
Data Science - Breve guía para interpretar modelos cluster
- Lee más sobre Data Science - Breve guía para interpretar modelos cluster
- Inicie sesión para enviar comentarios
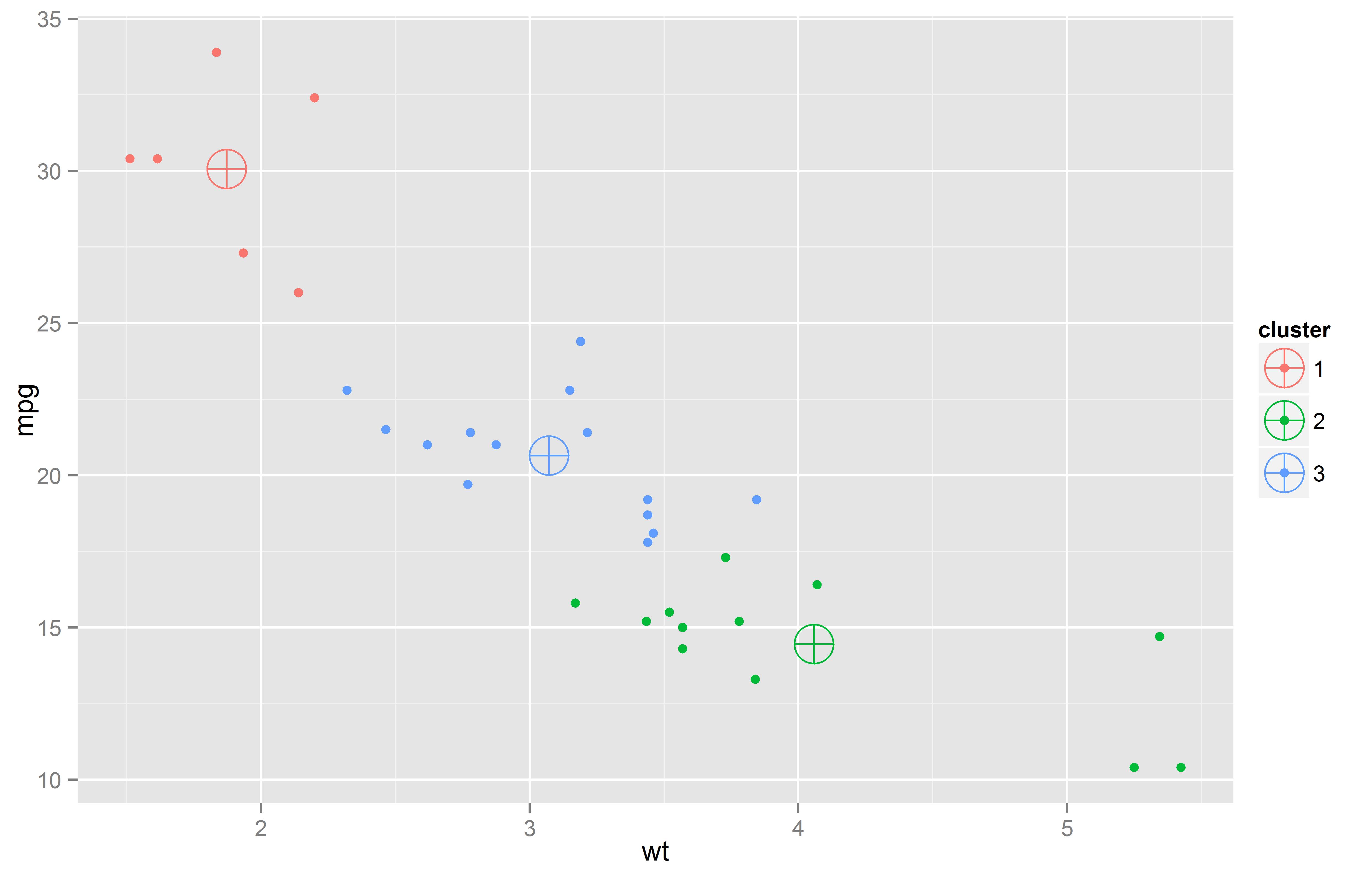 En clustering se deja que los datos se agrupen de acuerdo a su similitud. Estos modelos son agrupaciones de segmentos -clusters- que contienen casos, tales como clientes, pacientes, autos, etc.
En clustering se deja que los datos se agrupen de acuerdo a su similitud. Estos modelos son agrupaciones de segmentos -clusters- que contienen casos, tales como clientes, pacientes, autos, etc.
Una vez que un modelo de cluster es desarrollado, una pregunta emerge: ¿Cómo puedo describir mi modelo?
Aquí presentaremos una manera para acercarnos a la respuesta, a través de la implementación del Gráfico de Coordenadas in R (código disponible al final del post)..
 El siguiente análisis está realizado con el lenguaje R y la libreria Google Vis para la visualización de gráficos. Es tan importante medir la esperanza de vida así como también la calidad de la misma. Se analizarán datos de eurostat basados en las variables Healthy life years y Life expectancy..
El siguiente análisis está realizado con el lenguaje R y la libreria Google Vis para la visualización de gráficos. Es tan importante medir la esperanza de vida así como también la calidad de la misma. Se analizarán datos de eurostat basados en las variables Healthy life years y Life expectancy.. Los outliers, (o "valores extremos"), son un tema siempre presente cuando se analizan datos, sin importar el origen de los mismos. Aquí se presenta un análisis didáctico y visual hecho con el lenguaje R..
Los outliers, (o "valores extremos"), son un tema siempre presente cuando se analizan datos, sin importar el origen de los mismos. Aquí se presenta un análisis didáctico y visual hecho con el lenguaje R..
 La semana pasada asistí a un encuentro de RugBcn, el Grupo de Usuarios de R de Barcelona, que tenía por objetivo mostrar cómo crear informes automáticos directamente desde R gracias a las librerías rmarkdown y knitr. El título del evento era 'Automatic Reporting with rmarkdown'.
La semana pasada asistí a un encuentro de RugBcn, el Grupo de Usuarios de R de Barcelona, que tenía por objetivo mostrar cómo crear informes automáticos directamente desde R gracias a las librerías rmarkdown y knitr. El título del evento era 'Automatic Reporting with rmarkdown'. El libro Practical Data Science Cookbook es una introducción al mundo del Data Science a través de ejemplos prácticos en forma de recetas, que van enseñando cómo podría ser el proceso típico de analítica de datos que puede realizar un Científico de Datos con un entorno de analítica configurado para trabajar con el potente lenguaje de analítica y estadística R, o con el versátil lenguaje Python..
El libro Practical Data Science Cookbook es una introducción al mundo del Data Science a través de ejemplos prácticos en forma de recetas, que van enseñando cómo podría ser el proceso típico de analítica de datos que puede realizar un Científico de Datos con un entorno de analítica configurado para trabajar con el potente lenguaje de analítica y estadística R, o con el versátil lenguaje Python.. El libro Haskell Data Analysis Cookbook, de Nishant Shukla, hace un recorrido por las principales técnicas y algoritmos de análisis de datos utilizando el potente lenguaje open source Haskell para proporcionar numerosos ejemplos o recetas para implementarlas. En este post explicaré qué enseñan las recetas que contiene cada capítulo de este completo libro de analítica de datos..
El libro Haskell Data Analysis Cookbook, de Nishant Shukla, hace un recorrido por las principales técnicas y algoritmos de análisis de datos utilizando el potente lenguaje open source Haskell para proporcionar numerosos ejemplos o recetas para implementarlas. En este post explicaré qué enseñan las recetas que contiene cada capítulo de este completo libro de analítica de datos.. En el presente post mostramos un sencillo ejemplo de análisis discriminante en SAS que puede servir para analizar relaciones entre variables en un conjunto de datos. En el caso que vamos a estudiar, este análisis permite discriminar qué variable de las que caracteriza a un conjunto de clientes tiene más peso en la tasa de bajas
En el presente post mostramos un sencillo ejemplo de análisis discriminante en SAS que puede servir para analizar relaciones entre variables en un conjunto de datos. En el caso que vamos a estudiar, este análisis permite discriminar qué variable de las que caracteriza a un conjunto de clientes tiene más peso en la tasa de bajas De forma ineludible el crecimiento de las redes sociales está cambiando la concepción del valor del cliente por parte de las organizaciones. Se trata de un aspecto clave en la relación con los clientes que se analiza en el estudio 'Re-envisioning Customer Value', publicado en ‘The Economist’ y patrocinado por SAS.
De forma ineludible el crecimiento de las redes sociales está cambiando la concepción del valor del cliente por parte de las organizaciones. Se trata de un aspecto clave en la relación con los clientes que se analiza en el estudio 'Re-envisioning Customer Value', publicado en ‘The Economist’ y patrocinado por SAS.
