
En muchos casos el modelo aprendido no es de interés sino la exactitud del modelo. Una posible solución para estimar la precisión del modelo aprendido es aplicarlo a datos de prueba etiquetados y calcular la cantidad de errores de predicción (u otros criterios de performance). Debido a que los datos etiquetados son poco frecuentes, a menudo se usan otros enfoques para estimar la performance de un esquema de aprendizaje. Este proceso muestra la “validación cruzada” en RapidMiner.
La validación cruzada divide los datos etiquetados en conjuntos de entrenamiento y de prueba. Los modelos se aprenden sobre los datos de entrenamiento y se aplican sobre los datos de prueba. Los errores de predicción se calculan y promedian para todos los subconjuntos. Este bloque de construcción se puede utilizar como operador interno para varios wrappers (contenedores) como los operadores de generación/selección de características.
Este es el primer ejemplo de un proceso más complejo. Los operadores construyen una estructura de árbol. Por ahora esto es suficiente para aceptar que el operador de validación cruzada requiere un conjunto de ejemplos como entrada y entrega un vector de valores de performance como salida. Además gestiona la división en ejemplos de entrenamiento y de prueba. Los ejemplos de entrenamiento se utilizan como entrada para el aprendiz de entrenamiento, el cual entrega un modelo. Este modelo y los ejemplos de prueba forman la entrada de la cadena de aplicadores que entregan la performance para este conjunto de prueba. Los resultados para todos los posibles conjuntos de prueba son recogidos por el operador de validación cruzada. Finalmente se calcula el promedio y se entrega como resultado.
Una de las cosas más difíciles para el principiante de RapidMiner es a menudo tener una idea del flujo de datos. La solución es sorprendentemente simple: el flujo de datos se asemeja a una búsqueda primero en profundidad a través de la estructura de árbol. Por ejemplo, después de procesar el conjunto de entrenamiento con el primer hijo de la validación cruzada del modelo aprendido, se entrega al segundo hijo (la cadena de aplicadores). Esta idea básica de flujo de datos es siempre la misma para todos los procesos y pensar en este flujo será muy conveniente para el usuario experimentado.
1. Agregar el operador Repository Access → Retrieve a la zona de trabajo y localizar el archivo //Samples/data/Polynomial con el navegador del parámetro repository entry.
2. Agregar el operador Evaluation → Validation → X-Validation. Cambiar el nombre del mismo a “XVal” y el valor del parámetro sampling type (tipo de muestreo) a “shuffled sampling” (modo experto). Conectar la salida del operador Retrieve a la entrada tra (training) de este operador y la salida ave (averagable, promediable) de éste último al conector res (result) del panel.
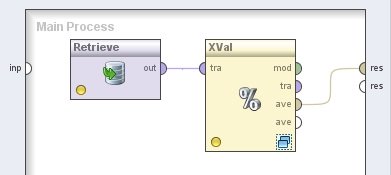
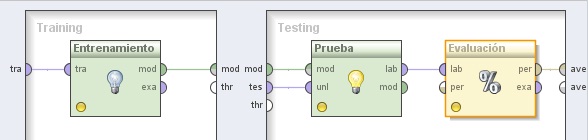
3. Hacer doble clic sobre el operador XVal (X-Validation). En el panel Training del nivel inferior, agregar el siguiente operador:
3.1 Modeling → Classification and Regression → Support Vector Modeling → Support Vector Machine (LibSVM). Cambiar el nombre del mismo a “Entrenamiento” y los valores de los parámetros svm type a “epsilon-SVR”, kernel type a “poly” y C a 1000.0. Conectar la entrada tra (training) y salida mod (model) de este operador a los puertos tra y mod del panel, respectivamente
En el panel Testing de la derecha, agregar los siguientes operadores:
3.2 Modeling → Model Application → Apply Model. Cambiar el nombre del mismo a “Prueba” y conectar las entradas mod y tes del panel a las entradas mod y unl de este operador, respectivamente.
3.3 Evaluation → Performance Measurement → Classification and Regression → Performance (Regression). Cambiar el nombre del mismo a “Evaluación” y tildar las siguientes opciones (además de las que están tildadas por defecto): absolute error (error absoluto), relative error (error relativo), normalized absolute error (error absoluto normalizado), root relative squared error (raíz cuadrada del error relativo al cuadrado), squared error (error al cuadrado), y correlation (correlación). Conectar la salida lab (labeled
data, datos etiquetados) del operador Prueba (Apply Model) a la entrada lab de este operador y la salida per (performance) de éste último al conector ave (averagable 1) del panel.
4. Ejecutar el proceso. El resultado es una estimación de la performance del esquema de aprendizaje sobre los datos de entrada.
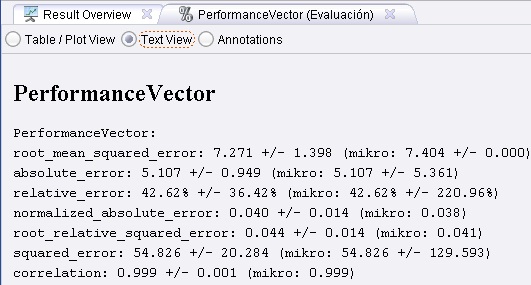
5. Seleccionar el operador de evaluación y elejir otros criterios de performance. El criterio principal se utiliza para las comparaciones de performance, por ejemplo, en un wrapper.
6. Sustituir la validación cruzada XVal por otros esquemas de evaluación y ejecutar el proceso con ellos. Alternativamente, se puede verificar cómo funcionan otros aprendices sobre estos datos y sustituir el operador de entrenamiento.
