
Hola a todos:
Estoy preparando el diseño de un DW para utilizarlo con Pentaho, y al revisar la definición de la dimensión tiempo me han surgido algunas dudas. Os cuento:
Es un Dw para analisis de ventas. En el modelo tengo dos tablas de hechos, una para las ventas, cuya granuralidad es a nivel de día, cliente, producto, etc, y otra tabla de hechos donde se registra la información de la previsión de ventas (esta tabla tiene un nivel de granuralidad diferente, siendo a nivel de mes y canal de cliente (que es uno de los atributos de la dimension cliente)). Las claves de la tabla de hechos no son por tanto las claves de la tabla de dimensiones, sino un componente dentro de la dimensión.
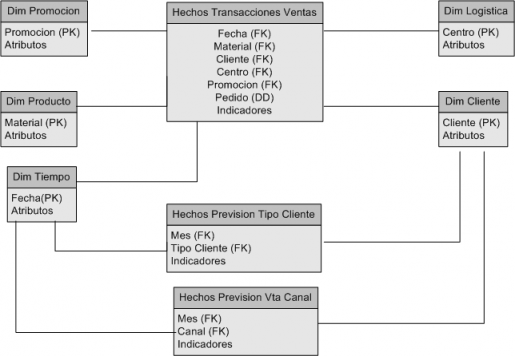
Modelo Logico Inicial
Teniendo en cuenta esto, me surgen bastantes dudas sobre el mejor diseño a elegir para construir la base de datos:
1) Al tener las tablas de hechos en un nivel diferente de granuralidad, ¿es necesario o recomendable pasar las dimensiones implicadas a un esquema de estrella para que luego funcionen correctamente las consultas?.
2) ¿Puede darse el caso de que aspectos de diseño como este sean condicionados por la herramienta que vamos a utilizar posteriormente?. Por ejemplo, si se que voy a utilizar Pentaho, o Microstrategy, etc, ¿puede darse el caso que el usar una herramienta u otra este determinando una forma de modelar en algunos aspectos concretos?. He leido en algún blog que por ejemplo, Microstrategy recomienda pasarnos a un esquema de copo de nieve (incluso los ejemplos que proporciona con su plataforma, los Analytic Modules, estan construidos de esa manera).
3) ¿Podriamos generalizar que para un esquema sencillo utilizamos sin problemas un esquema estrella total, pero en el momento que complicamos el modelo con mas tablas de hechos y diferentes granuralidades es mejor pasarse a copo de nieve?. ¿Para seguir la metodologia de Kimball en lo referente a las dimensiones conformadas es necesario hacer tambien eso, y asi poder abordar los modelos complejos con multiples tablas de hechos?.
Espero que me echeis un cable, sobre todo aquellos que teneis experiencia en la construcción de DW. Es un tema que para mi es un poco confuso (ademas en los ejemplos siempre se utilizan esquemas en estrella sencillos para ilustrar, que luego no corresponden con la realidad mas compleja).
- Log in to post comments

Para liar aun mas la
Submitted by respinosamilla on 21 April, 2010 - 11:35
Para liar aun mas la historia, mirar como Microstrategy implementa la dimensión tiempo en sus Analytic Modules, como os decia antes:
No es exactamente un copo de nieve y desde la fecha podemos llegar al mes, al trimestre o al año (es un grafo ciclico).
En el Blog La Mina Digital hay una interesante entrada sobre el dilema. Lo curioso es que no se decanta claramente por ninguna, aunque da unas premisas que nos pueden ser utiles para la decision.
Si gustas puedes contactarme
Submitted by Róger Guzmán (not verified) on 23 April, 2010 - 22:28
In reply to Para liar aun mas la by respinosamilla
Si gustas puedes contactarme al email y con gusto puedo ayudarte con la duda que tienes.
Luego si gustas la puedes comentar.
Saludos
A este email estaría
Submitted by Róger Guzmán (not verified) on 23 April, 2010 - 22:28
In reply to Si gustas puedes contactarme by Róger Guzmán (not verified)
A este email estaría bien
roger_guzman_22@hotmail.com
Roger, y no sería más
Submitted by Carlos on 24 April, 2010 - 09:54
In reply to A este email estaría by Róger Guzmán (not verified)
Roger, y no sería más sencillo si hicieras directamente un comentario sobre el diseño, o sobre las dudas que plantea Roberto?
Despues de darle muchas
Submitted by respinosamilla on 25 April, 2010 - 23:24
Despues de darle muchas vueltas, releer en los libros de referencia y buscar información, creo que lo he entendido y una solución sería la siguiente:
La dimensión Tiempo tendría la siguiente estructura, incluyendo todos los atributos habituales de una dimension tiempo:
Como vamos a tener una tabla de hechos a nivel de día (nivel de granuralidad) y otras dos tablas de hechos a nivel mes (diferente nivel), necesitaremos tener una tabla de dimensión para el mes. Para solucionar este problema, tenemos dos opciones:
Dimensión derivada para el mes en la dimensión Tiempo
Modelo Lógico - Dimension Tiempo Normalizada
Para nuestro caso, nos quedamos con la opción 1, que es la recomendada por Kimball. Como vemos, hemos creado un set o subconjunto de la dimensión tiempo, y todos los atributos tienen los mismos nombres tanto en la dimensión original como en la dimensión derivada. Con esta filosofia podemos construir dimensiones conformadas que nos ayudan a implementar el concepto del data warehouse Bus. La técnica la podemos utilizar para cualquier caso que tengamos un diferente nivel de granuralidad. También se podría utilizar para el caso de que tengamos un datamart donde nos llevamos la dimensión con la misma estructura de atributos, pero limitando el número de valores (imaginar que tenemos varios canales de venta y para un análisis concreto, solo nos llevamos a la dimensión derivada los valores de clientes de uno de esos canales).
Concepto de Dimensión Roll-up o derivada
Para la construcción de la nueva dimensión, podriamos utilizar una vista normal o una vista materializada.
Creo que con esto contesto a las dudas que plantee. No es necesario pasar al modelo normalizado cuando se plantea el problema de tablas de hechos con diferente granuralidad, y ademas el metodo descrito lo podemos utilizar siempre que se plantee un escenario similar.
Estoy de acuerdo en todo lo
Submitted by Carlos on 26 April, 2010 - 12:30
In reply to Despues de darle muchas by respinosamilla
Estoy de acuerdo en todo lo que comentas en tu autorespuesta, yo lo resolvería de la misma manera.
Yo, como norma, siempre comienzo por crear un modelo lógico totalmente desnormalizado y después, al entrar más en detalle pensando ya en el modelo fisico, me voy planteando, entre otras cosas, la utilización de dimensiones conformadas, o incluso la normalización de alguna dimensión.
Pero para mi la normalización es siempre el último recurso, me gustan más las estrellas que los copos de nieve ;)
Lo que sí es cierto es que cuando nos encaramos ya hacia el diseño físico hay que empezar a pensar en el software de BI que vamos a utilizar, y en muchos casos los requerimientos del mismo pueden influir mucho en la decisión final.
Yo tengo más experiencia en herramientas ROLAP, y tiendo a pensar en soluciones que se apoyen en bases de datos, pero el panorama puede cambiar bastante si tenemos que optimizar nuestro diseño para que la explotación del Data Warehouse de haga con herramientas MOLAP.
Gracias por tu comentario,
Submitted by respinosamilla on 26 April, 2010 - 13:53
In reply to Estoy de acuerdo en todo lo by Carlos
Gracias por tu comentario, Carlos. Creo que al final lo he entendido. Y supongo que como tu dices, cuando vas a utilizar determinadas herramientas, es normal que hagas el diseño físico pensando en como se comporta y que peculiaridades tiene cada una de ellas. Y tambien esta el enfoque personal de cada uno conforme a las experiencias que haya ido teniendo en proyectos.
Un saludo.
Buenas tardes yo quiero
Submitted by sistemasmjdiaz (not verified) on 26 April, 2010 - 22:46
In reply to Estoy de acuerdo en todo lo by Carlos
Buenas tardes
yo quiero trabajar en pentaho quisiera saber si es Rolap o Molap,
Quiero contarles un poco el problema que tengo, estoy trabajando con la base de datos en moodle, en este momento estoy haciendo la construcción del modelo, estoy enredada si lo hago como copo de nieve o como estrella por aquello que una de las dimension curso tiene asociadas categorias.
Tambien quisiera saber como funciona petaho Kettle como principal inquietud, pues nose como construir este modelo ahi, la ayuda que me puedan brindar quedare muy agradecida, con un ejemplo claro de un modelo parecido seria muy bueno.
Pentaho utiliza Mondrian como
Submitted by Carlos on 27 April, 2010 - 11:36
In reply to Buenas tardes yo quiero by sistemasmjdiaz (not verified)
Pentaho utiliza Mondrian como servidor de BI, y Mondrian es ROLAP porque almacena las estructuras OLAP que utiliza en una base de datos. Si quieres saber más detalles puedes consultar esta explicación de la arquitectura de Mondrian en la web de Pentaho.
Sobre Kettle, rebautizado como Pentaho Data Integration tienes bastante documentación en el apartado correspondiente de la web de Pentaho Community. Otra opción que te puedes plantear es adquirir el libro Pentaho 3.2 Data Integration que acaba de publicar Maria Carina Roldan, o al menos mirarte el capítulo sobre la construcción de un Datamart con PDI, que se puede descargar libremente.
Sobre el diseño que muestras, yo no le veo el problema, ni tampoco veo ninguna razón para crear un copo de nieve.
Buenas tardes quería saber
Submitted by nelsonlujan (not verified) on 12 May, 2015 - 00:11
Hola Nelson MicroStrategy
Submitted by Carlos on 12 May, 2015 - 13:45
In reply to Buenas tardes quería saber by nelsonlujan (not verified)