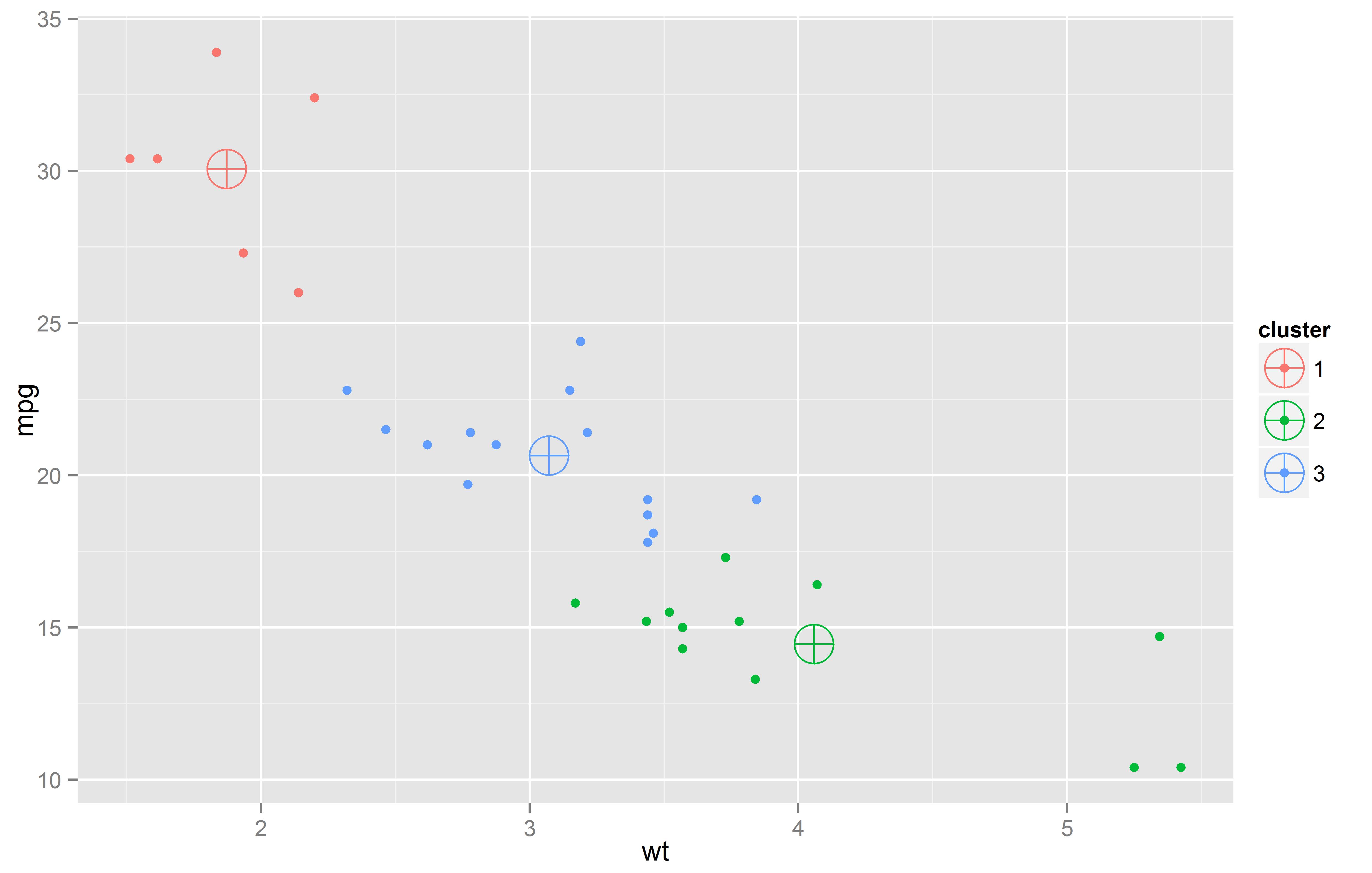 En clustering se deja que los datos se agrupen de acuerdo a su similitud. Estos modelos son agrupaciones de segmentos -clusters- que contienen casos, tales como clientes, pacientes, autos, etc.
En clustering se deja que los datos se agrupen de acuerdo a su similitud. Estos modelos son agrupaciones de segmentos -clusters- que contienen casos, tales como clientes, pacientes, autos, etc.
Una vez que un modelo de cluster es desarrollado, una pregunta emerge: ¿Cómo puedo describir mi modelo?
Aquí presentaremos una manera para acercarnos a la respuesta, a través de la implementación del Gráfico de Coordenadas in R (código disponible al final del post)..
 Los outliers, (o "valores extremos"), son un tema siempre presente cuando se analizan datos, sin importar el origen de los mismos. Aquí se presenta un análisis didáctico y visual hecho con el lenguaje R..
Los outliers, (o "valores extremos"), son un tema siempre presente cuando se analizan datos, sin importar el origen de los mismos. Aquí se presenta un análisis didáctico y visual hecho con el lenguaje R.. El siguiente análisis está realizado con el lenguaje R y la libreria Google Vis para la visualización de gráficos. Es tan importante medir la esperanza de vida así como también la calidad de la misma. Se analizarán datos de eurostat basados en las variables Healthy life years y Life expectancy..
El siguiente análisis está realizado con el lenguaje R y la libreria Google Vis para la visualización de gráficos. Es tan importante medir la esperanza de vida así como también la calidad de la misma. Se analizarán datos de eurostat basados en las variables Healthy life years y Life expectancy..


 La semana pasada asistí a un encuentro de RugBcn, el Grupo de Usuarios de R de Barcelona, que tenía por objetivo mostrar cómo crear informes automáticos directamente desde R gracias a las librerías rmarkdown y knitr. El título del evento era 'Automatic Reporting with rmarkdown'.
La semana pasada asistí a un encuentro de RugBcn, el Grupo de Usuarios de R de Barcelona, que tenía por objetivo mostrar cómo crear informes automáticos directamente desde R gracias a las librerías rmarkdown y knitr. El título del evento era 'Automatic Reporting with rmarkdown'.


 Existen muchos mitos que no son lo que parecen, y en el mundo del BI también. Estos son los seis mitos identificados por Qlik más comunes en entornos de Inteligencia de Negocios..
Existen muchos mitos que no son lo que parecen, y en el mundo del BI también. Estos son los seis mitos identificados por Qlik más comunes en entornos de Inteligencia de Negocios...jpg) Para hacer un update de SQL Server podemos utilizar una join de la tabla que actualizamos contra otra tabla de la base de datos, que contiene la información que necesitamos. Pero si la join es contra la misma tabla (self-join) hay que cambiar un poco la sentencia para que funcione bien..
Para hacer un update de SQL Server podemos utilizar una join de la tabla que actualizamos contra otra tabla de la base de datos, que contiene la información que necesitamos. Pero si la join es contra la misma tabla (self-join) hay que cambiar un poco la sentencia para que funcione bien..