
Dentro de las actividades de Gestión de los Datos que realiza una organización resultan cada vez más críticos los procesos que supervisan y garantizan la calidad de los datos. El volumen de información crece constantemente en las organizaciones y disponer de almacenes de datos fiables resulta imprescindible para realizar un correcto análisis y explotación de los mismos evitando inconsistencias, conclusiones erróneas y facilitando el desarrollo de futuros sistemas basados en maestros de datos consistentes, depurados, enriquecidos y fiables. Se trata de un pilar básico dentro de las actividades de Gobierno de Dato y tal y como revela el siguiente post: Un estudio de Information Builders revela la poca calidad de los datos en las empresas, un aspecto poco cuidado por las empresas.
Por otro lado, actualmente hay situaciones coyunturales que obligan a una inversión fuerte en procesos de calidad de datos, como puede ser la fusión o compra de empresas. En estas situaciones aparece una importante necesidad de normalización, como puede ser la unificación e BBDD de clientes, empleados, productos, servicios, etc..
De igual forma hay procesos de la empresa para los que son clave la fiabilidad de los datos, como pueden ser los datos de clientes en las acciones comerciales o en el cumplimiento de legislaciones tipo LOPD o cuestiones técnicas como migraciones de plataforma tecnológica.
Estos procesos ya no sólo afectan a compañías con extensas BBDD de clientes como un operador de telecomunicaciones o una entidad financiera o seguros, sino que empieza a ser un proceso vital para cualquier compañía con un grado de madurez importante en sus sistemas de información.
A continuación realizamos un repaso de las principales fases y actividades que conforman los procesos de análisis, mejora y control de los de datos.
Análisis y perfilado de datos
En esta fase se realiza un análisis de las diferentes fuentes de datos origen del Data Mart o Data Warehouse. El objetivo del análisis es conocer la estructura, contenido, fiabilidad y relaciones entre los datos. Esto conlleva analizar:
-
La estructura de las fuentes origen: tipo de fuente (fichero host, Excel, tabla BBDD, XML, etc..) tipo de estructura (bloque fijo, bloque variable, etc..), formatos de los campo (tipo de datos, longitud, etc..) y nivel de granularidad. Nos topamos aquí con la información no estructurada cuyo análisis merece capítulo aparte.
-
Contenido de los datos: tipo de información que contiene cada fuente y campo. Identificar qué información es realmente relevante para el análisis.
-
Identificación de claves únicas. Identificación de posibles claves foráneas.
-
Validaciones técnicas: integridad, duplicidades, valores obligatorios, nulos, etc…
-
Validaciones en base a reglas de negocio. Por ejemplo, rangos de valores límites, valores no posibles, umbrales (edad < 0, código postal de más de n dígitos, número de cuenta corriente de menos de n dígitos, etc..).
-
Identificación de duplicados, no sólo por validación técnica de clave idéntica, sino de posibles duplicados entre registros que contienen campos con diferentes valores, pero que por error de grabación pueden ser el mismo.
-
Estadísticas y distribuciones de datos. Ejemplo centrándonos en una columna efectuar conteos, agregaciones, valores máximos, mínimos, medio, desviaciones, frecuencias, distribución de los valores, rangos de valores, número de valores distintos, ratio de nulos, distribución de longitudes, etc…
-
Estadística predictiva: en base a la estadísticas realizadas, obtener el valor más probable, más frecuente, construir tablas de frecuencia en base a las existentes.
-
Análisis de los campos descriptivos (descripciones incompletas, errores ortográficos y confusiones fonéticas, caracteres extraños, descripciones en diferentes idiomas, etc..), cualquier tipo de error que deba ser corregido o normalizado antes de ser tratada esa información. Reconocimiento de patrones.
-
Estudiar la codificación de los campos. Existencia de diferentes codificaciones del mismo campo (ejemplo código cliente o producto, diferente en sistemas de marketing y en sistemas de facturación o en función del ERP que provee la información) y reglas de relación (tablas de normalización) entre ellas.
-
Relaciones entre las diferentes fuentes origen. Relaciones entre los campos de una misma fuente. Tipo de relaciones, tipo de dependencias. Identificar restricciones en las relaciones que pueden dar problemas. Detectar relaciones ocultas o no evidentes entre los datos.
-
Identificar campos comunes y estandarizados, que deben seguir un patrón establecido, para tratamiento y normalización estándar. Ejemplo: nacionalidad, nombres, direcciones postales, teléfono, e-mail, código divisa, código cuenta correinte, código entidad financiera, etc…
-
Determinar el posible impacto de datos de baja calidad. Profundizar en registros específicos con mala calidad de datos para determinar su impacto en el negocio y hallar una solución. Una mala calidad de datos, no impacta los mismo según qué tipo de información provea y puede haber casos de gran impacto en el análisis final de la información.
-
Definir las acciones a tomar en los errores detectados. Ejemplo: si debemos establecer código de valor indeterminado para los nulos, qué hacer en los errores de integridad referencial, etc..
Esta fase nos proporciona un conocimiento minucioso de la información de origen que debe servir para establecer pautas sobre su posterior normalización, depuración, mejora y tratamiento. Se trabaja a todos los niveles (columna, tabla, modelo). En esta fase debemos identificar qué fuentes pueden dar problemas por cuestiones estructurales para su descarte o modificación con objeto de evitar problemas posteriores. Las actuales herramientas de perfilado de datos proveen una interfaz que facilita la fácil visualización de las relaciones entre los datos y automatizan considerablemente la creación, ejecución y reutilización de reglas de validación y limpieza. Estas herramientas, como es lógico, deben disponer de conectores para acceder a todo tipo de fuentes de datos y todo tipo de plataformas, considerando diferentes infraestructuras tanto locales, remotas como cloud. Así mismo, deben minimizar el movimiento de datos.
Normalización, mejora y enriquecimiento de los datos
El paso posterior al perfilado de datos es la normalización y mejora de los mismos.
Una primera técnica en la normalización de datos sería reconocer entidades de texto con cadenas de texto diferentes, pero que representan la misma entidad de datos.
Un ejemplo típico sería el de las direcciones postales:
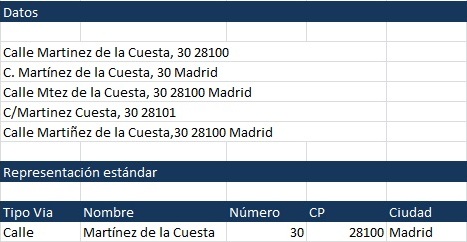
En una normalización de direcciones deberíamos conseguir:
-
Separar los datos en diferentes campos: tipo vía, nombre, número de vía, código postal y ciudad.
-
Marcar registros duplicados mediante la comparación de los campos identificados.
-
Detectar errores tipográficos, abreviaturas, prefijos, etc...
-
Diferentes juegos de caracteres.
-
Eliminar caracteres no deseados.
-
Añadir otros campos como el código postal.
-
Corregir y codificar la vía utilizando BBDD estándar (ejemplo INE).
-
Detectar y corregir cambios de nombre en direcciones.
-
Marcar direcciones no válidas.
-
Asignar, finalmente un indicador de fiabilidad.
Para ello y apoyándonos en el perfilado de datos realizado inicialmente hay que realizar un parsing de datos, el analizador sintáctico debe extraer componentes con significado, en nuestro ejemplo direcciones postales, que después puedan ser normalizados.
El resultado final es una representación única y estandarización de direcciones.
Caso similar puede ser el de los nombres:
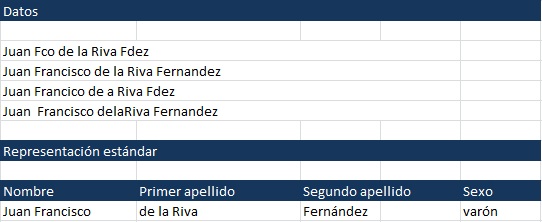
En donde el objetivo debe ser:
-
Señalar nombres no identificables.
-
Eliminar caracteres no deseados.
-
Dividir cadenas en nombre, primer y segundo apellido. Obtener representación estándar considerando nombres y apellidos compuestos, preposiciones que preceden apellidos, etc..
-
Añadir género en función del nombre de pila.
-
Marcar registros duplicados mediante la comparación de los campos identificados.
-
Corregir errores de grabación, errores tipográficos, errores ortográficos.
-
Interpretar abreviaturas.
-
Asignar, un indicador de fiabilidad.
En estos casos particulares de nombres y direcciones postales hay que tener en cuenta que normalizar nombres y direcciones es imprescindible para realizar de forma eficaz campañas de marketing, facilita la segmentación por sexo de estas campañas. Igualmente la LOPD exige que los datos de carácter personal sean exactos.
En los casos de aplicación de calidad de datos a las acciones de marketing es necesario también normalizar teléfonos y direcciones de e-mail, de forma que:
-
Validar cuentas de correo electrónico: direcciones mal escritas, validar existencia de dominio, validación a nivel SMTP, etc..
-
Marcar números de teléfono incorrectos, asignar el prefijo telefónico según la población, validaciones a nivel de vía y número.
En estos procesos un paso fundamental es el ‘matching’ entre diferentes fuentes de datos. De tal forma que en el cruce de registros entre tablas, eliminemos duplicados, unifiquemos códigos empleando tablas de normalización (relaciones entre códigos), seleccionemos el registro más fiable y finalmente realicemos una consolidación de datos.
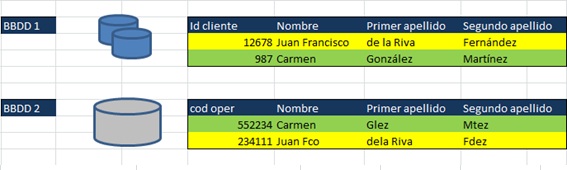
Son de especial relevancia los procesos de matching en los casos de compras o fusiones entre empresas, en el establecimiento de datos maestros en una organización, en la adquisición de bases de datos externas, etc…, en estos procesos la deduplicación de registros supone un ahorro de costes muy considerable.
En el apartado de enriquecimiento de datos, basaremos estos procesos en la utilización de bases de datos estándar como pueden ser: bases de datos de códigos postales, direcciones postales, localidades, bases de datos para geolocalización y georeferenciación, bases de datos empresas, hogares y otras de carácter más amplio como bases de datos con datos sociodemográficos, bases de datos de instituciones estadísticas (ejemplo INE), etc..
Monitorización y calidad de datos en tiempo real
Una vez realizados los anteriores pasos y una vez que consideramos el dato un recurso estratégico de la organización se hace necesario realizar una monitorización y seguimiento de la calidad de los mismos.
Hay que definir métricas, en base a las reglas de calidad de datos construidas. Se establecerán indicadores de calidad de datos, objetivos en la calidad de los mismos y se definirán scorecards de calidad de datos que permitan realizar un seguimiento continuo estableciendo alertas que nos informen sobre posibles entidades o sistemas con baja calidad de datos. Estos indicadores deben basarse en los objetivos que persiguen los procesos de calidad de datos:
-
Precisión
-
Integridad
-
Consistencia
-
Completitud
-
Validez
-
Oportunidad
-
Accesibilidad
Las reglas definidas en los anteriores pasos que auditan, normalizan y enriquecen los datos de la organización, deben ser implementadas en una última fase como servicios de calidad de datos en tiempo real. De forma que aseguremos la calidad en los nuevos datos que entran a nuestros sistemas y en las nuevas entidades de datos que incorporemos a nuestros sistemas corporativos. Esta automatización de las reglas de calidad de datos y su integración en los sistemas corporativos, suponen un servicio en tiempo real, que actúa a modo de firewall que asegura la calidad del dato.
Herramientas de calidad de datos
Se trata de un mercado actualmente en expansión, muchas empresas realizan algunos de los procesos de calidad de dato en base a procedimientos de bases de datos o programas SQL a medida o bien utilizando las prestaciones de calidad de datos incluidas en las herramientas ETL. Se estima que sólo un tercio de las empresas cuentan con herramientas específicas de calidad de datos.
