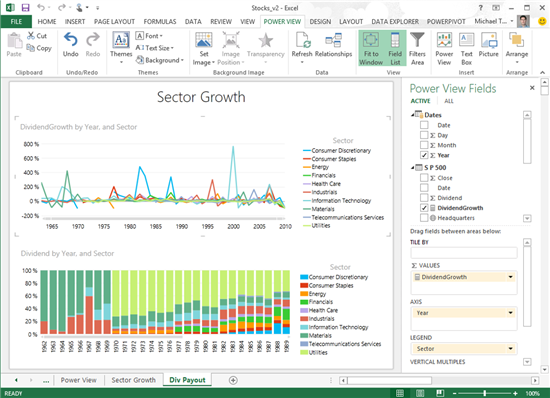
TOP 10 Software o Plataforma de Datos para Empresas: La clasificación de Dataprix 2025

La capacidad de gestionar y analizar grandes volúmenes de datos es esencial para la competitividad de cualquier empresa. El software de base de datos y las plataformas de datos proporcionan el soporte necesario para integrar, almacenar y procesar información de manera ágil y segura.
En Dataprix hemos elaborado nuestro TOP 10 de software o plataforma de datos, una clasificación que reúne las soluciones más destacadas del mercado en términos de rendimiento, escalabilidad, seguridad e integración. Descubre las 10 herramientas que están transformando la gestión de datos en las empresas.

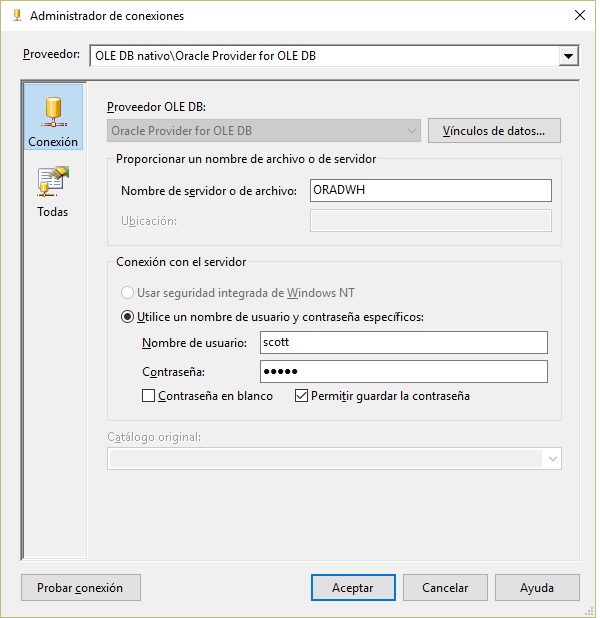 Conectar flujos de datos de Integration Services con bases de datos Oracle es muy sencillo, siempre que tengas bien configurado el driver de Oracle que te va a permitir esta conexión.
Conectar flujos de datos de Integration Services con bases de datos Oracle es muy sencillo, siempre que tengas bien configurado el driver de Oracle que te va a permitir esta conexión.
 Uno de los problemas que encuentran muchas empresas a la hora de vender es que las puertas a las que llaman se encuentran cerradas. O dicho de otro modo, los clientes a los que están contactando no les prestan atención. El primer paso para tener un base de datos de clientes de calidad comienza por una adecuada captación. Cuando los equipos de ventas y marketing no captan clientes de forma adecuada se reduce mucho la tasa de conversión, haciendo que nuestros esfuerzos no se traduzcan en mejoras en la facturación y creando frustración en los equipos comerciales..
Uno de los problemas que encuentran muchas empresas a la hora de vender es que las puertas a las que llaman se encuentran cerradas. O dicho de otro modo, los clientes a los que están contactando no les prestan atención. El primer paso para tener un base de datos de clientes de calidad comienza por una adecuada captación. Cuando los equipos de ventas y marketing no captan clientes de forma adecuada se reduce mucho la tasa de conversión, haciendo que nuestros esfuerzos no se traduzcan en mejoras en la facturación y creando frustración en los equipos comerciales.. Mantenerse actualizado es bueno y de vez en cuando va bien probar cosas nuevas que nos puedan permitir mejorar en algún aspecto de nuestro día a día. De vez en cuando me gusta ir viendo nuevas herramientas y tratar de seguir siendo proactivo para hacer mejor mi trabajo o al menos más cómodo. Anteriormente comente en otro post la existencia de un complemento de Apex llamado Refactor que permitía refactorizar para codificar de forma más clara y/o automática. En este post comento un poco el funcionamiento de una herramienta que se llama SQL Sentry Plan Explorer.
Mantenerse actualizado es bueno y de vez en cuando va bien probar cosas nuevas que nos puedan permitir mejorar en algún aspecto de nuestro día a día. De vez en cuando me gusta ir viendo nuevas herramientas y tratar de seguir siendo proactivo para hacer mejor mi trabajo o al menos más cómodo. Anteriormente comente en otro post la existencia de un complemento de Apex llamado Refactor que permitía refactorizar para codificar de forma más clara y/o automática. En este post comento un poco el funcionamiento de una herramienta que se llama SQL Sentry Plan Explorer.