
IA y Arquitecturas de Datos: Cómo Redefinir tu Plataforma para una Empresa AI-Native

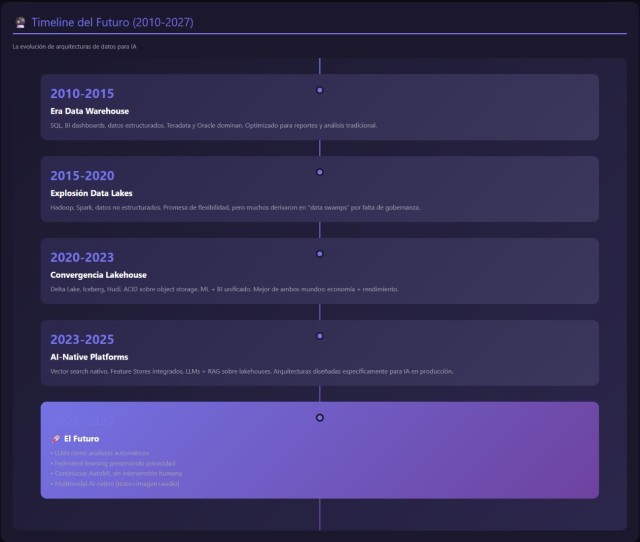
La Inteligencia Artificial ha dejado de ser una capa funcional superpuesta a los sistemas tradicionales para convertirse en un principio estructural que redefine cómo deben diseñarse, gobernarse y operar las arquitecturas de datos modernas.
Durante décadas, las plataformas empresariales se han construido alrededor de patrones estables: bases de datos relacionales, almacenes centralizados, ETLs recurrentes y modelos de gobernanza que asumían que el dato era fundamentalmente un activo estático.
Sin embargo, la irrupción de modelos de machine learning —y, más recientemente, los modelos generativos y LLMs— ha provocado un cambio profundo: ahora el dato es dinámico, contextual, tiempo-dependiente y semánticamente rico..
 This article will describe the relevance of open source software and big data before describing five interesting and useful open source big data tools and projects.
This article will describe the relevance of open source software and big data before describing five interesting and useful open source big data tools and projects.